114人参与 • 2025-04-24 • Mysql
语法:insert [into] table_name [column , column...] values (value_list) [ ,(value_list)];
mysql> create table students (
-> id int unsigned primary key auto_increment,
-> number int not null unique comment '学号',
-> name varchar(20) not null,
-> telephone char(11)
-> );
query ok, 0 rows affected (0.05 sec)value_list的数量必须和表中定义的字段数量一样的时候,才属于全列插入,才可以省略指定插入元素的部分。因为我们设置了自增属性,所以可以不用给id设定值,但是这样的话,就不属于全列插入了就必须指定插入的字段是哪些了。
//全列插入 insert into students values(1, 202501, '张三', '15812345678'); //指定列插入 insert into students (number, name, telephone) values(202503, '王五', '17712345678');
在插入数据的时候也可以同时插入多条数据,对于多行数据的插入也满足全列插入与指定列插入的规则。
//全列多行插入 insert into students values(4, 202504, '赵六', '12312345678'), (5, 202505, '田七', '12345656789'); //指定列多行插入 insert into students (number, name, telephone) values(202506, '你好', '12312345678'), (202507, '哈哈', '12345656789');
更新语法:on duplicate key update
替换语法:replace
因为一般表中都会有主键和唯一键的约束,那么我们在插入的时候如果出现唯一键和主键冲突的情况就会插入失败,那么如果我们就想插入呢,那么可以使用更新或者替换语句,将数据更新成我们新插入的,或者整个替换一下。
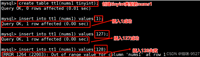
mysql> insert into students (id, number, name) values(1, 202501, '北顾') on duplicate key update number=202510, name = '北顾'; query ok, 2 rows affected (0.00 sec) mysql> select * from students; +----+--------+--------+-------------+ | id | number | name | telephone | +----+--------+--------+-------------+ | 1 | 202510 | 北顾 | 15812345678 | | 2 | 202502 | 李四 | 17712345678 | | 3 | 202503 | 王五 | 17712345678 | | 4 | 202504 | 赵六 | 12312345678 | | 5 | 202505 | 田七 | 12345656789 | | 6 | 202506 | 你好 | 12312345678 | | 7 | 202507 | 哈哈 | 12345656789 | +----+--------+--------+-------------+ 7 rows in set (0.00 sec)
上面的代码为插入否则更新的操作,先使用insert插入数据,如果说遇到主键或者唯一键的冲突而导致的插入失败的时候,可以执行duplicate key update进行数据的更新操作。
如图可以看到返回值发生了变化,如果说插入的数据有冲突的但是冲突的数据和原数据是一样的那么就相当于不做任何操作,返回0;如果说没有数据冲突的话,直接插入返回1;如果有数据冲突,并执行了数据更新操作的话,就返回2。
mysql> replace into students (number, name) value(202510, 'hello'); query ok, 2 rows affected (0.01 sec) mysql> select * from students; +----+---------+--------+-------------+ | id | number | name | telephone | +----+---------+--------+-------------+ | 2 | 202502 | 李四 | 17712345678 | | 3 | 202503 | 王五 | 17712345678 | | 4 | 202504 | 赵六 | 12312345678 | | 5 | 202505 | 田七 | 12345656789 | | 6 | 202506 | 你好 | 12312345678 | | 7 | 202507 | 哈哈 | 12345656789 | | 8 | 202510 | hello | null | +----+---------+--------+-------------+ 9 rows in set (0.00 sec)
上面的代码则是替换代码,他的操作是如果没有冲突那么就直接插入并返回1,如果有冲突大的话,他会先删除冲突数据,然后再重新插入并返回2。
select [column, column] from table_name;
当column不指定且设置为*的时候,就是全列查询了,但是一般不建议使用全列查询,因为查询的列越多,意味着需要传输的数据量就越大,会影响效率。对于指定列查询输入的字段名称不需要和定义的时候顺序一样,select关键字的作用相当于是打印,而我们定义打印什么他就会显示什么,定义什么顺序显示,他就会按什么顺序显示。
上述也说了select是一个起到一个打印显示的作用,而column from table_name,才是指定打印的内容,那么打印的内容可不可以不是表中的呢?或者打印的字段可以不可以是表达式呢?打印的字段可不可以用表中的字段作为参数的表达式呢?
mysql> create table exam (
-> id int unsigned primary key auto_increment,
-> name varchar(20) not null,
-> chinese float default 0.0,
-> math float default 0.0,
-> english float default 0.0
-> );
query ok, 0 rows affected (0.05 sec)
mysql> insert into exam (name, chinese, math, english) values
-> ('张三', 67, 65, 86),
-> ('李四', 98, 56, 84),
-> ('王五', 76, 45, 97),
-> ('赵六', 99, 43, 91);
query ok, 4 rows affected (0.00 sec)
records: 4 duplicates: 0 warnings: 0
//显示非表中的数据
mysql> select 10;
+----+
| 10 |
+----+
| 10 |
+----+
1 row in set (0.00 sec)
//显示表达式数据
mysql> select 10 + 20;
+---------+
| 10 + 20 |
+---------+
| 30 |
+---------+
1 row in set (0.00 sec)
//显示表中数据为参数的表达式数据
mysql> select id + 10 from exam;
+---------+
| id + 10 |
+---------+
| 11 |
| 12 |
| 13 |
| 14 |
+---------+
4 rows in set (0.00 sec)语法:select column [as] alias_name [...] from table_name;
mysql> select 10 + 20 as '总数'; +--------+ | 总数 | +--------+ | 30 | +--------+ 1 row in set (0.00 sec) mysql> select id, name, chinese + math + english as '总分' from exam; +----+--------+--------+ | id | name | 总分 | +----+--------+--------+ | 1 | 张三 | 218 | | 2 | 李四 | 238 | | 3 | 王五 | 218 | | 4 | 赵六 | 233 | +----+--------+--------+ 4 rows in set (0.00 sec)
语法: select distinct column from table_name;
| 运算符 | 说明 |
| >, >=, <, <= | 没有什么特殊含义,就是单纯的比较 |
| = | 等于, |
| <=> | 等于 |
| !=, <> | 不等于 |
between x1 and x2 | 进行范围匹配,如果一个数值再[x1, x2]之间,那么就返回true |
| in (option, ...) | 如果是option中的一个,那么就返回ture |
| is null | 是null |
| is not null | 不是null |
| like | 模糊匹配。 %表示任意多个任意字符;_表示任意一个字符 |
| 运算符 | 说明 |
| and | 多个条件都必须满足才返回true |
| or | 任意满足一个条件返回true |
| not | 满足条件的时候,返回false,相当于匹配不是该条件的内容 |
between x1 and x2
下面是操作符的一些使用案例:
基本比较的使用
mysql> select * from exam; +----+--------+---------+------+---------+ | id | name | chinese | math | english | +----+--------+---------+------+---------+ | 1 | 张三 | 67 | 65 | 86 | | 2 | 李四 | 98 | 56 | 84 | | 3 | 王五 | 76 | 45 | 97 | | 4 | 赵六 | 99 | 43 | 91 | +----+--------+---------+------+---------+ 4 rows in set (0.00 sec) mysql> select id, name, math from exam where math < 60; +----+--------+------+ | id | name | math | +----+--------+------+ | 2 | 李四 | 56 | | 3 | 王五 | 45 | | 4 | 赵六 | 43 | +----+--------+------+ 3 rows in set (0.00 sec)
and与betwenn and的使用
//查询语文分数再80到100之间的同学 mysql> select id, name, chinese from exam where chinese >= 80 and chinese <= 100; +----+--------+---------+ | id | name | chinese | +----+--------+---------+ | 2 | 李四 | 98 | | 4 | 赵六 | 99 | +----+--------+---------+ 2 rows in set (0.00 sec) mysql> select id, name, chinese from exam where chinese between 80 and 100; +----+--------+---------+ | id | name | chinese | +----+--------+---------+ | 2 | 李四 | 98 | | 4 | 赵六 | 99 | +----+--------+---------+ 2 rows in set (0.00 sec)
or与in的使用
//查询英语分数为86或97的同学 mysql> select id, name, english from exam where english=86 or english=97; +----+--------+---------+ | id | name | english | +----+--------+---------+ | 1 | 张三 | 86 | | 3 | 王五 | 97 | +----+--------+---------+ 2 rows in set (0.00 sec) mysql> select id, name, english from exam where english in(86, 97); +----+--------+---------+ | id | name | english | +----+--------+---------+ | 1 | 张三 | 86 | | 3 | 王五 | 97 | +----+--------+---------+ 2 rows in set (0.00 sec)
like的使用
//查询姓张和姓王的同学 mysql> select id, name from exam where name like '张%' or name like '王%'; +----+--------+ | id | name | +----+--------+ | 1 | 张三 | | 3 | 王五 | +----+--------+ 2 rows in set (0.00 sec) mysql> insert into exam values(5, '张文强', 98, 90, 79); query ok, 1 row affected (0.01 sec) //查询名字为2个字,还性张的同学 mysql> select id, name from exam where name like '张_'; +----+--------+ | id | name | +----+--------+ | 1 | 张三 | +----+--------+ 1 row in set (0.00 sec)
where与表达式混合使用
//总分大于230的同学 mysql> select id, name, chinese + math + english as '总分' from exam where chinese + math + english > 230; +----+-----------+--------+ | id | name | 总分 | +----+-----------+--------+ | 2 | 李四 | 238 | | 4 | 赵六 | 233 | | 5 | 田七 | 231 | | 6 | 张文强 | 267 | +----+-----------+--------+ 4 rows in set (0.00 sec)
and与not混合使用
//语文分数大于90,不是不姓李的同学 mysql> select name, chinese from exam where chinese > 90 and name not like '李_'; +-----------+---------+ | name | chinese | +-----------+---------+ | 赵六 | 99 | | 田七 | 92 | | 张文强 | 98 | +-----------+---------+ 3 rows in set (0.00 sec)
=和<=>的区别
两者都是判断两个值是否相等的,但是第一个属于非安全的,如果用null去和任意值就行比较的话,都会返回null,因为mysql中对于null代表的是未知的值,所以说比较的时候结果也是未知的。而<=>的话能处理null值的比较,会把null当作一个值来看待,如果都是null就返回1,不是返回0。
语法:select ... from table_name ... order by column [asc|desc], [...];
使用案例:select * from tset_table order by xxxx;
操作是将select选出的显示数据,按照column数据的值进行升序或者降序排列显示,asc是默认值,表示升序,desc表示降序。对于null的话,看作比任何数据都小的一个值。还可以进行多段排序规则的定义,如果两个数值相等,那么第一个排序规则就无法排序,就会继续按照第二个排序规则继续排序了。
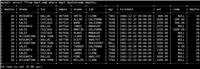
mysql> insert into exam values(7, '哈哈', 98, 77, 79); query ok, 1 row affected (0.01 sec) mysql> insert into exam values(8, '王强', null, 79, 59); query ok, 1 row affected (0.01 sec) //语文按照降序,数学按照升序排列 mysql> select * from exam order by chinese desc, math; +----+-----------+---------+------+---------+ | id | name | chinese | math | english | +----+-----------+---------+------+---------+ | 4 | 赵六 | 99 | 43 | 91 | | 2 | 李四 | 98 | 56 | 84 | | 7 | 哈哈 | 98 | 77 | 79 | | 6 | 张文强 | 98 | 90 | 79 | | 5 | 田七 | 92 | 60 | 79 | | 3 | 王五 | 76 | 45 | 97 | | 1 | 张三 | 67 | 65 | 86 | | 8 | 王强 | null | 79 | 59 | +----+-----------+---------+------+---------+ 8 rows in set (0.00 sec) //排序总分, order by中可以使用列名称的别名 mysql> select id, name, chinese + math + english as 总分 from exam order by 总分 desc; +----+-----------+--------+ | id | name | 总分 | +----+-----------+--------+ | 6 | 张文强 | 267 | | 7 | 哈哈 | 254 | | 2 | 李四 | 238 | | 4 | 赵六 | 233 | | 5 | 田七 | 231 | | 1 | 张三 | 218 | | 3 | 王五 | 218 | | 8 | 王强 | null | +----+-----------+--------+ 8 rows in set (0.00 sec)
//从0开始筛选n条结果
select ... from table_name [...] limit n;
//从s开始筛选n条结果
select ... from table_name [...] limit s, n;
select ... from table_name [...] limit n offset s;
在对未知的表就行查询显示的时候,最好加上limit,避免表中大的数据量过大,查询全表导致数据库卡顿。如果查询的数据不够n个的话不会有任何的影响。
mysql> select * from exam limit 3; +----+--------+---------+------+---------+ | id | name | chinese | math | english | +----+--------+---------+------+---------+ | 1 | 张三 | 67 | 65 | 86 | | 2 | 李四 | 98 | 56 | 84 | | 3 | 王五 | 76 | 45 | 97 | +----+--------+---------+------+---------+ 3 rows in set (0.00 sec) mysql> select * from exam limit 3, 3; +----+-----------+---------+------+---------+ | id | name | chinese | math | english | +----+-----------+---------+------+---------+ | 4 | 赵六 | 99 | 43 | 91 | | 5 | 田七 | 92 | 60 | 79 | | 6 | 张文强 | 98 | 90 | 79 | +----+-----------+---------+------+---------+ 3 rows in set (0.00 sec) mysql> select * from exam limit 6, 3; +----+--------+---------+------+---------+ | id | name | chinese | math | english | +----+--------+---------+------+---------+ | 7 | 哈哈 | 98 | 77 | 79 | | 8 | 王强 | null | 79 | 59 | +----+--------+---------+------+---------+ 2 rows in set (0.00 sec) mysql>
mysql> create table exam_zhang (
-> id int unsigned primary key auto_increment,
-> name varchar(20) not null,
-> chinese float default 0.0,
-> math float default 0.0,
-> english float default 0.0
-> );
query ok, 0 rows affected (0.05 sec)
mysql> insert into exam_zhang select distinct * from exam where name like '张%';
query ok, 2 rows affected (0.00 sec)
records: 2 duplicates: 0 warnings: 0
mysql> select * from exam_zhang;
+----+-----------+---------+------+---------+
| id | name | chinese | math | english |
+----+-----------+---------+------+---------+
| 1 | 张三 | 100 | 130 | 116 |
| 6 | 张文强 | 98 | 120 | 109 |
+----+-----------+---------+------+---------+
2 rows in set (0.01 sec)使用该子句可以将指定的列进行分组查询,对于使用分组查询的时候,select显示的列必须是出现在group by子句中,或者说是聚合函数才可以。
mysql> create table student (
-> class_id int not null,
-> name varchar(10) not null,
-> score float default 0.0
-> );
query ok, 0 rows affected (0.03 sec)
mysql> insert into student values
-> (1, '张三', 98.7),
-> (1, '李四', 97.2),
-> (1, '王五', 88.6),
-> (2, '赵六', 79.4),
-> (2, '田七', 99.9),
-> (2, '王强', 50.4);
query ok, 6 rows affected (0.01 sec)
records: 6 duplicates: 0 warnings: 0
//查看每个班级的最高分
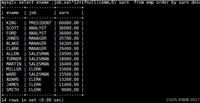
mysql> select class_id, max(score) from student group by class_id;
+----------+------------+
| class_id | max(score) |
+----------+------------+
| 1 | 98.7 |
| 2 | 99.9 |
+----------+------------+
2 rows in set (0.00 sec)
//必须是聚合函数,或者是group by里出现的列
mysql> select class_id, name, max(score) from student group by class_id;
error 1055 (42000): expression #2 of select list is not in group by clause and contains nonaggregated column 'test.student.name' which is not functionally dependent on columns in group by clause; this is incompatible with sql_mode=only_full_group_by语法:update table_name set column=xx [, column=xx, ...] [where ...];
//将总分最高的前三名英语成绩提供30分 mysql> select name, english, math+chinese+english as 总分 from exam order by 总分 desc limit 3; +-----------+---------+--------+ | name | english | 总分 | +-----------+---------+--------+ | 张三 | 86 | 286 | | 张文强 | 79 | 267 | | 哈哈 | 79 | 254 | +-----------+---------+--------+ 3 rows in set (0.00 sec) mysql> update exam set english = english + 30 order by math+english+chinese desc limit 3; query ok, 3 rows affected (0.01 sec) rows matched: 3 changed: 3 warnings: 0 mysql> select name, english, math+chinese+english as 总分 from exam order by 总分 desc limit 3; +-----------+---------+--------+ | name | english | 总分 | +-----------+---------+--------+ | 张三 | 116 | 316 | | 张文强 | 109 | 297 | | 哈哈 | 109 | 284 | +-----------+---------+------- //全列更改--非常不建议这样做 mysql> update exam set math = math + 30; query ok, 8 rows affected (0.00 sec) rows matched: 8 changed: 8 warnings: 0
删除语法:delete from table_name [....];
如果说不加任何范围选择条件的话,那么就相当于是删除整个表数据的操作了。
截断语法:truncate [table] table_name;
对于删除操作来说,是将表单个或者多个数据进行删除,而截断则是对整个表进行操作,会将整个表数据都清除。这样的话可以通过释放表的存储空间来实现清空表的操作,而delete语句需要逐行删除记录,并且会记录每一行的删除操作到日志中。所以会比delete快很多。
如果表中有自增列,操作会将自增列的值重置为初始值(通常是 1)。而delete语句不会重置自增列的值。还有不可滚回和不处罚触发器的特点,以后在讲述。
到此这篇关于mysql数据库表内容的增删查改操作大全的文章就介绍到这了,更多相关mysql数据库表增删查改内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!
您想发表意见!!点此发布评论
版权声明:本文内容由互联网用户贡献,该文观点仅代表作者本人。本站仅提供信息存储服务,不拥有所有权,不承担相关法律责任。 如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 2386932994@qq.com 举报,一经查实将立刻删除。


发表评论