8人参与 • 2025-07-24 • Redis
在现代高并发系统中,缓存是提升系统性能的关键组件之一。传统的单一缓存方案往往难以同时满足高性能和高可用性的需求。本文将介绍如何结合 redis 和 caffeine 构建一个高效的两级缓存系统,并通过三个版本的演进展示如何逐步优化代码结构。
两级缓存通常由本地缓存(如 caffeine)和分布式缓存(如 redis)组成:
通过结合两者优势,我们可以构建一个既快速又具备一致性的缓存系统。
| 缓存类型 | 平均延迟 | 延迟波动范围 |
|---|---|---|
| 本地缓存 | 0.05-1ms | 稳定 |
| 远程缓存 | 1-10ms | 受网络影响大 |
| 数据库查询 | 10-100ms | 取决于sql复杂度 |
典型案例:某电商平台商品详情页采用两级缓存后:
本地缓存的延迟是最低的,远远低于redis等远程缓存,而且本地缓存不受网络的影响,所以延迟的波动范围也是最稳定的。所以,二级缓存在性能上有极大的优势。
1.抗流量洪峰能力
假如电商环境中出现了秒杀场景,或者促销活动。会有大量的访问到同一个商品或者优惠券,以下是两种情景:
纯redis方案,所有请求直达redis,容易导致:
两级缓存方案:
2.故障容忍度
由于redis等远程缓存需要通过网络连接,如果网络出现异常,很容易出现访问不到数据的情况。本地缓存则不存在网络问题,所以对故障的容忍度是非常高的。
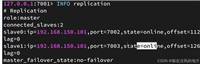
网络分区场景测试:
模拟 机房网络抖动(丢包率30%):
caffeine 是一个高性能的 java 本地缓存库,可以理解为 java 版的"内存临时储物柜"。它的核心特点可以用日常生活中的例子来理解:
就像一个智能的文件柜:
技术特点:
基于 google guava 缓存改进而来
读写性能接近 hashmap(o(1)时间复杂度)
提供多种淘汰策略:
// 按数量淘汰(保留最近使用的1000个) caffeine.newbuilder().maximumsize(1000) // 按时间淘汰(数据保存1小时) caffeine.newbuilder().expireafterwrite(1, timeunit.hours)
典型使用场景:
// 创建缓存(相当于准备一个储物柜)
cache<string, user> cache = caffeine.newbuilder()
.maximumsize(100) // 最多存100个用户
.expireafterwrite(10, timeunit.minutes) // 10分钟不用就清理
.build();
// 存数据(往柜子里放东西)
cache.put("user101", new user("张三"));
// 取数据(从柜子拿东西)
user user = cache.getifpresent("user101");
// 取不到时自动加载(柜子没有就去仓库找)
user user = cache.get("user101", key -> userdao.getuser(key));
优势对比:
注意事项:
在第一个版本中,我们直接在 service 层实现了两级缓存逻辑:
@override
public order getorderbyid(integer id) {
string key = cacheconstant.order + id;
return (order) ordercache.get(key, k -> {
// 先查询 redis
object obj = redistemplate.opsforvalue().get(key);
if (obj != null) {
log.info("get data from redis");
if (obj instanceof order) {
return (order) obj;
} else {
log.warn("unexpected type from redis, expected order but got {}", obj.getclass());
}
}
// redis没有或类型不匹配则查询 db
log.info("get data from database");
order myorder = ordermapper.getorderbyid(id);
redistemplate.opsforvalue().set(key, myorder, 120, timeunit.seconds);
return myorder;
});
}
优点:
缺点:
在spring项目中,提供了cachemanager接口和一些注解,允许让我们通过注解的方式来操作缓存。先来看一下常用的几个注解说明:
1.@cacheable- 缓存查询
作用:将方法的返回值缓存起来,下次调用时直接返回缓存数据,避免重复计算或查询数据库。
适用场景:
getuserbyid、findproduct)示例:
@cacheable(value = "users", key = "#userid")
public user getuserbyid(long userid) {
// 如果缓存中没有,才执行此方法
return userrepository.findbyid(userid).orelse(null);
}
参数说明:
value / cachenames:缓存名称(如 "users")key:缓存键(支持 spel 表达式,如 #userid)condition:条件缓存(如 condition = "#userid > 100")unless:排除某些返回值(如 unless = "#result == null")2.@cacheput- 更新缓存
作用:方法执行后,更新缓存(通常用于 insert 或 update 操作)。
适用场景:
示例:
@cacheput(value = "users", key = "#user.id")
public user updateuser(user user) {
return userrepository.save(user); // 更新数据库后,自动更新缓存
}
注意:
与 @cacheable 不同,@cacheput 一定会执行方法,并更新缓存。
3.@cacheevict- 删除缓存
作用:方法执行后,删除缓存(适用于 delete 操作)。
适用场景:
示例:
@cacheevict(value = "users", key = "#userid")
public void deleteuser(long userid) {
userrepository.deletebyid(userid); // 删除数据库数据后,自动删除缓存
}
参数扩展:
allentries = true:清空整个缓存(如 @cacheevict(value = "users", allentries = true))beforeinvocation = true:在方法执行前删除缓存(避免方法异常导致缓存未清理)第二个版本利用了 spring 的缓存注解来简化代码,如果要使用上面这几个注解管理缓存的话,我们就不需要配置v1版本中的那个类型为cache的bean了,而是需要配置spring中的cachemanager的相关参数,具体参数的配置和之前一样。
注意,在改进更新操作的时,这里和v1版本的代码有一点区别,在之前的更新操作方法中,是没有返回值的void类型,但是这里需要修改返回值的类型,否则会缓存一个空对象到缓存中对应的key上。当下次执行查询操作时,会直接返回空对象给调用方,而不会执行方法中查询数据库或redis的操作。
@cacheable(value = "order", key = "#id")
@override
public order getorderbyid(integer id) {
string key = cacheconstant.order + id;
// 先查询 redis
object obj = redistemplate.opsforvalue().get(key);
if (obj != null) {
log.info("get data from redis");
if (obj instanceof order) {
return (order) obj;
} else {
log.warn("unexpected type from redis, expected order but got {}", obj.getclass());
}
}
// redis没有或类型不匹配则查询 db
log.info("get data from database");
order myorder = ordermapper.getorderbyid(id);
redistemplate.opsforvalue().set(key, myorder, 120, timeunit.seconds);
return myorder;
}
@override
@cacheput(cachenames = "order",key = "#order.id")
public order updateorder(order order) {
log.info("update order data");
ordermapper.updateorderbyid(order);
//修改 redis
redistemplate.opsforvalue().set(cacheconstant.order + order.getid(),
order, 120, timeunit.seconds);
return order;
}
@override
@cacheevict(cachenames = "order",key = "#id")
public void deleteorderbyid(integer id) {
log.info("delete order");
ordermapper.deleteorderbyid(id);
redistemplate.delete(cacheconstant.order + id);
}
改进点:
@cacheable 注解管理 caffeine 缓存遗留问题:
如果单纯只是使用cache注解进行缓存,还是无法把redis功能实现从server模块中剥离出去。如果按照spring对cache注解的思路,我们可以自定义注解再利用aop切片操作,把对应的缓存功能切入到service的代码中,就能实现二者之间的解耦。
首先,需要定义一个注解:
/**
* 双缓存注解,用于标记需要使用双缓存(通常为本地缓存和远程缓存)的方法
*/
@target(elementtype.method)
@retention(retentionpolicy.runtime)
@documented
public @interface doublecache {
/**
* 指定缓存的名称
* @return 缓存名称
*/
string cachename();
/**
* 指定缓存的键,支持spring el表达式
* @return 缓存键
*/
string key(); //支持springel表达式
/**
* 指定二级缓存的超时时间,单位默认根据实现确定(通常为秒)
* 默认值为120
* @return 二级缓存超时时间
*/
long l2timeout() default 120;
/**
* 指定缓存类型
* 默认值为 cachetype.full
* @return 缓存类型
*/
cachetype type() default cachetype.full;
}
定义一个枚举类型的变量,表示缓存操作的类型:
public enum cachetype {
full, //存取
put, //只存
delete //删除
}
如果要支持springel的表达式,还需要一个工具类来解析springei的表达式:
public class spelexpressionutils {
/**
* 解析 spel 表达式并替换变量
* @param elstring 表达式(如 "user.name")
* @param map 变量键值对
* @return 解析后的字符串
*/
public static string parse(string elstring, treemap<string, object> map) {
// 将输入的表达式包装为 spel 表达式格式
elstring = string.format("#{%s}", elstring);
// 创建 spel 表达式解析器
expressionparser parser = new spelexpressionparser();
// 创建标准的评估上下文,用于存储变量
evaluationcontext context = new standardevaluationcontext();
// 将传入的变量键值对设置到评估上下文中
map.foreach(context::setvariable);
// 使用解析器解析表达式,使用模板解析上下文
expression expression = parser.parseexpression(elstring, new templateparsercontext());
// 在指定上下文中计算表达式的值,并将结果转换为字符串返回
return expression.getvalue(context, string.class);
}
}
定义切片,在切片操作中来实现caffeine和redis的缓存操作:
@slf4j
@component
@aspect
@allargsconstructor
public class cacheaspect {
private final cache<string, object> cache;
private final redistemplate<string, object> redistemplate;
/**
* 定义切点,匹配使用了 @doublecache 注解的方法
*/
@pointcut("@annotation(com.example.redis_caffeine.annonation.doublecache)")
public void cacheaspect() {}
/**
* 环绕通知,处理缓存的读写、更新和删除操作
*
* @param point 切入点对象,包含方法执行的相关信息
* @return 方法执行的返回结果
* @throws throwable 方法执行过程中可能抛出的异常
*/
@around("cacheaspect()")
public object doaround(proceedingjoinpoint point) throws throwable {
try {
// 获取方法签名和方法对象
methodsignature signature = (methodsignature) point.getsignature();
method method = signature.getmethod();
// 解析参数,将参数名和参数值存入 treemap 中
string[] paramnames = signature.getparameternames();
object[] args = point.getargs();
treemap<string, object> treemap = new treemap<>();
for (int i = 0; i < paramnames.length; i++) {
treemap.put(paramnames[i], args[i]);
}
// 获取方法上的 @doublecache 注解
doublecache annotation = method.getannotation(doublecache.class);
// 解析 spel 表达式,得到最终的 key 片段
string elresult = spelexpressionutils.parse(annotation.key(), treemap);
// 拼接完整的缓存 key
string realkey = annotation.cachename() + cacheconstant.order + elresult;
// 处理强制更新操作
if (annotation.type() == cachetype.put) {
// 执行目标方法
object object = point.proceed();
// 将结果存入 redis,并设置过期时间
redistemplate.opsforvalue().set(realkey, object, annotation.l2timeout(), timeunit.seconds);
// 将结果存入 caffeine 缓存
cache.put(realkey, object);
return object;
}
// 处理删除操作
if (annotation.type() == cachetype.delete) {
// 从 redis 中删除缓存
redistemplate.delete(realkey);
// 从 caffeine 缓存中删除缓存
cache.invalidate(realkey);
return point.proceed();
}
// 优先从 caffeine 缓存中获取数据
object caffeinecache = cache.getifpresent(realkey);
if (caffeinecache != null) {
log.info("get data from caffeine");
return caffeinecache;
}
// 其次从 redis 中获取数据
object rediscache = redistemplate.opsforvalue().get(realkey);
if (rediscache != null) {
log.info("get data from redis");
// 将从 redis 中获取的数据存入 caffeine 缓存
cache.put(realkey, rediscache);
return rediscache;
}
// 最后查询数据库
log.info("get data from database");
object object = point.proceed();
if (object != null) {
// 将数据库查询结果存入 redis,并设置过期时间
redistemplate.opsforvalue().set(realkey, object, annotation.l2timeout(), timeunit.seconds);
// 将数据库查询结果存入 caffeine 缓存
cache.put(realkey, object);
}
return object;
} catch (exception e) {
// 记录缓存切面处理过程中的错误
log.error("cache aspect error", e);
throw e;
}
}
}
以上操作的主要工作总结下来是:
@doublecache 注解的方法执行操作流程,以查询操作为例:
拦截被 @doublecache 标记的目标方法
生成缓存键 realkey
依次查询caffeine → redis → 数据库
将数据库结果写入两级缓存并返回
若触发更新/删除操作,则同步清理或更新缓存
/**
* 根据订单id获取订单信息
* 使用 @doublecache 注解,类型为 full,会执行完整的缓存操作逻辑
* @param id 订单id
* @return 订单对象
*/
@override
@doublecache(cachename = "order", key = "#id",
type = cachetype.full)
public order getorderbyid(integer id) {
return ordermapper.getorderbyid(id);
}
/**
* 更新订单信息
* 使用 @doublecache 注解,类型为 put,会执行缓存更新操作
* @param order 订单对象
*/
@override
@doublecache(cachename = "order", key = "#id",
type = cachetype.put)
public void updateorder(order order) {
ordermapper.updateorderbyid(order);
}
/**
* 根据订单id删除订单信息
* 使用 @doublecache 注解,类型为 delete,会执行缓存删除操作
* @param id 订单id
*/
@override
@doublecache(cachename = "order", key = "#id",
type = cachetype.delete)
public void deleteorderbyid(integer id) {
ordermapper.deleteorderbyid(id);
}
核心注解:
@doublecache:自定义注解,用于标记需要两级缓存的方法cachetype:枚举,定义缓存操作类型(full, put, delete)aop实现要点:
优势:
@configuration
@enablecaching
public class caffeineconfig {
//-----------------------------v1------v3-----------------------------------
@bean
public cache<string, object> ordercache() {
return caffeine.newbuilder()
.initialcapacity(128)
.maximumsize(1024)
.expireafterwrite(60, timeunit.seconds)
.build();
}
//-----------------------------v2------------------------------------------
@bean
public cachemanager cachemanager(){
caffeinecachemanager cachemanager=new caffeinecachemanager();
cachemanager.setcaffeine(caffeine.newbuilder()
.initialcapacity(128)
.maximumsize(1024)
.expireafterwrite(60, timeunit.seconds));
return cachemanager;
}
}
@bean
public redistemplate<string, object> redistemplate(redisconnectionfactory factory) {
redistemplate<string, object> template = new redistemplate<>();
template.setconnectionfactory(factory);
// 创建 objectmapper 实例,用于 json 序列化和反序列化
objectmapper objectmapper = new objectmapper();
// 注册 javatimemodule,用于支持 java 8 日期时间类型的序列化和反序列化
objectmapper.registermodule(new javatimemodule());
// 禁用将日期写成时间戳的功能
objectmapper.disable(serializationfeature.write_dates_as_timestamps);
// 启用默认类型信息,用于处理多态类型的序列化和反序列化
objectmapper.activatedefaulttyping(objectmapper.getpolymorphictypevalidator(),
objectmapper.defaulttyping.non_final);
// 创建 genericjackson2jsonredisserializer 实例,使用配置好的 objectmapper
genericjackson2jsonredisserializer serializer =
new genericjackson2jsonredisserializer(objectmapper);
template.setkeyserializer(new stringredisserializer());
template.setvalueserializer(serializer);
template.sethashkeyserializer(new stringredisserializer());
template.sethashvalueserializer(serializer);
template.afterpropertiesset();
return template;
}
合理设置缓存过期时间:
缓存穿透防护:
缓存雪崩防护:
一致性保证:
通过三个版本的演进,我们实现了一个从强耦合到完全解耦的两级缓存系统。最终版本利用自定义注解和 aop 技术,既保持了代码的简洁性,又提供了强大的缓存功能。这种架构特别适合读多写少、对性能要求较高的场景。
在实际应用中,还需要根据具体业务特点调整缓存策略,并做好监控和指标收集,以便持续优化缓存效果。redis + caffeine 实现高效的两级缓存架构
以上就是redis+caffeine实现高效两级缓存架构的详细指南的详细内容,更多关于redis caffeine两级缓存的资料请关注代码网其它相关文章!
您想发表意见!!点此发布评论
版权声明:本文内容由互联网用户贡献,该文观点仅代表作者本人。本站仅提供信息存储服务,不拥有所有权,不承担相关法律责任。 如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 2386932994@qq.com 举报,一经查实将立刻删除。




发表评论