【大模型应用开发极简入门】微调(一):1.微调基础原理介绍、2. 微调的步骤、3. 微调的应用(Copilot、邮件、法律文本分析等)
582人参与 • 2024-07-28 • Windows Phone
文章目录
openai提供了许多可直接使用的gpt模型。尽管这些模型在各种任务上表现出色,但针对特定任务或上下文对这些模型进行微调,可以进一步提高它们的性能。
一. 开始微调
假设你想为公司创建一个电子邮件自动回复生成器。由于你的公司所在的行业使用专有词汇,因此你希望生成器给出的电子邮件回复保持一定的写作风格。要做到这一点,有两种策略:要么使用之前介绍的提示工程技巧来强制模型输出你想要的文本,要么对现有模型进行微调。
本文对微调进行讨论。
微调的基本逻辑
通过对现有模型进行微调,你可以创建一个专门针对特定业务所用语言模式和词汇的电子邮件自动回复生成器。
下图展示了微调过程,也就是使用特定领域的数据集来更新现有gpt模型的内部权重。微调的目标是使新模型能够在特定领域中做出比原始gpt模型更好的预测。
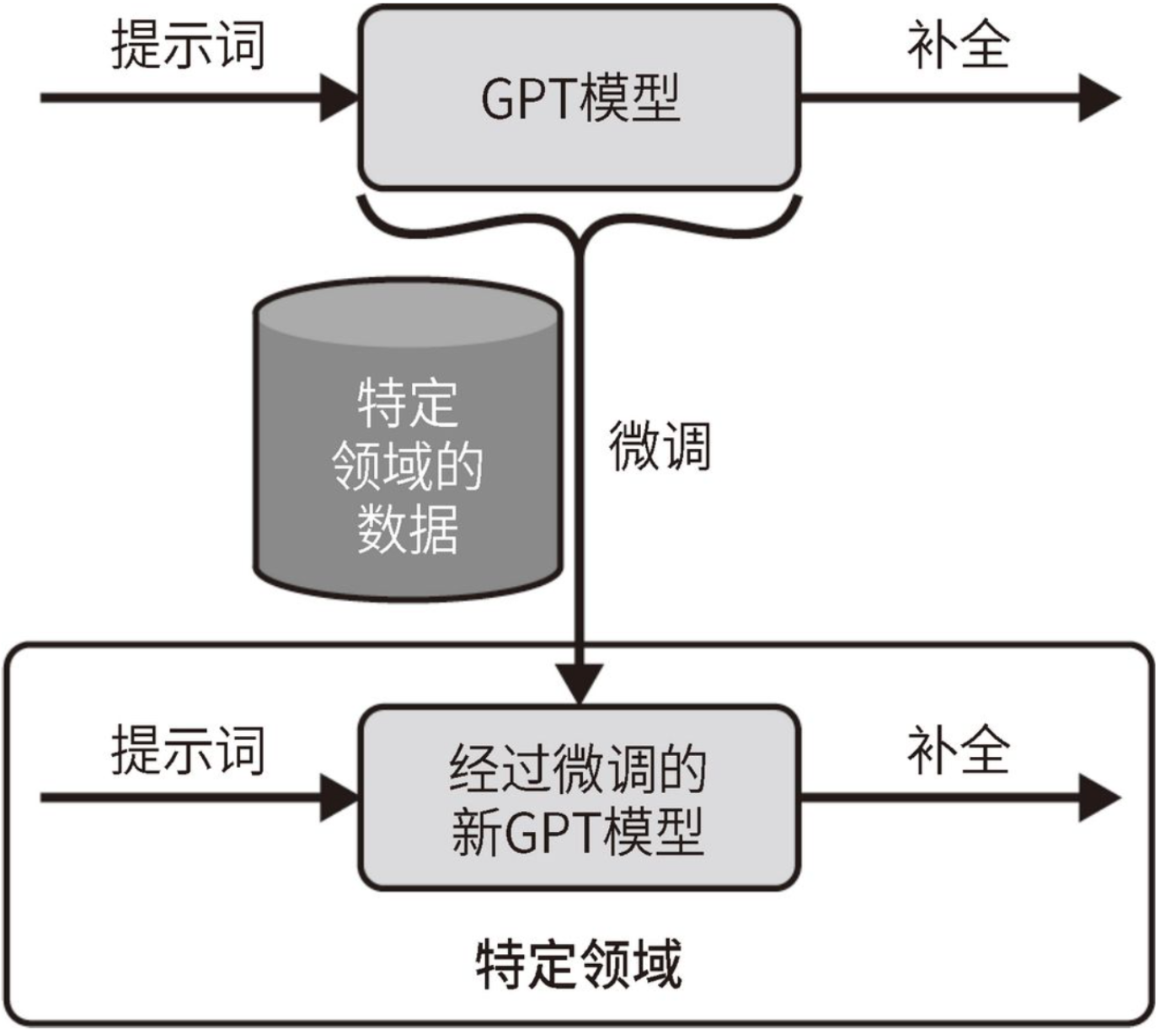
需要注意的是:新模型仍然在openai服务器上
1. 选择合适的基础模型
目前,微调仅适用于davinci、curie、babbage和ada这几个基础模型。这些模型都在准确性和所需资源之间做出了权衡。
开发人员可以为应用程序选择最合适的模型:
微调后的专有能力
2. 微调和少样本学习
2.1. 对比微调和少样本学习
模型是否进行了更新
都可以用来增强gpt模型
2.2. 微调需要的数据量
微调通常需要用到大量数据。可用示例的缺乏往往限制了我们使用这种技巧。
ing
二. 使用openai api进行微调
本节使用openai api来微调llm。我们将学习如何准备数据、上传数据,并使用openai api创建一个经过微调的模型。
1. 数据生成
1.1. jsonl的数据格式
更新llm需要提供一个包含示例的数据集。该数据集是一个jsonl文件,其中每一行对应一个<提示词:补全文本>对,如下示例:
{"prompt": "<prompt text>", "completion": "<completion text>"}
{"prompt": "<prompt text>", "completion": "<completion text>"}
{"prompt": "<prompt text>", "completion": "<completion text>"}
...
jsonl文件是文本文件,其中每一行表示一个单独的json对象。你可以使用它来高效地存储大量数据。
1.2. 数据生成工具
openai提供了一个工具,可以帮助你生成此训练文件。
安装:当执行pip install openai时,该工具会自动安装。
终端使用此工具:
$ openai tools fine_tunes.prepare_data -f <local_file>
1.3. 数据文件的细节注意
2. 上传数据来训练模型
准备好数据后,需要将其上传到openai服务器。openai api提供了不同的函数来操作文件。以下是一些重要函数。
上传文件:
openai.file.create(
file=open("out_openai_completion_prepared.jsonl", "rb"),
purpose='fine-tune'
)
# 两个参数是必需的:file和purpose。
# 在微调时,将purpose设置为fine-tune。这将验证用于微调的下载文件格式。
此函数的输出是一个字典,你可以在id字段中检索文件id。目前,文件的总大小可以达到1 gb 。
删除文件:
openai.file.delete("file-z5mgg(...)")
列出所有已上传的文件:
openai.file.list()
3. 创建微调模型
如下:微调已上传文件是一个简单的过程。
openai.finetune.create(
training_file='', # 给定数据集
model='', # 根据给定的数据集优化指定的模型
validation_file='',
suffix='' #
)
主要的输入参数
| 字段名称 | 类型 | 描述 |
|---|---|---|
| training_file | string | 这是唯一的必填参数,包含已上传文件的 id。数据集必须格式化为 jsonl 文件。每个训练示例是一个带有 prompt 键和 completion 键的 json 对象 |
| model | string | 指定用于微调的基础模型。可选项有 ada, babbage, curie, davinci,或曾之前微调过的模型。默认的基础模型是 curie |
| validation_file | string | 包含验证数据的已上传文件。该文件中的数据将仅在微调过程中用来生成验证指标 |
| suffix | string | 这是一个最多由 40 个字符组成的字符串,它将被添加到自定义模型名称中 |
该函数的响应
4. 列出微调作业
可以通过以下函数获取openai服务器上的所有微调作业
openai.finetune.list()
# 结果是一个字典,包含所有微调模型的信息。
5. 取消微调作业
可以通过以下函数立即中断在openai服务器上运行的作业:
openai.finetune.cancel()
# 只有一个必需的参数:fine_tune_id。
# 该参数是以ft-开头的字符串,例如ft-re12otqdraj(...)。
# 它是在使用openai.finetune.create创建作业后获得的。
# 如果你丢失了fine_tune_id,那么可以使用openai.finetune.list检索它。
二. 微调的应用
微调提供了一种强大的技术手段,有助于提升模型在各类应用场景中的性能。再次提醒,微调的成本比基于提示工程的技术更高,因此在大多数情况下并非必需。不过当需要使用它时,微调可以显著地改善效果。
1. 法律文本分析
场景
微调
成果
2. 自动代码审查-类copilot
在这个案例中,微调可以帮助模型分析开发人员编写的代码,并提出改进建议。
举例:
你可以使用微调来训练模型完成特定任务,比如代码审查,如下例子:
{"prompt": "review the following python code:
'def sum(a, b): return a + b\nresult = sum(5, '5')'",
"completion": "type error: the 'sum' function is adding an integer
and a string. consider converting the string to an integer using
int() before passing it to the function."}
3. 财务文档摘要
针对收益报告、财务报表和分析师报告等财务文档,经过微调的llm可以生成简明、准确的摘要。
{"prompt": "the central bank announced a 0.25% increase in the benchmark
interest rate, citing concerns about inflationary pressures.
this move is expected to affect borrowing costs for consumers
and businesses.",
"completion": "bank increases rate 0.25% for inflation worry. may
affect people, business borrowing costs."}
4. 技术文档翻译
与少样本学习相比,使用微调后的模型来翻译技术文档可以显著地改善翻译效果。主要原因是,技术文档通常包含专业词汇和复杂的句子结构,少样本学习无法有效处理这种复杂性。
对于技术文档翻译的用例,该文件应该包括将技术文本翻译为目标语言的翻译内容。
5. 为专业领域生成内容
一个经过微调的模型可以针对高度专业化的主题生成高质量、引人入胜且与上下文相关的内容。
微调模型可以显著提高客户服务聊天机器人的性能,使模型更好地理解和响应特定领域的客户查询。客户服务场景具备天然的优势,即容易收集典型客户服务对话的高质量问答集,通过用户反馈形成回路,再通过微调持续改进模型的响应质量。这使模型能够更准确地识别客户问题的本质,并提供合适的解决方案。比如,模型可以学习如何处理账户查询、故障排除或产品推荐等具体问题。
三. 微调的成本
使用微调模型的成本不低。你不仅需要支付模型训练费用,而且在模型准备好后,每次进行预测时需要支付的费用也会比使用openai提供的基础模型略高一些。在我们撰写本书之时,费用如表所示,不过具体的费用会有所变化。
| 模型 | 训练 | 使用 |
|---|---|---|
| ada | 每千个标记 0.0004 美元 | 每千个标记 0.0016 美元 |
| babbage | 每千个标记 0.0006 美元 | 每千个标记 0.0024 美元 |
| curie | 每千个标记 0.0030 美元 | 每千个标记 0.0120 美元 |
| davinci | 每千个标记 0.0300 美元 | 每千个标记 0.1200 美元 |
作为比较,gpt-3.5-turbo模型的定价是每千个输出标记0.0020美元。可见,gpt-3.5-turbo模型的性价比最高。要了解最新的模型定价,请访问openai的pricing页面。
赞 (0)
您想发表意见!!点此发布评论




发表评论