50人参与 • 2026-04-13 • Redis
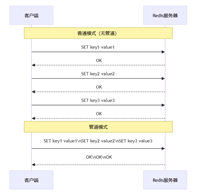
旁路缓存(cache-aside pattern)是 redis 最常用的缓存策略,通过"先查缓存,后查数据库"的读写模式,显著提升系统读取性能
在互联网应用中,数据库通常是系统性能的瓶颈。当面对高并发读取请求时,直接查询数据库会造成:
缓存的出现正是为了解决这一问题。通过将热点数据存储在内存中,缓存能够提供微秒级的访问速度。
旁路缓存(cache-aside pattern)是最经典的缓存应用模式,其核心思想是:应用层主动管理缓存,数据库为主,缓存为从。
public product getproduct(long id) {
// 1. 先查缓存
product cachedproduct = redis.get("product:" + id);
if (cachedproduct != null) {
// 缓存命中,直接返回
return cachedproduct;
}
// 2. 缓存未命中,查询数据库
product product = productmapper.findbyid(id);
if (product != null) {
// 3. 将数据写入缓存,设置过期时间
redis.set("product:" + id, product, 3600);
}
return product;
}读操作的关键步骤:
public void updateproduct(product product) {
// 1. 先更新数据库
productmapper.update(product);
// 2. 再删除缓存
redis.del("product:" + product.getid());
}写操作采用先更新数据库,后删除缓存的策略,原因如下:
问题描述:查询一个不存在的数据,由于缓存和数据库都没有,每次请求都会打到数据库。
危害:恶意用户可能利用此漏洞,大量请求不存在的数据导致数据库崩溃。
解决方案:
public product getproduct(long id) {
// 参数校验
if (id == null || id <= 0) {
return null;
}
// 1. 先查缓存
product cachedproduct = redis.get("product:" + id);
if (cachedproduct != null) {
return cachedproduct;
}
// 2. 缓存未命中,查询数据库
product product = productmapper.findbyid(id);
if (product == null) {
// 3. 缓存空值,防止穿透
redis.set("product:" + id, null, 60); // 短过期时间
return null;
}
// 4. 写入缓存
redis.set("product:" + id, product, 3600);
return product;
}额外防护措施:
// 使用布隆过滤器
private bloomfilter<long> bloomfilter;
public product getproduct(long id) {
// 布隆过滤器检查
if (!bloomfilter.mightcontain(id)) {
return null; // 一定不存在
}
// 正常查询流程
product product = getproductfromcacheordb(id);
return product;
}问题描述:某个热点数据过期的瞬间,大量并发请求同时发现缓存失效,全部涌入数据库查询。
解决方案:
private boolean lock = false;
public product getproduct(long id) {
product product = redis.get("product:" + id);
if (product != null) {
return product;
}
// 获取锁
if (trylock("lock:product:" + id)) {
try {
// double check
product = redis.get("product:" + id);
if (product != null) {
return product;
}
// 查询数据库
product = productmapper.findbyid(id);
redis.set("product:" + id, product, 3600);
} finally {
unlock("lock:product:" + id);
}
} else {
// 等待后重试
thread.sleep(100);
return getproduct(id);
}
return product;
}public product getproduct(long id) {
// 1. 查缓存
product product = redis.get("product:" + id);
if (product == null) {
// 缓存为空,尝试获取锁重建缓存
if (trylock("lock:product:" + id)) {
product newproduct = productmapper.findbyid(id);
redis.set("product:" + id, newproduct, 3600);
unlock("lock:product:" + id);
return newproduct;
}
// 等待后重试
thread.sleep(100);
return getproduct(id);
}
// 2. 检查是否逻辑过期
if (islogicalexpired(product)) {
// 异步重建缓存,不阻塞请求
if (trylock("lock:product:" + id)) {
threadpool.execute(() -> {
product newproduct = productmapper.findbyid(id);
redis.set("product:" + id, newproduct, 3600);
unlock("lock:product:" + id);
});
}
}
return product;
}问题描述:大量缓存数据在同一时间过期,导致大量请求同时打到数据库。
解决方案:
// 设置过期时间添加随机值
int baseexpire = 3600;
int randomexpire = threadlocalrandom.current().nextint(300);
redis.set("product:" + id, product, baseexpire + randomexpire);public product getproduct(long id) {
// 1. 先查本地缓存
product product = localcache.get(id);
if (product != null) {
return product;
}
// 2. 查 redis
product = redis.get("product:" + id);
if (product != null) {
// 回填本地缓存
localcache.put(id, product, 300);
return product;
}
// 3. 查数据库
product = productmapper.findbyid(id);
redis.set("product:" + id, product, 3600);
return product;
}public product getproduct(long id) {
try {
// 1. 查缓存
product product = redis.get("product:" + id);
if (product != null) {
return product;
}
// 2. 缓存未命中,降级处理
return getproductfrombackup(id);
} catch (exception e) {
// redis 异常,降级到数据库
log.error("redis error, fallback to db", e);
return productmapper.findbyid(id);
}
}public void updateproduct(product product) {
// 1. 删除缓存
redis.del("product:" + product.getid());
// 2. 更新数据库
productmapper.update(product);
// 3. 延迟删除缓存
threadpool.execute(() -> {
try {
thread.sleep(1000);
redis.del("product:" + product.getid());
} catch (interruptedexception e) {
thread.currentthread().interrupt();
}
});
}延迟双删的适用场景:写操作非常频繁,且对一致性要求较高。
// canal 配置
@canalmessagelistener(topic = "product_db.product")
public void onmessage(canalentry.entry entry) {
canalentry.rowchange rowchange = canalentry.rowchange.parsefrom(entry.getstorevalue());
for (canalentry.rowdata rowdata : rowchange.getrowdataslist()) {
if (rowchange.geteventtype() == canalentry.eventtype.update) {
// 更新操作
for (column column : rowdata.getbeforecolumnslist()) {
if ("id".equals(column.getname())) {
long id = long.parselong(column.getvalue());
redis.del("product:" + id);
}
}
}
}
}优势:
// 好的设计 string key = "product:info:" + categoryid + ":" + productid; string key = "user:profile:" + userid; string key = "order:summary:" + datestr; // 避免的设计 string key = "product_" + productid; // 缺少命名空间 string key = getcomplexkey(product); // 复杂计算 string key = "temp:" + system.currenttimemillis(); // 时效性数据
// 序列化配置
@cacheable(value = "products", key = "#id", unless = "#result == null")
public product getproduct(long id) {
return productmapper.findbyid(id);
}
// json 序列化
@configuration
public class redisconfig {
@bean
public redistemplate<string, object> redistemplate(redisconnectionfactory factory) {
redistemplate<string, object> template = new redistemplate<>();
template.setconnectionfactory(factory);
jackson2jsonredisserializer<object> serializer = new jackson2jsonredisserializer<>(object.class);
objectmapper mapper = new objectmapper();
mapper.setvisibility(propertyaccessor.all, jsonautodetect.visibility.any);
mapper.activatedefaulttyping(mapper.getpolymorphictypevalidator());
serializer.setobjectmapper(mapper);
template.setkeyserializer(new stringredisserializer());
template.setvalueserializer(serializer);
template.sethashkeyserializer(new stringredisserializer());
template.sethashvalueserializer(serializer);
return template;
}
}| 数据类型 | 过期时间 | 原因 |
|---|---|---|
| 热点商品 | 24 小时 | 数据相对稳定 |
| 用户会话 | 30 分钟 | 安全性考虑 |
| 排行榜数据 | 5 分钟 | 更新频繁 |
| 配置信息 | 1 小时 | 变更不频繁 |
| 计数器 | 不过期 | 需要持久化 |
// 预估缓存容量
// 假设每秒 10000 次查询,缓存 10000 条数据
// 每条数据 1kb
// 需要的内存 = 10000 * 1kb = 10mb// 实际规划需要预留 20-30% 冗余
// 还需要考虑 redis 本身的内存开销
# 监控指标
- alert: redishighmemoryusage
expr: redis_memory_used_bytes / redis_memory_max_bytes > 0.8
for: 5m
labels:
severity: warning
annotations:
summary: "redis 内存使用率过高"
- alert: redishighhitmissratio
expr: redis_keyspace_hits_total / (redis_keyspace_hits_total + redis_keyspace_misses_total) < 0.8
for: 5m
labels:
severity: warning
annotations:
summary: "redis 缓存命中率过低"// 批量查询
public map<long, product> getproducts(list<long> ids) {
list<string> keys = ids.stream()
.map(id -> "product:" + id)
.collect(collectors.tolist());
list<product> products = redis.mget(keys);
map<long, product> result = new hashmap<>();
for (int i = 0; i < ids.size(); i++) {
if (products.get(i) != null) {
result.put(ids.get(i), products.get(i));
}
}
// 批量回补缓存
result.foreach((id, product) ->
redis.set("product:" + id, product, 3600)
);
return result;
}public void batchwriteproducts(list<product> products) {
redis.executepipelined((rediscallback<object>) connection -> {
for (product product : products) {
string key = "product:" + product.getid();
byte[] value = serializationutils.serialize(product);
connection.setex(key.getbytes(), 3600, value);
}
return null;
});
}@postconstruct
public void warmupcache() {
// 系统启动时预加载热点数据
log.info("start cache warmup...");
list<long> hotproductids = productservice.gethotproductids();
for (long id : hotproductids) {
product product = productmapper.findbyid(id);
redis.set("product:" + id, product, 3600);
}
log.info("cache warmup completed, {} products loaded", hotproductids.size());
}// 错误写法:先更新缓存,再更新数据库
public void updateproduct(product product) {
redis.set("product:" + product.getid(), product); // 先更新缓存
productmapper.update(product); // 后更新数据库
// 并发时可能缓存是旧数据
}
// 正确写法:先删缓存,再更新数据库
public void updateproduct(product product) {
redis.del("product:" + product.getid()); // 先删缓存
productmapper.update(product); // 后更新数据库
}// 错误写法:每次访问都更新缓存
public product getproduct(long id) {
product product = redis.get("product:" + id);
if (product == null) {
product = productmapper.findbyid(id);
}
// 每次都更新,浪费资源
redis.set("product:" + id, product, 3600);
return product;
}
// 正确写法:只在缓存不存在时更新
public product getproduct(long id) {
product product = redis.get("product:" + id);
if (product == null) {
product = productmapper.findbyid(id);
if (product != null) {
redis.set("product:" + id, product, 3600);
}
}
return product;
}// 错误写法:缓存整个列表
public list<product> getallproducts() {
list<product> products = redis.get("all_products");
if (products == null) {
products = productmapper.findall();
redis.set("all_products", products, 300);
}
return products;
}
// 正确写法:分页缓存或使用压缩
public list<product> getproducts(int page, int size) {
string key = "products:" + page + ":" + size;
return redis.get(key);
}旁路缓存是提升系统读取性能的利器,但在实际应用中需要注意:
正确使用旁路缓存,能够将系统性能提升一个数量级,是后端开发必备的核心技能。
到此这篇关于redis 旁路缓存深度解析的文章就介绍到这了,更多相关redis 旁路缓存内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!
您想发表意见!!点此发布评论
版权声明:本文内容由互联网用户贡献,该文观点仅代表作者本人。本站仅提供信息存储服务,不拥有所有权,不承担相关法律责任。 如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 2386932994@qq.com 举报,一经查实将立刻删除。



发表评论