机器学习 | 实验四:正则化
171人参与 • 2024-08-05 • 正则表达式
📚描述
在这个练习中,你将实现正则化的线性回归和正则化的逻辑回归。
📚数据
这个数据包包含两组数据,一组用于线性回归,另一个用于逻辑回归。还包含一个名为"map_feature"的辅助函数,将用于逻辑回归。确保这个函数的m文件位于您计划编写代码的相同工作目录中。
📚正则化线性回归
本练习第一部分着重于正规线性回归和正规方程。加载数据文件"ex5linx.dat"和"ex5liny.dat",这对应你要开始的变量x和y。注意,在这个数据中,输入"x"是一个单独的特征,因此你可以将y作为x的函数绘制在二维图上:
x=load('ex5linx.dat');
y=load('ex5liny.dat');
figure
plot(x,y,'o');
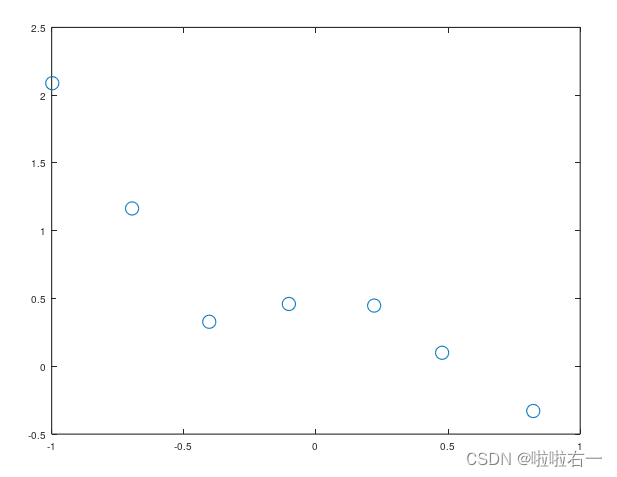
从这个图上可以看出来,拟合直线可能过于简单。相反,我们将尝试对数据拟合一个高阶多项式,以捕捉更多点的变化。我们试试五阶多项式。我们的假设是:
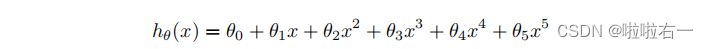
这意味着有六个特征的假设,因为 x 0 , x 1 , . . . , x 5 x_0,x_1,...,x_5 x0,x1,...,x5都是我们回归的所有特征。注意,即使我们得到了一个多项式拟合,我们仍有一个线性回归的问题,因为假设在每个特征中都是线性的。
由于我们正在将一个五阶多项式拟合到一个只有7个点的数据集上,因此很可能会发生过拟合。为了防止这种情况发生,我们将在模型中使用正则化。回想一下,在正则化问题中,目标是最小化以下关于θ的成本函数:
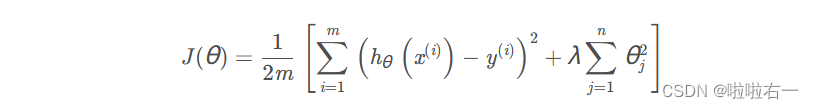
式中,λ为正则化参数。正则化参数λ是对拟合参数的控制。随着拟合参数大小的增加,对代价函数的惩罚也会增加。这个惩罚取决于参数的平方以及λ的大小。另外,请注意,λ求和不包括 θ 0 2 θ_0^2 θ02。
现在,我们将使用正规方程找到模型的最佳参数。回想一下正则化线性回归的正规方程解是:
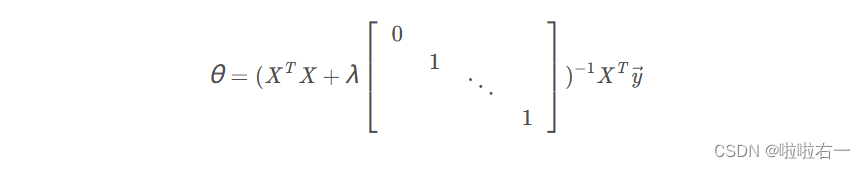
跟在 λ后的矩阵是一个左上角一个0和剩余对角线元素为1的对角(n+1)×(n+1)矩阵(记住,n是特征的数量)。向量 y和矩阵 x 对于非正则回归有相同的定义。使用这个方程,找出使用以下三个正则化参数 θ 的值: λ=0,λ = 1,λ = 10
x = load('ex5linx.dat');
y = load('ex5liny.dat');
figure
plot(x,y,'o');
hold on
m = length(y);
x = [ones(m,1),x,x.^2,x.^3,x.^4,x.^5];
theta = zeros(6,3);
t = diag([0 1 1 1 1 1]);
lamda = [0,1,10];
for i = 1:3
theta(:,i) = inv(x'*x+lamda(i)*t)*x'*y;
end
x = linspace(-1,1,100)';
x = [ones(100,1),x,x.^2,x.^3,x.^4,x.^5];
plot(x(:,2), x*theta(:,1),'--r');
hold on
plot(x(:,2), x*theta(:,2),'--b');
hold on
plot(x(:,2), x*theta(:,3),'--g');
hold on
legend('training data','lamda = 0','lamda = 1','lamda = 10');
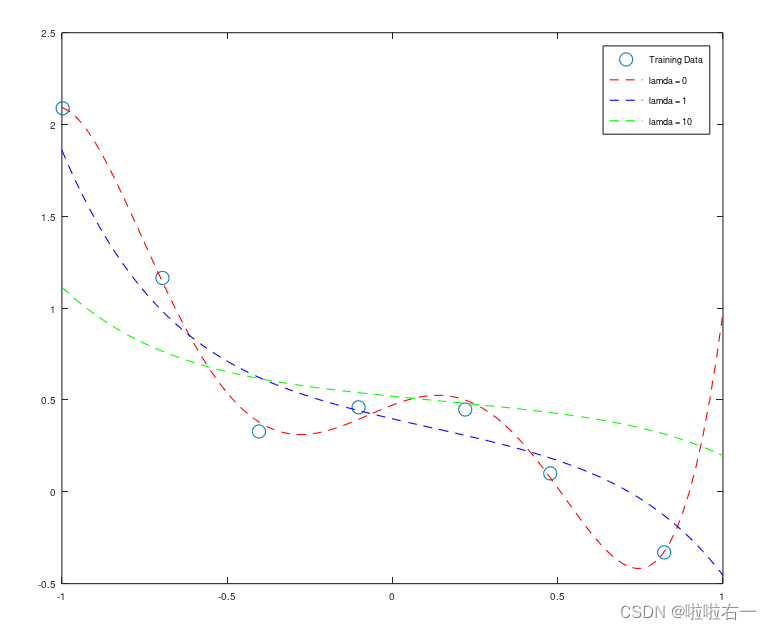
⭐通过查看这些图表,您可以得出关于正则化参数λ如何影响您的模型的什么结论?
- λ = 0的时候曲线会出现过拟合现象,而 λ = 0 对应的是非正则化的线性回归。对比 λ = 1 和 λ = 10,会发现 λ = 10时曲线偏离数据点比较严重,即发生了欠拟合现象。
- λ越大,曲线拟合效果越差。当 λ 比较小时,惩罚太小,导致曲线的过拟合度依旧很高;随着 λ 的值增大,拟合出来的曲线会渐渐波动性下降,同时在训练集上的拟合度会稍有下降,但会防止过拟合现象的发生;如果 λ 太大,会导致曲线最后无限逼近于常数项系数θ ,成为一条平稳的直线,以至于欠拟合。
📚正则化逻辑回归
在本练习的第二部分中,您将使用牛顿法实现正则化的逻辑回归。首先,将文件“ex5logx.dat”和“ex5logy.dat”加载到程序中。该数据集表示具有两个特征的逻辑回归问题的训练集。为了避免以后的混淆,我们将把包含在“ex5logx.dat”中的两个输入特性称为u和v。所以在“ex5logx.dat”文件中,第一列数字代表特征u,你将在横轴上绘制,第二个特征代表v,你将在纵轴上绘制。加载数据后,使用不同的标记绘制点,以区分两种分类。
x = load('ex5logx.dat');
y = load('ex5logy.dat');
figure
%find the indices for the 2 calsses
pos = find(y == 1); neg = find(y == 0);
plot(x(pos,1),x(pos,2),'+');
hold on
plot(x(neg,1),x(neg,2),'o');
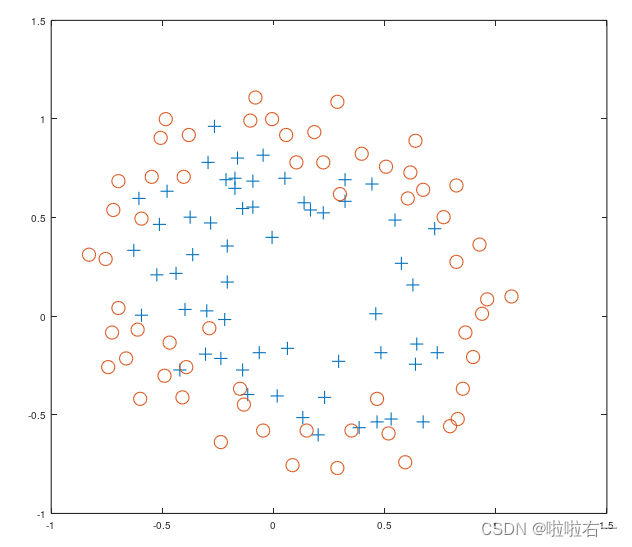
我们现在将对这个数据拟合一个正则化的回归模型。回想一下,在逻辑回归中,假设函数是:
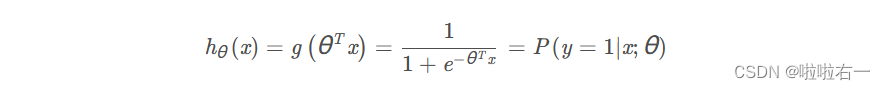
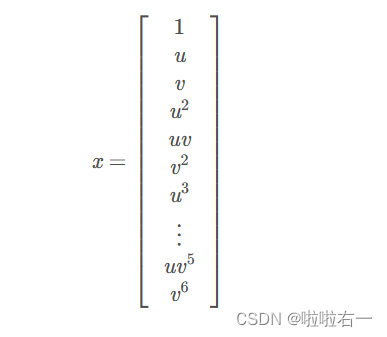
在这个练习中,我们将把x赋值为u和v的所有单项式(即多项式3项),直到第六次幂:
为了避免枚举所有 x 项的麻烦,我们包含了一个辅助函数,“map_feature”,它将原始数据映射到特征向量。这个函数使用于单个训练示例,也适用于整个训练示例。为了使用这个函数,将"map_feature.m"放在你的工作目录中
x = map_feature(u,v)
在建立这个模型之前,回想一下我们的目标是最小化正则化逻辑回归的最小代价函数:
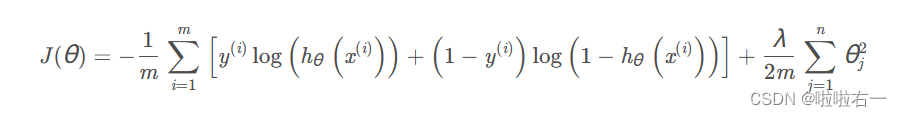
这看起来像是非正则化逻辑回归的成本函数,除了在最后有一个正则化项。我们现在将用牛顿的方法来最小化这个函数。回想一下,牛顿方法的更新规则是:
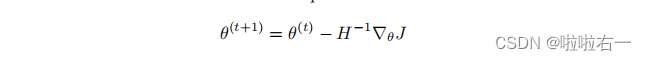
这与非正则化逻辑回归的规则相同。但是因为你现在正在实现正则化,梯度∇θ(j)和hessian h有不同的形式:
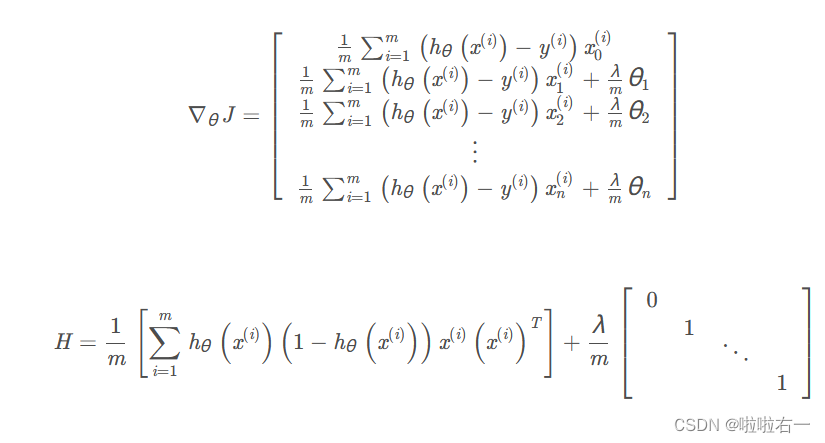
现在在这个数据集上使用如下的 λ值运行牛顿法:λ=0,λ = 1,λ = 10
收敛后,用θ的值找出分类问题中的决策边界。决策边界定义为其中的直线

x = load('ex5logx.dat');
y = load('ex5logy.dat');
figure
pos = find(y); neg = find(y == 0);
plot(x(pos, 1), x(pos, 2), '+');
hold on;
plot(x(neg, 1), x(neg, 2), 'o');
u = x(:, 1); v = x(:, 2);
x = map_feature(u, v);
m = length(y);
lamda = 10; %lamda修改处
g = inline('1.0 ./ (1.0 + exp(-z))');
t = eye(28, 28); t(1, 1) = 0;
theta = zeros(28, 1);
eps = 10^-6;
h = g(x * theta);
l(1) = 0;
l(2) = (1 / m) .* sum(-y .* log(h) - (1 - y) .* log(1 - h));
cnt = 2;
while abs(l(cnt) - l(cnt - 1)) > eps
cnt = cnt + 1;
h = (1 / m) .* x' * diag(h) * diag(1 - h) * x + (lamda / m) * t;
theta_j = theta; theta_j(1, 1) = 0;
theta = theta - h \ ((1 / m) * x' * (h - y) + (lamda / m) * theta_j);
h = g(x * theta);
l(cnt) = (1 / m) .* sum(-y .* log(h) - (1 - y) .* log(1 - h)) + (lamda / (2 * m)) * sum(theta .* theta);
end
hold on
u = linspace(-1, 1.5, 200);
v = linspace(-1, 1.5, 200);
z = zeros(length(u), length(v));
for i = 1:length(u)
for j = 1:length(v)
z(j, i) = map_feature(u(i), v(j)) * theta;
end
end
z = z';
contour(u, v, z, [0, 0], 'linewidth', 2);
figure;
plot(1:cnt - 1, l(2: cnt), 'o-')
norm(theta)
⭐️下图表示grid 图与决策边界和损失函数与迭代次数关系
λ=0
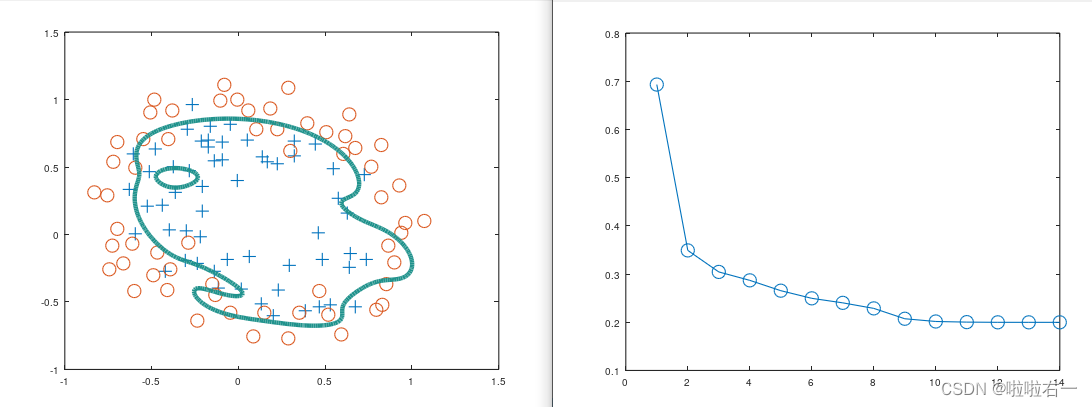
λ=1
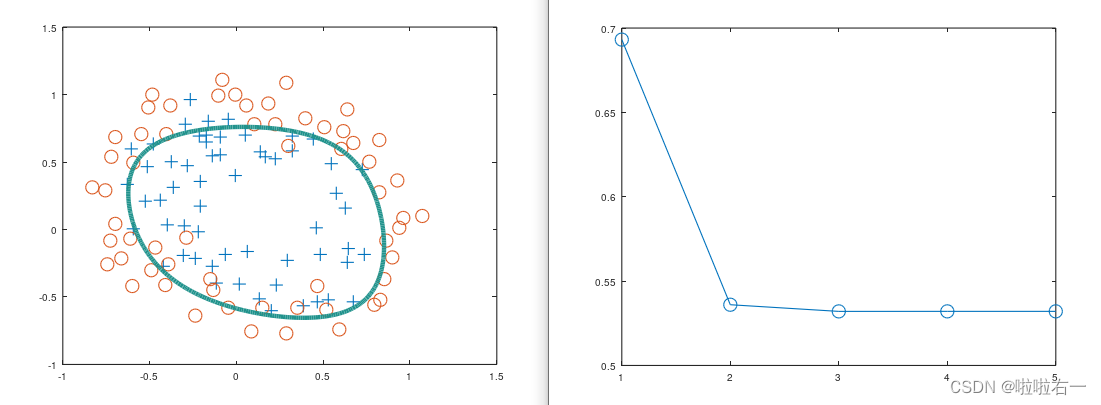
λ=10
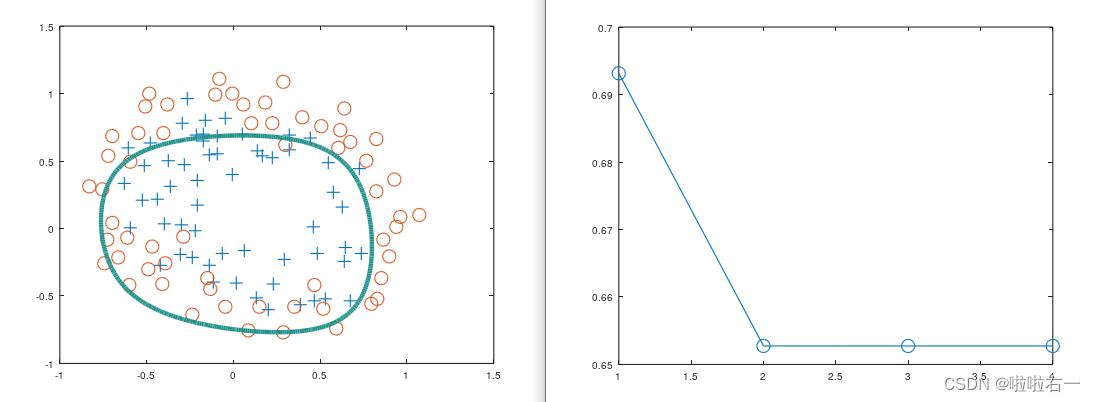
⭐️λ如何影响结果?
从以上三张图可以看出惩罚越大,其精度、查准率和查全率越低,曲线会逼近于正则化项的圆形边界,但收敛速度会越快。对比λ取0、1、10的情况,某种程度上说,λ=1是比较合适的,既保证了精度、查准率和查全率相对较高,又提高了模型的泛化能力,一定程度上缓解了过拟合。
赞 (0)
打赏
 微信扫一扫
微信扫一扫
微信扫一扫
您想发表意见!!点此发布评论




发表评论