8个Python中批量处理数据的核心库使用指南
8人参与 • 2026-01-31 • Python
处理数据的时候,我发现 excel 有时候不好用,不是说它的功能不好用,而是它的隐形转换和不可复现输在起跑线上了。日期格式错乱、大文件卡死、逻辑难以追踪,这些问题在工程化项目中是致命的。
所以,我整理了一套 python 工具栈。它们不搞花哨的噱头,只解决具体的问题。
duckdb:轻松搞定亿级数据
如果在单机上处理几百兆到几 gb 的数据,pandas 的内存占用简直让我抓狂。duckdb 的出现填补了 sqlite 和分布式数据库之间的空白。它是一个进程内的 olap 数据库,最大的特点是零配置和向量化计算。
duckdb 可以直接对 csv、parquet 或 json 文件执行 sql 查询,无需将数据全部加载到内存。
import duckdb
# 直接对 parquet 文件执行 sql,无需建库建表
# 这里的 query 类似于 pandas 的 dataframe,但计算是在 duckdb 引擎中完成的
result = duckdb.sql("""
select
department,
avg(salary) as avg_salary
from 'employees.parquet'
where join_date > '2022-01-01'
group by department
order by avg_salary desc
""").df()
print(result)
ibis:写一次代码,到处运行
ibis 和 duckdb 是目前数据工程领域的黄金搭档。
ibis 将业务逻辑与执行引擎分离,这也是它的核心。可以使用类似 pandas 的 python api 来编写查询逻辑,后端可以无缝切换为 duckdb、clickhouse、bigquery 甚至是 pyspark。
使用 ibis 驱动 duckdb 时,既享受了 python 代码的优雅和类型检查,又利用了 duckdb 极速的执行引擎。一举两得,棒棒哒。
import ibis
# 连接到 duckdb 后端(也可以是 sqlite, postgres 等)
con = ibis.duckdb.connect()
# 惰性读取数据,此时并未真正加载
table = con.read_csv("sales_data.csv")
# 构建查询表达式
expr = (
table.filter(table["status"] == "completed")
.group_by("region")
.aggregate(total_revenue=table["amount"].sum())
.order_by(ibis.desc("total_revenue"))
)
# 只有调用 execute() 时才会生成 sql 并执行
print(expr.execute())
polars:多线程时代的 dataframe
pandas 是单线程的,而 polars 是用 rust 编写的,天生支持并行计算。在处理大规模数据集时,polars 的速度通常比 pandas 快数倍。
它的设计理念采用了“惰性求值”(lazy evaluation),先构建查询计划,经优化器优化后再执行,这能极大减少内存开销。
import polars as pl
# 扫描文件而非读取,启用 lazy 模式
q = (
pl.scan_csv("large_dataset.csv")
.filter(pl.col("age") > 30)
.select(["name", "salary", "department"])
.group_by("department")
.agg(pl.col("salary").mean().alias("avg_salary"))
)
# collect() 触发实际计算
df = q.collect()
print(df)
pyarrow compute:底层的计算基石
pyarrow 不仅仅是数据格式标准,其 compute 模块提供了一套高性能的向量化计算函数。很多现代数据工具(包括 pandas 2.0+)底层都在使用它。
如果需要对数组进行极速的数学运算或字符串处理,且不想引入 dataframe 的额外开销,可以考虑一下 pyarrow compute。
import pyarrow as pa import pyarrow.compute as pc # 创建 arrow 数组 arr_a = pa.array([10, 20, 30, 40, none]) arr_b = pa.array([2, 4, 5, 8, 1]) # 使用计算内核进行向量化乘法,自动处理 none 值 result = pc.multiply(arr_a, arr_b) # 过滤数据 mask = pc.greater(result, 50) filtered = pc.filter(result, mask) print(filtered)
tinydb:面向文档的轻量级存储
并非所有项目都需要 postgresql。对于配置文件管理、小型爬虫数据存储或单机小工具,tinydb 非常合适。它是一个纯 python 编写的文档型数据库,数据存储在 json 文件中,api 像操作 python 列表一样自然。
from tinydb import tinydb, query
db = tinydb('local_storage.json')
user = query()
# 插入数据
db.insert({'name': 'alice', 'role': 'admin', 'points': 85})
db.insert({'name': 'bob', 'role': 'user', 'points': 60})
# 查询数据
results = db.search(user.role == 'admin')
print(results)
rill:开发者的 bi 工具
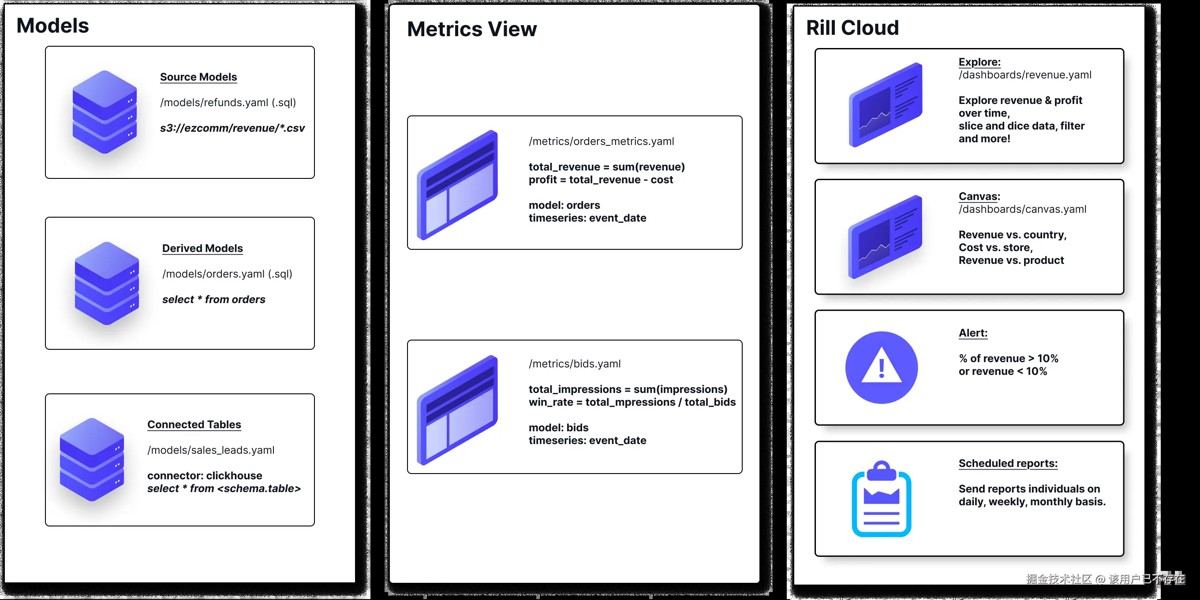
虽然 rill 更像是一个工具而非传统的 python 库,但它在现代 python 数据栈中地位独特。rill 基于 duckdb,能够快速读取本地数据(csv, parquet),并瞬间生成交互式的 bi 仪表盘。它解决了“为了看个图表还要搭一套 superset”的痛点,非常适合快速探索数据分布。
numba:让 python 跑出 c 的速度
当代码中包含大量原生 for 循环(如科学计算、复杂算法)时,python 的解释器性能往往成为瓶颈。numba 是一个 jit(即时)编译器,通过加一行装饰器,就能将 python 函数编译成机器码运行。
from numba import jit
import time
# 不使用 @jit 时,python 循环较慢
# 使用 nopython=true 强制生成机器码
@jit(nopython=true)
def heavy_computation(n):
total = 0
for i in range(n):
total += i * 2
return total
start = time.time()
print(heavy_computation(100_000_000))
print(f"耗时: {time.time() - start:.4f} 秒")
bonobo:轻量级 etl 框架
对于不需要 airflow 这种重型调度系统的数据迁移任务,bonobo 提供了一种基于图(graph)的轻量级 etl 方案。它使用纯 python 代码定义数据流向,逻辑清晰,非常适合处理中小规模的数据清洗和转换任务。
import bonobo
def extract():
yield {'id': 1, 'name': ' item a '}
yield {'id': 2, 'name': ' item b '}
def transform(row):
return {
'id': row['id'],
'name_clean': row['name'].strip().upper()
}
def load(row):
print(f"loading: {row}")
def get_graph(**options):
graph = bonobo.graph()
graph.add_chain(extract, transform, load)
return graph
if __name__ == '__main__':
# 实际运行时使用 bonobo run
parser = bonobo.get_argument_parser()
with bonobo.parse_args(parser) as options:
bonobo.run(get_graph(**options))
上述库涵盖了从数据存储、计算引擎到 etl 流程的各个环节,python的库,需要的肯定是 python 环境。
而且码农怎么可能只有一个项目需要维护呢?肯定是有的依赖最新的 python 3.14,有的则必须跑在 python 3.8 甚至古老的 python 2.7 上维护遗留系统。系统自带的 python 环境一旦弄乱,修复起来就头大了。
那这时候我们就要请上 servbay 了。
servbay 为开发者提供了一个隔离且纯净的开发环境。它最大的优势是一键部署和多版本共存。
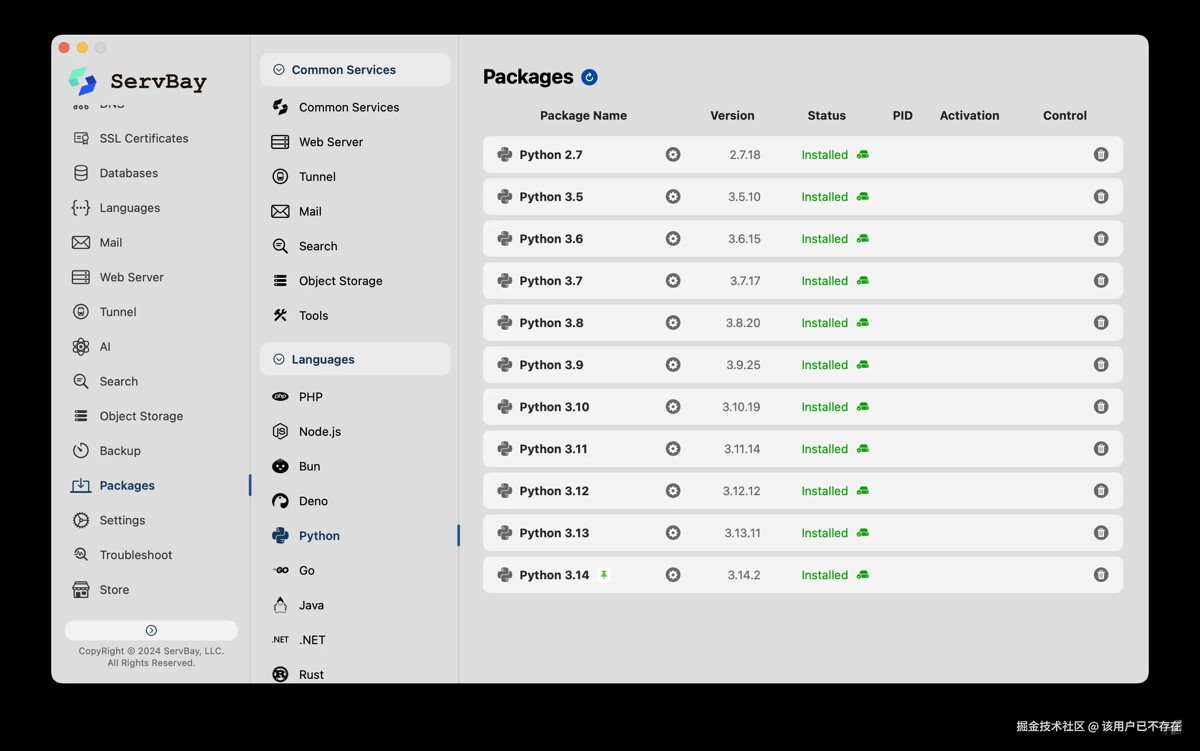
- 极速安装:还在用命令行就out了。servbay 点击即可安装好包含常用组件的开发环境。
- 全版本支持:它支持从最新的 python 3.x 到早期的 python 2.x 版本。
- 环境隔离:servbay 的环境独立于系统,不会污染系统自带的 python,保证了系统的稳定性。
对于追求效率的开发者而言,将环境管理交给 servbay,把精力集中在代码和数据逻辑上,才是更明智的选择。
数据处理的边界正在被这些新兴的工具不断拓展。对于开发者而言,保持对新技术的敏感度,同时拥有一个随时能推倒重来且互不干扰的好工具,也是提高效率的关键。
到此这篇关于8个python中批量处理数据的核心库使用指南的文章就介绍到这了,更多相关python处理数据内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!
赞 (0)
您想发表意见!!点此发布评论




发表评论