FPGA - 以太网UDP通信(一)
432人参与 • 2024-08-03 • fpga开发
一,简述以太网
以太网简介
以太网是一种计算机局域网技术。ieee组织的ieee 802.3标准制定了以太网的技术标准,它规定了包括物理层的连线、电子信号和介质访问层协议的内容。
以太网类型介绍
以太网是现实世界中最普遍的一种计算机网络。以太网有两类:第一类是经典以太网,第二类是交换式以太网,使用了一种称为交换机的设备连接不同的计算机。经典以太网是以太网的原始形式,运行速度从3~10 mbps不等;而交换式以太网正是广泛应用的以太网,可运行在100、1000和10000mbps那样的高速率,分别以快速以太网、千兆以太网和万兆以太网的形式呈现。
二,osi七层模型和tcp/ip五层模型
“osi模型,即开放式通信系统互联参考模型(open system interconnection reference model),是国际标准化组织(iso)提出的一个试图使各种计算机在世界范围内互连为网络的标准框架,简称osi。”
osi七层模型
osi定义了网络互连的七层模型(物理层、数据链路层、网络层、传输层、会话层、表示层、应用层),如下图所示:

应用层:为应用程序或用户请求提供各种请求服务。osi参考模型最高层,也是最靠近用户的一层,为计算机用户、各种应用程序以及网络提供接口,也为用户直接提供各种网络服务。
表示层:数据编码、格式转换、数据加密。提供各种用于应用层数据的编码和转换功能,确保一个系统的应用层发送的数据能被另一个系统的应用层识别。如果必要,该层可提供一种标准表示形式,用于将计算机内部的多种数据格式转换成通信中采用的标准表示形式。数据压缩和加密也是表示层可提供的转换功能之一。
会话层:创建、管理和维护会话。接收来自传输层的数据,负责建立、管理和终止表示层实体之间的通信会话,支持它们之间的数据交换。该层的通信由不同设备中的应用程序之间的服务请求和响应组成。
传输层:数据通信。建立主机端到端的链接,为会话层和网络层提供端到端可靠的和透明的数据传输服务,确保数据能完整的传输到网络层。
网络层:ip选址及路由选择。通过路由选择算法,为报文或通信子网选择最适当的路径。控制数据链路层与传输层之间的信息转发,建立、维持和终止网络的连接。数据链路层的数据在这一层被转换为数据包,然后通过路径选择、分段组合、顺序、进/出路由等控制,将信息从一个网络设备传送到另一个网络设备。
数据链路层:提供介质访问和链路管理。接收来自物理层的位流形式的数据,封装成帧,传送到网络层;将网络层的数据帧,拆装为位流形式的数据转发到物理层;负责建立和管理节点间的链路,通过各种控制协议,将有差错的物理信道变为无差错的、能可靠传输数据帧的数据链路。
物理层:管理通信设备和网络媒体之间的互联互通。传输介质为数据链路层提供物理连接,实现比特流的透明传输。实现相邻计算机节点之间比特流的透明传送,屏蔽具体传输介质和物理设备的差异。
tcp/ip五层模型
tcp/ip是一组协议的代名词,它包括许多协议,组成了tcp/ip协议簇。它是把osi七层模型简化成了五层模型。每一层都呼叫它的下一层所提供的网络来完成自己的需求
tcp/ip 五层协议和 osi 的七层协议对应关系如下:
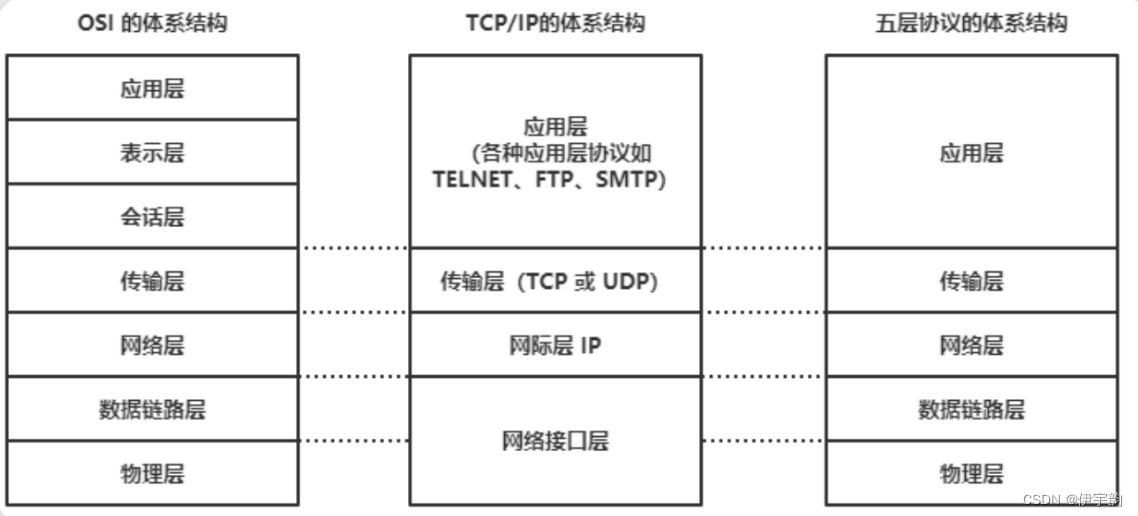
从上图中可以看出, tcp/ip 模型⽐ osi 模型更加简洁,它把 应⽤层/表示层/会话层 全部整合为了 应⽤层 。
在每⼀层都⼯作着不同的设备,⽐如我们常⽤的交换机就⼯作在数据链路层的,⼀般的路由器是⼯作在⽹络层的。
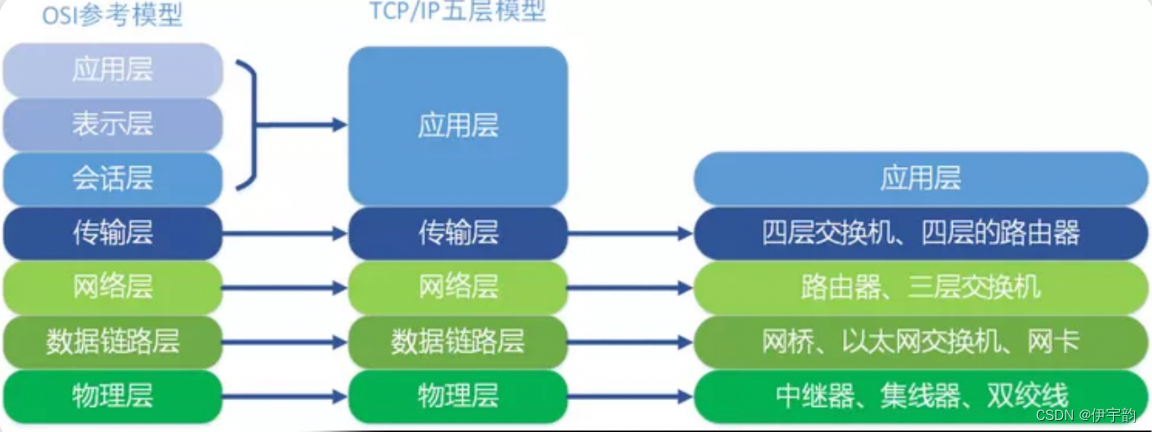
在每⼀层实现的协议也各不同,即每⼀层的服务也不同,下图列出了每层主要的传输协议:

一般说的fpga udp通信,fpga只做到了传输层,传输层以上的会话层、表示层等等,fpga是没有的。fpga 开发板通过一片 以太网phy芯片 提供对以太网连接的支持,phy芯片内提供物理层,进行4b/10b编码,phy芯片提供mii/gmii/rgmii 接口的mac连接。
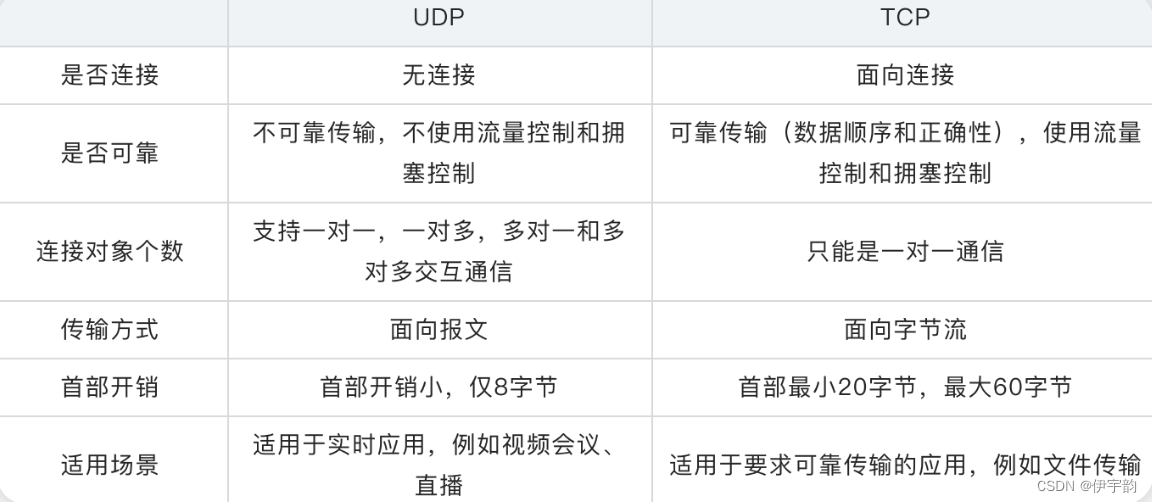
在传输层中 tcp 和 udp都是传输层协议,它们都属于tcp/ip协议族:
🤔 udp
udp的全称是⽤户数据报协议,在⽹络中它与tcp协议⼀样⽤于处理数据包,是⼀种⽆连接的协议。在osi模型中,在传输层,处于ip协议的上⼀层。udp有 不提供数据包分组、组装和不能对数据包进⾏排序的缺点,也就是说,当报⽂发送之后,是⽆法得知其是否安全完整到达的。
它的特点如下:
- 面向无连接
- 有单播、多播、广播的功能
- 面向报文
- 不可靠性
- 头部开销⼩,传输数据报⽂⾼效。
🧐 tcp
- 面向连接
- 仅支持单播传输
- 面向字节流
- 可靠传输
- 提供拥塞控制
- 提供全双工通信
😜 tcp和udp的区别
三,fpga udp通信硬件构成
根据以上的简述,我们知道 fpga udp通信 fpga只做到了传输层,传输层以上的会话层、表示层等等,fpga是没有的。 所以pc端发送数据经过传输层添加tcp/udp 头部后,在经过网络层添加ip头部,然后经过数据链路层添加mac头部,通过层级组包传输到fpga的phy芯片内提供物理层,进行4b/10b编码,phy芯片提供mii/gmii/rgmii 接口的mac连接。
四,phy芯片接口介绍
从数据传输角度来看,控制器(fpga )和 phy 侧芯片实现以太网传输的数据链路两端,有 3 种主要的接口形式。这 3 种接口形式主要是 mii gmii 和 rgmii 。 mii 主要应用在百兆网传输中,而 gmii 和 rgmii 则均可以运用于千兆网, rgmii 相较于 gmii ,则可以有更高的数据位通信效率。
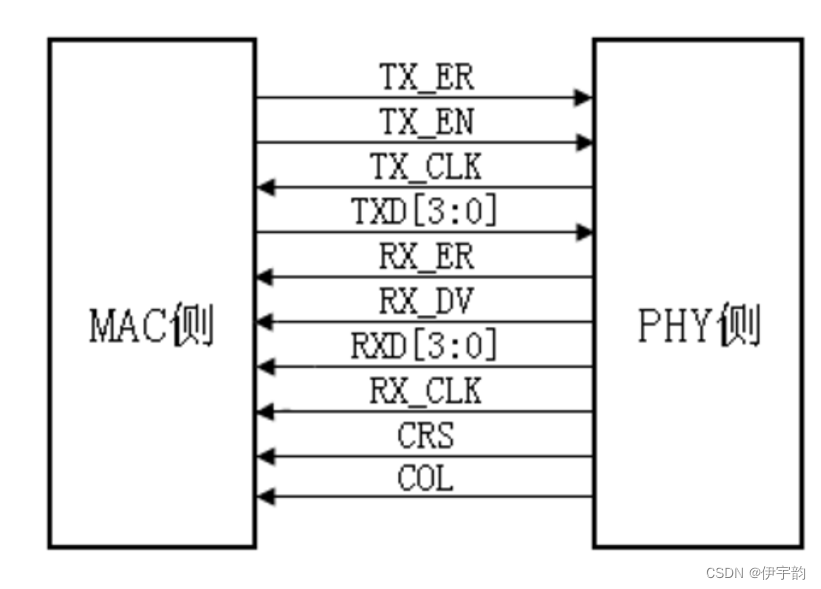
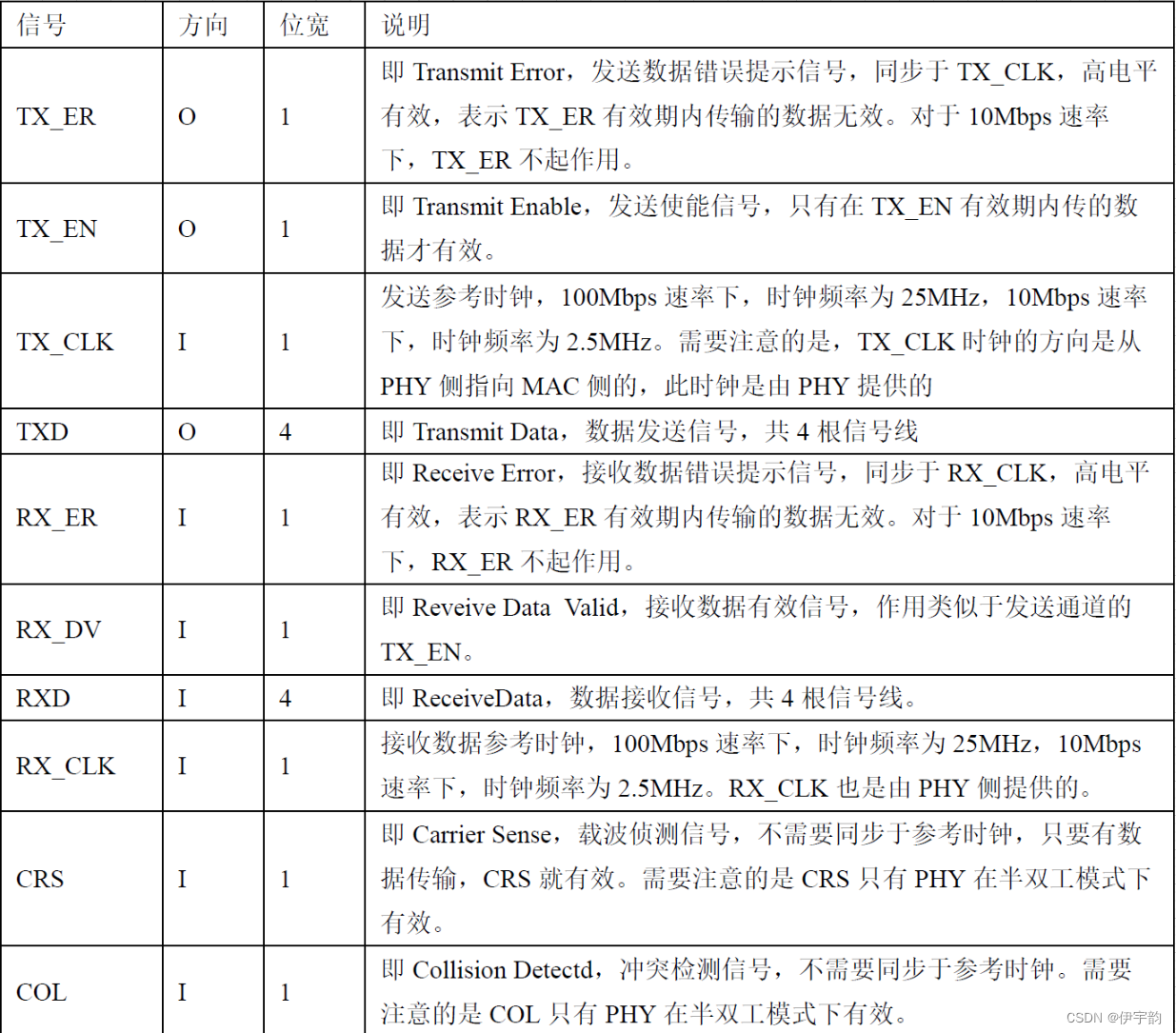
mii 接口
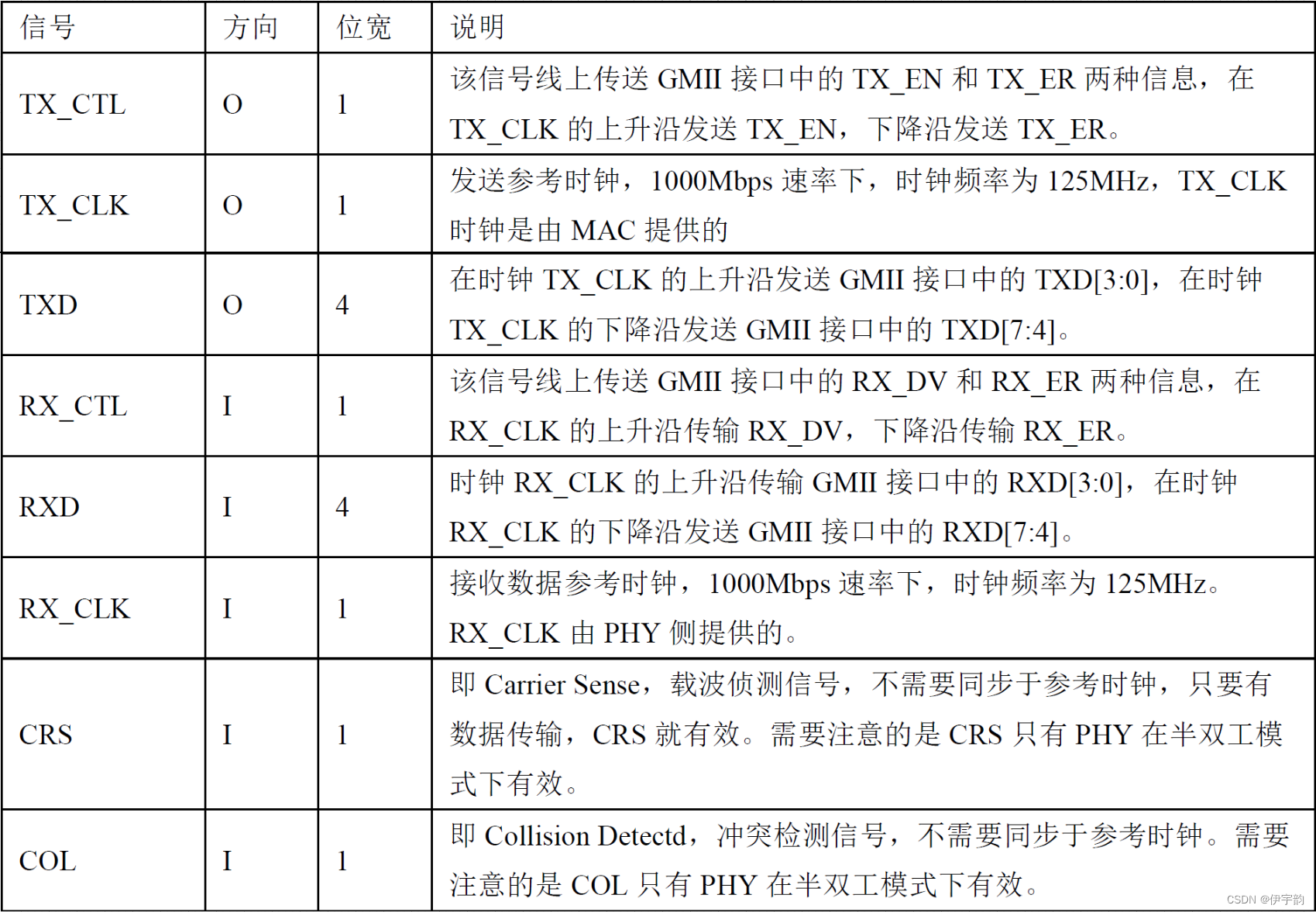
mii 接口信号连接关系及各信号的介绍如下。
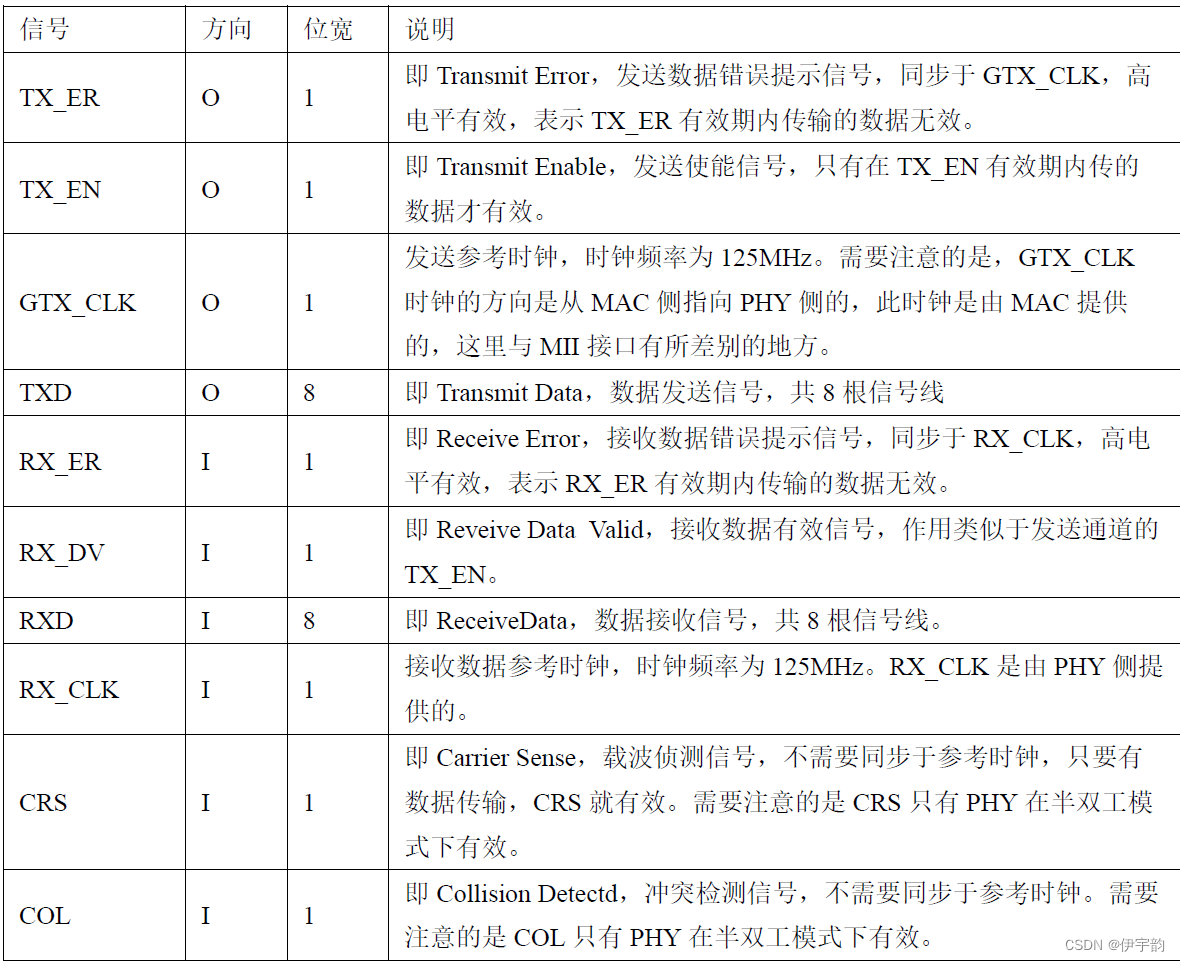
gmii 接口
gmii 接口信号连接关系及各信号的介绍如下。

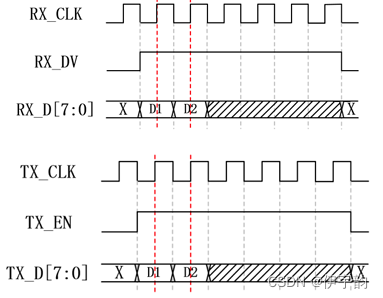
gmii 发送和接收时序:
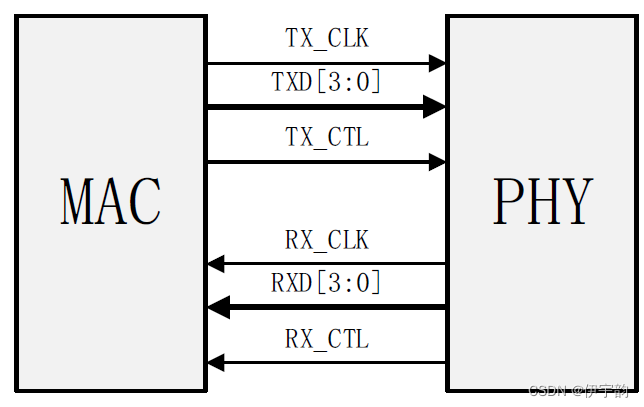
rgmii 接口
rgmii 即reducedgmii,是gmii 的简化版本,将接口信号线数量从24根减少到14根,时钟频率仍旧为125mhz,tx/rx 数据宽度从8 位变为4位。rgmii接口信号连接关系及各信号的介绍如下。
rgmii接口为了保持1000mbps 的传输速率不变, rgmii 接口在时钟的上升沿和下降沿都采样数据。在参考时钟的上升沿发送 gmii 接口中的 txd[3:0]/rxd[3:0] ,在参考时钟的下降沿发送 gmii 接口中的 txd[7:4]/rxd[7:4] 。
rgmii 的时序分为两种:延时模式和非延时模式,可以通过配置phy芯片改变模式。 用的比较多的模式是延时模式,一般phy芯片默认配置为延时模式。
时序图如下:
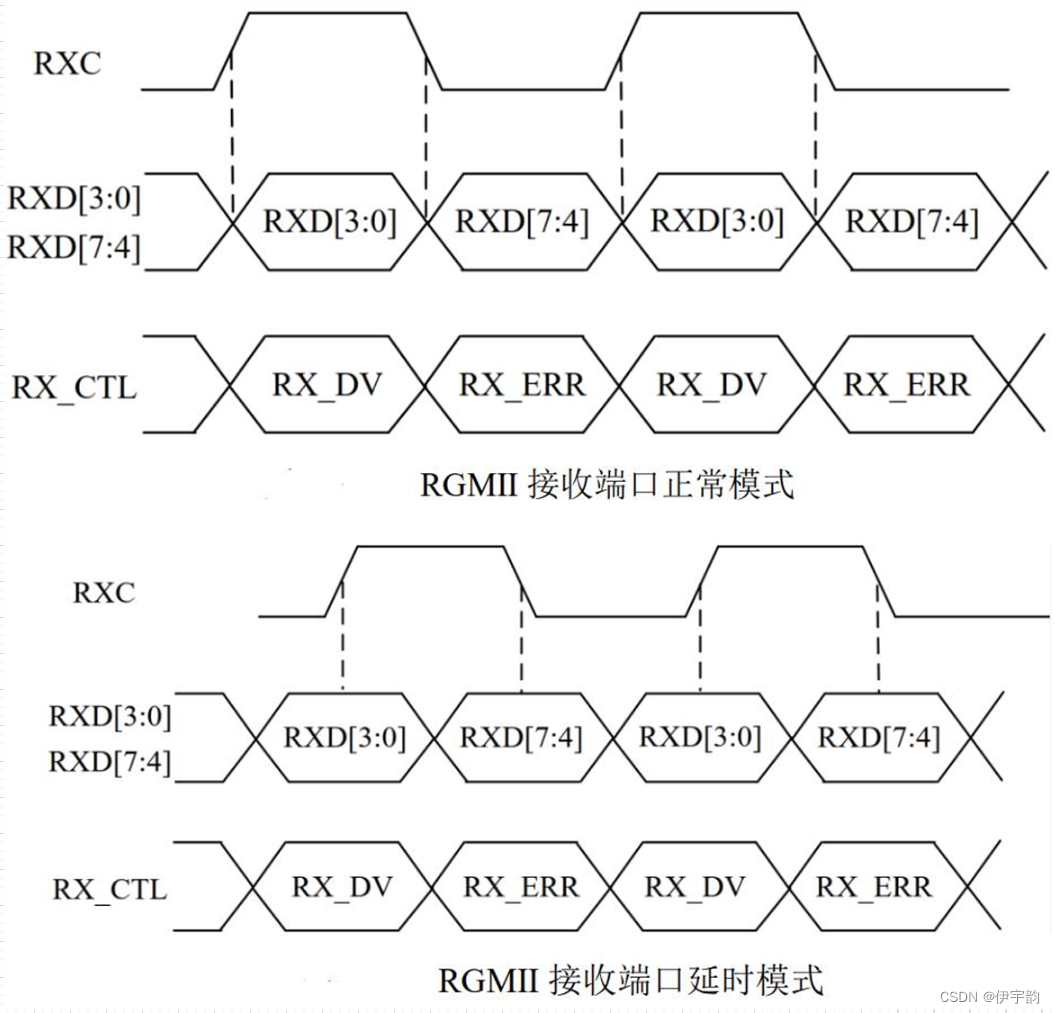
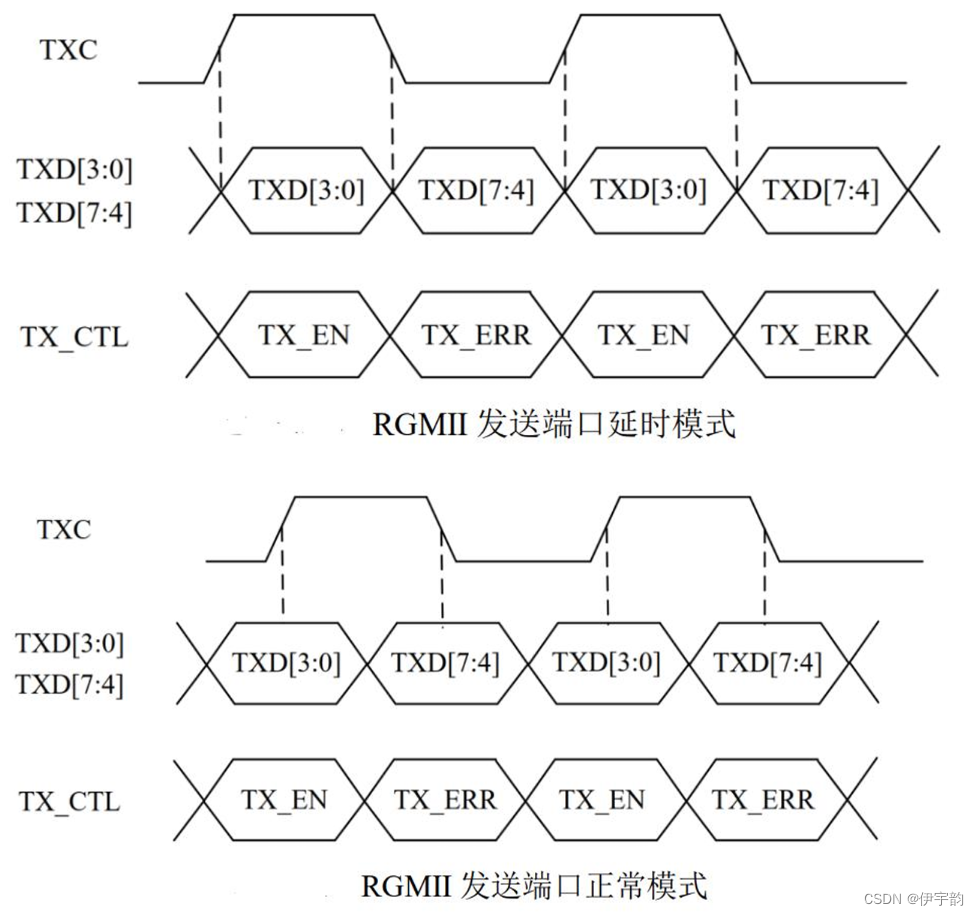
根据以上介绍,我们使用rgmii接口的以太网 phy 与 mac (phy )的连接实现方法,解决了接口问题,才能编写对应的网络协议实现逻辑。
五,rgmii和gmii转换电路设计
在以上了解中,我们知道rgmii 是gmii 的简化版本,接口信号线数量从24根减少到14根,tx/rx 数据宽度从8 位变为4位,所以我们要实现rgmii的发送与接收。
rgmii发送
对于fpga来说,实现 rgmii 接口的发送是一个非常直接的过程,整个发送逻辑框图如图所示:
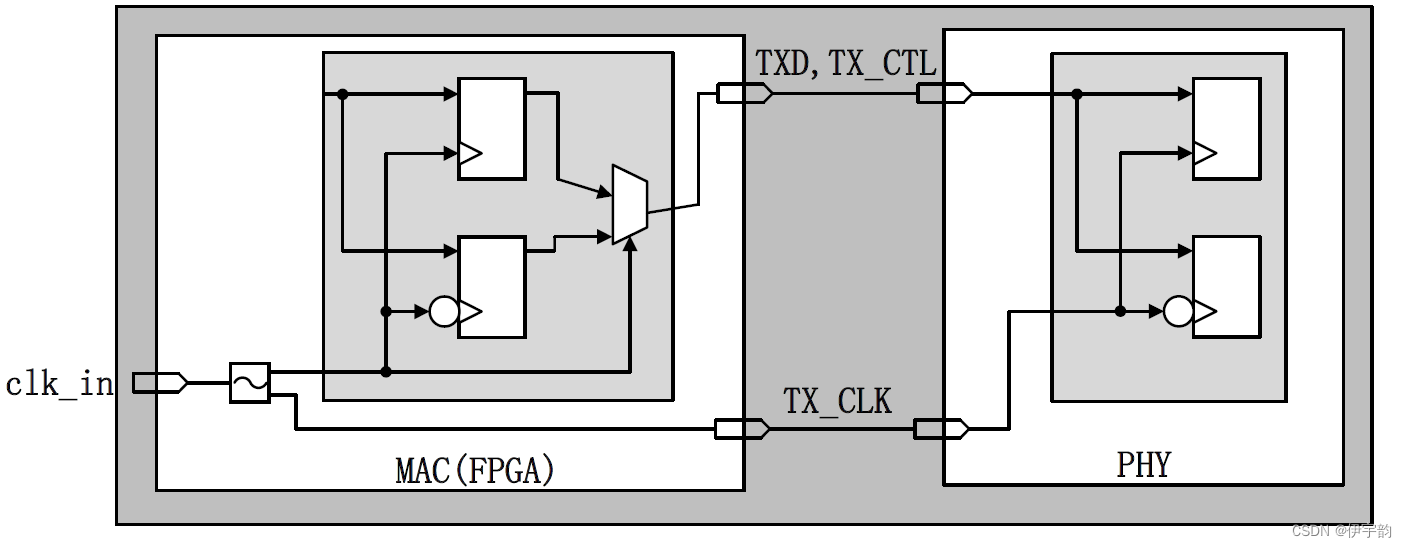
设计实现时,我们需要使用xilinx 的oddr(output double data rate,输出双倍数据速率)原语,将该接口使用ologic 块实现。oddr 原语只有一个时钟输入,下降沿数据由输入时钟的本地反转来计时,反馈到i/o块的所有的时钟被完全复用,oddr 原语的框图如图 所示:
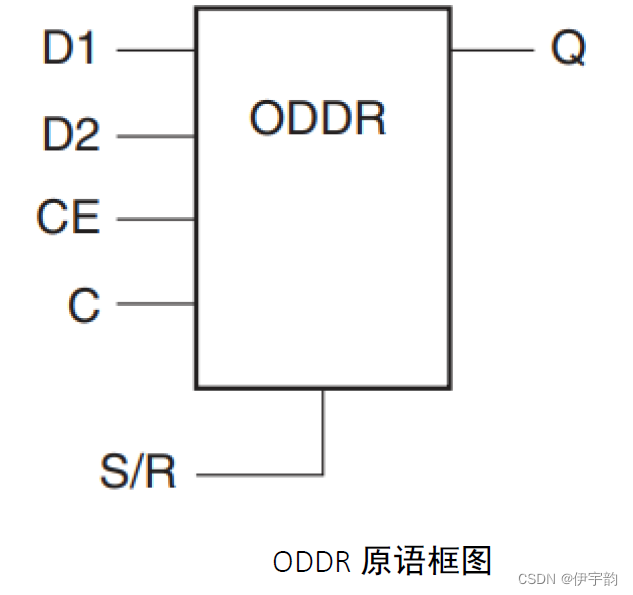
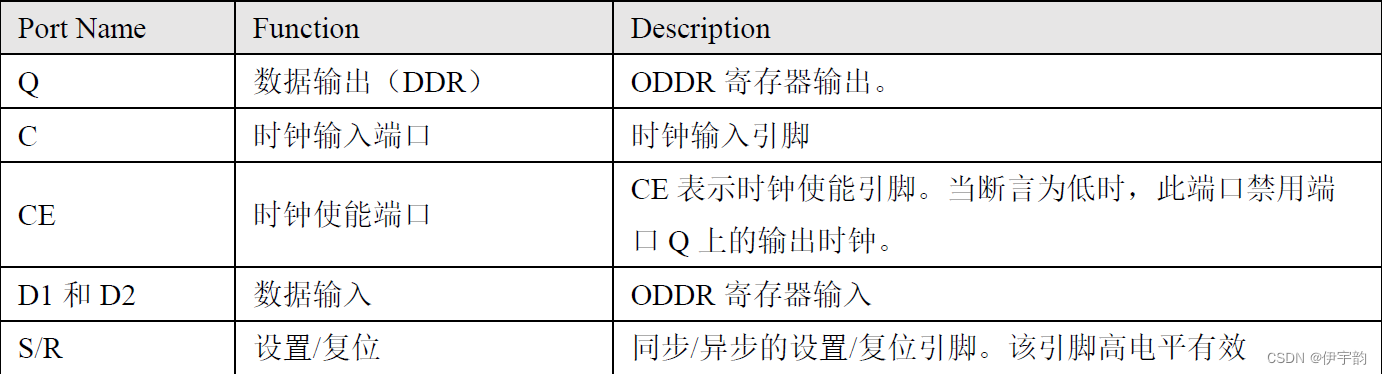
其中各个端口的功能及描述如下:
除了这些端口外, oddr原语还包含一些可用属性:

编写rgmii_send代码:
module gmii_to_rgmii(
reset_n,
gmii_tx_clk,
gmii_txd,
gmii_txen,
gmii_txer,
rgmii_tx_clk,
rgmii_txd,
rgmii_txen
);
input reset_n;
input gmii_tx_clk;
input [7:0] gmii_txd;
input gmii_txen;
input gmii_txer;
output rgmii_tx_clk;
output [3:0] rgmii_txd;
output rgmii_txen;
genvar i;
generate
for(i=0;i<4;i=i+1)
begin: rgmii_txd_o
oddr #(
.ddr_clk_edge("same_edge"), // "opposite_edge" or "same_edge"
.init (1'b0 ), // initial value of q: 1'b0 or 1'b1
.srtype("sync" ) // set/reset type: "sync" or "async"
) oddr_rgmii_txd (
.q (rgmii_txd[i] ), // 1-bit ddr output
.c (gmii_tx_clk ), // 1-bit clock input
.ce (1'b1 ), // 1-bit clock enable input
.d1 (gmii_txd[i] ), // 1-bit data input (positive edge)
.d2 (gmii_txd[i+4] ), // 1-bit data input (negative edge)
.r (~reset_n ), // 1-bit reset
.s (1'b0 ) // 1-bit set
);
end
endgenerate
oddr #(
.ddr_clk_edge("same_edge"), // "opposite_edge" or "same_edge"
.init (1'b0 ), // initial value of q: 1'b0 or 1'b1
.srtype("sync" ) // set/reset type: "sync" or "async"
) oddr_rgmii_txd (
.q (rgmii_txen ), // 1-bit ddr output
.c (gmii_tx_clk ), // 1-bit clock input
.ce (1'b1 ), // 1-bit clock enable input
.d1 (gmii_txen ), // 1-bit data input (positive edge)
.d2 (gmii_txen^gmii_txer ), // 1-bit data input (negative edge)
.r (~reset_n ), // 1-bit reset
.s (1'b0 ) // 1-bit set
);
oddr #(
.ddr_clk_edge("same_edge"), // "opposite_edge" or "same_edge"
.init (1'b0 ), // initial value of q: 1'b0 or 1'b1
.srtype("sync" ) // set/reset type: "sync" or "async"
) oddr_rgmii_clk (
.q (rgmii_tx_clk ), // 1-bit ddr output
.c (gmii_tx_clk ), // 1-bit clock input
.ce (1'b1 ), // 1-bit clock enable input
.d1 (1'b1 ), // 1-bit data input (positive edge)
.d2 (1'b0 ), // 1-bit data input (negative edge)
.r (~reset_n ), // 1-bit reset
.s (1'b0 ) // 1-bit set
);
endmodule
rgmii接收
对于 fpga 来说,实现 rgmii 接口的接收同样是一个非常直接的过程, 整个接收逻辑框图如图所示:
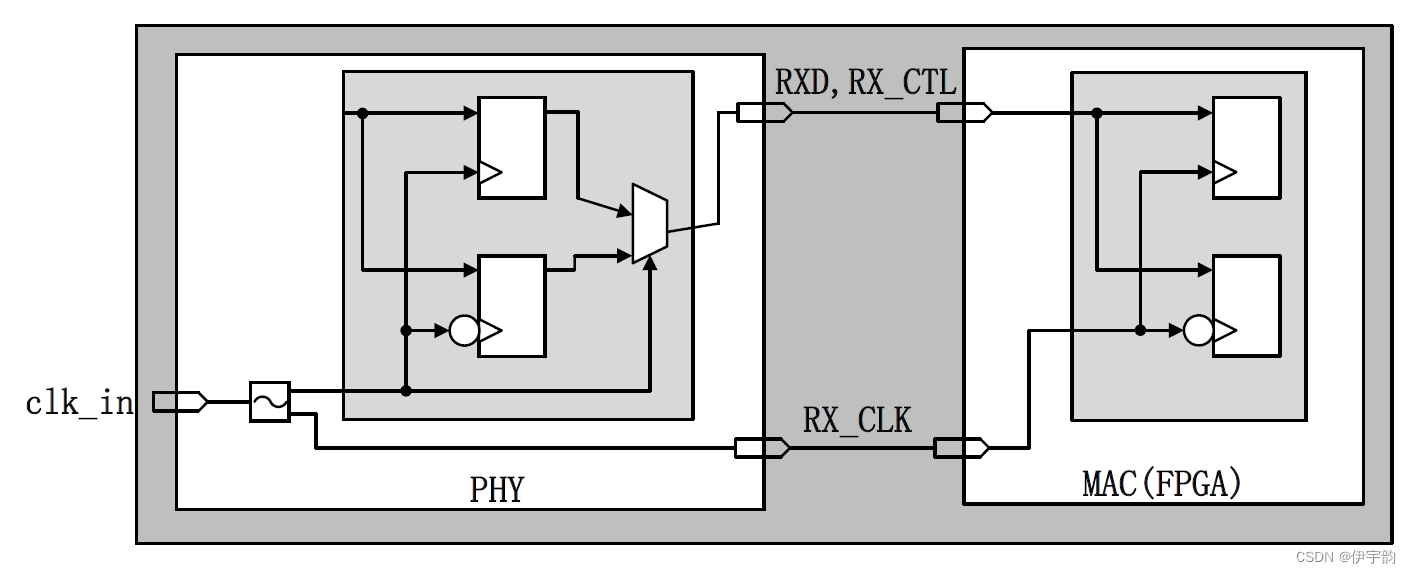
同样,设计实现时,可通过使用xilinx 的iddr 原语,将该接口使用ilogic 块实现。在ilogic 块中,有着专用的寄存器,用于实现输入双倍数据速率(ddr)寄存器,当我们实例化iddr 原语时便会自动访问该功能。iddr 原语的框图如图所示:
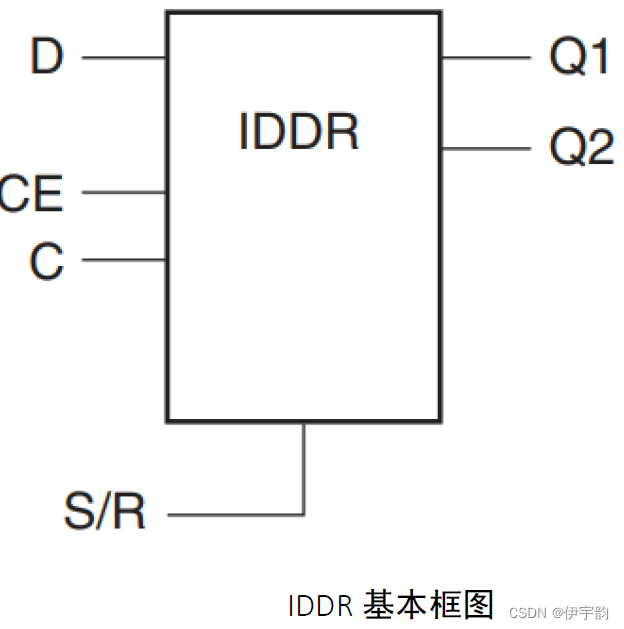
其中各个端口的功能及描述如表
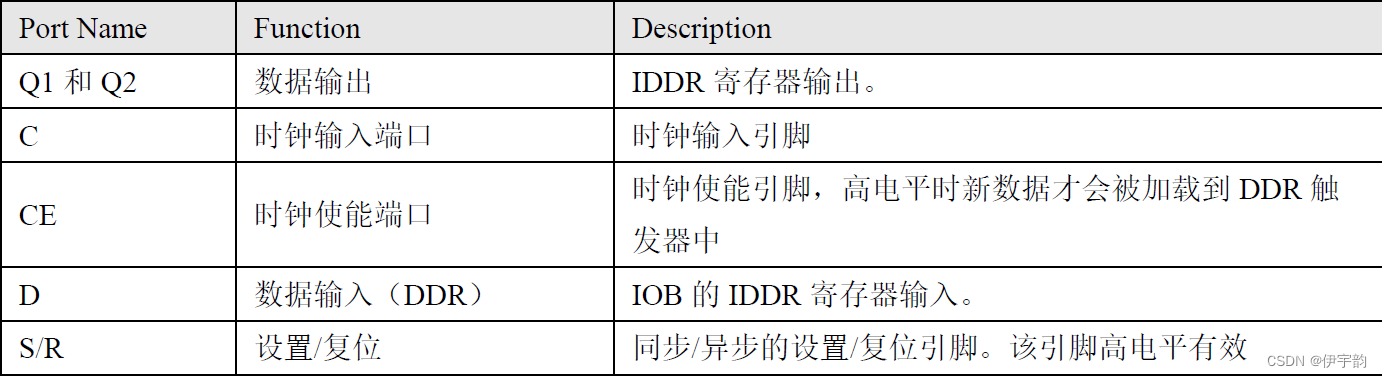
除了这些端口外, iddr 原语还包含一些可用属性:
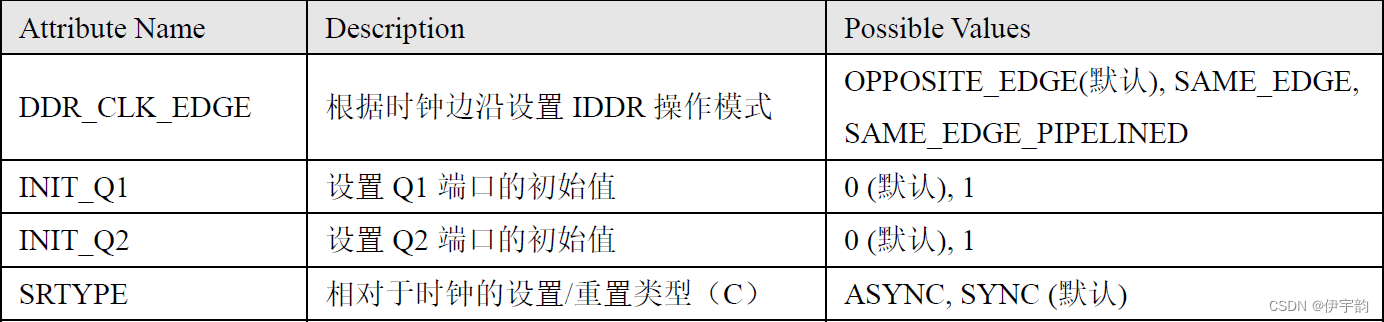
编写rgmii_receive代码:
module rgmii_to_gmii(
reset_n,
gmii_rx_clk,
gmii_rxdv,
gmii_rxd,
gmii_rxerr,
rgmii_rx_clk,
rgmii_rxd,
rgmii_rxdv
);
input reset_n;
output gmii_rx_clk;
output [7:0] gmii_rxd;
output gmii_rxdv;
output gmii_rxerr;
input rgmii_rx_clk;
input [3:0] rgmii_rxd;
input rgmii_rxdv;
wire gmii_rxer;
assign gmii_rx_clk = rgmii_rx_clk;
assign gmii_rxerr = gmii_rxer^gmii_rxdv ;
genvar i;
generate
for(i=0;i<4;i=i+1)
begin: rgmii_rxd_i
iddr #(
// "opposite_edge", "same_edge" or "same_edge_pipelined"
.ddr_clk_edge("same_edge_pipelined"),
.init_q1(1'b0 ), // initial value of q1: 1'b0 or 1'b1
.init_q2(1'b0 ), // initial value of q2: 1'b0 or 1'b1
.srtype ("sync" ) // set/reset type: "sync" or "async"
) iddr_rxd (
.q1(gmii_rxd[i]),//1-bit output for positive edge of clock
.q2(gmii_rxd[i+4]),//1-bit output for negative edge of clock
.c (rgmii_rx_clk ), // 1-bit clock input
.ce (1'b1 ), // 1-breset_nit clock enable input
.d (rgmii_rxd[i] ), // 1-bit ddr data input
.r (!reset_n ), // 1-bit reset
.s (1'b0 ) // 1-bit set
);
end
endgenerate
iddr #(
// "opposite_edge", "same_edge" or "same_edge_pipelined"
.ddr_clk_edge("same_edge_pipelined"),
.init_q1(1'b0 ), // initial value of q1: 1'b0 or 1'b1
.init_q2(1'b0 ), // initial value of q2: 1'b0 or 1'b1
.srtype ("sync" ) // set/reset type: "sync" or "async"
) iddr_rxdv (
.q1(gmii_rxdv), // 1-bit output for positive edge of clock
.q2(gmii_rxer), // 1-bit output for negative edge of clock
.c (rgmii_rx_clk ), // 1-bit clock input
.ce (1'b1 ), // 1-breset_nit clock enable input
.d (rgmii_rxdv ), // 1-bit ddr data input
.r (!reset_n ), // 1-bit reset
.s (1'b0 ) // 1-bit set
);
endmodule
六,总结
至此,关于fpga udp通信的rgmii 接口与 gmii 接口的互转逻辑设计已经实现,在 fpga 中设计以太网的接收和发送逻辑时,只需要按照 gmii 接口的形式,先设计出对应的发送和接收逻辑,再将对应的端口连接到 rgmii 与 gmii 接口转换逻辑上,就能够完成基于 rgmii 接口的以太网接收和发送。
赞 (0)
您想发表意见!!点此发布评论



发表评论