[学习笔记] [机器学习] 1. 机器学习前置知识(机器学习概述、Matplotlib、Numpy、Pandas)
38人参与 • 2024-08-01 • 机器学习
- 视频链接
- 所有数据集下载地址:
1. 机器学习概述
1.1 机器学习算法分类
根据数据集组成不同,可以把机器学习算法分为:
- 监督学习
- 无监督学习
- 半监督学习
- 强化学习
1.1.1 监督学习
定义:输入数据是由输入特征值和目标值组成。
- 函数的输出可以是一个连续的值(称为回归)
- 输出是有限个离散值(称作分类)
监督学习可分为:
- 回归问题:预测房价,根据样本集拟合出一条连续曲线。
- 分类问题:根据肿瘤特征判断良性还是恶性,得到的是结果是“良性”或者“恶性”,是离散的。
1.1.2 无监督学习
定义:输入数据是由输入特征值组成,没有目标值。
- 输入数据没有被标记,也没有确定的结果。样本数据类别未知,需要根据样本间的相似性对样本集进行类别划分。
有监督、无监督算法对比:
1.1.3 半监督学习
定义:训练集同时包有标记样本数据(有目标值)和未标记样本数据(无目标值)。
1.1.4 强化学习
定义:实质是 auto make decisions 问题,即自动进行决策,并且可以做连续决策。
举例:小孩想要走路,但在这之前,他需要先站起来,站起来之后还要保持平衡。接下来还要先迈出一条腿,是左腿还是右腿,迈出一步后还要迈出下一步。
小孩就是agent,他试图通过采取行动(即行走)来操纵环境(行走的表面),并且从一个状态转变到另一个状态(即他走的每一步)。当他完成任务的子任务(即走了几步)时,孩子得到奖励(给巧克力吃);并且当他不能走路时,就不会给巧克力。
主要包含五个元素: agent, action, reward, environment, observation
强化学习的目标就是获得最多的累计奖励。
监督学习和强化学习的对比:
| 监督学习 | 强化学习 | |
|---|---|---|
| 反馈映射 | 输出的是之间的关系,可以告诉算法什么样的输入对应着什么样的输出 | 输出的是给机器的反馈 reward function,即用来判断这个行为是好是坏 |
| 反馈时间 | 做了比较坏的选择会立刻反馈给算法 | 结果反馈有延时,有时候可能需要走了很多步以后才知道以前的某一步的选择是好还是坏 |
| 输入特征 | 输入是独立同分布的 | 面对的输入总是在变化,每当算法做出一个行为,它影响下一次决策的输入 |
【拓展概念】什么是独立同分布?
独立同分布(independent and identically distributed,iid):
- 在概率统计理论中,如果变量序列或者其他随机变量有相同的概率分布,并且互相独立,那么这些随机变量是独立同分布。
- 在西瓜书中解释是:输入空间中的所有样本服从一个隐含未知的分布,训练数据所有样本都是独立地从这个分布上采样而得。
独立、同分布、独立同分布的简单解释:
- 独立:
- 满足条件的例子:假设你有两个骰子,你分别把它们投掷一次。第一个骰子的点数不会影响第二个骰子的点数,所以这两次投掷是独立的。
- 不满足条件的例子:假设你有一个骰子,你把它投掷两次。如果你只有在第一次投掷得到偶数时才进行第二次投掷,那么这两次投掷就不是独立的,因为第二次投掷是否发生取决于第一次投掷的结果。
- 同分布:
- 满足条件的例子:假设你有两个相同的骰子,每个骰子都有六个面,每个面上的点数都是 1 到 6。这两个骰子的概率分布是相同的,所以它们是同分布的。
- 不满足条件的例子:假设你有两个不同的骰子,一个骰子有六个面,每个面上的点数都是 1 到 6;另一个骰子有四个面,每个面上的点数都是1到4。这两个骰子的概率分布是不同的,所以它们不是同分布的。
- 独立同分布:
- 满足条件的例子:如果你有两个相同的骰子,并且你分别把它们投掷一次。由于这两个骰子是相同的,所以它们是同分布的;由于第一个骰子的点数不会影响第二个骰子的点数,所以这两次投掷是独立的。因此,这两次投掷是独立同分布的。
- 不满足条件的例子:如果你有两个不同的骰子,并且你只有在第一个骰子投掷得到偶数时才进行第二次投掷。由于这两个骰子不同,所以它们不是同分布的;由于第二次投掷是否发生取决于第一次投掷的结果,所以这两次投掷也不是独立的。因此,这两次投掷既不是独立也不是同分布。
小结:
| in(输入) | out(输出) | 目的 | 案例 | |
|---|---|---|---|---|
| 监督学习 | 有标签 | 有反馈 | 预测结果 | 猫狗分类、房价预测 |
| 无监督学习 | 无标签 | 无反馈 | 发现潜在结构 | “物以聚类,人以群分” |
| 半监督学习 | 部分有标签,部分无标签 | 有反馈 | 降低数据标记的难度 | 在文本分类中,有大量未标记的文本数据和少量已标记的文本数据 |
| 强化学习 | 决策流程及激励系统 | 一系列行动 | 长期利益最大化 | 学下棋 |
1.2 模型评估
学习目标:
- 了解机器学习中模型评估的方法。
- 知道过拟合、欠拟合发生情况
模型评估是模型开发过程不可或缺的一部分。它有助于发现表达数据的最佳模型和所选模型将来工作的性能如何(模型的泛化性能)。
按照数据集的目标值不同,可以把模型评估分为分类模型评估和回归模型评估。
1.2.1 分类模型评估
- 准确率(accuracy):预测正确的数占样本总数的比例。
- 其他评价指标:精确率(precision)、召回率(recall)、f1-score、auc指标等
1.2.2 回归模型评估
均方根误差(root mean squared error,rmse):rmse 是一个衡量回归模型误差率(loss)的常用公式。不过,它仅能比较误差是相同单位的模型。
r m s e = ∑ i n ( p i − y ^ i ) 2 n rmse = \sqrt{\frac{\sum_i^n(p_i - \hat{y}_i)^2}{n}} rmse=n∑in(pi−y^i)2
其中:
- y y y 为预测值
- y ^ \hat{y} y^ 为真实值
- n n n 为样本数量
其他评价指标:
- 相对平方误差(relative squared error,rse)
- 平均绝对误差(mean absoluteerror,mae)
- 相对绝对误差(relative absolute error,rae)
1.3 拟合
模型评估用于评价训练好的的模型的表现效果,其表现效果大致可以分为过拟合和欠拟合。
在训练过程中,你可能会遇到如下问题:
训练数据训练的很好啊,误差也不大,为什么在测试集上面有问题呢?当算法在某个数据集当中出现这种情况,可能就出现了拟合问题。
1.3.1 欠拟合
欠拟合(under-fitting):模型学习的太过粗糙,连训练集中的样本数据特征关系都没有学出来。
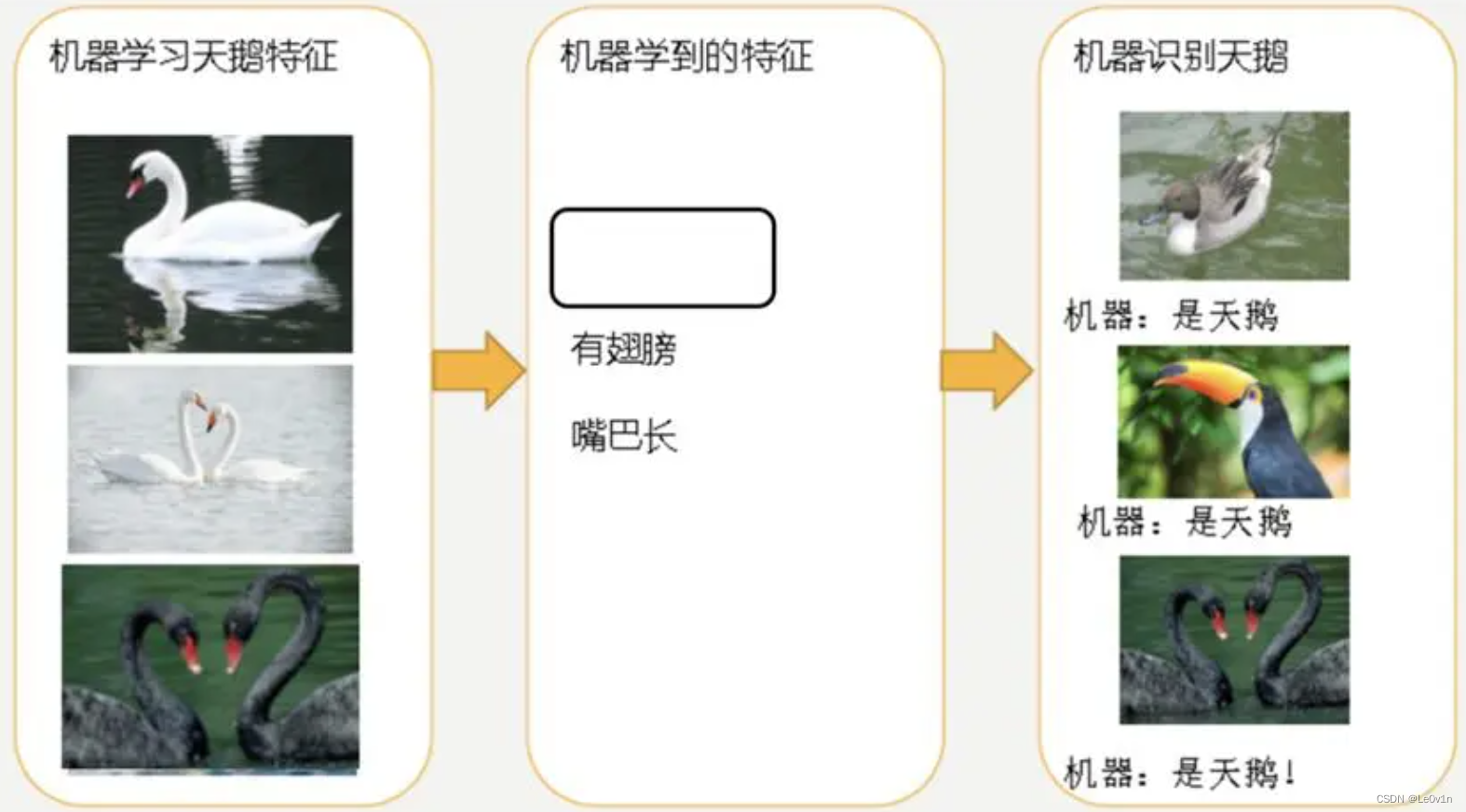
因为机器学习到的天鹅特征太少了,导致区分标准太粗糙,不能准确识别出天鹅。
1.3.2 过拟合
过拟合(over-fitting):所建的机器学习模型或者是深度学习模型在训练样本中表现得过于优越,导致在测试数据集中表现不佳。

机器已经基本能区别天鹅和其他动物了。然后,很不巧已有的天鹅图片全是白天鹅的,于是机器经过学习后,会认为天鹅的羽毛都是白的,以后看到羽毛是黑的天鹅就会认为那不是天鹅。
小结:
- 分类模型评估【了解】
- 准确率
- 回归模型评估【了解】
- rmse —— 均方根误差
- 拟合【知道】
- 欠拟合
- 学习到的东西太少
- 模型学习的太过粗糙
- 过拟合
- 学习到的东西太多
- 学习到的特征多,不好泛化
- 欠拟合
2. matplotlib
matplotlib 是一个用于绘制数据可视化图表的 python 库,可以满足各种绘图需求。它可以用来创建各种类型的图表,例如线图、散点图、柱状图、直方图、饼图等。matplotlib 还可以与其他 python 库(例如 numpy 和 pandas)结合使用。它是数据科学和机器学习领域中最受欢迎的可视化工具之一。
示例:
import matplotlib.pyplot as plt
import random
# 1. 创建画布
plt.figure(figsize=(20, 8), dpi=100) # figsize=(长, 宽)
# 2. 绘制图像
x = [i for i in range(1, 10)]
y = [i for i in range(11, 20)]
random.shuffle(y)
plt.plot(x, y)
# 3. 图像显示
plt.show()
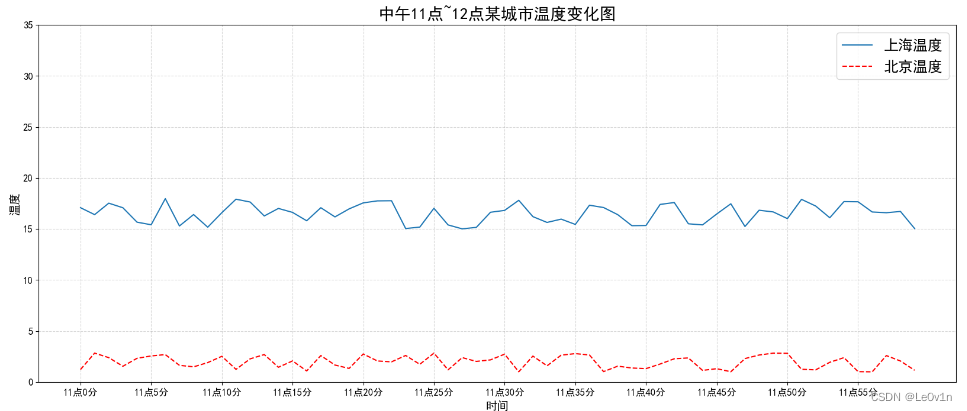
2.1 示例
为了更好地理解所有基础绘图功能,我们通过天气温度变化的绘图来融合所有的基础 api 使用需求:画出某城市 11 点到 12 点 1 小时内每分钟的温度变化折线图,温度范围在 15 度 ~ 18 度。
import matplotlib.pyplot as plt
import random
from pylab import mpl
# 设置中文字体
mpl.rcparams["font.sans-serif"] = ["simhei"]
# 设置正常显示符号
mpl.rcparams["axes.unicode_minus"] = false
# 0. 准备数据
x = range(60)
y = [random.uniform(15, 18) for i in x]
# 1. 创建画布
plt.figure(figsize=(20, 8), dpi=100)
# 2. 绘制图像
plt.plot(x, y)
## 2.1 自定义x,y轴刻度
x_tickes_label = [f"11点{i}分" for i in x]
y_tickes_label = range(40)
## 2.2 指定xy轴的空隙
plt.xticks(x[::5], x_tickes_label[::5], fontsize=12) # xticks(ticks=none, labels=none, **kwargs)
plt.yticks(y_tickes_label[::5], fontsize=12)
# 2.3 添加网格显示
plt.grid(visible=true, linestyle="--", alpha=0.5) # alpha为透明度
# 2.4 添加描述信息
plt.xlabel("时间", fontsize=14)
plt.ylabel("温度", fontsize=14)
plt.title("中午11点~12点某城市温度变化图", fontsize=20)
# 2.5 保存图片(保存图片一定要在plt.show()之前,否则会保存一张空的图片)
plt.savefig("./test.png")
# 3. 图像显示
plt.show()

其中:random.uniform() 是 python 的 random 模块中的一个函数,它用于生成一个指定范围内的随机浮点数。函数的语法为 random.uniform(a, b),其中 a 和 b 分别表示生成随机数的范围的下限和上限。生成的随机数 n 满足 a <= n < b。
2.2 常见的注意事项
2.2.1 坐标轴
xticks(ticks=none, labels=none, **kwargs):
- ticks:x 轴刻度位置的列表,若传入空列表,即不显示 x 轴
- labels:放在指定刻度位置的标签文本。当 ticks 参数有输入值,该参数才能传入参数
2.2.2 显示中文字体
from pylab import mpl
# 设置中文字体
mpl.rcparams["font.sans-serif"] = ["simhei"]
# 设置正常显示符号
mpl.rcparams["axes.unicode_minus"] = false
2.2.3 图片保存
保存图片一定要在plt.show()之前,否则会保存一张空的图片。
2.3 在一个坐标系中绘制多个图像
需求:再添加一个城市的温度变化。收集到北京当天温度变化情况,温度在1度到3度。效果如下:
import matplotlib.pyplot as plt
import random
from pylab import mpl
# 设置中文字体
mpl.rcparams["font.sans-serif"] = ["simhei"]
# 设置正常显示符号
mpl.rcparams["axes.unicode_minus"] = false
# 0. 准备数据
x = range(60)
y = [random.uniform(15, 18) for i in x]
y_bj = [random.uniform(1, 3) for i in x]
# 1. 创建画布
plt.figure(figsize=(20, 8), dpi=100)
# 2. 绘制图像
plt.plot(x, y, label="上海温度")
plt.plot(x, y_bj, color="red", linestyle="--", label="北京温度")
## 2.1 自定义x,y轴刻度
x_tickes_label = [f"11点{i}分" for i in x]
y_tickes_label = range(40)
## 2.2 指定xy轴的空隙
plt.xticks(x[::5], x_tickes_label[::5], fontsize=12) # xticks(ticks=none, labels=none, **kwargs)
plt.yticks(y_tickes_label[::5], fontsize=12)
# 2.3 添加网格显示
plt.grid(visible=true, linestyle="--", alpha=0.5) # alpha为透明度
# 2.4 添加描述信息
plt.xlabel("时间", fontsize=14)
plt.ylabel("温度", fontsize=14)
plt.title("中午11点~12点某城市温度变化图", fontsize=20)
# 2.5 保存图片(保存图片一定要在plt.show()之前,否则会保存一张空的图片)
plt.savefig("./test.png")
# 2.6 显示图例
plt.legend(loc="best", fontsize=18)
# 3. 图像显示
plt.show()
2.4 多个坐标系显示 —— plt.subplots(面向对象的画图方法)
如果我们想要将上海和北京的天气图显示在同一个图的不同坐标系当中。效果如下:
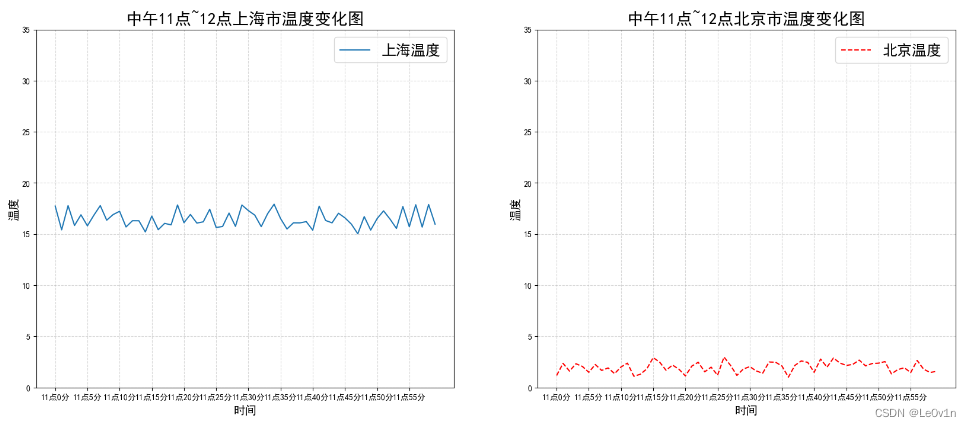
可以通过subplots函数实现(旧的版本中有subplot,使用起来不方便),推荐subplots函数。
matplotlib.pyplot.subplots(nrows=1, ncols=1, **fig_kw)创建一个带有多个axes(坐标系/绘图区)的图。
parameters:
nrows, ncols: 设置几行几列坐标系
int, optional, default: 1, number of rows/columns of the subplot grid.
return:
fig: 图对象
axes: 返回相应数量的坐标系
设置标题等方法不同:
set_xticks
set_yticks
set_xlabel
set_ylabel
关于 axes 子坐标系的更多方法:matplotlib.axes
注意:plt.函数名()相当于面向过程的画图方法,axes.set_方法名()相当于面向对象的画图方法。
import matplotlib.pyplot as plt
import random
from pylab import mpl
# 设置中文字体
mpl.rcparams["font.sans-serif"] = ["simhei"]
# 设置正常显示符号
mpl.rcparams["axes.unicode_minus"] = false
# 0. 准备数据
x = range(60)
y = [random.uniform(15, 18) for _ in x]
y_bj = [random.uniform(1, 3) for _ in x]
# 1. 创建画布
# plt.figure(figsize=(20, 8), dpi=100)
fig, axes = plt.subplots(nrows=1, ncols=2, figsize=(20, 8), dpi=100)
# 2. 绘制图像
# plt.plot(x, y, label="上海温度")
# plt.plot(x, y_bj, color="red", linestyle="--", label="北京温度")
axes[0].plot(x, y, label="上海温度")
axes[1].plot(x, y_bj, color="red", linestyle="--", label="北京温度")
## 2.1 自定义x,y轴刻度
x_tickes_label = [f"11点{i}分" for i in x]
y_tickes_label = range(40)
## 2.2 指定xy轴的空隙
# plt.xticks(x[::5], x_tickes_label[::5], fontsize=12) # xticks(ticks=none, labels=none, **kwargs)
# plt.yticks(y_tickes_label[::5], fontsize=12)
axes[0].set_xticks(x[::5])
axes[0].set_yticks(y_tickes_label[::5])
axes[0].set_xticklabels(x_tickes_label[::5])
axes[1].set_xticks(x[::5])
axes[1].set_yticks(y_tickes_label[::5])
axes[1].set_xticklabels(x_tickes_label[::5])
# 2.3 添加网格显示
# plt.grid(visible=true, linestyle="--", alpha=0.5) # alpha为透明度
axes[0].grid(visible=true, linestyle="--", alpha=0.5)
axes[1].grid(visible=true, linestyle="--", alpha=0.5)
# # 2.4 添加描述信息
# plt.xlabel("时间", fontsize=14)
# plt.ylabel("温度", fontsize=14)
# plt.title("中午11点~12点某城市温度变化图", fontsize=20)
axes[0].set_xlabel("时间", fontsize=14)
axes[0].set_ylabel("温度", fontsize=14)
axes[0].set_title("中午11点~12点上海市温度变化图", fontsize=20)
axes[1].set_xlabel("时间", fontsize=14)
axes[1].set_ylabel("温度", fontsize=14)
axes[1].set_title("中午11点~12点北京市温度变化图", fontsize=20)
# 2.5 保存图片(保存图片一定要在plt.show()之前,否则会保存一张空的图片)
plt.savefig("./test.png")
# 2.6 显示图例
# plt.legend(loc="best", fontsize=18)
axes[0].legend(loc="best", fontsize=18)
axes[1].legend(loc="best", fontsize=18)
# 3. 图像显示
plt.show()
2.5 折线图的应用场景
举例:
- 呈现公司产品(不同区域)每天活跃用户数
- 呈现 app 每天下载数量
- 呈现产品新功能上线后,用户点击次数随时间的变化
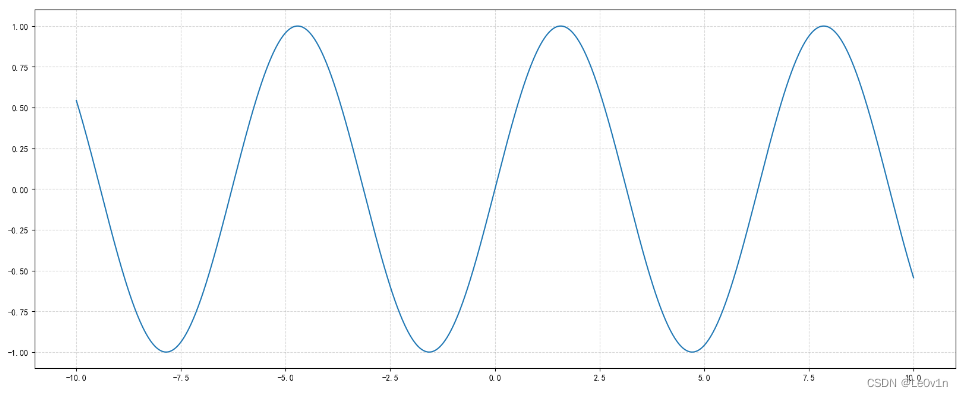
- 拓展:画各种数学函数图像
注意:plt.plot()除了可以画折线图,也可以用于画各种数学函数图像。
import matplotlib.pyplot as plt
import numpy as np
from pylab import mpl
# 设置中文字体
mpl.rcparams["font.sans-serif"] = ["simhei"]
# 设置正常显示符号
mpl.rcparams["axes.unicode_minus"] = false
# 0. 准备数据
x = np.linspace(-10, 10, 1000)
y = np.sin(x)
# 1. 创建画布
plt.figure(figsize=(20, 8), dpi=100)
## 2. 绘制函数图像
plt.plot(x, y)
## 2.1 添加网格显示
plt.grid(visible=true, linestyle="--", alpha=0.5)
# 3. 显示图像
plt.show()
小结:
- 添加 x,y 轴列度【知道】
plt.xticks()plt.yticks()- 注意:在传递进去的第一个参数必须是数字,不能是字符串。如果是字符串,需要进行替换操作
- 添加网格显示【知道】
plt.grid(linestyle="--"", alpha=0.5)
- 添加描述信息【知道】
plt.xlabel()plt.ylabel()plt.title()
- 图像保存【知道】
plt.savefig("路径")
- 多次plot【了解】
- 直接进行添加就ok
- 显示图例【知道】
plt.legend(loc="best")- 注意:一定要在
plt.plot()里面设置一个label。如果不设置,没法显示
- 多个坐标系显示【了解】
plt.subplots(nrows=, ncols=)
- 折线图的应用【知道】
- 应用于观察数据的变化
- 画出一些数学函数图像
2.6 常见图形绘制
学习目标:
- 掌握常见统计图及其意义
matplotlib能够绘制折线图、散点图、柱状图、直方图、饼图。我们需要知道不同的统计图的意义,以此来决定选择哪种统计图来呈现我们的数据。

- 折线图:以折线的上升或下降来表示统计数量的增减变化的统计图。
- 特点:能够显示数据的变化趋势,反映事物的变化情况。——变化
- api:
plt.plot(x, y)
- 散点图:用两组数据构成多个坐标点,考察坐标点的分布,判断两变量之间是否存在某种关联或总结坐标点的分布模式。
- 特点:判断变量之间是否存在数量关系趋势,展示离群点。——分布规律
- api:
plt.scatter(x, y)
- 柱状图:排列在工作表的列或行中的数据可以绘制到柱状图中。
- 特点:绘制离散的数据,能够一眼看出各个数据的大小,比较数据之间的差别。——统计/对比
- api:
plt.bar(x, width, align="center", **kwargs) - 参数说明:
x:需要传递的数据width:柱状图的宽度align:每个柱状图的位置对齐方式:{"center", "edge"}, optional, default: "center"**kwargs:color:选择柱状图的颜色
- 直方图:由一系列高度不等的纵向条纹或线段表示数据分布的情况。一般用横轴表示数据范围,纵轴表示分布情况。
- 特点:绘制连续性的数据,展示一组或多组数据的分布情况。——统计
- api:
plt.hist(x, bins=none) - 参数说明:
x:需要传递的数据bins:bins参数指定直方图的箱子数量,用于将数据分成若干个区间并计算每个区间内数据的频数。可以通过调整bins的值来控制直方图的分辨率和精度,从而更好地理解数据的分布情况。如果不指定bins参数,则默认将数据分为10个区间。
- 饼图:用于表示不同分类的占比情况,通过弧度大小来对比各种分类,
- 特点:分类数据的占比情况。——占比
- api:
plt.pie(x, labels=, autopct=, colors) - 参数说明:
x:数量,自动算百分比labels:每个section的名称autopct:占比显示指定%1.2f%colors:每部分颜色
直方图(plt.hist)和柱状图(plt.bar)的区别:直方图和柱状图都是用于表示数据分布的图形,但它们的意义和使用场景不同。
-
直方图(
plt.hist)是一种连续型数据的图形表示方法,横轴表示数据的取值范围,纵轴表示数据出现的频率或概率密度。直方图的连续条形图之间没有间隔,因为它们代表的是连续的数据范围,因此在直方图中所有的条形都是相邻且相互重叠的,而且它们的宽度通常是不等的。直方图通常用于表示数据的分布情况,包括数据的集中程度、对称性、偏斜程度等。 -
柱状图(
plt.bar)则是一种离散型数据的图形表示方法,横轴表示不同的类别或数据,纵轴表示数量或比例。柱状图的条形之间有间隔,因为它们代表的是不同的类别或数据,它们的宽度通常是相等的。柱状图通常用于比较不同类别或数据之间的数量或比例。
因此,直方图(plt.hist)和柱状图(plt.bar)的区别在于数据类型和表示方式:直方图适用于连续型数据的分布表示,而柱状图适用于离散型数据的比较表示。
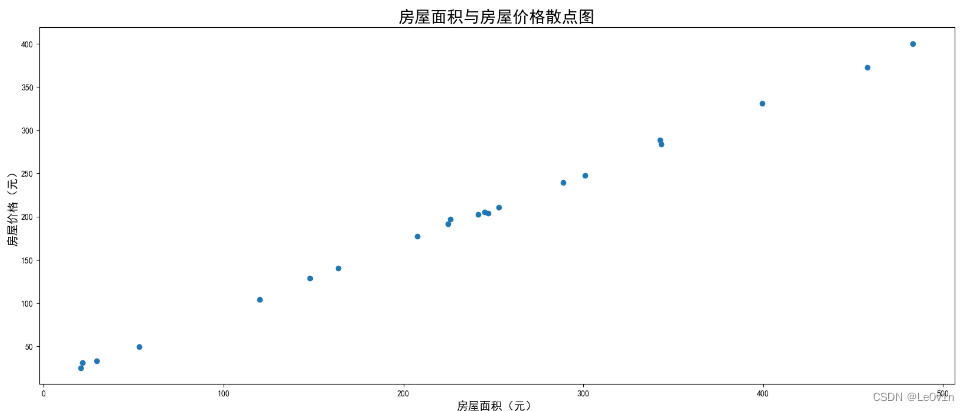
2.6.1 绘制散点图
需求:退散房屋面积和房屋价格的关系。
房屋面积数据:
x = [225.98, 247.07, 253.14, 457.85, 241.58, 301.01, 20.67, 288.64,
163.56, 120.06, 207.83, 342.75, 147.9, 53.06, 224.72, 29.51,
21.61, 483.21, 245.25, 399.25, 343.35]
房屋价格数据:
y = [196.63, 203.88, 210.75, 372.74, 202.41, 247.61, 24.9, 239.34,
140.32, 104.15, 176.84, 288.23, 128.79, 49.64, 191.74, 33.1,
30.74, 400.02, 205.35, 330.64, 283.45]
import matplotlib.pyplot as plt
from pylab import mpl
# 设置中文字体
mpl.rcparams["font.sans-serif"] = ["simhei"]
# 设置正常显示符号
mpl.rcparams["axes.unicode_minus"] = false
x = [225.98, 247.07, 253.14, 457.85, 241.58, 301.01, 20.67, 288.64,
163.56, 120.06, 207.83, 342.75, 147.9, 53.06, 224.72, 29.51,
21.61, 483.21, 245.25, 399.25, 343.35]
y = [196.63, 203.88, 210.75, 372.74, 202.41, 247.61, 24.9, 239.34,
140.32, 104.15, 176.84, 288.23, 128.79, 49.64, 191.74, 33.1,
30.74, 400.02, 205.35, 330.64, 283.45]
# 1. 创建画布
plt.figure(figsize=(20, 8), dpi=100)
# 2. 绘制图像
plt.scatter(x, y)
# 2.1 添加细节
plt.title("房屋面积与房屋价格散点图", fontsize=20)
plt.xlabel("房屋面积(元)", fontsize=14)
plt.ylabel("房屋价格(元)", fontsize=14)
# 3. 显示图像
plt.show()
效果如下:
2.6.2 绘制柱状图
需求:对比每部电影的票房收入。
import matplotlib.pyplot as plt
from pylab import mpl
# 设置中文字体
mpl.rcparams["font.sans-serif"] = ["simhei"]
# 设置正常显示符号
mpl.rcparams["axes.unicode_minus"] = false
import random
# 电影名称
movie_name = ["电影" + str(i) for i in range(1, 11)]
x = range(len(movie_name))
y = [random.randint(10000, 20000) for _ in range(10)]
# 1. 创建画布
plt.figure()
# 2. 绘制图像
movie_color_seed = ['b', 'r', 'g', 'y', 'c', 'm', 'k', 'b']
movie_color = [movie_color_seed[random.randint(0, len(movie_color_seed)-1)] for _ in range(len(movie_name))]
plt.bar(x, y, width=0.5, color=movie_color)
# 2.1 添加细节
plt.title("不同电影单日票房收入", fontsize=20)
plt.xlabel("电影名", fontsize=14)
plt.ylabel("单日票房(元)", fontsize=14)
# 2.2 修改x轴显示
plt.xticks(x, movie_name)
# 2.3 添加网格
plt.grid(linestyle="--", alpha=0.5)
# 3. 显示图像
plt.show()

小结:
- 折线图【知道】
- 能够显示数据的变化趋势,反映事物的变化情况。(变化)
plt.plot()
- 散点图【知道】
- 判断变量之间是否存在数量关联趋势,展示离群点(分布规律)
plt.scatter()
- 柱状图【知道】
- 绘制连离散的数据,能够一眼看出各个数据的大小,比较数据之间的差别。(统计/对比)
plt.bar(x, width, align="center")
- 直方图【知道】
- 绘制连续性的数据展示一组或者多组数据的分布状况(统计)
plt.hist(x, bins)
- 饼图【知道】
- 用于表示不同分类的占比情况,通过弧度大小来对比各种分类(占比)
plt.pie(x, labels, autopct, colors)
3. numpy
numpy 是 python 中的一个开源数学计算库,它提供了一个高性能的多维数组对象,以及用于处理这些数组的工具。它是科学计算、数据分析和机器学习领域中常用的库之一,广泛应用于各种领域,如自然语言处理、图像处理、信号处理、统计分析等。numpy 是基于 c 语言编写的,因此它的计算速度非常快,远远超过了 python 原生的列表和数组的计算速度。
numpy 使用ndarray对象来处理多维数组,该对象是一个快速而灵活的大数据容器。
学习目标:
- 了解 numpy 运算速度上的优势
- 知道数组的属性,形状、类型
- 应用 numpy 实现数组的基本操作
- 应用随机数组的创建实现正态分布应用
- 应用 numpy 实现数组的逻辑运算
- 应用 numpy 实现数组的统计运算
- 应用 numpy 实现数组之间的运算
3.1 ndarray的介绍
numpy 提供了一个n维数组类型ndarray,它描述了相同类型的"items"的集合。
ndarray是 numpy 中的一个核心对象,它是一个多维数组对象,可以存储任意类型的数据(但确定了数据类型后,ndarray 容器中所有元素的数据类型必须相同),并且支持各种数学运算。ndarray的全称是n-dimensional array,即n维数组,它可以是 1 维数组、2 维数组、3 维数组等任意维度的数组。ndarray中的每个元素在内存中是连续存储的,因此它的计算速度非常快。
ndarray的创建非常灵活,可以通过多种方式创建,如从 python 列表、元组等数据结构转换而来,也可以通过各种函数直接创建,例如zeros、ones、arange、linspace等函数。
ndarray是 numpy 中最常用的对象之一,几乎所有的 numpy 函数都是基于ndarray进行计算的,因此熟练掌握ndarray的使用对于学习和使用 numpy 非常重要。
| 语文 | 数学 | 英语 | 政治 | 体育 |
|---|---|---|---|---|
| 87 | 55 | 87 | 64 | 63 |
| 61 | 83 | 93 | 76 | 99 |
| 89 | 78 | 100 | 63 | 90 |
| 84 | 71 | 47 | 100 | 73 |
| 40 | 73 | 94 | 53 | 71 |
| 99 | 63 | 71 | 41 | 41 |
| 57 | 52 | 72 | 61 | 66 |
可以使用ndarray进行存储:
import numpy as np
score = np.array(
[[ 87 55 87 64 63]
[ 61 83 93 76 99]
[ 89 78 100 63 90]
[ 84 71 47 100 73]
[ 40 73 94 53 71]
[ 99 63 71 41 41]
[ 57 52 72 61 66]]
)
print(score)
提问:使用 python 列表 list 可以存储一维数组,通过列表的嵌套可以实现多维数组,那么为什么还需要使用 numpy 的ndarray呢?
3.1.1 ndarray 与 python 原生的 list 运算效率对比
在这里我们通过一段代码运行来体会到 ndarray 的好处。
import numpy as np
import time
import random
a = []
for i in range(100000000):
a.append(random.random())
# 通过%time魔法方法查看当前代码运行一行所花费的时间
%time sum1 = sum(a)
b = np.array(a)
%time sum2 = np.sum(b)
"""
cpu times: total: 250 ms
wall time: 429 ms
cpu times: total: 31.2 ms
wall time: 106 ms
"""
从中我们看到ndarray的计算速度要快很多,节约了时间。
机器学习的最大特点就是大量的数据运算,那么如果没有一个快速的解决方案,那可能现在 python 也在机器学习领域达不到好的效果。
numpy 专门针对ndarray的操作和运算进行了设计,所以数组的存储效率和输入输出性能远优于 python 中的嵌套列表,数组越大,numpy 的优势就越明显。
思考:ndarray为什么可以这么快?
3.1.2 ndarray 的优势
- 内存块风格
- ndarray 支持并行化运算(向量化运算)
- 效率远高于纯 python 代码
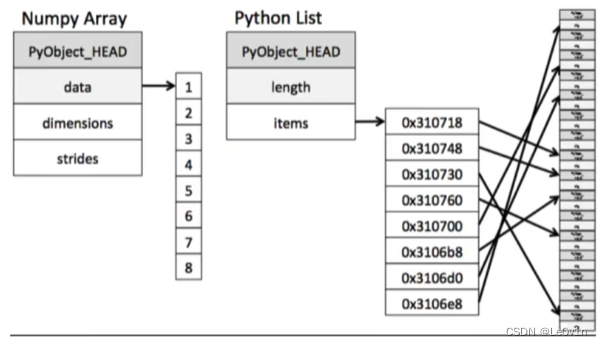
一、内存块风格
从图中我们可以看出ndarray在存储数据的时候,数据与数据的地址都是连续的,这样就给使得批量操作数组元素时速度更快。
这是因为ndarray中的所有元素的类型都是相同的,而 python 列表中的元素类型是任意的,所以ndarray在存储元素时内存可以连续,而 python 原生 list 就只能通过寻址方式找到下一个元素,这虽然也导致了在通用性能方面 numpy 的ndarray不及 python 原生 list,但在科学计算中,numpy 的ndarray就可以省掉很多循环语句,代码使用方面比 python 原生 list 简单的多。
ndarray存储元素的数据类型必须相同。这是由于ndarray中的所有元素在内存中是连续存储的,而不同类型的数据在内存中所占用的空间大小不同,因此如果存储不同类型的数据,就无法保证在内存中的连续性和一致性。
在创建ndarray时,可以通过指定dtype参数来指定数据类型,如果不指定,则默认为float64类型。例如,可以通过以下方式创建一个存储整数类型的一维数组:
import numpy as np
arr = np.array([1, 2, 3], dtype=int)
在这个例子中,通过dtype=int指定了数组的数据类型为整数类型。如果不指定dtype,则默认为float64类型。
需要注意的是,如果在创建ndarray时指定的数据类型与数组中的元素类型不匹配,则会自动进行类型转换。例如,如果将一个整数类型的数组赋值给一个浮点类型的数组,则会自动将整数类型转换为浮点类型。但是,在进行类型转换时需要注意数据精度的问题,避免数据精度的损失。
二、ndarray 支持并行化运算(向量化运算)
numpy 内置了并行运算功能,当系统有多个核心时,在做某种计算时,numpy 会自动做并行计算。
三、ndarray 支持并行化运算(向量化运算)
numpy 底层使用 c 语言编写,内部解除了 gil(全局解释器锁),其对数组的操作速度不受 python 解释器的限制,所以,其效率远高于纯 python 代码。
小结:
- numpy 的介绍【了解】
- 一个开源的 python 科学计算库
- 计算起来要比 python 简洁高效
- numpy 使用
ndarray对象来处理多维数组
ndarray介绍【了解】- numpy 提供了一个
n维数组类型ndarray,它描述了相同类型的item的集合。 - 生成 numpy 对象:
np.array()
- numpy 提供了一个
ndarray的优势【掌握】- 内存块风格
list– 分离式存储,存储内容多样化ndarray– 一体式存储,存储类型必须一样
ndarray支持并行化运算(向量化运算)ndarray底层是用 c 语言写的,效率更高,不受 gil 的影响
- 内存块风格
3.2 ndarray的属性、形状、类型
学习目标:了解数组的属性、形状、类型。
3.2.1 ndarray的属性
数组属性反映了数组本身固有的信息。
| 属性名字 | 返回值 |
|---|---|
ndarray.shape | 数组维度的元组 |
ndarray.ndim | 数组维数 |
ndarray.size | 数组中的元素数量(容器的大小) |
ndarray.itemsize | 一个数组元素的长度(字节) |
ndarray.dtype | 数组元素的类型 |
3.2.2 ndarray的形状
a = np.array([[1, 2, 3], [4, 5, 6]])
b = np.array([1, 2, 3, 4])
c = np.array([[[1, 2, 3], [4, 5, 6]], [[1, 2, 3], [4, 5, 6]]])
print(a.shape) # (2, 3)
print(b.shape) # (4,)
print(c.shape) # (2, 2, 3)
print(a.ndim, "维") # 2维
print(b.ndim, "维") # 1维
print(c.ndim, "维") # 3维
3.2.3 ndarray的类型
type(score.dtype) # numpy.dtype[int32]
dtype 是 numpy.dtype 类型,先看看对于数组来说都有哪些类型:
| 名称 | 描述 | 简写 |
|---|---|---|
np.bool | 用一个字节存储的布尔类型(true或false) | 'b' |
np.int8 | 一个字节大小,-128 ~ 127 ( − 2 7 → 2 7 − 1 -2^7 \to 2^7-1 −27→27−1) | 'i' |
np.int16 | 整数, − 2 15 -2^{15} −215(-32768) ~ 2 15 − 1 2^{15}-1 215−1(32767) | 'i2' |
np.int32 | 整数, − 2 31 -2^{31} −231 ~ 2 31 − 1 2^{31}-1 231−1 | 'i4' |
np.int64 | 整数, − 2 63 -2^{63} −263 ~ 2 63 − 1 2^{63}-1 263−1 | 'i8' |
np.uint8 | 无符号整数,0 ~ 255( 2 8 − 1 2^{8} - 1 28−1) | 'u' |
np.uint16 | 无符号整数,0 ~ 65535( 2 16 − 1 2^{16}-1 216−1) | 'u2' |
np.uint32 | 无符号整数,0 ~ 2 32 − 1 2^{32}-1 232−1 | 'u4' |
np.uint64 | 无符号整数,0 ~ 2 64 − 1 2^{64}-1 264−1 | 'u8' |
np.float16 | 半精度浮点数:16 位,正负号 1 位,指数 5 位,精度 10 位 | f2 |
np.float32 | 单精度浮点数:32 位,正负号 1 位,指数 8 位,精度 23 位 | f4 |
np.float64 | 双精度浮点数:64 位,正负号 1位,指数 11 位,精度 52 位 | f8 |
np.complex64 | 复数,分别用两个 32 位浮点数表示实部和虚部 | 'c8' |
np.complex128 | 复数,分别用两个 64 位浮点数表示实部和虚部 | 'c16' |
np.object_ | python 对象 | 'o' |
np.string_ | 字符串 | 's' |
np.unicode_ | unicode 类型 | 'u' |
创建数组的时候指定类型,若不指定,整数默认 int64,小数默认为 float64。
a = np.array([[1, 2, 3], [4, 5, 6]], dtype=np.float32)
print(a.dtype) # float32
# 类型转换
b = a.astype(np.int64) # 不改变原ndarray的dtype,需要新的ndarray数组接收
print(a.dtype) # float32
print(b.dtype) # int64
a.dtype = np.float16
print(a.dtype) # float16
# ndarray存储字符串
c = np.array([["python", "hello"], ["hello", "world"]])
print(c.dtype) # <u6
3.3 ndarray 的基本操作
学习目标:
- 理解数组的各种生成方法
- 应用数组的索引机制实现数组的切片获取
- 应用维度变换实现数组的形状改变
- 应用类型变换实现数组类型改变
- 应用数组的转换
3.3.1 [生成数组]生成 0 和 1 的数组
np.ones(shape, dtype)np.ones_like(a, dtype)np.zeros(shape, dtype)np.zeros_like(a, dtype)
其中:
shape为形状的 tuple 或 lista为一个 ndarray 数组
例子:
"""
生成0和1的数组
1. np.ones(shape, dtype)
2. np.ones_like(a, dtype)
3. np.zeros(shape, dtype)
4. np.zeros_like(a, dtype)
其中:
shape为形状的tuple或list
a为一个ndarray数组
"""
# 1. np.ones(shape, dtype)
a = np.ones([4, 8], dtype=np.int64)
a = np.ones((4, 8), dtype=np.int64) # 两种方法都可以
print(a)
"""
[[1 1 1 1 1 1 1 1]
[1 1 1 1 1 1 1 1]
[1 1 1 1 1 1 1 1]
[1 1 1 1 1 1 1 1]]
"""
# 2. np.ones_like(a, dtype)
b = np.ones_like(a, dtype=np.float64)
print(b)
"""
[[1. 1. 1. 1. 1. 1. 1. 1.]
[1. 1. 1. 1. 1. 1. 1. 1.]
[1. 1. 1. 1. 1. 1. 1. 1.]
[1. 1. 1. 1. 1. 1. 1. 1.]]
"""
## 3. np.zeros(shape, dtype)
c = np.zeros([3, 3])
print(c)
print(c.dtype) # float64
"""
[[0. 0. 0.]
[0. 0. 0.]
[0. 0. 0.]]
"""
## 4. np.zeros_like(a, dtype)
d = np.zeros_like(a, dtype=np.int64)
print(d)
"""
[[0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0]]
"""
3.3.2 [生成数组]从现有数组生成
从现有数组生成新数组的方式有两种方式:
np.array(object, dtype):深拷贝np.asarray(a, dtype):浅拷贝
示例:
a = np.array([[1, 2, 3], [4, 5, 6]])
# 从现有的数组当中创建
a1 = np.array(a)
print(a1)
"""
[[1 2 3]
[4 5 6]]
"""
# 相当于索引的形式,并没有真正的创建一个新的数组
a2 = np.asarray(a)
print(a2)
"""
[[1 2 3]
[4 5 6]]
"""
两种从现有数组生成新数组方式的不同之处:
np.array(arr)是深拷贝np.asarray(arr)是浅拷贝
示例:
a = np.array([[1, 2, 3], [4, 5, 6]])
print(a)
"""
[[1 2 3]
[4 5 6]]
"""
# 深拷贝
a1 = np.array(a)
print(a1)
"""
[[1 2 3]
[4 5 6]]
"""
# 浅拷贝
a2 = np.asarray(a)
print(a2)
"""
[[1 2 3]
[4 5 6]]
"""
# 修改值
a[0, 0] = 100
print(a)
"""
[[100 2 3]
[ 4 5 6]]
"""
print(a1)
"""
[[1 2 3]
[4 5 6]]
"""
print(a2)
"""
[[100 2 3]
[ 4 5 6]]
"""
3.3.3 [生成数组]生成固定范围的数组
有三种方式:
np.linspace(start, stop, num, endpoint)- 作用:创建等差数组一指定数量
- 参数:
start:序列的起始值stop:序列的终止值num:要生成的等间隔样例数量,默认为50endpoint:序列中是否包含stop值,默认为true
np.arange(start, stop, step, dtype)- 作用:创建等差数组并指定步长
- 参数:
start:序列的起始值stop:序列的终止值step:步长,默认值为1
np.logspace(start, stop, num)- 作用:创建等比数列(默认以10为底,修改参数
base即可) - 参数:
num:要生成的等比数列数量,默认为50
- 作用:创建等比数列(默认以10为底,修改参数
举例:
# 1. np.linspace(start, stop, num, endpoint)
arr = np.linspace(0, 100, 11)
print(arr) # [ 0. 10. 20. 30. 40. 50. 60. 70. 80. 90. 100.]
print(arr.dtype) # float64
print(arr.shape) # (11,)
print(arr.ndim) # 1
arr = np.linspace(0, 100, 11, dtype=np.int64)
print(arr) # [ 0 10 20 30 40 50 60 70 80 90 100]
# 2. np.arange(start, stop, step, dtype)
arr = np.arange(0, 10, 2)
print(arr) # [0 2 4 6 8]
print(arr.dtype) # int32
# 3. np.logspace(start, stop, num)
arr = np.logspace(0, 2, 3)
print(arr) # [ 1. 10. 100.]
print(arr.dtype) # float64
3.3.4 [生成数组]生成随机数组
核心:np.random模块。
场景一:正态分布
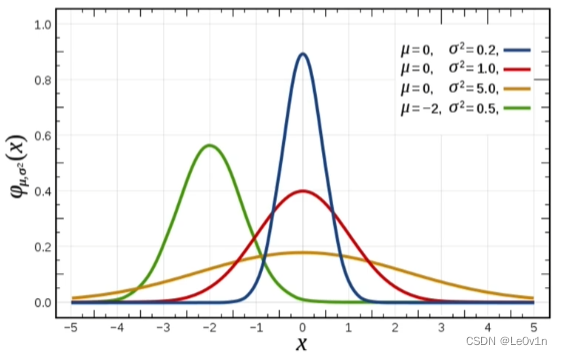
一、基础概念复习:正态分布(理解)
a. 什么是正态分布?
正态分布是一种概率分布。正态分布是具有两个参数 μ \mu μ 和 σ \sigma σ 的连续型随机变量的分布,第一参数 μ \mu μ 是服从正态分布的随机变量的均值,第二个参数 σ \sigma σ 是此随机变量的方差,所以正态分布记作 n ( μ , σ ) n(\mu, \sigma) n(μ,σ)。
b. 正态分布的应用?
生活、生产与科学实验中很多随机变量的概率分布都可以近似地用正态分布来描述。
c. 正态分布特点
- μ \mu μ 决定了其位置,其标准差 σ \sigma σ 决定了分布的幅度( σ \sigma σ 越大,越矮胖, σ \sigma σ 越小,越高瘦)。
- 当 μ = 0 , σ = 1 \mu=0, \sigma=1 μ=0,σ=1 时的正态分布是标准正态分布。
d. μ \mu μ 和 σ \sigma σ 的求解:
- 均值: μ = x 1 + x 2 + . . . + x n n \mu = \frac{x_1+ x_2 + ... + x_n}{n} μ=nx1+x2+...+xn
- 方差: σ 2 = ( x 1 − μ ) 2 + ( x 2 − μ ) 2 + . . . + ( x n − μ ) 2 n \sigma^2 = \frac{(x_1-\mu)^2 + (x_2 - \mu)^2 + ... + (x_n - \mu)^2}{n} σ2=n(x1−μ)2+(x2−μ)2+...+(xn−μ)2
- 标准差: σ = ( x 1 − μ ) 2 + ( x 2 − μ ) 2 + . . . + ( x n − μ ) 2 n = = 1 n ∑ i = 1 n ( x i − μ ) 2 \sigma = \sqrt{\frac{(x_1-\mu)^2 + (x_2 - \mu)^2 + ... + (x_n - \mu)^2}{n}} == \sqrt{\frac{1}{n}\sum_{i=1}^n(x_i-\mu)^2} σ=n(x1−μ)2+(x2−μ)2+...+(xn−μ)2==n1∑i=1n(xi−μ)2
其中 n n n 为数据总个数。
e. 标准差 σ \sigma σ 与方差 σ 2 \sigma^2 σ2 的意义:
可以理解为为数据的离散程度:
- 当标准差 σ \sigma σ 越大时,数据越分散
- 当标准差 σ \sigma σ 越小时,数据越紧密
二、正态分布创建方式
np.random.randn(d0, d1, ..., dn)- 功能:从标准正态分布中返回一个或多个样本值
- 参数:
d0, d1, ..., dn为返回值的shape
np.random.normal(loc=0.0, scale=1.0, size=none)- 功能:用于生成符合正态分布(高斯分布)的随机数
- 参数:
loc: float:此概率分布的均值 μ \mu μ(对应着整个分布的中心 centre)scale: float:此概率分布的标准差 σ \sigma σ(对应于分布的宽度,scale越大越矮胖;scale越小,越瘦高)size: int or tuple of ints:输出的 shape,默认为 none,只输出一个值
np.random.standard_normal(size=none)- 功能:返回指定形状标准正态分布的数组。
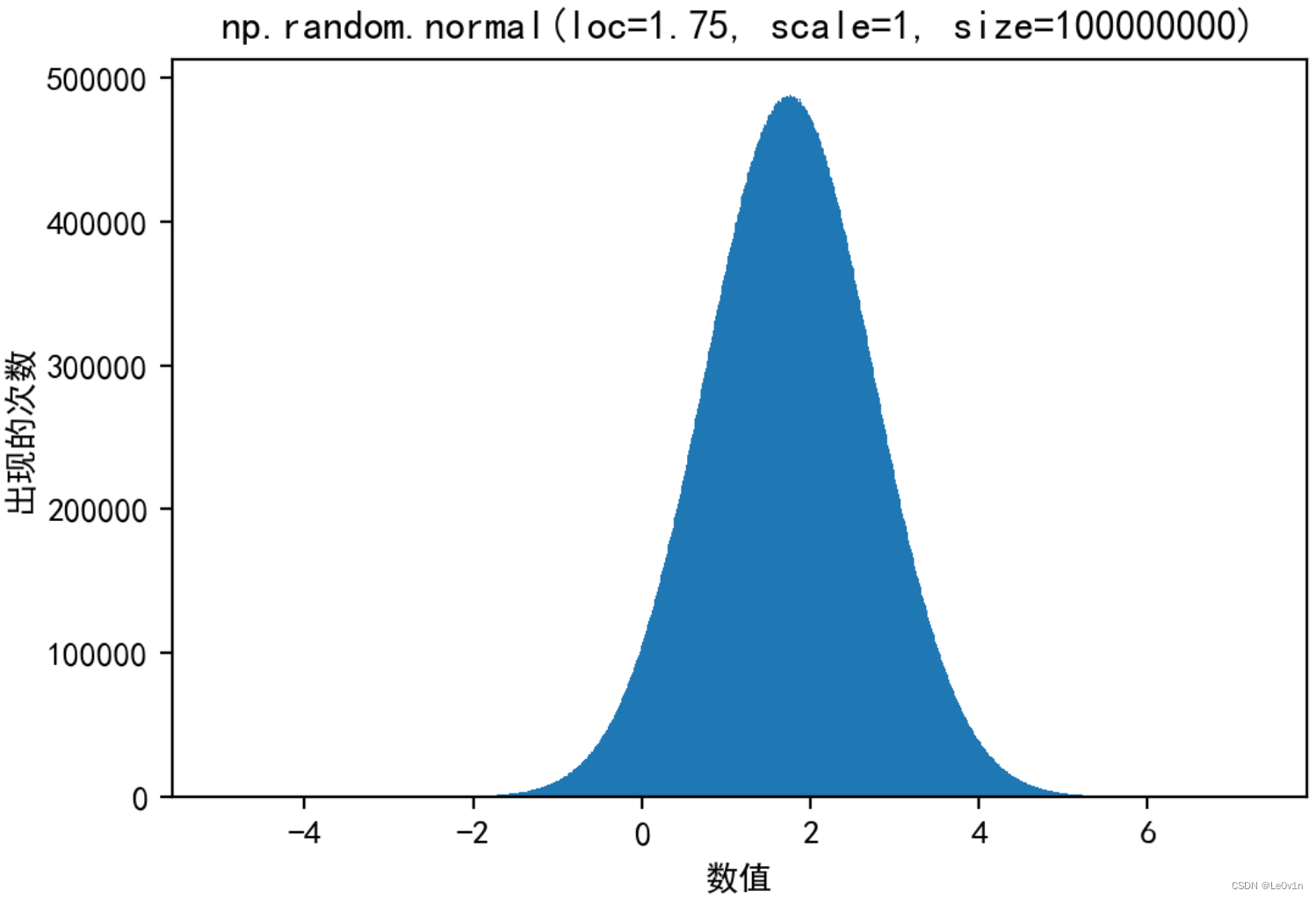
举例 1:生成均值为 1.75,标准差为 1 的正态分布数据,100000000 个
x1 = np.random.normal(loc=1.75, scale=1, size=100000000)
print(x1) # [2.9201503 2.00146211 1.42538312 ... 2.37253866 3.15273716 1.4312834 ]
print(x1.shape) # (100000000,)
画出该图像:
import numpy as np
import matplotlib.pyplot as plt
from pylab import mpl
# 设置中文字体
mpl.rcparams["font.sans-serif"] = ["simhei"]
# 设置正常显示符号
mpl.rcparams["axes.unicode_minus"] = false
x1 = np.random.normal(loc=1.75, scale=1, size=100000000)
plt.figure()
plt.hist(x1, 1000) # plt.hist(数据,组距)
plt.xlabel("数值")
plt.ylabel("出现的次数")
plt.title("np.random.normal(loc=1.75, scale=1, size=100000000)")
plt.show()
举例 2:随机生成 4 支股票 1 周的交易日涨幅数据。
随机生成涨跌幅在某个正态分布内,比如均值 0,方差 1:
# 创建符合正态分布的4只股票5天的涨跌幅数据
stock_change = np.random.normal(loc=0, scale=1, size=[4, 5])
print(stock_change)
返回结果:
[[ 1.74073454 0.13384577 -1.15700707 0.4169004 -0.30539835]
[-0.62736583 0.01223323 -0.00524497 0.61583305 -0.98697203]
[ 0.59925948 0.45820375 -1.86175106 -0.59848094 -0.29423742]
[-2.83592608 -0.90993324 0.99710497 -0.65825899 0.934991 ]]
场景二:均匀分布
np.random.rand(d0, d1, ..., dn)- 功能:返回
[0.0, 1.0)区间的一组均匀分布的数。 - 参数:
d0, d1, ..., dn为返回值的shape
- 功能:返回
np.random.uniform(low=0.0, high=1.0, size=none)- 功能:从一个均匀分布
[low,high)区间中随机采样,注意定义域是左闭右开,即包含low,不包含high。 - 参数介绍:
low:采样下界,float 类型,默认值为0;high:采样上界,float 类型,默认值为1;size:输出样本数目,为 int 或元组 (tuple) 类型,例如,size=(m, n, k),则输出mnk个样本,缺省时输出1个值。
- 返回值:ndarray类型,其形状和参数size中描述一致。
- 功能:从一个均匀分布
np.random.randint(low, high=none, size=none, dtype=)- 功能:从一个均匀分布中随机采样,生成一个整数或n维整数数组
- 取数范围:若 high 不为 none 时,取
[low,high)区间的随机整数,否则取值[0,low)区间的随机整数。
示例:
# 1. np.random.rand(d0, d1, ..., dn)
arr1 = np.random.rand(2, 3)
print(arr1)
"""
[[0.03633364 0.35502351 0.18559704]
[0.72854027 0.80302261 0.82313366]]
"""
# 2. np.random.uniform(low=0.0, high=1.0, size=none)
arr2 = np.random.uniform(low=1, high=10, size=[2, 3])
print(arr2)
"""
[[2.04443524 4.44514576 4.41786813]
[7.25102016 5.02834325 9.75242862]]
"""
# 3. np.random.randint(low, high=none, size=none, dtype=)
arr3 = np.random.randint(0, 10, size=[2, 3])
print(arr3)
"""
[[6 2 6]
[1 7 8]]
"""
画图:
import numpy as np
import matplotlib.pyplot as plt
from pylab import mpl
# 设置中文字体
mpl.rcparams["font.sans-serif"] = ["simhei"]
# 设置正常显示符号
mpl.rcparams["axes.unicode_minus"] = false
x2 = np.random.uniform(-1, 1, 10000000)
plt.figure()
plt.hist(x2, 1000)
plt.xlabel("数值")
plt.ylabel("出现的次数")
plt.title("np.random.uniform(low=0.0, high=1.0, size=none)")
plt.show()

3.3.5 数组的索引、切片
一维、二维、三维的数组如何索引?
- 直接进行索引,切片
- 对象
[:, :]:先行后列
示例:
# 二维数组
arr_2d = np.random.normal(loc=0, scale=1, size=[4, 5])
print(arr_2d, "\r\n")
"""
[[ 0.66610887 0.60331317 0.75724806 0.65241078 -1.09456943]
[-0.70859007 0.45414909 0.00162145 -0.60455284 -1.43747196]
[ 0.36120038 0.51901282 -0.60272547 1.18274746 1.14338992]
[ 0.08029827 -0.65563637 1.50467988 -0.25218452 1.03742514]]
"""
print(arr_2d[0, 0:3], "\r\n")
"""
[0.66610887 0.60331317 0.75724806]
"""
# 三维数组
arr_3d = np.random.randint(0, 100, size=[2, 3, 4])
print(arr_3d, "\r\n")
"""
[[[53 74 59 48]
[35 19 73 92]
[25 92 95 86]]
[[56 8 66 17]
[62 95 94 4]
[31 32 92 19]]]
"""
print(arr_3d[-1, :, 1:])
"""
[[ 8 66 17]
[95 94 4]
[32 92 19]]
"""
3.3.6 形状修改
一般有三种修改 ndarray 形状的接口:
ndarray.reshape(shape, order)ndarray.resize(new_shape)ndarray.t
第一种:ndarray.reshape(shape, order)
- 功能:返回一个具有相同数据域,但 shape 不一样的视图
- 参数:
shape:新的形状order:顺序- 有返回值(浅拷贝)
- 注意:
reshape函数会返回一个新的数组,而不会改变原始数组的形状。如果需要改变原始数组的形状,可以使用ndarray.resize(new_shape)函数- 可以使用
-1来自动推导形状
示例:
arr = np.random.random(size=[4, 5])
print(arr.shape) # (4, 5)
# 1. ndarray.reshape(shape, order)
arr.reshape([5, 4])
print(arr.shape) # (4, 5)
arr.reshape([2, -1])
print(arr.shape) # (4, 5)
# reshape函数会返回一个新的数组,而不会改变原始数组的形状
new_arr = arr.reshape([5, 4])
print(new_arr.shape) # (5, 4)
# 可以使用-1来自动推导形状
new_arr = arr.reshape([10, -1])
print(new_arr.shape) # (10, 2)
需要注意的是,如果原数组是一个视图(view),则reshape操作也会返回一个视图,而不是创建新的数组对象。视图是共享数据存储的,因此,对视图的修改会影响原数组的数据。可以使用numpy.base属性来判断数组是否是视图,如果是视图,则numpy.base属性返回它所共享数据存储的原始数组对象,如果不是,则返回 none。
以下是一个示例代码:
import numpy as np
# 创建一个数组
a = np.array([1, 2, 3, 4, 5, 6])
# 创建一个视图
b = a[0:4]
# reshape操作返回一个新的数组对象
c = a.reshape(2, 3)
print(a) # [1 2 3 4 5 6]
print(b) # [1 2 3 4]
print(c) # [[1 2 3]
# [4 5 6]]
# 修改新数组会影响原数组(reshape是浅拷贝),也会影响视图
c[0, 0] = 0
print(a) # [0 2 3 4 5 6]
print(b) # [0 2 3 4]
print(c) # [[0 2 3]
# [4 5 6]]
# 视图的reshape操作返回一个视图
d = b.reshape(2, 2)
print(d) # [[0 2]
# [3 4]]
print(d.base) # [0 2 3 4 5 6]
第二种:ndarray.resize(new_shape)
- 功能:直接修改数组本身的形状(需要保持元素个数前后相同)
- 没有返回值(如果直接使用
=则是浅拷贝!) - 注意:
darray.resize(new_shape)函数会改变原始数组的形状并返回none- 不可以使用
-1来自动推导形状
示例:
arr = np.random.random(size=[4, 5])
print(arr.shape) # (4, 5)
# 2. ndarray.resize(new_shape)
arr.resize([5, 4])
print(arr.shape) # (5, 4)
arr.resize([2, 10])
print(arr.shape) # (2, 10)
# 不可以使用-1来自动推导形状
arr.resize([-1, 10])
print(arr.shape) # valueerror: negative dimensions not allowed
第三种:ndarray.t
- 数组的转置:将数组的行、列行互换
- 返回转置后的数组(浅拷贝,相当于是视图 view)
arr.t返回一个转置后的ndarray对象,这个操作是浅拷贝。它不会创建新的数组对象,而是返回原数组的一个视图,只是视图的维度顺序发生了变化。
如果需要创建一个新的数组对象,可以使用np.transpose方法,它会返回一个转置后的新数组对象,不会影响原数组。
示例:
arr = np.random.random(size=[4, 5])
print(arr.shape) # (4, 5)
# 3. ndarray.t
new_arr = arr.t
print(arr.shape) # (4, 5)
print(new_arr.shape) # (5, 4)
3.3.7 类型修改
ndarray 类型的修改一般有两种方法:
ndarray.astype(new_type)ndarray.tostring([order]) / ndarray.tobytes([order])
第一种:ndarray.astype(type)
- 作用:返回修改类型之后的数组
- 注意:
ndarray.astype(type)返回一个新的ndarray数组,其中的数据类型被转换成了指定的type。这个操作是深拷贝。
这意味着,如果你修改了新数组中的元素,原数组中对应的元素不会被修改。
示例:
arr = np.array([[1, 2, 3], [4, 5, 6]])
print(arr)
"""
[[1 2 3]
[4 5 6]]
"""
new_arr = arr.astype(np.float32)
print(new_arr)
"""
[[1. 2. 3.]
[4. 5. 6.]]
"""
# 深拷贝、浅拷贝测试
arr[0][0] = 10
print(arr)
"""
[[10 2 3]
[ 4 5 6]]
"""
print(new_arr)
"""
[[1. 2. 3.]
[4. 5. 6.]]
"""
第二种:ndarray.tobytes([order])
- 作用:构造包含数组中原始数据字节的 python 字节。
- 用途:主要用途是将数组中的原始数据转换为 python 字节对象。这样可以将数组中的数据以二进制形式存储或传输。例如,可以使用此方法将数组数据写入文件或通过网络发送。
示例:
arr = np.array([[1, 2, 3], [4, 5, 6]])
arr_string = arr.tobytes()
print(arr_string)
"""
"\nb'\x01\x00\x00\x00\x02\x00\x00\x00\x03\x00\x00\x00\x04\x00\x00\x00\x05\x00\x00\x00\x06\x00\x00\x00'\n"
"""
3.3.8 数组的去重
np.unique(arr, return_index=false, return_inverse=false, return_counts=false,)- 作用:返回去重后的数组,对原数组无影响(深拷贝)。
- 参数:
arr:传入的数组return_index=true:返回ndarray索引,该索引为新数组(去重后的数组)元素在原数组中的位置return_inverse=true:返回ndarray索引,该索引为原数组元素在新数组(去重后的数组)中的位置return_counts=true:返回ndarray索引,该索引为新数组(去重后的数组)元素在原数组中出现的次数
- 返回值:去重后的
ndarray 数组 + [idx](看return_index,return_inverse,return_counts是否为true)
np.unique 函数用于找出数组中独一无二的元素值,并按照从小到大排序。它的参数包括 ar,return_index,return_inverse 和 return_counts。ar 是输入数组,除非设定了 axis 参数,否则输入数组均会被自动扁平化成一个一维数组。return_index 是一个可选参数,如果为 true 则结果会同时返回被提取元素在原始数组中的索引值。return_inverse 是一个可选参数,如果为 true 则结果会同时返回原始数组中的元素在新数组中的索引值。return_counts 是一个可选参数,如果为 true 则结果会同时返回去重数组中的元素在原数组中的出现次数。
示例:
arr = np.array([1, 2, 3, 4, 1, 1, 2])
print(arr) # [1 2 3 4 1 1 2]
# 默认返回去重后的ndarray
unique_arr = np.unique(arr)
print(unique_arr) # [1 2 3 4]
# return_index=true:返回去重后的ndarray及其元素在原数组(arr)中的索引
unique_arr, idx = np.unique(arr, return_index=true)
print(unique_arr) # [1 2 3 4]
print(idx) # [0 1 2 3]
# return_inverse=true:返回去重后的ndarray和arr中的元素在unique_arr的位置
unique_arr, idx = np.unique(arr, return_inverse=true)
print(unique_arr) # [1 2 3 4]
print(idx) # [0 1 2 3 0 0 1]
# return_counts=true:返回去重后的ndarray及其元素在arr中出现的次数
unique_arr, idx = np.unique(arr, return_counts=true)
print(unique_arr) # [1 2 3 4]
print(idx) # [3 2 1 1]
小结:
- 创建数组【掌握】
- 生成 0 和 1 的数组
np.ones()np.ones_like()
- 从现有数组中生成
np.array()– 会创建一个新的数组,它是原数组的一个深拷贝。这意味着,如果你修改了新数组中的元素,原数组中对应的元素不会被修改。np.asarray– 当 dtype 相同时,指针指向的内存相同,属于浅拷贝。当 dtype 不同时,使用深拷贝。
- 生成固定范围数组
np.linspace()num– 生成等间隔的多少个
np.arange()step– 每间隔多少生成数据
np.logspace()- 生成以 10 为底的 n 次幂的数据
- 生成随机数组
- 正态分布
- 均值: μ \mu μ
- 标准差: σ \sigma σ
- μ \mu μ – 决定了这个图形的左右位置
- σ \sigma σ – 决定了这个图形是瘦高还是矮胖
- 方法1:
np.random.randn() - 方法2:
np.random.normal(0, 1, 100)
- 均匀分布
- 方法1:
np.random.rand() - 方法2:
np.random.uniform(0, 1, 100) - 方法3:
np.random.randint(0, 10, 10)
- 方法1:
- 正态分布
- 生成 0 和 1 的数组
- 数组索引【知道】
- 直接进行索引,切片
- 对象
[:, :]– 先行后列
- 数组形状改变【掌握】
ndarray.reshape(new_shape) -> ndarray- 不修改原来的ndarray
- 深拷贝
ndarray.resize() -> none- 修改原来的 ndarray
- 使用
=赋值则是浅拷贝
ndarray.t -> view- 不修改原来的 ndarray
- 浅拷贝
- 数组去重【知道】
np.unique(ndarray)
3.4 ndarray的运算
学习目标:
- 应用数组的通用判断函数
- 应用
np.where实现数组的三元运算
q:如果想要操作符合某一条件的 ndarray 数据,应该怎么做?
a:接下来要学习的内容就是解决这一问题的。
3.4.1 逻辑运算
语法:ndarray > int
示例:
np.random.seed(10086)
# 生成10名同学,5门功课的数据
score = np.random.randint(40, 100, size=[10, 5])
# 取出最后4名同学的成绩,用于逻辑判断
test_score = score[-4:, :]
print(test_score)
"""
[[77 90 92 53 59]
[99 61 78 45 46]
[47 82 49 53 49]
[85 95 87 68 41]]
"""
# bool赋值,将满足条件的设置为指定的值 -> bool索引
condiction_idx = test_score > 60
print(condiction_idx)
print(type(condiction_idx)) # <class 'numpy.ndarray'>
print(condiction_idx.dtype) # bool
"""
[[ true true true false false]
[ true true true false false]
[false true false false false]
[ true true true true false]]
"""
test_score[test_score > 60] = 1
print(test_score)
"""
[[ 1 1 1 53 59]
[ 1 1 1 45 46]
[47 1 49 53 49]
[ 1 1 1 1 41]]
"""
3.4.2 通用判断函数
通用判断函数有两个:
np.all() -> bool:所有元素满足条件则返回 true,否则返回 falsenp.any() -> bool:任意元素满足条件则返回 true,否则返回 false
注意:
axis=0:先将 ndarray 展平后,按单个元素进行操作axis=1:按行进行操作axis=2:按列进行操作
示例:
print(score)
"""
[[96 50 76 94 44]
[97 48 47 98 79]
[91 85 47 76 70]
[97 75 75 74 77]
[73 48 58 71 94]
[69 44 92 87 65]
[ 1 1 1 53 59]
[ 1 1 1 45 46]
[47 1 49 53 49]
[ 1 1 1 1 41]]
"""
# 1. 判断前两名同学的成绩是否全及格 -> np.all()
res = np.all(score[:2, :] > 60)
print(res) # false
# 2. 判断前两名同学的成绩是否有大于90分的 -> np.any()
res = np.any(score[:2, :] > 90) # axis=none —— 按单个元素进行(将数组展平)
print(res) # true
res = np.any(score[:2, :] > 90, axis=0) # —— 按行进行
print(res) # [ true false false true false]
res = np.any(score[:2, :] > 90, axis=1) # —— 按列进行
print(res) # [ true true]
3.4.3 np.where(三元运算符)
通过使用np.where()函数能够进行更加复杂的运算。
np.where() 函数有两种用法。
- 第一种用法是
np.where(condition, x, y) -> ndarray- 参数:
condition是一个布尔数组x和y是两个数组
- 作用:返回相同的数组,元素均被
x, y替换 - 当
condition中的元素为true时,返回x中对应位置的元素; - 当
condition中的元素为false时,返回y中对应位置的元素。
- 参数:
- 第二种用法是
np.where(condition) -> tuple、- 参数:
condition是一个布尔数组。
- 作用:返回一个元组,其中包含满足条件(即值为
true)的元素的索引。 - 返回值说明:返回一个元组
tuple(ndarray1, ndarray2, ...) - 第一个数组表示第一维的索引(行)
- 第二个数组表示第二维的索引(列)
- …
- 参数:
[拓展]复合逻辑:结合np.logical_and和np.logical_or使用
np.logical_and 函数接受两个参数 x1 和 x2,它们都是数组。该函数返回一个布尔数组,其形状与 x1 和 x2 相同。返回数组中的每个元素都是对应位置的 x1 和 x2 元素的逻辑与运算结果。例如,如果 x1 和 x2 都是一维数组,那么返回数组中的第 i 个元素为 x1[i] and x2[i] 的结果。
np.logical_or函数同理。
示例:
np.random.seed(10086)
score = np.random.randint(40, 100, size=[5, 5])
print(score)
"""
[[96 50 76 94 44]
[97 48 47 98 79]
[91 85 47 76 70]
[97 75 75 74 77]
[73 48 58 71 94]]
"""
# 1. np.where(condition, x, y):返回相同的数组,元素均被x,y替换
res = np.where(score[:2, :] > 85, "g", "p")
print(res)
"""
[['g' 'p' 'p' 'g' 'p']
['g' 'p' 'p' 'g' 'p']]
"""
# 2. np.where(condition):返回一个元组,其中包含满足条件(即值为 `true`)的元素的索引。
res = np.where(score < 80)
print(res)
"""
(
array([0, 0, 0, 1, 1, 1, 2, 2, 2, 3, 3, 3, 3, 4, 4, 4, 4], dtype=int64),
array([1, 2, 4, 1, 2, 4, 2, 3, 4, 1, 2, 3, 4, 0, 1, 2, 3], dtype=int64)
)
其中,第一个数组表示行索引,第二个数组表示列索引。
如果 score 是一个三维数组,那么 res = np.where(score < 80) 的结果仍然是一个元组,
其中包含三个数组:
第一个数组表示第一维的索引
第二个数组表示第二维的索引
第三个数组表示第三维的索引。
"""
# 拓展:结合np.logical_and和np.logical_or使用
res = np.where(np.logical_and(score > 60, score < 90), "g", "p")
print(res)
"""
[['p' 'p' 'g' 'p' 'p']
['p' 'p' 'p' 'p' 'g']
['p' 'g' 'p' 'g' 'g']
['p' 'g' 'g' 'g' 'g']
['g' 'p' 'p' 'g' 'p']]
"""
res = np.where(np.logical_or(score > 60, score[:, 1:2] > 70), "g", "p")
print(res)
"""
[['g' 'p' 'g' 'g' 'p']
['g' 'p' 'p' 'g' 'g']
['g' 'g' 'g' 'g' 'g']
['g' 'g' 'g' 'g' 'g']
['g' 'p' 'p' 'g' 'g']]
"""
res = np.where(np.logical_and(score > 60, score < 90))
print(res)
"""
(array([0, 1, 2, 2, 2, 3, 3, 3, 3, 4, 4], dtype=int64),
array([2, 4, 1, 3, 4, 1, 2, 3, 4, 0, 3], dtype=int64))
"""
res = np.where(np.logical_or(score >60, score[:, 1:2] > 70))
print(res)
"""
(array([0, 0, 0, 1, 1, 1, 2, 2, 2, 2, 2, 3, 3, 3, 3, 3, 4, 4, 4], dtype=int64),
array([0, 2, 3, 0, 3, 4, 0, 1, 2, 3, 4, 0, 1, 2, 3, 4, 0, 3, 4], dtype=int64))
"""
3.5 统计运算
3.5.1 统计指标及其 api
在数据挖掘/机器学习领域,统计指标的值也是我们分析问题的一种方式。常用的指标如下:
min(a, axis):返回数组的最小值或沿轴的最小值。max(a, axis):返回数组的最大值或沿轴的最大值。median(a, axis):沿指定轴计算中位数。mean(a, axis, dtype):沿指定轴计算算术平均值。std(a, axis, dtype):沿指定轴计算标准差。var(a, axis, dtype):沿指定轴计算方差。np.argmax(a, axis):返回数组的最大值或沿轴的最大值元素的索引。np.argmin(a, axis):返回数组的最小值或沿轴的最小值元素的索引。
3.5.2 案例:学生成绩统计
进行统计的时候,axis 轴的取值并不一定,numpy 中不同的 api 轴的值都不一样,
在这里,axis=0 代表列,axis=1 代表行去进行统计。
q:怎么看行怎么看列?
a:其实很简单,如果是按行计算,那么应该返回行数量个结果;如果按列计算,那么应该返回列数量个结果。
示例:
import os
def print_separator(char='-'):
terminal_width = os.get_terminal_size().columns
print(char * terminal_width)
np.random.seed(10086)
score = np.random.randint(40, 100, size=[4, 5])
print(score)
"""
[[96 50 76 94 44]
[97 48 47 98 79]
[91 85 47 76 70]
[97 75 75 74 77]]
"""
np.set_printoptions(precision=2) # 设置numpy的精度
print("各科成绩的最大值分别为: {}".format(np.max(score, axis=0))) # [97 85 76 98 79]
print("各科成绩的最小值分别为: {}".format(np.min(score, axis=0))) # [91 48 47 74 44]
print("各科成绩的平均值分别为: {}".format(np.mean(score, axis=0))) # [95.25 64.5 61.25 85.5 67.5 ]
print("各科成绩的波动情况为: {}".format(np.std(score, axis=0))) # [ 2.49 15.91 14.25 10.62 13.97]
print("各科成绩的波动情况^2为: {}".format(np.var(score, axis=0))) # [ 6.19 253.25 203.19 112.75 195.25]
print_separator()
print("学生的最大成绩分别为: {}".format(np.max(score, axis=1))) # [96 98 91 97]
print("学生的最小成绩分别为: {}".format(np.min(score, axis=1))) # [44 47 47 74]
print("学生的最大成绩分别为: {}".format(np.mean(score, axis=1))) # [72. 73.8 73.8 79.6]
print("学生的偏科情况分别为: {}".format(np.std(score, axis=1))) # [21.65 22.52 15.22 8.75]
print("学生的偏科情况^2分别为: {}".format(np.var(score, axis=1))) # [468.8 506.96 231.76 76.64]
"""
进行统计的时候,axis轴的取值并不一定,numpy中不同的api轴的值都不一样,
在这里,axis=0代表列,axis=1代表行去进行统计。
q:怎么看行怎么看列?
a:其实很简单,如果是按行计算,那么应该返回行数量个结果;如果按列计算,那么应该返回列数量个结果。
"""
print_separator()
print("各科成绩最高的学生的索引分别为: {}".format(np.argmax(score, axis=0))) # [1 2 0 1 1]
print("各科成绩最低的学生的索引分别为: {}".format(np.argmin(score, axis=0))) # [2 1 1 3 0]
print_separator()
print("学生分数最高的科目分别为: {}".format(np.argmin(score, axis=1))) # [4 2 2 3]
小结:
- 逻辑运算【知道】
- 直接进行大于,小于的判断
- 合适之后,可以直接进行赋值
- 通用判断函数【知道】
np.all()np.any()
- 统计运算【掌握】
np.max()np.min()np.median()np.mean()np.std()np.var()np.argmax(axis=):返回最大元素对应的下标np.argmin(axis=):返回最小元素对应的下标
3.6 数组间的运算
学习目标:
- 知道数组与数之间的运算
- 知道数组与数组之间的运算
- 说明数组间运算的广播机制
3.6.1 数组与数的运算
我们先看一下 python 中的 list 与数的运算。
# 先看一下python中list的运算
lst = [1, 2, 3]
# print(lst + 3) # typeerror: can only concatenate list (not "int") to list
# print(lst - 3) # typeerror: unsupported operand type(s) for -: 'list' and 'int'
print(lst * 3) # [1, 2, 3, 1, 2, 3, 1, 2, 3]
print(lst / 3) # typeerror: unsupported operand type(s) for /: 'list' and 'int'
可以看到,python 的 list 不能和 int 进行 +-/,只能进行 *,即将 list 中的元素再扩充 int 倍。
结论:python 的列表支持加法和乘法运算,对减法和除法不支持:
- 加法只能两个
list相加 - 乘法是
list和int相乘
numpy 的 ndarray 与 list 不同,ndarray 是支持基本的与 int 数据类型的加减乘除的。
示例:
arr = np.array([[1, 2, 3], [3, 4, 5]])
print(arr)
"""
[[1 2 3]
[3 4 5]]
"""
print(arr + 3)
"""
[[4 5 6]
[6 7 8]]
"""
print(arr - 3)
"""
[[-2 -1 0]
[ 0 1 2]]
"""
print(arr * 3)
"""
[[ 3 6 9]
[ 9 12 15]]
"""
print(arr / 3)
"""
[[0.33333333 0.66666667 1. ]
[1. 1.33333333 1.66666667]]
"""
3.6.2 数组与数组的运算
arr1 = np.array([[1, 2, 3, 2, 1, 4], [5, 6, 1, 2, 3, 1]])
arr2 = np.array([[1, 2, 3, 4], [3, 4, 5, 6]])
print(arr1.shape) # (2, 6)
print(arr2.shape) # (2, 4)
# print(arr1 + arr2) # valueerror: operands could not be broadcast together with shapes (2,6) (2,4)
# print(arr1 - arr2) # valueerror: operands could not be broadcast together with shapes (2,6) (2,4)
# print(arr1 * arr2) # valueerror: operands could not be broadcast together with shapes (2,6) (2,4)
# print(arr1 / arr2) # valueerror: operands could not be broadcast together with shapes (2,6) (2,4)
可以看到,两个数组的 shape 不同,不能进行加减乘除,为了解决这个问题,我们需要了解 numpy 的广播机制。
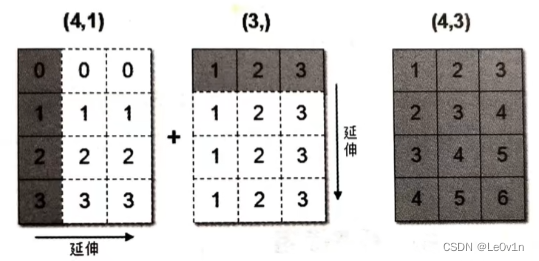
3.6.3 广播机制
数组在进行矢量化运算的,要求数组的形状是相等的。当形状不相等的数组执行算术运算的时候,就会出现广播机制,该机制会对数组进行扩展,使数组的 shape 属性值一样,这样,就可以进行矢量化运算了。
下面通过一个例子进行说明:
arr1 = np.array([[0], [1], [2], [3]])
arr2 = np.array([1, 2, 3])
print(arr1.shape) # (4, 1)
print(arr2.shape) # (3,)
print(arr1 + arr2)
"""
[[1 2 3]
[2 3 4]
[3 4 5]
[4 5 6]]
"""
print(arr1 - arr2)
"""
[[-1 -2 -3]
[ 0 -1 -2]
[ 1 0 -1]
[ 2 1 0]]
"""
print(arr1 * arr2)
"""
[[0 0 0]
[1 2 3]
[2 4 6]
[3 6 9]]
"""
print(arr1 / arr2)
"""
[[0. 0. 0. ]
[1. 0.5 0.33333333]
[2. 1. 0.66666667]
[3. 1.5 1. ]]
"""
上述代码中,数组 arr1 是 4 行 1 列,arr2 是 1 行 3 列。这两个数组要进行相加,按照广播机制会对数组 arr1 和 arr2 都进行扩展,使得数组 arr1 和 arr2 都变成4行3列。
下面通过一张图来描述广播机制扩展数组的过程:
广播机制实现了时两个或两个以上数组的运算,即使这些数组的 shape 不是完全相同的,只需要每个维度满足如下任意一个条件即可。
- 维度长度相等。
- 有一个的长度为 1。
广播机制需要扩展维度小的数组,使得它与维度最大的数组的 shape 值相同,以便使用元素级函数或者运算符进行运算。
如果是下面这样,则不匹配:
a (1d array): 10
b (1d array): 12
a (2d array): 2 × 1
b (2d array): 8 × 4 × 3
以上都不可以。

对于后面两个数组,从后往前看,1, 3 是可以的,但 2, 4 不行,所以不行。
思考:下面两个 ndarray 是否能够进行运算?
arr1 = np.array([[1, 2, 3, 2, 1, 4], [5, 6, 1, 2, 3, 1]])
arr2 = np.array([[1], [3]])
print(arr1.shape) # (2, 6)
print(arr2.shape) # (2, 1)
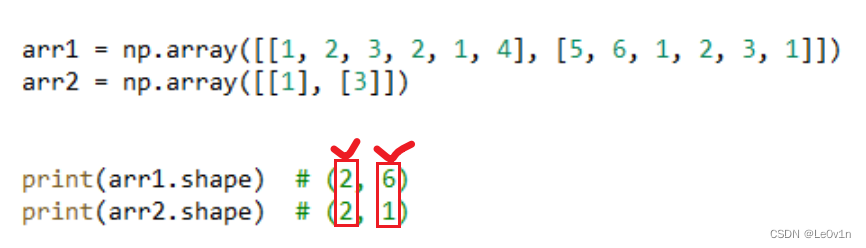
可以进行运算!
小结:
- 数组运算,满足广播机制。就 ok【知道】。
- 每个维度相等或维度为1
3.7 矩阵
矩阵,英文 matrix,和 array 的区别是:
- 矩阵必须是2维的
- 但是 array 可以是多维的
如图:这个是 3×2 矩阵,即 3 行 2 列,如 m m m 为行, n n n 为列,那么 m × n m\times n m×n 即 3×2。
[ 1 2 3 4 5 6 ] \begin{bmatrix} 1 & 2 \\ 3 & 4 \\ 5 & 6 \end{bmatrix} 135246
矩阵的维数即行数×列数。
矩阵元素(矩阵项):
a = [ 1 2 3 4 5 6 ] a=\begin{bmatrix} 1 & 2 \\ 3 & 4 \\ 5 & 6 \end{bmatrix} a= 135246
a i j a_{ij} aij 指第 i i i 行,第 j j j 列的元素。
3.8 向量
向量是一种特殊的矩阵,讲义中的向量一般都是列向量,下面展示的就是三维列向量 (3×1)。
a = [ 1 2 3 ] a = \begin{bmatrix} 1 \\ 2 \\ 3 \\ \end{bmatrix} a= 123
3.9 矩阵的加法和标量乘法
矩阵的加法:行列数相等的可以加。
例:
[ 1 2 3 4 5 6 ] + [ 1 2 3 4 5 6 ] = [ 2 4 6 8 10 12 ] \begin{bmatrix} 1 & 2\\ 3 & 4\\ 5 & 6\\ \end{bmatrix}+ \begin{bmatrix} 1 & 2\\ 3 & 4\\ 5 & 6\\ \end{bmatrix}= \begin{bmatrix} 2 & 4\\ 6 & 8\\ 10 & 12\\ \end{bmatrix} 135246 + 135246 = 26104812
矩阵的乘法:每个元素都要乘。
例:
3 × [ 1 2 3 4 5 6 ] = [ 3 6 9 12 15 18 ] 3 \times \begin{bmatrix} 1 & 2\\ 3 & 4\\ 5 & 6\\ \end{bmatrix}= \begin{bmatrix} 3 & 6\\ 9 & 12\\ 15 & 18\\ \end{bmatrix} 3× 135246 = 391561218
组合算法也是类似的。
3.10 矩阵向量的乘法
矩阵和向量的乘法如图: m × n m\times n m×n 的矩阵乘以 n × 1 n\times 1 n×1 的向量,得到的是 m × 1 m \times 1 m×1 的向量。
例:
[ 1 3 4 0 2 1 ] 3 × 2 × [ 1 5 ] 2 × 1 = [ 16 4 7 ] 3 × 1 \begin{bmatrix} 1 & 3 \\ 4 & 0 \\ 2 & 1 \\ \end{bmatrix}_{3\times 2} \times \begin{bmatrix} 1 \\ 5 \end{bmatrix}_{2\times 1} = \begin{bmatrix} 16\\ 4\\ 7 \end{bmatrix}_{3\times 1} 142301 3×2×[15]2×1= 1647 3×1
1 * 1 + 3 * 5 = 16
4 * 1 + 0 * 5 = 4
2 * 1 + 1 * 5 = 7
矩阵乘法遵循准则:
( m 行 , n 列 ) × ( n 行 , l 列 ) = ( m 行 , l 列 ) (m行, n列) \times (n行, l列) = (m行, l列) (m行,n列)×(n行,l列)=(m行,l列)
c = a × b [ c 0 c 1 c 2 c 3 ] = [ a 0 a 1 a 2 a 3 ] × [ b 0 b 1 b 2 b 3 ] c 0 = a 0 × b 0 + a 1 × b 2 c 1 = a 0 × b 1 + a 1 × b 3 c 2 = a 2 × b 0 + a 3 × b 2 c 3 = a 2 × b 1 + a 3 × b 3 c = a \times b \\ \begin{bmatrix} c_0 & c_1 \\ c_2 & c_3 \end{bmatrix} = \begin{bmatrix} a_0 & a_1 \\ a_2 & a_3 \end{bmatrix} \times \begin{bmatrix} b_0 & b_1 \\ b_2 & b_3 \end{bmatrix}\\ c_0 = a_0 \times b_0 + a_1 \times b_2 \\ c_1 = a_0 \times b_1 + a_1 \times b_3 \\ c_2 = a_2 \times b_0 + a_3 \times b_2 \\ c_3 = a_2 \times b_1 + a_3 \times b_3 \\ c=a×b[c0c2c1c3]=[a0a2a1a3]×[b0b2b1b3]c0=a0×b0+a1×b2c1=a0×b1+a1×b3c2=a2×b0+a3×b2c3=a2×b1+a3×b3
3.11 矩阵乘法的性质
- 矩阵的乘法不满足交换律: a × b ≠ b × a a\times b \neq b \times a a×b=b×a
- 矩阵的乘法满足结合律: a × ( b × c ) = ( a × b ) × c a \times (b \times c) = (a\times b) \times c a×(b×c)=(a×b)×c
单位矩阵:在矩阵的乘法中,有一种矩阵起着特殊的作用,如同 数的乘法中的 1,我们称这种矩阵为单位矩阵。单位矩阵是个方阵,一般用 i i i 或者 e e e 表示,从左上角到右下角的对角线(称为主对角线)上的元素均为 1,剩下的全为 0。如:
[ 1 0 0 1 ] 2 × 2 或 [ 1 0 0 0 1 0 0 0 10 ] 3 × 3 或 [ 1 0 0 0 0 1 0 0 0 0 1 0 0 0 0 10 ] 4 × 4 \begin{bmatrix} 1 & 0 \\ 0 & 1 \end{bmatrix}_{2 \times 2} \quad 或\quad \begin{bmatrix} 1 & 0 & 0 \\ 0 & 1 & 0 \\ 0 & 0 & 1 0\end{bmatrix}_{3 \times 3} \quad 或\quad \begin{bmatrix} 1 & 0 & 0 & 0 \\ 0 & 1 & 0 & 0 \\ 0 & 0 & 1 & 0 \\ 0 & 0 & 0 & 1 0\end{bmatrix}_{4 \times 4} [1001]2×2或 1000100010 3×3或 10000100001000010 4×4
3.12 矩阵的逆和转置
一、矩阵的逆:如矩阵 a a a 是一个 m × m m\times m m×m 矩阵(方阵),如果有逆矩阵,则:
a a − 1 = a − 1 a = e ( 单位矩阵 ) aa^{-1} = a^{-1}a = e(单位矩阵) aa−1=a−1a=e(单位矩阵)
低阶矩阵求逆的方法(了解):
- 待定系数法
- 初等变换
二、矩阵的转置:设 a a a 为 m × n m\times n m×n 阶矩阵(即 m m m 行 n n n 列),第 i i i 行 j j j 列的元素是 a ( i , j ) a(i,j) a(i,j),即:
a = a ( i , j ) a = a(i, j) a=a(i,j)
定义 a a a 的转置为这样一个 n × m n\times m n×m 阶矩阵 b b b,满足 b = a ( i , j ) b=a(i,j) b=a(i,j),即 b ( i , j ) = a ( j , i ) b(i,j)=a(j,i) b(i,j)=a(j,i)( b b b 的第 i i i 行第 j j j 列元素是 a a a 的第 j j j 行第 i i i 列元素),记 a t = b a^t=b at=b。
直观来看,将 a a a 的所有元素绕着一条从第 1 1 1 行第 1 1 1 列元素出发的右下方45度的射线作镜面反转,即得到 a a a的转置。
例:
[ a b c d e f ] 3 × 2 t = [ a c e b d f ] 2 × 3 \begin{bmatrix} a & b \\ c & d \\ e & f \end{bmatrix}^t_{3 \times 2} = \begin{bmatrix} a & c & e \\ b & d & f \end{bmatrix}_{2 \times 3} acebdf 3×2t=[abcdef]2×3
3.13 矩阵乘法的日常应用举例
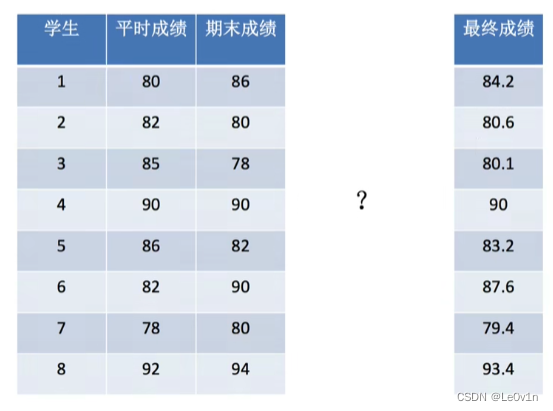
平时成绩占 70%,期末成绩占 30%,如何使用矩阵乘法求出最终成绩?
[ 80 86 82 80 85 78 90 90 86 82 82 90 78 80 92 94 ] 8 × 2 × [ 0.7 0.3 ] 2 × 1 = [ 84.2 80.6 80.1 90.0 83.2 87.6 79.4 93.4 ] 8 × 1 \begin{bmatrix} 80 & 86 \\ 82 & 80 \\ 85 & 78 \\ 90 & 90 \\ 86 & 82 \\ 82 & 90 \\ 78 & 80 \\ 92 & 94 \\ \end{bmatrix}_{8 \times 2} \times \begin{bmatrix} 0.7 \\ 0.3 \\ \end{bmatrix}_{2 \times 1} = \begin{bmatrix} 84.2 \\ 80.6 \\ 80.1 \\ 90.0 \\ 83.2 \\ 87.6 \\ 79.4 \\ 93.4 \\ \end{bmatrix}_{8 \times 1} 80828590868278928680789082908094 8×2×[0.70.3]2×1= 84.280.680.190.083.287.679.493.4 8×1
3.14 numpy中的矩阵乘法
在 numpy 中,矩阵乘法有两个 api:
np.matmul(arr1, arr2, out):
- 作用:矩阵乘法的函数
- 参数说明:
arr1和arr2是输入数组,必须是类似数组的对象。out是一个可选参数,它是一个 n n n 维数组,用于存储输出结果
np.dot(vector_a, vector_b, out)
- 作用:计算点积和矩阵乘法的函数
- 参数说明:
vector_a和vector_b是输入向量out是一个可选参数,它是一个 n 维数组,用于存储输出结果
np.matmul和np.dot的区别:
- 二者都是矩阵乘法,在进行矩阵×矩阵时二者没有区别。
np.matmul中禁止矩阵与标量的乘法。- 在矢量乘矢量的内积运算中,
np.matmul与np.dot没有区别。
示例:
a = np.array([[80, 86], [82, 80], [85, 78], [90, 90], [86, 82], [82, 90], [78, 80], [92, 94]])
b = np.array([[0.7], [0.3]])
print(a.shape) # (8, 2)
print(b.shape) # (2, 1)
# print(a * b) # valueerror: operands could not be broadcast together with shapes (8,2) (2,1)
res1 = np.matmul(a, b)
print(res1, res1.shape)
"""
[[81.8]
[81.4]
[82.9]
[90. ]
[84.8]
[84.4]
[78.6]
[92.6]] (8, 1)
"""
res2 = np.dot(a, b)
print(res2, res2.shape)
"""
[[81.8]
[81.4]
[82.9]
[90. ]
[84.8]
[84.4]
[78.6]
[92.6]] (8, 1)
"""
# np.matmul不支持矩阵与标量的乘法
c = 10
# res3 = np.matmul(a, c) # valueerror: matmul: input operand 1 does not have enough dimensions (has 0, gufunc core with signature (n?,k),(k,m?)->(n?,m?) requires 1)
# np.dot支持矩阵与标量的乘法
c = 10
res3 = np.dot(a, c)
print(res3, res3.shape)
"""
[[800 860]
[820 800]
[850 780]
[900 900]
[860 820]
[820 900]
[780 800]
[920 940]] (8, 2)
"""
如果想要实现两个矩阵对应位置元素的加减乘除,则使用 + - * / 即可(前提是两个矩阵的 shape 必须相等)
a = np.array([[1, 2], [3, 4]])
b = np.array([[5, 6], [7, 8]])
print(a.shape) # (8, 2)
print(b.shape) # (2, 1)
# 对应位置元素相加
res_add = a + b
print(res_add)
"""
[[ 6 8]
[10 12]]
"""
# 对应位置元素相减
res_sub = a - b
print(res_sub)
"""
[[-4 -4]
[-4 -4]]
"""
# 对应位置元素相乘
res_mul = a * b
print(res_mul)
"""
[[ 5 12]
[21 32]]
"""
# 对应位置元素相除
res_div = a / b
print(res_div)
"""
[[0.2 0.33333333]
[0.42857143 0.5 ]]
"""
小结:
- 矩阵和向量【知道】
- 矩阵就是特殊的二维数组
- 向量就是一行或者一列的数据
- 矩阵加法和标量乘法【知道】
- 矩阵的加法:行列数相等的可以加
- 矩阵的乘法:每个元素都要乘
- 矩阵和矩阵(向量)相乘【知道】
- ( m 行 , n 列 ) × ( n 行 , l 列 ) = ( m 行 , l 列 ) (m行, n列) \times (n行, l列) = (m行, l列) (m行,n列)×(n行,l列)=(m行,l列)
- 矩阵性质【知道】
- 矩阵不满足交换率,但满足结合律
- 单位矩阵【知道】
- 对角线都是 1 1 1,其他位置都为 0 0 0 的矩阵
- 矩阵运算【掌握】
np.matmul()np.dot()- 注意:二者都是矩阵乘法
np.matmul中禁止矩阵与标量的乘法- 在矢量乘矢量的内积运算中,
np.matmul()与np.dot()没有区别
3.15 【扩展】shape=(3, ), shape=(3, 1), shape=(1, 3) 的区别
形状为 (3,) 和形状为 (3, 1) 的数组在 numpy 中被认为是不同的,它们的数据类型不同,且在进行一些运算时可能会有不同的表现。
-
形状为
(3,)的数组是一维数组,通常被称为行向量或列向量,但是在 numpy 中是行向量。这种数组只有一个轴,其中的元素按照一维数组的方式排列,例如[1, 2, 3]。 -
形状为
(3, 1)的数组是二维数组,其中第一维度的长度为 3,第二维度的长度为1,通常被称为列向量。这种数组有两个轴,其中的元素按照二维数组的方式排列,例如[[1], [2], [3]]。 -
形状为
(1, 3)的数组也是二维数组,其中第一维度的长度为1,第二维度的长度为 3,通常被称为行向量。这种数组有两个轴,其中的元素按照二维数组的方式排列,例如[[1, 2, 3]]。
在进行一些运算时,这些数组的表现可能会有不同。例如:
- 对于形状为
(3,)的数组,它的转置仍然是(3,)的行向量; - 对于形状为
(3, 1)的数组,它的转置是(1, 3)的行向量; - 对于形状为
(1, 3)的数组,它的转置是(3, 1)的列向量。
因此,在使用这些数组时,需要根据具体的情况来选择合适的形状和操作。
示例代码:
import numpy as np
a = np.array([1, 2, 3]) # 形状为(3,)
b = np.array([[1], [2], [3]]) # 形状为(3, 1)
c = np.array([[1, 2, 3]]) # 形状为(1, 3)
print(a.t) # [1 2 3]
print(b.t) # [[1 2 3]]
print(c.t) # [[1], [2], [3]]
上述示例代码中,分别定义了三个不同形状的数组,分别对它们进行了转置操作,并打印了转置后的结果。可以看出,转置操作对于不同形状的数组,得到的结果也是不同的。
4. pandas
- 2008 年 wesmckinney 开发的库,专门用于数据挖掘的开源 python 库
- 以 numpy 为基础,借力 numpy 模块在计算方面性能高的优势
- 基于 matplotlib,能够简便的画图
- 独特的数据结构
numpy 已经能够帮助我们处理数据,能够结合 matplotlib 解决部分数据展示等问题,那么 pandas 学习的目的是什么呢?
- 增强图表的可读性
- 便捷的数据处理能力
- 方便读取文件
- 封装了 matplotlib 和 numpy 的画图和计算优势
pandas 中一共有三种数据结构,分别为:
series:一维数据结构dataframe:二维的表格型数据结构multiindex(老版本中叫panel):三维的数据结构
学习目标:
- 了解 numpy 与 pandas 的不同
- 说明 pandas 的
series与dataframe两种结构的区别 - 了解 pandas 的
multiindex与panel结构 - 应用 pandas 实现基本数据操作
- 应用 pandas 实现数据的合并
- 应用
crosstab和pivot_table实现交叉表与透视表 - 应用
groupby和 聚合函数 实现数据的分组与聚合 - 了解 pandas 的
plot画图功能 - 应用 pandas 实现数据的读取和存储
4.1 series 数据结构
series 是一个类似于一维数组(1d-array)的数据结构,它能够保存任何类型的数据,比如整数、字符串、浮点数等,主要由一组数据和与之相关的索引两部分构成。

4.1.1 series 的创建
import pandas as pd
pd.series(data=none, index=none, dtype=none)
- 参数:
data:传入的数据,可以是 ndarray、list 等index:索引,必须是唯一的,且与数据的长度相等。如果没有传入索引参数,则默认会自动创建一个从 0 ~ n 的整数索引。dtype:数据的类型
- 可以通过已有数据创建
series 的创建方式一般有三种:
- 指定内容,默认索引
- 指定内容,指定索引
- 通过字典数据创建
一、指定内容,默认索引
pd.series(np.arange(10))
"""
0 0
1 1
2 2
3 3
4 4
5 5
6 6
7 7
8 8
9 9
dtype: int32
"""
二、指定内容,指定索引
pd.series([6.7, 5.6, 3, 10, 2], index=[1, 2, 3, 4, 5])
"""
1 6.7
2 5.6
3 3.0
4 10.0
5 2.0
dtype: float64
"""
三、通过字典数据创建
color_count = pd.series({"red": 100, "blue": 200, "green": 500, "yellow": 1000})
color_count
"""
red 100
blue 200
green 500
yellow 1000
dtype: int64
"""
4.1.2 series 的属性
为了更方便地操作 series 对象中的索引和数据,series 中提供了两个属性 index 和 values 。
示例:
color_count = pd.series({"red": 100, "blue": 200, "green": 500, "yellow": 1000})
print(color_count.index) # index(['red', 'blue', 'green', 'yellow'], dtype='object')
print(color_count.values) # [ 100 200 500 1000]
# 读取series的元素
print(color_count["red"]) # 100
print(color_count["blue"]) # 200
print(color_count["green"]) # 500
print(color_count["yellow"]) # 1000
# series也可以通过int索引来取值
print(color_count[0]) # 100
print(color_count[1]) # 200
print(color_count[2]) # 500
print(color_count[3]) # 1000
q:pandas 的 series 可以理解为是一种容器吗?
a:pandas 的 series 可以被理解为一种容器,它可以存储不同类型的数据。series 是 pandas 中的一维数组,它可以存储整数、浮点数、字符串、python 对象等类型的数据。series 具有与 numpy 数组(ndarray)类似的功能,但它还具有轴标签,这意味着它可以通过索引标签来访问数据。
4.2 dataframe 数据结构
dataframe 是一个类似于二维数组或表格(如 excel )的对象,既有行索引,又有列索引。
- 行索引,表明不同行,横向索引,叫 index,0 轴,
axis=0 - 列索引,表明不同列,纵向索引,叫 columns,1 轴,
axis=1
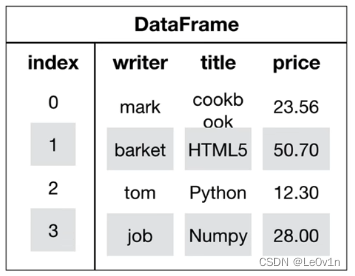
4.2.1 dataframe 的创建
pd.dataframe(data=none, index=none, columns=none)
参数:
- 参数:
index:行标签。如果没有传入索引参数,则默认会自动创建一个从 0 ~ n 的整数索引。columns:列标签。如果没有传入索引参数,则默认会自动创建一个从 0 ~ n 的整数索引。
- 可以通过已有数据创建
示例1:随机创建一个 2 行 3 列的 dataframe 对象
tmp = pd.dataframe(np.random.randn(2, 3))
print(tmp)
"""
0 1 2
0 1.248340 0.921399 0.651492
1 0.506594 0.944270 -0.411782
"""
示例2:创建学生成绩表
score = np.random.randint(40, 100, (10, 5))
print(score)
"""
[[74 98 74 40 94]
[52 63 72 54 50]
[54 90 92 70 61]
[71 44 61 70 99]
[88 79 57 64 95]
[51 83 47 71 76]
[70 42 48 90 44]
[95 54 48 66 40]
[55 65 59 94 65]
[81 91 85 61 91]]
"""
但是这样的数据形式很难看到存储的是什么的样的数据,可读性比较差!
我们可以使用 pandas 使得数据更加直观的显示:
score_df = pd.dataframe(score)
print(score_df)
"""
0 1 2 3 4
0 74 98 74 40 94
1 52 63 72 54 50
2 54 90 92 70 61
3 71 44 61 70 99
4 88 79 57 64 95
5 51 83 47 71 76
6 70 42 48 90 44
7 95 54 48 66 40
8 55 65 59 94 65
9 81 91 85 61 91
"""
# 增加行、列索引
subjects = ["语文", "数学", "英语", "政治", "体育"]
# 构造列表索引序列
stu = ["同学{}".format(i) for i in range(score_df.shape[0])]
# 添加行索引
data = pd.dataframe(score, index=stu, columns=subjects)
print(data)
"""
语文 数学 英语 政治 体育
同学0 74 98 74 40 94
同学1 52 63 72 54 50
同学2 54 90 92 70 61
同学3 71 44 61 70 99
同学4 88 79 57 64 95
同学5 51 83 47 71 76
同学6 70 42 48 90 44
同学7 95 54 48 66 40
同学8 55 65 59 94 65
同学9 81 91 85 61 91
"""
4.2.2 dataframe 的属性
.shape:返回一个 tuple,(行,列).index:返回一个 index() 对象,里面存放一个行索引的 list.columns:返回一个 index() 对象,里面存放一个列索引的 list.values:返回一个 array() 对象,里面存放一个值的 list.t:转置.head(n=5):返回前n行数据 —— 这个属于方法了,所以要加()tail(n=5):返回倒数n行数据 —— 这个属于方法了,所以要加()
示例:
# 1. .shape:返回一个tuple,(行,列)
print(data.shape) # (10, 5)
# 2. .index:返回一个index()对象,里面存放一个行索引的list
print(data.index) # index(['同学0', '同学1', '同学2', '同学3', '同学4', '同学5', '同学6', '同学7', '同学8', '同学9'], dtype='object')
# 3. .columns:返回一个index()对象,里面存放一个列索引的list
print(data.columns) # index(['语文', '数学', '英语', '政治', '体育'], dtype='object')
# 4. .values:返回一个array()对象,里面存放一个值的list
print(data.values)
print(type(data.values)) # <class 'numpy.ndarray'>
"""
[[74 98 74 40 94]
[52 63 72 54 50]
[54 90 92 70 61]
[71 44 61 70 99]
[88 79 57 64 95]
[51 83 47 71 76]
[70 42 48 90 44]
[95 54 48 66 40]
[55 65 59 94 65]
[81 91 85 61 91]]
"""
# 5. .t:转置
print(data.t)
"""
同学0 同学1 同学2 同学3 同学4 同学5 同学6 同学7 同学8 同学9
语文 74 52 54 71 88 51 70 95 55 81
数学 98 63 90 44 79 83 42 54 65 91
英语 74 72 92 61 57 47 48 48 59 85
政治 40 54 70 70 64 71 90 66 94 61
体育 94 50 61 99 95 76 44 40 65 91
"""
# 6. .head(n=5):返回前n行数据
print(data.head())
"""
语文 数学 英语 政治 体育
同学0 74 98 74 40 94
同学1 52 63 72 54 50
同学2 54 90 92 70 61
同学3 71 44 61 70 99
同学4 88 79 57 64 95
"""
# 7. tail(n=5):返回倒数n行数据
print(data.tail())
"""
语文 数学 英语 政治 体育
同学5 51 83 47 71 76
同学6 70 42 48 90 44
同学7 95 54 48 66 40
同学8 55 65 59 94 65
同学9 81 91 85 61 91
"""
4.2.3 dataframe 索引的设置
注意:
df.index是支持索引访问的(如df.index[0]),但不支持修改,即可以访问单个索引,但不可以修改单个索引df.index这个整体是可以修改的!(要修改一定要全修改,否则会报错!)
一、修改行列索引值
需求:将"同学0"改为"学生_0",该如何操作?
示例:
print(data)
"""
语文 数学 英语 政治 体育
同学0 74 98 74 40 94
同学1 52 63 72 54 50
同学2 54 90 92 70 61
同学3 71 44 61 70 99
同学4 88 79 57 64 95
同学5 51 83 47 71 76
同学6 70 42 48 90 44
同学7 95 54 48 66 40
同学8 55 65 59 94 65
同学9 81 91 85 61 91
"""
# 直接修改单个index的方式是错误的!
# data.index[3] = "学生_3" # typeerror: index does not support mutable operations
# 可以访问单个索引,但不可以修改单个索引
print(data.index[1]) # 学生_1
# df.index[int]不是mutable属性,但df.index这个整体是可以修改的!(要修改一定要全修改,否则会报错!)
# 方法1
data.index = ["学生_0", "学生_1", "学生_2", "学生_3",
"学生_4", "学生_5", "学生_6", "学生_7",
"学生_8", "学生_9"]
# 方法2
# stu = ["学生_" + str(i) for i in range(score_df.shape[0])]
data.index = stu
print(data)
"""
语文 数学 英语 政治 体育
学生_0 74 98 74 40 94
学生_1 52 63 72 54 50
学生_2 54 90 92 70 61
学生_3 71 44 61 70 99
学生_4 88 79 57 64 95
学生_5 51 83 47 71 76
学生_6 70 42 48 90 44
学生_7 95 54 48 66 40
学生_8 55 65 59 94 65
学生_9 81 91 85 61 91
"""
二、重设索引
方法:reset_index(drop=false) -> dataframe
- 作用:将 dataframe 索引重置为从 0 开始的默认整数索引。
- 参数说明:
drop: 默认值为false,表示是否在重置索引时丢弃原来的索引列。如果设置为true,则会将原来的索引列删除。level: 如果数据框是多级索引,可以指定需要重置的级别。col_level: 如果数据框有多级列索引,则可以指定要求重置的级别。col_fill: 如果数据框有多级列索引,则可以指定新列的名称。
- 返回值:返回一个新的 dataframe,其中包含重置后的索引。
示例:
# .reset_index方法对原来的df没有影响
data.reset_index()
print(data)
"""
语文 数学 英语 政治 体育
学生_0 74 98 74 40 94
学生_1 52 63 72 54 50
学生_2 54 90 92 70 61
学生_3 71 44 61 70 99
学生_4 88 79 57 64 95
学生_5 51 83 47 71 76
学生_6 70 42 48 90 44
学生_7 95 54 48 66 40
学生_8 55 65 59 94 65
学生_9 81 91 85 61 91
"""
print(data.reset_index())
"""
index 语文 数学 英语 政治 体育
0 学生_0 74 98 74 40 94
1 学生_1 52 63 72 54 50
2 学生_2 54 90 92 70 61
3 学生_3 71 44 61 70 99
4 学生_4 88 79 57 64 95
5 学生_5 51 83 47 71 76
6 学生_6 70 42 48 90 44
7 学生_7 95 54 48 66 40
8 学生_8 55 65 59 94 65
9 学生_9 81 91 85 61 91
"""
new_data = data.reset_index(drop=true)
print(data)
"""
语文 数学 英语 政治 体育
学生_0 74 98 74 40 94
学生_1 52 63 72 54 50
学生_2 54 90 92 70 61
学生_3 71 44 61 70 99
学生_4 88 79 57 64 95
学生_5 51 83 47 71 76
学生_6 70 42 48 90 44
学生_7 95 54 48 66 40
学生_8 55 65 59 94 65
学生_9 81 91 85 61 91
"""
print(new_data)
"""
语文 数学 英语 政治 体育
0 74 98 74 40 94
1 52 63 72 54 50
2 54 90 92 70 61
3 71 44 61 70 99
4 88 79 57 64 95
5 51 83 47 71 76
6 70 42 48 90 44
7 95 54 48 66 40
8 55 65 59 94 65
9 81 91 85 61 91
"""
三、以某列值设置为新的索引
方法:set_index(keys, drop=true) -> dataframe
- 作用:设置新的下标索引
- 参数说明:
keys:列索引名称或列索引名称的列表drop:默认为 false,即不删除原来的索引;如果为 true,则删除原来的索引值
- 注意:该方法返回一个 dataframe,对原来的 df 并没有影响!
示例:
# 1. 创建df
df = pd.dataframe({"month": [1, 4, 7, 10],
"year": [2012, 2014, 2020, 2023],
"sale": [55, 40, 70, 35]})
print(df)
"""
month year sale
0 1 2012 55
1 4 2014 40
2 7 2020 70
3 10 2023 35
"""
# 2. 将月份设置为索引
new_df = df.set_index("month")
print(new_df)
"""
year sale
month
1 2012 55
4 2014 40
7 2020 70
10 2023 35
"""
# 3. 设置多个索引:以年和月份作为索引
new_df = df.set_index(["year", "month"])
print(new_df)
"""
sale
year month
2012 1 55
2014 4 40
2020 7 70
2023 10 35
"""
4.3 multiindex
multilndex 是三维的数据结构,叫做多级索引。多级索引(也称层次化索引)是 pandas 的重要功能,可以在 series、dataframe 对象上拥有 2 个以及 2 个以上的索引。
4.3.1 multiindex 的特性
打印刚才的 df 的行索引结果:
new_df.index
"""
multiindex([(2012, 1),
(2014, 4),
(2020, 7),
(2023, 10)],
names=['year', 'month'])
"""
print(new_df.index.names) # ['year', 'month']
print(new_df.index.levels) # [[2012, 2014, 2020, 2023], [1, 4, 7, 10]]
.index属性:names:levels的名称levels:每个level的元组值
4.3.2 multiindex的创建
from_tuples:使用元组列表创建 multiindex。from_arrays:使用数组列表创建 multiindex。from_product:使用笛卡尔积创建 multiindex。from_frame:从 dataframe 创建 multiindex。
示例:
arrays = [[1, 1, 2, 2], ["red", "blue", "red", "blue"]]
pd.multiindex.from_arrays(arrays, names=("number", "color"))
"""
multiindex([(1, 'red'),
(1, 'blue'),
(2, 'red'),
(2, 'blue')],
names=['number', 'color'])
"""
import pandas as pd
# 1. `from_tuples`:使用元组列表创建 multiindex。
tup = ('x', 'a'), ('x', 'b'), ('y', 'a'), ('y', 'b')
index = pd.multiindex.from_tuples(tup)
print(index)
"""
multiindex([('x', 'a'),
('x', 'b'),
('y', 'a'),
('y', 'b')],
)
"""
# 2. `from_arrays`:使用数组列表创建 multiindex。
arrays = ['x', 'x', 'y', 'y'], ['a', 'b', 'a', 'b']
index = pd.multiindex.from_arrays(arrays)
print(index)
"""
multiindex([('x', 'a'),
('x', 'b'),
('y', 'a'),
('y', 'b')],
)
"""
# 3. `from_product`:使用笛卡尔积创建 multiindex。
cartesian_produc = [['x', 'y'], ['a', 'b']]
index = pd.multiindex.from_product(cartesian_produc)
print(index)
"""
multiindex([('x', 'a'),
('x', 'b'),
('y', 'a'),
('y', 'b')],
)
"""
# 4. `from_frame`:从 dataframe 创建 multiindex。
dt = {'a': ['x', 'x', 'y', 'y'], 'b': ['a', 'b', 'a', 'b']}
df = pd.dataframe(dt)
index = pd.multiindex.from_frame(df)
print(index)
"""
multiindex([('x', 'a'),
('x', 'b'),
('y', 'a'),
('y', 'b')],
names=['a', 'b'])
"""
小结:
- pandas 的优势【了解】
- 增强图表可读性。
- 便捷的数据处理能力。
- 读取文件方便
- 封装了 matplotlib、numpy 的画图和计算
- series【知道】
- 创建
pd.series([], index=[])pd.series({})
- 属性
对象.index对象.values
- 创建
- dataframe【掌握】
- 创建
pd.dataframe(data=none, index=none, columns=none)
- 属性
.shape– 形状.index– 行索引.columns– 列索引.values– 查看值.t– 转置.head()– 查看头部内容.tail()– 查看尾部内容
- dataframe索引
- 修改的时候,需要进行全局修改
对象.reset_index(drop=false) -> df对象.set_index(keys, drop=false) -> df
- 创建
- multilndex【了解】
- 类似 ndarray 中的三维数组创建
- 创建:
pd.multilndex.from_arrays()
- 属性:
对象.index
4.4 索引操作
numpy 当中我们已经讲过使用索引选取序列和切片选择,pandas 也支持类似的操作,也可以直接使用列名、行名称,甚至组合使用。
数据集下载地址:https://www.kaggle.com/datasets/varpit94/uber-stock-data
# 读取文件
data = pd.read_csv("./data/uber.csv", index_col=0)
data = data.drop(["adj close", "volume"], axis=1) # 按列
print(data.head())
"""
open high low close
date
2019-5-10 42.000000 45.000000 41.060001 41.570000
2019-5-13 38.790001 39.240002 36.080002 37.099998
2019-5-14 38.310001 39.959999 36.849998 39.959999
2019-5-15 39.369999 41.880001 38.950001 41.290001
2019-5-16 41.480000 44.060001 41.250000 43.000000
"""
4.4.1 直接使用行列索引(先列后行)
示例:获取"2022-03-7’这天的’close"的结果:
# 支持的操作 —— 先列后行
res = data["close"]["2022-3-7"]
print(res) # 28.57
# 不支持的操作(先行后列)
# res = data["2022-3-7"]["close"] # keyerror: '2022-02-27'
# 不支持的操作(切片)
# res = data[:1, :2] # invalidindexerror: (slice(none, 1, none), slice(none, 2, none))
与 ndarray 数组不同,上面的两种操作是不允许的!
4.4.2 结合 .loc 或者 .iloc 使用索引
.loc(开始行名: 结束行名, 列名: 列名).iloc[开始行索引: 结束行索引, 开始列索引: 结束列索引]
示例:获取从 ‘2021-2-22: 2021-2-26’,'open’的结果:
# 使用loc只能指定行列索引的名字
res = data.loc["2021-2-22": "2021-2-26", "open"]
print(res)
"""
date
2021-2-22 57.759998
2021-2-23 53.500000
2021-2-24 54.950001
2021-2-25 54.580002
2021-2-26 52.070000
name: open, dtype: float64
"""
# 使用iloc可以通过索引的下标去获取
res = data.iloc[:3, :5] # 获取前3行,前5列的结果
print(res)
"""
open high low close
date
2019-5-10 42.000000 45.000000 41.060001 41.570000
2019-5-13 38.790001 39.240002 36.080002 37.099998
2019-5-14 38.310001 39.959999 36.849998 39.959999
"""
4.5 赋值操作
df[列名]= 数值df.列名= 数值
举例:对 dataframe 当中的 close 列进行重新赋值为 1。
# 直接修改原来的值
data["close"] = 1
print(data.head())
"""
open high low close
date
2019-5-10 42.000000 45.000000 41.060001 1
2019-5-13 38.790001 39.240002 36.080002 1
2019-5-14 38.310001 39.959999 36.849998 1
2019-5-15 39.369999 41.880001 38.950001 1
2019-5-16 41.480000 44.060001 41.250000 1
"""
# 或者
data.close = 1
print(data.head())
"""
open high low close
date
2019-5-10 42.000000 45.000000 41.060001 1
2019-5-13 38.790001 39.240002 36.080002 1
2019-5-14 38.310001 39.959999 36.849998 1
2019-5-15 39.369999 41.880001 38.950001 1
2019-5-16 41.480000 44.060001 41.250000 1
"""
4.6 排序
排序有两种形式:
- 对索引(index)进行排序
- 对于内容(values)进行排序
4.6.1 dataframe排序
一、值排序
df.sort_values(axis=0, by=, ascending=true, inplace=false) -> df- 作用:单个键或者多个键进行排序
- 参数:
axis:要排序的轴by:指定排序参考的键ascending:默认升序ascending=false:降序ascending=true:升序
inplace:原地排序(将结果赋值给原变量)
示例1:按照开盘价的大小进行升序排序。
data.sort_values(axis=0, by="open", ascending=true, inplace=true)
print(data.head())
"""
open high low close
date
2020-3-19 15.96 21.260000 15.70 20.490000
2020-3-18 17.76 17.799999 13.71 14.820000
2020-3-16 20.15 21.490000 19.10 20.290001
2020-3-17 20.18 20.309999 18.01 18.910000
2020-3-23 21.07 22.730000 19.73 22.400000
"""
示例2:按照多个键进行排序。
data.sort_values(by=["open", "high"], ascending=true, inplace=true)
print(data)
"""
open high low close
date
2020-3-19 15.960000 21.260000 15.700000 20.490000
2020-3-18 17.760000 17.799999 13.710000 14.820000
2020-3-16 20.150000 21.490000 19.100000 20.290001
2020-3-17 20.180000 20.309999 18.010000 18.910000
2020-3-23 21.070000 22.730000 19.730000 22.400000
... ... ... ... ...
2021-3-15 60.349998 60.529999 59.119999 60.189999
2021-4-16 60.740002 60.849998 59.540001 60.349998
2021-2-16 61.020000 61.310001 59.840000 60.520000
2021-2-10 62.000000 63.500000 60.799999 63.180000
2021-2-11 63.250000 64.050003 60.395000 60.709999
"""
二、索引排序
df.sort_index(axis=0, ascending=true, inplace=false) -> df- 作用:对 dataframe 的索引进行排序
- 参数:
axis:要排序的轴ascending:默认升序ascending=false:降序ascending=true:升序
inplace:原地排序(将结果赋值给原变量)
示例1:按照日期从大到小降序排序。
data.sort_index(axis=0, ascending=false, inplace=true)
print(data.head())
"""
open high low close
date
2022-3-9 31.750000 32.730 31.200001 31.500000
2022-3-8 28.510000 31.570 28.278000 30.740000
2022-3-7 31.480000 31.938 28.549999 28.570000
2022-3-4 31.500000 31.730 29.270000 29.830000
2022-3-3 34.220001 34.291 31.415001 31.719999
"""
4.6.2 series排序
一、值排序
series.sort_values(axis=0, ascending=true, inplace=false) -> series- 作用:对 series 的索引进行排序
- 参数:
axis:要排序的轴by:指定排序参考的键ascending:默认升序ascending=false:降序ascending=true:升序
inplace:原地排序(将结果赋值给原变量)
示例:
series = data["close"].copy()
series.sort_values(ascending=false, inplace=true) # 对值进行降序
print(series.head())
"""
date
2021-2-10 63.180000
2021-2-17 60.810001
2021-4-15 60.740002
2021-2-11 60.709999
2021-4-13 60.639999
name: close, dtype: float64
"""
二、索引排序
series.sort_index(axis=0, ascending=true, inplace=false) -> series- 作用:单个键或者多个键进行排序
- 参数:
axis:要排序的轴ascending:默认升序ascending=false:降序ascending=true:升序
inplace:原地排序(将结果赋值给原变量)
series.sort_index(ascending=true, inplace=true) # 对索引进行升序
print(series.head())
"""
date
2019-10-1 29.150000
2019-10-10 28.870001
2019-10-11 30.129999
2019-10-14 31.120001
2019-10-15 32.000000
name: close, dtype: float64
"""
小结:
- 索引【掌握】
- 直接索引
[] / [][]:先列后行,是需要通过索引的字符串进行获取 loc:先行后列,是需要通过索引的字符串进行获取iloc:先行后列,是通过下标进行索引
- 直接索引
- 赋值【知道】
data["列名"] = 数值data.列名 = 数值
- 排序【知道】
dataframedf.sort_values()df.sort_index()
seriesseries.sort_values()series.sort_index()
4.7 dataframe运算
学习目标:
- 应用
add等实现数据间的加、减法运算 - 应用逻辑运算符号实现数据的逻辑筛选
- 应用
isin、query实现数据的筛选 - 使用
describe完成综合统计 - 使用
max、min、mean、std完成统计计算 - 使用
idxmin、idxmax完成最大值最小值的索引 - 使用
cumsum等实现累计分析 - 应用
apply函数实现数据的自定义处理
4.7.1 算术运算
add(other)sub(other)
直接使用加法运算符 + 和减法运算符 - 也是可以的,但一般不这样写。
一、add(other)
比如进行数学运算加上具体的一个数字。
res = data["open"].add(1)
print(type(res)) # <class 'pandas.core.series.series'>
print(res.head())
"""
date
2022-3-9 32.750000
2022-3-8 29.510000
2022-3-7 32.480000
2022-3-4 32.500000
2022-3-3 35.220001
name: open, dtype: float64
"""
# 直接使用 加法运算符+ 也是可以的
# 因为df[列名]返回的是一个view,因此不会改变原有的数据
res = data["open"] + 1
print(type(res)) # <class 'pandas.core.series.series'>
print(res.head())
"""
date
2022-3-9 32.750000
2022-3-8 29.510000
2022-3-7 32.480000
2022-3-4 32.500000
2022-3-3 35.220001
name: open, dtype: float64
"""
二、sub(other)
res = data["open"].sub(1)
print(type(res)) # <class 'pandas.core.series.series'>
print(res.head())
"""
date
2022-3-9 30.750000
2022-3-8 27.510000
2022-3-7 30.480000
2022-3-4 30.500000
2022-3-3 33.220001
name: open, dtype: float64
"""
# 直接使用 加法运算符- 也是可以的
# 因为df[列名]返回的是一个view,因此不会改变原有的数据
res = data["open"] - 1
print(type(res)) # <class 'pandas.core.series.series'>
print(res.head())
"""
date
2022-3-9 30.750000
2022-3-8 27.510000
2022-3-7 30.480000
2022-3-4 30.500000
2022-3-3 33.220001
name: open, dtype: float64
"""
4.7.2 逻辑运算
一、逻辑运算符号
>:返回逻辑结果(true / false)<:返回逻辑结果(true / false)>=:返回逻辑结果(true / false)<=:返回逻辑结果(true / false)&:与|:或
示例:筛选 data["open"] > 30 的日期数据:
condition = data["open"] > 30
print(type(condition)) # <class 'pandas.core.series.series'>
print(condition.head())
"""
date
2022-3-9 true
2022-3-8 false
2022-3-7 true
2022-3-4 true
2022-3-3 true
name: open, dtype: bool
"""
# 和ndarray对象一样,可以根据筛选结果取值
res = data[condition]
print(type(res)) # <class 'pandas.core.frame.dataframe'>
print(res.head())
"""
open high low close
date
2022-3-9 31.750000 32.730000 31.200001 1
2022-3-7 31.480000 31.938000 28.549999 1
2022-3-4 31.500000 31.730000 29.270000 1
2022-3-3 34.220001 34.291000 31.415001 1
2022-3-24 34.740002 34.950001 33.439999 1
"""
# 完成多个逻辑判断
condition_1 = data["open"] > 30
print(type(condition_1)) # <class 'pandas.core.series.series'>
condition_2 = data["high"] < 40
print(type(condition_2)) # <class 'pandas.core.series.series'>
res = data[condition_1 & condition_2]
print(type(res)) # <class 'pandas.core.frame.dataframe'>
print(res)
"""
open high low close
date
2022-3-9 31.750000 32.730000 31.200001 1
2022-3-7 31.480000 31.938000 28.549999 1
2022-3-4 31.500000 31.730000 29.270000 1
2022-3-3 34.220001 34.291000 31.415001 1
2022-3-24 34.740002 34.950001 33.439999 1
... ... ... ... ...
2019-10-17 31.799999 32.930000 31.450001 1
2019-10-16 31.799999 32.380001 31.438000 1
2019-10-15 31.200001 32.169998 31.195000 1
2019-10-14 30.219999 31.540001 29.819000 1
2019-10-1 30.370001 30.510000 28.650000 1
[278 rows x 4 columns]
"""
注意:在上面的代码中,condition_1 和 condition_2 都是 pandas series 对象,它们包含了布尔值。当我们使用 & 运算符对两个 series 对象进行运算时,它会对两个 series 对象中的每个元素进行逐一比较,并返回一个新的 series 对象,其中每个元素都是原 series 对象中对应元素的逻辑与结果。
res = data[condition_1 & condition_2]
这行代码会返回一个新的 dataframe 对象,它只包含满足 condition_1 & condition_2 条件的行。
而 and 是逻辑与运算符,它不能用于对两个 series 对象进行运算。如果我们尝试使用 and 运算符来代替 & 运算符,就会得到一个错误信息。
res = data[condition_1 and condition_2]
# valueerror: the truth value of a series is ambiguous. use a.empty, a.bool(), a.item(), a.any() or a.all().
所以,在这种情况下,我们应该使用 & 运算符来对两个 series 对象进行逐一比较。
二、逻辑运算函数
query(expr)- 作用:允许使用类似于 sql 的语句来查询 dataframe
- 参数说明:
expr是一个字符串,表示用于过滤 dataframe 的布尔表达式。
- 例子:
df.query("a < 4")。表示a列中值小于 4 的 行
isin(values)- 作用: 用于过滤数据帧。
isin()方法有助于选择在特定列中具有特定(或多个)值的 行 - 参数:
values是一个 list,里面包含具体的值(这个列表并不是一个范围)
- 如
[a, b, c, d, e],这个 list 不是一个范围,而是特定的值
- 作用: 用于过滤数据帧。
示例:
# 1. query(expr)
res = data.query("open > 30 & open < 50")
print(type(res)) # <class 'pandas.core.frame.dataframe'>
print(res.head())
"""
open high low close
date
2022-3-9 31.750000 32.730000 31.200001 1
2022-3-7 31.480000 31.938000 28.549999 1
2022-3-4 31.500000 31.730000 29.270000 1
2022-3-3 34.220001 34.291000 31.415001 1
2022-3-24 34.740002 34.950001 33.439999 1
"""
# 2. isin(values)
res = data[data["open"].isin([31, 32, 33, 34])]
print(type(res)) # <class 'pandas.core.frame.dataframe'>
print(res.head())
"""
open high low close
date
2022-3-2 34.0 34.220001 32.970001 1
2020-8-28 33.0 33.939999 32.820000 1
2020-6-18 33.0 33.439999 32.799999 1
2020-6-16 34.0 34.169998 32.430000 1
2020-4-29 31.0 32.000000 30.330000 1
"""
4.7.3 统计运算
一、综合分析 —— .describe()
综合分析 .describe() 能够直接得出很多统计结果:
count、mean、std、min、max等
示例:
res = data.describe()
print(type(res)) # <class 'pandas.core.frame.dataframe'>
print(res)
"""
open high low close
count 725.000000 725.000000 725.000000 725.0
mean 40.166447 40.961435 39.261123 1.0
std 9.198940 9.259164 9.075919 0.0
min 15.960000 17.799999 13.710000 1.0
25% 32.730000 33.419998 31.983000 1.0
50% 39.000000 39.959999 38.009998 1.0
75% 46.700001 47.520000 45.860001 1.0
max 63.250000 64.050003 60.799999 1.0
"""
说明:25%、50% 和 75% 分别表示第一四分位数、第二四分位数(中位数)和第三四分位数。
- 第一四分位数(
25%):表示数据集中所有数值中有25%的数据比它小。 - 第二四分位数(
50%):也就是中位数,表示数据集中所有数值的中间值。有50%的数据比它小,另外50%的数据比它大。 - 第三四分位数(
75%):表示数据集中所有数值中有75%的数据比它小。
这些值可以帮助我们了解数据集的分布情况。
二、统计函数
numpy 当中已经详细介绍,在这里我们演示
min(最小值)max(最大值)mean(平均值)median(中位数)var(方差)std(标准差)mode(众数)
| 统计方法 | 含义 |
|---|---|
min | 返回 dataframe 或 series 中的最小值 |
max | 返回 dataframe 或 series 中的最大值 |
mean | 返回 dataframe 或 series 中的算术平均值 |
median | 返回 dataframe 或 series 中的中位数 |
var | 返回 dataframe 或 series 中的方差 |
std | 返回 dataframe 或 series 中的标准差 |
mode | 返回 dataframe 或 series 中的众数 |
abs | 返回 dataframe 或 series 中每个元素的绝对值 |
prod | 返回 dataframe 或 series 中所有元素的乘积 |
idxmax | 返回 dataframe 或 series 中最大值的索引 |
idxmin | 返回 dataframe 或 series 中最小值的索引 |
这些方法都是对 dataframe 的每一列进行计算,返回一个 series 对象,其中索引为原 dataframe 的列名,值为对应列的计算结果(除了 abs 方法,它返回一个与原 dataframe 形状相同的 dataframe)。
说明:
mode众数:出现最多次数的数median中位数:先将数据从小到大排列,再取最中间的那个数为中位数。如果没有中间数,取中间两个数的平均值。
对于单个函数去进行统计的时候,坐标轴还是按照默认列 columns(axis=0, default),如果要对行 index 需要指定 (axis=1)。
示例:
# 使用统计函数时,0代表对列求结果;1代表对行求结果(默认为0)
df = pd.dataframe({"col1": [2, 3, 4, 5, 4, 2],
"col2": [0, 1, 2, 3, 4, 2],
"col3": [1, 2, 3, 4, 3, 1],
})
print("------------min------------")
# 1. min:返回dataframe或series中的最小值
res = df.min(0)
print(type(res)) # <class 'pandas.core.series.series'>
print(res, "\r\n")
"""
col1 2
col2 0
col3 1
dtype: int64
"""
print("------------max------------")
# 2. max:返回dataframe或series中的最大值
res = df.max(0)
print(type(res)) # <class 'pandas.core.series.series'>
print(res, "\r\n")
"""
col1 5
col2 4
col3 4
dtype: int64
"""
print("------------mean------------")
# 3. mean:返回dataframe或series中的算术平均值
res = df.mean(0)
print(type(res)) # <class 'pandas.core.series.series'>
print(res, "\r\n")
"""
col1 3.333333
col2 2.000000
col3 2.333333
dtype: float64
"""
print("------------median------------")
# 4. median:返回dataframe或series中的中位数
res = df.median(0)
print(type(res)) # <class 'pandas.core.series.series'>
print(res, "\r\n")
"""
col1 3.5
col2 2.0
col3 2.5
dtype: float64
"""
print("------------var------------")
# 5. var:返回dataframe或series中的方差
res = df.var(0)
print(type(res)) # <class 'pandas.core.series.series'>
print(res, "\r\n")
"""
col1 1.466667
col2 2.000000
col3 1.466667
dtype: float64
"""
print("------------std------------")
# 6. std:返回dataframe或series中的标准差
res = df.std(0)
print(type(res)) # <class 'pandas.core.series.series'>
print(res, "\r\n")
"""
col1 1.211060
col2 1.414214
col3 1.211060
dtype: float64
"""
print("------------mode------------")
# 7. mode:返回dataframe或series中的众数
res = df.mode()
print(type(res)) # <class 'pandas.core.frame.dataframe'>
print(res, "\r\n")
"""
col1 col2 col3
0 2 2.0 1
1 4 nan 3
"""
print("------------abs------------")
# 8. abs:返回dataframe或series中每个元素的绝对值
res = df.abs()
print(type(res)) # <class 'pandas.core.frame.dataframe'>
print(res, "\r\n")
"""
col1 col2 col3
0 2 0 1
1 3 1 2
2 4 2 3
3 5 3 4
4 4 4 3
5 2 2 1
"""
print("------------prod------------")
# 9. prod:返回dataframe或series中所有元素的乘积
res = df.prod(0)
print(type(res)) # <class 'pandas.core.series.series'>
print(res, "\r\n")
"""
col1 960
col2 0
col3 72
dtype: int64
"""
print("------------idmax------------")
# 10. idxmax:返回dataframe或series中最大值的索引
res = df.idxmax(0)
print(type(res)) # <class 'pandas.core.series.series'>
print(res, "\r\n")
"""
col1 3
col2 4
col3 3
dtype: int64
"""
print("------------idmin------------")
# 11. idxmin:返回dataframe或series中最小值的索引
res = df.idxmin()
print(type(res)) # <class 'pandas.core.series.series'>
print(res, "\r\n")
"""
col1 0
col2 0
col3 0
dtype: int64
"""
三、累积统计函数
在 pandas 中,cumsum、cummax、cummin 和 cumprod 都是累积函数,它们分别用于计算累积和、累积最大值、累积最小值和累积乘积。
cumsum(axis=0, skipna=true)cummax(axis=0, skipna=true)cummin(axis=0, skipna=true)cumprod(axis=0, skipna=true)
| 累积统计函数 | 作用 |
|---|---|
cumsum | 计算前 1/2/3/.../n 个数的和 |
cummax | 计算前1/2/3/.../n个数的最大值 |
cummin | 计算前 1/2/3/.../n 个数的最小值 |
cumprod | 计算前 1/2/3/.../n 个数的积 |
q:那么如何让这些累积的结果更好的显示呢?
a:利用 matplotlib 画图
语法示例:
import matplotlib.pyplot as plt # 必须先导入matplotlib库
# plot显示图像
res = series.cumsum()
res.plot() # 直接调用.plot()即可实现画图
# 需要调用show()才能显示图像
plt.show()
示例:
import matplotlib.pyplot as plt
from pylab import mpl
# 设置中文字体
mpl.rcparams["font.sans-serif"] = ["simhei"]
# 设置正常显示符号
mpl.rcparams["axes.unicode_minus"] = false
print(data)
"""
open high low close
date
2019-5-10 42.000000 45.000000 41.060001 41.570000
2019-5-13 38.790001 39.240002 36.080002 37.099998
2019-5-14 38.310001 39.959999 36.849998 39.959999
2019-5-15 39.369999 41.880001 38.950001 41.290001
2019-5-16 41.480000 44.060001 41.250000 43.000000
... ... ... ... ...
2022-3-18 32.520000 33.419998 32.330002 33.360001
2022-3-21 32.820000 32.820000 31.250000 31.980000
2022-3-22 31.930000 33.599998 31.840000 33.349998
2022-3-23 32.709999 33.680000 32.570000 33.060001
2022-3-24 34.740002 34.950001 33.439999 34.700001
[725 rows x 4 columns]
"""
# 0.1 排序
data.sort_index(inplace=true)
# 0.2 获取series
series_open = data["open"]
print(series_open, "\r\n")
"""
date
2019-10-1 30.370001
2019-10-10 29.209999
2019-10-11 28.950001
2019-10-14 30.219999
2019-10-15 31.200001
...
2022-3-3 34.220001
2022-3-4 31.500000
2022-3-7 31.480000
2022-3-8 28.510000
2022-3-9 31.750000
name: open, length: 725, dtype: float64
"""
# 1. cumsum(axis=0, skipna=true)
res = series_open.cumsum()
plt.figure(figsize=(20, 8))
plt.subplot(221)
res.plot()
plt.title("cumsum(axis=0, skipna=true)")
print(res, "\r\n")
"""
date
2019-10-1 30.370001
2019-10-10 59.580000
2019-10-11 88.530001
2019-10-14 118.750000
2019-10-15 149.950001
...
2022-3-3 28997.434011
2022-3-4 29028.934011
2022-3-7 29060.414011
2022-3-8 29088.924011
2022-3-9 29120.674011
name: open, length: 725, dtype: float64
"""
# 2. cummax(axis=0, skipna=true)
res = series_open.cummax()
plt.subplot(222)
res.plot()
plt.title("cummax(axis=0, skipna=true)")
print(res, "\r\n")
"""
date
2019-10-1 30.370001
2019-10-10 30.370001
2019-10-11 30.370001
2019-10-14 30.370001
2019-10-15 31.200001
...
2022-3-3 63.250000
2022-3-4 63.250000
2022-3-7 63.250000
2022-3-8 63.250000
2022-3-9 63.250000
name: open, length: 725, dtype: float64
"""
# 3. cummin(axis=0, skipna=true)
res = series_open.cummin()
plt.subplot(223)
res.plot()
plt.title("cummin(axis=0, skipna=true)")
print(res, "\r\n")
"""
date
2019-10-1 30.370001
2019-10-10 29.209999
2019-10-11 28.950001
2019-10-14 28.950001
2019-10-15 28.950001
...
2022-3-3 15.960000
2022-3-4 15.960000
2022-3-7 15.960000
2022-3-8 15.960000
2022-3-9 15.960000
name: open, length: 725, dtype: float64
"""
# 4. cumprod(axis=0, skipna=true)
res = series_open.cumprod()
plt.subplot(224)
res.plot()
plt.title("cumprod(axis=0, skipna=true)")
plt.suptitle("累积统计函数")
print(res, "\r\n")
"""
date
2019-10-1 3.037000e+01
2019-10-10 8.871077e+02
2019-10-11 2.568177e+04
2019-10-14 7.761030e+05
2019-10-15 2.421442e+07
...
2022-3-3 inf
2022-3-4 inf
2022-3-7 inf
2022-3-8 inf
2022-3-9 inf
name: open, length: 725, dtype: float64
"""
4.7.4 自定义运算
apply(func, axis=0)- 作用:用于将指定的函数应用于数据的轴(行或列)上
- 参数说明:
func:要应用的函数。该函数应该接受一个 series 作为输入,并返回一个 标量 或 series。axis=0:指定要应用函数的轴。对于 series,该参数无效;对于 dataframe ,可以设置为 0 或 1(默认为 0),分别表示沿行或沿列应用函数。在示例中,axis=0表示沿列应用函数。
示例:定义一个对列,最大值-最小值的函数
df = data[["open", "close"]].copy()
print(type(df)) # <class 'pandas.core.frame.dataframe'>
print(df.head())
"""
open close
date
2019-10-1 30.370001 29.150000
2019-10-10 29.209999 28.870001
2019-10-11 28.950001 30.129999
2019-10-14 30.219999 31.120001
2019-10-15 31.200001 32.000000
"""
res = df.apply(func=lambda x: x.max() - x.min(), axis=0)
print(type(res)) # <class 'pandas.core.series.series'>
print(res)
"""
open 47.29
close 48.36
dtype: float64
"""
# 我们看一下过程
process_1 = df.max()
print(type(process_1)) # <class 'pandas.core.series.series'>
print(process_1)
"""
open 63.25
close 63.18
dtype: float64
"""
process_2 = df.min()
print(type(process_2)) # <class 'pandas.core.series.series'>
print(process_2)
"""
open 15.96
close 14.82
dtype: float64
"""
小结:
- 算术运算【知道】
- 逻辑运算【知道】
- 逻辑运算符号
- 逻辑运算函数
对象.query()对象.isin()
- 统计运算【知道】
对象.describe()- 统计函数
- 累积统计函数
- 自定义运算【知道】
apply(func, axis=0)
4.8 pandas 画图
学习目标:
- 了解 dataframe 的画图函数
- 了解 series 的画图函数
dataframe.plot(kind="line")series.plot(kind="line")
- 作用:用于绘制
series或dataframe的函数。它使用由选项plotting.backend指定的后端。默认情况下,使用matplotlib。 - 参数:
data:series或dataframe对象,调用该方法的对象。x: 仅在数据为dataframe时使用。标签或位置,默认为none。y: 仅在数据为dataframe时使用。标签、位置或标签列表、位置,默认为none。允许绘制一列与另一列。kind: 字符串,要生成的图形类型:line:折线图(默认);bar:垂直条形图;barh:水平条形图;hist:直方图;box:箱线图;kde:核密度估计图;density:与kde相同;area:面积图;pie(x):饼图;scatter(x, y):散点图(仅限 dataframe);hexbin(x, y):六边形图(仅限 dataframe)。
ax: matplotlib 轴对象,默认为none。当前图形的轴。subplots: 布尔值或可迭代序列,默认为 false。是否将列分组到子图中。sharex: 布尔值,默认为true(如果ax为none)否则为false。如果subplots=true,则共享x轴并将某些x轴标签设置为不可见。sharey: 布尔值,默认为false。如果subplots=true,则共享 y 轴并将某些y轴标签设置为不可见。layout: 元组,可选(行,列),用于子图布局。figsize: 元组(宽度,高度),以英寸为单位。图形对象的大小。use_index: 布尔值,默认为true。使用索引作为x轴刻度。title: 字符串或列表。用于绘图的标题。如果传递了字符串,则在图形顶部打印字符串。如果传递了列表并且subplots为true,则在相应子图上方打印列表中的每个项目。grid: 布尔值,默认为none(matlab 风格默认)。轴网格线。legend: 布尔值或 {reverse}。在轴子图上放置图例。
需要注意的是:
- dataframe 和 series 都可以画图:
- 有些图的横坐标是 index,数值为列;
- 有些图的横坐标需要我们指定;
- 有些图横纵坐标都需要我们指定。
- 因为 df 可能有多列,数据比较多,所以我们可以使用
df.loc或df.iloc来截取部分数据,以方便展示!
示例:
import matplotlib.pyplot as plt
print(data.head())
"""
open high low close
date
2019-10-1 30.370001 30.510000 28.650000 29.150000
2019-10-10 29.209999 29.280001 28.580000 28.870001
2019-10-11 28.950001 30.400000 28.940001 30.129999
2019-10-14 30.219999 31.540001 29.819000 31.120001
2019-10-15 31.200001 32.169998 31.195000 32.000000
"""
data_subset_df = data.iloc[:3, 1:2] # 取前三行第二列
print(type(data_subset_df)) # <class 'pandas.core.frame.dataframe'>
print(data_subset_df)
"""
high
date
2019-10-1 30.510000
2019-10-10 29.280001
2019-10-11 30.400000
"""
data_subset_series = data.iloc[:3, 1] # 取前三行第二列
print(type(data_subset_series)) # <class 'pandas.core.series.series'>
print(data_subset_series)
"""
date
2019-10-1 30.510000
2019-10-10 29.280001
2019-10-11 30.400000
name: high, dtype: float64
"""
fig, axes = plt.subplots(4, 3, figsize=[40, 16])
data.plot(kind="line", ax=axes[0][0], title="kind=line", grid=true, legend=true)
data.iloc[:10, :].plot(kind="bar", ax=axes[0][1], title="kind=bar")
data.iloc[:10, :].plot(kind="barh", ax=axes[0][2], title="kind=barh")
data.plot(kind="hist", ax=axes[1][0], title="kind=hist")
data.plot(kind="box", ax=axes[1][1], title="kind=box")
data.plot(kind="kde", ax=axes[1][2], title="kind=kde")
data.plot(kind="density", ax=axes[2][0], title="kind=density")
data.plot(kind="area", ax=axes[2][1], title="kind=area")
data.iloc[:5, 2].plot(kind="pie", ax=axes[2][2], title="kind=pie")
data.plot(kind="scatter", x="open", y="high", ax=axes[3][0], title="kind=scatter")
data.plot(kind="hexbin", x="open", y="high", ax=axes[3][1], title="kind=hexbin")
# 不能直接调节透明度,我们可以对axes进行调节
# 使用 for 循环遍历所有轴对象并调整网格线透明度
# for row in axes:
# for ax in row:
# ax.grid(true, alpha=0.5)
plt.show()
4.9 文件读取与存储
学习目标
- 了解 pandas 的几种文件读取存储操作
- 应用 csv 方式、hdf 方式和 json 方式实现文件的读取和存储
我们的数据大部分存在于文件当中,所以 pandas 会支持复杂的 i/o 操作,pandas 的 api 支持众多的文件格式,如 .csv、.sql、.xls、.json、.hdf5。
| 文件格式 | 数据描述 | 文件后缀 | 读取语法 | 写入语法 |
|---|---|---|---|---|
| 文本文件 | csv | .csv | pd.read_csv() | df.to_csv() |
| 文本文件 | json | .json | pd.read_json() | df.to_json() |
| 文本文件 | html | .html或.htm | pd.read_html() | df.to_html() |
| 文本文件 | local clipboard (剪切板) | 无 | pd.read_clipboard() | df.to_clipboard() |
| 二进制文件 | ms excel | .xls或.xlsx | pd.read_excel() | df.to_excel() |
| 二进制文件 | hdf5 format | .h5或.hdf5 | pd.read_hdf() | df.to_hdf() |
| 二进制文件 | feather format | .feather | pd.read_feather() | df.to_feather() |
| 二进制文件 | parquet format | .parquet | pd.read_parquet() | df.to_parquet() |
| 二进制文件 | msgpack | .msg或.mspack | pd.read_msgpack() | df.to_msgpack() |
| 二进制文件 | stata | .dta | pd.read_stata() | df.to_stata() |
| 二进制文件 | sas | .sas7bdat | pd.read_sas() | `` |
| 二进制文件 | python pickle format | .pkl或.pickle | pd.read_pickle() | df.to_pickle() |
| sql | sql | 无(.sql或.db) | pd.read_sql() | pd.to_sql() |
| sql | google big query | 无 | pd.read_gbq() | df.to_gbq() |
注意:
- local clipboard 不是一种文件格式,而是指计算机的剪贴板。它不具有特定的文件后缀。
- sql 通常没有特定的文件后缀,但有时会使用
.sql或.db。 - google big query 不是一种文件格式,而是一种云端数据存储和分析服务,因此没有特定的文件后缀。
文本文件和二进制文件的优缺点:
- 二进制文件的优点包括:
- 通常占用更少的磁盘空间,因为它们可以使用更紧凑的数据表示形式。
- 可以更快地读取和写入,因为不需要进行文本解析和格式化。
- 可以存储更多类型的数据,包括图像、音频和视频等。
- 二进制文件的缺点包括:
- 不易于人类阅读和编辑,因为它们不是以文本形式存储的。
- 可能不具有跨平台兼容性,因为不同的计算机系统可能使用不同的二进制数据表示形式。
- 文本文件的优点包括:
- 易于人类阅读和编辑,因为它们是以文本形式存储的。
- 具有很好的跨平台兼容性,因为文本文件通常使用标准化的字符编码。
- 文本文件的缺点包括:
- 通常占用更多的磁盘空间,因为它们使用文本形式存储数据。
- 读取和写入速度可能较慢,因为需要进行文本解析和格式化。
- 可能无法存储某些类型的数据,例如图像、音频和视频等。
4.9.1 csv
csv(comma-separated values) 是逗号分隔值的意思。csv 文件是一个存储表格和电子表格信息的纯文本文件,其内容通常是一个文本、数字或日期的表格。csv 文件可以使用以表格形式存储数据的程序轻松导入和导出。通常 csv 文件的第一行包含表格的列标签。随后的每一行代表表格的一行。逗号分隔行中的每个单元格,这就是名称的由来。
pd.read_csv(filepath_or_buffer, sep=",") -> dataframedf.to_csv()
一、pd.read_csv()
pd.read_csv(filepath_or_buffer, sep=",") -> dataframe:
- 作用:用于从 csv 文件(逗号分隔值)或类似的文本文件中读取数据。它返回一个包含文件数据的
pandas.dataframe对象。 - 参数说明:
filepath_or_buffer:字符串或文件句柄,指定要读取的文件的路径或类似文件的对象。sep:字符串,指定字段分隔符。- 默认为
,。
- 默认为
header:整数或整数列表,指定行号以用作列名。- 默认为
infer,表示第一行为列名。
- 默认为
names:数组类型,指定列名。- 如果文件中不包含列名,则应指定此参数。
index_col:整数、字符串或整数/字符串序列,指定一列或多列作为dataframe的行索引。- 如果不想进行索引,可以设置
index_col=none。
- 如果不想进行索引,可以设置
usecols:列表类型,指定要读取的列。可以使用列索引或列名。
- 返回值:
- 返回值是一个 pandas.dataframe 对象,其中包含从 csv 文件中读取的数据。
示例:读取 uber.csv 文件,并指定只获取 “open”, “close” 指标
# 读取csv文件,并指定只获取"open", "close"指标
data = pd.read_csv(filepath_or_buffer="./data/uber.csv", sep=',', index_col="date", usecols=["date", "open", "close"])
print(data.head())
"""
open close
date
2019-5-10 42.000000 41.570000
2019-5-13 38.790001 37.099998
2019-5-14 38.310001 39.959999
2019-5-15 39.369999 41.290001
2019-5-16 41.480000 43.000000
"""
二、df.to_csv()
df.to_csv(path_or_buf, sep=",") -> none:
- 作用:用于将
pandas.dataframe对象中的数据写入 csv 文件(逗号分隔值)或类似的文本文件。它返回 none。 - 参数说明:
path_or_buf:字符串或文件句柄,指定要写入的文件的路径或类似文件的对象。sep:字符串,指定字段分隔符。- 默认为
,。
- 默认为
na_rep:字符串,指定缺失值的表示形式。- 默认为
''(空字符串:什么都不写入)。
- 默认为
header:布尔值或字符串列表,指定是否写入列名。- 如果为
true,则使用列名; - 如果为字符串列表,则使用提供的列名;
- 如果为
false,则不写入列名。
- 如果为
index:布尔值,指定是否写入行索引。默认为true。columns:序列类型,指定要写入的列。- 如果未指定,则写入所有列。
mode:指定写入文件时使用的模式。它的默认值为'w',表示写入模式。'w':写入模式。如果文件已存在,则覆盖其内容;如果文件不存在,则创建新文件。'a':追加模式。如果文件已存在,则在其末尾追加内容;如果文件不存在,则创建新文件。'x':独占模式。仅当文件不存在时才创建新文件。
- 返回值:
- 没有返回值
示例:保存 “open” 列的数据,并读取查看结果。
# 保存"open"列的数据,并读取查看结果。
data.to_csv(path_or_buf="./data/uber_open.csv", header=true, index=true, columns=["open"], mode='w')
print("保存成功!")
# 读取
res = pd.read_csv(filepath_or_buffer="./data/uber_open.csv")
print(res.head())
"""
date open
0 2019-5-10 42.000000
1 2019-5-13 38.790001
2 2019-5-14 38.310001
3 2019-5-15 39.369999
4 2019-5-16 41.480000
"""
# 重新确定索引(在读取csv文件的时候也可以进行)
res.set_index(keys="date", drop=true, inplace=true)
print(res.head())
"""
open
date
2019-5-10 42.000000
2019-5-13 38.790001
2019-5-14 38.310001
2019-5-15 39.369999
2019-5-16 41.480000
"""
根据上面的结果会发现将索引存入到文件当中,变成单独的一列数据。如果需要删除,可以指定 index 参数,删除原来的文件,重新保存一次。
# 保存"open"列的数据,并读取查看结果。
data.to_csv(path_or_buf="./data/uber_open.csv", header=true, index=false, columns=["open"], mode='w')
print("保存成功!")
# 读取
res = pd.read_csv(filepath_or_buffer="./data/uber_open.csv", index_col=none)
print(res.head())
"""
open
0 42.000000
1 38.790001
2 38.310001
3 39.369999
4 41.480000
"""
"""
在代码中将 `index_col` 参数设置为 `none`,这意味着在读取数据时不会使用任何一列作为索引。
但是,当我们查看结果时,我们会发现仍然显示了索引。这是因为在 pandas 中,每个 dataframe
都有一个默认的索引,即使我们没有指定索引列。这个默认的索引是一个整数序列,从 0 开始。
所以,在我们的例子中,看到的索引实际上是 dataframe 的默认索引,而不是从文件中读取的数据。
"""
4.9.2 hdf5
hdf5 文件的英文全称是 hierarchical data format version 5。它是一种存储相同类型数值的大数组的机制,适用于可被层次性组织且数据集需要被元数据标记的数据模型。一个 hdf5 文件是一种存放两类对象的容器:dataset 和 group。dataset 是类似于数组的数据集,而 group 是类似文件夹一样的容器,存放 dataset 和其他 group。
pd.read_hdf()df.to_hdf()
hdf5 文件的读取和存储需要指定一个键,值为要存储的 dataframe。
一、pd.read_hdf()
pd.read_hdf(path_or_buf, key=none, **kwargs) -> dataframe:
- 作用:用于从 hdf5 文件中读取数据。hdf5 是一种用于存储大量数据的文件格式。
- 参数说明:
path_or_buf:指定要读取的 hdf5 文件的路径。key:指定要读取的 hdf5 文件中的对象。mode:指定文件打开模式,默认为'r',表示只读模式。'r':只读模式。这是默认值。'r+':读写模式。文件必须已经存在。'a':读写模式。如果文件不存在,则创建新文件。'w'或'w-':写模式。如果文件已经存在,则覆盖原有内容。- 需要注意的是,
mode参数只在使用 pytables 库时有效。如果使用的是 h5py 库,则mode参数会被忽略。
where:指定查询条件,用于筛选数据。columns:指定要读取的列。start和stop:指定要读取的行范围。
- 返回值:
- 返回一个 dataframe 对象,其中包含从 hdf5 文件中读取的数据。
示例:
# 读取.h5文件
data = pd.read_hdf(path_or_buf="./data/uber.h5", key="uber")
print(type(data)) # <class 'pandas.core.frame.dataframe'>
print(data.head())
"""
open high low close adj close volume
date
2019-5-10 42.000000 45.000000 41.060001 41.570000 41.570000 186322500
2019-5-13 38.790001 39.240002 36.080002 37.099998 37.099998 79442400
2019-5-14 38.310001 39.959999 36.849998 39.959999 39.959999 46661100
2019-5-15 39.369999 41.880001 38.950001 41.290001 41.290001 36086100
2019-5-16 41.480000 44.060001 41.250000 43.000000 43.000000 38115500
"""
注意:在读取 .h5 文件时报错,需要安装 tables 库。
pip install tables
二、df.to_hdf()
df.to_hdf(path_or_buf, key, **kwargs) -> none:
- 作用:用于将 pandas dataframe 写入 hdf5 文件的方法。hdf5 是一种自描述的文件格式,允许应用程序在没有外部信息的情况下解释文件的结构和内容。一个 hdf5 文件可以容纳一组相关对象,可以作为一组或作为单个对象访问。它返回 none。
- 参数说明:
path_or_buf:文件路径或 hdfstore 对象。key:存储中组的标识符。mode:打开文件的模式。默认为 ‘a’,表示追加模式。'w':写入模式。如果文件已存在,则覆盖其内容;如果文件不存在,则创建新文件。'a':追加模式。如果文件已存在,则在其末尾追加内容;如果文件不存在,则创建新文件。'x':独占模式。仅当文件不存在时才创建新文件。
format:指定写入格式。可选值为 ‘fixed’ 或 ‘table’。data_columns:要创建为磁盘查询的索引数据列的列列表,或 true 以使用所有列。
- 返回值:
- 没有返回值
示例:
# 存储文件
data.iloc[:10, :].to_hdf(path_or_buf="./data/uber_row_10.h5", key="row_10", mode='w')
print("保存成功")
# 再次读取文件并查看内容
res = pd.read_hdf("./data/uber_row_10.h5", key="row_10")
print(type(res)) # <class 'pandas.core.frame.dataframe'>
print(res)
"""
open high low close adj close volume
date
2019-5-10 42.000000 45.000000 41.060001 41.570000 41.570000 186322500
2019-5-13 38.790001 39.240002 36.080002 37.099998 37.099998 79442400
2019-5-14 38.310001 39.959999 36.849998 39.959999 39.959999 46661100
2019-5-15 39.369999 41.880001 38.950001 41.290001 41.290001 36086100
2019-5-16 41.480000 44.060001 41.250000 43.000000 43.000000 38115500
2019-5-17 41.980000 43.290001 41.270000 41.910000 41.910000 20225700
2019-5-20 41.189999 41.680000 39.459999 41.590000 41.590000 29222300
2019-5-21 42.000000 42.240002 41.250000 41.500000 41.500000 10802900
2019-5-22 41.049999 41.279999 40.500000 41.250000 41.250000 9089500
2019-5-23 40.799999 41.090000 40.020000 40.470001 40.470001 11119900
"""
三、key 参数及其获取
key 参数用于指定存储中组的标识符。你可以任意指定 key 的值,但是要确保它是一个字符串。如果你想在同一个 hdf5 文件中添加另一个 dataframe 或 series,请使用追加模式并使用不同的键。
q1:这个key相当于是一个密码吗?
a1:不,key 参数不是密码。它是一个字符串,用于标识 hdf5 文件中的组。你可以把它看作是一个名称,用于在 hdf5 文件中组织和存储数据。
q2:那如果我不知道一个.h5文件的key,那么在使用pd.read_hdf()时怎么确定key参数呢?
a2:如果你不知道一个 hdf5 文件中的 key,你可以使用 pandas.hdfstore 类来查看文件中可用的键。例如,你可以这样做:
store = pd.hdfstore(path="./data/uber.h5")
print(store.keys()) # ['/uber']
store.close()
上面的代码将打开名为 filename.h5 的 hdf5 文件,并打印出文件中可用的键。然后你就可以使用这些键中的一个来读取数据了。
四、h5文件的优势
推荐优先选择使用 hdf5 文件存储,原因如下:
- hdf5 在存储的时候支持压缩,使用的方式是 blosc,这个是速度最快的也是 pandas 默认支持的
- 使用压缩可以提磁盘利用率,节省空间
- hdf5 还是跨平台的,它可以在不同的操作系统和硬件平台上使用,包括 pc 端和移动端、windows 和 linux、安卓和 ios 等
4.9.3 json
json 是一种轻量级的数据交换格式,它基于 ecmascript (w3c 制定的 js 规范)的一个子集,采用完全独立于编程语言的文本格式来存储和表示数据。它易于人阅读和编写,同时也易于机器解析和生成,并有效地提升网络传输效率。
json 数据的书写格式是:名称/值对。名称/值对组合中的名称写在前面(在双引号中),值对写在后面,中间用冒号隔开。其中值可以是:数字(整数或浮点数)、字符串(在双引号中)、布尔值(true或false)、数组(在方括号中)、对象(在花括号中)、null。
pd.read_json()df.to_json()
一、pd.read_json()
pd.read_json(path_or_buf=none, orient=none, typ="frame", lines=false) -> dataframe:
- 作用:将 json 格式的字符串或文件读取为 dataframe。
- 参数说明:
path_or_buf:默认为 none。表示要读取的 json 字符串或文件路径。orient:str,指定解析 json 的格式。可选值包括- ‘split’:表示 json 字符串为 dict-like
{index -> [index], columns -> [columns], data -> [values]}的形式。- 像
{index -> [index], columns -> [columns], data -> [values]}这样的字典
- 像
- ‘records’:表示 json 字符串为 list-like
[{column -> value}, … , {column -> value}]的形式。- 像
[ {column -> value}, ... , {column -> value}]这样的列表
- 像
- ‘index’:表示 json 字符串为 dict-like
{index -> {column -> value}}的形式。- 像
{index -> {column -> value}}这样的字典
- 像
- ‘columns’: 表示 json 字符串为 dict-like
{column -> {index -> value}}的形式。- 像
{column -> {index -> value}}这样的字典
- 像
- ‘values’:表示 json 字符串仅为
values数组。- 只是值数组
- ‘split’:表示 json 字符串为 dict-like
typ:str,指定返回的数据类型,默认为 ‘frame’。- 可选值包括:
- ‘frame’:表示返回一个 pandas dataframe 对象。这是默认值。
- ‘series’:表示返回一个 pandas series 对象。
- 可选值包括:
dtype:参数用于控制是否推断列的数据类型。它可以是布尔值或字典。默认为 true。- 如果
dtype为 true(默认值),则会推断列的数据类型。 - 如果
dtype为 false,则不会推断列的数据类型,而是直接使用数据。 - 如果
dtype为字典,则会使用字典中指定的列的数据类型。
- 如果
lines:bool,默认为 false。- 如果为 true,则每行读取该文件作为 json 对象。
- 返回值:
- 返回一个 dataframe 对象。
直观展示 orient 参数:
下面是一个示例 dataframe:
a b
0 1 2
1 3 4
- 当
orient='split'时,json 字符串如下:
‘split’:表示 json 字符串为 dict-like {index -> [index], columns -> [columns], data -> [values]} 的形式。
{"columns":["a","b"],"index":[0,1],"data":[[1,2],[3,4]]}
- 当
orient='records'时,json 字符串如下:
‘records’:表示 json 字符串为 list-like [{column -> value}, … , {column -> value}] 的形式。
[{"a":1,"b":2},{"a":3,"b":4}]
- 当
orient='index'时,json 字符串如下:
‘index’:表示 json 字符串为 dict-like {index -> {column -> value}} 的形式。
{"0":{"a":1,"b":2},"1":{"a":3,"b":4}}
- 当
orient='columns'时,json 字符串如下:
‘columns’: 表示 json 字符串为 dict-like {column -> {index -> value}} 的形式。
{"a":{"0":1,"1":3},"b":{"0":2,"1":4}}
- 当
orient='values'时,json 字符串如下:
‘values’:表示 json 字符串仅为 values 数组。
[[1,2],[3,4]]
直观展示 lines 参数:
下面是一个简单的例子,演示如何使用 lines 参数从包含多个 json 对象的文件中读取数据:
import pandas as pd
from io import stringio
data = """
{"a": 1, "b": 2}
{"a": 3, "b": 4}
"""
df = pd.read_json(stringio(data), lines=true)
print(df)
输出结果为:
a b
0 1 2
1 3 4
在这个例子中,我们使用 stringio 模拟一个包含多行 json 对象的文件。然后,我们使用 pd.read_json() 函数并将 lines 参数设置为 true 来读取数据。最后,我们打印出结果 dataframe。
当 lines 参数设置为 false(默认值)时,pd.read_json() 函数期望读取一个包含单个 json 对象的文件。下面是一个简单的例子,演示如何从包含单个 json 对象的文件中读取数据:
import pandas as pd
from io import stringio
data = """
{
"a": [1, 3],
"b": [2, 4]
}
"""
df = pd.read_json(stringio(data))
print(df)
输出结果为:
a b
0 1 2
1 3 4
在这个例子中,我们使用 stringio 模拟一个包含单个 json 对象的文件。然后,我们使用 pd.read_json() 函数并保留 lines 参数的默认值 false 来读取数据。最后,我们打印出结果 dataframe。
示例:
这里使用一个新闻标题讽刺数据集,格式为 .json。“is_sarcastic”: 1 讽刺的,否则为 0;“headline”:新闻报道的标题;“article_link”:链接到原始新闻文章。存储格式为:
案例数据集下载地址:news headlines dataset for sarcasm detection
{"article_link": "https://www.huffingtonpost.com/entry/versace-black-code_us_5861fbefe4b0de3a08f600d5", "headline": "former versace store clerk sues over secret 'black code' for minority shoppers", "is_sarcastic": 0}
{"article_link": "https://www.huffingtonpost.com/entry/roseanne-revival-review_us_5ab3a497e4b054d118e04365", "headline": "the 'roseanne' revival catches up to our thorny political mood, for better and worse", "is_sarcastic": 0}
读取:orient 指定解析 json 的格式。
import pandas as pd
# lines = true
df_json = pd.read_json("./data/sarcasm_headlines_dataset.json", orient="records", lines=true)
print(type(df_json)) # <class 'pandas.core.frame.dataframe'>
print(df_json.head())
"""
article_link \
0 https://www.huffingtonpost.com/entry/versace-b...
1 https://www.huffingtonpost.com/entry/roseanne-...
2 https://local.theonion.com/mom-starting-to-fea...
3 https://politics.theonion.com/boehner-just-wan...
4 https://www.huffingtonpost.com/entry/jk-rowlin...
headline is_sarcastic
0 former versace store clerk sues over secret 'b... 0
1 the 'roseanne' revival catches up to our thorn... 0
2 mom starting to fear son's web series closest ... 1
3 boehner just wants wife to listen, not come up... 1
4 j.k. rowling wishes snape happy birthday in th... 0
"""
# lines = false
# df_json = pd.read_json("./data/sarcasm_headlines_dataset.json", orient="records", lines=false)
# print(df_json) # valueerror: trailing data
"""
valueerror: trailing data 是一个常见的错误,它通常发生在使用 pd.read_json() 函数读取 json 文件时。这个错误表示 json 文件中存在多余的数据。
这个错误通常发生在 json 文件中包含多个 json 对象,但没有使用 lines=true 参数来指定每行都是一个单独的 json 对象。例如,如果你有一个 json 文件,其中包含多个 json 对象,每个对象都在一行中,你可以使用 pd.read_json(file, lines=true) 来读取这个文件。
如果你的 json 文件不是这种格式,那么你可能需要检查文件中是否存在多余的数据,并删除它们。
"""
# 1. orient = split
# df_json = pd.read_json("./data/sarcasm_headlines_dataset.json", orient="split", lines=true)
# print(df_json.head()) # attributeerror: 'list' object has no attribute 'items'
# 2. orient = records
df_json = pd.read_json("./data/sarcasm_headlines_dataset.json", orient="records", lines=true)
print(df_json.head())
"""
article_link \
0 https://www.huffingtonpost.com/entry/versace-b...
1 https://www.huffingtonpost.com/entry/roseanne-...
2 https://local.theonion.com/mom-starting-to-fea...
3 https://politics.theonion.com/boehner-just-wan...
4 https://www.huffingtonpost.com/entry/jk-rowlin...
headline is_sarcastic
0 former versace store clerk sues over secret 'b... 0
1 the 'roseanne' revival catches up to our thorn... 0
2 mom starting to fear son's web series closest ... 1
3 boehner just wants wife to listen, not come up... 1
4 j.k. rowling wishes snape happy birthday in th... 0
"""
# 3. orient = index
# df_json = pd.read_json("./data/sarcasm_headlines_dataset.json", orient="index", lines=true)
# print(df_json.head()) # attributeerror: 'list' object has no attribute 'values'
# 4. orient = columns
df_json = pd.read_json("./data/sarcasm_headlines_dataset.json", orient="columns", lines=true)
print(df_json.head())
"""
article_link \
0 https://www.huffingtonpost.com/entry/versace-b...
1 https://www.huffingtonpost.com/entry/roseanne-...
2 https://local.theonion.com/mom-starting-to-fea...
3 https://politics.theonion.com/boehner-just-wan...
4 https://www.huffingtonpost.com/entry/jk-rowlin...
headline is_sarcastic
0 former versace store clerk sues over secret 'b... 0
1 the 'roseanne' revival catches up to our thorn... 0
2 mom starting to fear son's web series closest ... 1
3 boehner just wants wife to listen, not come up... 1
4 j.k. rowling wishes snape happy birthday in th... 0
"""
# 5. orient = values
df_json = pd.read_json("./data/sarcasm_headlines_dataset.json", orient="values", lines=true)
print(df_json.head())
"""
article_link \
0 https://www.huffingtonpost.com/entry/versace-b...
1 https://www.huffingtonpost.com/entry/roseanne-...
2 https://local.theonion.com/mom-starting-to-fea...
3 https://politics.theonion.com/boehner-just-wan...
4 https://www.huffingtonpost.com/entry/jk-rowlin...
headline is_sarcastic
0 former versace store clerk sues over secret 'b... 0
1 the 'roseanne' revival catches up to our thorn... 0
2 mom starting to fear son's web series closest ... 1
3 boehner just wants wife to listen, not come up... 1
4 j.k. rowling wishes snape happy birthday in th... 0
"""

二、df.to_json()
df.to_json(path_or_buf=none, orient=none, lines=false) -> none:
- 作用:将 pandas dataframe 对象转换为 json 字符串的函数。注意,
nan和none会被转换为null,而datetime对象会被转换为unix时间戳。它返回none。 - 参数说明:
path_or_buf:字符串、路径对象或类文件对象,或 none(默认)。- 如果为 none,则结果作为字符串返回。
orient:指示预期的 json 字符串格式。对于 dataframe,默认值为 ‘columns’,允许的值有:{"split","records","index","columns","values","table"}。date_format:日期转换类型。它可以是none、'epoch'或'iso'- 如果设置为
'epoch',则日期将转换为 epoch 毫秒; - 如果设置为
'iso',则日期将转换为 iso8601 格式。 - 默认值取决于
orient参数。- 对于
orient='table',默认值为'iso'; - 对于所有其他
orient,默认值为'epoch'。
- 对于
- 如果设置为
double_precision:编码浮点值时使用的小数位数,默认为 10。force_ascii:强制编码字符串为 ascii,默认为 true。date_unit:编码时间单位,默认为 “ms”(毫秒)。default_handler:如果对象无法转换为 json 的适当格式,则调用的处理程序,默认为 none。lines:如果 “orient” 为 “records”,则以行分隔的 json 格式写出,默认为 false。compression:用于对输出数据进行即时压缩。- 如果设置为
'infer'(默认值),并且path_or_buf是类路径,则从以下扩展名中检测压缩:‘.gz’、‘.bz2’、‘.zip’、‘.xz’、‘.zst’、‘.tar’、‘.tar.gz’、‘.tar.xz’ 或 ‘.tar.bz2’(否则不压缩)。 - 如果设置为
none,则不进行压缩。
- 如果设置为
- 返回值:
- 没有返回值
示例:
# 1. 存储文件(lines=false)
df_json.iloc[:3, :].to_json("./data/test.json", orient="records")
"""
此时json文件中的内容如下:
[{"article_link":"https:\/\/www.huffingtonpost.com\/entry\/versace-black-code_us_5861fbefe4b0de3a08f600d5","headline":"former versace store clerk sues over secret 'black code' for minority shoppers","is_sarcastic":0},{"article_link":"https:\/\/www.huffingtonpost.com\/entry\/roseanne-revival-review_us_5ab3a497e4b054d118e04365","headline":"the 'roseanne' revival catches up to our thorny political mood, for better and worse","is_sarcastic":0},{"article_link":"https:\/\/local.theonion.com\/mom-starting-to-fear-son-s-web-series-closest-thing-she-1819576697","headline":"mom starting to fear son's web series closest thing she will have to grandchild","is_sarcastic":1}]
因为我们没有设置lines=true,所以所有内容都保存到一行了
"""
# 2. 存储文件(lines=true):为了方便我们查看json文件,设置lines=true
df_json.iloc[:3, :].to_json("./data/test.json", orient="records", lines=true)
"""
此时json文件中的内容如下:
{"article_link":"https:\/\/www.huffingtonpost.com\/entry\/versace-black-code_us_5861fbefe4b0de3a08f600d5","headline":"former versace store clerk sues over secret 'black code' for minority shoppers","is_sarcastic":0}
{"article_link":"https:\/\/www.huffingtonpost.com\/entry\/roseanne-revival-review_us_5ab3a497e4b054d118e04365","headline":"the 'roseanne' revival catches up to our thorny political mood, for better and worse","is_sarcastic":0}
{"article_link":"https:\/\/local.theonion.com\/mom-starting-to-fear-son-s-web-series-closest-thing-she-1819576697","headline":"mom starting to fear son's web series closest thing she will have to grandchild","is_sarcastic":1}
"""
4.10 高级处理:缺失值处理
学习目标:
- 应用
isnull判断是否有缺失数据 nan。 - 应用
fillna实现缺失值的填充 - 应用
dropna实现缺失值所在 行 / 列 的删除 - 应用
replace实现数据的替换
在 pandas 中,缺失值分为两种,一种是pandas中的空值,另一种是自定义的缺失值。pandas中的空值有三个:np.nan (not a number) 、 none 和 pd.nat (时间格式的空值,注意大小写不能错),这三个值可以用pandas中的函数 isnull (),notnull (),isna () 进行判断。
nan是 “not a number” 的缩写,中文翻译为 “非数字”。它表示一个未定义或不可表示的值,通常用于浮点运算中。null是一个特殊的值,表示没有值或没有对象。它在许多编程语言中都有类似的概念。在中文中,它通常被翻译为 “空值” 或 “无”。none是 python 中的一个特殊常量,表示空值或无。它在许多情况下用于表示变量未被初始化或函数没有返回值。在中文中,它通常被翻译为 “无” 或 “空”。
如何处理nan?
- 获取缺失值的标记方式(nan 或者其他标记方式)
- 如果缺失值的标记方式是 nan
- 判断数据中是否包含 nan:
pd.isnull(df) -> df:接受一个参数,即要检测的对象(例如 dataframe 或 series),并返回一个与输入对象形状相同的布尔值对象,其中缺失值的位置为 true,非缺失值的位置为 false。pd.notnull(df) -> df:与pd.isnull(df)函数相反,它返回一个与输入对象形状相同的布尔值对象,其中缺失值的位置为 false,非缺失值的位置为 true。- 返回一个值为 bool 的 df 对象一般需要借助 numpy 函数来判断这个对象是否存在缺失值:
pd.isnull()配合np.any()使用np.any(pd.isnull(df)) # 里面如果有一个缺失值,就返回true
pd.notnull()配合np.all()使用np.all(pd.notnull(df)) # 里面如果有一个缺失值,就返回false
- 存在缺失值
nan:- 删除存在缺失值的:
df.dropna(axis="rows", how="any") -> df- 注:不会修改原数据,需要接受返回值
- 替换缺失值:
df.fillna(value, inplace=true) -> dfvalue:替换成的值inplace=true:会修改原数据inplace=false:不修改原数据,而是替换后生成新的对象- 例子:
df[col].fillna(value=df[col].mean(), inplace=true)
- 删除存在缺失值的:
- 如果缺失值没有使用 nan 标记,替换:
df.replace(to_replace=, value=np.nan, inplace=false) -> df- 参数:
to_replace:替换前的值(要替换的值)value:替换后的值inplace=false:是否原地操作
- 例子:比如使用
'?'作为空值- 先替换
'?'为np.nan,然后继续处理 df.replace(to_replace='?', value=np.nan)
- 先替换
- 参数:
- 判断数据中是否包含 nan:
q:什么时候用删除,什么时候用替换呢?
a:缺失值不是太多的时候,一般可以将缺失值所在行删除;如果数据非常重要,且缺失值较多,一般使用替换。
特别说明:df.dropna -> df
- 作用:用于删除 dataframe 或 series 中的缺失值。
- 参数:
axis:指定删除缺失值的轴,0或'index'表示删除包含缺失值的行,1或'columns'表示删除包含缺失值的列。默认值为0。how:指定删除缺失值的方式。'any'表示只要有缺失值就删除整行/列'all'表示只有当整行/列都是缺失值时才删除- 默认值为
'any'
thresh:指定行/列中非缺失值的最小数量,只有当非缺失值的数量小于这个阈值时才会删除该行/列。默认值为none。subset:指定在哪些行/列中查找缺失值。默认值为none,表示在整个 dataframe/series 中查找。inplace:指定是否在原地修改数据。- 如果为
true,则不返回任何值,直接在原 dataframe/series 上进行修改; - 如果为
false,则返回一个新的 dataframe/series,原 dataframe/series 不变。默认值为false。
- 如果为
- 返回值:返回一个新的 dataframe/series,其中已经删除了包含缺失值的行/列。
案例:电影数据的缺失值处理。
数据集下载地址:imdb data from 2006 to 2016
# 1. 读取电影数据
movie = pd.read_csv(filepath_or_buffer="./data/imdb-movie-data.csv")
movie.head()

# 2. 判断缺失值是否存在
res = pd.notnull(movie) # 缺失值的位置为false
res.head()

对于一张大表而言,使用pd.notnull或pd.isnull来判断的话,我们很难知道这个 df 对象有没有缺失值。因此我们需要借助 numpy 的 np.all() 函数来进行判断,如果返回 true,说明没有缺失值;如果返回 false,说明有缺失值。
np.all():- 作用:用于测试沿指定轴的所有元素是否都为true。
- 参数:
a:输入数组。axis:沿着哪个轴进行计算。默认情况下,将所有元素视为一个大数组。out:可选,指定结果的输出数组。keepdims:可选,如果为 true,则保留输入数组的维度。
- 返回值:返回一个布尔值或布尔值数组,表示沿指定轴的所有元素是否都为 true。
np.all()的示例:
import numpy as np
a = np.array([[true, true], [true, true]])
b = np.array([[true, false], [true, true]])
print(a)
"""
[[ true true]
[ true true]]
"""
print(b)
"""
[[ true false]
[ true true]]
"""
print(np.all(a)) # true
print(np.all(b)) # false
print(np.all(b, axis=0)) # [ true false]
print(np.all(b, axis=1)) # [false true]
# 3. 使用np.all()来判断是否存在缺失值
print(np.all(res)) # false -> 说明存在缺失值
pd.isnull() 和 pd.notnull() 是相反的,且判断函数不使用 np.all(),而是 np.any()!
import pandas as pd
import numpy as np
# 1. 读取电影数据
movie = pd.read_csv(filepath_or_buffer="./data/imdb-movie-data.csv")
# 2. 判断缺失值是否存在
res = pd.isnull(movie) # true: 缺失值; false: 不是缺失值
# 3. 使用np.any()来判断是否存在缺失值
print(np.any(res)) # true -> 说明存在缺失值
情况一、存在缺失值nan,并且是np.nan

这种空值就是 np.nan。
- 方法1:删除缺失值
- 方法2:替换缺失值
- 方法3:替换所有缺失值(这个是最重要的,我们只执行这一步就行)
# 读取电影数据
data = pd.read_csv(filepath_or_buffer="./data/imdb-movie-data.csv")
# 方法1:删除缺失值
data.dropna(how="all", inplace=true)
data
# 读取电影数据
data = pd.read_csv(filepath_or_buffer="./data/imdb-movie-data.csv")
# 方法2:替换缺失值
"""
替换存在缺失值的两列,替换方法有平均值、中位数
"""
data["revenue (millions)"].fillna(data["revenue (millions)"].mean(), inplace=true)
data["metascore"].fillna(data["metascore"].median(), inplace=true)
# 我们再看一下这两列有缺失值吗?
print(np.any(pd.isnull(data["revenue (millions)"]))) # false -> 没有缺失值了
print(np.any(pd.isnull(data["metascore"]))) # false -> 没有缺失值了
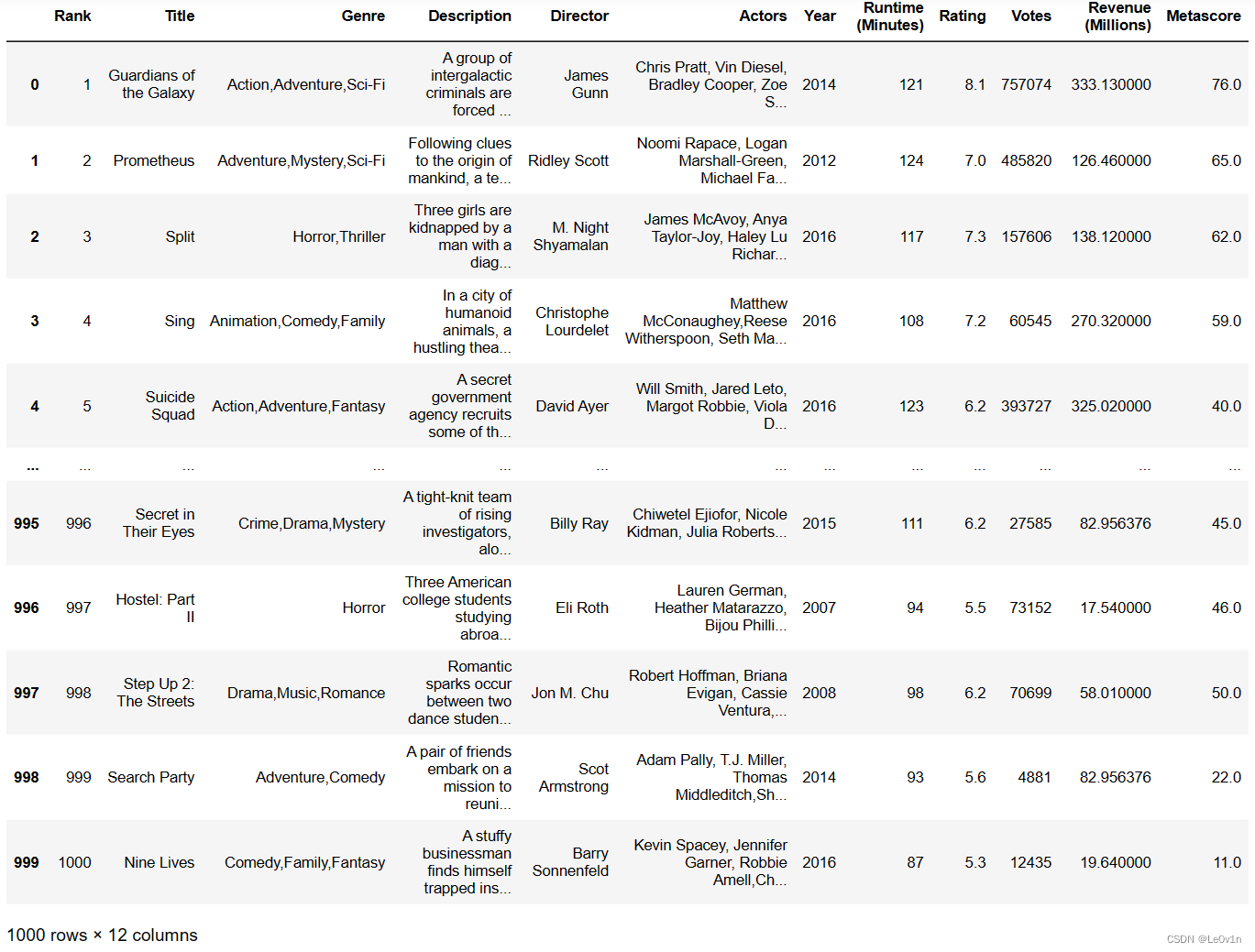
上面这种替换缺失值有点慢,我们替换所有的缺失值:
# 读取电影数据
data = pd.read_csv(filepath_or_buffer="./data/imdb-movie-data.csv")
# 方法3:替换所有缺失值(这个是最重要的,我们只执行这一步就行)
for col in data.columns:
if np.all(pd.notnull(data[col])) == false: # 有缺失值
print(col) # 打印有缺失值的列名
data[col].fillna(data[col].mean(), inplace=true)
# 我们再看一下df对象还有缺失值吗?
print(np.all(pd.notnull(data))) # true -> 没有缺失值了
情况二、不是缺失值 nan,有默认标记
# 我们手动创建一个空值为?的csv文件
movie = pd.read_csv("./data/imdb-movie-data.csv")
data = moive.fillna(value='?')
data.to_csv(path_or_buf="./data/test.csv")
# 或者直接使用data.to_csv(path_or_buf="./data/test.csv", rep_na='?')也可以
数据是这样的:
思路:
- 先替换
'?'为np.nandf.replace(to_replace=, value=)to_replace:替换前的值value:替换后的值
- 再进行缺失值的处理
- 替换所有缺失值
# 读取数据
data = pd.read_csv("./data/test.csv")
# 1. 替换'?'为np.nan
data.replace(to_replace='?', value=np.nan, inplace=true)
# 2. 再进行缺失值处理
## 替换所有缺失值
for col in data.columns:
if np.all(pd.notnull(data[col])) == false: # 有缺失值
print(col)
data[col].fillna(data[col].median(), inplace=true)
"""
revenue (millions)
metascore
"""
print(np.all(pd.notnull(data))) # true -> 没有缺失值了

小结:
pd.isnull、pd.notnull判断是否存在缺失值【知道】np.any(pd.isnull(df)) # 里面如果有一个缺失值,就返回truenp.all(pd.notnull(df)) # 里面如果有一个缺失值,就返回false
df.dropna丢弃np.nan标记的缺失值【知道】fillna填充缺失值【知道】df[col].fillna(value=df[col].mean(), inplace=true)
df.replace替换具体某些值【知道】df.replace(to_replace='?', value=np.nan)
4.11 高级处理:数据离散化
学习目标:
- 应用
cut、qcut实现数据的区间分组 - 应用
get_dummies实现数据的one-hot编码
q1:为什么要离散化?
a1:连续属性离散化的目的是为了简化数据结构,数据离散化技术可以用来减少给定连续属性值的个数。离散化方法经常作为数据挖掘的工具。
q2:什么是数据的离散化
a2:连续属性的离散化就是在连续属性的值域上,将值域划分为若干个离散的区间,最后用不同的符号或整数值代表落在每个子区间中的属性值。
离散化有很多种方法,这使用一种最简单的方式:
- 原始人的身高数据:165,174,160,180,159,163,192,184
- 假设按照身高分几个区间段:150 ~ 165,165 ~ 180,180 ~ 195
这样我们将数据分到了三个区间段,我可以对应的标记为矮、中、高三个类别,最终要处理成一个**"哑变量"矩阵**。
q3:因为我们想要数据都是数字,但有些数字是字符串,可以使用哑变量来对字符串进行量化,是这个意思吗?
a3:是的,这样的理解是正确的。在数据分析和机器学习中,我们通常使用数字数据进行建模和预测。但是,有些特征(例如性别、颜色或者国籍)可能是字符串或文本形式的。为了将这些非数字特征转换为数字,我们可以使用哑变量编码技术(也称为独热编码),将每个类别变成一个单独的二进制特征。这种方法可以让我们在统计分析和机器学习算法中使用这些非数值特征,并且不会引入任何偏差。
案例:股票的涨跌幅离散化
我们对股票每日的 “p_change” 进行离散化。
一、读取股票的数据,筛选出 p_change 数据
import pandas as pd
import numpy as np
data = pd.read_csv(filepath_or_buffer="./data/stock_day.csv")
p_change = data["p_change"]
print(type(p_change)) # <class 'pandas.core.series.series'>
p_change
"""
2018-02-27 2.68
2018-02-26 3.02
2018-02-23 2.42
2018-02-22 1.64
2018-02-14 2.05
...
2015-03-06 8.51
2015-03-05 2.02
2015-03-04 1.57
2015-03-03 1.44
2015-03-02 2.62
name: p_change, length: 643, dtype: float64
"""
二、将股票涨跌幅数据进行分组
使用到的工具:
-
pd.qcut(data, q) -> categorical对象:- 作用:一种基于样本分位数的离散化函数,它根据指定的分位数将一个连续型变量转换为分类变量。
- 参数:
x:必须,要进行离散化的数据。q:可选,指定分位数的数量,可以是整数或列表。- 如
q=4等价于q=[0, 0.25, 0.5, 0.75, 1]。默认为 4。 - 一般会与
series.value_counts()搭配使用,统计每组的个数
- 如
labels:可选,定义离散化后每个区间的标签。retbins:可选,如果值为true,则会同时返回分组的边界。precision:可选,指定小数点精度,默认值为3。duplicates:可选,对于相同的分位数值是否去重,默认值为false。
- 返回值:返回值是一个 categorical 对象,它包含原始数据离散化后的结果,每个区间都对应一个标签,这些标签可以通过
cat属性来访问。如果指定了retbins=true,则会同时返回分组的边界。
-
series.value_counts():- 作用:用于统计 series 对象中每个不同元素出现的次数,返回一个新的 series 对象。
- 参数(没有必选参数):
normalize: bool 类型,表示是否返回相对频率而非绝对频率,默认为 false。- 如果设置为 true,则将每个元素出现的次数除以总数。
sort: bool 类型,表示是否按照元素出现的频率进行排序,默认为 true。ascending: bool 类型,表示是否按照升序排列,默认为 false。
- 返回值:该函数返回一个新的 series 对象,其中每个唯一元素都是原始 series 对象中的元素,并且每个唯一元素的值是它在原始 series 对象中出现的次数。
- 如果指定了
normalize=true,则每个唯一元素的值将除以原始 series 对象中的元素总数。
- 如果指定了
-
pd.cut(x, bins) -> series:- 作用:是 pandas 中的一种离散化工具,可以根据指定的区间将数据按照一定的规则分成若干个组。离散化是数据预处理过程中常用的操作之一,它可以用于将连续型数值转换为离散型变量,从而减少统计时所需的资源和时间。
- 参数(没有必选参数):
x:需要被切割的数组或者 series。bins:想要把x分成的组数或组距。labels: 对每个分组进行标记的列表或数组,长度必须与分组的数量相同。right:第一个箱子的右侧边界和最后一个箱子的左侧边界的显式设置。include_lowest:低端点是否包含在内,默认为false。- 如果设置为
true,则第一个箱子的左侧边界将包含在内。
- 如果设置为
precision:小数点精度。
- 返回值:返回一个
pandas.core.series.series类型的对象,其中每个元素都对应了原始数据x中的一个值,并且根据bins参数的设定被分配到了不同的区间。这个对象还会附带一个特殊属性categories,保存有所有的区间信息;另外,还有一个value_counts()方法,可以用来快速获取每个区间中有多少个元素。
示例1:pd.qcut(data, q) -> categorical对象
# 自行分组
qcut = pd.qcut(x=p_change, q=10) # 分为10组
print(qcut)
"""
2018-02-27 (1.738, 2.938]
2018-02-26 (2.938, 5.27]
2018-02-23 (1.738, 2.938]
2018-02-22 (0.94, 1.738]
2018-02-14 (1.738, 2.938]
...
2015-03-06 (5.27, 10.03]
2015-03-05 (1.738, 2.938]
2015-03-04 (0.94, 1.738]
2015-03-03 (0.94, 1.738]
2015-03-02 (1.738, 2.938]
name: p_change, length: 643, dtype: category
categories (10, interval[float64, right]): [(-10.030999999999999, -4.836] < (-4.836, -2.444] < (-2.444, -1.352] < (-1.352, -0.462] ... (0.94, 1.738] < (1.738, 2.938] < (2.938, 5.27] < (5.27, 10.03]
"""
# 计算分到每个组数据的个数
print("--------------------------------------")
res = qcut.value_counts()
print(type(print(res))) # <class 'nonetype'>
print(res)
"""
(-10.030999999999999, -4.836] 65
(-0.462, 0.26] 65
(0.26, 0.94] 65
(5.27, 10.03] 65
(-4.836, -2.444] 64
(-2.444, -1.352] 64
(-1.352, -0.462] 64
(1.738, 2.938] 64
(2.938, 5.27] 64
(0.94, 1.738] 63
name: p_change, dtype: int64
"""
示例2:pd.cut(x, bins) -> series
# 自定义区间分组
bins = [-100, -7, -5, -3, 0, 3, 5, 7, 100]
p_counts = pd.cut(x=p_change, bins=bins)
print(type(p_counts)) # <class 'pandas.core.series.series'>
print(p_counts)
"""
2018-02-27 (0, 3]
2018-02-26 (3, 5]
2018-02-23 (0, 3]
2018-02-22 (0, 3]
2018-02-14 (0, 3]
...
2015-03-06 (7, 100]
2015-03-05 (0, 3]
2015-03-04 (0, 3]
2015-03-03 (0, 3]
2015-03-02 (0, 3]
name: p_change, length: 643, dtype: category
categories (8, interval[int64, right]): [(-100, -7] < (-7, -5] < (-5, -3] < (-3, 0] < (0, 3] < (3, 5] < (5, 7] < (7, 100]]
"""
q:pd.qcut 和 pd.cut的区别?
a:pd.qcut 和 pd.cut 的主要区别在于分箱方式的不同。
pd.qcut是等频的分箱。pd.cut是等宽的分箱
pd.qcut 则可以根据指定的分位数将数据划分为各个区间,每个区间内包含相同数量的观测值。这种方法适用于数据分布不均匀的情况,因为它可以确保每个区间内的观测值数量相等。
例如,下面的代码将一个数组分成四个等频的区间:
data = [0.1, 0.4, 0.6, 0.8, 1.2]
bins = pd.qcut(data, q=4)
print(bins)
print("------------------------------")
print(bins.value_counts())
输出:
[(0.099, 0.4], (0.099, 0.4], (0.4, 0.6], (0.6, 0.8], (0.8, 1.2]]
categories (4, interval[float64, right]): [(0.099, 0.4] < (0.4, 0.6] < (0.6, 0.8] < (0.8, 1.2]]
------------------------------
(0.099, 0.4] 2
(0.4, 0.6] 1
(0.6, 0.8] 1
(0.8, 1.2] 1
dtype: int64
pd.cut 可以根据指定的分箱数量或分箱宽度将数据划分到各个区间。如果数据的分布不均匀,可能会导致某些区间内的观测值较少。
例如,下面的代码将一个数组分成四个等宽的区间:
import pandas as pd
data = [0.1, 0.4, 0.6, 0.8, 1.2]
bins = pd.cut(data, bins=4)
print(bins)
print("------------------------------")
print(bins.value_counts())
输出:
[(0.0989, 0.375], (0.375, 0.65], (0.375, 0.65], (0.65, 0.925], (0.925, 1.2]]
categories (4, interval[float64, right]): [(0.0989, 0.375] < (0.375, 0.65] < (0.65, 0.925] < (0.925, 1.2]]
------------------------------
(0.0989, 0.375] 1
(0.375, 0.65] 2
(0.65, 0.925] 1
(0.925, 1.2] 1
dtype: int64
因此,pd.qcut 和 pd.cut 的主要区别在于分箱方式的不同。即
pd.qcut是等宽的分箱pd.cut是等频的分箱
三、股票涨跌幅分组数据编程 one-hot 编码
one-hot 编码是一种在机器学习和计算机视觉中广泛使用的编码技术,用于将分类变量转换为可供机器学习算法处理的数字向量。
one-hot 编码的基本思想是为每个可能的分类值分配一个二进制位,并在该分类值的位置上设置为 1,而在其他未选定的位置上设置为 0。例如,假设我们有一个颜色特征,包括“红色”,“绿色”和“蓝色”,我们可以将它们转换成如下的向量:
- 红色:[1, 0, 0]
- 绿色:[0, 1, 0]
- 蓝色:[0, 0, 1]
这样,我们就可以将分类变量作为数字向量来处理,使其可以输入到机器学习算法中进行训练和预测。此外,由于每个分类值只有一个非零元素,因此 one-hot 编码还具有表示唯一性的优点,避免了不同分类值之间的混淆。
语法:pd.get_dummies(data, prefix=none) -> pandas dataframe 或 sparsedataframe 对象:
- 作用:用于将分类变量转换为指示变量/虚拟变量(dummy variables),以便于分析。
- 例如,如果你有一个名为“性别”的列,其中包含“男”和“女”两个值,则可以使用
pd.get_dummies()将其转换为两个虚拟变量(哑变量):一个表示“男”的布尔值列和另一个表示“女”的布尔值列。
- 例如,如果你有一个名为“性别”的列,其中包含“男”和“女”两个值,则可以使用
- 参数:
data: 必需,要进行独热编码的数据。prefix: 可选,添加前缀(字符串)到列名中。prefix_sep: 可选,添加到前缀(如果有)与原始列名之间的分隔符。默认为'_'columns: 可选,定义哪些列需要进行独热编码。如果不指定,则对所有对象或类别类型的列进行编码。sparse: 可选,默认为 false 。返回稠密数组或稀疏矩阵。drop_first: 可选,默认为 false。从每个类别变量中删除第一个类别,以避免共线性的问题。
- 返回值:返回值是一个 pandas dataframe 或 sparsedataframe 对象,其中每个类别变量都被转换成了一个或多个虚拟变量,并且列名已经被修改以反映虚拟变量的名称。如果指定了
drop_first参数,则删除第一个类别变量,并且每个类别变量都将被转换为 k − 1 k-1 k−1 个虚拟变量( k k k 是类别变量中的唯一值数)。
# 得出一个one-hot编码矩阵
dummies = pd.get_dummies(data=p_counts, prefix="rise")
dummies
小结:
- 数据离散化【知道】
- 可以用来减少给定连续属性值的个数
- 在连续属性的值域上,将值域划分为若干个离散的区间,最后用不同的符号或整数值代表落在每个子区间中的属性值
qcut.cut():实现数据分组【知道】pd.qcut():大致分为相同的几组pd.cut():自定义分组区间
df.get_dummies():实现哑变量矩阵【知道】
4.12 高级处理:合并
学习目标:
- 应用
pd.concat实现数据的合并 - 应用
pd.merge实现数据的合并
使用场景:如果你的数据由多张表组成,那么有时候需要将不同的内容合并在一起分析。
方法:
pd.concat([data1, data2], axis=1)pd.merge(left, right, how="inner", on=none)
一、pd.concat() 实现数据合并
pd.concat([data1, data2], axis=1) -> df/series
- 作用:用于合并(连接)数据框或系列对象的函数。它可以将多个数据框或系列沿着一条轴(默认是行轴
axis=0)进行拼接,生成一个新的数据框或系列。 - 参数:
objs: 要合并的数据框或系列对象列表,必选参数。axis: 合并的轴,默认为 0。- 当
axis=0或'index'时,表示沿着行索引进行连接,即将多个 dataframe 纵向堆叠。 - 当
axis=1或'columns'时,表示沿着列索引进行连接,即将多个 dataframe 横向拼接。
- 当
join: 指定合并的方式,有 inner 和 outer 两种方式,inner 表示内连接,outer 表示外连接,默认为 outer。ignore_index: 是否忽略原来的索引,如果设为 true,则合并后的数据框(系列)的索引会从 0 开始重新编号。keys: 为合并前的各个数据框(系列)添加标签,以区分来源,默认为 none。sort: 在合并后是否对数据进行排序,默认为 false。
- 返回值:返回一个合并后的新数据框或系列对象。
比如我们将刚才处理好的 one-hot 编码与原数据合并:
pd.concat(objs=[data, dummies], axis=1) # 按列合并
二、pd.merge()实现数据合并
pd.merge(left, right, how="inner", on=none) -> df
- 作用:用于合并两个或多个 dataframe 的函数。该函数基于类似 sql 中 join 操作的概念,将两个或多个 dataframe 中的行和列进行组合,生成一个新的 dataframe。
- 参数:
left:要合并的左侧 dataframe。right:要合并的右侧 dataframe。on:指定连接的列名,即根据哪些列进行合并。如果省略此参数,则使用两个 dataframe 中公共的列。how:指定连接类型,包括 inner(内连接)、outer(外连接)、left(左连接)和 right(右连接)。默认为 inner。suffixes:指定两个 dataframe 中具有相同列名的列的后缀字符串。默认值为(“_x”, “_y”)。
- 返回值:返回一个新的 dataframe,其中包含两个或多个 dataframe 中的所有行和列。返回的 dataframe 将根据指定的连接键进行合并,这些键可以是一个或多个列。返回的 dataframe 包含每个输入 dataframe 中的所有列,也可以根据需要重命名重复的列名。
| 合并方式 | sql join name | 说明 |
|---|---|---|
left | left outer join | 仅使用左侧 dataframe 的键,类似于 sql 左外连接;保留键顺序 |
right | right outer join | 仅使用右侧 dataframe 的键,类似于 sql 右外连接;保留键顺序 |
outer | full outer join | 使用两个 dataframe 的键的并集,类似于 sql 完外连接;按字典顺序对键进行排序 |
inner | inner outer join | 使用两个 dataframe 的键的交集,类似于 sql 内连接;保留左侧键的顺序 |
left = pd.dataframe({"key1": ["k0", "k0", "k1", "k2"],
"key2": ["k0", "k1", "k0", "k1"],
'a': ["a0", "a1", "a2", "a3"],
'b': ["b0", "b1", "b2", "b3"]})
right = pd.dataframe({"key1": ["k0", "k1", "k1", "k2"],
"key2": ["k0", "k0", "k0", "k0"],
'c': ["c0", "c1", "c2", "c3"],
'd': ["d0", "d1", "d2", "d3"]})
print(left)
"""
key1 key2 a b
0 k0 k0 a0 b0
1 k0 k1 a1 b1
2 k1 k0 a2 b2
3 k2 k1 a3 b3
"""
print(right)
"""
key1 key2 c d
0 k0 k0 c0 d0
1 k1 k0 c1 d1
2 k1 k0 c2 d2
3 k2 k0 c3 d3
"""
- 内连接(默认)
如果 key1 和 key2 都相同,就进行拼接,不相同的不进行拼接(重复的也要拼接)
# 内连接(默认)
result = pd.merge(left, right, on=["key1", "key2"])
print(result)
"""
key1 key2 a b c d
0 k0 k0 a0 b0 c0 d0
1 k1 k0 a2 b2 c1 d1
2 k1 k0 a2 b2 c2 d2
"""

- 左连接
以左表为主,右表没有的则设置为空值 nan(重复的也要拼接)
# 左连接
result = pd.merge(left, right, on=["key1", "key2"], how="left")
print(result)
"""
key1 key2 a b c d
0 k0 k0 a0 b0 c0 d0
1 k0 k1 a1 b1 nan nan
2 k1 k0 a2 b2 c1 d1
3 k1 k0 a2 b2 c2 d2
4 k2 k1 a3 b3 nan nan
"""
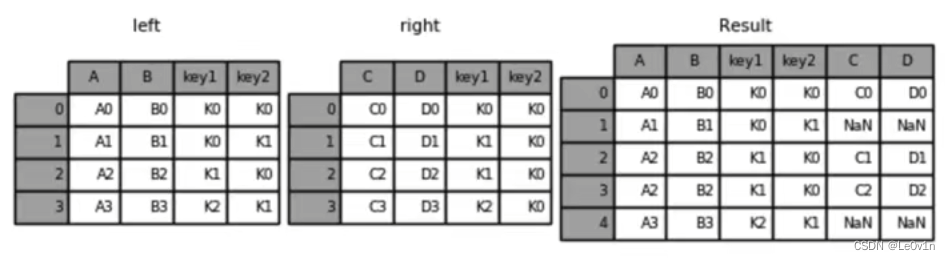
- 右连接
以右表为主,左表没有的则设置为空值 nan(重复的也要拼接)
# 右连接
result = pd.merge(left, right, on=["key1", "key2"], how="right")
print(result)
"""
key1 key2 a b c d
0 k0 k0 a0 b0 c0 d0
1 k1 k0 a2 b2 c1 d1
2 k1 k0 a2 b2 c2 d2
3 k2 k0 nan nan c3 d3
"""
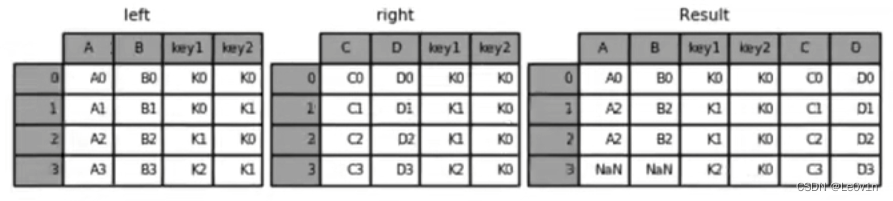
- 外连接
所有数据都合并起来,没有的设置为 nan(与内连接不同,内连接没有的就不合并了)
# 外连接
result = pd.merge(left, right, on=["key1", "key2"], how="outer")
print(result)
"""
key1 key2 a b c d
0 k0 k0 a0 b0 c0 d0
1 k0 k1 a1 b1 nan nan
2 k1 k0 a2 b2 c1 d1
3 k1 k0 a2 b2 c2 d2
4 k2 k1 a3 b3 nan nan
5 k2 k0 nan nan c3 d3
"""
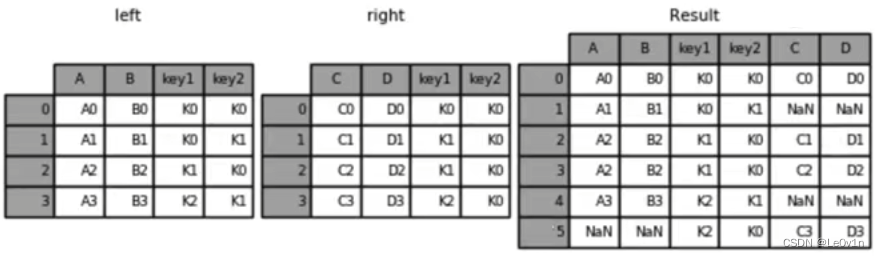
三、pd.concat() 和 pd.merge() 的联系
pd.concat 和 pd.merge 都是 pandas 库中用于合并数据的函数,二者的相同点和不同点如下:
- 相同点:
- 用途:
pd.concat和pd.merge都用于将多个数据集合并成一个。 - 参数:两个函数都有类似的参数,包括要合并的数据集、合并方式、删除重复值等。
- 用途:
- 不同点:
- 合并方式:
pd.concat默认以行方向(纵向)拼接数据,可以通过axis参数修改为以列方向(横向)拼接;而pd.merge默认以列方向(横向)拼接数据,可以通过how参数修改为其他合并方式(如内连接、左连接、右连接、外连接)。 - 数据来源:
pd.concat主要用于将多个来自相同表结构的数据源合并,而pd.merge则主要用于将来自不同数据源的数据按照特定条件进行合并。 - 数据重叠:当待合并的数据集中存在相同的列名时,
pd.concat会直接将这些列合并到一起,而pd.merge则需要指定要合并的列名或者索引,并根据这些列或索引进行合并。
- 合并方式:
小结:
pd.concat([数据1, 数据2], axis=0)【知道】pd.merge(left, right, how="inner", on=)【知道】how:以何种方式连接on:连接的键的依据是哪几个
4.13 高级处理:交叉表与透视表
学习目标:
- 应用 crosstab 和 pivot_table 实现交叉表与透视表
q:交叉表与透视表什么作用?
a:在 pandas 中,交叉表(crosstab)和透视表(pivot table)都是用来对数据进行汇总和分组的工具。
- 交叉表是一种用于计算两个或更多因素的简单交叉表。默认情况下,它会计算因素的频率表,除非传递了值数组和聚合函数。它不一定需要一个 dataframe 作为输入,也可以接受类似数组的对象作为行和列。
- 透视表则是一种类似于电子表格的透视表,它允许对数据进行多维汇总。它需要一个 dataframe 作为输入,并且可以通过传递列名作为字符串来指定索引/列/值。
- 总之,交叉表和透视表都可以用来对数据进行汇总和分组,但它们在输入数据类型和使用方式上略有不同。可以根据实际情况选择使用哪种工具。
举例:探究股票的涨跌与星期几有关?
以下图当中表示,week 代表星期几,1, 0 代表这一天股票的涨跌幅是好还是坏,里面的数据代表比例可以理解为涨跌幅好坏的比例。

这样查看数据可能不够直观,可以画个图展示。
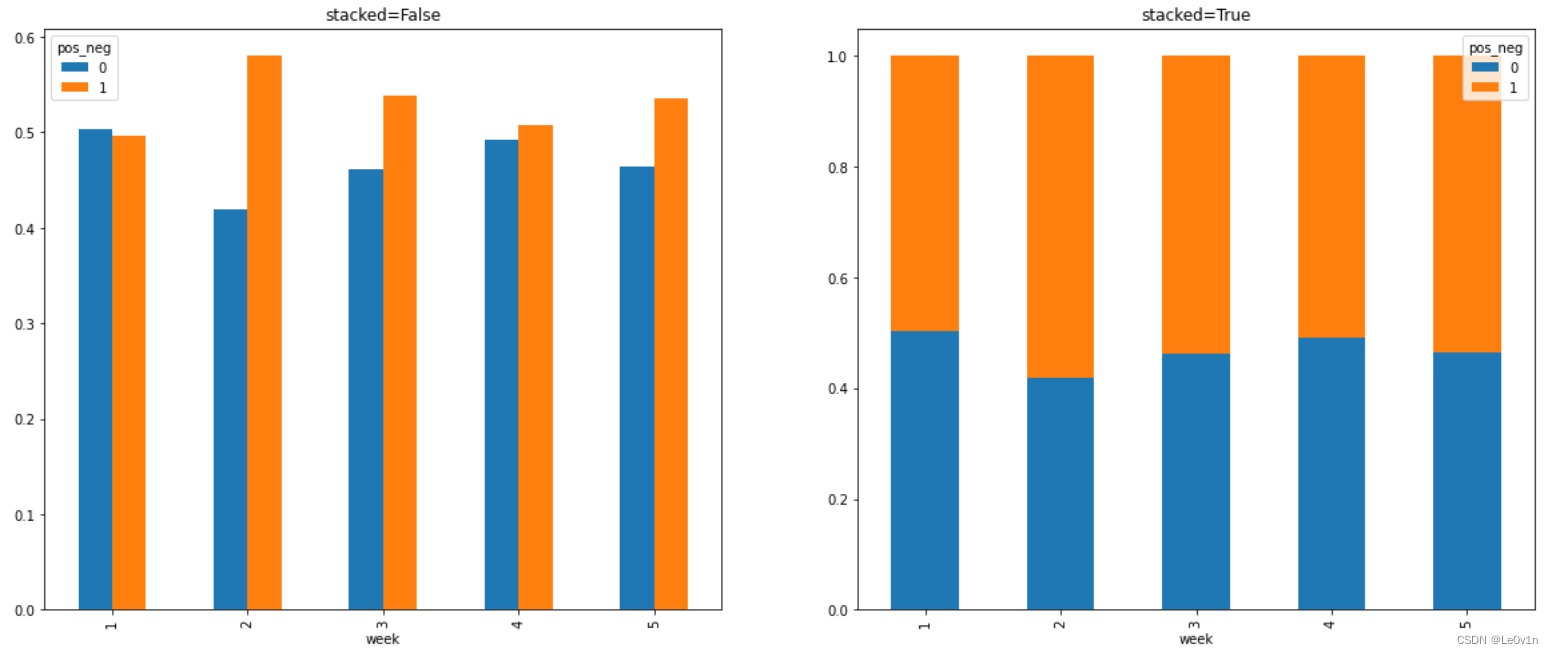
pd.crosstab(value1, value2)df.pivot_table([], index=[])
一、pd.crosstab(value1, value2) -> df
- 作用:用于计算两个或多个因素的简单交叉表的函数。默认情况下,它会计算因素的频率表,除非传递了值数组和聚合函数。
- 参数:
index:用于分组行的值,可以是类似数组的对象、series 或多个数组/series 的列表。columns:用于分组列的值,可以是类似数组的对象、series 或多个数组/series 的列表。values:可选,要根据因素进行聚合的值数组。需要指定aggfunc。rownames:可选,行名称序列。colnames:可选,列名称序列。aggfunc:可选,聚合函数。如果指定,则需要指定values。margins:布尔值,默认为 false。是否添加行/列边距(小计)。margins_name:字符串,默认为 ‘all’。当margins=true时,包含总计的行/列的名称。dropna:布尔值,默认为 true。不包括所有条目都为 nan 的列。normalize:布尔值,默认为 false。通过将所有值除以值之和来进行归一化。
- 返回值:返回一个 dataframe,表示数据的交叉表。
例子:假设我们有一个 dataframe,其中包含有关人口普查数据的信息:
import pandas as pd
data = {'gender': ['male', 'male', 'female', 'female', 'male'],
'age': ['young', 'young', 'old', 'young', 'old'],
'income': [10, 20, 30, 40, 50]}
df = pd.dataframe(data)
print(df)
"""
gender age income
0 male young 10
1 male young 20
2 female old 30
3 female young 40
4 male old 50
"""
我们可以使用 pd.crosstab() 函数来计算性别和年龄分组的收入平均值:
result = pd.crosstab(index=df['gender'], columns=df['age'], values=df['income'], aggfunc='mean')
print(result)
输出结果为:
age old young
gender
female 30.0 40.0
male 50.0 15.0
这表示男性中年龄为 “old” 的人的平均收入为 50,年龄为 “young” 的人的平均收入为 15;女性中年龄为 “old” 的人的平均收入为 30,年龄为 “young” 的人的平均收入为 40。
二、df.pivot_table([], index=[]) -> df
- 作用:创建数据透视表,即原有的 dataframe 的列分别作为行索引和列索引,然后对指定的列应用聚集函数。
- 参数:
index参数用于指定透视表的行索引。每个pivot_table必须拥有一个index。values参数用于指定需要聚合的数据列。columns参数用于指定透视表的列层次字段,它不是一个必要参数,作为一种分割数据的可选方式。aggfunc参数用于指定对数据聚合时进行的函数操作。如果未设置aggfunc,则默认计算均值(aggfunc='mean')。
- 返回值:返回一个新的 dataframe,其中包含根据指定参数创建的数据透视表。
下面是一个简单的例子,演示如何使用 df.pivot_table() 函数创建数据透视表:
import pandas as pd
# 创建一个 dataframe
df = pd.dataframe({
"a": ["foo", "foo", "foo", "foo", "foo", "bar", "bar", "bar", "bar"],
"b": ["one", "one", "one", "two", "two", "one", "one", "two", "two"],
"c": ["small", "large", "large", "small", "small", "large", "small", "small", "large"],
"d": [1, 2, 2, 3, 3, 4, 5, 6, 7],
"e": [2, 4, 5, 5, 6, 6, 8, 9, 9]
})
print(df)
"""
a b c d e
0 foo one small 1 2
1 foo one large 2 4
2 foo one large 2 5
3 foo two small 3 5
4 foo two small 3 6
5 bar one large 4 6
6 bar one small 5 8
7 bar two small 6 9
8 bar two large 7 9
"""
# 创建数据透视表
table = pd.pivot_table(df, values='d', index=['a', 'b'], columns=['c'], aggfunc=np.sum)
# 显示数据透视表
print(table)
上面的代码创建了一个简单的 dataframe,然后使用 df.pivot_table() 函数创建了一个数据透视表。在这个例子中,我们指定了 values='d' 来表示我们想要对 'd' 列进行聚合。我们还指定了 index=['a', 'b'] 来表示我们想要根据 'a' 和 'b' 列来分组数据。最后,我们指定了 columns=['c'] 来表示我们想要根据 'c' 列来创建透视表的列。
运行上面的代码会输出以下结果:
c large small
a b
bar one nan 5.0
two 7.0 6.0
foo one 4.0 1.0
two nan 6.0
这就是一个简单的例子,演示了如何使用 df.pivot_table() 函数创建数据透视表。可以根据自己的需求调整参数来创建不同的数据透视表。
三、案例分析
- 准备两列数据,星期数据以及涨跌幅是好是坏数据
- 进行交叉表计算
# 寻找星期几跟股票涨跌的关系
# 1. 先根据对应的日期获取当天是星期几
date = pd.to_datetime(data.index).weekday + 1 # 不从0开始,而是从1开始
# 创建"week"列
data["week"] = date
# 2. 把p_change按照分类,其中以0为界限
data["pos_neg"] = np.where(data["p_change"] > 0, 1, 0)
# 通过交叉表找寻两列数据的关系
count = pd.crosstab(index=data["week"], columns=data["pos_neg"])
print(count)
"""
pos_neg 0 1
week
1 63 62
2 55 76
3 61 71
4 63 65
5 59 68
"""
q:但是我们看到 count 只是每个星期日子的好坏天数,并没有得到比例,该怎么去做?
a:对每个星期几的总天数求和,运用除法运算求出比例。
# 算术运算,先求和
sum = count.sum(axis=1).astype(np.float32)
print(sum)
"""
week
1 125.0
2 131.0
3 132.0
4 128.0
5 127.0
dtype: float32
"""
# 进行相除操作,得出比例
res = count.div(sum, axis=0)
print(res)
"""
pos_neg 0 1
week
1 0.504000 0.496000
2 0.419847 0.580153
3 0.462121 0.537879
4 0.492188 0.507812
5 0.464567 0.535433
"""
为了直观的体现交叉表,画柱状图:
import matplotlib.pyplot as plt
fig, axes = plt.subplots(1, 2, figsize=(20, 8))
res.plot(kind="bar", ax=axes[0], title="stacked=false")
res.plot(kind="bar", ax=axes[1], stacked=true, title="stacked=true")
使用透视表,刚才的过程更加简单。
# 通过透视表,将整个过程变得更简单一些
res = data.pivot_table(["pos_neg"], index="week")
print(res)
"""
pos_neg
week
1 0.496000
2 0.580153
3 0.537879
4 0.507812
5 0.535433
"""
res.plot(kind="bar", title="stacked=false")
plt.show()
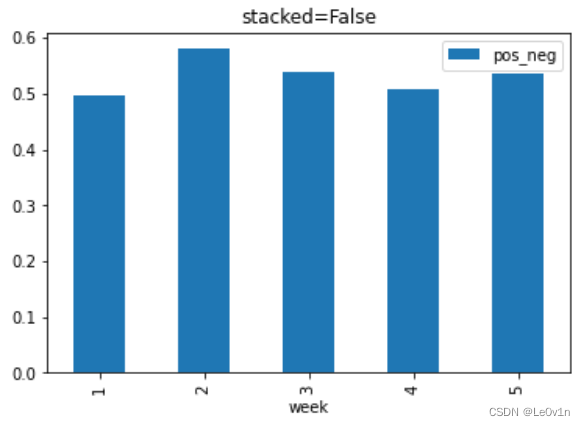
小结:
- 交叉表与透视表的作用【知道】
- 交叉表:计算一列数据对于另外一列数据的分组个数。
- 透视表:指定某一列对另一列的关系。
4.14 高级处理:分组与聚合
学习目标:
- 应用groupby和聚合函数实现数据的分组与聚合。
分组与聚合通常是分析数据的一种方式,通常与一些统计函数一起使用,查看数据的分组情况。
在 pandas 中,分组(grouping)和聚合(aggregating)是数据处理中非常重要的工具。它们可以帮助我们对数据进行分类汇总,提取有用信息,并生成新的数据集。
分组的作用:
在实际数据处理过程中,我们通常需要根据某些特征把数据进行分组以便后续的操作。例如,在一个销售数据表中,我们可能希望按照不同的产品类型或销售时间来分组数据。这样就可以更好地理解和分析数据,找出其中的规律和趋势。
聚合的作用:
在分组之后,我们通常会对每个分组进行统计计算,例如求和、平均值、最大值等等,这就是聚合的作用。pandas 提供了多种内置的聚合函数,例如 sum()、mean()、max() 等等,可以方便地对每个分组进行计算,并生成新的数据集。
应用场景:
【简单理解】分组和聚合是数据处理中非常常见的操作,通常应用于以下场景:
- 对大型数据集进行分类汇总,并提取有用信息。
- 对数据集进行统计计算,并生成新的数据集。
- 简化数据集,方便后续的分析和可视化。
【总结】pandas 中,分组与聚合的应用场景包括:
- 按类别对数据进行统计:比如对于一个电商网站的销售数据,可以按照商品种类进行分组,然后对每个类别的销售总额、平均价、最大价等进行聚合。
- 数据透视表:类似 excel 中的数据透视表,通过指定行和列索引以及聚合函数,将数据进行多维度的汇总和统计。
- 时间序列分析:对于时间序列数据,可以按照年、月、日等时间维度进行分组,然后对每个时间段内的数据进行聚合,得到相应的统计结果。
- 数据清洗:在数据清洗过程中,有时需要按照某些规则对数据进行分组,并对每个分组中的数据进行处理和操作。
- 数据可视化:在数据可视化中,通过对数据进行分组和聚合,可以得到更加直观的图表展示效果。
分组与聚合是 pandas 中非常重要的功能,它们可以帮助我们对大量数据进行快速高效的统计和分析,并得到有意义的
q:什么是分组与聚合?
a:看下面这张图片。
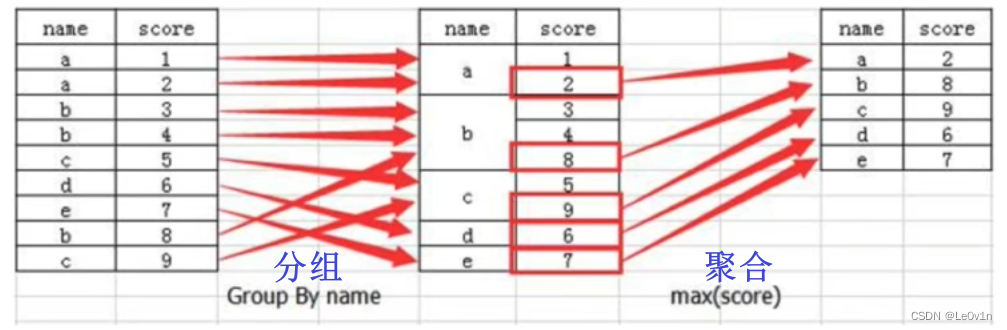
一、分组 api
df.groupby(by, as_index=true) -> dataframegroupby/seriesgroupby
- 作用:用于根据指定的列或索引对数据进行分组。该方法可以将数据按照某些标准分为若干组,并对每一组进行统计分析。
- 参数:
by:用于指定分组所依据的列或索引。可以传入单个列名、多个列名组成的列表或元组、series对象、dataframe对象、函数或函数列表等。axis:用于指定分组依据的轴方向。默认为0表示按列进行分组,1表示按行进行分组。level:用于指定分组所依据的索引层级。当分组依据为多层索引时使用。sort:用于指定是否对结果进行排序,默认为true。group_keys:用于指定是否要在结果中显示分组键,默认为true。as_index:用于指定是否将分组键设置为结果的索引,默认为true。squeeze:用于指定是否对结果进行压缩,默认为false。
- 返回值:返回值为一个
dataframegroupby或者seriesgroupby对象。这个对象可以进行很多操作,如聚合(aggregation)、过滤(filtering)和转换(transformation)等。也可以通过groups属性查看分组情况。
二、聚合api
pandas 提供了许多聚合函数用于数据处理和分析。以下是常见的一些聚合函数:
sum():计算数据的总和。mean():计算数据的平均值。median():计算数据的中位数。min():找出数据的最小值。max():找出数据的最大值。count():计算数据的数量。std():计算数据的标准差。var():计算数据的方差。describe():统计数据的基本信息,如平均数、标准差、最小值、最大值等。
以上只是部分常用的聚合函数,pandas 还提供了一个综合的聚合函数agg。它可以对单列或多列进行单一或多个不同的聚合函数处理,常用函数如 min、max、median、std、count、size、sum 等,直接用函数名加引号即可,如果有多个函数,用逗号隔开:
df.agg(func=none, axis=0, *args, **kwargs)- 作用:用于对数据进行聚合操作
- 参数:
func:用于聚合数据的函数,函数必须在dataframe和apply函数中均可用;输入可以是函数名称、函数名称的字符串、函数组成的列表、或轴标签字典。axis:取值为 0 或 ’index’(函数作用于每列),1 或 ’columns’(函数作用于每行),默认为 0。*args:传递函数的位置参数。**kwargs:传递关键字的位置参数。
- 返回值:返回值可以是
scalar(当在series.agg()中使用单个函数时),series(当在dataframe.agg()中使用单个函数时)或dataframe(当在dataframe.agg()中使用多个函数时)。
例如,我们可以使用以下代码对数据进行聚合:
df.agg({'列名1': 'sum', '列名2': 'mean'})
上面的代码将对列名1列求和,对列名2列求平均值。
三、案例:不同颜色的不同笔的价格数据。
col = pd.dataframe({
"color": ["white", "red", "green", "red", "green"],
"oibject": ["pen", "pencil", "pencil", "ashtray", "pen"],
"price1": [5.56, 4.20, 1.30, 0.56, 2.75],
"price2": [4.75, 4.12, 1.60, 0.75, 3.15]})
print(col)
"""
color oibject price1 price2
0 white pen 5.56 4.75
1 red pencil 4.20 4.12
2 green pencil 1.30 1.60
3 red ashtray 0.56 0.75
4 green pen 2.75 3.15
"""
进行分组:对颜色分组,对 “price1” 进行聚合:
# 分组、求平均值
# dataframe的分组
res1 = col.groupby(by=["color"])
print(type(res1)) # <class 'pandas.core.groupby.generic.dataframegroupby'>
print(res1) # <pandas.core.groupby.generic.dataframegroupby object at 0x000002b12bd689a0>
res1 = res1["price1"].mean()
print(res1)
"""
color
green 2.025
red 2.380
white 5.560
name: price1, dtype: float64
"""
# series的分组
res2 = col["price1"]
print(type(res2)) # <class 'pandas.core.series.series'>
print(res2)
"""
0 5.56
1 4.20
2 1.30
3 0.56
4 2.75
name: price1, dtype: float64
"""
res2 = res2.groupby(by=col["color"]).mean()
print(res2)
"""
color
green 2.025
red 2.380
white 5.560
name: price1, dtype: float64
"""
# 分组,数据的结构不变
res3 = col.groupby(by=["color"], as_index=false)["price1"].mean()
print(res3)
"""
color price1
0 green 2.025
1 red 2.380
2 white 5.560
"""
四、案例:星巴克零售店铺数据
现在我们有一组关于全球星巴克店铺的统计数据,如果我想知道美国的星巴克数量和中国的哪个多,或者我想知道中国每个省份星巴克的数量的情况,那么应该怎么办?
数据集下载地址:starbucks locations worldwide
step1:读取数据
# step1:读取数据
starbucks = pd.read_csv("./data/starbucks_directory.csv")
step2:进行分组聚合
# step2:进行分组聚合
# 按照国家分组,求出每个国家的零售店数量
count = starbucks.groupby(by="country").count()

step3:画图显示结果
# step3:画图显示结果
count["brand"].plot(kind="bar", figsize=(20, 8))
plt.show()
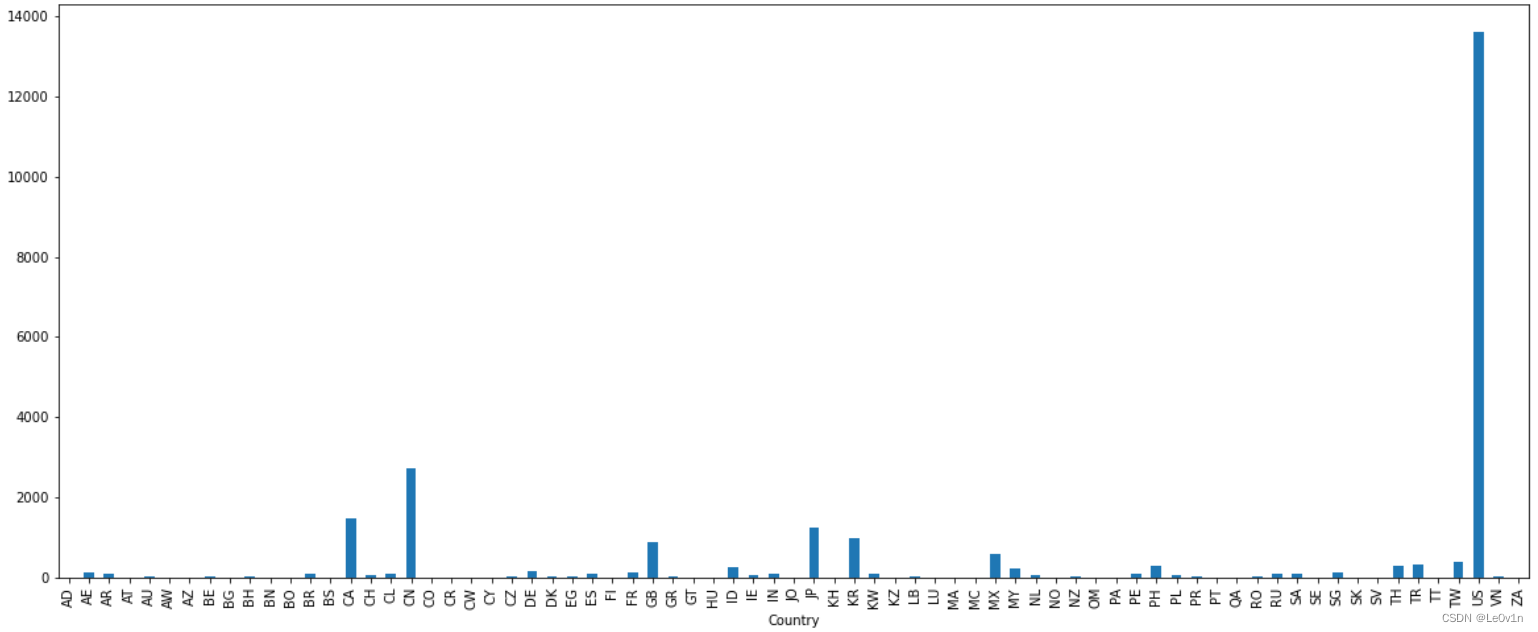
假设我们加入省市一起进行分组:
# 设置多个索引
counts = starbucks.groupby(["country", "state/province"]).count()
counts.head()
q:仔细观察这个结构,与我们前面讲的哪个结构类似?
a:与前面的 multiindex 结构类似
画图:
counts["brand"].plot(kind="bar", figsize=(20, 8))
plt.show()
问题:
如果在分组聚合后得到了一个具有两个索引(即两个横坐标)的 dataframe,那么直接绘图可能会导致图形混乱。
解决方案:在这种情况下,可以考虑使用 reset_index 函数将其中一个索引重置为普通列,然后再进行绘图。
例如,如果你想要绘制一个柱状图来展示每个国家/地区的星巴克门店数量,可以使用以下代码:
print(counts.index) # ['country', 'state/province']
print(type(counts)) # <class 'pandas.core.frame.dataframe'>
# 重置索引(将其变为普通的列)
country_counts = counts.reset_index(level=1) # 让'state/province'从索引变为普通列
print(type(country_counts)) # <class 'pandas.core.frame.dataframe'>
print(country_counts.index)
"""
index(['ad', 'ae', 'ae', 'ae', 'ae', 'ae', 'ae', 'ae', 'ar', 'ar',
...
'us', 'us', 'us', 'us', 'us', 'us', 'us', 'vn', 'vn', 'za'],
dtype='object', name='country', length=545)
"""
"""
注意:在执行`country_counts = counts.reset_index(level=1)`这行代码后,
`country_counts`变量中存储的不再是一个分组聚合后的dataframe,而是一个普通的dataframe。
因此我们不能直接plot,因为横坐标已经不再是分组聚合后的了,我们需要重新分组聚合
"""
# 重新分组聚合:计算每个国家/地区的星巴克门店数量
country_counts = country_counts.groupby("country").count()
# 绘制柱状图
country_counts["brand"].plot(kind="bar")
# 显示图形
plt.show()
上面的代码首先使用 reset_index 函数将第二个索引(即 state/province 列)重置为普通列。然后,计算了每个国家/地区的星巴克门店数量,并使用 plot 函数绘制了一个柱状图。最后,使用 plt.show() 函数显示了图形。
注意:在执行 country_counts = counts.reset_index(level=1) 这行代码后,
country_counts 变量中存储的不再是一个分组聚合后的dataframe,而是一个普通的dataframe。
因此我们不能直接 plot,因为横坐标已经不再是分组聚合后的了,我们需要重新分组聚合!
# 重置索引
country_counts = counts.reset_index() # 重置索引
# 重新分组聚合:计算每个国家/地区的星巴克门店数量
country_counts = country_counts.groupby("state/province").count()
# 绘制柱状图
country_counts["brand"].plot(kind="bar", figsize=(20, 8))
# 隐藏横坐标标签(省份太多了,显示的就会很乱)
plt.xticks([])
# 显示图形
plt.show()
小结:
groupby进行数据的分组【知道】- pandas 中,抛开聚合谈分组,无意义
4.15 案例:综合应用
4.15.1 需求
现在我们有一组从 2006 年到 2016 年 1000 部最流行的电影数据。
- 问题1:我们想知道这些电影数据中评分的平均分,导演的人数等信息,我们应该怎么获取?
- 问题2:对于这一组电影数据,如果我们想 rating,runtime 的分布情况,应该如何呈现数据?
- 问题3:对于这一组电影数据,如果我们希望统计电影分类(genre)的情况,应该如何处理数据?
数据集下载地址:imdb data from 2006 to 2016
4.15.2 实现
一、获取数据
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# 读取文件
path = "./data/imdb-movie-data.csv"
df = pd.read_csv(path)
df.head()

二、问题1:我们想知道这些电影数据中评分的平均分,导演的人数信息,我们应该怎么获取?
- 得出评分的平均分:使用mean函数
res = df["rating"].mean()
print(res) # 6.723199999999999
- 得出导演人数信息:求出唯一值,然后进行形状获取
# 导演人数
# 方法1
res = df["director"].unique()
print(type(res)) # <class 'numpy.ndarray'>
counts = res.shape[0]
print(counts) # 644
# 方法2
res = np.unique(df["director"])
print(type(res)) # <class 'numpy.ndarray'>
counts = res.shape[0]
print(counts) # 644
三、问题2:对于这一组电影数据,如果我们想知道 rating,runtime (minutes) 的分布情况,应该如何呈现数据?
分布情况应该考虑直方图。
from pylab import mpl
# 设置中文字体
mpl.rcparams["font.sans-serif"] = ["simhei"]
# 设置正常显示符号
mpl.rcparams["axes.unicode_minus"] = false
df["rating"].plot(kind="hist", figsize=(20, 8))
plt.show()
上面这幅图像是有问题的, x = 5 x=5 x=5 应该是对应的 bin 的边,现在偏右了。
下面是合格的直方图要求:
-
合适的间隔: 直方图中的间隔(bin)应该足够小,以便能够捕捉到数据中的所有变化,并且足够大,以便在不失真地呈现数据的情况下,使直方图易于理解。如果间隔太小,则直方图将变得嘈杂混乱,难以解读;如果间隔太大,则可能会掩盖数据的细节。
-
相应的轴: 直方图必须具有明确的轴标签,包括 x 轴和 y 轴,以便用户可以轻松地了解其内容。轴标题应该准确地描述数据的含义,并使用适当的度量单位。
-
可视化效果: 直方图的外观应该整洁美观,颜色、字体和线条等元素应该恰如其分,以便最大程度上展示数据的特征。
-
合适的统计分析: 直方图不能仅仅是数据的可视化表示,还需要结合统计分析方法,如均值、中位数、标准差等,以便客户能够更好地理解数据并做出正确的决策。
综上所述,我们需要更加复杂的操作,所以我们不直接 plot(),而是借助 matplotlib 画图。
# 借助matplotlib画图
# 设置画布大小
plt.figure(figsize=(15, 8))
# 绘制直方图
plt.hist(x=df["rating"], bins=25, alpha=0.7, color='green')
# 修改刻度间隔
max_ = df["rating"].max() + 0.5
min_ = df["rating"].min() - 0.5
t1 = np.arange(min_, max_, 0.5)
plt.xticks(t1, fontsize=14)
# 添加标签和标题
plt.xlabel("电影评分rating", fontsize=14)
plt.ylabel("对应评分出现次数", fontsize=14)
plt.title("电影评分rating直方图", fontsize=16)
# 添加网格
plt.grid(visible=true, alpha=0.5)
# 显示图像
plt.show()
runtime (minutes) 的分布情况也是同理:
# runtime (minutes)的分布情况
plt.figure(figsize=(15, 8))
bins_num = 25
plt.hist(x=df["runtime (minutes)"].values, bins=bins_num, alpha=0.7)
max_ = df["runtime (minutes)"].max()
min_ = df["runtime (minutes)"].min()
# 修改刻度间隔
step = np.linspace(start=min_, stop=max_, num=bins_num+1)
plt.xticks(step, fontsize=14)
# 修改其他
plt.xlabel("播放时长(分钟)", fontsize=14)
plt.ylabel("对应出现次数", fontsize=14)
plt.title("电影播放时长直方图", fontsize=18)
plt.grid(visible=true, alpha=0.5)
# 显示图像
plt.show()
四、问题3:对于这一组电影数据,如果我们希望统计电影分类(genre)的情况,应该如何处理数据?
从图中可以看到,genre 不像 director,只有一个字符串。genre 中有多个字符串,所以解决起来比较麻烦,我们需要对字符串进行拆分。
思路分析:
- 创建一个全为 0 的 dataframe,列索引置为电影的分类:
temp_df - 遍历每一部电影,
temp_df中把分类出现的列的值置为 1 - 求和、绘图
具体实现:
- 创建一个全为 0 的 dataframe,列索引置为电影的分类:
temp_df
# 1. 创建一个全为0的dataframe,列索引置为电影的分类:`temp_df`
# 进行字符串分割
tmp_lst = [values.split(',') for values in df["genre"]]
# print(tmp_lst)
"""
[['action', 'adventure', 'sci-fi'],
['adventure', 'mystery', 'sci-fi'],
['horror', 'thriller'],
['animation', 'comedy', 'family'],
['action', 'adventure', 'fantasy'],
['action', 'adventure', 'fantasy'],
['comedy', 'drama', 'music'],
...
]
"""
# 获取电影的分类
genre_lst = []
for lst in tmp_lst:
for val in lst:
genre_lst.append(val)
genre_lst = np.unique(genre_lst)
# 也可以直接使用列表推导式来进行
# genre_lst = np.unique([i for j in tmp_lst for i in j])
print(genre_lst)
"""
['action' 'adventure' 'animation' 'biography' 'comedy' 'crime' 'drama'
'family' 'fantasy' 'history' 'horror' 'music' 'musical' 'mystery'
'romance' 'sci-fi' 'sport' 'thriller' 'war' 'western']
"""
# 增加新的列
tmp_df = pd.dataframe(data=np.zeros(shape=[df.shape[0], genre_lst.shape[0]]), columns=genre_lst)
print(tmp_df.head())
"""
action adventure animation biography comedy crime ... romance sci-fi sport thriller war western
0 0.0 0.0 0.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0 0.0 0.0
1 0.0 0.0 0.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0 0.0 0.0
2 0.0 0.0 0.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0 0.0 0.0
3 0.0 0.0 0.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0 0.0 0.0
4 0.0 0.0 0.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0 0.0 0.0
[5 rows x 20 columns]
"""
- 遍历每一部电影,
temp_df中把分类出现的列的值置为1
# 2. 遍历每一部电影,`temp_df`中把分类出现的列的值置为1
for i in range(df.shape[0]):
tmp_df.iloc[i].loc[tmp_lst[i]] = 1
"""
tmp_df.iloc[i]:选取第i行
tmp_df.iloc[i].loc[tmp_lst[i]]:选取第i行的tmp_lst[i]列(可以是lst,多次选列)
tmp_df.iloc[i].loc[tmp_lst[i]] = 1:赋值为1
"""
print(tmp_df.head())
"""
action adventure animation biography comedy crime ... romance sci-fi sport thriller war western
0 1.0 1.0 0.0 0.0 0.0 0.0 ... 0.0 1.0 0.0 0.0 0.0 0.0
1 0.0 1.0 0.0 0.0 0.0 0.0 ... 0.0 1.0 0.0 0.0 0.0 0.0
2 0.0 0.0 0.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 1.0 0.0 0.0
3 0.0 0.0 1.0 0.0 1.0 0.0 ... 0.0 0.0 0.0 0.0 0.0 0.0
4 1.0 1.0 0.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0 0.0 0.0
[5 rows x 20 columns]
"""
print(tmp_df.sum())
"""
action 303.0
adventure 259.0
animation 49.0
biography 81.0
comedy 279.0
crime 150.0
drama 513.0
family 51.0
fantasy 101.0
history 29.0
horror 119.0
music 16.0
musical 5.0
mystery 106.0
romance 141.0
sci-fi 120.0
sport 18.0
thriller 195.0
war 13.0
western 7.0
dtype: float64
"""
print(tmp_df.sum().sort_values()) # 排序显示
"""
musical 5.0
western 7.0
war 13.0
music 16.0
sport 18.0
history 29.0
animation 49.0
family 51.0
biography 81.0
fantasy 101.0
mystery 106.0
horror 119.0
sci-fi 120.0
romance 141.0
crime 150.0
thriller 195.0
adventure 259.0
comedy 279.0
action 303.0
drama 513.0
dtype: float64
"""
- 求和、绘图
# 3. 求和、绘图
# 3.1 求和
res = tmp_df.sum().sort_values(ascending=false) # 降序排序
print(type(res)) # <class 'pandas.core.series.series'>
print(res)
"""
drama 513.0
action 303.0
comedy 279.0
adventure 259.0
thriller 195.0
crime 150.0
romance 141.0
sci-fi 120.0
horror 119.0
mystery 106.0
fantasy 101.0
biography 81.0
family 51.0
animation 49.0
history 29.0
sport 18.0
music 16.0
war 13.0
western 7.0
musical 5.0
dtype: float64
"""
# 3.2 画图
res.plot(kind="bar", figsize=(20, 8), fontsize=14)
plt.xlabel("电影分类", fontsize=14)
plt.ylabel("分类出现的次数", fontsize=14)
plt.title("电影分类柱状图", fontsize=18)
plt.show()

因为有好几列的数据,因此不适合画直方图,用柱状图就可以很好的展示数据了。
赞 (0)
打赏
 微信扫一扫
微信扫一扫
微信扫一扫
您想发表意见!!点此发布评论




发表评论