一篇文章带你从入门到精通:RabbitMQ
352人参与 • 2024-05-15 • Erlang
1. 浅浅道来
1.1 什么是中间件?
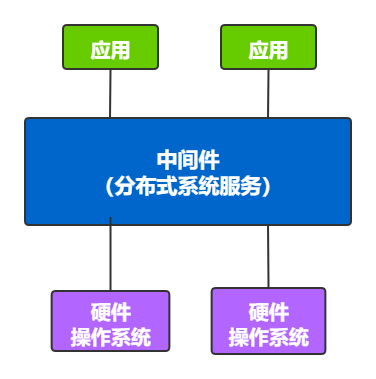
idc(互联网数据中心)的定义:中间件是一种独立的系统软件服务程序,分布式应用软件借助这种软件在不同的技术之间共享资源,中间件位于客户机服务器的操作系统之上,管理计算资源和网络通信。
首先,中间件是某一类软件的总称,而不是某一种具体的软件。它是一种位于平台(操作系统硬件) 和 应用程序之间的通用服务,它屏蔽了底层操作系统的各种复杂性,减轻了开发人员的技术负担,同时它的设计不针对某一具体目标,而是提供具有普遍通用特点的功能模块服务,这些服务具有标准的程序接口和协议,根据平台的不同,也可以有不同的实现。
通俗的例子(仅供参考,并不算完全一致):
我开了一家咖啡店,我身边有 a b c 等 n 家咖啡豆的供应商,但是我肯定要挑选价格又实惠,质量还不错的豆子,但是市场是受到多方面因素波动的,可能我现在的选择,在一段时间后已经不是最佳选项了。所以我专门找到一家市场中介,让他帮我操心这一摊子事情,我只和你说清价格和质量要求,你去找就是了,过程我一点也不操心。这个中介的概念,就类似中间件的
1.1.1 分布式的概念(补充)
这一段,来自我之前写的 dubbo 入门的那篇文章哈
在百度以及维基中的定义都相对专业且晦涩,大部分博客或者教程经常会使用《分布式系统原理和范型》中的定义,即:“分布式系统是若干独立计算机的集合,这些计算机对于用户来说就像是单个相关系统”
下面我们用一些篇幅来通俗的解释一下什么叫做分布式
1.1.1.1 什么是集中式系统
提到分布式,不得不提的就是 “集中式系统”,这个概念最好理解了,它就是将功能,程序等安装在同一台设备上,就由这一台主机设备向外提供服务
举个最简单的例子:你拿一台pc主机,将其改装成了一台简单的服务器,配置好各种内容后,你将mysql,web服务器,ftp,nginx 等等,全部安装在其中,打包部署项目后,就可以对外提供服务了,但是一旦这台机器无论是软件还是硬件出现了问题,整个系统都会受到严重的牵连错误,鸡蛋放在一个篮子里,要打就全打了
1.1.12 什么是分布式系统
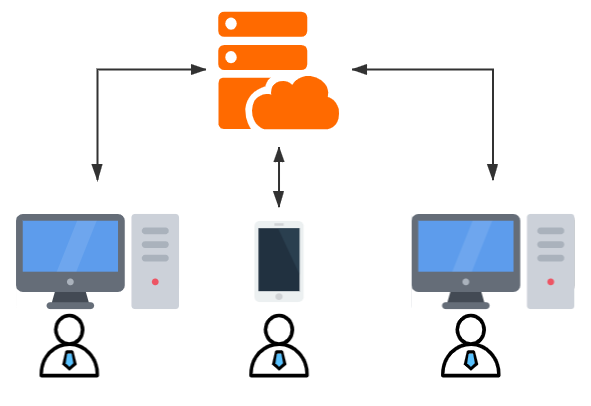
既然集中式系统有这样一种牵一发而动全身的问题,那么分布式的其中一个作用,自然是来解决这样的问题了,正如定义中所知,分布式系统在用户的体验感官里,就像传统的单系统一样,一些变化都是这个系统本身内部进行的,对于用户并没有什么太大的感觉
例如:淘宝,京东这种大型电商平台,它们的主机都是数以万计的,否则根本没法处理大量的数据和请求,具体其中有什么划分,以及操作,我们下面会说到,但是对于用户的我们,我们不需要也不想关心这些,我们仍可以单纯的认为,我们面对的就是 “淘宝” 这一台 “主机”
所以分布式的一个相对专业一些的说法是这样的(进程粒度)两个或者多个程序,分别运行在不同的主机进程上,它们互相配合协调,完成共同的功能,那么这几个程序之间构成的系统就可以叫做分布式系统
这几者都是相同的程序 —— 分布式这几者都是不同的程序 —— 集群

1.2 什么是消息中间件/消息队列(mq)
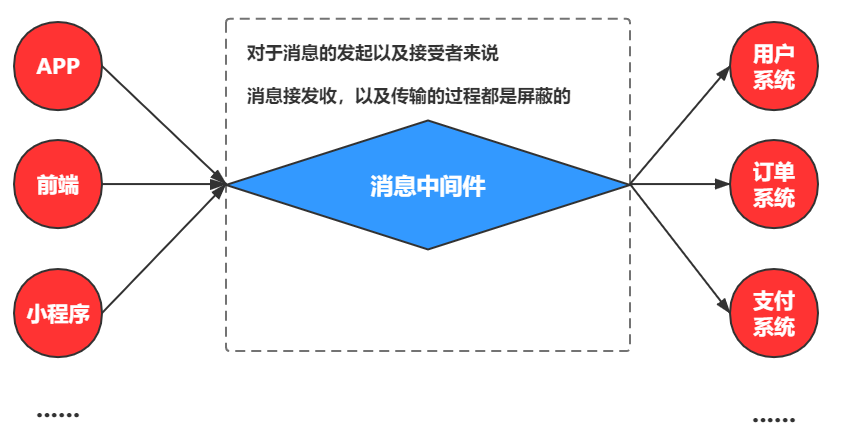
消息中间件,顾名思义就是用来处理消息相关服务的中间件,它提供了一种系统之间通信交互的通道,例如发送方只需要把想传输的信息交给消息中间件,而发送的协议,方式,发送过程中出现的网络,故障等等问题,都由中间件进行处理,因此它负责保证信息的可靠传输。
所以消息中间件,就是一种用来接受数据,存储数据,发送数据的技术,它提供了各种功能,可以实现消息的高可用,高可靠,也提供了很好的容错机制等。可以程序对系统资源的占用,以及传输效率的提升有很大帮助。
常说的 mq 就是指消息队列,即 message quene,常见的消息队列有,经典的 activiemq,热门的 kafka,阿里的 rocketmq 等等,以及这里讲解的 rabbitmq。
不同的 mq 有着不同的特点,以及其更加擅长的方向,倒也说不上谁好谁坏,只有谁更合适。
1.2.1 消息队列应用场景
根据业务的需要,其实它可以有多种应用场景,例如解耦,削峰填谷,广播等,我们举两个场景来梳理一下简单的过程
1.2.1.1 业务解耦
最近在考虑买几本书看,就以买书下订单举例,当我点击购买之后,可能会有这么一串业务逻辑执行,① 减去库存容量 ② 生成订单 ③ 支付 ④ 更新订单状态 ⑤ 发送购买成功短信 ⑥ 更新商品快递揽收状态。在初期阶段,我们完全可以让这些业务同步执行,但是后期为了提升效率,就可以将需要立即执行的任务和可稍缓执行的任务进行分离,例如 ⑤ 发送购买成功短信 ⑥ 更新商品快递揽收状态,都可以考虑异执行。在主流程执行结束后,这些可稍缓的业务可以通过给 mq 发送消息,就判定已经执行,保证流程先结束。然后再通过拉取 mq 消息,或者 mq 主动推送去异步执行其他的业务。
1.2.1.2 削峰填谷
例如发送一条带有已读未读标识的公告信息,所以需要对每一个用户都写一条这样的公告消息,例如存到 mongodb 中,即便 mongodb 也支撑不下来瞬时写入百万、千万记录的情况,所以可以考虑使用消息队列。比如说我们可以在java后端系统上面,用异步多线程的方法,向消息队列mq中发送消息,这样web系统发布公告消息的时候就不占用数据库正常的 crud 操作。系统消息保存在消息队列中,我们只是用它来做削峰填谷,系统消息最终还是要存储在数据库上面。于是我们可以这样设计,在用户登陆系统的时候,用异步线程从消息队列mq中,接收该用户的系统消息,然后把系统消息存储在数据库中,最后消息队列mq中的该条消息自动删除。因为用户的错峰登录,所以往数据库中写入消息的任务也变成了错峰写入。
1.3 什么是 rabbitmq
rabbitmq 是一个使用 erlang 语言编写,且遵循 amqp协议的开源消息队列系统,支持多种客户端(语言),用于在分布式系统中存储消息,转发消息,具有高可用,高可扩性,易用性等特征。
更详细的介绍可以直接看一下官网:https://www.rabbitmq.com/
总之这就是一种常见的消息队列,它的这些特点,都会在后面逐条讲解到,我们首先从入门下载安装部分先说起,然后再到使用。
2. 下载与安装
一般来说,安装的方式有手动安装和 docker 安装,大部分场景下,都会使用 docker 安装,但是作为学习阶段,如果不是特别着急,学习一下手动安装,也不是什么坏事。
注:云服务器和虚拟机都可以,演示的 linux 版本为 centos 7.9
2.1 手动安装
2.1.1 下载安装过程
注:可以在 linux 中通过 yum 直接下载安装,这里选择了在自己的 windows 主机先下载文件,然后再通过 ftp 传到 linux 上,直接安装。可以避免虚拟机上因为网络而造成的一些下载问题。
首先打开官网的下载目录,然后根据自己 linux 的版本,选择版本。
1.地址:https://www.rabbitmq.com/download.html
2.因为 rabbitmq 是 erlang 语言编写的,所以还需要提供 erlang 环境,接着去下载 erlang。
- 地址:https://www.erlang-solutions.com/downloads
- a:此网站访问速度极慢,请耐心等待,或者需要挂上梯子
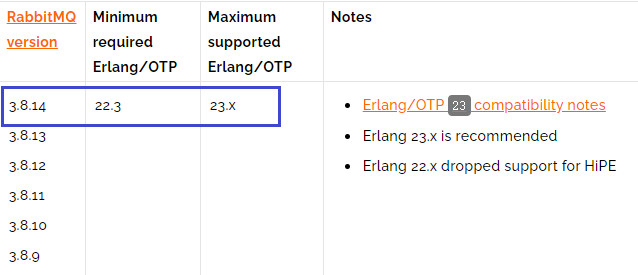
- b:erlang 版本需要与 rabbitmq 匹配(如图,有最大和最小版本的限制)
- 版本查看地址:https://www.rabbitmq.com/which-erlang.html
- 这里选择了 rabbitmq 3.8.14 和 erlang 23.2.3
3.将文件上传到 linux 中(我这里指定位置是 /usr/local/bin/rabbitmq ,可以自己更改选择)
- 现在很多 shell 软件都自带内置的 ftp 上传,例如 finalshell,mobaxterm 等等
- 上传后的文件和目录位置如下
[root@centos7 rabbitmq]# ls esl-erlang_23.2.3-1_centos_7_amd64.rpm rabbitmq-server-3.8.14-1.el7.noarch.rpm [root@centos7 rabbitmq]# pwd /usr/local/bin/rabbitmq
4.安装 erlang 、socat 和 rabbitmq
- erlang 、socat 都是 rabbitmq 所依赖的
# 安装 erlang,安装后执行 erl -v 显示版本号则代表成功 rpm -ivh esl-erlang_23.2.3-1_centos_7_amd64.rpm # 安装 socat 这里没有下载源文件,而是直接通过 yum 在线安装,因为它并不大 yum install -y socat # 安装 rabbitmq rpm -ivh rabbitmq-server-3.8.14-1.el7.noarch.rpm
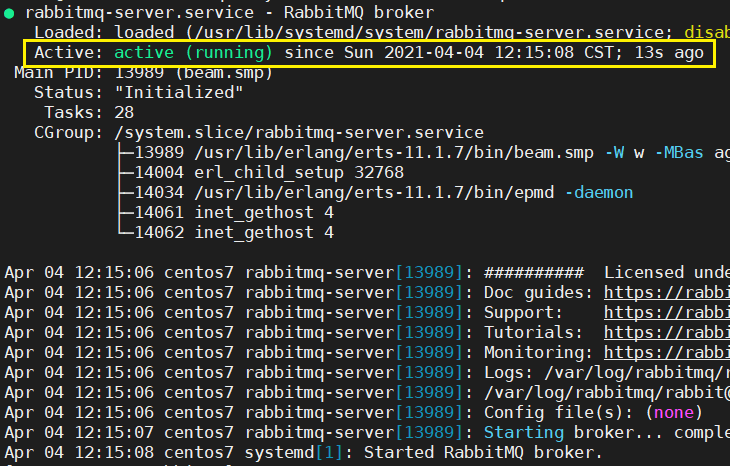
5.安装结束,启动服务查看 rabbitmq 是否可以启动成功
# 启动服务 systemctl start rabbitmq-server # 开机自启 systemctl enable rabbitmq-server # 停止服务 systemctl stop rabbitmq-server # 查看服务状态 systemctl status rabbitmq-server.service
如图所示,即安装启动成功
2.1.2 配置 web 界面管理
上面的安装其实已经结束了,但是 rabbitmq 提供给了我们一个 web 形式的管理界面,默认是没有的,需要进行安装。
1.安装 web 管理插件,然后重启服务
# 安装命令 rabbitmq-plugins enable rabbitmq_management # 重启服务 systemctl restart rabbitmq-server
2.一定要开放 linux 防火墙 的 15672 端口,否则就会无法访问,在学习阶段,你甚至可以去查询命令把防火墙关掉
对应服务器(阿里云,腾讯云等)就是在安全组中开放 15672 端口
访问 linux ip:15672 ,例如 http://192.168.122.1:15672
# 查询 15672 是否开放,一般默认都是 no firewall-cmd --query-port=15672/tcp # 开放指定端口 15672 firewall-cmd --add-port=15672/tcp --permanent # 重新载入 firewall-cmd --reload # 再次查询,结果就是 yes 了 firewall-cmd --query-port=15672/tcp
3.添加远程登录的账户
- rabbitmq 有一个默认账号和密码都是 guest 但是只能在 localhost 下访问
# 新增用户 用户名和密码都是 admin rabbitmqctl add_user admin admin
4.为远程登录的账户添加权限
- administrator(超级管理员):登录控制台、查看所有信息、操作用户、操作策略
- monitoring(监控者): 登录控制台、查看所有信息
- policymaker(策略制定者): 登录控制台、指定策略
- managment(普通管理员): 登录控制台
# 设置用户分配操作权限,admin 用户的权限为 administrator rabbitmqctl set_user_tags admin administrator
5.为用户添加资源权限
- 因为 admin 已经是超级管理员权限了,所以其实不分配资源权限也可以,会默认去做。
# 命令格式为: set_permissions [-p <vhostpath>] <user> <conf> <write> <read> # 这里即为 admin 用户开启 配置文件和读写的权限 rabbitmqctl set_permissions -p / admin ".*"".*"".*"
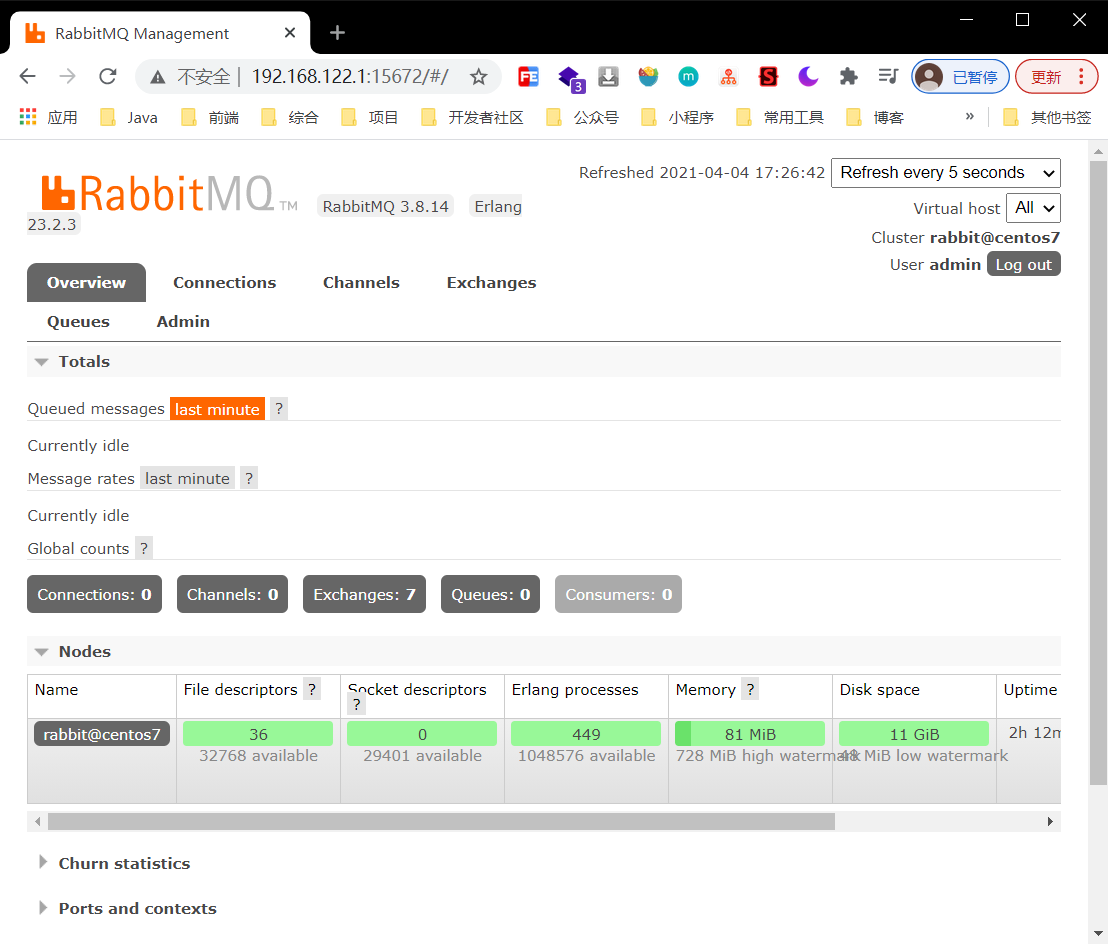
6.访问 linux ip:15672 ,例如 http://192.168.122.1:15672 ,输入刚才设置好的用户名密码 admin
- 如图:访问成功
2.1.2.1 命令小结
1.添加用户:rabbitmqctl add_user <username> <password>
2.修改密码:rabbitmqctl change_password <username> <newpass>
3.删除用户:rabbitmqctl delete_user <username>
4.用户列表:rabbitmqctl list_users
5.设置用户角色:rabbitmqctl set_user_tags <username> <tag1,tag2>
6.删除用户所有角色:rabbitmqctl set_user_tags <username>
7.为用户添加资源权限:set_permissions [-p <vhostpath>] <user> <conf> <write> <read>
使用:输入 rabbitmqctl ,则会提示可能使用的命令,然后 使用 rabbitmqctl hepl <命令> 可以查看具体命令的使用方法和参数。
2.1.3 简单介绍 web 界面管理
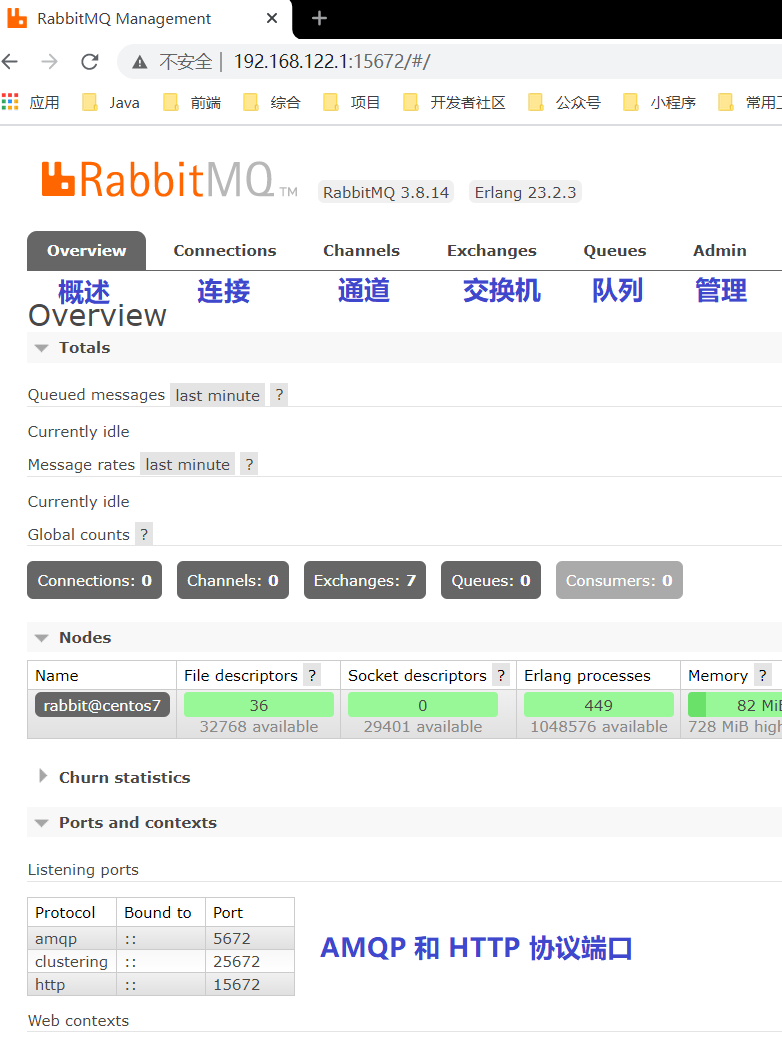
- connections(连接):此处用来管理与
- rabbitmq 建立连接后的生产者和消费者
- channels(通道):连接建立后,会形成通道,消息的投递获取依赖通道。
- exchanges(交换机):用来实现消息的路由
- queues(队列):存放消息的队列,消息等待被消费,消费后被移除队列。
- admin(管理):用于对管理用户,以及对应权限进行设置,如下图所示

tags 就是用来指定用户的角色
- administrator(超级管理员):登录控制台、查看所有信息、操作用户、操作策略
- monitoring(监控者): 登录控制台、查看所有信息
- policymaker(策略制定者): 登录控制台、指定策略
- managment(普通管理员): 登录控制台
2.2 docker 安装
在 docker 中安装 rabbitmq 不需要自己去考虑版本,环境等的各种冲突不兼容问题,是非常便捷的,我演示的这台虚拟机是一个 centos 7.9 裸机,所以我们从更新 yum,到安装 docker 和 安装 rabbitmq 按步骤都讲一下
2.2.1 配置 yum
1.更新 yum 到最新版
# 更新 yum yum update # 检查yum依赖的几个包 yum-utils 提供 yum-config-manager 功能, 后面两个是 devicemapper 用到的 yum install -y yum-utils device-mapper-persistent-data lvm2
2.设置 yum 源为阿里云
yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
2.2.2 安装 docker
2.2.2.1 步骤
1.使用 yum 安装 docker
- docker-ce 是社区版的意思,ee为企业版
yum install docker-ce -y
2.通过查看版本,检查安装是否成功
docker -v
sudo mkdir -p /etc/docker
sudo tee /etc/docker/daemon.json <<-'eof'
{
"registry-mirrors": ["https://<你的id>.mirror.aliyuncs.com"]
}
eof
sudo systemctl daemon-reload
sudo systemctl restart docker
- 国内从 dockerhub 拉取镜像有时会遇到困难,此时可以配置镜像加速器。docker 官方和国内很多云服务商都提供了国内加速器服务,例如:
- 科大镜像:https://docker.mirrors.ustc.edu.cn/
- 网易:https://hub-mirror.c.163.com/
- 阿里云:https://<你的id>.mirror.aliyuncs.com
- 七牛云加速器:https://reg-mirror.qiniu.com
当配置某一个加速器地址之后,若发现拉取不到镜像,请切换到另一个加速器地址。国内各大云服务商均提供了 docker 镜像加速服务,建议根据运行 docker 的云平台选择对应的镜像加速服务。
阿里云镜像获取地址:https://cr.console.aliyun.com/cn-hangzhou/instances/mirrors,登陆后,左侧菜单选中镜像加速器就可以看到你的专属地址了
2.2.2.2 docker 常见命令
2.2.2.2.1 管理命令
- 就启动,停止,重启这些简单的命令使用 service 也是可以的,systemctl 功能稍微强大一些
# 启动 docker systemctl docker start # 停止 docker systemctl docker stop # 重启 docker systemctl docker restart # 查看 docker 状态 systemctl status docker # 开机自启 systemctl enable docker systemctl unenable docker
2.2.2.2.2 镜像命令
# 导入镜像文件 docker load < xxx.tar.gz # 查看安装的镜像 docker images # 删除镜像 docker rmi 镜像名
2.2.3 安装 rabbitmq (任选其一)
注:直接用 2.2.3.2 一句话安装 会更好一些
2.2.3.1 一步一步安装获取
1.rabbitmq 的镜像
docker pull rabbitmq:management
2.创建并运行容器(具体参数在 3 中介绍)
docker run -id --name 容器名 -p 15672:15672 -p 5672:5672 rabbitmq:management
2.2.3.2 一句话安装
上面的安装方式,就是先获取到 rabbitmq 镜像后再开始安装,这里是没有问题的,创建时会有一个问题,因为我们要安装 management 也就是它的 web 管理,如果不做一些处理,默认装好的是没有用户的,所以还需要像前面一样自己进去配置,而 docker hub 已经给出了我们配置的示例,即使用 -e 代表配置,使用 rabbitmq_default_user 和 rabbitmq_default_pass 配置用户名和密码
更多请查看 docker hub 官方给予例子中的 setting default user and password 章节https://registry.hub.docker.com/_/rabbitmq/
1.执行安装
docker run -di --name myrabbitmq -e rabbitmq_default_user=admin -e rabbitmq_default_pass=admin -p 15672:15672 -p 5672:5672 -p 25672:25672 -p 61613:61613 -p 1883:1883 rabbitmq:management
2.通过容器状态,查看是否运行成功
# 查看容器运行状态docker ps -a# 启动docker start 容器名# 停止docker stop 容器名# 退出命令行,不停止exit# 进入到node容器(如果开启了 -t 的情况)docker exec -it 容器名 bash
2.2.3.2.1 参数介绍
下面分别讲解一下这些参数的说明:
-i:表示运行容器。-t:表示为容器保留交互的方式(命令行),即分配一个伪终端。所以常常会见到-it这样的搭配。--name:为容器起个名字。-v:表示目录映射关系(前者是宿主机目录,后者是映射到宿主机上的目录),可以使用多个-v做多个目录或文件映射。注意:推荐做目录映射,在宿主机上做修改,然后共享到容器上。-d:表示创建一个守护式容器在后台运行(这样创建容器后不会自动登录容器,如果只加-i -t两个参数,创建后就会自动进去容器),即后端挂起运行。-p:表示端口映射,前者是宿主机端口,后者是容器内的映射端口。可以使用多个-p做多个端口映射,只有做了端口映射,才能被外界访问。
给大家举个例子:
# 查看容器运行状态 docker ps -a # 启动 docker start 容器名 # 停止 docker stop 容器名 # 退出命令行,不停止 exit # 进入到node容器(如果开启了 -t 的情况) docker exec -it 容器名 bash
因为使用了 -t 这个参数,所以可以分配到一个伪终端,通过 docker exec -it 容器名 bash 进入命令行
-v 目录映射后,进入容器后,也会有一个一模一样的 demo 文件夹,例如在其中可以执行 python 程序
2.2.3.2.1 端口介绍
4369 :erlang发现端口
5672:client端通信端口
15672:管理界面ui端口
25672:server间内部通信端口
61613:不带tls和带tls的stomp客户端
1883:不启用和启用tls的mqtt客户端
比较关键的就是 5672 和 15672
更多端口详情可以访问官网文档https://www.rabbitmq.com/networking.html
注:如果要通过远程连接,例如访问 web 管理页面的 15672 端口,java 客户端连接的 5672 端口, 一定要进行一个开放操作,否则都连接不到。
- 以下为基于 centos 7.9 开放 15672 端口的例子
# 查询 15672 是否开放,一般默认都是 no firewall-cmd --query-port=15672/tcp # 开放指定端口 15672 firewall-cmd --add-port=15672/tcp --permanent # 重新载入 firewall-cmd --reload # 再次查询,结果就是 yes 了 firewall-cmd --query-port=15672/tcp
]以下是关闭防火墙的命令
systemctl disable firewalld systemctl stop firewalld
3. rabbitmq 协议和模型
安装结束后,就要进入主题,即用 java 或者 springboot 代码来实现 rabbitmq的几种方式,但是想要很好的理解这几种路由交换方式,就需要对它的协议和架构模型有所了解。
3.1 协议
3.1.1 什么是协议?
协议,网络协议的简称,网络协议是通信计算机双方必须共同遵从的一组约定。如怎么样建立连接、怎么样互相识别等。只有遵守这个约定,计算机之间才能相互通信交流。它的三要素是:语法、语义、时序。
为了使数据在网络上从源到达目的,网络通信的参与方必须遵循相同的规则,这套规则称为协议(protocol),它最终体现为在网络上传输的数据包的格式。
3.1.1.1 网络协议的三要素
1.语法:数据与控制信息的结构和格式,以及数据出现的顺序。
2.语义:解释控制信息每个部分的意义,以及规定了需要发出何种控制信息以及完成的动作做出何种响应。
3.时序:对事件发生顺序的详细说明。
人们形象地把这三个要素描述为:做什么,怎么做,做的顺序。
举个例子 http 协议
语法:http 规定了请求报文和响应报文的格式
语义:客户端主动发起请求称为请求,服务端随之返回数据,称为响应
时序: 一个请求对应一个响应,而且先有请求后有响应
3.1.1.1.1 面试题:为什么消息中间件不直接使用 http 协议
对于一个消息中间件来说,其主要责任就是负责数据传递,存储,分发,高性能和简洁才是我们所追求的,而 http 请求报文头和响应报文头是比较复杂的,包含了cookie,数据的加密解密,窗台吗,响应码等附加的功能,我们并不需要这么复杂的功能。
同时大部分情况下 http 大部分都是短链接,在实际的交互过程中,一个请求到响应都很有可能会中断,中断以后就不会执行持久化,就会造成请求的丢失。这样就不利于消息中间件的业务场景,因为消息中间件可能是一个长期的获取信息的过程,出现问题和故障要对数据或消息执行持久化等,目的是为了保证消息和数据的高可靠和稳健的运行
3.1.2 rabbitmq 的 amqp 协议
rabbitmq 的使用的协议是 amqp(advanced message queuing protocol),它在2003年时被提出,最早用于解决金融领不同平台之间的消息传递交互问题。
amqp 更准确的说是一种 binary wire-level protocol(链接协议)。这是其和 jms 的本质差别,amqp 不从 api 层进行限定,而是直接定义网络交换的数据格式。这使得实现了amqp的 provider(producer) 天然性就是跨平台的。
相比较其它消息协议,其特性为:
1.分布式事务支持
2.消息的持久化支持
3.高性能和高可靠的消息处理优势
3.1.3 架构模型
想要学习后面的几种消息具体的发送模式,这个模型图就必须理解清楚,因为这几种方式就是对这个模型不同程度的选择和缩减
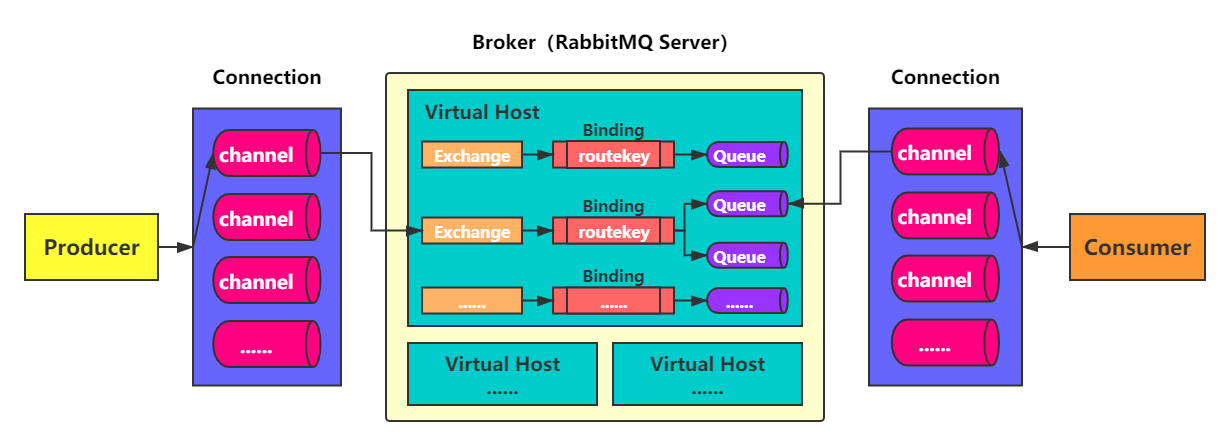
producer:消息的生产者(发送消息的程序)。connection:应用程序与broker之间的网络连接。channel:信道,即信息传输的通道,可以建立多个 channel,每个 channel 代表一个会话任务。- 信道是建立在 tcp 连接内的虚拟连接,信息的读写都通过信道传输,因为对于操纵系统而言,建立和销毁 tcp 是非常昂贵的,所以引入了信道的概念,以复用一条 tcp 连接。
broker(server):标识消息队列服务器实体,例如这里就是 rabbitmq server。virtual host:虚拟主机,一个 broker 中可以设置多个 virtual host,用作不同用户的权限隔离。- broker 可以理解为整个数据库服务,而 virtual host 就是其中每个数据库的感觉,不同项目可以对应不同的数据库,其中有着项目所属的业务表等等。
- 每个 virtual host 中,可以有若干个 exchange 和 queue。
exchange:交换机,用来接收生产者发送的消息,然后将这些消息根据路由键发送到队列。binding:exchange 和 queue 之间的虚拟连接,binding 中可以包括多个 routing key。routing key:路由规则,虚拟机用它来确认如何路由一个特定消息。queue:消息队列,它是消息的容器,用来保存消息,每一条消息都能传入一个或者多个队列中,等待消费者消费,即取出这个消息。consumer:消息的消费者(接收消息的程序)。
4. java 实现 rabbitmq
4.1 环境搭建
官网介绍几种模型:https://www.rabbitmq.com/getstarted.html
截止目前为止,官网一共提供了 7 中模型的介绍,我们主要介绍前五种基本的模式,也有人将 direct 和 topic模式都归入 routing 模式,也可以看做四大种。
4.1.1 创建 java 项目
首先创建好一个不使用骨架的 maven 项目,然后引入 rabbitmq 依赖,还有单元测试依赖即可
<dependency>
<groupid>com.rabbitmq</groupid>
<artifactid>amqp-client</artifactid>
<version>5.10.0</version>
</dependency>
<dependency>
<groupid>junit</groupid>
<artifactid>junit</artifactid>
<version>4.11</version>
</dependency>
4.1.2 创建虚拟主机(可选)
在这里,我们创建了一个新的 virtual hosts,用来为这个java项目服务,大家还可以创建一个新的用户,然后对其开启这个 virtual hosts 的访问权限(即将虚拟主机与用户绑定)。我们这里还是用 admin(我之前创建的一个管理员权限用户) 来演示。
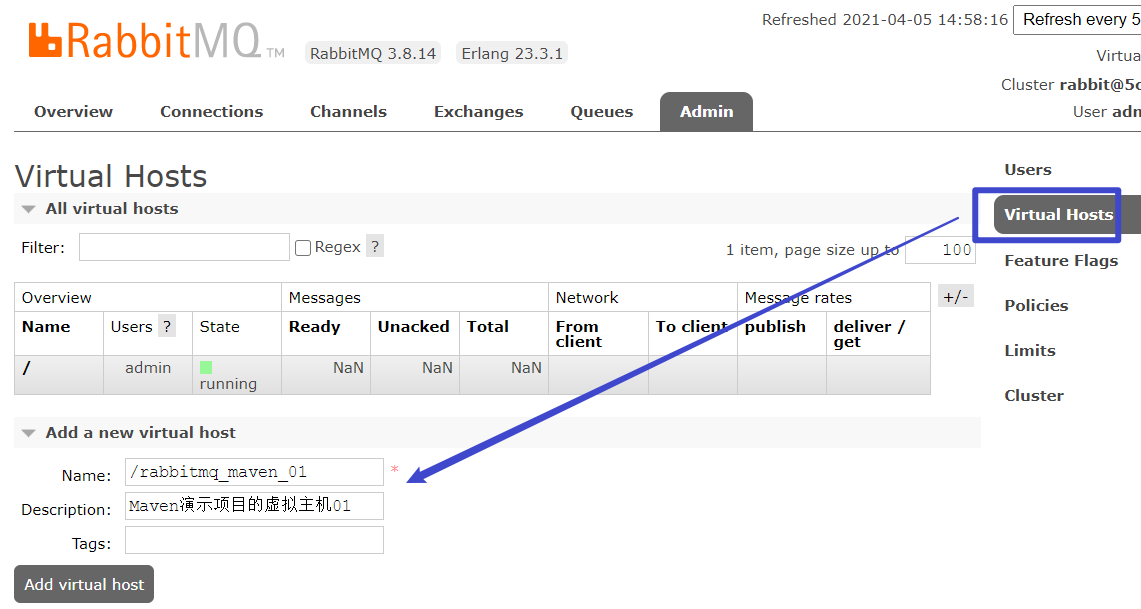
注:这部分不去做也可以,直接用 / 和 admin 用户也行
4.1.3 创建连接工具类
由于我们后面要演示多种例子,而每一次获取连接和释放连接、关闭资源等操作代码都是一致的,为了防止代码冗余,优化代码,更易理解,提取出一个工具类,这样大家将重心放在不同实现方式的对比上就行了。
- rabbitmqutil 工具类
- properties
public class rabbitmqutil {
/**
* 主机名 即 linux ip地址
*/
private static string host = "";
/**
* 端口号 客户端访问默认都是 5672
*/
private static int port = 0;
/**
* 虚拟主机 可以设置为默认的 / 或者自己创建出指定的虚拟主机
*/
private static string virtualhost = "";
/**
* 用户名
*/
private static string username = "";
/**
* 密码
*/
private static string password = "";
// 使用静态代码块为properties对象赋值
static {
try {
//实例化对象
properties properties = new properties();
//获取properties文件的流对象
inputstream in = rabbitmqutil.class.getclassloader().getresourceasstream("rabbitmq.properties");
properties.load(in);
// 分别获取 value
host = properties.getproperty("host");
port = integer.parseint(properties.getproperty("port"));
virtualhost = properties.getproperty("virtualhost");
username = properties.getproperty("username");
password = properties.getproperty("password");
} catch (exception e) {
e.printstacktrace();
}
}
/**
* 获取连接
*
* @return 连接
*/
public static connection getconnection() {
try {
// 创建连接工厂
connectionfactory connectionfactory = new connectionfactory();
// 设置连接 rabbitmq 主机
connectionfactory.sethost(host);
// 设置端口号
connectionfactory.setport(port);
// 设置连接的虚拟主机(数据库的感觉)
connectionfactory.setvirtualhost(virtualhost);
// 设置访问虚拟主机的用户名和密码
connectionfactory.setusername(username);
connectionfactory.setpassword(password);
// 返回一个新连接
return connectionfactory.newconnection();
} catch (exception e) {
e.printstacktrace();
}
return null;
}
/**
* 关闭通道和释放连接
*
* @param channel channel
* @param connection connection
*/
public static void close(channel channel, connection connection) {
try {
if (channel != null) {
channel.close();
}
if (connection != null) {
connection.close();
}
} catch (exception e) {
e.printstacktrace();
}
}
}
host=192.168.122.1 port=5672 virtualhost=/rabbitmq_maven_01 username=admin password=adminv
4.2 五种实现方式
说明:
- 队列名,消息等等字符串内容,更推荐定义成变量传入,我文中都是直接写在参数中的,这种魔法值的写法,并不是很优美。
- 生产者中使用了 junit 单元测试,但是消费者中却在 main 函数中编写,这是因为,我们希望消费者处于一个持续运行等待的状态,如果使用 junit 会导致,程序在执行一次后结束掉.
- 除了在 main 函数中编写,还可以考虑使用 sleep 等待或者 while(true) 让程序不要直接终止掉。
4.2.1 简单队列模式(hello word)
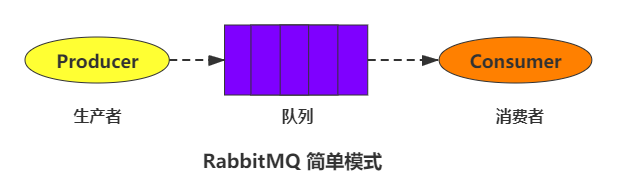
producer:消息的生产者(发送消息的程序)。queue:消息队列,理解为一个容器,生产者向它发送消息,它把消息存储,等待消费者消费。consumer:消息的消费者(接收消息的程序)。
4.2.1.1 如何理解
由图所示,简单队列模式,一个生产者,经过一个队列,对应一个消费者。可以看做是点对点的一种传输方式,相较与 3.1.3 中的模型图,最主要的特点就是看不到 exchange(交换机) 和 routekey(路由键) ,正是因为这种模式简单,所以并不会涉及到复杂的条件分发等等,因此也不需要用户去显式的考虑交换机和路由键的问题。
- 但是要注意,这种模式并不是生产者直接对接队列,而是用了默认的交换机,默认的交换机会把消息发送到和 routekey 名称相同的队列中去,这也是我们在后面代码中在 routekey 位置填写了队列名称的原因
4.2.1.2 代码实现
4.2.1.2.1 生产者代码
public class producer {
@test
public void sendmessage() throws ioexception, timeoutexception {
// 通过工具类获取连接
connection connection = rabbitmqutil.getconnection();
// 获取连接通道
channel channel = connection.createchannel();
// 通道绑定消息队列
channel.queuedeclare("queue1",false,false,false,null);
// 发布消息
channel.basicpublish("","queue1",null,"this is rabbitmq message 001 !".getbytes());
// 通过工具关闭channel和释放连接
rabbitmqutil.close(channel,connection);
}
}public class producer {
@test
public void sendmessage() throws ioexception, timeoutexception {
// 通过工具类获取连接
connection connection = rabbitmqutil.getconnection();
// 获取连接通道
channel channel = connection.createchannel();
// 通道绑定消息队列
channel.queuedeclare("queue1",false,false,false,null);
// 发布消息
channel.basicpublish("","queue1",null,"this is rabbitmq message 001 !".getbytes());
// 通过工具关闭channel和释放连接
rabbitmqutil.close(channel,connection);
}
}
1.通过工具类获取连接
2.获取连接通道:根据 3.1.3 的模型图可知,生产者需要在获取到连接后,再获取信道,才能去访问后面的交换机队列等。
3.通道绑定消息队列:绑定队列前,应该绑定交换机,但是此模式中隐蔽了交换机的概念,背后使用了默认的交换机,所以直接绑定队列。
- queuedeclare 方法解释
- 参数1:queue(队列名称),如果队列不存在,则自动创建。
- 参数2:durable(队列是否持久化),持久化可以保证服务器重启后此队列仍然存在。
- 参数3:exclusive(排他队列)即是否独占队列,如果此项为 true,该队列仅对首次申明它的连接可见,并在连接断开时自动删除。
- 参数4:autodelete(自动删除),最后一个消费者将消息消费完毕后,自动删除队列。
- 参数5:arguments(携带附加属性)。
4.发布消息:此处可以指定消息队列的发送方法,以及内容等,因为此模式比较简单,所以没有涉及到全部参数,后面的模式会有详细的讲解
- basicpublish 方法解释
- 参数1:exchange(交换机名称)。
- 参数2:routingkey(路由key),此处填写队列名,可理解为把消息发送到和 routekey 名称相同的队列中去。
- 参数3:props(消息的控制状态),可以在此处控制消息的持久化。参数为:messageproperties.persistent_text_plain参数4:body(消息主体),类型是一个字节数组,要转一下类型。
5.通过工具关闭channel和释放连接:先关闭通道,再释放连接。
4.2.1.2.2 消费者代码
public class consumer {
public static void main(string[] args) throws ioexception, timeoutexception{
// 通过工具类获取连接
connection connection = rabbitmqutil.getconnection();
// 获取连接通道
channel channel = connection.createchannel();
// 通道绑定消息队列
channel.queuedeclare("queue1", false, false, false, null);
// 消费消息
channel.basicconsume("queue1", true, new defaultconsumer(channel) {
@override
public void handledelivery(string consumertag, envelope envelope, amqp.basicproperties properties, byte[] body) throws ioexception {
system.out.println("new string(body): " + new string(body));
}
});
}
}
1.通过工具类获取连接
2.获取连接通道
3.通道绑定消息队列
4.消费消息:此处用来指定消费哪个队列的消息,以及一些机制和回调
- basicconsume 方法解释
- 参数1:queue(队列名称),即消费哪个队列的消息 。
- 参数2:autoack(自动应答)开始消息的自动确认机制,只要消费了就从队列删除消息。
- 参数3:callback(消费时的回调接口),callback 的类型是 consumer 这里使用了 defaultconsumer 就是 consumer 的一个实现类。其中重写 handledelivery 方法,就可以获取到消费的数据内容了,这里主要使用了其中的 body,即查看消息主体,其他三个参数暂时还没用到,有兴趣可以先打印输出一下,能先有个大概的了解。4.2.2 工作队列模式(work queue)
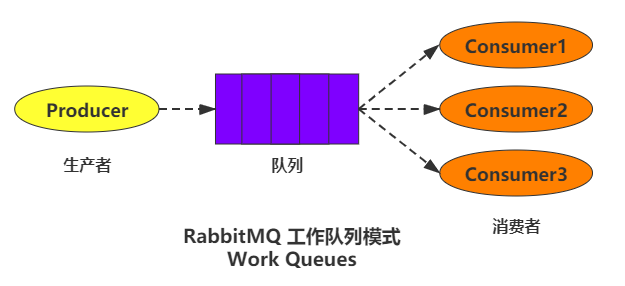
producer:消息的生产者(发送消息的程序)。queue:消息队列,理解为一个容器,生产者向它发送消息,它把消息存储,等待消费者消费。- consumer:消息的消费者(接收消息的程序)。
- 此处我们假设 consumer1、consumer2、consumer3 分别为完成任务速度不一样快的消费者,这会引出此模式的一个重点问题。
4.2.2.1 如何理解
工作模式由图可以看出,就是在简单队列模式的基础上,增加了多个消费者,也就是让多个消费者绑定同一个队列,共同去消费,这样能解决简单队列模式中,如果生产速速远大于消费速度,而导致的消息堆积现象。
- 因为消息被消费后就会消失,所以不必担心任务会重复执行。
4.2.2.2 代码实现
注:工作队列模式有两种
轮询模式:每个消费者均分消息公平分发模式(能者多劳):按能力分发,处理速度快的分发的多,处理速度慢的分发的少
我们首先演示的是轮询模式,根据它的缺点,又能引出公平分发模式
下面只描述与上面有差异的部分,在简单模式中,这些基本的方法都有介绍过
4.2.2.2.1 轮询模式-生产者代码
public class producer {
@test
public void sendmessage() throws ioexception, timeoutexception {
// 通过工具类获取连接
connection connection = rabbitmqutil.getconnection();
// 获取连接通道
channel channel = connection.createchannel();
// 通道绑定消息队列
channel.queuedeclare("work", true, false, false, null);
for (int i = 1; i <= 20; i++) {
// 发布消息
channel.basicpublish("", "work", null, (i + "号消息").getbytes());
}
// 通过工具关闭channel和释放连接
rabbitmqutil.close(channel, connection);
}
}
流程和简单队列模式基本一致,有一些小小的改动,生产者中主要就是加了层循环,因为有多个消费者,所以多发送一些消息,可以看出一些特点和问题。
4.2.2.2.2 轮询模式-消费者代码
消费者 1
public class consumer1 {
public static void main(string[] args) throws ioexception {
// 通过工具类获取连接
connection connection = rabbitmqutil.getconnection();
// 获取连接通道
final channel channel = connection.createchannel();
// 通道绑定消息队列
channel.queuedeclare("work", true, false, false, null);
// 消费消息
channel.basicconsume("work", true, new defaultconsumer(channel) {
@override
public void handledelivery(string consumertag, envelope envelope, amqp.basicproperties properties, byte[] body) throws ioexception {
try {
thread.sleep(2000);
} catch (interruptedexception e) {
e.printstacktrace();
}
system.out.println("消费者1号:消费-" + new string(body));
}
});
}
}
消费者 2
public class consumer2 {
public static void main(string[] args) throws ioexception {
// 通过工具类获取连接
connection connection = rabbitmqutil.getconnection();
// 获取连接通道
final channel channel = connection.createchannel();
// 通道绑定消息队列
channel.queuedeclare("work", true, false, false, null);
// 消费消息
channel.basicconsume("work", true, new defaultconsumer(channel) {
@override
public void handledelivery(string consumertag, envelope envelope, amqp.basicproperties properties, byte[] body) throws ioexception {
system.out.println("消费者2号:消费-" + new string(body));
}
});
}
上述两个消费者都在 basicconsume中开启了自动 ack 应答,这一点下面会详述,同时在消费者 1 中,增加了 sleep 2s 的语句,模拟消费者1处理消息速度慢,而消费者2处理消息速度快的场景。
运行结果:
consumer1
消费者1号:消费-1号消息
消费者1号:消费-3号消息
消费者1号:消费-5号消息
消费者1号:消费-7号消息
消费者1号:消费-9号消息
消费者1号:消费-11号消息
消费者1号:消费-13号消息
消费者1号:消费-15号消息
消费者1号:消费-17号消息
消费者1号:消费-19号消息
consumer2
消费者2号:消费-2号消息
消费者2号:消费-4号消息
消费者2号:消费-6号消息
消费者2号:消费-8号消息
消费者2号:消费-10号消息
消费者2号:消费-12号消息
消费者2号:消费-14号消息
消费者2号:消费-16号消息
消费者2号:消费-18号消息
消费者2号:消费-20号消息
观察执行过程:发现两个消费者虽然每个人最后都各自处理了一半的消息,而且是按照一人一条分配的,但是消费者2号处理速度快,一下子就全部处理完了,但是消费者1号,每一次处理都需要 2s 所以,只能缓慢的处理,而消费者2号就处于一个空闲浪费的情况了。
如何切换为公平分发模式呢?
这就和 basicconsume 中的第二个参数,开启自动确认消费有关了,它默认是 true,也就代表只要一旦拿到队列中分发给这个消费者的消息,我就会自动返回一个确认消费的标识,队列收到后就会自动删除掉队列中的消息。
- 但是这其中有一个很重要的问题,这种方式就是将风险交给了消费者,例如消费者收到了自己需要处理的 10 条消息,刚消费了 4 个,消费者宕机,挂掉了,后面的 6 个消息就丢失了。
如果想要修改为按能力分配的方式,有两个要点
1.设置通道一次只能消费一个消息
2.关闭消息的自动确认,手动确认消息
4.2.2.2.3 公平分发模式-生产者代码
public class producer {
@test
public void sendmessage() throws ioexception, timeoutexception {
// 通过工具类获取连接
connection connection = rabbitmqutil.getconnection();
// 获取连接通道
channel channel = connection.createchannel();
// 一次只发送一条消息
channel.basicqos(1);
// 通道绑定消息队列
channel.queuedeclare("work", true, false, false, null);
for (int i = 1; i <= 20; i++) {
// 发布消息
channel.basicpublish("", "work", null, (i + "号消息").getbytes());
}
// 通过工具关闭channel和释放连接
rabbitmqutil.close(channel, connection);
}
4.2.2.2.4 公平分发模式-消费者代码
消费者1
public class consumer1 {
public static void main(string[] args) throws ioexception {
// 通过工具类获取连接
connection connection = rabbitmqutil.getconnection();
// 获取连接通道
final channel channel = connection.createchannel();
// 一次只接受一条未确认的消息
channel.basicqos(1);
// 通道绑定消息队列
channel.queuedeclare("work", true, false, false, null);
// 消费消息
channel.basicconsume("work", false, new defaultconsumer(channel) {
@override
public void handledelivery(string consumertag, envelope envelope, amqp.basicproperties properties, byte[] body) throws ioexception {
try {
thread.sleep(2000);
} catch (interruptedexception e) {
e.printstacktrace();
}
system.out.println("消费者1号:消费-" + new string(body));
// 返回 deliverytag 代表队列可以删除此消息了
channel.basicack(envelope.getdeliverytag(), false);
}
});
}
}
消费者2
public class consumer2 {
public static void main(string[] args) throws ioexception {
// 通过工具类获取连接
connection connection = rabbitmqutil.getconnection();
// 获取连接通道
final channel channel = connection.createchannel();
//步骤一:一次只接受一条未确认的消息
channel.basicqos(1);
// 通道绑定消息队列
channel.queuedeclare("work", true, false, false, null);
// 消费消息
channel.basicconsume("work", false, new defaultconsumer(channel) {
@override
public void handledelivery(string consumertag, envelope envelope, amqp.basicproperties properties, byte[] body) throws ioexception {
system.out.println("消费者2号:消费-" + new string(body));
channel.basicack(envelope.getdeliverytag(), false);
}
});
}
public class consumer2 {
public static void main(string[] args) throws ioexception {
// 通过工具类获取连接
connection connection = rabbitmqutil.getconnection();
// 获取连接通道
final channel channel = connection.createchannel();
//步骤一:一次只接受一条未确认的消息
channel.basicqos(1);
// 通道绑定消息队列
channel.queuedeclare("work", true, false, false, null);
// 消费消息
channel.basicconsume("work", false, new defaultconsumer(channel) {
@override
public void handledelivery(string consumertag, envelope envelope, amqp.basicproperties properties, byte[] body) throws ioexception {
system.out.println("消费者2号:消费-" + new string(body));
channel.basicack(envelope.getdeliverytag(), false);
}
});
}
运行结果:
consumer1
消费者1号:消费-1号消息
consumer2
消费者2号:消费-2号消息
消费者2号:消费-3号消息
消费者2号:消费-4号消息
消费者2号:消费-5号消息
消费者2号:消费-6号消息
消费者2号:消费-7号消息
消费者2号:消费-8号消息
消费者2号:消费-9号消息
消费者2号:消费-10号消息
消费者2号:消费-11号消息
消费者2号:消费-12号消息
消费者2号:消费-13号消息
消费者2号:消费-14号消息
消费者2号:消费-15号消息
消费者2号:消费-16号消息
消费者2号:消费-17号消息
消费者2号:消费-18号消息
消费者2号:消费-19号消息
消费者2号:消费-20号消息
4.2.3 发布与订阅模式(fanout 广播)
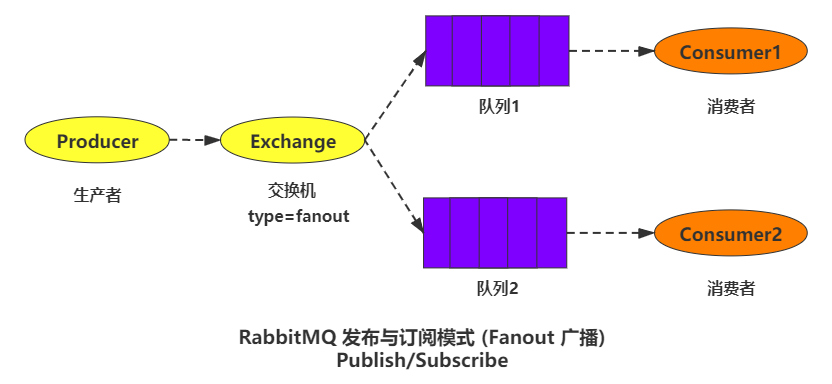
producer:消息的生产者(发送消息的程序)。exchange:交换机,负责发送消息给指定队列。queue:消息队列,理解为一个容器,生产者向它发送消息,它把消息存储,等待消费者消费。consumer:消息的消费者(接收消息的程序)。
4.2.3.1 如何理解
fanout 直译为 “扇出” 但是大家更多的会把它叫做广播或者发布与订阅,它是一种没有路由key的模式,生产者将消息发送给交换机,交换机会把所有消息复制同步到所有与它绑定过的队列上,而每个队列只能有一个消费者拿到这条消息,如果在一个消费者连接中,创建多个通道,则会出现争抢消息的结果。
4.2.3.2 代码实现
注:下面只描述与上面有差异的部分,在简单模式中,这些基本的方法都有介绍过
4.2.3.2.1 生产者代码
public class producer {
@test
public void sendmessage() throws ioexception, timeoutexception {
// 通过工具类获取连接
connection connection = rabbitmqutil.getconnection();
// 获取连接通道
final channel channel = connection.createchannel();
// 声明交换机
channel.exchangedeclare("order", "fanout");
for (int i = 1; i <= 20; i++) {
// 发布消息
channel.basicpublish("order", "", null, "fanout!".getbytes());
}
// 通过工具关闭channel和释放连接
rabbitmqutil.close(channel, connection);
}
}
1.声明交换机
- exchangedeclare 方法解释
- 参数1:exchange(交换机名称),如果交换机不存在,则自动创建
- 参数2:type(类型),此处选择 fanout 模式
2.发布消息:在 basicpublish 方法的第一个参数中输入上述定义好的交换机的名字,第二个参数,路由键为空
- 循环 20 条是为了演示消费者
4.2.3.2.2 消费者代码
public class consumer1 {
public static void main(string[] args) throws ioexception {
// 通过工具类获取连接
connection connection = rabbitmqutil.getconnection();
channel channel = connection.createchannel();
// 声明交换机
channel.exchangedeclare("order", "fanout");
// 创建临时队列
string queue = channel.queuedeclare().getqueue();
// 绑定临时队列和交换机
channel.queuebind(queue, "order", "");
// 消费消息
channel.basicconsume(queue, true, new defaultconsumer(channel) {
@override
public void handledelivery(string consumertag, envelope envelope, amqp.basicproperties properties, byte[] body) throws ioexception {
system.out.println("消费者1号:消费-" + new string(body));
}
});
}
}
1.声明交换机
2.创建临时队列
3..绑定临时队列和交换机
- queuebind 方法解释
- 参数1:queue(临时队列)
- 参数2:exchange(交换机)
- 参数3:routingkey(路由key)
- 消费者2:演示了一个连接中,多个通道的情况
public class consumer2 {
public static void main(string[] args) throws ioexception {
// 通过工具类获取连接
connection connection = rabbitmqutil.getconnection();
// 获取连接通道
channel channel = connection.createchannel();
channel channel2 = connection.createchannel();
// 声明交换机
channel.exchangedeclare("order", "fanout");
channel2.exchangedeclare("order", "fanout");
// 创建临时队列
string queue = channel.queuedeclare().getqueue();
system.out.println(queue);
// 绑定临时队列和交换机
channel.queuebind(queue, "order", "");
channel2.queuebind(queue, "order", "");
// 消费消息
channel.basicconsume(queue, true, new defaultconsumer(channel) {
@override
public void handledelivery(string consumertag, envelope envelope, amqp.basicproperties properties, byte[] body) throws ioexception {
system.out.println("消费者2号:消费-" + new string(body));
}
});
// 消费消息
channel2.basicconsume(queue, true, new defaultconsumer(channel2) {
@override
public void handledelivery(string consumertag, envelope envelope, amqp.basicproperties properties, byte[] body) throws ioexception {
system.out.println("消费者2-2号:消费-" + new string(body));
}
});
}
}
运行结果:
消费者2号:消费-2号消息
消费者2号:消费-3号消息
消费者2号:消费-4号消息
消费者2号:消费-5号消息
消费者2号:消费-6号消息
消费者2号:消费-7号消息
消费者2号:消费-8号消息
消费者2号:消费-9号消息
消费者2号:消费-10号消息
消费者2号:消费-11号消息
消费者2号:消费-12号消息
消费者2号:消费-13号消息
消费者2号:消费-14号消息
消费者2号:消费-15号消息
消费者2号:消费-16号消息
消费者2号:消费-17号消息
消费者2号:消费-18号消息
消费者2号:消费-19号消息
消费者2号:消费-20号消息
4.2.3.2.3 为什么消费者中也声明交换机?
从上面的代码中可以看出,在 producer 和 conusmer 中我们都分别声明了交换机,但是消费者由图可知,并不会与交换机有直接的接触,为什么消费者中也声明交换机呢?
这是为了保证 producer 或者 producer 执行的时候,永远不会因为交换机还没被声明而出错,例如你只在 producer 声明了交换机,那么你就必须先启动 producer ,如果直接执行 conusmer 此时交换机就还不存在,就会报错。而全部写入声明,则可以保证不论先启动谁,都会声明到交换机。
4.2.4 路由模式( routing / direct)
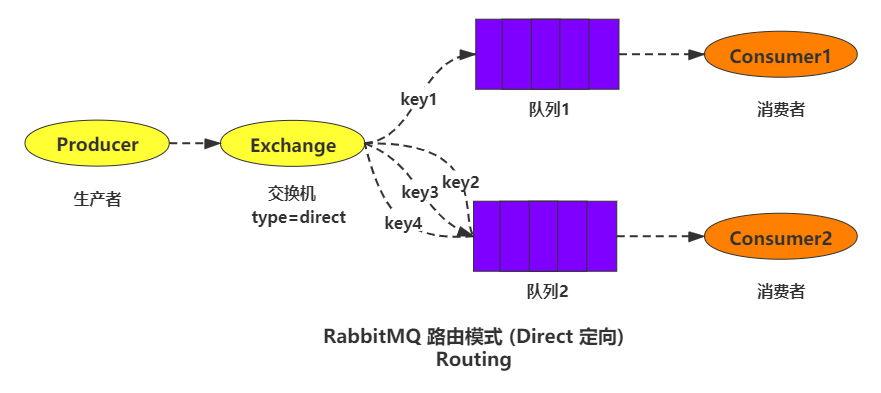
producer:消息的生产者(发送消息的程序)。exchange:交换机,负责发送消息给指定队列。routingkey:路由key,即上图的 key1,key2 等,相当于在交换机和队列之间又加了一层限制queue:消息队列,理解为一个容器,生产者向它发送消息,它把消息存储,等待消费者消费。consumer:消息的消费者(接收消息的程序)。
4.2.4.1 如何理解
路由模式的交换机类型是 direct,与 fanout 模式相比,多了路由 key 这个概念。生产者发送携带指定 routingkey(路由key) 的消息到交换机,交换机拿着此 routingkey 去找到绑定了这个 routingkey 的队列,然后发送到此队列,一个队列可以绑定多个 routingkey 。
4.2.4.2 代码实现
4.2.4.2.1 生产者代码
public class producer {
@test
public void sendmessage() throws ioexception, timeoutexception {
// 通过工具类获取连接
connection connection = rabbitmqutil.getconnection();
// 获取连接通道
channel channel = connection.createchannel();
// 声明交换机
channel.exchangedeclare("order_direct", "direct");
// 指定 routingkey
string key = "info";
// 发布消息
channel.basicpublish("order_direct", key, null, ("发送给指定路由" + key + "的消息").getbytes());
// 通过工具关闭channel和释放连接
rabbitmqutil.close(channel, connection);
}
}
1.指定 routingkey ,即在 basicpublish 方法 的第二个参数中,指定 key 的值
4.2.4.2.2 消费者代码
- 消费者 1
public class consumer1 {
public static void main(string[] args) throws ioexception {
// 通过工具类获取连接
connection connection = rabbitmqutil.getconnection();
channel channel = connection.createchannel();
// 声明交换机
channel.exchangedeclare("order_direct", "direct");
// 获取临时队列
string queue = channel.queuedeclare().getqueue();
// 绑定临时队列和交换机
channel.queuebind(queue, "order_direct", "info");
channel.queuebind(queue, "order_direct", "error");
channel.queuebind(queue, "order_direct", "warn");
// 消费消息
channel.basicconsume(queue, true, new defaultconsumer(channel) {
@override
public void handledelivery(string consumertag, envelope envelope, amqp.basicproperties properties, byte[] body) throws ioexception {
system.out.println("消费者1:消费-" + new string(body));
}
});
}
}
1.只是在绑定队列和交换机的时候,增加了 key 这个值
- 消费者2
public class consumer2 {
public static void main(string[] args) throws ioexception {
// 通过工具类获取连接
connection connection = rabbitmqutil.getconnection();
channel channel = connection.createchannel();
// 声明交换机
channel.exchangedeclare("order_direct", "direct");
// 获取临时队列
string queue = channel.queuedeclare().getqueue();
// 绑定临时队列和交换机
channel.queuebind(queue, "order_direct", "error");
// 消费消息
channel.basicconsume(queue, true, new defaultconsumer(channel) {
@override
public void handledelivery(string consumertag, envelope envelope, amqp.basicproperties properties, byte[] body) throws ioexception {
system.out.println("消费者2:消费-" + new string(body));
}
});
}
}
运行结果:只有消费者 1 收到了消息
[code]消费者1:消费-发送给指定路由info的消息
4.2.5 通配符匹配模式(topic)
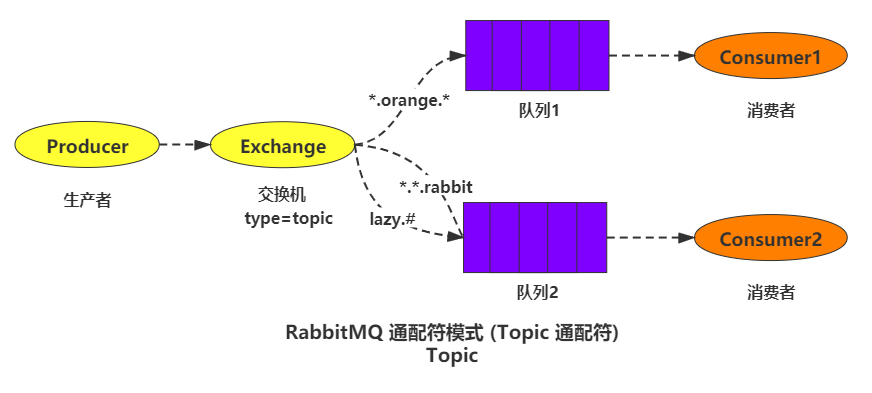
producer:消息的生产者(发送消息的程序)。exchange:交换机,负责发送消息给指定队列。routingkey:路由key,即上图的 key1,key2 等,相当于在交换机和队列之间又加了一层限制但是 topic 中的 key 为通配符的形式,这样可以大大的提高效率queue:消息队列,理解为一个容器,生产者向它发送消息,它把消息存储,等待消费者消费。consumer:消息的消费者(接收消息的程序)。
4.2.5.1 如何理解
通配符匹配模式的交换机类型为 topic,因为它与 direct 模式很相似,所以大家有时候也会把 direct 模式和 topic 共同归入路由模式下,它们的区别就是,direct 模式的 routingkey 是一个指定的值,而 topic 模式的 routingkey 可以使用通配符, 而且一般都是由一个或多个单词组成,多个单词之间以”.”分割,例如: ideal.insert。
*:匹配正好一个词,例如:order.*可以匹配到 order.insert#:匹配一个或者多个词,例如:order.#可以匹配到 order.insert.common#就像一个多层的概念,而*只是一个单层的概念
4.2.5.2 代码实现
4.2.5.2.1 生产者代码
public class producer {
@test
public void sendmessage() throws ioexception, timeoutexception {
// 通过工具类获取连接
connection connection = rabbitmqutil.getconnection();
// 获取连接通道
channel channel = connection.createchannel();
channel.exchangedeclare("order_topic", "topic");
// 声明交换机
string key = "user.query.all";
// 发布消息
channel.basicpublish("order_topic", key, null, ("发送给指定路由" + key + "的消息").getbytes());
rabbitmqutil.close(channel, connection);
}
}
4.2.5.2.2 消费者代码
- 消费者1
public class producer {
@test
public void sendmessage() throws ioexception, timeoutexception {
// 通过工具类获取连接
connection connection = rabbitmqutil.getconnection();
// 获取连接通道
channel channel = connection.createchannel();
channel.exchangedeclare("order_topic", "topic");
// 声明交换机
string key = "user.query.all";
// 发布消息
channel.basicpublish("order_topic", key, null, ("发送给指定路由" + key + "的消息").getbytes());
rabbitmqutil.close(channel, connection);
}
}
消费者2
public class producer {
@test
public void sendmessage() throws ioexception, timeoutexception {
// 通过工具类获取连接
connection connection = rabbitmqutil.getconnection();
// 获取连接通道
channel channel = connection.createchannel();
channel.exchangedeclare("order_topic", "topic");
// 声明交换机
string key = "user.query.all";
// 发布消息
channel.basicpublish("order_topic", key, null, ("发送给指定路由" + key + "的消息").getbytes());
rabbitmqutil.close(channel, connection);
}
}
运行结果:只有消费者 2 收到了消息,因为消息是一个多层的结构,只有 user.# 能匹配到
消费者2:消费-发送给指定路由user.query.all的消息
5. springboot 实现 rabbitmq
springboot 提供 spring for rabbitmq 的启动器,同时提供了一系列注解以及 rabbittemplate 供我们使用,能够极大的简化开发 rabbitmq 的步骤,下面分别演示了【5.1 基于纯注解】 以及【 5.2 基于注解 + 配置类】 的写法,其使用方式大同小异,只是声明和绑定队列交换机等的位置不同。一般认为后者更好维护管理,任选其一即可。
环境准备:
1.首先创建 sprinboot 项目,然后选择 rabbitmq 的启动器,以及单元测试等基本启动器
2.编写 yml 配置文件,编写连接 rabbitmq 需要的数据
rabbitmq 依赖
<dependency> <groupid>org.springframework.boot</groupid> <artifactid>spring-boot-starter-amqp</artifactid> </dependency>
yml 配置文件
spring:
rabbitmq:
host: 192.168.122.1 # 服务器地址
port: 5672 # tcp端口
username: admin # 用户名
password: admin # 用户密码
virtual-host: /rabbitmq_springboot_01 # 虚拟主机
5.1 基于纯注解
注:此方式没有创建配置类来管理队列以及交换机的声明和绑定等,而是全部通过注解的方式直接在消费者中写入
5.1.1 简单队列模式
所有生产消息的代码,我们都放到 test 中去做
- 生产者
@springboottest(classes = rabbitmqspringbootapplication.class)
@runwith(springrunner.class)
public class rabbitmqtest {
/**
* 注入 rabbittemplate
*/
@autowired
private rabbittemplate rabbittemplate;
@test
public void testsimplesendmessage() {
rabbittemplate.convertandsend("simple_queue", "this is a message !");
}
}
第一步就是注入 springboot 提供给我们的 rabbittemplate
通过 rabbittemplate 的 convertandsend 方法用来发送消息,他有多种重载方式,今天分别会用到 2 个 和 3 个参数的
- convertandsend 方法详解(两个参数)
- 参数1:routingkey(路由key)
- 参数2:object(发送的消息正文)
- convertandsend 方法详解(三个参数)
- 参数1:exchange(交换机)
- 参数2:routingkey(路由key)
- 参数3:object(发送的消息正文)
- 消费者
// 注入容器
@component
// 监听 rabbitmq
@rabbitlistener(queuestodeclare = @queue(value = "simple_queue", durable = "true", exclusive = "false", autodelete = "false"))
public class simpleconsumer {
// 自动回调
@rabbithandler
public void receivemessage(string message) {
system.out.println("消费者:" + message);
}
}
1.注入容器
2.监听 rabbitmq,在 @rabbitlistener 注解中,可以实现,队列的声明,以及后面交换机与队列的绑定等
- @queue 可以有四个参数,因为其各有默认值,所以只给定 value 值,就会按照 持久化,非独占,非自动删除的方式默认创建
- 参数1:value(队列名)
- 参数2:durable ( 持久化消息队列)rabbitmq 重启后,队列仍存在,默认 true
- 参数3:exclusive(是否独占) 表示该消息队列是否只在当前 connection 生效,默认是 false
- 参数4:auto-delete(自动删除)表示消息队列没有在使用时将被自动删除,默认是 false
3.在方法上添加 @rabbithandler 注解,就能够实现自动回调,这样我们就能拿到生产者中的消息了
- 注:receivemessage 这个方法的参数类型,取决于你在生产者有发送了什么类型的数据
5.1.2 工作队列模式
5.1.2.1 轮询模式
生产者:没什么好说的,因为工作模式有多个消费者,所以多发送几条消息
- 消费者
@springboottest(classes = rabbitmqspringbootapplication.class)
@runwith(springrunner.class)
public class rabbitmqtest {
/**
* 注入 rabbittemplate
*/
@autowired
@test
public void testworksendmessage() {
for (int i = 0; i < 20; i++) {
rabbittemplate.convertandsend("work_queue", "this is a message !, 序号:" + i);
}
}
}@springboottest(classes = rabbitmqspringbootapplication.class)
@runwith(springrunner.class)
public class rabbitmqtest {
/**
* 注入 rabbittemplate
*/
@autowired
@test
public void testworksendmessage() {
for (int i = 0; i < 20; i++) {
rabbittemplate.convertandsend("work_queue", "this is a message !, 序号:" + i);
}
}
}
- 1.@rabbitlistener 注解,既可以放在类上,也可以放在方法上,例如上述代码,我们就分别放在了两个方法上,用来指代不同的消费者。
- 但是如果在类上加入 @rabbitlistener 注解,而在下面两个方法中,添加 @rabbithandler 注解则会报错,需要分别为每个消费者都创建一个类
@component
public class workconsumer {
// 监听 rabbitmq
@rabbitlistener(queuestodeclare = @queue("work_queue"))
// 消费者1
public void receivemessage1(string message) {
system.out.println("消费者1:" + message);
// 监听 rabbitmq
@rabbitlistener(queuestodeclare = @queue("work_queue")
// 消费者2
public void receivemessage2(string message) {
system.out.println("消费者2:" + message);
}
}
5.1.2.2 公平模式(按能力分配)
5.1.2.2.1 修改配置文件的方式
- 生产者不变
- 修改配置文件 yml / properties
spring:
rabbitmq:
host: 192.168.122.1 # 服务器地址
port: 5672 # tcp端口
username: admin # 用户名
password: admin # 用户密码
virtual-host: /rabbitmq_springboot_01 # 虚拟主机
# 新增部分
listener:
simple:
acknowledge-mode: manual # 开启 ack 手动应答
prefetch: 1 # 每次只能消费 1 条消息
acknowledge-mode 选项介绍
auto:自动确认,为默认选项
manual:手动确认(按能力分配就需要设置为手动确认)
none:不确认,发送后自动丢弃
- 消费者
@component
public class workconsumer {
// 监听 rabbitmq
@rabbitlistener(queuestodeclare = @queue("work_queue"))
// 消费者 1
public void receivemessage(string body, message message, channel channel) throws ioexception {
try {
// 打印输出消息主题
system.out.println("消费者1:" + body);
// 返回 deliverytag 代表队列可以删除此消息了
channel.basicack(message.getmessageproperties().getdeliverytag(),false);
} catch (ioexception e) {
e.printstacktrace();
// 消费者告诉队列信息消费失败
channel.basicnack(message.getmessageproperties().getdeliverytag(), false, true);
}
}
// 监听 rabbitmq
@rabbitlistener(queuestodeclare = @queue("work_queue"))
// 消费者 2
public void receivemessage2(string body, message message, channel channel) throws ioexception{
try {
// 延迟 2s 代表处理业务慢
thread.sleep(2000);
} catch (interruptedexception e) {
e.printstacktrace();
}
try {
// 打印输出消息主题
system.out.println("消费者2:" + body);
// 返回 deliverytag 代表队列可以删除此消息了
channel.basicack(message.getmessageproperties().getdeliverytag(), false);
} catch (ioexception e) {
e.printstacktrace();
// 消费者告诉队列信息消费失败
channel.basicnack(message.getmessageproperties().getdeliverytag(), false, true);
}
}
}
1.因为在 yml 配置中开启了手动确认,所以,需要在成功和失败后分别返回确认消息
2.basicack 方法解释
- 参数1:deliverytag(交付标志,即该消息的index),返回即代表确认收到消息,队列可以删除此消息了
- 参数2:mutiple(是否批量)选择 true 将一次性拒绝所有小于 deliverytag 的消息
3.basicnack 方法解释
- 参数 1 |参数 2 同上
- 参数3:requeue(被拒绝的是否重新进入队列)
运行结果:
消费者1:this is a message !, 序号:2
消费者1:this is a message !, 序号:3
消费者1:this is a message !, 序号:4
消费者1:this is a message !, 序号:5
消费者1:this is a message !, 序号:6
消费者1:this is a message !, 序号:7
消费者1:this is a message !, 序号:8
消费者1:this is a message !, 序号:9
消费者1:this is a message !, 序号:10
消费者1:this is a message !, 序号:11
消费者1:this is a message !, 序号:12
消费者1:this is a message !, 序号:13
消费者1:this is a message !, 序号:14
消费者1:this is a message !, 序号:15
消费者1:this is a message !, 序号:16
消费者1:this is a message !, 序号:17
消费者1:this is a message !, 序号:18
消费者1:this is a message !, 序号:19
消费者1:this is a message !, 序号:20
消费者2:this is a message !, 序号:1
到现在已经实现了修改配置文件的方式实现按能力分配,补充几个配置的内容,我们上面只用了一部分,其他的方便大家参考,yml 和 properties 大家自己选择即可
# 发送确认 spring.rabbitmq.publisher-confirm-type=correlated # spring.rabbitmq.publisher-confirms=true(旧版) # 发送回调 spring.rabbitmq.publisher-returns=true # 消费手动确认 spring.rabbitmq.listener.direct.acknowledge-mode=manual spring.rabbitmq.listener.simple.acknowledge-mode=manual # 并发消费者初始化值 spring.rabbitmq.listener.simple.concurrency=1 # 并发消费者的最大值 spring.rabbitmq.listener.simple.max-concurrency=10 # 每个消费者每次监听时可拉取处理的消息数量 # 在单个请求中处理的消息个数,他应该大于等于事务数量(unack的最大数量) spring.rabbitmq.listener.simple.prefetch=1 # 是否支持重试 spring.rabbitmq.listener.simple.retry.enabled=true
5.1.2.2.1 配置工厂的方式
- 消费者修改
/**
* 设置消费者的确认机制,并达到能者多劳的效果
*
* @param connectionfactory 连接工厂
* @return
*/
@bean("worklistenerfactory")
public rabbitlistenercontainerfactory myfactory(connectionfactory connectionfactory) {
simplerabbitlistenercontainerfactory containerfactory =
new simplerabbitlistenercontainerfactory();
containerfactory.setconnectionfactory(connectionfactory);
// 修改为手动确认
containerfactory.setacknowledgemode(acknowledgemode.manual);
// 拒绝策略,true 回到队列 false丢弃,默认是true
containerfactory.setdefaultrequeuerejected(true);
// 默认的prefetchcount是250 修改为 1
containerfactory.setprefetchcount(1);
return containerfactory;
}
@rabbitlistener(queuestodeclare = @queue("work_queue"))
// 将上面的监听,增加 containerfactory 属性,然后将配置好的工厂传入
@rabbitlistener(queuestodeclare = @queue("work_queue"), containerfactory = "worklistenerfactory")
5.1.3 发布与订阅模式
- 生产者
@springboottest(classes = rabbitmqspringbootapplication.class)
@runwith(springrunner.class)
public class rabbitmqtest {
/**
* 注入 rabbittemplate
*/
@autowired
@test
public void testfanoutsendmessage() {
rabbittemplate.convertandsend("order_exchange", "", "this is a message !");
}
}
1.因为从这个模式开始,就涉及到交换机了,所以用的是三个参数的方法
- 消费者
@component
public class fanoutconsumer {
// 绑定临时队列和交换机
@rabbitlistener(bindings = {
@queuebinding(
value = @queue(), // 临时队列
exchange = @exchange(name = "order_exchange", type = "fanout") // 交换机与类型
)
})
public void receivemessage1(string message) {
system.out.println("消费者1:" + message);
}
// 绑定临时队列和交换机
@rabbitlistener(bindings = {
@queuebinding(
value = @queue(), // 临时队列
exchange = @exchange(name = "order_exchange", type = "fanout") // 交换机与类型
)
})
public void receivemessage2(string message) {
system.out.println("消费者2:" + message);
}
}
5.1.4 路由模式(direct)
- 生产者
- 消费者
@springboottest(classes = rabbitmqspringbootapplication.class)
@runwith(springrunner.class)
public class rabbitmqtest {
/**
* 注入 rabbittemplate
*/
@autowired
@test
public void testdirectsendmessage() {
rabbittemplate.convertandsend("direct_exchange", "info", "this is a message !");
}
}
@component
public class directconsumer {
// 绑定临时队列和交换机
@rabbitlistener(bindings = {
@queuebinding(
value = @queue(), // 临时队列
exchange = @exchange(name = "direct_exchange", type = "direct"), // 交换机和类型
key = {"info", "warn", "error"} // 路由key
)
})
public void receivemessage1(string message) {
system.out.println("消费者1:" + message);
}
// 绑定临时队列和交换机
@rabbitlistener(bindings = {
@queuebinding(
value = @queue(), // 临时队列
exchange = @exchange(name = "direct_exchange", type = "direct"), // 交换机和类型
key = {"info", "warn", "error"} // 路由key
)
})
public void receivemessage2(string message) {
system.out.println("消费者2:" + message);
}
}
5.1.5 主题模式
- 生产者
- 消费者
@springboottest(classes = rabbitmqspringbootapplication.class)
@runwith(springrunner.class)
public class rabbitmqtest {
/**
* 注入 rabbittemplate
*/
@autowired
@test
public void testtopicsendmessage() {
rabbittemplate.convertandsend("topic_exchange", "order.insert.common", "this is a message !");
}
}
@component
public class topicconsumer {
// 绑定临时队列和交换机
@rabbitlistener(bindings = {
@queuebinding(
value = @queue(), // 临时队列
exchange = @exchange(name = "topic_exchange", type = "topic"), // 交换机和类型
key = {"order.*"} // 通配符路由key
)
})
public void receivemessage1(string message) {
system.out.println("消费者1:" + message);
}
// 绑定临时队列和交换机
@rabbitlistener(bindings = {
@queuebinding(
value = @queue(), // 临时队列
exchange = @exchange(name = "topic_exchange", type = "topic"), // 交换机和类型
key = {"order.*"} // 通配符路由key
)
})
public void receivemessage2(string message) {
system.out.println("消费者2:" + message);
}
}
5.2 基于注解 + 配置类
其实这种方式,就是将交换机,队列的声明和绑定都在配置类中进行,一个是消费者中的注解变的简洁了,再有就是统一管理,更加条理,而且生产者和消费者引用的时候也更加方便,日后修改的时候,也不需要对每一处都修改。
由于篇幅过长了,这里演示最复杂的 topic 方式,其他的也是信手拈来。
配置类
@configuration
public class rabbitmqconfiguration {
public static final string topic_exchange = "topic_order_exchange";
public static final string topic_queue_name_1 = "test_topic_queue_1";
public static final string topic_queue_name_2 = "test_topic_queue_2";
public static final string topic_routingkey_1 = "test.*";
public static final string topic_routingkey_2 = "test.#";
@bean
public topicexchange topicexchange() {
return new topicexchange(topic_exchange);
}
@bean
public queue topicqueue1() {
return new queue(topic_queue_name_1);
}
@bean
public queue topicqueue2() {
return new queue(topic_queue_name_2);
}
@bean
public binding bindingtopic1(){
return bindingbuilder.bind(topicqueue1())
.to(topicexchange())
.with(topic_routingkey_1);
}
@bean
public binding bindingtopic2(){
return bindingbuilder.bind(topicqueue2())
.to(topicexchange())
.with(topic_routingkey_2);
}
}
1.添加 @configuration 注解:表明这是一个配置类
2.定义常量:将交换机名,队列名,路由key 等都可以创建为常量,调用,管理和修改都非常方便,还可以创建出一个专门的 rabbitmq 的常量类。
3.定义交换机:因为这个例子是 topic 所以选择 topicexchange 类型
4.定义队列:传入队列名常量即可,因为持久化等存在默认值,也可以自己自定持久化,是否独占等参数
5.绑定交换机和队列:利用 bindingbuilder 的 bind 方法绑定队列,to 绑定到指定交换机,with 传入路由key
- 生产者
- 消费者
@springboottest(classes = rabbitmqspringbootapplication.class)
@runwith(springrunner.class)
public class rabbitmqtest {
/**
* 注入 rabbittemplate
*/
@autowired
@test
public void testtopicsendmessage() {
rabbittemplate.convertandsend(rabbitmqconfiguration.topic_exchange, "test.order.insert", "this is a message !");
}
}
@component
public class topicconsumer {
// 绑定队列即可
@rabbitlistener(queues = {rabbitmqconfiguration.topic_queue_name_1})
public void receivemessage1(string message) {
system.out.println("消费者1:" + message);
}
// 绑定队列即可
@rabbitlistener(queues = {rabbitmqconfiguration.topic_queue_name_2})
public void receivemessage2(string message) {
system.out.println("消费者2:" + message);
}
}
5、总结
这篇文章就到这里了,希望大家可以多多关注代码网的其他文章!
赞 (0)
您想发表意见!!点此发布评论





发表评论