使用C#删除Excel表格中的重复行数据的代码详解
93人参与 • 2025-05-29 • Asp.net
简介
重复行是指在excel表格中完全相同的多行数据。这些冗余行的存在可能源于多种原因,例如:
- 数据输入错误:用户在手动输入数据时,可能不小心多次输入相同的信息。
- 数据导入:从其他系统或文件导入数据时,可能会出现重复记录,尤其是在合并多个数据源时。
- 复制粘贴:在处理数据时,复制粘贴操作可能导致无意中创建重复行。
删除这些重复行至关重要,因为它们不仅会干扰数据分析,还可能导致错误的决策和结论。通过清理重复数据,可以提高数据的准确性和整洁性,从而使后续的分析工作更加高效。这篇文章将探讨如何使用c# 实现快速删除excel表格中的重复行,主要涵盖内容如下:
- c# 删除excel工作表中的重复行
- c# 删除指定excel单元格区域中的重复行
- c# 基于特定列删除重复行
使用工具
要使用 c# 从 excel 表格中删除重复数据,需要使用合适的excel文档处理库。本文所使用的库是 spire.xls for .net,它支持在.net应用程序中创建和操作excel 文件,无需安装microsoft excel。
安装spire.xls for .net
在开始之前,在package manager console中运行以下命令从nuget 安装 spire.xls 库:
install-package spire.xls
c# 删除excel工作表中的重复行
重复行可能会导致工作表结构混乱,影响数据的完整性。spire.xls 提供了一种简单的方法来检测和删除工作表中的重复行。
语法
sheet.removeduplicates();
工作原理
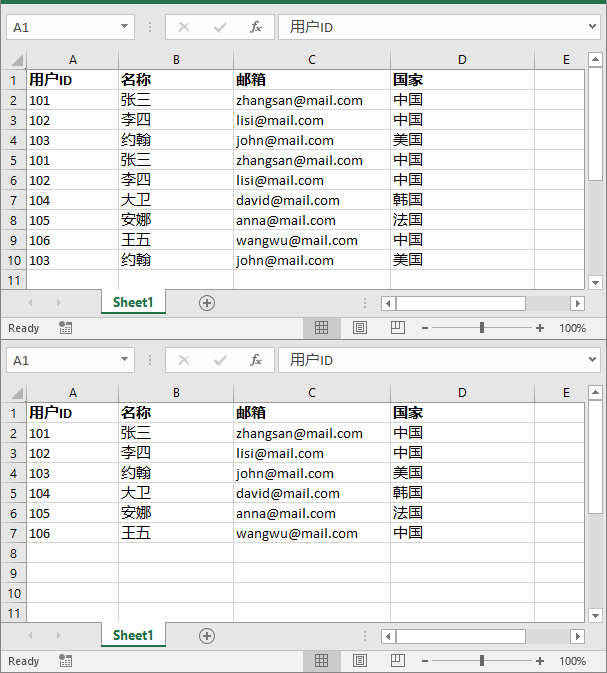
该方法会检查工作表中的每一行,并比较每行内的所有单元格。只有当所有单元格的值与另一行完全一致时,该行才会被视为重复。第一次出现的行将被保留,而后续的重复行将被删除。
实现代码
using spire.xls;
namespace removeduplicatesfromworksheet
{
internal class program
{
static void main(string[] args)
{
// 打开 excel 文件
workbook workbook = new workbook();
workbook.loadfromfile("测试.xlsx");
// 获取所需的工作表(索引从0开始)
worksheet sheet = workbook.worksheets[0];
// 从工作表中删除重复行
sheet.removeduplicates();
// 保存修改后的文件
workbook.savetofile("删除工作表内重复行.xlsx", excelversion.version2016);
workbook.dispose();
}
}
}
c# 删除指定excel单元格区域中的重复行
有时,你可能只想清除工作表特定单元格区域中的重复行数据,而不影响其他部分。spire.xls 支持指定要删除重复项的单元格范围。
语法
sheet.removeduplicates(int startrow, int startcolumn, int endrow, int endcolumn);
参数
startrow, startcolumn, endrow, endcolumn: 定义要检查重复项的单元格区域(行列索引从1开始)。
工作原理
该方法会比较指定单元格区域内的所有行,如果有两行或多行的每一列的值都完全相同,那么这些行就被认为是重复的,只保留第一次出现的那一行。区域外的行不会受到影响,仍然保持原样。
实现代码
using spire.xls;
namespace removeduplicaterowsfromcellrange
{
internal class program
{
static void main(string[] args)
{
// 打开 excel 文件
workbook workbook = new workbook();
workbook.loadfromfile("测试.xlsx");
// 获取所需的工作表(索引从0开始)
worksheet sheet = workbook.worksheets[0];
// 从特定单元格区域中删除重复行
sheet.removeduplicates(2, 1, 9, 4);
// 保存修改后的文件
workbook.savetofile("删除单元格区域内重复行.xlsx", excelversion.version2016);
workbook.dispose();
}
}
}c# 基于特定列删除重复行
在处理某些特定数据集时,您可能只希望根据特定的关键列来删除重复项,而忽略其他列的值。
spire.xls 提供了另一种 removeduplicates() 方法重载,以支持这种需求。使用此方法,你可以:
- 指定要操作的单元格区域
- 指明该区域是否包含标题行
- 选择用于比较重复的列
语法
sheet.removeduplicates(int startrow, int startcolumn, int endrow, int endcolumn, bool hasheaders, int[] columnoffsets);
参数
- startrow, startcolumn, endrow, endcolumn: 定义要检查重复数据的单元格区域(行列索引从1开始)。
- hasheaders: 判定第一行是否为标题行。如果为 true,则第一行将不参与比较。
- columnoffsets: 相对于 startcolumn 的偏移数组,指定用于比较的列,例如0表示指定区域中的第一列。
工作原理
该方法在删除重复行时,仅考虑用户指定的某些列。如果多行在这些指定列中的值完全相同,则只保留第一行,其他重复的行将被删除。这种做法尤其适用于需要根据特定标识(如客户 id 或电子邮件)来确保数据唯一性的场景。
实现代码
using spire.xls;
namespace removeduplicaterows
{
internal class program
{
static void main(string[] args)
{
// 打开 excel 文件
workbook workbook = new workbook();
workbook.loadfromfile("测试.xlsx");
// 获取所需的工作表(索引从0开始)
worksheet sheet = workbook.worksheets[0];
// 定义要检查重复行的区域
int startrow = 2;
int startcolumn = 1;
int endrow = 9;
int endcolumn = 4;
// 判定区域内的第一行是否是标题行
bool hasheaders = false;
// 指定用于比较重复的列
int[] columnstocompare = { 1, 2 };
// 在定义的区域内基于指定列删除重复行
sheet.removeduplicates(startrow, startcolumn, endrow, endcolumn, hasheaders, columnstocompare);
// 保存修改后的文件
workbook.savetofile("基于特定列删除重复行.xlsx", excelversion.version2016);
workbook.dispose();
}
}
}removeduplicates 方法快速比较
以下是removeduplicates 几种方法的快速比较,你可以根据自己的需求选择最合适的方法:
方法 | 适用范围 |
removeduplicates() | 整个工作表 |
removeduplicates(int startrow, int startcolumn, int endrow, int endcolumn) | 指定单元格区域 |
removeduplicates(int startrow, int startcolumn, int endrow, int endcolumn, bool hasheaders, int[] columnoffsets) | 基于特定列 |
以上就是使用c#实现快速删除excel工作表中重复行数据的全部内容。
到此这篇关于使用c#删除excel表格中的重复行数据的代码详解的文章就介绍到这了,更多相关c#删除excel重复行数据内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!
赞 (0)
您想发表意见!!点此发布评论






发表评论