36人参与 • 2025-12-25 • Redis
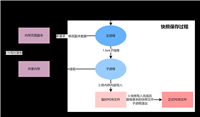
在合伙人系统的产品分配流程中,存在两种分配模式,核心差异在于是否需要审核:
为提升城市合伙人的操作效率,小程序需在 “分配产品页面” 为城市合伙人显示待审核数,实时提醒其待处理的间接分配申请,而未读计数的存储与管理是实现该功能的核心。
在 “间接分配审核接口” 的最后,通过一行代码触发未读计数更新,直接调用工具类完成城市合伙人未读数量的累加:
// 添加未读数(默认新增1条待审核提醒) appletredisutil.addunreadcount(citypartner.getid());
工具类基于 redis 实现未读计数的 “新增、查询、重置” 全流程管理,代码与逻辑解析如下:
import jakarta.annotation.resource;
import org.springblade.business.constant.rediskeyconstant;
import org.springblade.business.pojo.entity.productapplyrecord;
import org.springblade.business.service.productapplyrecordservice;
import org.springframework.data.redis.core.redistemplate;
import org.springframework.stereotype.component;
import java.util.objects;
@component // 注入spring容器,全局可用
public class appletredisutil {
@resource
private redistemplate<string, long> redistemplate; // 操作redis的核心组件
// 1. 重载方法:默认给城市合伙人新增1条未读消息
public void addunreadcount(long miniuserid) {
addunreadcount(miniuserid, 1l);
}
// 2. 核心方法:支持自定义新增未读条数,含数据准确性校验
public void addunreadcount(long miniuserid, long value) {
// 2.1 工具类无法直接注入service,通过spring上下文获取
productapplyrecordservice productapplyrecordservice = springcontextutil.getbean(productapplyrecordservice.class);
// 2.2 查该城市合伙人的总申请数(未读上限,避免未读数超过实际总数)
long totalcount = productapplyrecordservice.lambdaquery()
.eq(productapplyrecord::getcitypartnerid, miniuserid)
.count();
// 2.3 查当前redis中的未读数量(空值兜底返回0,避免空指针)
long currentunread = getunreadcount(miniuserid);
// 2.4 修正未读数量:若累加后超总申请数,取总申请数(防止数据异常)
value = (currentunread + value) > totalcount ? totalcount : (currentunread + value);
// 2.5 更新redis:用“常量前缀+用户id”作为key,原子自增未读数量
redistemplate.opsforvalue().increment(rediskeyconstant.product_apply_unread_num + miniuserid, value);
}
// 3. 查询未读数量:空值兜底,确保返回非null
public long getunreadcount(long miniuserid) {
string key = rediskeyconstant.product_apply_unread_num + miniuserid;
long unread = redistemplate.opsforvalue().get(key);
return objects.isnull(unread) ? 0l : unread;
}
// 4. 重置未读数量:先置0再删key,确保状态彻底清空
public void resetunreadcount(long miniuserid) {
string key = rediskeyconstant.product_apply_unread_num + miniuserid;
redistemplate.opsforvalue().set(key, 0l);
redistemplate.delete(key);
}
}未读计数的核心诉求是 “快、并发安全、简单”,redis 完美匹配这些需求,而 mysql 更擅长 “复杂查询、事务一致性、永久存储”,具体优势对比如下:
特性 | redis(内存数据库) | mysql(磁盘数据库) |
响应时间 | 微秒级(1μs = 10⁻⁶秒) | 毫秒级(1ms = 10⁻³ 秒) |
每秒读写能力 | 数万~数十万次 | 千级次 |
高频场景表现 | 无卡顿,轻松扛住并发(如同时 100 个申请提交) | 易出现 “查询卡顿”“写入排队”,拖慢数据库 |
当多个请求同时修改同一城市合伙人的未读计数时(如同时 2 条申请提交):
redis 的特性可轻松满足未来扩展需求,mysql 难以实现:
虽然 redis 是内存数据库,但工具类已做足数据安全保障,避免数据丢失:
到此这篇关于redis实现未读消息计数的示例代码的文章就介绍到这了,更多相关redis 未读消息计数内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!
您想发表意见!!点此发布评论
版权声明:本文内容由互联网用户贡献,该文观点仅代表作者本人。本站仅提供信息存储服务,不拥有所有权,不承担相关法律责任。 如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 2386932994@qq.com 举报,一经查实将立刻删除。




发表评论