2024年大数据最新计算机视觉项目实战-驾驶员疲劳检测_计算机视觉疲劳检测,帮你解决95%以上的问题
453人参与 • 2024-08-02 • 人脸识别
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事it行业的老鸟或是对it行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
🌟项目前言
上次博客我们讲到了如何定位人脸,并且在人脸上进行关键点定位。其中包括5点定位和68点定位等,在定位之后呢,我们就可以使用定位信息来做一些相关操作,例如闭眼检测,这里就可以应用到驾驶员的疲劳检测上,或者是经常使用电脑的人,不闭眼可能会导致眼睛干涩等。
🌟项目关键点讲解
我们本次博客主要讲解通过闭眼来检测疲劳驾驶,那么我们首先就要了解怎么让计算机来判断人是否闭了眼睛。我们通过上次的博客可以知道,我们首先要让计算机识别出来人脸,然后在识别出来的人脸上继续做关键点查找。我们这里用的是68关键点检测。

对于眼睛来讲,他每一个眼睛都有6个关键点。这里我们可以通过一种方式来判断是否进行了眨眼。
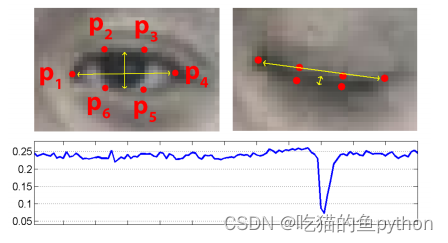
在眼睛的6个关键点中,我们可以发现当睁眼的时候,2和6点以及3和5点的欧氏距离较大。1和4点稍稍距离会增加一点,那么我们可以设定一个公式。
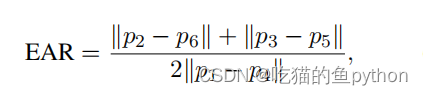

对应在图上就是2点和6点相减,3和5点相减。然后比上2倍的1和4点的差。其中都是绝对值。这样睁眼的时候ear的数值就会较大,闭眼的时候ear的数值就会较小。然后我们自己设定一个阈值,如果ear的数值低于这个阈值超过了视频帧中的几帧。那么我们就认为该驾驶员正在闭眼。
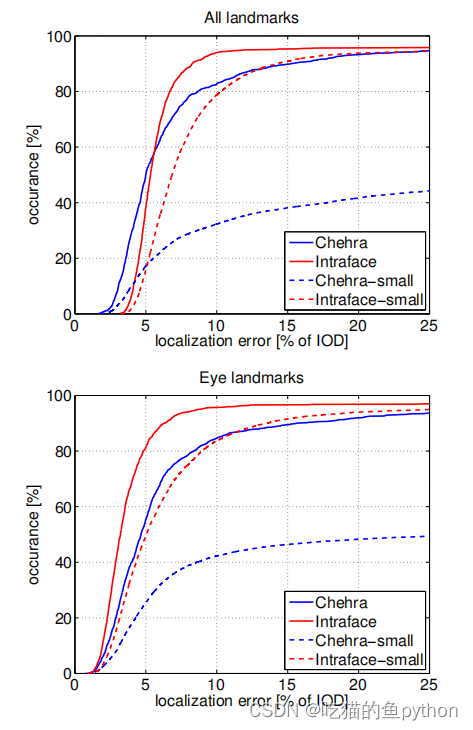
经过了论文验证,说明该方法的准确度是非常可观的,且具有较强的鲁棒性。
🌟项目代码详解
首先我们导入工具包,这里面也包括了计算欧氏距离的工具包。
from scipy.spatial import distance as dist
from collections import ordereddict
import numpy as np
import argparse
import time
import dlib
import cv2
然后我们把68点关键点定位信息定位好。
facial_landmarks_68_idxs = ordereddict([
("mouth", (48, 68)),
("right\_eyebrow", (17, 22)),
("left\_eyebrow", (22, 27)),
("right\_eye", (36, 42)),
("left\_eye", (42, 48)),
("nose", (27, 36)),
("jaw", (0, 17))
])
这里"jaw", (0, 17)表示的是下巴的位置的关键点标识分别是0-17点。
然后我们将需要的模型和视频导入到程序当中。关键点检测模型。
ap = argparse.argumentparser()
ap.add_argument("-p", "--shape-predictor", required=true,
help="path to facial landmark predictor")
ap.add_argument("-v", "--video", type=str, default="",
help="path to input video file")
args = vars(ap.parse_args())
eye_ar_thresh = 0.3
eye_ar_consec_frames = 3
这里这两个参数很重要,其中eye_ar_thresh这个表示ear的阈值。如果高于这个阈值说明人这个时候是睁眼的,如果低于这个阈值的话,那么这个时候就要注意了,驾驶员可能在闭眼。而eye_ar_consec_frames这个表示如果ear数值超过了三帧及以上我们就可以把他认定为一次闭眼。为什么是三帧呢?因为如果一帧两帧的话可能是其他因素影响的。
counter = 0
total = 0
然后我们又设定了两个计数器,如果小于阈值那么counter的数值就加一,知道counter的数值大于等于3的时候,这个total就加一,就说明记录的闭眼了一次。
print("[info] loading facial landmark predictor...")
detector = dlib.get_frontal_face_detector()
predictor = dlib.shape_predictor(args["shape\_predictor"])
这里我们就很熟悉了,一个是人脸定位器,一个是关键点检测器。这里分别调出来。
(lstart, lend) = facial_landmarks_68_idxs["left\_eye"]
(rstart, rend) = facial_landmarks_68_idxs["right\_eye"]
然后我们通过关键点只取两个roi区域,就是左眼区域和右眼区域。
print("[info] starting video stream thread...")
vs = cv2.videocapture(args["video"])
随后我们将视频读进来。
while true:
# 预处理
frame = vs.read()[1]
if frame is none:
break
(h, w) = frame.shape[:2]
width=1200
r = width / float(w)
dim = (width, int(h \* r))
frame = cv2.resize(frame, dim, interpolation=cv2.inter_area)
gray = cv2.cvtcolor(frame, cv2.color_bgr2gray)
将视频的展示框放大一点,这里很关键就是如果视频的框框设置的太小的话,可能无法检测到人脸。然后我们就把宽设置成了1200,然后对长度也同比例就行resize操作。最后转换成灰度图。
rects = detector(gray, 0)
这里面检测到人脸,将人脸框的四个坐标拿到手。注意就是必须要是对灰度图进行处理。
for rect in rects:
# 获取坐标
shape = predictor(gray, rect)
shape = shape_to_np(shape)
在这里进行人脸框遍历,然后检测68关键点。
def shape\_to\_np(shape, dtype="int"):
# 创建68\*2
coords = np.zeros((shape.num_parts, 2), dtype=dtype)
# 遍历每一个关键点
# 得到坐标
for i in range(0, shape.num_parts):
coords[i] = (shape.part(i).x, shape.part(i).y)
return coords
这里就是提取关键点的坐标。
lefteye = shape[lstart:lend]
righteye = shape[rstart:rend]
leftear = eye_aspect_ratio(lefteye)
rightear = eye_aspect_ratio(righteye)
然后我们把左眼和右眼分别求了一下ear数值。这里的eye_aspect_ratio函数就是计算ear数值的。
def eye\_aspect\_ratio(eye):
# 计算距离,竖直的
a = dist.euclidean(eye[1], eye[5])
b = dist.euclidean(eye[2], eye[4])
# 计算距离,水平的
c = dist.euclidean(eye[0], eye[3])
# ear值
ear = (a + b) / (2.0 \* c)
return ear
其中dist.euclidean表示计算欧式距离,和公式中计算ear数值一摸一样。
ear = (leftear + rightear) / 2.0
# 绘制眼睛区域
lefteyehull = cv2.convexhull(lefteye)
righteyehull = cv2.convexhull(righteye)
cv2.drawcontours(frame, [lefteyehull], -1, (0, 255, 0), 1)
cv2.drawcontours(frame, [righteyehull], -1, (0, 255, 0), 1)
然后对于左眼和右眼都进行了ear求解然后求了一个平均值,然后根据凸包的概念,对眼睛区域进行了绘图。将左眼区域和右眼区域绘图出来。
if ear < eye_ar_thresh:
counter += 1
else:
# 如果连续几帧都是闭眼的,总数算一次
if counter >= eye_ar_consec_frames:
total += 1
# 重置
counter = 0
# 显示
cv2.puttext(frame, "blinks: {}".format(total), (10, 30),
cv2.font_hershey_simplex, 0.7, (0, 0, 255), 2)
cv2.puttext(frame, "ear: {:.2f}".format(ear), (300, 30),
cv2.font_hershey_simplex, 0.7, (0, 0, 255), 2)
cv2.imshow("frame", frame)
key = cv2.waitkey(10) & 0xff
if key == 27:
break
vs.release()
cv2.destroyallwindows()
最后进行了一次阈值判断,如果ear连续三帧都小于0.3,那么我们就把total加一,这样记录一次闭眼的过程。然后最后将ear数值和total的数值展示在视频当中。最后完成整体的训练。
🌟项目结果展示


🌟项目改进方向(打哈欠检测疲劳方法)
我们知道在疲劳检测当中,光光检测眨眼可能不是特别准确,因此我们还要在其他可以展示驾驶员疲劳的点来结合展示驾驶员是否处于疲劳驾驶阶段。我们了解到还可以通过嘴巴打哈欠,和点头来展示驾驶员是否疲劳。我们首先来考虑嘴巴打哈欠。
首先我们来看一下嘴巴的关键点。
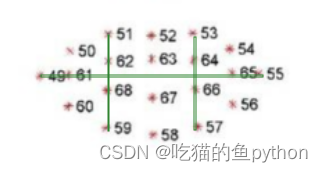
我们使用对眨眼检测的方法继续对嘴巴使用同样的方法检测是否张嘴!对应公式是:
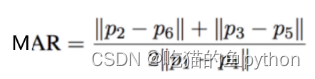
def mouth\_aspect\_ratio(mouth):
a = np.linalg.norm(mouth[2] - mouth[9]) # 51, 59
b = np.linalg.norm(mouth[4] - mouth[7]) # 53, 57
c = np.linalg.norm(mouth[0] - mouth[6]) # 49, 55
mar = (a + b) / (2.0 \* c)
return mar
这里面我们选择的是嘴部区域内的六个点,来判断驾驶员是否进行了张嘴!
mar_thresh = 0.5
mouth_ar_consec_frames = 3
同样我们也要设置一个阈值,解释同对眨眼检测的时候一样。
(mstart, mend) = facial_landmarks_68_idxs["mouth"]
首先我们取到68关键点中对应的嘴部区域。
mouth = shape[mstart:mend]
mar = mouth_aspect_ratio(mouth)

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
spect_ratio(mouth)
[外链图片转存中...(img-rwmlhhya-1715624317558)]
[外链图片转存中...(img-e6u024pw-1715624317559)]
[外链图片转存中...(img-nd34mn57-1715624317559)]
**既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!**
**由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新**
**[需要这份系统化资料的朋友,可以戳这里获取](https://bbs.csdn.net/topics/618545628)**
赞 (0)
您想发表意见!!点此发布评论






发表评论