Redis中的有序集合zset从使用到原理分析
35人参与 • 2025-09-29 • Redis
开篇:排行榜背后的秘密
想象一下你正在玩一个手机游戏,游戏里有一个全球排行榜,实时显示着所有玩家的得分情况。这个排行榜每分钟都在变化,新玩家加入,老玩家提升分数,排名不断调整。这种场景下,如果使用传统的关系型数据库来实现,每次更新分数都需要重新排序整个表,性能将会非常糟糕。
这就像在高峰期的地铁站,如果每次有人进出站都需要重新排队,那场面一定会混乱不堪。而redis的有序集合(zset)就像是一个智能的排队系统,它能自动维护元素的顺序,无论新增、删除还是修改元素,都能高效地保持有序状态。
今天我们就来深入探讨redis中这个强大的数据结构——有序集合(zset),从基本使用到内部实现原理,帮助大家更好地理解和运用这个工具。
小知识: redis的有序集合(zset)是字符串成员(member)与浮点数分值(score)的有序映射,集合中的成员是唯一的,但分值可以重复。
一、zset的基本使用
理解了zset的应用场景后,我们来看看如何使用它。redis为zset提供了丰富的命令集,让我们能够方便地操作这个数据结构。
1.1 常用命令
下面是一些最常用的zset命令:
# 添加元素 zadd key score member [score member ...] # 获取元素分数 zscore key member # 获取元素排名(从低到高) zrank key member # 获取元素排名(从高到低) zrevrank key member # 获取范围内的元素(按分数从低到高) zrange key start stop [withscores] # 获取范围内的元素(按分数从高到低) zrevrange key start stop [withscores] # 获取分数范围内的元素 zrangebyscore key min max [withscores] [limit offset count] # 删除元素 zrem key member [member ...] # 获取集合大小 zcard key # 统计分数范围内的元素数量 zcount key min max # 增加元素的分数 zincrby key increment member
这些命令构成了zset的基本操作集,能够满足大多数使用场景的需求。
1.2 java客户端示例
在实际开发中,我们通常会使用redis的java客户端来操作zset。下面是一个使用jedis的示例:
import redis.clients.jedis.jedis;
import java.util.set;
public class zsetexample {
public static void main(string[] args) {
// 连接redis
jedis jedis = new jedis("localhost");
// 添加元素到zset
jedis.zadd("player_scores", 100, "player1");
jedis.zadd("player_scores", 200, "player2");
jedis.zadd("player_scores", 150, "player3");
// 获取所有元素(按分数升序)
set<string> players = jedis.zrange("player_scores", 0, -1);
system.out.println("所有玩家(升序): " + players);
// 获取玩家排名
long rank = jedis.zrank("player_scores", "player2");
system.out.println("player2的排名: " + (rank + 1));
// 获取玩家分数
double score = jedis.zscore("player_scores", "player3");
system.out.println("player3的分数: " + score);
// 增加玩家分数
jedis.zincrby("player_scores", 50, "player1");
// 关闭连接
jedis.close();
}
}
上述代码展示了如何使用jedis客户端操作zset。我们首先添加了几个玩家的分数,然后查询了排序结果、特定玩家的排名和分数,最后还演示了如何增加玩家的分数。
最佳实践: 在实际项目中,建议使用连接池来管理redis连接,而不是每次操作都创建新连接。这样可以显著提高性能。
二、zset的应用场景
掌握了基本操作后,我们来看看zset在实际项目中的典型应用场景。zset的独特特性使其在某些场景下成为不可替代的解决方案。
2.1 排行榜系统
这是zset最经典的应用场景。无论是游戏玩家排名、商品销量排行,还是热门内容推荐,zset都能轻松应对。
// 更新玩家分数
public void updateplayerscore(string playerid, double score) {
try (jedis jedis = jedispool.getresource()) {
jedis.zadd("game_leaderboard", score, playerid);
}
}
// 获取前10名玩家
public list<string> gettop10players() {
try (jedis jedis = jedispool.getresource()) {
return new arraylist<>(jedis.zrevrange("game_leaderboard", 0, 9));
}
}
上述代码展示了如何实现一个简单的游戏排行榜系统。zadd命令会自动维护元素的排序,而zrevrange可以方便地获取排名靠前的元素。
2.2 延迟队列
zset可以用作延迟队列的实现基础。将任务执行时间作为score,使用当前时间戳作为判断依据,可以轻松实现定时任务。
// 添加延迟任务
public void adddelayedtask(string taskid, long delayseconds) {
try (jedis jedis = jedispool.getresource()) {
long executetime = system.currenttimemillis() + delayseconds * 1000;
jedis.zadd("delayed_tasks", executetime, taskid);
}
}
// 处理到期任务
public void processreadytasks() {
try (jedis jedis = jedispool.getresource()) {
// 获取所有score小于当前时间的任务
set<string> tasks = jedis.zrangebyscore("delayed_tasks", 0, system.currenttimemillis());
for (string task : tasks) {
// 处理任务
handletask(task);
// 从队列中移除已处理任务
jedis.zrem("delayed_tasks", task);
}
}
}
这个例子展示了如何使用zset实现延迟队列。通过将执行时间作为score,我们可以轻松查询到期的任务。
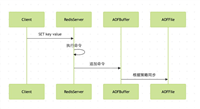
2.3 时间轴
社交网络中的时间轴功能也可以使用zset来实现。将时间戳作为score,内容id作为member,可以方便地按时间顺序获取内容。
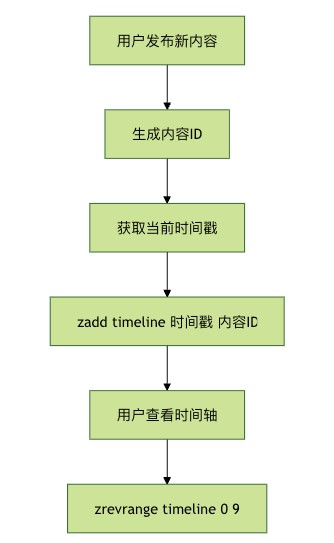
以上流程图说明了使用zset实现时间轴功能的基本流程。新内容发布时,将内容id和时间戳添加到zset中;查看时间轴时,按时间倒序获取最新的内容。
三、zset的实现原理
了解了zset的应用场景后,我们不禁要问:redis是如何实现这个高效的数据结构的?下面我们就来揭开zset的内部实现原理。
3.1 数据结构选择
redis的zset同时使用了两种数据结构来实现:
- 跳跃表(skip list):用于维护元素的有序性,支持快速的范围查询
- 哈希表(hash table):用于存储member到score的映射,支持o(1)时间复杂度的分数查询
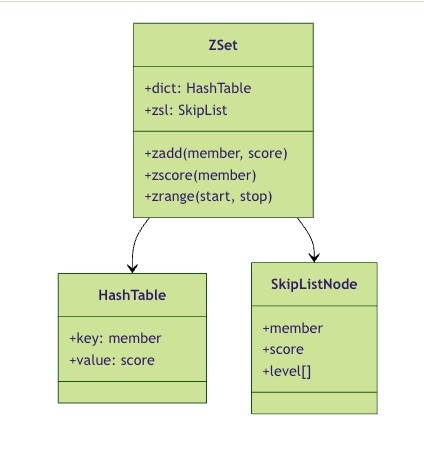
这个类图展示了zset的内部结构。zset同时维护了一个哈希表和一个跳跃表,哈希表用于快速查找member对应的score,跳跃表用于维护member的有序排列。
3.2 跳跃表详解
跳跃表是zset实现有序性的核心数据结构。它是一种概率平衡的数据结构,可以看作是多层链表的结合体。
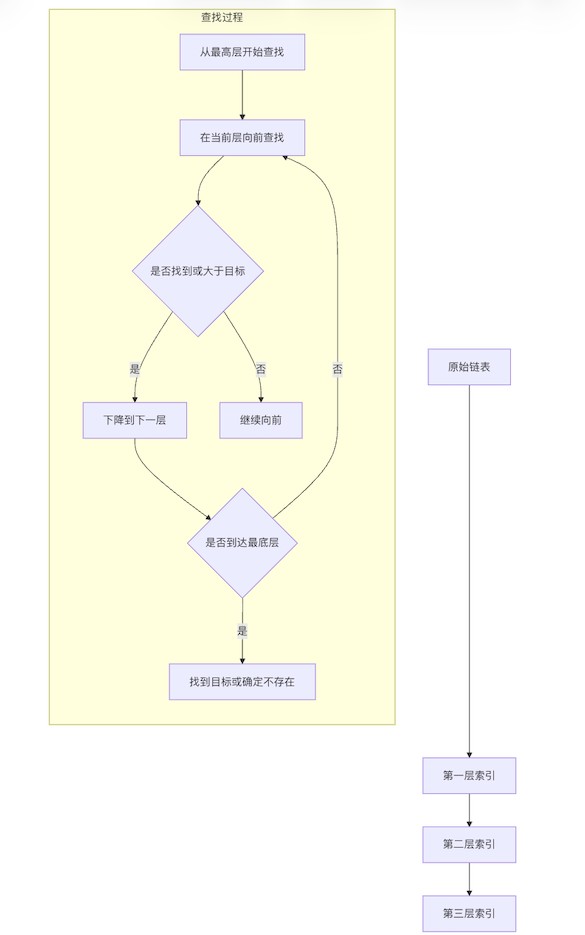
这个流程图展示了跳跃表的基本结构和查找过程。跳跃表通过建立多级索引,使得查找时间复杂度可以降低到o(log n)。
3.3 为什么使用跳跃表
redis选择跳跃表而不是平衡树来实现zset,主要基于以下几个原因:
- 实现简单:跳跃表的实现比平衡树简单得多,代码更易于维护
- 范围查询高效:跳跃表在范围查询上比平衡树更高效
- 并发友好:跳跃表在并发环境下更容易实现无锁操作
- 内存友好:跳跃表在某些情况下比平衡树更节省内存
3.4 内存结构示例
让我们通过一个具体的例子来看看zset在内存中的存储方式。假设我们有以下zset:
zadd myzset 10 "a" zadd myzset 20 "b" zadd myzset 15 "c"
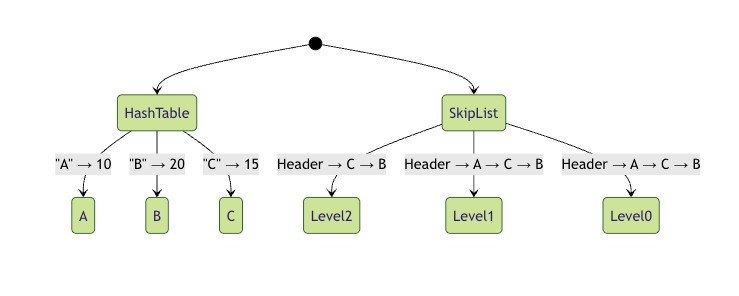
这个状态图展示了上述zset在内存中的存储结构。哈希表部分存储了member到score的映射,跳跃表部分维护了member的有序排列。
四、zset的性能分析
了解了zset的实现原理后,我们来看看它的性能特点,这对于我们在实际项目中选择合适的解决方案非常重要。
4.1 时间复杂度
zset各操作的时间复杂度如下:
- zadd:o(log n) - 需要更新跳跃表和哈希表
- zrem:o(log n) - 需要从跳跃表和哈希表中删除
- zscore:o(1) - 直接从哈希表获取
- zrank/zrevrank:o(log n) - 需要在跳跃表中查找
- zrange/zrevrange:o(log n + m) - m是返回的元素数量
- zcard:o(1) - 直接返回集合大小
4.2 内存占用
zset的内存占用主要来自两部分:
- 哈希表:存储所有member和score的映射关系
- 跳跃表:存储member的有序排列和各级索引
平均来说,zset的内存占用大约是简单字符串的2-3倍。对于内存敏感的应用,需要谨慎使用大型zset。
注意: 当zset的元素数量较少时(默认配置下小于128个元素),redis会使用一种更紧凑的编码方式(zip list)来存储zset,可以显著减少内存使用。只有元素数量超过阈值或元素大小超过限制时,才会转换为跳跃表+哈希表的存储方式。
五、高级用法与优化
掌握了zset的基本原理后,我们来看看一些高级用法和优化技巧,这些可以帮助我们在实际项目中更好地利用zset。
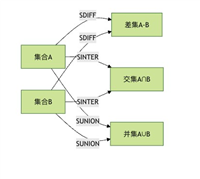
5.1 聚合操作
redis提供了zunionstore和zinterstore命令,可以对多个zset进行并集和交集运算。
# 计算两个zset的并集 zunionstore destination numkeys key [key ...] [weights weight [weight ...]] [aggregate sum|min|max] # 计算两个zset的交集 zinterstore destination numkeys key [key ...] [weights weight [weight ...]] [aggregate sum|min|max]
这些命令在需要合并多个排行榜或计算多个维度的交集时非常有用。
5.2 使用权重和聚合函数
在聚合操作中,我们可以为每个zset指定权重,并选择不同的聚合函数:
# 创建两个zset zadd zset1 1 "a" 2 "b" zadd zset2 10 "a" 20 "b" # 计算加权并集(第一个zset权重为1,第二个为0.1) zunionstore result 2 zset1 zset2 weights 1 0.1 aggregate sum # 结果应该是: "a"→2, "b"→4 zrange result 0 -1 withscores
这个例子展示了如何使用权重和聚合函数。通过合理设置权重,我们可以实现复杂的分数计算逻辑。
5.3 大zset的优化
当zset非常大时(包含数百万元素),需要考虑以下优化措施:
- 分片:将大zset拆分为多个小zset
- 定期清理:移除过期或不再需要的元素
- 使用scan代替全量查询:对于大范围查询,使用zscan避免阻塞
- 合理设置zset-max-ziplist-entries:根据实际情况调整内存优化阈值
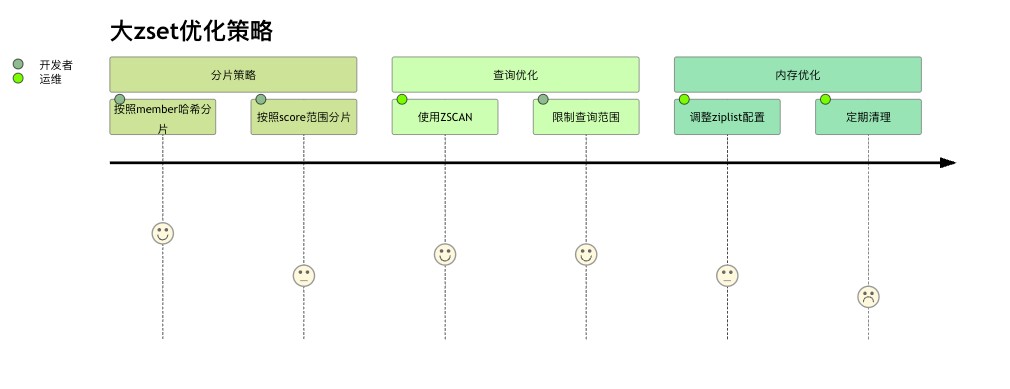
这个用户旅程图展示了大zset的各种优化策略及其重要性和相关责任人。不同的策略适用于不同的场景,需要根据实际情况选择。
六、总结
通过今天的讨论,我们对redis的有序集合(zset)有了全面的了解。让我们回顾一下本文的主要内容:
- 基本使用:介绍了zset的常用命令和java客户端示例
- 应用场景:探讨了zset在排行榜、延迟队列和时间轴等场景的应用
- 实现原理:深入分析了zset的跳跃表+哈希表的内部实现
- 性能分析:了解了zset的时间复杂度和内存占用特点
- 高级用法:学习了聚合操作、权重设置和大zset优化等高级技巧
redis的zset是一个非常强大且灵活的数据结构,它在许多场景下都能提供高效的解决方案。希望通过本文的分享,能帮助大家更好地理解和运用这个工具。
在实际项目中,建议大家根据具体需求选择合适的实现方式,并注意性能优化和内存使用。如果有任何问题或想法,欢迎随时交流讨论!
最后建议:
使用zset时,要特别注意member的大小。过大的member会显著增加内存使用,建议尽量使用较短的member(如id而非完整内容)。
以上为个人经验,希望能给大家一个参考,也希望大家多多支持代码网。
赞 (0)
您想发表意见!!点此发布评论

发表评论