MySQL 存储引擎InnoDB 架构与原理深度解析
13人参与 • 2026-03-17 • Mysql
索引结构提供了高效的数据检索方式,索引信息与数据记录均存储于文件系统中,具体而言是存储在页结构中。索引的实现依赖于存储引擎,mysql 服务器通过存储引擎完成对表数据的读写操作。不同存储引擎的数据存储格式各异,部分存储引擎(如 memory)甚至不使用磁盘存储数据,而是将数据保存在内存中。
mysql 支持的存储引擎类型
通过以下命令可以查看 mysql 支持的所有存储引擎:
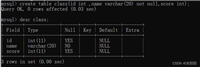
show engines;
查询结果示例:
| 存储引擎 | 支持状态 | 说明 | 事务 | 分布式事务 | 保存点 |
|---|---|---|---|---|---|
| innodb | 默认 | 支持事务、行级锁和外键 | 是 | 是 | 是 |
| myisam | 是 | 传统存储引擎,不支持事务 | 否 | 否 | 否 |
| memory | 是 | 基于哈希索引,数据存储于内存,适用于临时表 | 否 | 否 | 否 |
| csv | 是 | 以 csv 格式存储数据 | 否 | 否 | 否 |
| archive | 是 | 高压缩比的归档存储引擎 | 否 | 否 | 否 |
| blackhole | 是 | 黑洞存储引擎,写入的数据不会被保存 | 否 | 否 | 否 |
| federated | 否 | 联邦存储引擎,用于访问远程表 | 空 | 空 | 空 |
| mrg_myisam | 是 | myisam 表的集合 | 否 | 否 | 否 |
| performance_schema | 是 | 性能监控与诊断 | 否 | 否 | 否 |
默认存储引擎的查看与配置
版本差异
mysql 在不同版本中采用不同的默认存储引擎:
- mysql 5.5 及以后版本:默认存储引擎为 innodb
- mysql 5.5 之前版本:默认存储引擎为 myisam
若在创建表时未显式指定存储引擎,mysql 将自动使用默认存储引擎。
查看当前 mysql 版本
select version();
查看默认存储引擎
show variables like 'default_storage_engine';
查询结果示例(mysql 5.6.40):
| variable_name | value |
|---|---|
| default_storage_engine | innodb |
修改默认存储引擎
- 方式一:通过配置文件修改(永久生效)
- 定位 mysql 配置文件
- linux 系统:
my.cnf - windows 系统:
my.ini
- linux 系统:
- 在配置文件中添加或修改
[mysqld]部分:
[mysqld] default-storage-engine = innodb
重启 mysql 服务使配置生效:
systemctl restart mysqld.service
方式二:通过 sql 命令修改(会话级别)
set default_storage_engine = myisam;
主要存储引擎特性对比
各存储引擎核心特性
- innodb:支持 acid 事务、行级锁定、崩溃恢复、外键约束,是 mysql 的默认存储引擎
- myisam:不支持事务、行级锁和外键约束,但针对数据统计操作进行了优化,
count(*)查询效率较高 - memory:将表数据完全存储于内存中,读写速度极快,但数据不具备持久性
- archive:采用高压缩比存储,适用于存储大量历史数据,仅支持 insert 和 select 操作
- ndb:分布式存储引擎,支持高可用性和容错性,适用于高并发写入场景
核心区别:innodb 与 myisam 的三大关键差异在于事务支持、外键约束和行级锁定。
功能特性对比表
| 功能 | myisam | memory | innodb |
|---|---|---|---|
| 存储限制 | 258 tb | ram | 64 tb |
| 事务支持 | × | × | √ |
| 全文索引支持 | √ | × | √(5.6+) |
| b 树索引支持 | √ | √ | √ |
| 哈希索引支持 | × | √ | √(自适应) |
| 集群索引支持 | × | × | √ |
| 数据索引支持 | × | √ | √ |
| 数据压缩支持 | √ | × | × |
| 空间使用率 | 低 | n/a | 高 |
| 外键支持 | × | × | √ |
innodb 与 myisam 存储引擎对比分析
innodb 存储引擎
innodb 提供了完善的事务管理、崩溃恢复能力和并发控制机制。其主要优势在于:
- 事务完整性:支持 acid 特性,适用于对数据一致性要求较高的应用场景,特别是涉及频繁更新和删除操作的业务系统
- 并发性能:支持行级锁定,能够有效处理高并发访问场景,避免表级锁带来的性能瓶颈
- 数据安全性:提供崩溃恢复功能,服务器异常重启后能够自动恢复已提交的事务并回滚未提交的操作
主要劣势:
- 读写效率相对较低
- 磁盘空间占用较大
myisam 存储引擎
myisam 适用于以读取和插入操作为主、更新和删除操作较少且对事务要求不高的系统。其主要优势在于:
- 查询性能:在数据量较小的情况下,读写效率优于 innodb
- 存储效率:磁盘空间占用相对较少
主要劣势:
- 不支持事务和行级锁,仅支持表级锁
- 在高并发场景下容易出现锁表问题,影响系统性能
选型建议
innodb 是处理大规模数据的首选存储引擎。除非存在特殊的业务需求,否则应优先选择 innodb 存储引擎。
innodb 核心优势
- 崩溃恢复:服务器崩溃后重启时,innodb 自动执行崩溃恢复流程,将已提交的事务固化到磁盘,回滚未提交的事务,无需人工干预
- 缓冲池机制:innodb 在主内存中维护缓冲池(buffer pool),将高频访问的数据缓存在内存中直接处理,显著提升数据访问速度。该缓存机制适用于多种数据类型,有效加速数据处理过程
- 内存配置:在专用数据库服务器上,建议将物理内存的 60%-80% 分配给 innodb 缓冲池
- 外键约束:支持外键约束以维护数据完整性。当向子表插入数据时,若主表中不存在对应的主键记录,插入操作将被自动拒绝。更新或删除主表数据时,相关联的子表数据会自动更新或删除
- 数据校验:内置校验和(checksum)机制,在磁盘或内存数据损坏时及时发出警告,防止使用损坏的数据
- 查询优化:当表的主键设计合理时,涉及主键的操作会被自动优化。插入、更新、删除操作通过变更缓冲(change buffer)机制自动优化
- 读写并行:innodb 不仅支持当前读写操作,还会将变更数据缓存并异步刷新到磁盘
- 自适应哈希索引:当同一列被频繁查询时,自适应哈希索引会自动创建,显著提升查询性能
- 表压缩:支持表和索引的压缩,在不影响性能和可用性的前提下节省存储空间
- 在线 ddl:支持在不影响业务的情况下创建或删除索引
- 大对象存储:对于大型文本和 blob 数据,采用动态行格式(dynamic row format),提供更高效的存储布局
- 监控能力:通过查询 information_schema 数据库中的系统表,可以实时监控存储引擎的内部运行状态
- 混合使用:在同一 sql 语句中,innodb 表可以与其他存储引擎的表混合使用
- 大文件支持:即使操作系统限制单个文件大小为 2gb,innodb 仍然可以处理更大的数据量
- cpu 优化:在处理大数据量时,innodb 能够充分利用 cpu 资源以达到最优性能
表级存储引擎操作
| 操作描述 | sql 语句 |
|---|---|
| 查看表的存储引擎 | show table status like 表名称; |
| 创建表时指定存储引擎 | create table 表名称 (…) engine = 存储引擎名称; |
| 修改表的存储引擎 | alter table 表名称 engine = 存储引擎名称; |
| 查看数据库所有表的存储引擎 | select table_name, engine from information_schema.tables where table_schema = ‘数据库名称’; |
| 查看表的创建语句(包括存储引擎) | show create table 表名称; |
innodb 存储引擎架构
页:磁盘与内存交互的基本单位
innodb 将数据划分为若干个页(page),默认页大小为 16kb。页是磁盘与内存之间数据交换的基本单位,即每次至少从磁盘读取 16kb 数据到内存,或将内存中的 16kb 数据刷新到磁盘。
设计原理:数据库不以行为单位进行读取,否则每次磁盘 i/o 操作仅能处理一行数据,效率极低。
在数据库系统中,无论读取一行还是多行数据,都会将这些行所在的整个页加载到内存。因此,页是数据库管理存储空间和执行 i/o 操作的最小单位,一个页可以存储多行记录。
不同数据库系统的页大小
- mysql innodb:16kb(默认)
- sql server:8kb
- oracle:2kb、4kb、8kb、16kb、32kb、64kb(称为"块")
查看 innodb 页大小:
show variables like '%innodb_page_size%';
查询结果默认为 16384 字节,即 16kb。
页结构组织方式
页之间通过双向链表关联,无需在物理结构上连续存储。每个数据页内部的记录按主键值从小到大组成单向链表。为了提高查询效率,每个数据页会为其中的记录生成页目录(page directory),通过主键查找记录时,可以在页目录中使用二分查找法快速定位到对应的槽(slot),然后遍历该槽对应分组中的记录即可快速找到目标记录。
innodb 存储结构层次
innodb 采用分层的存储结构,从小到大依次为:行(row)、页(page)、区(extent)、段(segment)、表空间(tablespace)。
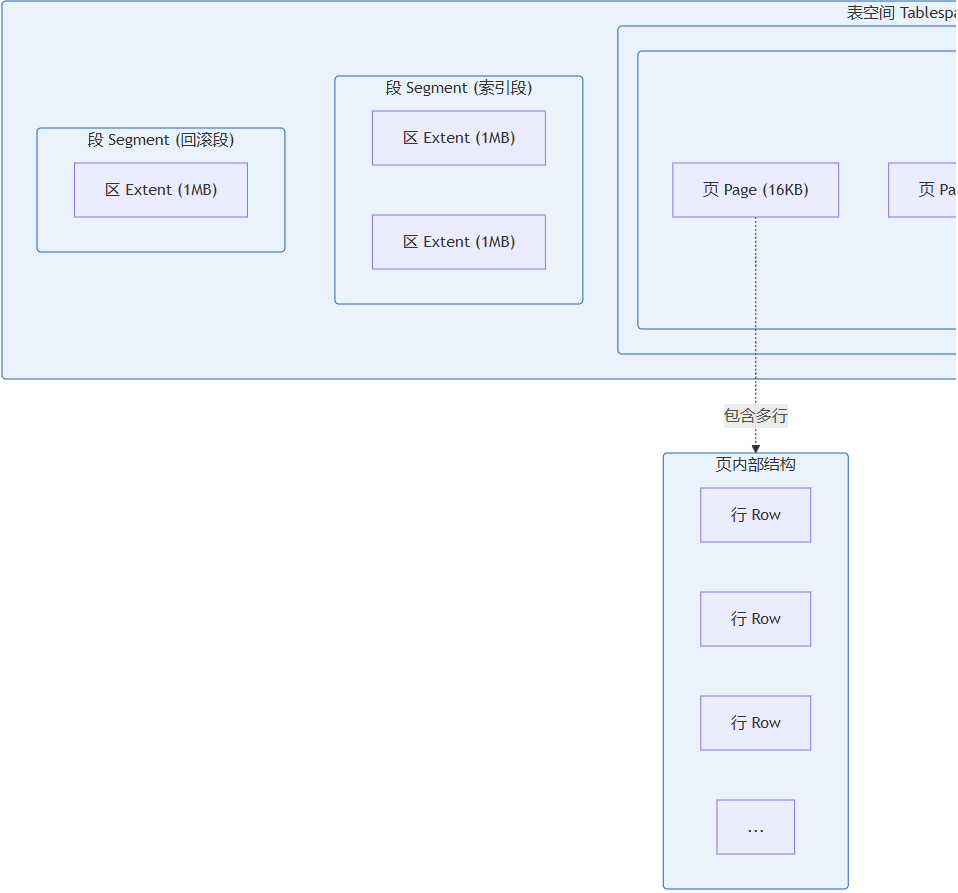
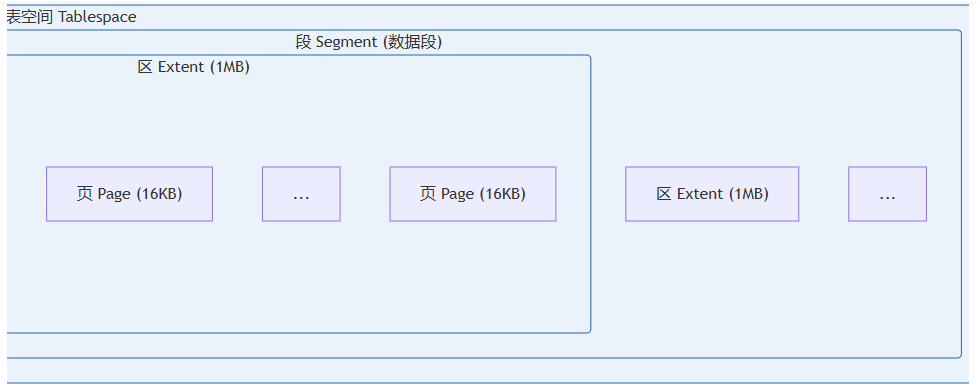
存储结构层次关系
- 行(row):数据库表中的一条记录
- 页(page):innodb 的基本存储单位,默认 16kb,包含多行记录
- 区(extent):由 64 个连续的页组成,大小为 1mb(64 × 16kb)
- 段(segment):由一个或多个区组成,如数据段、索引段、回滚段等
- 表空间(tablespace):最高层的逻辑容器,包含多个段
区(extent)
区是比页更高一级的存储结构。在 innodb 中,一个区包含 64 个连续的页。由于页的默认大小为 16kb,因此一个区的大小为 64 × 16kb = 1024kb = 1mb。
段(segment)
段由一个或多个区组成。区在文件系统中是连续分配的空间(在 innodb 中为连续的 64 个页),但段中的区之间无需相邻。段是数据库的分配单位,不同类型的数据库对象以不同的段形式存在。创建表时会创建表段,创建索引时会创建索引段。
根据存储内容和用途的不同,innodb 中的段主要分为以下三种类型:
1. 数据段(data segment / leaf node segment)
数据段用于存储表的实际数据行,对应 b+ 树索引结构的叶子节点。
- 存储位置:b+ 树的叶子节点层
- 存储内容:在 innodb 的聚簇索引(主键索引)中,叶子节点存储完整的行数据,包括所有列的值
- 数量关系:每个 innodb 表至少有一个数据段,对应主键索引的叶子节点部分
- 访问特点:数据段是顺序扫描和范围查询的主要访问对象
2. 索引段(index segment / non-leaf node segment)
索引段用于存储索引的非叶子节点数据,对应 b+ 树索引结构的内部节点。
- 存储位置:b+ 树的非叶子节点层(根节点和中间节点)
- 存储内容:索引键值和指向下一层节点的指针,用于快速定位数据位置
- 适用范围:
- 主键索引的非叶子节点属于索引段
- 二级索引(辅助索引)的所有节点(包括叶子节点和非叶子节点)都属于索引段
- 作用:通过索引段的层次结构,实现高效的数据检索
3. 回滚段(rollback segment / undo segment)
回滚段用于存储事务的回滚信息(undo log),是 innodb 事务机制的核心组件。
- 存储内容:数据修改前的旧版本(undo log)
- 主要用途:
- 事务回滚:当事务执行失败或主动回滚时,使用 undo log 将数据恢复到修改前的状态
- mvcc 实现:通过保存数据的历史版本,支持多版本并发控制(multi-version concurrency control),使不同事务能够读取到数据的不同版本
- 崩溃恢复:系统崩溃后,利用 undo log 回滚未提交的事务
- 事务保证:回滚段是实现事务原子性(atomicity)和一致性(consistency)的关键机制
三种段的协同工作
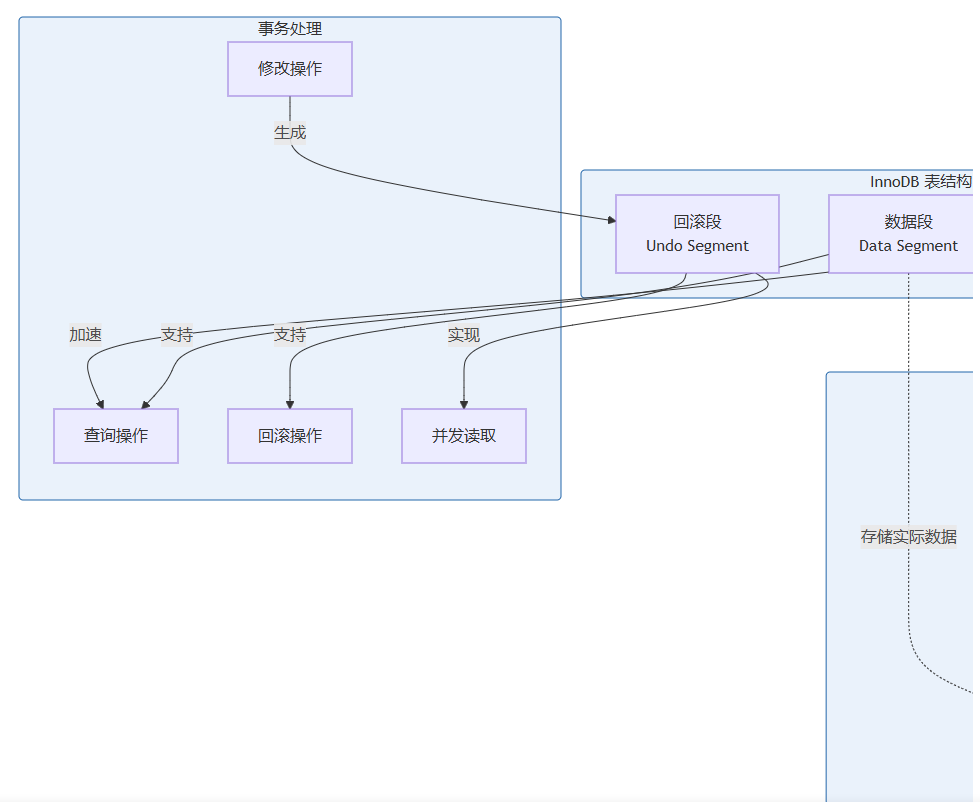
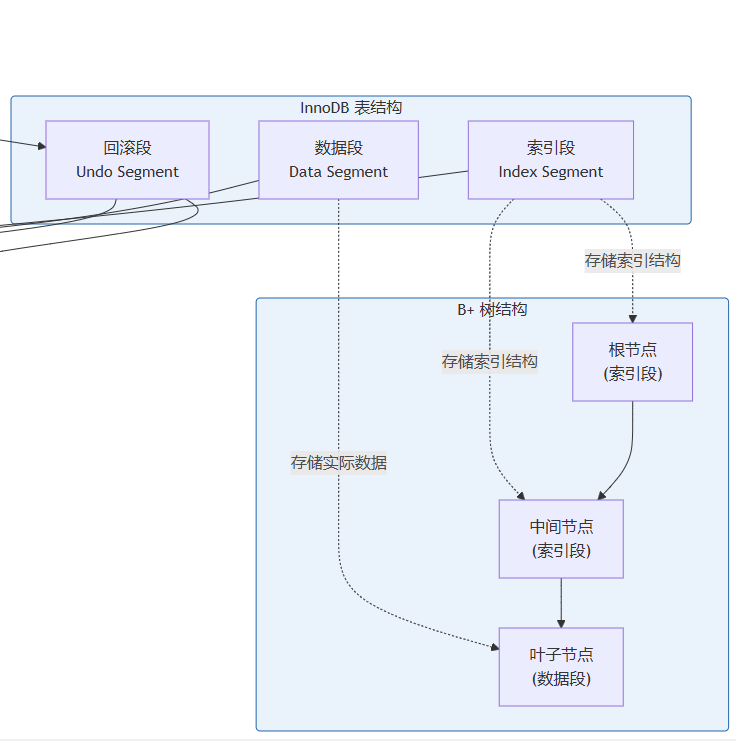
段类型对比表
| 特性 | 数据段 | 索引段 | 回滚段 |
|---|---|---|---|
| 存储内容 | 完整的行数据 | 索引键值和指针 | 数据修改前的旧版本 |
| 对应结构 | b+ 树叶子节点 | b+ 树非叶子节点 | undo log |
| 主要用途 | 存储表数据 | 加速数据检索 | 事务回滚和 mvcc |
| 创建时机 | 创建表时 | 创建索引时 | 事务修改数据时 |
| 生命周期 | 与表同生命周期 | 与索引同生命周期 | 事务提交后可清理 |
| 访问频率 | 高(数据查询) | 高(索引查询) | 中(事务回滚、mvcc) |
表空间(tablespace)
表空间是逻辑容器,用于存储段。一个表空间可以包含一个或多个段,但一个段只能属于一个表空间。数据库由一个或多个表空间组成,表空间从管理角度可划分为系统表空间、用户表空间、撤销表空间、临时表空间等。
到此这篇关于mysql 存储引擎innodb 架构与原理深度解析的文章就介绍到这了,更多相关mysql 存储引擎innodb内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!
赞 (0)
您想发表意见!!点此发布评论




发表评论