MySQL分区表的具体使用
8人参与 • 2025-06-11 • Mysql
通常情况下,同一张表的数据在物理层面都是存放在一起的。随着业务增长,当同一张表的数据量过大时,会带来管理上的不便。而分区特性可以将一张表从物理层面根据一定的规则将数据划分为多个分区,多个分区可以单独管理,甚至存放在不同的磁盘/文件系统上,提升效率。
分区表的优点:
- 数据可以跨磁盘/文件系统存储,适合存储大量数据。
- 数据的管理非常方便,以分区为单位操作数据,不会影响其他分区的正常运行。
- 数据查询上在某些条件可以利用分区裁剪(partition pruning)特性,将搜索范围快速定位到特性分区,提升查询性能。
对于应用来说,表依然是一个逻辑整体,但数据库可以针对不同的数据分区独立执行管理操作,不影响其他分区的运行。而数据划分的规则即称为分区函数,数据写入表时,会根据运算结果决定写入哪个分区。
mysql的分区插件与存储引擎运行在不同的层,因此大部分存储引擎都可以利用mysql的分区特性,只有少数存储引擎(merge,csv,federated)不支持分区特性。若某张表使用的分区特性,则所有的分区都需要使用相同的存储引擎,且分区特性会同时应用到数据和索引上。
一、分区的类型
1. range partition(范围分区)
range partition是按照分区表达式的运算结果,判断结果落在某个范围内,从而将数据存储在对应的分区。各个分区定义之间需要连续且不能重叠,范围分区通过partition by range子句定义,而分区的范围通过values less than子句划分。
例:定义一个员工表,根据员工id分区,1~10号员工一个分区,11~20号员工一个分区,依次类推,共建立4个分区:
create table employees (
id int not null primary key,
first_name varchar(30),
last_name varchar(30))
partition by range(id)(
partition p0 values less than (11),
partition p1 values less than (21),
partition p2 values less than (31),
partition p3 values less than (41)
);现在随便插入几条数据:
insert into employees values(1,'vincent','chen'); insert into employees values(6,'victor','chen'); insert into employees values(11,'grace','li'); insert into employees values(16,'san','zhang'); commit;
分区查询:
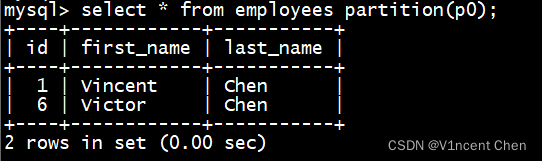
如果在查询时候明确的知道数据所在的分区,我们可以直接指定分区:
select * from employees partition(p0); -- 查询p0分区 select * from employees partition(p0,p1); -- 查询p0和p1分区
分区删除:
如果某分区数据不再需要的时候,我们可以用alter table ... drop partition来删除指定分区,例如删除分区p1,采用drop partition的方式可以快速清除历史数据:
alter table employees drop partition p1;

分区p1被删除后,所有p1分区的数据都已丢失,此时原p1分区的范围将由p2覆盖。
分区新增:
对于range分区来说,分区新增只能在最大范围之上增加分区,因此p1分区被删除后就无法通过新增分区的方式加回了,下例试图对id10~20的员工新增一个分区,系统会返还错误。
alter table employees add partition (partition n1 values less than(21));

而在最大的分区范围之上是可以的:
alter table employees add partition (partition p4 values less than(51));

分区重组织:
如果一定要在分区之间插入新的分区,则可以采用重组织的方式,将已有分区的数据重新划分,达到创建新分区的效果:

例如我要将p2划分为2个分区,分别是11~20,21~30:
alter table employees reorganize partition p2 into ( partition p1 values less than(21), partition p2 values less than(31));

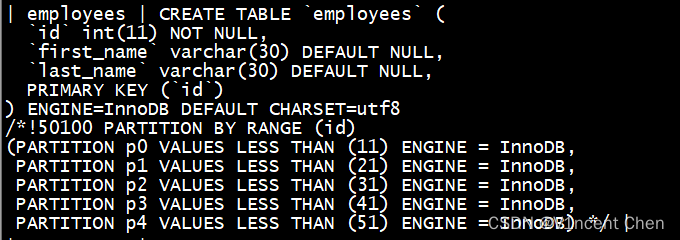
此时原p2分区被拆分为了p1,p2,数据也在2个分区间重新分布,保证不会丢失。效果就像我们在中间插入了一个分区一样。
目前定义的分区都是有上限的,如果有大于分区上限的值想插入表中,系统会返还错误,为了兼容这种情况,我们可以新增一个分区,上限为maxvalue。所有大于当前上限的值都会放入这个分区:
alter table employees add partition(partition pmax values less than(maxvalue));

范围分区的条件除了直接用值,还可以用函数来定义。一个常用的场景就是按时间分区,例如:在create table中使用partition by range(year(hire_date)),可以按照年份来进行分区。这种分区方式在需要定期清理过期数据的场景会非常方便。
range columns分区:
range分区还有一个变种,叫做range columns分区。此分区方式允许使用多个column来作为分区范围条件。但是此分区方式不能接受函数,只能直接用列的名称。但是对分区列的类型不再限制为整数,可以使用string,date等类型。
使用range columns对多个列进行分区:
create table rc2 (
a int,
b int
)
partition by range columns(a,b) (
partition p0 values less than (0,10),
partition p1 values less than (10,20),
partition p2 values less than (10,30),
partition p3 values less than (maxvalue,maxvalue) );使用range columns直接对date类型进行分区:
create table members (
firstname varchar(25) not null,
lastname varchar(25) not null,
username varchar(16) not null,
joined date not null
)
partition by range columns(joined) (
partition p0 values less than ('1960-01-01'),
partition p1 values less than ('1970-01-01'),
partition p2 values less than ('1980-01-01'),
partition p3 values less than ('1990-01-01'),
partition p4 values less than maxvalue);
range partition和null:
对range分区来说,如果插入数据分区键为null,是可以成功的,数据会被放到第一个分区中。
2. list partition(列表分区)
列表分区和范围分区类似,主要区别是list partition的分区范围是预先定义好的一系列值,而不是连续的范围。列表分区采用partition by list和values in子句定义。
示例,创建一张员工表按照id进行列表分区:
create table employees (
id int not null,
fname varchar(30),
lname varchar(30)
)
partition by list(id) (
partition p0 values in (1,3,5,7,9),
partition p1 values in (2,4,6,8,10)
);和range分区一样,可以使用alter table ... add/drop partition新增/删除分区:
alter table employees add partition(partition p2 values in (11,12,13,14,15));
alter table employees drop partition p0;
list partition和非事务引擎:
如果插入的值在list分区范围中不存在的话,语句会返还错误。如果表使用的是事务型引擎,如innodb。则这个事务会完全回滚。如果使用的是非事务引擎,若myisam,虽然也会报错,但是已插入的行无法回滚。
下面新建两张表,一张使用innodb,一张使用myisam:
create table employees_innodb (
id int not null,
fname varchar(30),
lname varchar(30)
) engine=innodb -- 事务型引擎
partition by list(id) (
partition p0 values in (1,3,5,7,9),
partition p1 values in (2,4,6,8,10));
create table employees_myisam (
id int not null,
fname varchar(30),
lname varchar(30)
) engine=myisam -- 非事务型引擎
partition by list(id) (
partition p0 values in (1,3,5,7,9),
partition p1 values in (2,4,6,8,10));insert into employees_innodb values(1,'vincent','chen'),(11,'grace','li'),(2,'victor','chen'); insert into employees_myisam values(1,'vincent','chen'),(11,'grace','li'),(2,'victor','chen'); select * from employees_innodb; select * from employees_myisam;
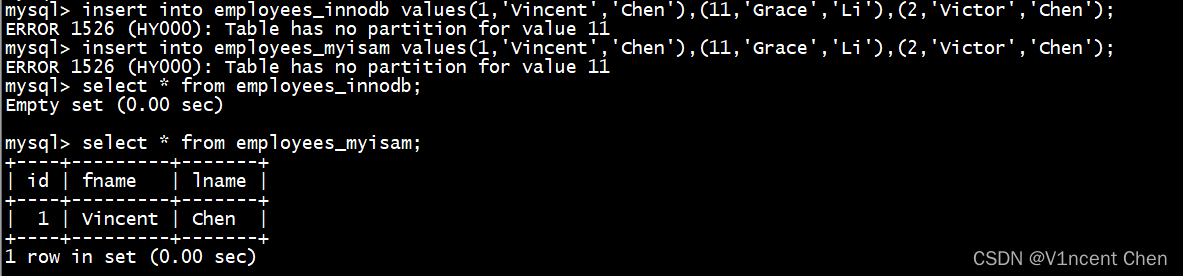
我们在中间放了一个不存在对应分区的记录来触发错误, 可以看到innodb引擎数据没有数据插入(回滚)。但myisam引擎报错前的数据已经保留了下来,但是报错之后的记录未执行插入。
如果要忽略此错误,可以在insert语句中使用ignore关键字来忽略此错误,只插入符合分区条件的值:
insert ignore into employees_innodb values(1,'vincent','chen'),(11,'grace','li'),(2,'victor','chen'); insert ignore into employees_myisam values(1,'vincent','chen'),(11,'grace','li'),(2,'victor','chen');

可以看到符合条件的记录被插入,不符合条件的自动被过滤,不返回错误。
list columns分区:
和range分区类似,list partition也有一个变种的list columns 分区,此分区类型可以使用多个列同时作为分区条件,且不再限制整数。并且可以使用string,date等数据类型作为分区条件。
list partition和null:
对于列表分区来说,必须有1个分区显示的指定可以包含null,否则插入会失败。
3. hash partition(哈希分区)
hash partition主要的应用场景是将数据平均的分布在指定数量的hash分区中。在range和list分区类型中,根据分区条件的计算结果,数据可以确定存储在哪个分区,而在hash分区中,数据存储在某个分区是由数据库自己决定的,你只需要指定分区的数量。
要创建hash分区,你需要使用create table的partition by hash(expr)子句,其中expr是整数类型的列或返还整数的表达式。另外还需要使用partions num来指定hash分区的数量(若忽略partitions子句则默认只创建1个hash分区)。
例:创建一个具有4个hash分区的表,按照id进行分区:
create table employees (
id int not null,
first_name varchar(30),
last_name varchar(30)
)
partition by hash(id)
partitions 4;hash分区的性能考虑:
对于hash分区,数据库决定将数据存储在哪个分区是采用取余的方式进行运算的。存储分区的编号n = mod(expr, num),其中expr是分区值,num为定义的分区数量。
例如:对于4个hash分区,id为5的记录,会存储在mod(5,4)=1,即1号分区中。
因此,最佳的分区键值的变化方式应该是线性变化,此时使用hash分区的效率最高,分布也会均匀。由于分区键值expr在每次insert/update/delete时都会运算,太复杂的表达式也会带来负面的性能影响,在选择时也需要考虑。
liner hash partition(线性哈希分区):
以上的分区类型即普通hash分区,另外还有一类变种叫做liner hash partition(线性哈希分区),线性哈希分区的区别是其使用了更复杂的计算方法来确定数据的分布:
1. 对于分区数量为num的分区表,先计算v: v = power(2, ceiling(log(2, num))) 2. 对于分区值与v-1进行位与运算 n = expr & (v - 1) -- 位与运算 3. 对于n>num的情况,再次计算 n = n & ((v/2)-1)
例:假设分区数量为4
1. 先根据分区数量num计算v的值,先log再power,如果分区数量如果是2的次方,则此公式计算结果不变。
v = power(2,ceilling(log(2,4))) = power(2,ceillling(2)) = power(2,2) = 4
2. 对于id为5的记录:
n = 5 & (v-1) = 5 & 3 = 1
3. 第二步计算出的结果为1,n<=num,不再需要第三步计算,数据存储在1号分区。
计算机的位计算效率是非常高的,因此liner hash在新增/删除/合并/分裂分区场景(需要重新计算并分布数据)速度会快很多,非常适合特别大的数据存储场景(tb级别)。
liner hash的缺点是数据的分布可能没有普通hash均匀。
管理hash分区数量:
hash分区无法像range和list那样添加和删除分区,但是你可以用alter table的coalesce partition子句来减少hash分区的数量,用add partition partitions n来增加指定数量的分区。
例:将employees的hash分区数量由4调整为3:
alter table employees coalesce partition 1; -- 移除一个分区
例:为employees表新增3个hash分区:
alter table employees add partition partitions 3; -- 新增3个hash分区
hahs partition和null:
对于hash partition和key partition,任何表达式对null运算,都会被当做返回为0.
4. key partition(键值分区)
key paritition与hash分区类似,主要区别在于key partition的hash函数是由mysql server提供的,且使用主键(或非空唯一键)作为分区列:
例如:创建一个2个分区的key partition table:
create table k1 (
id int not null primary key,
name varchar(20)
)
partition by key() -- 未指定分区列,自动使用主键
partitions 2;create table k1 (
id int not null, -- 如果未定义not null,创建表会失败
name varchar(20),
unique key (id)
)
partition by key() -- 未定义主键,自动使用unique key
partitions 2;另外对于key partition,paritition key也不像其他分区类型那样限制为整数类型,例如,可以使用字符型作为分区键:
create table tm1 (
s1 char(32) primary key -- 字符型主键,同时作为partition key
)
partition by key(s1)
partitions 10;对于key partition,由于primary key需要同时作为partition key,所以执行alter table ... drop partition会报错(ndb引擎表会重组织并生成隐藏的primary key,不受此限制)。
mysql> alter table k1 drop primary key; error 1488 (hy000): field in list of fields for partition function not found in table -- 主键删除失败
key partition和hash partition一样,也有liner key分区。
create table tk (
col1 int not null,
col2 char(5),
col3 date
)
partition by linear key (col1) -- liner key partition
partitions 3;key partition数量的管理方法与hash partition相同。
二、subparitioning(子分区)
subpartitioning可以在原有分区表的基础上,对每个分区再次进行分区(子分区)。子分区的分区类型可以和父分区不同,因此也叫复合分区。
下面的示例即对range partition的每个分区再次进行hash partition。父分区p0,p1,p2将各包含2个子分区,因此最终分区的数量为3*2=6个
create table ts (id int, purchased date)
partition by range( year(purchased) ) -- 父分区采用range partition
subpartition by hash( to_days(purchased) ) -- 子分区采用hash partition
subpartitions 2 -- 子分区数量为2
(
partition p0 values less than (1990),
partition p1 values less than (2000),
partition p2 values less than maxvalue
);你也可以显示的定义每个子分区的名称,但如果采用这种方式定义,则必须显示指定所有子分区。且子分区的数量必须相同,子分区名称不能重复:
create table ts (id int, purchased date)
partition by range( year(purchased) ) --父分区为range partition
subpartition by hash( to_days(purchased) ) --子分区为hash partition
(
partition p0 values less than (1990) (
subpartition s0, -- 显式指定子分区名称和数量
subpartition s1
),
partition p1 values less than (2000) (
subpartition s2,
subpartition s3
),
partition p2 values less than maxvalue (
subpartition s4,
subpartition s5
)
);三、分区的基本维护
分区表的一大优势就是各个分区可以独立存储和管理。因此大部分在表级别上的管理操作都可以应该在分区上。
重建分区:
重建分区功能相当于清除分区中所有记录,然后在重新插入。对于频繁的更新的分区,可以定期使用重建的方式清除碎片。
alter table employees rebuild partition p0, p1; -- 重建p0,p1分区 alter table employees rebuild partition all; -- 重建所有分区
检查分区:
你可以用check table语句来检查指定分区是否存在损坏:
alter table employees check partition p1; -- 检查p1分区 alter table employees check partition all; -- 检查所有分区
键值分布统计:
使用alter table ... analyze partition可以统计指定分区的键值分布,已便更好的生成执行计划:
alter table employees analyze partition p0; -- 分析p0分区 alter table employees analyze partition all; -- 分析所有分区
分区修复:
使用alter table ... repair partition来修复损坏的分区:
alter table employees repair partition p0; -- 分析p0分区 alter table employees repair partition all; -- 修复所有分区
优化分区:
如果分区存在大量的数据更新,你可以使用optimize partition来回收空间,收集统计信息。其效果相当于在分区上执执行check partition、analyze partition 和 repair partition一样。
alter table employees optimize partition p0;
但是对于innodb存储引擎来说,并不支持optimize partition操作,对单一分区执行会导致所有的分区都重建,谨慎使用(table does not support optimize on partitions. all partitions will be rebuilt and analyzed.)。
到此这篇关于mysql分区表的具体使用的文章就介绍到这了,更多相关mysql分区表 内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!
赞 (0)
您想发表意见!!点此发布评论



发表评论