【机器学习】集成学习:使用scikitLearn中的BaggingClassifier实现bagging和pasting策略
536人参与 • 2024-08-06 • Bootstrap
集成学习导航:决策树与随机森林
【机器学习】使用scikitlearn进行决策树分类与回归:decisiontreeclassifier及decisiontreeregressor
【机器学习】集成学习:使用scikitlearn中的votingclassifier综合多个不同模型进行软硬投票
【机器学习】集成学习:使用scikitlearn中的randomforestclassifier及randomforestregressor实现随机森林
【机器学习】集成学习:scikitlearn实现adaboost及梯度提升gradientboosting,及xgbt库
1.当所集成的若干模型对应的训练算法相同,但每个模型是在训练集上的不同随机子集上训练使,对应的集成学习策略叫做bagging和pasting。
2.进一步,bagging和pasting的区别是,bagging是放回的采样,在训练某一预测模型时,允许多次使用同一样本。bagging和pasting均允许不同的模型训练时采样同一实例。
3.待所有模型的训练都完成后,采用硬投票类似的统计法用于分类,采用取平均的方法应用于回归任务。这种方法也可以叫做是聚合,经聚合后,偏差(由于使用的是相同算法训练的模型)相近或更低,方差显著降低。
对于决策树来讲,它属于无参模型,特别容易出现过拟合,此时采用集成学习,可以达到减少其方差的目的。
4.其优势在于,可以应用于cpu并行的进行训练以及预测,最后再将结果进行聚会。
其代码如下:
from sklearn.ensemble import baggingclassifier
from sklearn.tree import decisiontreeclassifier
bag_clf = baggingclassifier(
decisiontreeclassifier(), n_estimators=500,
max_samples=100, bootstrap=true, random_state=42)
bag_clf.fit(x_train, y_train)
y_pred = bag_clf.predict(x_test)
上述代码集成了500棵决策树的预测结果,每次训练模型随机采样100个实例进行训练,当预测模型自身带有可供概率预测的方法时,如含predict_proba()方法时,baggingclassifier分类器将做软投票,否则使用硬投票的方法完成分类。当想使用pasting时,在上述代码中设置bootstrap=false即可。
当训练样本为2维时(这里使用的是月亮数据集),下面提供的代码可供绘制预测的边界:
from matplotlib.colors import listedcolormap
def plot_decision_boundary(clf, x, y, axes=[-1.5, 2.45, -1, 1.5], alpha=0.5, contour=true):
#等距划分x及y轴的数据,分割成网
x1s = np.linspace(axes[0], axes[1], 100)
x2s = np.linspace(axes[2], axes[3], 100)
x1, x2 = np.meshgrid(x1s, x2s)
#拉直,降维
x_new = np.c_[x1.ravel(), x2.ravel()]
y_pred = clf.predict(x_new).reshape(x1.shape)
#定义颜色地图
custom_cmap = listedcolormap(['#fafab0','#9898ff','#a0faa0'])
#该函数绘制带填充的等高线,由于最终分成2类,所以是两种颜色填充
plt.contourf(x1, x2, y_pred, alpha=0.3, cmap=custom_cmap)
if contour:
custom_cmap2 = listedcolormap(['#7d7d58','#4c4c7f','#507d50'])
plt.contour(x1, x2, y_pred, cmap=custom_cmap2, alpha=0.8)
plt.plot(x[:, 0][y==0], x[:, 1][y==0], "yo", alpha=alpha)
plt.plot(x[:, 0][y==1], x[:, 1][y==1], "bs", alpha=alpha)
plt.axis(axes)
plt.xlabel(r"$x_1$", fontsize=18)
plt.ylabel(r"$x_2$", fontsize=18, rotation=0)
调用绘图处:
fig, axes = plt.subplots(ncols=2, figsize=(10,4), sharey=true)
plt.sca(axes[0])
plot_decision_boundary(tree_clf, x, y)
plt.title("decision tree", fontsize=14)
plt.sca(axes[1])
plot_decision_boundary(bag_clf, x, y)
plt.title("decision trees with bagging", fontsize=14)
plt.ylabel("")
plt.show()
绘制最终结果为:
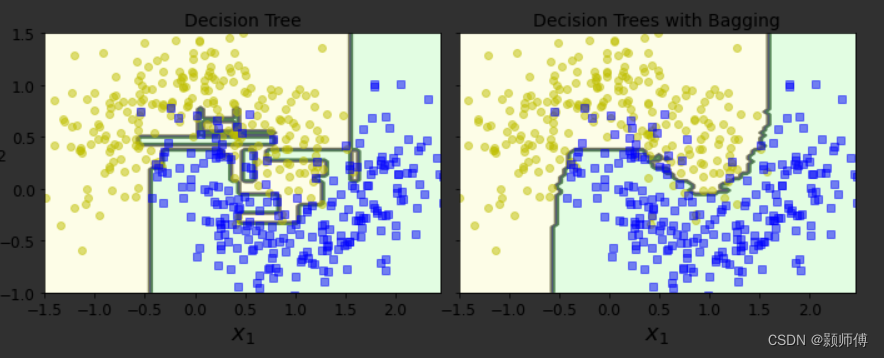
可以看到右图中,经过集成学习后,模型的方差要好很多。
特别注意,当使用bagging时,由于抽样后被放回(bootstrap=true),有些实例被放回,而有些实例从未被使用,这部分实例比例固定约占30%,这部分未被使用实例被称为“包外实例”,可使用这部分实例进行包外评估,代替测试集对模型进行评估。其代码如下:
bag_clf = baggingclassifier(
decisiontreeclassifier(), n_estimators=500,
bootstrap=true, oob_score=true, random_state=40)
bag_clf.fit(x_train, y_train)
#打印出包外分数
bag_clf.oob_score_
baggingclassifier类也支持对特征进行采样。由两个超参数控制:max_features和bootstrap_features。它们的工作方式与max_samples和bootstrap相同,但用于特征采样而不是实例采样。因此,每个预测器将用输入特征的随机子集进行训练。
当保留所有训练实例,但是对特征进行抽样,这种方法叫随机子空间法,代码如下:
from sklearn.ensemble import baggingclassifier
from sklearn.tree import decisiontreeclassifier
bag_clf = baggingclassifier(
decisiontreeclassifier(), n_estimators=500,
#每次取全部样本训练
max_samples=1.0, bootstrap=false, random_state=42,bootstrap_features=true,
#当特征数很多时,固定抽取0.5的特征进行训练
max_features=0.5)
bag_clf.fit(x_train, y_train)
y_pred = bag_clf.predict(x_test)
赞 (0)
您想发表意见!!点此发布评论



发表评论