Zookeeper 复习知识点(更新中)
265人参与 • 2024-08-02 • 微服务
zookeeper
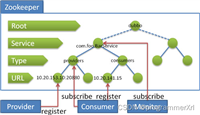
zookeeper 是开源的,是一个基于观察者模式设计的分布式服务管理框架,负责存储和管理大家都关心的数据,然后接收观察者的注册,一旦这些数据发生变化,zookeeper 负责通知已经注册的观察者。zookeeper 相当于文件系统 + 通知机制。
第 1 章 zookeeper 简介
1.1 zookeeper 特点
- 集群架构:zookeeper 通常由一组机器组成,一个 leader 和多个 follower 的集群结构。只要集群中存在过半的节点正常工作,整个集群就能够对外提供服务。为了保证高容错性,建议安装奇数台服务器
- 简单api:zookeeper 的 api 设计简洁且易于使用,其设计灵感来源于文件系统 api
- 顺序一致性和原子性:从同一客户端发起的事务请求,最终将严格按顺序被应用到 zookeeper 中。所有事务请求的处理结果在整个集群中的所有机器上是一致的
- 监听机制:zookeeper 支持强大的监听机制,能够快速捕捉到数据的变化
1.2 zookeeper 数据结构
zookeeper 数据模型类似 unix 文件系统(树状),每个节点称为 znode,每个 znode 默认可以存储 1mb 数据(对于记录状态性质的数据来说,足够使用)。
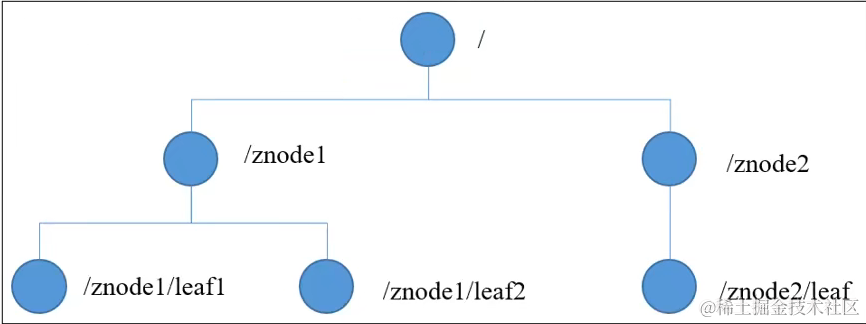
znode 节点类型有 4 种:
- persistent 持久节点:在节点创建后就一直存在,直到有删除操作来主动删除该节点。该节点不会因为创建该节点的客户端会话失效而消失
- persistent_sequential 持久顺序编号节点:基本特性和持久节点是一致的。额外的特性是,在 zookeeper 中,每个父节点会为它的第一级子节点维护一份时序,记录每个子节点创建的先后顺序。基于这个特性,那么在创建子节点过程中,zookeeper 会自动为给定节点名加上一个数字后缀,作为新的节点名。在创建节点的时候只需要传入节点 “/test_”,这样之后,zookeeper 自动会给 “/test_” 后面补充数字
- ephemeral 临时节点:和持久节点不同的是,临时节点的生命周期和客户端会话绑定。也就是说,如果客户端会话失效,那么这个节点就会自动被清除掉。注意,这里提到的是会话失效,而非连接断开。另外,在临时节点下面不能创建子节点。 这里还要注意一件事,就是当你客户端会话失效后,所产生的节点也不是一下子就消失了,也要过一段时间,大概是 10 秒以内
- ephemeral_sequential 临时顺序编号节点:此节点是属于临时节点,不过带有顺序编号,客户端会话结束节点就消失
1.3 zookeeper 应用场景
1.3.1 统一命名服务 / 统一配置管理 / 统一集群管理
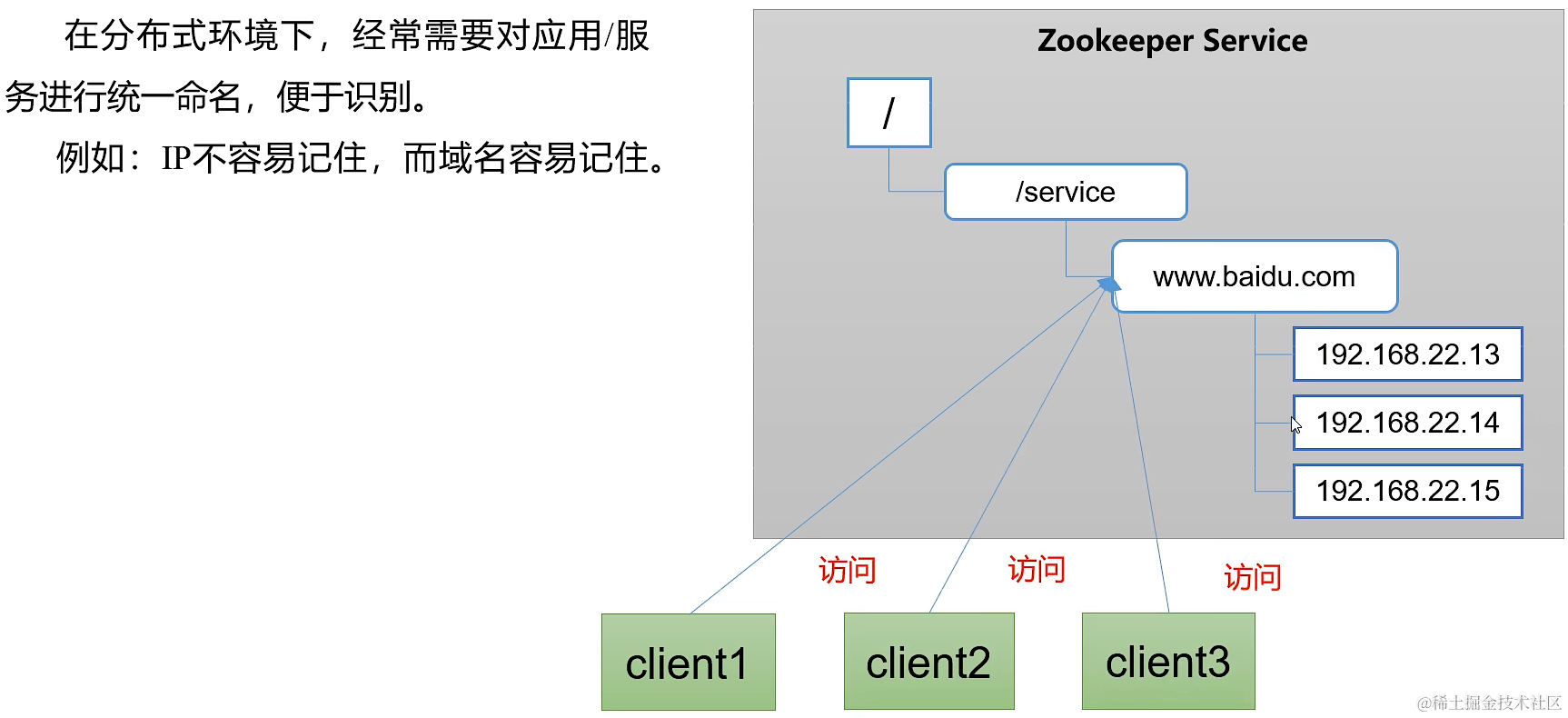
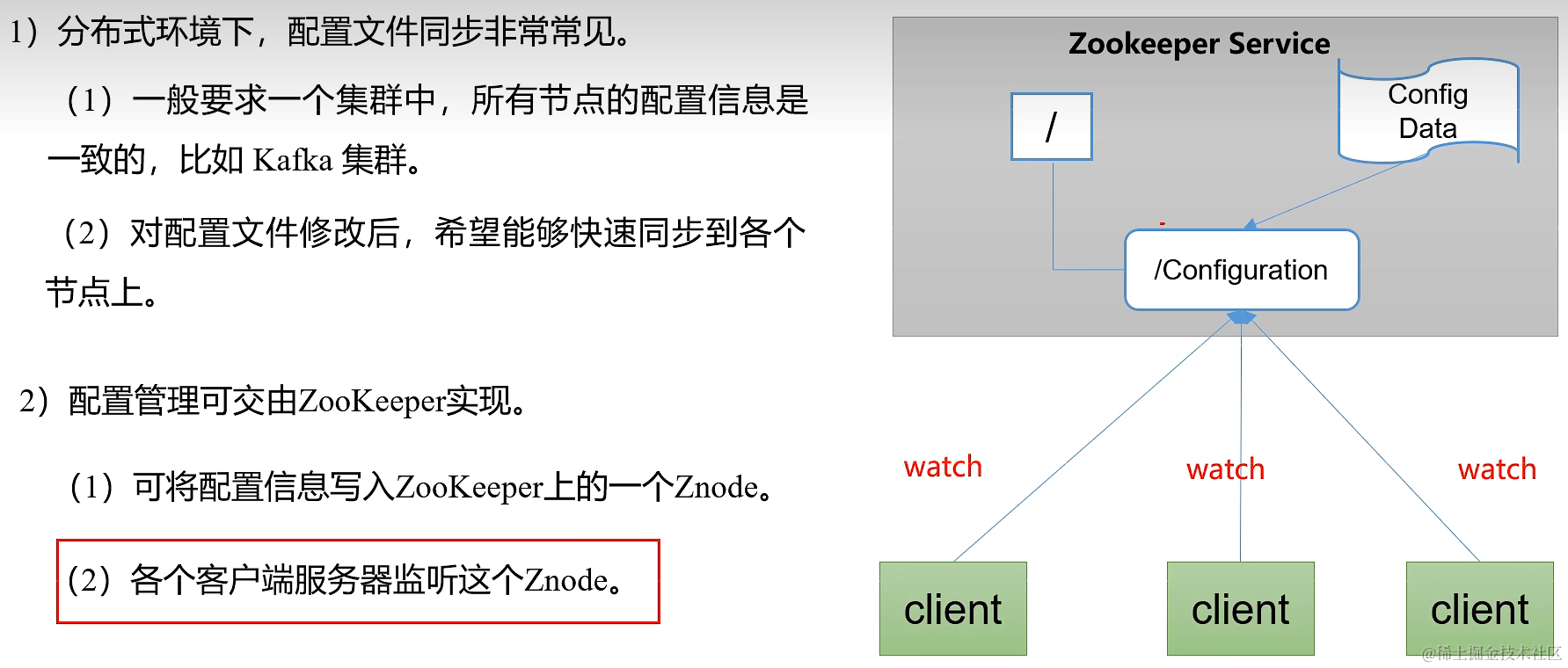
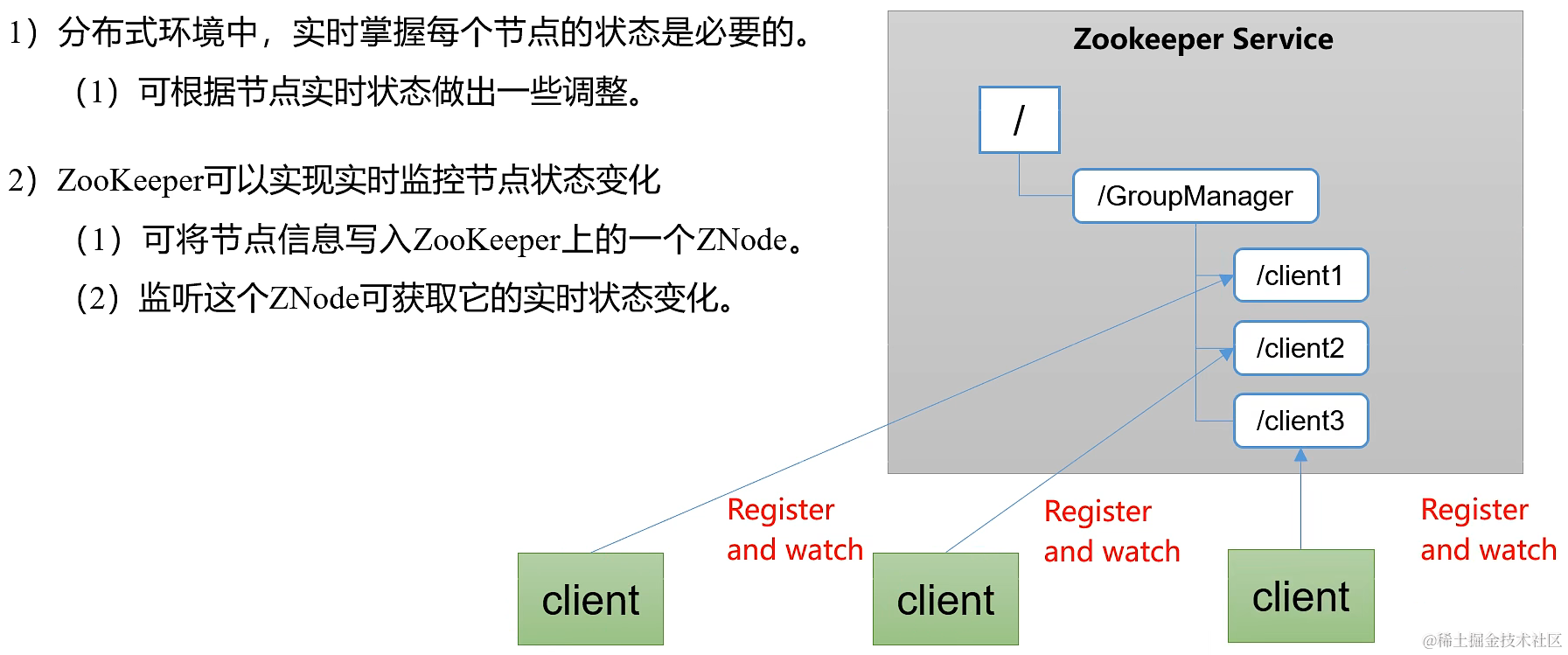
1.3.2 服务器动态上下线

1.3.3 分布式锁(⭐)

第 2 章 zookeeper 集群
zookeeper 稳定 3.5.7 版本下载:https://archive.apache.org/dist/zookeeper/zookeeper-3.5.7/
2.1 部署 zookeeper 集群
在 hostname 为 hadoop101、hadoop102、hadoop103 的三个节点上部署 zookeeper 集群。
2.1.1 安装解压
在 hadoop101 上解压压缩包:
tar -zxvf apache-zookeeper-3.5.7-bin.tar.gz
mv apache-zookeeper-3.5.7-bin/ zookeeper
cd zookeeper/
# 创建 zookeeper 数据目录
mkdir zkdata
2.1.2 配置服务器编号
在 /zookeeper/zkdata 目录下创建一个名为 myid 的文件,内容输入文件编号 1。
2.1.3 修改配置文件
cd zookeeper/conf
mv zoo_sample.cfg zoo.cfg
打开 zoo.cfg,进行以下修改添加:
ticktime=2000
initlimit=5
synclimit=2
datadir=/home/sy/zookeeper/zkdata
datalogdir=/var/log/zookeeper/datalog
reconfigenabled=true
standaloneenabled=false
clientport=2181
server.1=hadoop101:2888:3888
server.2=hadoop102:2888:3888
server.3=hadoop103:2888:3888
2.1.4 同步配置到其它节点
将 hadoop101 中已经配置好的 zookeeper 目录拷贝到 hadoop102 和 hadoop103 上,注意 hadoop102 和 hadoop103 需要分别修改 myid 的内容为 2、3。
2.1.5 启动集群
在三台服务器的 zookeeper 目录下分别输入命令:
bin/zkserver.sh start
bin/zkserver.sh status
2.2 zookeeper 集群配置文件
# zookeeper 服务端和客户端心跳时间,单位毫秒
ticktime=2000
# leader 和 follower 初始连接时能容忍的最多心跳数(ticktime 数量)
initlimit=5
# leader 和 follower 之间通信时间如果超过 synclimit * ticktime,leader 会认为该 follwer 挂掉,从服务列表中删除
synclimit=2
# 保存 zookeeper 数据的目录
datadir=/home/sy/zookeeper/zkdata
# 保存 zookeeper 事务日志的目录,与上面分开存储提高系统性能
datalogdir=/var/log/zookeeper/datalog
# 集群启动后是否可以修改现有配置
reconfigenabled=true
# zookeeper 是否以独立模式运行,集群模式下设为 false
standaloneenabled=false
# 客户端连接端口
clientport=2181
# 集群内有几个节点以下就写几行配置
# a 表示服务器的编号,与该服务器 myid 文件中的编号必须相同
# b 表示服务器的 hostname 或 ip
# c 表示服务器中 follower 和 leader 交换信息的端口
# d 表示重新选举时服务器相互通信的端口。
server.a=b:c:d
...
2.3 zookeeper 集群选举机制(⭐)
以三台服务器为例。
2.3.1 第一次启动
- 第一台服务器 101 启动时,发起一次选举,投给自己一票,但是选票未超过集群服务器总数的一半,101 服务器保持 looking 状态(正在选举状态)
- 第二台服务器 102 启动时,再发起一次选举,101 和 102 分别投给自己一票,两个服务器之间交换选举信息。此时 101 发现 102 的 myid 比自己大,所以更改投票为 102。此时 102 的票数超过集群服务器总数的一半,成为 leader。101 成为 follower。一旦集群中产生了 leader,就不会继续选举,所以 103 最后加入集群自动成为 follower
2.3.2 leader 宕机后的选举
- 服务器运行期间主观认为无法与 leader 保持连接,如果 leader 确实宕机,就会开启 leader 选举
- leader 任期代号(epoch)大的直接当选;epoch 相同,事务 id(zxid)大的当选;zxid 相同,服务器 id(sid)大的当选
第 3 章 zookeeper 节点命令
首先需要进入 zookeeper 安装包的 bin 目录下,输入以下命令进入客户端:
./zkclient.sh
3.1 查看节点
查看节点命令:
# 查看根节点下的所有子节点
ls /
# 查看某个子节点的值,path 可以有多级,每级用 / 隔开(与 linux 文件系统访问路径一致,有 tab 提示)
ls /<path>
# 监听节点的子节点(执行一次命令表示监听一次,要想再次监听,就要再执行一次命令)
ls -w /<path>
# 查看某个子节点的值和其它详细信息
ls2 /<path>
# 有以下详细信息:
# czxid 节点的事务id
# ctime 节点创建时间的id
# mzxid 最后一次被修改的事务id
# mtime 最后一次修改时间
# pzxid 最后一次修改该节点的子节点的事务 id
# cversion 子节点的版本号
# dataversion 当前数据的版本号,默认 0,每被修改一次会累加1
# aclversion 权限更迭版本
# ephemeralowner 临时节点的客户端会话 id
# a)节点为持久化节点时:ephemeralowner 值为0
# b)节点为临时节点时:ephemeralowner 值表示该节点所属客户端会话 id
# datalength 存储数据的长度
# numchildren 子节点个数
3.3 创建节点
- 持久节点
create /<path> "<node-value>"
- 持久顺序节点
create -s /<path> "<node-value>"
- 临时节点
create -e /<path> "<node-value>"
- 临时顺序节点
create -e -s /<path> "<node-value>"
3.4 获取节点数据
# 获取节点数据
get /<path>
# 监听节点数据的变化(执行一次命令表示监听一次,要想再次监听,就要再执行一次命令)
get -w /<path>
3.5 修改节点数据
set /<path> "new value"
3.6 删除节点
删除没有子节点的节点:
delete /<path>
删除带有子节点的节点:
deleteall /<path>
赞 (0)
您想发表意见!!点此发布评论




发表评论