Oracle窗口函数详解及练习题总结
25人参与 • 2025-07-04 • Oracle
前言
oracle 窗口函数是sql语言中一项极其强大的功能,它赋予了你在保留原始行集的同时,对相关数据子集(“窗口”)进行复杂计算的能力。与将多行压缩为一行的标准聚合函数 (group by) 不同,窗口函数为结果集中的每一行都返回一个独立的计算值。
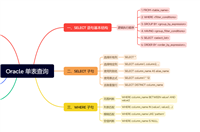
思维导图
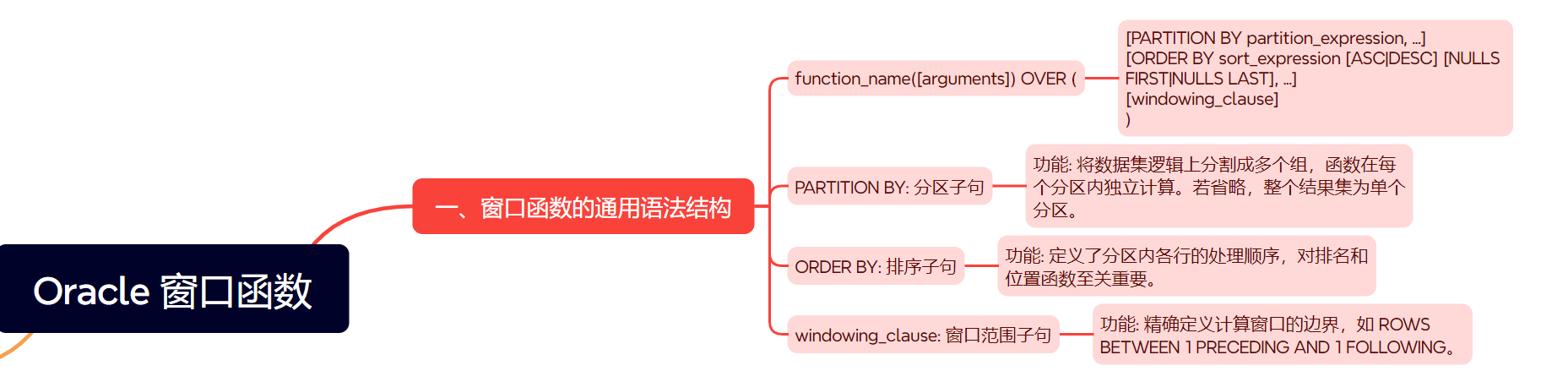
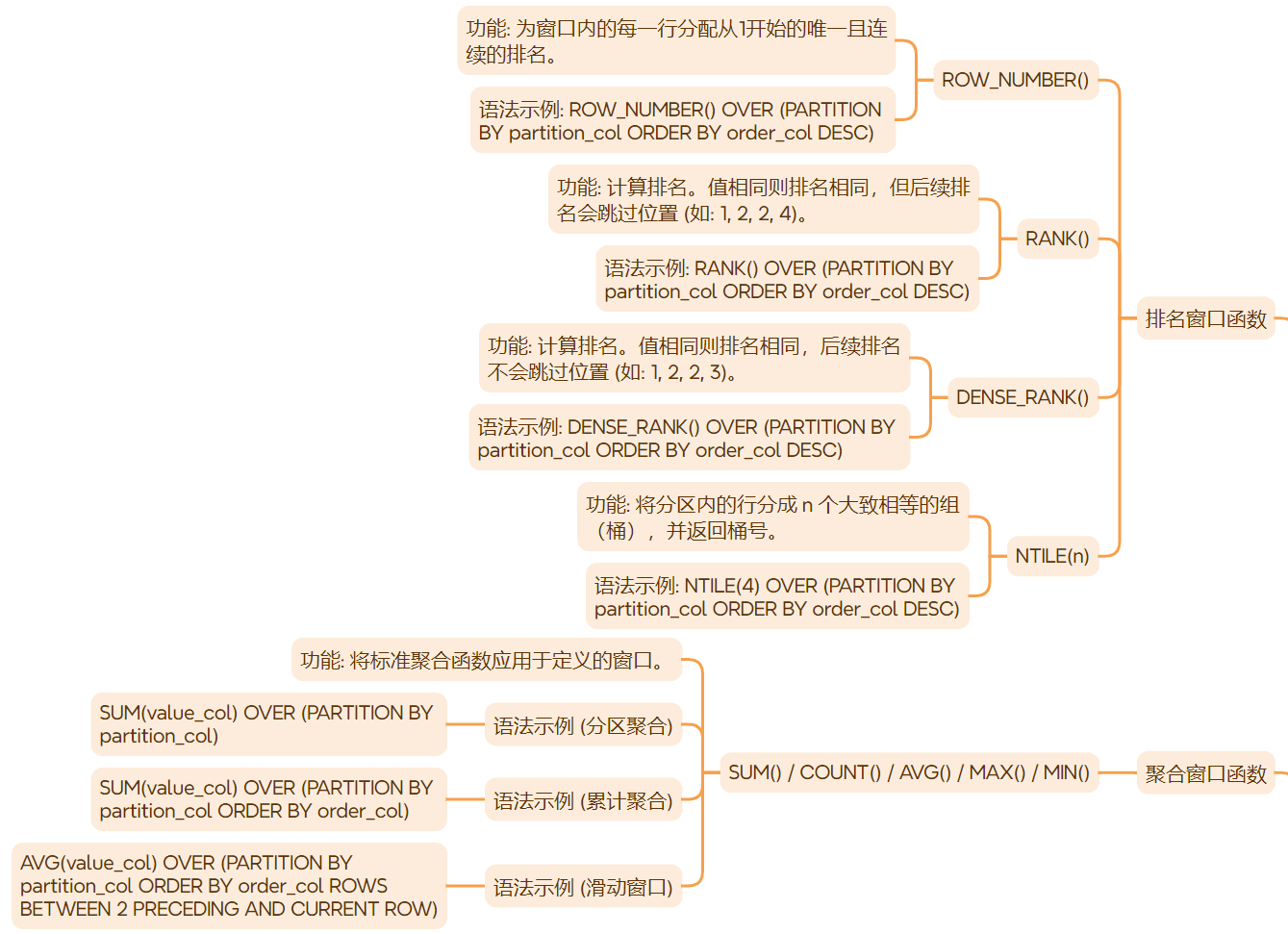
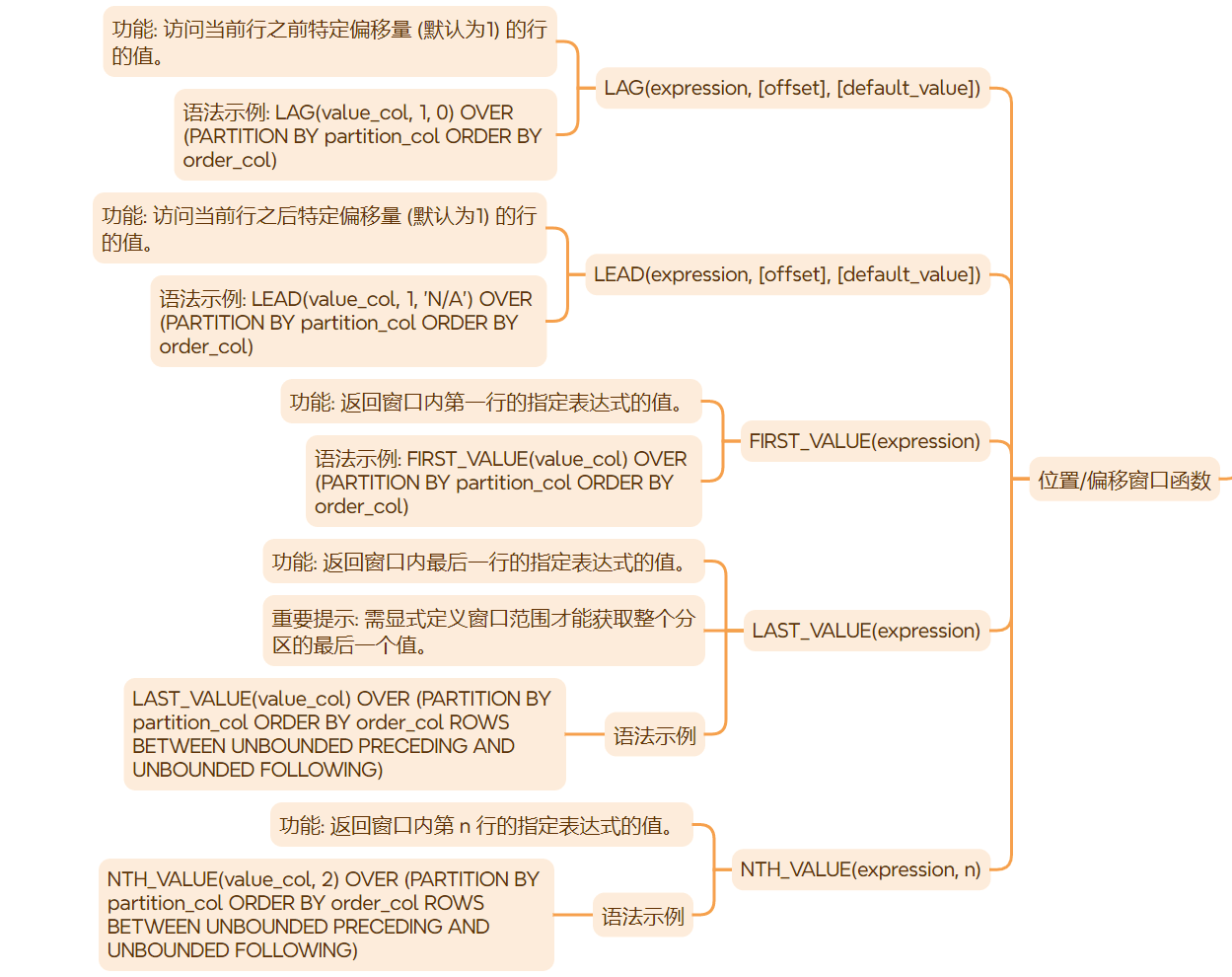
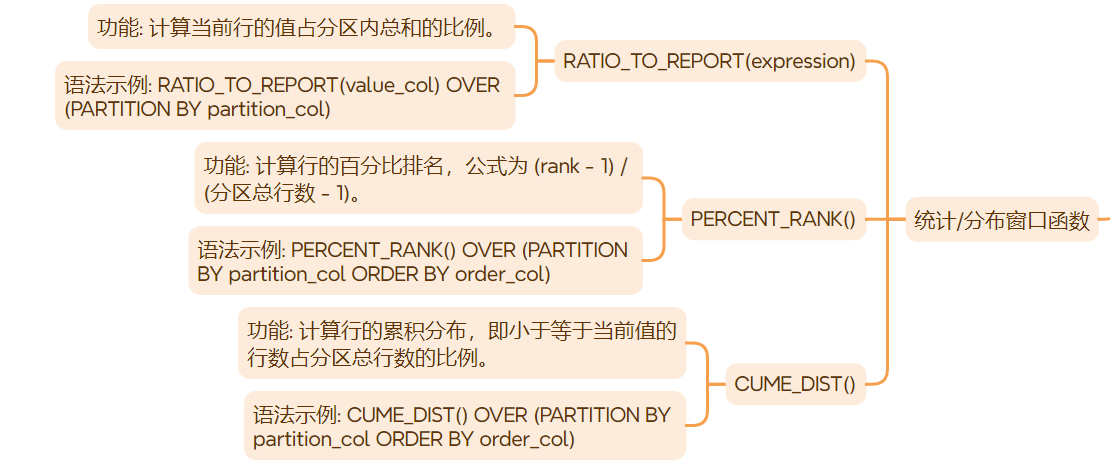
一、窗口函数的通用语法结构
所有窗口函数都遵循一个核心的 over() 子句结构,它定义了计算的上下文——“窗口”。
function_name([arguments]) over ( [partition by partition_expression, ...] [order by sort_expression [asc|desc] [nulls first|nulls last], ...] [windowing_clause] )
partition by: 分区子句。将数据集逻辑上分割成多个独立的组(分区),窗口函数在每个分区内部独立计算。若省略,整个结果集被视为单个分区。order by: 排序子句。它定义了分区内各行的处理顺序。对于排名和位置函数,此子句至关重要。windowing_clause: 窗口范围子句。它更精确地定义了计算窗口的边界(例如rows between 1 preceding and 1 following表示当前行、前一行和后一行)。如果省略(但有order by),默认通常是range between unbounded preceding and current row。
二、窗口函数分类与实战
背景表:我们将使用一个简化的 emp 表进行所有演示,包含 empno, ename, job, deptno, sal, hiredate 等列。
2.1 排名窗口函数
row_number()
- 功能:为窗口内的每一行分配一个从1开始的唯一且连续的排名。即使行具有相同的值,排名也不会重复。
- 代码示例:按部门为员工按薪水降序进行唯一排名。
select ename, deptno, sal, row_number() over (partition by deptno order by sal desc) as row_num_rank from emp;
rank()
- 功能:计算排名。如果值相同,则排名相同,但后续排名会跳过相应的位置(例如:1, 2, 2, 4)。
- 代码示例:按部门为员工按薪水降序进行跳跃排名。
select ename, deptno, sal, rank() over (partition by deptno order by sal desc) as rank_val from emp;
dense_rank()
- 功能:计算排名。如果值相同,则排名相同,且后续排名不会跳过位置(例如:1, 2, 2, 3)。
- 代码示例:按部门为员工按薪水降序进行连续排名。
select ename, deptno, sal, dense_rank() over (partition by deptno order by sal desc) as dense_rank_val from emp;
ntile(n)
- 功能:将分区内的行分成
n个大致相等的组(桶),并返回每行所在的桶号。 - 代码示例:将每个部门的员工按薪水降序分为4个等级。
select ename, deptno, sal, ntile(4) over (partition by deptno order by sal desc) as salary_quartile from emp;
2.2 聚合窗口函数
sum() / count() / avg() / max() / min()
- 功能:将标准聚合函数应用于窗口。
- 代码示例 (分区聚合):计算每个员工的薪水,并显示其所在部门的总薪水和平均薪水。
select ename, deptno, sal, sum(sal) over (partition by deptno) as total_dept_salary, round(avg(sal) over (partition by deptno), 2) as avg_dept_salary from emp;
- 代码示例 (累计聚合/移动求和):计算每个部门内,按入职日期排序的累计薪水。
select ename, deptno, sal, hiredate, sum(sal) over (partition by deptno order by hiredate) as running_total_salary from emp;
- 代码示例 (滑动窗口/移动平均):计算每个部门内,基于当前行及前两行(共三行)的移动平均薪水。
select ename, deptno, sal, hiredate, round(avg(sal) over (partition by deptno order by hiredate rows between 2 preceding and current row), 2) as moving_avg_3_rows from emp;
2.3 位置/偏移窗口函数
lag(expression, [offset], [default_value])
- 功能:访问当前行之前特定偏移量 (
offset,默认为1) 的行的值。 - 代码示例:显示每个员工的薪水,以及其同部门内按薪水降序排列的上一名员工的薪水(若无则为0)。
select ename, deptno, sal, lag(sal, 1, 0) over (partition by deptno order by sal desc) as previous_salary from emp;
lead(expression, [offset], [default_value])
- 功能:访问当前行之后特定偏移量 (
offset,默认为1) 的行的值。 - 代码示例:显示每个员工的薪水,以及其同部门内按入职日期排序的下一名入职员工的姓名(若无则为’n/a’)。
select ename, deptno, hiredate, lead(ename, 1, 'n/a') over (partition by deptno order by hiredate) as next_hired_employee from emp;
first_value(expression)
- 功能:返回窗口内第一行的指定表达式的值。
- 代码示例:显示每个员工及其所在部门最早入职的员工姓名。
select ename, deptno, hiredate, first_value(ename) over (partition by deptno order by hiredate) as first_hired_in_dept from emp;
last_value(expression)
- 功能:返回窗口内最后一行的指定表达式的值。
- 重要提示:默认窗口范围是到
current row,要获取整个分区的最后一个值,必须显式定义窗口范围。 - 代码示例:显示每个员工及其所在部门薪水最高的员工姓名。
select ename, deptno, sal, last_value(ename) over (partition by deptno order by sal asc rows between unbounded preceding and unbounded following) as highest_paid_in_dept from emp;
(这里通过薪水升序排列,然后取窗口的最后一行来找到薪水最高者)
nth_value(expression, n)
- 功能:返回窗口内第
n行的指定表达式的值。 - 代码示例:显示每个员工及其所在部门薪水第二高的员工薪水。
select ename, deptno, sal, nth_value(sal, 2) over (partition by deptno order by sal desc rows between unbounded preceding and unbounded following) as second_highest_salary from emp;
2.4 统计/分布窗口函数
ratio_to_report(expression)
- 功能:计算当前行的值占分区内总和的比例。
- 代码示例:计算每个员工的薪水占其所在部门总薪水的百分比。
select ename, deptno, sal, to_char(ratio_to_report(sal) over (partition by deptno) * 100, '990.99') || '%' as percentage_of_dept_sal from emp;
percent_rank()
- 功能:计算行的百分比排名,计算公式为
(rank - 1) / (rows_in_partition - 1)。 - 代码示例:计算每个员工薪水在其部门内的百分位排名。
select ename, deptno, sal, round(percent_rank() over (partition by deptno order by sal asc) * 100, 2) as percentile_rank from emp;
cume_dist()
- 功能:计算行的累积分布,即小于等于当前值的行数占分区总行数的比例。
- 代码示例:计算薪水小于等于当前员工薪水的员工在其部门内的累积占比。
select ename, deptno, sal, round(cume_dist() over (partition by deptno order by sal asc) * 100, 2) as cumulative_distribution from emp;
三、综合实战案例:构建员工绩效分析报告
这个案例整合了多种窗口函数来生成一份详细的员工分析报告。
目标:对于每一位员工,我们希望得到他/她在其部门内的薪水排名、与部门平均薪水的差距、薪水占部门总额的比例,以及其上司(按薪水排名的上一位)的薪水。
代码示例:
with emp_analysis as (
select
empno,
ename,
deptno,
sal,
-- 使用聚合窗口函数计算部门的统计数据
avg(sal) over (partition by deptno) as avg_dept_sal,
sum(sal) over (partition by deptno) as total_dept_sal,
-- 使用排名窗口函数计算薪水排名
rank() over (partition by deptno order by sal desc) as dept_sal_rank,
-- 使用位置窗口函数获取上一位员工的薪水
lag(sal, 1, 0) over (partition by deptno order by sal desc) as prev_rank_sal
from emp
)
select
a.ename as employee_name,
a.deptno,
a.sal as current_salary,
a.dept_sal_rank,
round(a.avg_dept_sal, 2) as department_avg_salary,
a.sal - round(a.avg_dept_sal, 2) as diff_from_avg,
to_char(a.sal / a.total_dept_sal * 100, '990.99') || '%' as percentage_of_total,
a.prev_rank_sal as superior_salary
from emp_analysis a
order by a.deptno, a.dept_sal_rank;
解析:
- 我们使用公用表表达式 (cte)
with emp_analysis as (...)来分步处理,使查询更清晰。 - 在
emp_analysiscte 内部:avg(sal) over (...)和sum(sal) over (...)为每行计算出其所在部门的平均和总薪水。rank() over (...)计算出部门内的薪水排名。lag(...) over (...)找到了排名紧邻的上一位员工的薪水。
- 在最终的
select语句中,我们引用 cteemp_analysis的结果,并进行简单的算术运算和格式化,生成了最终的报告列,如diff_from_avg(与平均薪水差额) 和percentage_of_total(薪水占比)。
总结: oracle 窗口函数是进行复杂数据分析的核心技能。通过灵活运用 partition by, order by, 和窗口范围子句,你可以用简洁的sql实现过去需要通过自连接、子查询或过程化代码才能完成的复杂逻辑。
练习题
背景表结构:
create table sales_data (
sale_id number(10),
product_category varchar2(50 char),
region varchar2(50 char),
sale_amount number(10, 2),
sale_date date
);
请为以下每个场景编写使用窗口函数的sql查询。
题目:
- 查询所有销售记录,并为每条记录添加一列
category_rank,表示该笔销售额 (sale_amount) 在其所属产品类别 (product_category) 内的排名 (销售额越高,排名越靠前)。使用rank()函数。 - 查询所有销售记录,并为每条记录添加一列
total_region_sales,显示该记录所在地区 (region) 的总销售额。 - 查询所有销售记录,并为每条记录添加一列
monthly_running_total,计算每个地区内,按销售日期 (sale_date) 排序的累计销售额。 - 查询所有销售记录,并为每条记录添加一列
prev_sale_amount,显示同一地区内,按销售日期排序的上一笔销售的销售额。如果不存在上一笔,则显示0。 - 查询所有销售记录,并为每条记录添加一-列
next_sale_amount,显示同一产品类别内,按销售日期排序的下一笔销售的销售额。如果不存在下一笔,则显示-1。 - 找出每个产品类别中销售额最高的两条销售记录。
- 查询所有销售记录,并为每条记录添加一列
highest_sale_in_category,显示该记录所在产品类别的单笔最高销售额。 - 查询所有销售记录,并为每条记录添加一列
sale_percentage_of_region,计算该笔销售额占其所在地区销售总额的百分比。 - 将每个地区的销售记录按销售额分为3个等级 (1为最高,3为最低)。为每条记录添加一列
sales_tier来表示这个等级。 - 查询所有销售记录,并为每条记录添加一列
moving_avg_3_sales,计算每个地区内,按销售日期排序,当前行及其前两行 (共三行) 的移动平均销售额。
答案与解析
- 类别内销售额排名:
select s.*, rank() over (partition by product_category order by sale_amount desc) as category_rank from sales_data s;
- 解析:
partition by product_category将数据按类别分片,order by sale_amount desc在每个片内按销售额降序排,rank()计算排名。
- 地区总销售额:
select s.*, sum(sale_amount) over (partition by region) as total_region_sales from sales_data s;
- 解析:
sum(...) over (partition by region)对每个地区分区内的所有sale_amount求和,并将这个总和赋给分区内的每一行。
- 地区内月度累计销售额:
select s.*, sum(sale_amount) over (partition by region order by sale_date) as monthly_running_total from sales_data s;
- 解析:
order by sale_date的加入,使得sum的计算窗口默认为range between unbounded preceding and current row,从而实现了从分区开始到当前行的累计求和。
- 获取上一笔销售额:
select s.*, lag(sale_amount, 1, 0) over (partition by region order by sale_date) as prev_sale_amount from sales_data s;
- 解析:
lag(sale_amount, 1, 0)在按地区分区、按日期排序的窗口中,获取往前1行的sale_amount值,如果不存在(即第一行),则返回默认值0。
- 获取下一笔销售额:
select s.*, lead(sale_amount, 1, -1) over (partition by product_category order by sale_date) as next_sale_amount from sales_data s;
- 解析:
lead(sale_amount, 1, -1)在按类别分区、按日期排序的窗口中,获取往后1行的sale_amount值,如果不存在(即最后一行),则返回默认值-1。
- 每个类别销售额最高的两条记录:
select * from (
select
s.*,
row_number() over (partition by product_category order by sale_amount desc) as rn
from sales_data s
)
where rn <= 2;
- 解析: 窗口函数不能直接用在
where子句中。因此,我们先用一个子查询(或cte)计算出每个类别内的行号排名rn,然后在外部查询中筛选出rn <= 2的记录。这里使用row_number()可以确保每个类别不多不少正好取两条(如果销售额相同)。
- 类别内最高销售额:
select s.*, max(sale_amount) over (partition by product_category) as highest_sale_in_category from sales_data s;
- 解析: 类似于第2题,
max(...) over (partition by ...)会找到每个分区内的最大值,并将其赋给该分区的所有行。
- 销售额占地区总额百分比:
select s.*, ratio_to_report(sale_amount) over (partition by region) as sale_percentage_of_region from sales_data s;
- 解析:
ratio_to_report在按region分区的窗口内计算,得出当前销售额占该地区总销售额的比例。
- 销售额分等级:
select s.*, ntile(3) over (partition by region order by sale_amount desc) as sales_tier from sales_data s;
- 解析:
ntile(3)将每个地区 (region) 的销售记录按销售额降序分成3个桶,并返回每条记录所在的桶号 (1, 2, 或 3)。
- 3行移动平均销售额:
select s.*, avg(sale_amount) over (partition by region order by sale_date rows between 2 preceding and current row) as moving_avg_3_sales from sales_data s;
- 解析: 这里必须显式定义
windowing_clause。rows between 2 preceding and current row定义了一个包含当前行和它前面两行(共三行)的滑动窗口,avg在这个窗口上计算平均值。
总结
到此这篇关于oracle窗口函数详解及练习题的文章就介绍到这了,更多相关oracle窗口函数内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!
赞 (0)
您想发表意见!!点此发布评论




发表评论