PostgreSQL主从复制的监控与故障切换指南
26人参与 • 2026-03-04 • MsSqlserver
在现代企业级应用中,数据库的高可用性(high availability, ha)已成为不可或缺的核心需求。postgresql 作为一款功能强大、开源且高度可扩展的关系型数据库管理系统,凭借其稳定性、性能和丰富的特性,被广泛应用于金融、电商、物联网等关键业务场景。而主从复制(replication)作为实现高可用性的基础技术之一,能够有效提升系统的容灾能力、读写分离能力和数据安全性。
然而,仅仅配置好主从复制并不足以保障系统稳定运行。如何实时监控复制状态?如何在主库发生故障时快速、安全地完成故障切换(failover)? 这些问题直接关系到业务连续性和用户体验。本文将深入探讨 postgresql 主从复制的监控机制与自动化故障切换策略,并结合 java 代码示例,构建一套实用的高可用解决方案。
一、postgresql 主从复制原理简述
在深入监控与故障切换之前,我们有必要先理解 postgresql 主从复制的基本工作原理。
postgresql 自 9.0 版本起引入了基于 wal(write-ahead logging)日志的流复制(streaming replication)机制。其核心思想是:主库(primary)将事务产生的 wal 日志实时传输给一个或多个从库(standby/replica),从库重放这些日志以保持与主库的数据同步。
1.1 复制类型
- 异步复制(asynchronous replication):主库在提交事务后无需等待从库确认即可返回成功。优点是性能高,缺点是在主库崩溃时可能丢失少量未同步的数据。
- 同步复制(synchronous replication):主库必须等待至少一个同步从库确认接收到并写入 wal 日志后,才向客户端返回事务成功。这保证了“零数据丢失”,但会增加事务延迟。
提示:可通过 synchronous_standby_names 参数配置同步从库。
1.2 从库角色
- 物理从库(physical standby):通过重放 wal 日志实现字节级的数据复制,与主库完全一致。这是最常用的形式。
- 逻辑从库(logical standby):基于逻辑解码(logical decoding)技术,可实现跨版本、跨结构甚至跨数据库的复制,常用于数据分发或 etl 场景。
本文主要讨论物理流复制下的监控与故障切换。
二、主从复制状态监控指标
要有效监控主从复制,我们需要关注一系列关键指标。这些指标不仅能反映复制是否正常,还能帮助我们评估延迟、吞吐量和潜在风险。
2.1 核心监控指标
| 指标 | 说明 | 查询方式 |
|---|---|---|
| 复制延迟(replication lag) | 从库落后主库的时间或 wal 位置 | pg_stat_replication / pg_last_wal_receive_lsn() 等 |
| wal 发送/接收状态 | 主库是否正在向从库发送 wal,从库是否正常接收 | pg_stat_replication 表 |
| 从库是否处于恢复模式 | 判断节点是否为从库 | pg_is_in_recovery() |
| 复制槽(replication slot)状态 | 防止 wal 被过早清理,需监控是否堆积 | pg_replication_slots |
| 连接状态 | 主从之间的网络连接是否正常 | 系统日志或 pg_stat_replication |
2.2 在主库上查询复制状态
-- 查看所有从库的连接和复制进度
select
pid,
usename,
application_name,
client_addr,
state,
sync_state,
sent_lsn,
write_lsn,
flush_lsn,
replay_lsn,
pg_wal_lsn_diff(sent_lsn, replay_lsn) as replay_lag_bytes
from pg_stat_replication;
sent_lsn:主库已发送的 wal 位置replay_lsn:从库已重放的 wal 位置replay_lag_bytes:重放延迟(字节数)
2.3 在从库上查询复制状态
-- 判断是否为从库
select pg_is_in_recovery(); -- true 表示是从库
-- 获取最后接收到的 wal 位置
select pg_last_wal_receive_lsn();
-- 获取最后重放的 wal 位置
select pg_last_wal_replay_lsn();
-- 计算时间延迟(需主库支持 track_commit_timestamp)
select
extract(epoch from (now() - pg_last_xact_replay_timestamp())) as replay_lag_seconds;
注意:pg_last_xact_replay_timestamp() 返回的是从库上最后一个重放事务的时间戳。若长时间无写入,该值可能不准确。
三、使用 java 监控主从复制状态
我们可以编写一个 java 程序,定期连接主库和从库,采集上述指标,并在异常时触发告警或自动处理。
3.1 依赖准备
使用 maven 引入 postgresql jdbc 驱动:
<dependency>
<groupid>org.postgresql</groupid>
<artifactid>postgresql</artifactid>
<version>42.7.3</version>
</dependency>
3.2 定义监控实体类
public class replicationstatus {
private string host;
private boolean isstandby;
private long replaylagbytes;
private double replaylagseconds;
private boolean isconnected;
private string errormessage;
// getters and setters
}
3.3 监控工具类
import java.sql.*;
import java.time.duration;
import java.time.instant;
public class pgreplicationmonitor {
public static replicationstatus checkreplication(string jdbcurl, string username, string password) {
replicationstatus status = new replicationstatus();
status.sethost(jdbcurl);
status.setconnected(false);
try (connection conn = drivermanager.getconnection(jdbcurl, username, password)) {
status.setconnected(true);
// 检查是否为从库
try (preparedstatement ps = conn.preparestatement("select pg_is_in_recovery()")) {
resultset rs = ps.executequery();
if (rs.next()) {
status.setisstandby(rs.getboolean(1));
}
}
if (status.isisstandby()) {
// 从库:获取延迟
try (preparedstatement ps = conn.preparestatement(
"select " +
"pg_last_wal_receive_lsn(), " +
"pg_last_wal_replay_lsn(), " +
"extract(epoch from (now() - pg_last_xact_replay_timestamp()))")) {
resultset rs = ps.executequery();
if (rs.next()) {
string receivelsn = rs.getstring(1);
string replaylsn = rs.getstring(2);
double lagseconds = rs.getdouble(3);
// 计算字节延迟(需转换 lsn)
long bytelag = calculatelsndiff(receivelsn, replaylsn);
status.setreplaylagbytes(bytelag);
status.setreplaylagseconds(lagseconds);
}
}
} else {
// 主库:可选,检查从库连接数等
// 此处略
}
} catch (sqlexception e) {
status.seterrormessage(e.getmessage());
}
return status;
}
// 简化版 lsn 差值计算(实际应解析 lsn 格式)
private static long calculatelsndiff(string lsn1, string lsn2) {
if (lsn1 == null || lsn2 == null) return 0;
// 实际项目中建议使用 postgresql 的 pg_wal_lsn_diff 函数在 sql 中计算
// 此处仅为示意
return math.abs(lsn1.hashcode() - lsn2.hashcode());
}
}
说明:lsn(log sequence number)格式如 0/1a2b3c4d,不能直接用字符串哈希计算。生产环境中应在 sql 中使用 pg_wal_lsn_diff(receive_lsn, replay_lsn) 获取字节差。
3.4 定时监控与告警
import java.util.concurrent.executors;
import java.util.concurrent.scheduledexecutorservice;
import java.util.concurrent.timeunit;
public class replicationwatcher {
private static final string primary_url = "jdbc:postgresql://primary-db:5432/mydb";
private static final string standby_url = "jdbc:postgresql://standby-db:5432/mydb";
private static final string username = "repuser";
private static final string password = "secret";
public static void main(string[] args) {
scheduledexecutorservice scheduler = executors.newscheduledthreadpool(2);
scheduler.scheduleatfixedrate(() -> {
replicationstatus standby = pgreplicationmonitor.checkreplication(standby_url, username, password);
if (!standby.isconnected()) {
alert("standby db connection failed: " + standby.geterrormessage());
} else if (standby.getreplaylagseconds() > 30) {
alert("high replication lag: " + standby.getreplaylagseconds() + " seconds");
}
}, 0, 10, timeunit.seconds); // 每10秒检查一次
}
private static void alert(string message) {
system.err.println("[alert] " + instant.now() + ": " + message);
// 可集成邮件、钉钉、企业微信等通知
}
}
通过上述代码,我们可以实现对从库复制状态的持续监控,并在延迟过高或连接中断时发出告警。
四、故障切换(failover)机制详解
当主库发生不可恢复的故障(如硬件损坏、网络分区、服务崩溃等)时,必须将一个从库提升为新的主库,以恢复写服务能力。这个过程称为故障切换(failover)。
4.1 故障切换的关键挑战
- 数据一致性:确保新主库包含尽可能多的已提交事务,避免数据丢失。
- 脑裂(split-brain):防止多个节点同时认为自己是主库,导致数据冲突。
- 客户端重定向:应用程序需能自动发现新主库并重连。
- 原主库恢复后的处理:故障修复后,原主库应作为从库重新加入集群。
4.2 手动 vs 自动故障切换
- 手动切换:dba 介入,执行
pg_ctl promote或创建trigger_file。适用于可控环境,但 rto(恢复时间目标)较长。 - 自动切换:由高可用管理工具(如 patroni、repmgr)自动完成。要求有可靠的健康检测和仲裁机制。
推荐:生产环境应使用自动化工具,避免人为失误。
五、使用 patroni 实现自动化高可用
patroni 是一个基于 python 的 postgresql 高可用模板,它利用分布式配置存储(如 etcd、zookeeper、consul)来协调主从角色,实现自动故障检测与切换。
patroni 的核心优势:
- 基于 raft/paxos 的 leader 选举
- 支持同步/异步复制
- 提供 rest api 用于状态查询和手动操作
- 与 kubernetes 深度集成(通过 spilo)
5.1 patroni 配置示例(etcd 后端)
scope: mycluster
namespace: /service/
name: pg-node1
restapi:
listen: 0.0.0.0:8008
connect_address: 192.168.1.10:8008
etcd:
hosts: ["etcd1:2379", "etcd2:2379", "etcd3:2379"]
bootstrap:
dcs:
ttl: 30
loop_wait: 10
retry_timeout: 10
maximum_lag_on_failover: 1048576 # 1mb
postgresql:
use_pg_rewind: true
parameters:
wal_level: replica
hot_standby: on
max_wal_senders: 10
wal_keep_segments: 8
postgresql:
listen: 0.0.0.0:5432
connect_address: 192.168.1.10:5432
data_dir: /var/lib/postgresql/14/main
bin_dir: /usr/lib/postgresql/14/bin
authentication:
replication:
username: replicator
password: rep-pass
superuser:
username: postgres
password: admin-pass
启动 patroni 后,它会自动初始化集群或加入现有集群。
5.2 故障切换流程
- 主库节点宕机,patroni 心跳超时(
ttl秒内未更新) - 其他节点通过 etcd 发起 leader 选举
- 选出新主库(通常选择 wal 最新的从库)
- 新主库执行
promote,停止恢复模式 - 更新 etcd 中的 leader 信息
- 应用程序通过负载均衡器或服务发现连接新主库
六、java 应用如何感知主库变更?
即使底层完成了故障切换,java 应用仍需能自动连接到新主库。以下是几种常见方案:
6.1 使用连接池 + 重试机制
hikaricp、druid 等连接池支持连接失败重试。配合合理的 sql 重试逻辑,可在主库切换后自动恢复。
// hikaricp 配置示例
hikariconfig config = new hikariconfig();
config.setjdbcurl("jdbc:postgresql://new-primary:5432/mydb");
config.setusername("appuser");
config.setpassword("pass");
config.setconnectiontimeout(3000);
config.setidletimeout(60000);
config.setmaxlifetime(1800000);
config.setmaximumpoolsize(20);
// 关键:启用自动重连
config.adddatasourceproperty("rewritebatchedinserts", "true");
config.adddatasourceproperty("tcpkeepalive", "true");
hikaridatasource ds = new hikaridatasource(config);
6.2 使用服务发现(如 consul + spring cloud)
通过 spring cloud consul,应用可动态获取数据库主库地址:
@refreshscope
@restcontroller
public class databasecontroller {
@value("${db.primary.host}")
private string primaryhost;
@getmapping("/db/host")
public string getdbhost() {
return primaryhost; // 由 consul 动态注入
}
}
当 patroni 切换主库后,更新 consul 中的服务注册,应用自动拉取新地址。
6.3 自定义主库探测逻辑
在无法使用外部服务发现时,可编写探测逻辑:
public class masterdetector {
private volatile string currentmaster = "primary-db";
public void startdetection() {
executors.newsinglethreadscheduledexecutor().schedulewithfixeddelay(() -> {
try {
// 尝试连接候选主库列表
for (string candidate : arrays.aslist("node1", "node2", "node3")) {
if (ismaster(candidate)) {
currentmaster = candidate;
break;
}
}
} catch (exception e) {
// log error
}
}, 0, 5, timeunit.seconds);
}
private boolean ismaster(string host) {
try (connection conn = drivermanager.getconnection(
"jdbc:postgresql://" + host + ":5432/mydb", "user", "pass")) {
try (statement stmt = conn.createstatement();
resultset rs = stmt.executequery("select pg_is_in_recovery()")) {
return rs.next() && !rs.getboolean(1); // 不在恢复模式即为主库
}
} catch (sqlexception e) {
return false;
}
}
public string getcurrentmaster() {
return currentmaster;
}
}
注意:此方法在高并发下可能产生大量连接,仅适用于小规模系统。
七、故障切换后的数据一致性保障
故障切换后,必须确保数据一致性,尤其是避免“旧主库复活”导致的脑裂。
7.1 使用 pg_rewind
pg_rewind 是 postgresql 提供的工具,可将原主库快速同步到新主库的状态,避免全量重建。
前提条件:
- 启用
wal_log_hints = on或data checksums - 原主库的
$pgdata未被修改
patroni 默认启用 use_pg_rewind: true,在原主库恢复后自动执行。
7.2 复制槽(replication slot)的作用
复制槽可防止主库在从库断开时清理 wal 日志,确保从库重连后能继续同步。
-- 创建物理复制槽
select pg_create_physical_replication_slot('standby1_slot');
-- 查看槽状态
select * from pg_replication_slots;
在 patroni 中,可自动管理复制槽:
postgresql:
parameters:
max_replication_slots: 5
use_slots: true # 启用自动槽管理
八、监控与故障切换的完整流程图
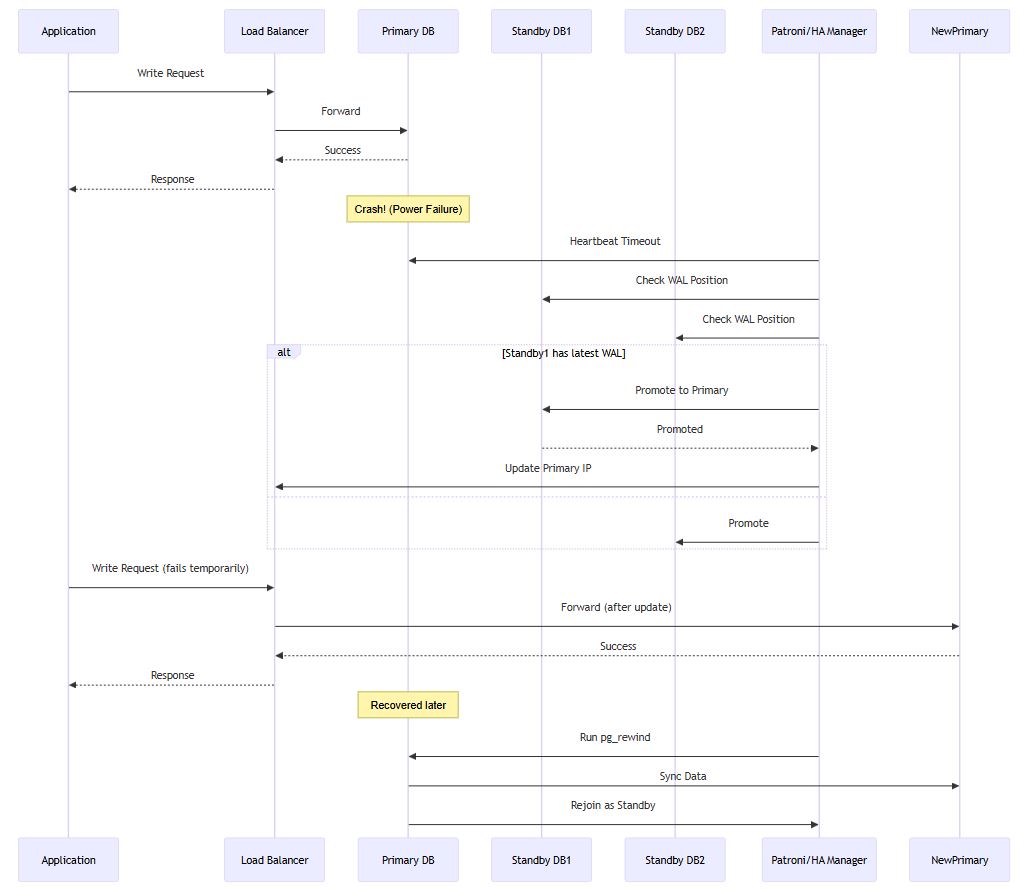
该流程展示了从故障发生到恢复的完整生命周期,强调了自动化工具在协调各组件中的作用。
九、最佳实践与避坑指南
9.1 监控层面
- 不要只监控连接状态:即使连接正常,也可能存在 wal 停滞。
- 设置合理的延迟阈值:根据业务容忍度设定(如 5 秒、30 秒)。
- 监控复制槽堆积:
pg_replication_slots.active = false且restart_lsn滞后,说明从库长期离线,wal 可能撑爆磁盘。
9.2 故障切换层面
- 避免单点仲裁:etcd/zookeeper 至少部署 3 节点,防止脑裂。
- 测试故障切换流程:定期演练,验证 rto/rpo 是否达标。
- 使用同步复制谨慎:同步从库宕机会阻塞主库写入,需配置
synchronous_commit = 'remote_write'或local降低风险。
9.3 应用层面
- 使用连接池:避免频繁创建连接。
- 实现幂等写操作:防止故障切换期间重复提交。
- 捕获特定异常:如
sqltransientconnectionexception,触发重试。
结语
postgresql 的主从复制为高可用架构奠定了坚实基础,但真正的高可用不仅在于“能复制”,更在于“能感知、能切换、能恢复”。通过结合有效的监控手段(如 java 程序采集指标)、可靠的自动化工具(如 patroni)以及健壮的应用设计(如服务发现与重试机制),我们能够构建出具备分钟级甚至秒级故障恢复能力的数据库系统。
在云原生时代,postgresql 的高可用方案也在不断演进。无论是传统虚拟机部署,还是 kubernetes 上的 operator 模式(如 zalando postgres operator),核心思想始终不变:自动化、可观测、可恢复。
以上就是postgresql主从复制的监控与故障切换指南的详细内容,更多关于postgresql主从复制监控与故障切换的资料请关注代码网其它相关文章!
赞 (0)
您想发表意见!!点此发布评论




发表评论