redis之数据过期清除策略、缓存淘汰策略详解
204人参与 • 2025-04-23 • Redis
redis是一个内存型数据库,我们的数据都是放在内存里面的!但是内存是有大小的!比如,redis有个很重要的配置文件,redis.conf,里面有个配置
# maxmemory <bytes> //redis占用的最大内存
如果我们不淘汰,那么它的数据就会满,满了肯定就不能再放数据,发挥不了redis的作用!
比如冰箱,你如果放满了,那么你的菜就不能放冰箱了!
过期策略:拿出redis中已经过期了的数据,就像你从冰箱把坏的菜拿出来!!但是有一种情况,就是冰箱里面的菜都没坏,redis里面的数据都没过期,它也是会放满的,那怎么办?
那么当redis里面的数据都没过期。但是内存满了的时候,我们就得从未过期的数据里面去拿出一些扔掉,那么这个就是我们的淘汰策略。
过期策略
redis 所有的数据结构都可以设置过期时间,时间一到,就会自动删除。可以想象里面有一个专门删除过期数据的线程,数据已过期就立马删除。
这个时候可以思考一下,会不会因为同一时间太多的 key 过期,以至于线程忙不过来。同时因为 redis 是单线程的,删除的时间也会占用线程的处理时间,如果删除的太过于繁忙,会不会导致线上读写指令出现卡顿。
立即删除
- 它会在设置键的过期时间的同时,创建一个定时器, 当键到了过期时间,定时器会立即对键进行删除。
- 这个策略能够保证过期键的尽快删除,快速释放内存空间。
优点:
- 立即删除能保证内存中数据的最大新鲜度,因为它保证过期键值会在过期后马上被删除,其所占用的内存也会随之释放。
- 对内存来说是非常友好的。
缺点:
- 立即删除对cpu是最不友好的。
- 因为删除操作会占用cpu的时间,如果刚好碰上了cpu很忙的时候,比如正在做交集或排序等计算的时候,就会给cpu造成额外的压力。
总结:
- 立即删除对cpu不友好,但是对内存友好,实际性质就是用处理器性能换区内存空间。
惰性删除(被动过期)
- 数据到达过期时间,不做处理。等下次访问该数据时,如果未过期,返回数据 ;发现已过期,删除,返回不存在。
- 开启惰性删除:lazyfree-lazy-eviction=yes
优点:
- 对于cpu来说是非常友好的,减少了cpu资源的占有。
缺点:
- 如果一个键已经过期,而这个键又仍然保留在redis中,那么只要这个过期键不被删除,它所占用的内存就不会释放。因此对于内存是很不友好的。
- 在使用惰性删除策略时,如果数据库中有非常多的过期键,而这些过期键又恰好没有被访问到的话,那么它们也许永远也不会被删除(除非用户手动执行flushdb),我们甚至可以将这种情况看作是一种内存泄漏–无用的垃圾数据占用了大量的内存,而服务器却不会自己去释放它们,这对于运行状态非常依赖于内存的redis服务器来说,肯定不是一个好消息
定期删除
- 定期删除策略是前两种策略的折中:
- 定期删除策略每隔一段时间执行一次删除过期键操作并通过限制删除操作执行时长和频率来减少删除操作对cpu时间的影响。
过期key的集合
redis 会将每个设置了过期时间的 key 放入到一个独立的字典中,以后会定时遍历这个 字典来删除到期的 key。除了定时遍历之外,它还会使用惰性策略来删除过期的 key。定期删除是集中处理,惰性删除是零散处理。
定时扫描策略
redis 默认会每秒进行十次过期扫描,过期扫描不会遍历过期字典中所有的 key,而是 采用了一种简单的贪心策略。
- 从过期字典中随机 20 个 key;
- 删除这 20 个 key 中已经过期的 key;
- 如果过期的 key 比率超过 1/4,那就重复步骤 1;
于此同时为了保证过期扫描不会出现循环过度,导致线程卡死现象,算法还增加了扫描时间的上限,默认不会超过 25ms。
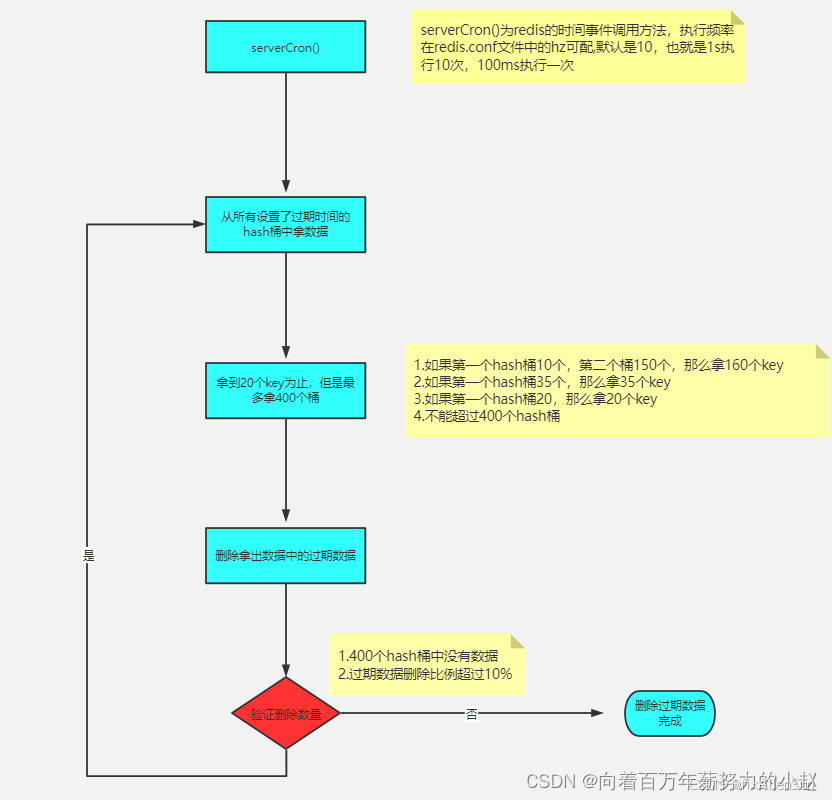
(1)定时过期到底是怎么实现?
定期去循环找过期的key,然后去删掉!
(2)去循环谁?是不是所有的key?
并不是去循环所有的key,因为redis里经常会存放巨多的数据,对我们需要经常清理,全部遍历一遍显然不现实,而redis采取的是取样这个操作。
- 1-不是一次性把所有设置了过期时间的数据拿出来,而是按hash桶维度取 里面取值,取到20个值为止,如果第一个有30个,那么也会取30个! 如果一直取不到20,那么最多400个桶
- 2-删除取出值的过期key
- 3-如果400个桶都取不到值,或者取出的key 删除的比例大于10%,继续上 面的操作
- 4-每循环16次会去检测时间,超过指定时间就跳出
ps:按hash桶维度取key的逻辑是:最后一个桶会取完桶内所有的key,不论里面有多少个,每取完一个桶判断一下是否取到了20个,最多取400个桶。
(3)多久循环一次?
redis里面有个很重要的概念叫做时间事件,那么这个时间事件是什么意思了,就是定时去做一些事情,那么redis里面有个方法叫servercron(),在文件server.c中;就是它的时间事件去调用的清理
它里面干了很多事情,比如:
- 1-更新服务器的各类统计信息,比如时间、内存占用、数据库占用情况等
- 2-清理数据库中的过期键值对。
- 3-关闭和清理连接失效的客户端
- 4-尝试进行持久化操作
那么这个时间事件多久去执行一次呢,其实是由你们自己决定的!
redis.conf 中通过 hz 配置,hz代表的意思是每秒执行多少次!默认10次,也就是100ms我们就会去执行定期过期!!
特别注意的情况
设想一个大型的 redis 实例中所有的 key 在同一时间过期了。redis 会持续扫描过期字典 (循环多次),直到过期字典中过期的 key 变得稀 疏,才会停止 (循环次数明显下降)。这就会导致线上读写请求出现明显的卡顿现象。导致这 种卡顿的另外一种原因是内存管理器需要频繁回收内存页,这也会产生一定的 cpu 消耗。
即使算法还增加了扫描时间的上限,也是会出现卡顿现象。假如有 101 个客户端同时将请求发过来了,然后前 100 个请求的执行时间都是 25ms,那么第 101 个指令需要等待多久才能执行?2500ms,这个就是客户端的卡顿时间,是由服务器不间断的小卡顿积少成多导致的(假如每次都达到了扫描上线25ms)。
所以开发的时候就需要特别注意,避免大量key在同一时间过期。可以给key在固定的过期时间上+随机范围的时间
定期删除注意事项
如果删除操作执行次数过多、执行时间太长,就会导致和定时删除同样的问题:占用大量cpu资源去进行删除操作
如果删除操作次数太少、执行时间短,就会导致和惰性删除同样的问题:内存资源被持续占用,得不到释放。
所以定时删除最关键的就在于执行时长和频率的设置,可在redis的配置文件中配置
对于hz参数,官方不建议超过100,否则会把cpu造成比较大的压力
缓存淘汰策略
缓存淘汰策略的作用
(1)当 redis 内存超出物理内存限制时,内存的数据会开始和磁盘产生频繁的交换,交换会让 redis 的性能急剧下降,对于访问量比较频繁的 redis 来说,这样龟速的存取效率 基本上等于不可用。
(2)一般生产上的redis内存都会设置一个内存上限(maxmemory),如果有许多没有加过期时间的数据,长期下来就会把redis内存打满,出现oom异常。
(3)定期删除是使用简单的贪心算法,会出现一些没有被抽查到的数据,而惰性删除也会出现一些长时间没有访问得数据,这就会导致大量过期的key堆积在内存中,导致redis内存空间紧张或者很快耗尽。所以必须要有一个兜底方案。这个方案就是缓存淘汰策略。
八种缓存淘汰策略
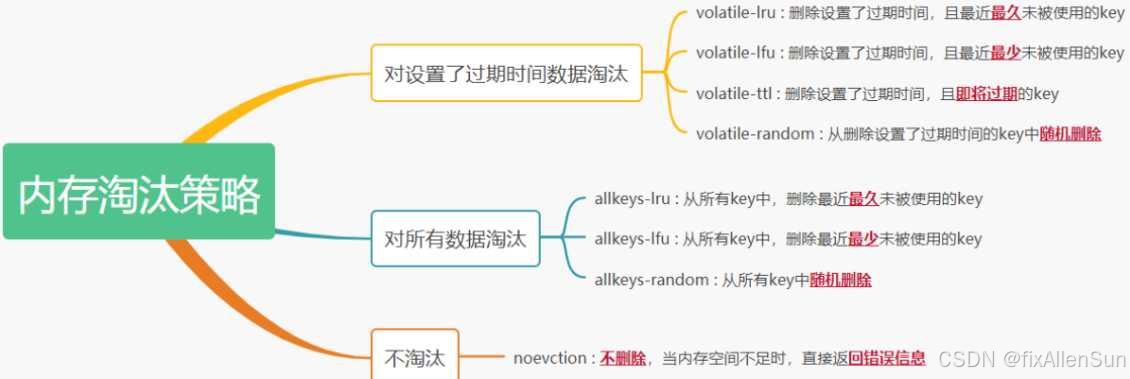
noeviction:不会继续服务写请求 (del 请求可以继续服务),读请求可以继续进行。这样 可以保证不会丢失数据,但是会让线上的业务不能持续进行。这是默认的淘汰策略。volatile-lru:尝试淘汰设置了过期时间的 key,最少使用的 key 优先被淘汰。没有设置过 期时间的 key: 不会被淘汰,这样可以保证需要持久化的数据不会突然丢失。allkeys-lru: 区别于 volatile-lru,这个策略要淘汰的 key 对象是全体的 key 集合,而不 只是过期的 key 集合。这意味着没有设置过期时间的 key 也会被淘汰。volatile-ttl: 跟上面一样,除了淘汰的策略不是 lru,而是 key 的剩余寿命 ttl 的值,ttl 越小越优先被淘汰。volatile-random:对所有设置了过期时间的key随机淘汰。allkeys-random:对所有key随机淘汰volatile-lfu:对设置了过期时间的key使用lfu算法进行删除allkeys-lfu:对所有key使用lfu算法进行删除
总结:
- volatile-xxx: 策略只会针对带过期时间的 key 进行淘汰,allkeys-xxx 策略会对所有的 key 进行淘汰。
- 如果你只是拿 redis 做缓存,那应该使用 allkeys-xxx,客户端写缓存时 不必携带过期时间。
- 如果你还想同时使用 redis 的持久化功能,那就使用 volatile-xxx 策略,这样可以保留没有设置过期时间的 key,它们是永久的 key 不会被 lru 算法淘 汰。
ps:是在config文件中配置的策略:
#maxmemory-policy noeviction
默认就是不淘汰,如果满了,能读不能写!
lru和lfu
lru(least recently used:最久未使用)
根据时间轴来走,很久没用的数据只要最近有用过,我就默认是有效的。也就是说这个策略的意思是先淘汰长时间没用过的,那么怎么去判断一个redis数据有多久没访问了,redis是这样做的:
redis的所有数据结构的对外对象里,它里面有个字段叫做lru
typedef struct redisobject {
unsigned type:4;
unsigned encoding:4;
unsigned lru:lru_bits;
/*
\*lru time (relative to global lru_clock) or
\* lfu data (least significant 8 bits frequency
\* and most significant 16 bits access time).
*/
int refcount;
void *ptr;
} robj;
每个对象都有1个lru的字段,看它的说明,好像lru跟我们后面讲的lfu都跟这个字段有关,并且这个lru代表的是一个时间相关的内容。
那么我们大概能猜出来,redis去实现lru肯定跟我们这个对象的lru相关!!
首先,我告诉大家,这个lru在lru算法的时候代表的是这个数据的访问时间的秒单位!!但是只有24bit,无符号位,所以这个lru记录的是它访问时候的秒单位时间的后24bit!
用java来写就是:
long timemillis=system.currenttimemillis(); system.out.println(timemillis/1000); //获取当前秒 system.out.println(timemillis/1000 & ((1<<24)-1));//获取秒的后24位
是获取当前时间的最后24位,那么当我们最后的24bit都是1了的时候,时间继续往前走,那么我们获取到的时间是不是就是24个0了!
举个例子:
11111111111111111000000000011111110 假如这个是我当前秒单位的时间,获取后8位 是 11111110 11111111111111111000000000011111111 获取后8位 是11111111 11111111111111111000000000100000000 获取后8位 是00000000
所以,它有个轮询的概念,它如果超过24位,又会从0开始!所以我们不能直接的用系统时间秒单位的24bit位去减对象的lru,而是要判断一下,还有一点,为了性能,我们系统的时间不是实时获取的,而是用redis的时间事件来获取,所以,我们这个时间获取是100ms去获取一次。
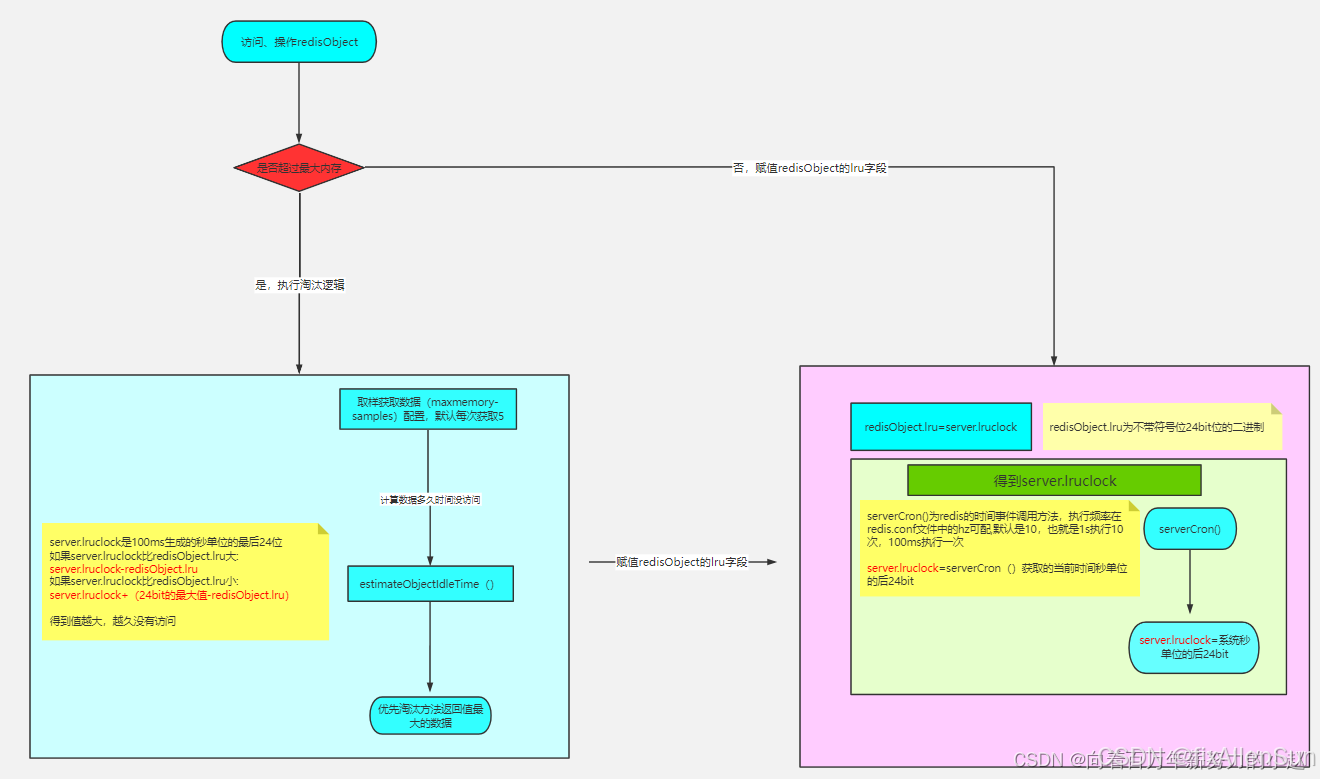
现在我们知道了原来redis对象里面原来有个字段是记录它访问时间的,那么接下来肯定有个东西去跟这个时间去比较,拿到差值!
我们去看下源码evict.c文件
unsigned long long estimateobjectidletime(robj *o) {
//获取秒单位时间的最后24位
unsigned long long lruclock = lru_clock();
//因为只有24位,所有最大的值为2的24次方-1
//超过最大值从0开始,所以需要判断lruclock(当前系统时间)跟缓存对象的lru字段的大小
if (lruclock >= o->lru) {
//如果lruclock>=robj.lru,返回lruclock-o->lru,再转换单位
return (lruclock - o->lru) * lru_clock_resolution;
} else {
//否则采用lruclock + (lru_clock_max - o->lru),得到对象的值越小,返回的值越大,越大越容易被淘汰
return (lruclock + (lru_clock_max - o->lru)) *
lru_clock_resolution;
}
}我们发现,跟对象的lru比较的时间也是servercron下面的当前时间的秒单位的后面24位!但是它有个判断,有种情况是系统时间跟对象的lru的大小,因为最大只有24位,会超过!!
所以,我们可以总结下我们的结论:
redis数据对象的lru用的是server.lruclock这个值,server.lruclock又是每隔100ms生成的系统时间的秒单位的后24位!所以server.lruclock可以理解为延迟了100ms的当前时间秒单位的后24位!
用server.lruclock 与 对象的lru字段进行比较,因为server.lruclock只获取了当前秒单位时间的后24位,所以肯定有个轮询。所以,我们会判断server.lruclock跟对象的lru字段进行比较,如 server.lruclock>obj.lru,那么我们用server.lruclock-obj.lru,否则server.lruclock+(lru_clock_max-obj.lru),得到lru越小,那么返回的数据越大,相差越大的就会被淘汰!
lfu(least frequently used:最不常用)
但是lfu的有个致命的缺点!就是它只会加不会减!为什么说这是个缺点
举个例子:去年有一个热搜,今年有一个热搜,热度相当,但是去年的那个因为有时间的积累,所以点击次数高,今年的点击次数因为刚发生,所以累积起来的次数没有去年的高,那么我们如果已点击次数作为衡量,是不是应该删除的就是今年的?这就导致了新的进不来旧的出不去
所以我们来看redis它是怎么实现的!怎么解决这个缺点!
我们还是来看我们的redisobject
typedef struct redisobject {
unsigned type:4;
unsigned encoding:4;
unsigned lru:lru_bits;
/* lru time (relative to global lru_clock) or
* lfu data (least significant 8 bits frequency
* and most significant 16 bits access time). */
int refcount;
void *ptr;
} robj;
我们看它的lru,它如果被用作lfu的时候!它前面16位代表的是时间,后8位代表的是一个数值,frequency是频率,应该就是代表这个对象的访问次数,我们先给它叫做counter。
那么这个16位的时间跟8位的counter到底有啥用呢?8位我们还能猜测下,可能就是这个对象的访问次数!
我们淘汰的时候,是不是就是去根据这个对象使用的次数,按照小的就去给它淘汰掉。
其实,差不多就是这么个意思。
还有个问题,如果8位用作访问次数的话,那么8位最大也就2的8次方,就是255次,够么?如果,按照我们的想法,肯定不够,那么redis去怎么解决呢?
既然不够,那么让它不用每次都加就可以了,能不能让它值越大,我们加的越慢就能解决这个问题
redis还加了个东西,让你们自己能主宰它加的速率,这个东西就是lfu-log-factor!它配置的越大,那么对象的访问次数就会加的越慢。
源码:
uint8_t lfulogincr(uint8_t counter) {
//如果已经到最大值255,返回255 ,8位的最大值
if (counter == 255) return 255;
//得到随机数(0-1)
double r = (double)rand()/rand_max;
//lfu_init_val表示基数值(在server.h配置)
double baseval = counter - lfu_init_val;
//如果达不到基数值,表示快不行了,baseval =0
if (baseval < 0) baseval = 0;
//如果快不行了,肯定给他加counter
//不然,按照几率是否加counter,同时跟baseval与lfu_log_factor相关
//都是在分子,所以2个值越大,加counter几率越小
double p = 1.0/(baseval*server.lfu_log_factor+1);
if (r < p) counter++;
return counter;
}所以,lfu加的逻辑我们可以总结下:
(1)如果已经是最大值,我们不再加!因为到达255的几率不是很高!可以支撑很大很大的数据量!
(2)counter属于随机添加,添加的几率根据已有的counter值和配置lfu-log-factor相关,counter值越大,添加的几率越小,lfu-log-factor配置的值越大,添加的几率越小!
我们的这个16bit记录的是这个对象的访问时间的分单位的后16位,每次访问或者操作的时候,都会去跟当前时间的分单位的后16位去比较,得到多少分钟没有访问了!然后去减去对应的次数!
那么这个次数每分钟没访问减多少了,就是根据我们的配置lfu-decay-time。
这样就能够实现我们的lfu,并且还解决了lfu不能减的问题。
- 总结如图:
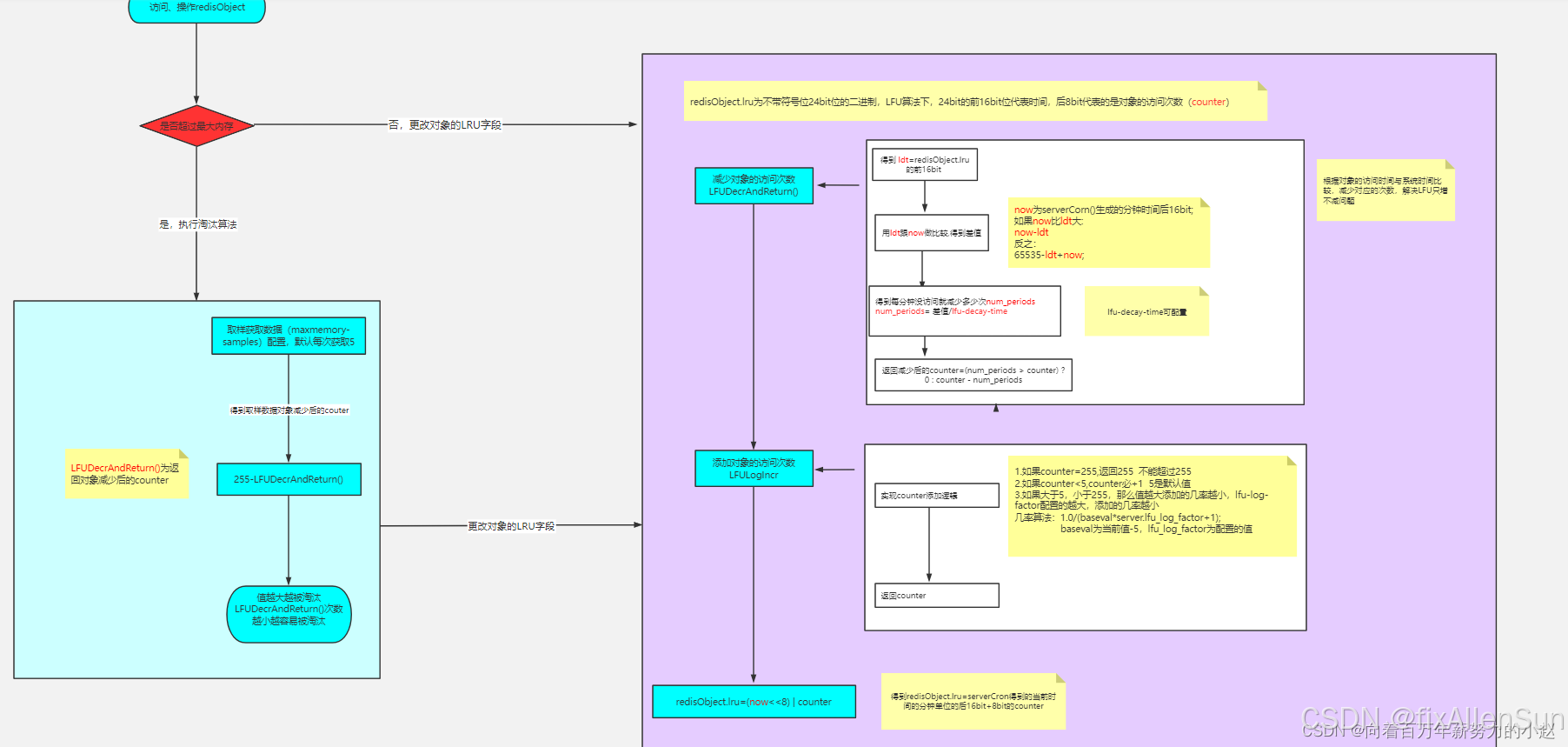
贴出减的源码:
unsigned long lfudecrandreturn(robj *o) {
//lru字段右移8位,得到前面16位的时间
unsigned long ldt = o->lru >> 8;
//lru字段与255进行&运算(255代表8位的最大值),
//得到8位counter值
unsigned long counter = o->lru & 255;
//如果配置了lfu_decay_time,用lfutimeelapsed(ldt) 除以配置的值
//lfutimeelapsed(ldt)源码见下
//总的没访问的分钟时间/配置值,得到每分钟没访问衰减多少
unsigned long num_periods = server.lfu_decay_time ?lfutimeelapsed(ldt) / server.lfu_decay_time : 0;
if (num_periods)
//不能减少为负数,非负数用couter值减去衰减值
counter = (num_periods > counter) ? 0 : counter - num_periods;
return counter;
}
lfutimeelapsed方法源码(evict.c):
//对象ldt时间的值越小,则说明时间过得越久
unsigned long lfutimeelapsed(unsigned long ldt) {
//得到当前时间分钟数的后面16位
unsigned long now = lfugettimeinminutes();
//如果当前时间分钟数的后面16位大于缓存对象的16位
//得到2个的差值
if (now >= ldt) return now-ldt;
//如果缓存对象的时间值大于当前时间后16位值,则用65535-ldt+now得到差值
return 65535-ldt+now;
}所以,lfu减逻辑我们可以总结下:
(1)我们可以根据对象的lru字段的前16位得到对象的访问时间(分钟),根据跟系统时间比较获取到多久没有访问过!
(2)根据lfu-decay-time(配置),代表每分钟没访问减少多少counter,不能减成负数
区别
- lru:最近最少使用页面置换算法,淘汰最长时间未被使用的页面,看页面最后一次被使用到发生调度的时间长短,首先淘汰最长时间未被使用的页面。
- lfu:最近最不常用页面置换算法,淘汰一定时期内被访问次数最少的页,看一定时间段内页面被使用的频率,淘汰一定时期内被访问次数最少的页
举个栗子:
- 某次时期time为10分钟,如果每分钟进行一次调页,主存块为3,若所需页面走向为2 1 2 1 2 3 4
- 假设到页面4时会发生缺页中断
- 若按lru算法,应换页面1(1页面最久未被使用),但按lfu算法应换页面3(十分钟内,页面3只使用了一次)
- 可见lru关键是看页面最后一次被使用到发生调度的时间长短,而lfu关键是看一定时间段内页面被使用的频率!
手写lru算法
底层shuju
- 使用linkedhashmap实现
/**
* @description :
* @author : huangcong
* @date : 2023/6/28 9:48
**/
public class linkedhashmaplru<k, v> extends linkedhashmap<k, v> {
private integer initialcapacity;
public linkedhashmaplru(integer initialcapacity) {
super(initialcapacity, 0.75f, boolean.false);
this.initialcapacity = initialcapacity;
}
@override
protected boolean removeeldestentry(map.entry<k, v> eldest) {
return super.size() > initialcapacity;
}
public object getvalue(object key) {
object v = super.get(key);
if (objects.isnull(v)) {
return -1;
}
return v;
}
public static void main(string[] args) {
linkedhashmaplru<object, object> hashmaplru = new linkedhashmaplru<>(3);
hashmaplru.put(1, "a");
hashmaplru.put(2, "b");
hashmaplru.put(3, "c");
system.out.println(hashmaplru.entryset());
// key存在变更其数据
hashmaplru.put(3, "l");
system.out.println(hashmaplru.entryset());
// 当缓存容量达到上限时,它应该在写入新数据之前删除最久未使用的数据值
hashmaplru.put(4, "d");
system.out.println(hashmaplru.entryset());
hashmaplru.put(5, "f");
system.out.println(hashmaplru.entryset());
// 获取数据 get(key) - 如果关键字 (key) 存在于缓存中,则获取关键字的值(总是正数),否则返回 -1
object value =hashmaplru.getvalue(1);
system.out.println(value);
}
}
- 其他方式实现
/**
* @description : 构造一个node节点,承载数据
* @author : hc
* @date : 2023/6/28 12:14
**/
public class node<k, v> {
k key;
v value;
node<k, v> pre;
node<k, v> next;
public node() {
}
public node(k key, v value) {
this.key = key;
this.value = value;
this.pre = this.next = null;
}
public void setkey(k key) {
this.key = key;
}
public void setvalue(v value) {
this.value = value;
}
}
/**
* @description :双向链表
* @author : hc
* @date : 2023/6/28 12:23
**/
public class lrucache <k,v>{
node<k,v> head;
node<k,v> tail;
public lrucache() {
head = new node<>();
tail = new node<>();
head.next = tail;
tail.pre = head;
}
// 头插法,靠近头部的是最新的数据
public void add(node<k,v> node){
node.next = head.next;
node.pre = head;
head.next.pre = node;
head.next = node;
}
public void delete(node<k,v> node){
node.next.pre =node.pre;
node.pre.next = node.next;
node.next = null;
node.pre = null;
}
public node getnode(){
return tail.pre;
}
// 打印链表
public string getcache(){
stringbuffer stringbuffer = new stringbuffer();
node<k, v> node = head.next;
while (node != tail){
stringbuffer.append(node.key+"="+node.value + "\r\n");
node = node.next;
}
return stringbuffer.tostring();
}
}
/**
* @description :
* hash表:通过hash函数计算出hash值,然后(hash值 % 数组大小)得到对应数组中的位置
* @author : hc
* @date : 2023/6/28 16:23
**/
public class lru {
private integer cachesize; // 规定容器大小
private map<integer,node<integer,integer>> map; // hash表,方便查找
private lrucache<integer,integer> doublelinkedmap;// 双向链表,方便插入以及删除
public lru(integer cachesize) {
this.cachesize = cachesize;
map = new hashmap<>();
doublelinkedmap = new lrucache<>();
}
public int get(integer key){
if (!map.containskey(key)){
return -1;
}
node<integer, integer> node = map.get(key);
doublelinkedmap.delete(node);
doublelinkedmap.add(node);
return node.value;
}
public integer put(integer key,integer value){
// 如果哈希表中有,替换节点的value值
if (map.containskey(key)){
node<integer, integer> node = map.get(key);
node.setvalue(value);
doublelinkedmap.delete(node);
doublelinkedmap.add(node);
return key;
}
node<integer, integer> node = new node<>(key, value);
// 如果hash没有,且容器中数据已经达到了规定大小,删除最后一个数据,在头部添加一个最新数据
if (map.size() >= cachesize){
node lastnode = doublelinkedmap.getnode();
doublelinkedmap.delete(lastnode);
doublelinkedmap.add(node);
map.remove(key);
map.put(key,node);
return key;
}
// 如果hash没有,且容器中数据未达到了规定大小,直接在头部添加一个最新数据
doublelinkedmap.add(node);
map.put(key,node);
return key;
}
// 删除节点
public integer delete(integer key){
if (!map.containskey(key)){
return -1;
}
node<integer, integer> node = map.get(key);
doublelinkedmap.delete(node);
map.remove(key);
return key;
}
public static void main(string[] args) {
lru lru = new lru(3);
lru.put(1,1);
lru.put(2,2);
lru.put(3,3);
system.out.println(lru.doublelinkedmap.getcache());
lru.put(2,4);
system.out.println(lru.doublelinkedmap.getcache());
lru.put(4,4);
system.out.println(lru.doublelinkedmap.getcache());
int i = lru.get(3);
system.out.println(i);
system.out.println(lru.doublelinkedmap.getcache());
}
}运行结果:
3=3
2=2
1=12=4
3=3
1=14=4
2=4
3=33
3=3
4=4
2=4
总结
以上为个人经验,希望能给大家一个参考,也希望大家多多支持代码网。
赞 (0)
您想发表意见!!点此发布评论






发表评论