PostgreSQL分区表的实现示例
77人参与 • 2025-07-21 • MsSqlserver
一、分区表介绍
分区表是一种数据库优化技术,它允许将一个大表逻辑上划分为多个较小的、可管理的部分,这些部分被称为分区或子表。分区表在物理上是分开存储的,但在逻辑上仍作为一个整体呈现给用户。这一特性特别适用于处理大量数据的场景,旨在提高查询性能、管理和维护大数据集的效率。
1.1 分区表的好处
- 提升查询性能:通过限制查询扫描的数据量,特别是当查询可以定位到一个或几个分区时。
- 简化维护操作:例如,删除旧数据时,可以直接删除整个分区而非逐行删除。
- 优化存储管理:可以将不同访问频度的分区放置在不同性能的存储上。
- 增强可扩展性:随着数据量增长,可通过增加分区来水平扩展。
1.2 常用分区策略
- 范围分区(range partitioning):根据表中某一列的值范围来创建分区。例如,可以根据时间列将数据按月、季度或年份划分到不同的分区中。
- 列表分区(list partitioning):根据列的特定值列表来划分分区。适合于当数据可以明确地根据某个列的枚举值进行分类的情况,如按地区或用户组划分。
- 哈希分区(hash partitioning):从postgresql 11版本开始支持。基于哈希算法将数据分布到不同分区中,适用于希望数据均匀分布在各个分区的场景,但不保证数据的顺序或范围。
二、分区表的实现
2.1 声明式分区
声明式分区是postgresql 10版本开始引入的一种简化分区管理的方法,允许用户直接在create table语句中通过partition by关键词指定如何根据列的值将数据分配到不同的分区中。它支持以下几种分区类型:范围分区(range)、(list)、哈希分区(hash)等分区策略。
1.创建分区表:
-- 范围分区
create table orders (
order_id serial,
customer_id int not null,
order_status char(1) not null check (order_status in ('p', 's', 'c')),
order_date date not null
) partition by range (order_date);
-- 列表分区
create table orders (
order_id serial,
customer_id int not null,
order_status char(1) not null check (order_status in ('p', 's', 'c')),
order_date date not null
) partition by list (order_status );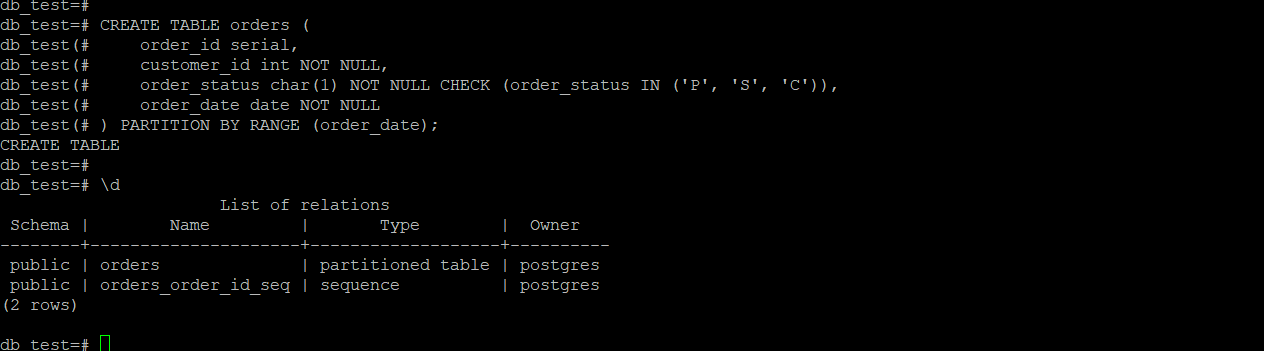
2.创建分区:
-- 范围分区
-- 2023年订单
create table orders_2023 partition of orders
for values from ('2023-01-01') to ('2024-01-01');
-- 2024年订单
create table orders_2024 partition of orders
for values from ('2024-01-01') to ('2025-01-01');
-- 列表分区
create table orders_pending partition of orders
for values in ('p');
create table orders_shipped partition of orders
for values in ('s');
create table orders_completed partition of orders
for values in ('c');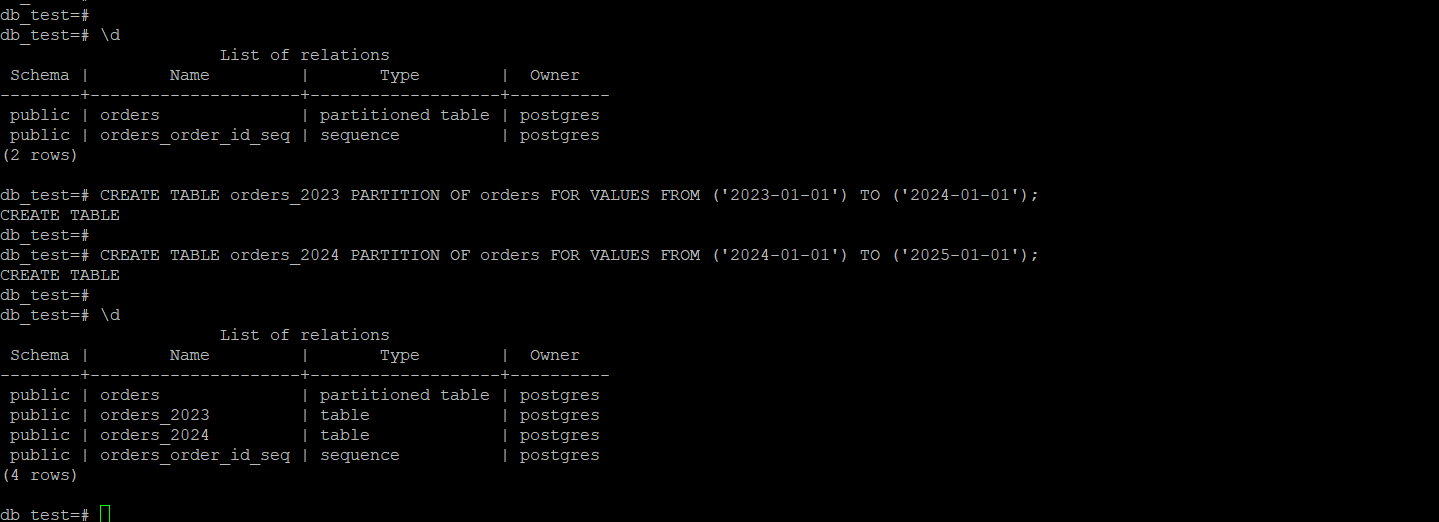
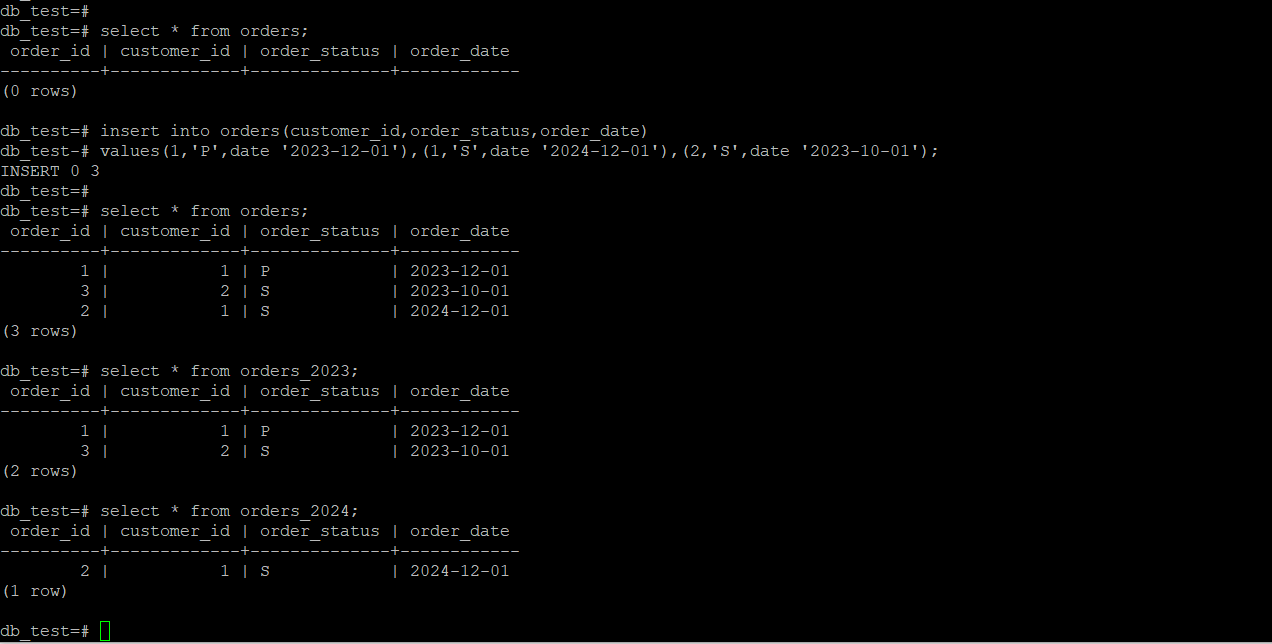
3.数据插入与查询
insert into orders(customer_id,order_status,order_date) values(1,'p',date '2023-12-01'),(1,'s',date '2024-12-01'),(2,'s',date '2023-10-01');
2.2 使用继承表进行分区
在postgresql中,使用继承表进行分区是一种较早(postgresql 10前)的分区实现方式,它依赖于postgresql的表继承特性。对于声明性分区,分区必须具有与分区表完全相同的列集,而对于表继承,子表可能具有父表中不存在的额外列。
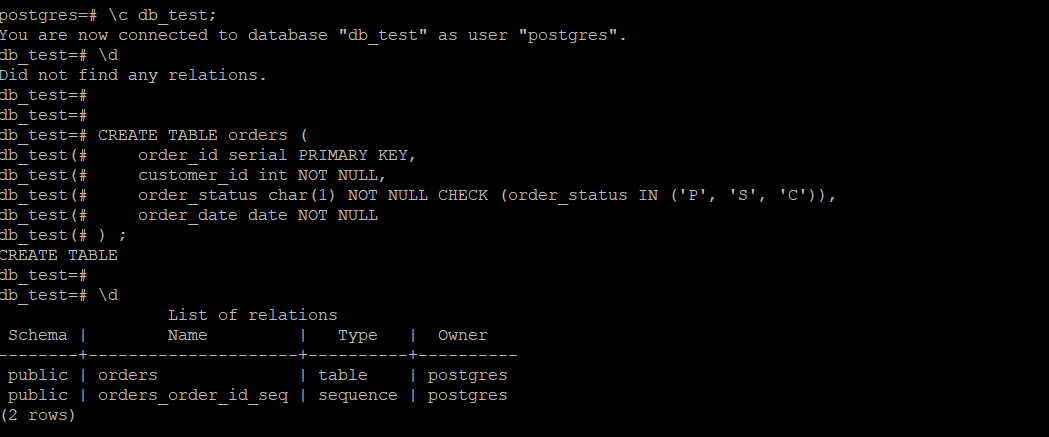
1.创建父表,所有子表继承该表,一般父表不存储数据,也不需要在父表中建立索引:
create table orders (
order_id serial primary key,
customer_id int not null,
order_status char(1) not null check (order_status in ('p', 's', 'c')),
order_date date not null
) ;
2. 创建子表,使用inherits关键字继承父表:
create table orders_2023 (
check (order_date >= '2023-01-01' and order_date < '2024-01-01')
) inherits (orders);
create table orders_2024 (
check (order_date >= '2024-01-01' and order_date < '2025-01-01')
) inherits (orders);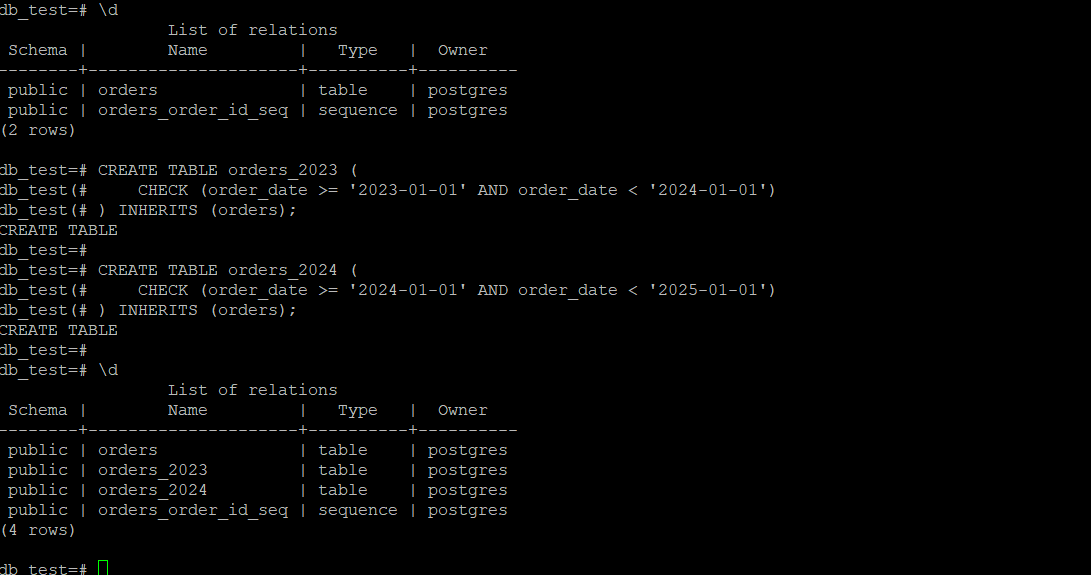
3.建立分区键索引
create index orders_2023_order_date on orders_2023(order_date); create index orders_2024_order_date on orders_2024(order_date);
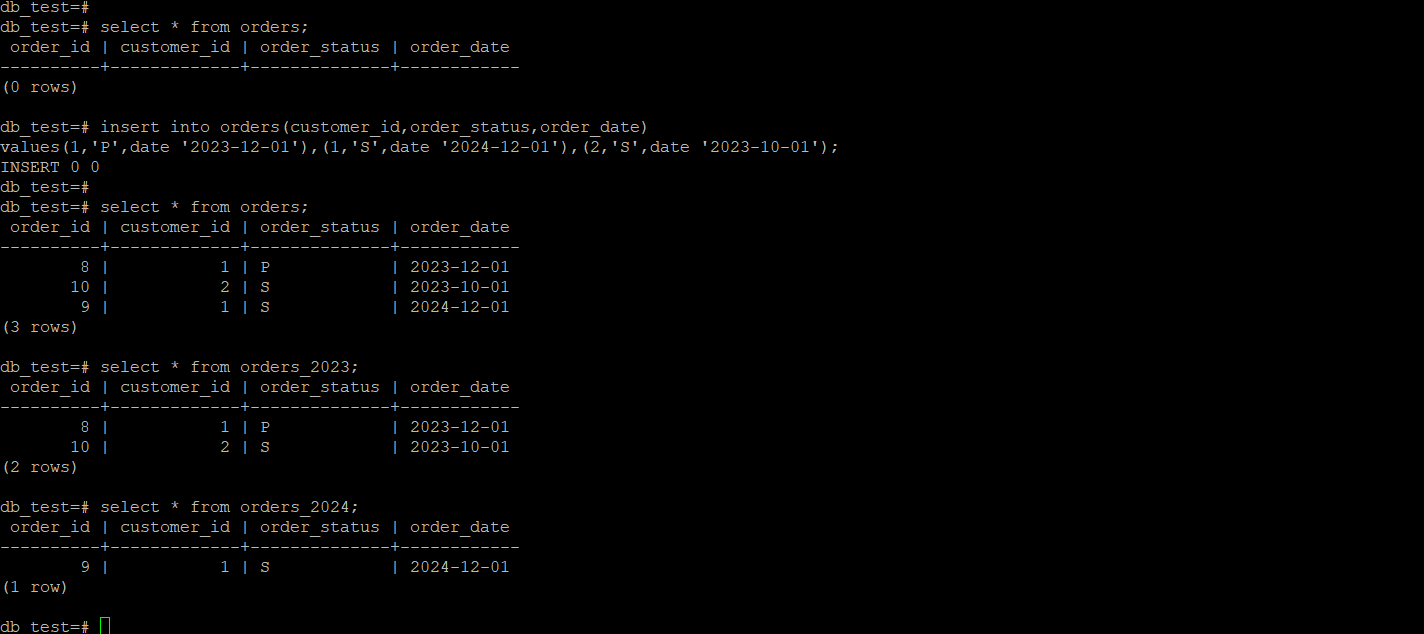
4.数据插入与查询
数据应该直接插入到相应的分区中,或者通过触发器(trigger)或规则(rule)自动路由到正确的分区。查询时,通常直接针对主表进行,postgresql 查询优化器会自动识别并只扫描相关的分区。
create or replace function orders_insert_trigger()
returns trigger as $$
begin
if(new.order_date >= '2023-01-01' and new.order_date < '2024-01-01') then
insert into orders_2023 values(new.*);
elseif(new.order_date >= '2024-01-01' and new.order_date < '2025-01-01') then
insert into orders_2024 values(new.*);
else
raise exception 'date out of range. fix the orders_insert_trigger() function!';
end if;
return null;
end;
$$
language plpgsql;
create trigger insert_order_trigger before insert on orders for each row execute procedure orders_insert_trigger();
三、管理分区
3.1 新建分区
参考上节实现。
3.2 删除分区
drop table orders_2023;
3.3 清空分区数据
alter table orders detach partition orders_2023;
到此这篇关于postgresql分区表的实现示例的文章就介绍到这了,更多相关postgresql分区表内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!
赞 (0)
您想发表意见!!点此发布评论






发表评论