Redis分布式锁中Redission底层实现方式
34人参与 • 2025-08-12 • Redis
redis分布式锁中redission底层实现
大家好,今天我们来聊聊分布式系统中一个非常实用的话题——redis分布式锁,特别是redission这个优秀客户端库的底层实现原理。就像我们生活中使用钥匙开锁一样,在分布式系统中,多个服务实例也需要一种机制来"锁住"共享资源,避免并发操作导致的数据不一致问题。
想象一下这样的场景:多个微服务实例同时要修改同一个订单状态,如果没有锁机制,可能会出现订单状态被多次修改的混乱情况。而redis分布式锁就像是一把"数字钥匙",确保同一时间只有一个服务能够操作关键资源。redission作为redis的java客户端,提供了更高级、更可靠的分布式锁实现,今天我们就来深入探讨它的工作原理。
一、redission分布式锁的基本使用
理解了分布式锁的重要性后,我们先来看看redission分布式锁的基本使用方法。redission提供了非常简洁的api,让开发者能够轻松实现分布式锁功能。
redission分布式锁的使用通常分为三个步骤:获取锁、执行业务逻辑、释放锁。
下面是一个典型的使用示例:
rlock lock = redisson.getlock("mylock");
try {
// 尝试获取锁,最多等待100秒,锁自动释放时间为10秒
boolean islocked = lock.trylock(100, 10, timeunit.seconds);
if (islocked) {
// 执行业务逻辑
dosomething();
}
} catch (interruptedexception e) {
thread.currentthread().interrupt();
} finally {
lock.unlock();
}
上述代码展示了redission分布式锁的基本用法。
我们首先通过redisson.getlock()获取一个rlock对象,然后调用trylock方法尝试获取锁,最后在finally块中确保锁被释放。
这种模式与java中的reentrantlock非常相似,使得开发者能够轻松上手。
**注意:**在实际使用中,我们通常会设置一个合理的等待时间和锁自动释放时间,避免死锁和长时间等待的问题。
二、redission分布式锁的执行流程
了解了基本使用后,我们来看看redission分布式锁的整体执行流程。redission的分布式锁实现相当精巧,它不仅仅是一个简单的set命令,而是包含了一系列的保障机制。
redission分布式锁的主要执行流程可以分为以下几个阶段:
- 锁获取阶段:客户端尝试在redis中设置一个键值对,表示获取锁
- 锁等待阶段:如果锁已被其他客户端持有,当前客户端会进入等待状态
- 锁续期阶段:获取锁后,客户端会启动一个后台线程定期续期锁
- 锁释放阶段:业务逻辑执行完毕后,客户端主动释放锁
- 锁超时阶段:如果客户端崩溃,锁会在超时后自动释放
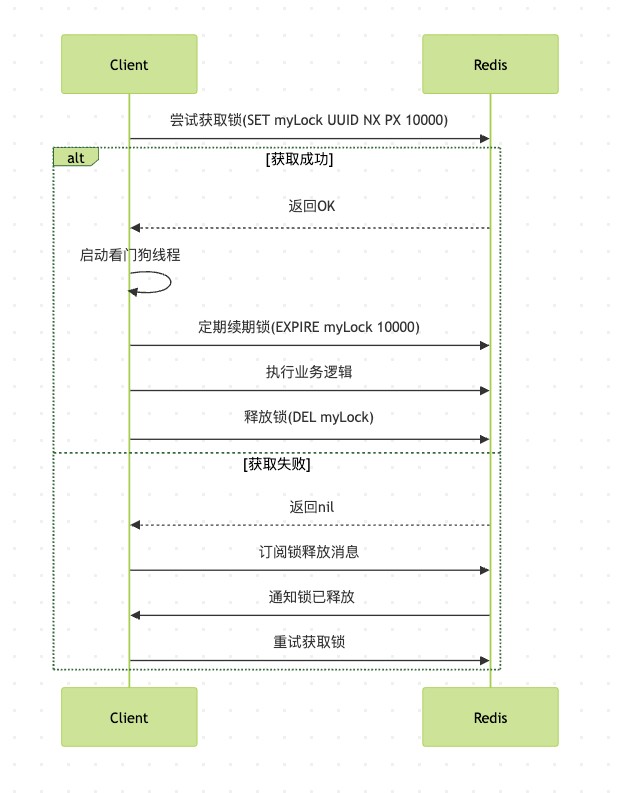
以上流程图说明了redission分布式锁的基本执行过程。我们可以看到,redission不仅实现了基本的锁获取和释放,还包含了锁等待、锁续期等高级功能,这些机制共同保证了分布式锁的可靠性和可用性。
三、redission分布式锁的技术原理
掌握了执行流程后,我们来深入探讨redission分布式锁的技术原理。redission的分布式锁实现基于redis的原子操作和lua脚本,确保了操作的原子性和一致性。
redission分布式锁的核心技术原理包括以下几个方面:
1. 基于redis的set nx px命令
redission底层使用redis的set命令配合nx(不存在才设置)和px(设置过期时间)选项来实现锁的获取。这个命令是原子性的,可以确保在高并发场景下只有一个客户端能够成功获取锁。
具体命令如下:
set lock_name random_value nx px 30000
这个命令的意思是:只有当键lock_name不存在时,才设置它的值为random_value,并设置30秒的过期时间。如果键已存在,则不做任何操作。
2. 看门狗机制(watchdog)
redission引入了一个称为"看门狗"的后台线程,它会定期检查客户端是否仍然持有锁,并在需要时延长锁的过期时间。这个机制解决了业务逻辑执行时间超过锁初始过期时间的问题。
看门狗线程默认每10秒检查一次锁状态,如果客户端仍然持有锁,就会将锁的过期时间重置为初始值(默认30秒)。这样,只要客户端还在正常运行,锁就不会因为超时而被意外释放。
3. lua脚本保证原子性
redission使用lua脚本来实现复杂的锁操作,如锁获取、锁释放等。lua脚本在redis中是原子执行的,这保证了即使在并发环境下,锁操作也不会出现竞态条件。
以下是redission用于释放锁的lua脚本简化版:
if redis.call("get",keys[1]) == argv[1] then
return redis.call("del",keys[1])
else
return 0
end
这个脚本首先检查锁的值是否与客户端持有的值匹配,只有匹配时才删除键。这避免了客户端误删其他客户端持有的锁。
4. 可重入锁实现
redission的分布式锁是可重入的,这意味着同一个线程可以多次获取同一个锁而不会阻塞自己。这是通过在redis中记录锁的持有者和获取次数来实现的。
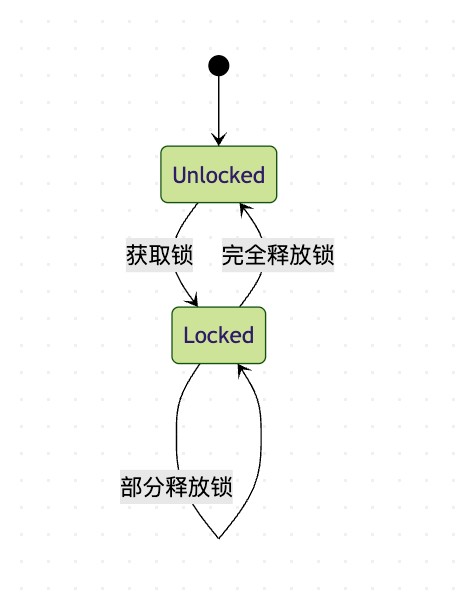
以上状态图说明了redission可重入锁的状态转换。锁会记录重入次数,只有当所有重入都被释放后,锁才会真正被释放。
四、redission分布式锁的底层实现细节
了解了基本原理后,我们再来看看redission分布式锁的具体实现细节。redission的分布式锁实现非常精巧,考虑了很多边界情况和异常处理。
1. 锁获取的详细过程
redission获取锁的过程可以分为以下几个步骤:
- 生成唯一的锁值(通常使用uuid+线程id)
- 尝试通过set nx px命令获取锁
- 如果获取失败,检查锁的剩余生存时间
- 订阅锁释放的频道,等待通知
- 收到通知后,重新尝试获取锁
- 如果等待超时,返回获取失败
2. 锁释放的详细过程
锁释放的过程同样需要考虑多种情况:
- 检查当前线程是否持有锁
- 如果是可重入锁,减少重入计数
- 如果重入计数为0,删除redis中的锁键
- 发布锁释放消息,通知等待的客户端
- 取消看门狗线程的续期任务
3. 异常处理机制
redission考虑了各种异常情况:
- 客户端崩溃:锁会在超时后自动释放,避免死锁
- 网络分区:锁最终会超时释放,保证系统最终一致性
- redis故障:redission支持多节点redis部署,提高可用性
**注意:**虽然redission提供了完善的异常处理机制,但在极端情况下(如长时间网络分区),仍然可能出现多个客户端同时持有锁的情况。对于特别关键的业务场景,需要考虑额外的保障措施。
4. 性能优化
redission在性能方面也做了很多优化:
- 使用异步方式执行redis命令,减少阻塞
- 批量执行多个redis操作,减少网络往返
- 本地缓存锁状态,减少redis访问
- 智能的锁等待策略,避免无效轮询
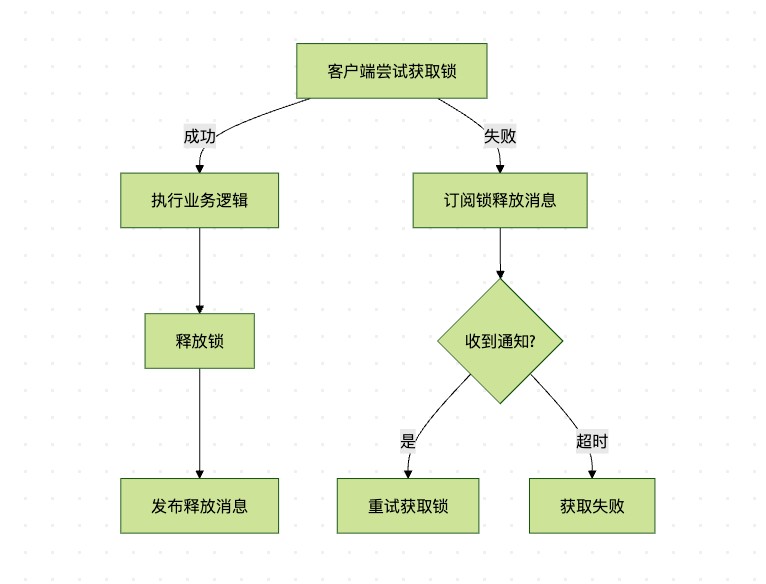
以上流程图展示了redission分布式锁的优化后的执行路径,可以看到它通过事件驱动的方式减少了不必要的轮询和资源消耗。
五、redission分布式锁的最佳实践
了解了底层实现后,我们来看看在实际项目中如何使用redission分布式锁才能发挥最大效益。
1. 合理设置锁超时时间
锁的超时时间设置非常重要:
- 设置过短:可能导致业务逻辑未执行完锁就超时释放
- 设置过长:如果客户端崩溃,其他客户端需要等待很长时间
建议根据业务逻辑的平均执行时间设置一个合理的值,并启用看门狗机制。
2. 正确处理锁释放
确保锁在finally块中释放:
rlock lock = redisson.getlock("mylock");
try {
lock.lock();
// 执行业务逻辑
} finally {
if (lock.islocked() && lock.isheldbycurrentthread()) {
lock.unlock();
}
}
这段代码展示了如何安全地释放锁,即使在异常情况下也能保证锁被正确释放。
3. 避免锁嵌套过深
虽然redission支持可重入锁,但过深的锁嵌套会导致:
- 代码难以理解和维护
- 锁持有时间过长,影响系统吞吐量
4. 考虑锁的粒度
锁的粒度选择很重要:
- 粗粒度锁:简单但并发度低
- 细粒度锁:并发度高但实现复杂
六、redission与其他分布式锁方案的比较
最后,我们来看看redission分布式锁与其他常见实现方案的比较,帮助大家在实际项目中做出合适的选择。
1. 与setnx实现的比较
简单的setnx实现:
- 优点:实现简单
- 缺点:缺乏锁续期、可重入等高级功能
2. 与zookeeper实现的比较
zookeeper分布式锁:
- 优点:强一致性,可靠性高
- 缺点:性能较低,实现复杂
3. 与数据库实现的比较
基于数据库的分布式锁:
- 优点:无需额外基础设施
- 缺点:性能差,影响数据库负载
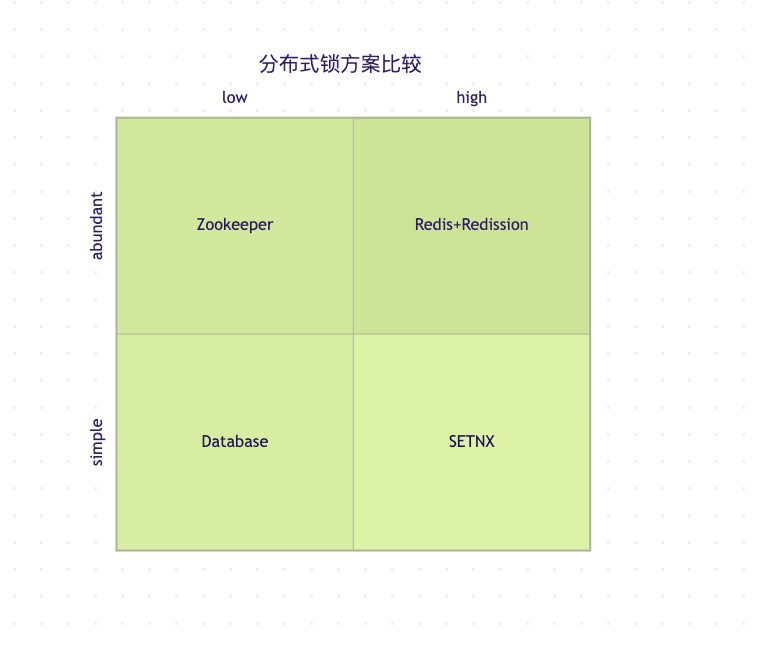
以上象限图展示了不同分布式锁方案在性能和功能丰富度上的对比。可以看到redis+redission在提供丰富功能的同时,保持了较高的性能。
总结
通过今天的讨论,我们深入了解了redission分布式锁的底层实现原理。redission通过精巧的设计,在redis基础上实现了可靠、高效的分布式锁,解决了分布式系统中的并发控制问题。
让我们回顾一下本文的主要内容:
- 基本使用:redission提供了简洁易用的api来实现分布式锁
- 执行流程:包含锁获取、等待、续期、释放等完整生命周期
- 技术原理:基于set nx px命令、看门狗机制、lua脚本和可重入设计
- 实现细节:详细的锁获取和释放过程,以及异常处理和性能优化
- 最佳实践:如何合理使用redission分布式锁
- 方案比较:与其他分布式锁实现的对比
redission的分布式锁实现既考虑了功能完整性,又注重性能优化,是java项目中实现分布式锁的优秀选择。
在实际项目中,我建议大家根据具体业务场景选择合适的锁方案,并充分测试锁在不同异常情况下的行为。记住,没有放之四海而皆准的解决方案,理解原理才能做出最佳选择。
以上为个人经验,希望能给大家一个参考,也希望大家多多支持代码网。
赞 (0)
您想发表意见!!点此发布评论




发表评论