openCV中KNN算法的实现
432人参与 • 2025-04-14 • 算法
opencv 是一个开源的跨平台计算机视觉库,它提供了各种用于图像处理、计算机视觉任务的算法和工具,涵盖图像滤波、特征提取、目标检测、图像分割、视频分析等众多领域,广泛应用于计算机视觉相关的科研和工业项目中,可帮助开发者快速实现各种视觉处理功能。
knn(k-最近邻)算法是一种简单且常用的分类算法。其核心思想是:如果一个样本在特征空间中的k个最相似的样本中的大多数属于某一个类别,则该样本也属于这个类别
knn算法流程
计算距离:使用向量之间的距离来衡量样本之间的相似度。常见的距离计算公式有欧式距离、曼哈顿距离等。
升序排序:根据计算好的距离进行升序排序。
取前k样本:选取距离最近的前k个样本。
加权平均:根据距离对样本进行加权计算,距离越近,权重越高。
使用opencv实现knn
以下是一张2000x1000像素的图片,包含5000个数字,我们将左边2500个数划分训练集,右边2500个数划分为测试集,构建模型训练结果

首先对图像进行切割并划分训练集和测试集
import numpy as np
import cv2
img=cv2.imread('digits.png')#读取名为 digits.png 的图像文件。
gray=cv2.cvtcolor(img,cv2.color_bgr2gray)#将图像转换为灰度图
cells=[np.hsplit(row,100) for row in np.vsplit(gray,50)]#将图像垂直分割50行,水平分割100列
x=np.array(cells)
train=x[:,:50]#划分训练集
test=x[:,50:100]#划分测试集
#将数据展平并转换为浮点型
train_new=train.reshape(-1,400).astype(np.float32)
test_new=test.reshape(-1,400).astype(np.float32)创建标签并对模型进行训练
k=np.arange(10)#生成一个数组 [0, 1, 2, ..., 9] labels=np.repeat(k,250)#将每个数字重复250次,生成标签数组,形状为 (2500,) train_labels=labels[:,np.newaxis]#将标签数组转换为列向量,形状为 (2500, 1) test_labels=np.repeat(k,250)[:,np.newaxis] knn=cv2.ml.knearest_create()#创建knn模型 knn.train(train_new,cv2.ml.row_sample,train_labels)#使用训练数据和标签训练模型
测试模型,计算准确率
ret,result,neighbours,dist=knn.findnearest(test_new,k=3)#对测试数据进行预测,k=3 表示使用3个最近邻居。ret:是否成功执行。result:预测结果。neighbours:最近的邻居。dist:与邻居的距离。
print(ret,result,neighbours,dist)
#计算准确率
matches=result==test_labels
correct=np.count_nonzero(matches)
accuracy=correct*100.0/result.size
print("当前使用knn识别手写数字的准确率为{}%。".format(accuracy))最终代码输出得到以下结果
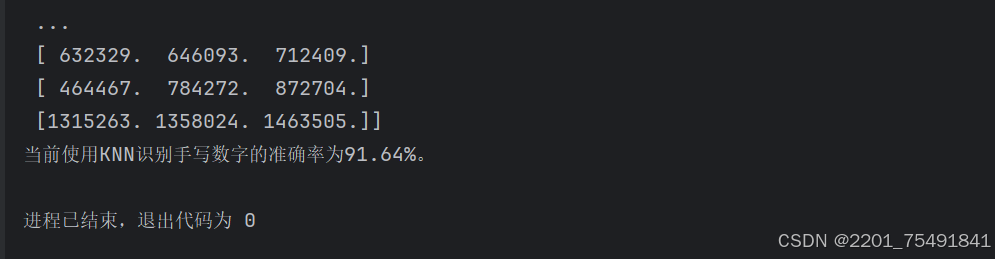
到此这篇关于opencv中knn算法的实现的文章就介绍到这了,更多相关opencv knn 内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!
赞 (0)
您想发表意见!!点此发布评论




发表评论