RAG 工业落地方案框架(Qanything、RAGFlow、FastGPT、智谱RAG)细节比对!CVPR自动驾驶最in挑战赛赛道,全球冠军被算力选手夺走了
455人参与 • 2024-08-05 • 驱动开发
rag 工业落地方案框架(qanything、ragflow、fastgpt、智谱rag)细节比对!cvpr自动驾驶最in挑战赛赛道,全球冠军被算力选手夺走了。
本文详细比较了四种 rag 工业落地方案 ——qanything、ragflow、fastgpt 和智谱 rag,重点分析了它们在知识处理、召回模块、重排模块、大模型处理、web 服务和切词处理等方面的具体实现。qanything 在 rerank 模块设计上表现出色;ragflow 在文档处理方面优势明显;fastgpt 提供了高度动态配置的模块;智谱 rag 则在领域数据上的模型微调上有着特殊的优势。每个方案都有其独特的技术细节和适用场景,强调了在实际应用中,选择合适的技术实现以及对细节的精细化处理对于项目的成功至关重要。
用强化学习解决现实问题:stochasticity、scale、gae与curriculum learning
文章探讨了强化学习在现实问题解决中的应用,特别是如何处理随机性(stochasticity)和规模(scale)问题。作者通过实例说明了在手机操作系统中完成查资料和购物任务的 rl 模型,强调了显式建模随机性的重要性。为了应对数据需求,开发了多机分布式并行脚本以大规模收集数据。此外,文章提出了使用任务完成情况作为整体轨迹的奖励,而非单步奖励,以简化评估过程。
在模型选择上,作者使用了参数量为 1.5b 的小模型,并通过与 gpt-4 的比较展示了其性能优势。文章还提供了 base 模型选择的建议,即选择性能不差且大小适中的模型,以便于训练。算法方面,提出了 filtered awr 和 gae 的简化版本,以及 automatic curriculum learning 策略,这些都是为了更好地适应现实问题的复杂性。实验结果显示,所提出的方法在性能上超越了现有的 agent,如 gpt-4 和 gemini,并在相同数据集上也表现出色。作者最终开源了代码和模型,邀请社区参与和验证这些研究成果。

chameleon和florence-2
chameleon 模型采用前融合技术,通过单一 tokenizer 同时处理视觉和语言信息,实现端到端的多模态学习。它使用 vqgan 进行图像编码,将图像转换为离散的 tokens,并与文本 tokens 一起输入到 transformer 模型中。这种方法使得不同模态的特征能够在同一表征空间内被有效地关联,提高了模型学习的效率。
florence-2 模型虽然采用后融合方式,但在多 cv 任务上展现了卓越的性能,能够处理包括 vqa、视觉地面化、ocr 等多种任务。它的模型规模较小,但通过多任务学习,取得了与大型模型相当的效果。florence-2 的成功表明,多模态模型在处理复杂的计算机视觉任务时,不仅要关注前融合技术,还要优化模型结构和训练方法,以适应实际应用的需求。
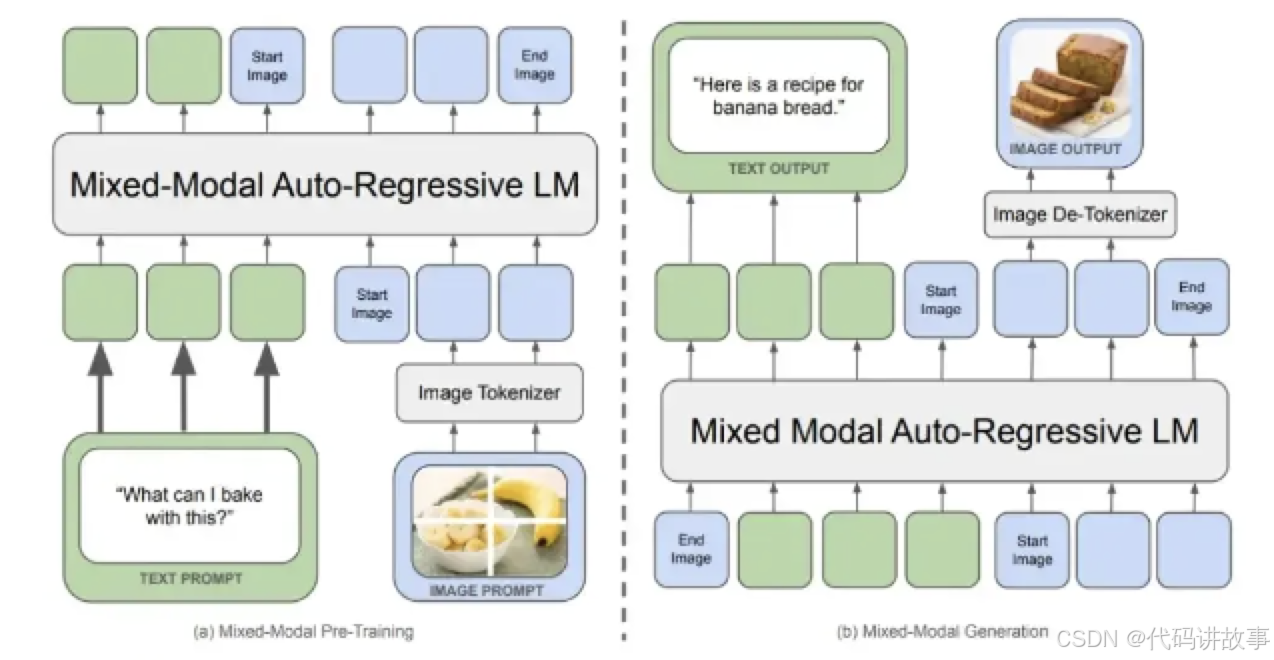
agent attention:集成 softmax 和 linear 注意力机制
注意力机制 (attention module) 是 transformers 中的关键组成部分。虽然全局的注意力机制具有很高的表征能力,但其计算成本较大,限制了其在各种场景下的适用性。本文提出一种新的注意力范式 agent attention,目的在计算效率和表征能力之间取得良好的平衡。具体而言,agent attention 表示为四元组 (𝑄,𝐴,𝐾,𝑉) ,在传统的注意力模块中引入了一组额外的 agent token 𝐴 。agent token 首先充当 query token 𝑄 的代理来聚合来自 𝐾 和 𝑉 的信息,然后将信息广播回 𝑄。鉴于 agent token 的数量可以设计为远小于 query token 的数量,代理注意力明显比 softmax 注意力更有效,同时保留了全局上下文建模能力。
有趣的是,本文展示了 agent attention 等效于 linear attention 的广义形式。因此,代理注意力无缝集成了强大的 softmax attention 和高效的 linear attention。
作者通过大量实验表明,agent attention 在各种视觉任务中证明了有效性,包括图像分类、目标检测、语义分割和图像生成。而且,代理注意力在高分辨率场景中表现出显着的性能,这得益于其线性注意力性质。例如,当应用于 stable diffusion 时,agent attention 会加速生成并显着提高图像生成质量,且无需任何额外的训练。
昇腾ai原生创新算子挑战赛s1——算子优化详解
昇腾 ai 原生创新算子挑战赛 s1是一个旨在优化 ai 算子性能的竞赛。竞赛分为初赛和决赛两个阶段,通过对算子进行原生优化,提高其在昇腾处理器上的执行效率。初赛要求参赛者对指定算子进行优化,并通过评测系统评估性能。评测标准包括性能提升比例和最终性能排名。决赛则是邀请初赛中表现最佳的选手进行线下深度优化比赛。竞赛提供了算子优化的学习资源,包括基础知识、实践技巧和高级优化方法。重点强调技术细节,如算子内存访问优化、计算密集型操作简化、并行化处理等,以实现更高效的 ai 计算。此外,竞赛鼓励参赛者探索创新的优化策略,以期在未来的 ai 领域中实现更大的性能突破。
华泰 | 电子:ai大模型需要什么样的硬件?
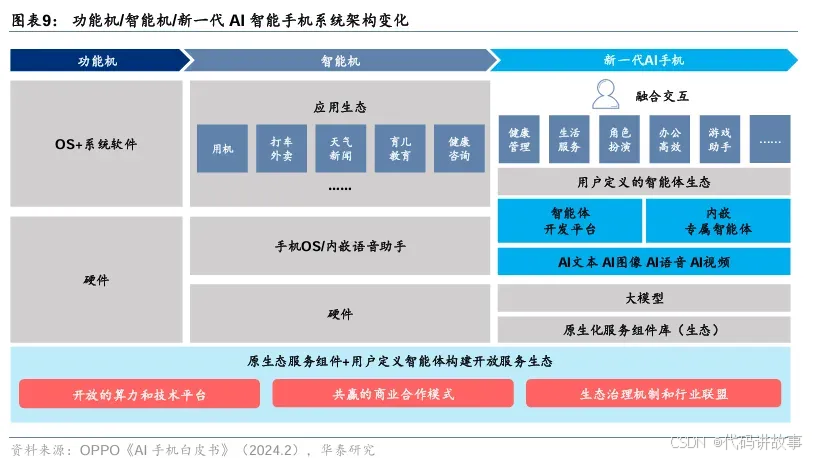
ai 大模型技术的快速发展对硬件产品提出了新的要求。在技术细节上,ai 大模型需要更高的算力支持,这导致了 soc 中 npu 算力的提升和存储容量的扩展。例如,ai pc 的推出需要具备 npu 提供的边缘算力能力,以及内置大模型的能力。在软件层面,ai 大模型的应用推动了系统架构和应用方面的匹配,如 ai 智能手机的智能体开发平台和专属智能体的提供。此外,ai 大模型在具身智能、自动驾驶和人形机器人等领域的应用,涉及到感知、决策和控制等多个环节的技术细节,这些细节包括但不限于大模型的多模态能力、运动控制算法的优化以及硬件级的安全芯片的使用。在云计算方面,ai 大模型的部署和服务化,如 maas 模式,也依赖于高效的算力和数据处理技术。
huggingface&github
01
maestro
maestro是一个python框架,可以利用anthropic的ai模型(如opus和haiku)来协调和执行复杂的任务。它可以将目标任务分解为更小的可管理子任务,利用子模型独立执行这些子任务,然后将结果汇总优化为最终输出。这种ai辅助的任务分解和执行方法可以提高复杂目标的完成效率和质量。
https://github.com/doriandarko/maestro
02
diffsynth-studio
diffsynth-studio是一个基于扩散模型的视频合成框架,提供了多种创新性功能,包括视频合成、去闪烁、卡通风格渲染等。它重构了文本编码器、unet、vae等核心架构,在保持与开源社区模型兼容的同时,也大幅提高了计算性能。
diffsynth-studio支持多种先进的扩散模型,如stable diffusion、controlnet、stable video diffusion等,并且还提出了exvideo等新技术来增强视频生成的能力。
https://github.com/modelscope/diffsynth-studio
cvpr自动驾驶最in挑战赛赛道,全球冠军被算力选手夺走了
浪潮信息ai团队,在自动驾驶领域再夺一冠!
不久前,计算机视觉领域的顶级学术会议cvpr在全球目光注视中顺利落幕,并正式公布了最佳论文等奖项。除诞生了绝佳的10 篇论文之外,另一场备受关注的自动驾驶国际挑战赛也在同期结束了“巅峰厮杀”。
就在cvpr 2024自动驾驶国际挑战赛“occupancy & flow”赛道中,浪潮信息ai团队以48.9%的出色成绩,从全球90余支顶尖ai团队中脱颖而出,摘下桂冠。
这也是该团队在2022年、2023年登顶nuscenes 3d目标检测榜单后,面向occupancy技术的又一次实力展示。
cvpr 2024自动驾驶国际挑战赛是国际计算机视觉与模式识别会议(ieee/cvf conference on computer vision and pattern recognition)的一个重要组成部分,专注于自动驾驶领域的技术创新和应用研究。今年的cvpr自动驾驶国际挑战赛赛道设置也非常之有意思了,完整地包含了感知、预测、规划三大方向七个赛道。
此次浪潮信息ai团队所登顶的占据栅格和运动估计(occupancy & flow)赛道,也正是本届cvpr自动驾驶国际挑战赛最受关注的赛道,聚焦感知任务,吸引了全球17个国家和地区,90余支顶尖ai团队参与挑战。
比赛提供了基于nuscenes数据集的大规模占用栅格数据与评测标准, 要求参赛队伍利用相机图像信息对栅格化三维空间的占据情况(occupancy)和运动(flow)进行预测,以此来评估感知系统对高度动态及不规则驾驶场景的表示能力。
占据栅格 occupancy:挑战更精细的环境感知与预测
道路布局的复杂性、交通工具的多样性以及行人流量的密集性,是当前城市道路交通的现状,也是自动驾驶领域面临的现实挑战。为了应对这一挑战,有效的障碍物识别和避障策略,以及对三维环境的感知和理解就变得至关重要。
传统的三维物体检测方法通常使用边界框来表示物体的位置和大小,但对于几何形状复杂的物体,这种方法往往无法准确描述其形状特征,同时也会忽略对背景元素的感知。因此,基于三维边界框的传统感知方法已经无法满足复杂道路环境下的精准感知和预测需求。
occupancy networks(占据栅格网络)作为一种全新的自动驾驶感知算法,通过获取立体的栅格占据信息,使系统能够在三维空间中确定物体的位置和形状,进而有效识别和处理那些未被明确标注或形状复杂的障碍物,如异形车、路上的石头、散落的纸箱等。
这种占据栅格网络使得自动驾驶系统能够更准确地理解周围的环境,不仅能识别物体,还能区分静态和动态物体。并以较高的分辨率和精度表示三维环境,对提升自动驾驶系统在复杂场景下的安全性、精度和可靠性至关重要。
浪潮信息ai团队创赛道最高成绩
在占据栅格和运动估计(occupancy & flow)赛道中,浪潮信息ai团队以48.9%的绝佳性能表现,创下本赛道最高成绩。
具体而言,团队所提交的“f-occ”算法模型,凭借先进的模型结构设计、数据处理能力和算子优化能力,实现了该赛道最强模型性能,在rayiou(基于投射光线的方式评估栅格的占用情况)及mave(平均速度误差)两个评测指标中均获得最高成绩。
更简洁高效的模型架构,实现运算效率与检测性能双突破
首先,模型整体选择基于前向投影的感知架构,并采用高效且性能良好的flashinternimage模型。
同时,通过对整体流程进行超参调优、算子加速等优化,在占据栅格和运动估计均获得最高分的同时,提升了模型的运算效率,加快了模型迭代与推理速度。
在实际应用场景中,这种改进使得模型能够更快速、高效地处理大规模3d体素数据,使得自动驾驶车辆能更好地理解环境,进而提升决策的准确度和实时性。
更强大完善的数据处理,全面提升模型检测能力
在数据处理方面,比赛提供的体素(voxel)标签包含了大量在图像中无法观测到的点,例如被物体遮挡的体素和物体内部不可见的体素,这些标签在训练过程中会对基于图像数据的预测网络训练产生干扰。
在训练数据中,浪潮信息ai团队通过模拟lidar光束的方法,生成可视化掩码,提升了模型的预测精度;另一方面,通过引入感知范围边缘的体素点参与训练,有效解决出现在感知边缘区域的误检问题,将模型的整体检测性能提升11%。
更精细的3d体素编码,模型占据预测能力提升超5%
在3d体素特征编码模块中,该算法团队将具有较大感知范围和编码能力的可形变卷积操作应用于3d体素数据,以提升3d特征的表示能力。
通过使用cuda对可形变3d卷积(dcn3d)进行实现与优化,大幅提升了模型的运算速度,并有效降低了显存消耗。
通过dcn3d替代传统3d卷积,模型整体占据预测能力提升超5%。
此外,基于开源大模型,浪潮信息ai团队也通过优化图像encoder模型和特征融合对齐方式,并从cot(chain of thought)、got(graph of thought)、prompt工程等方面优化,提升了多模态模型对自动驾驶bev图像的感知理解能力。最终以74.2%的成绩,摘得本届cvpr自动驾驶国际挑战赛 “大语言模型在自动驾驶中的应用”(llm4ad)赛道的第五名。
2022年,浪潮信息ai团队摘得nuscenes竞赛的纯视觉3d目标检测任务(nuscenes detection task)第一名,并一举将关键性指标nds提高至62.4%。
2023年,这支团队再度夺冠,以77.6%的高分成绩再创3d目标检测全赛道最高成绩。
从bev纯视觉到bev多模态,再至如今凭借“f-occ”算法模型再度登顶cvpr 2024自动驾驶国际挑战赛, 占据栅格和运动估计任务(occupancy & flow)榜首。浪潮信息ai团队逐步探索,一路绝杀,为探索更高级别的自动驾驶技术提供了有力的支撑和经验。
赞 (0)
您想发表意见!!点此发布评论



发表评论