【计算机视觉】万字长文详解:卷积神经网络
530人参与 • 2024-08-06 • 神经网络

以下部分文字资料整合于网络,本文仅供自己学习用!
一、计算机视觉概述
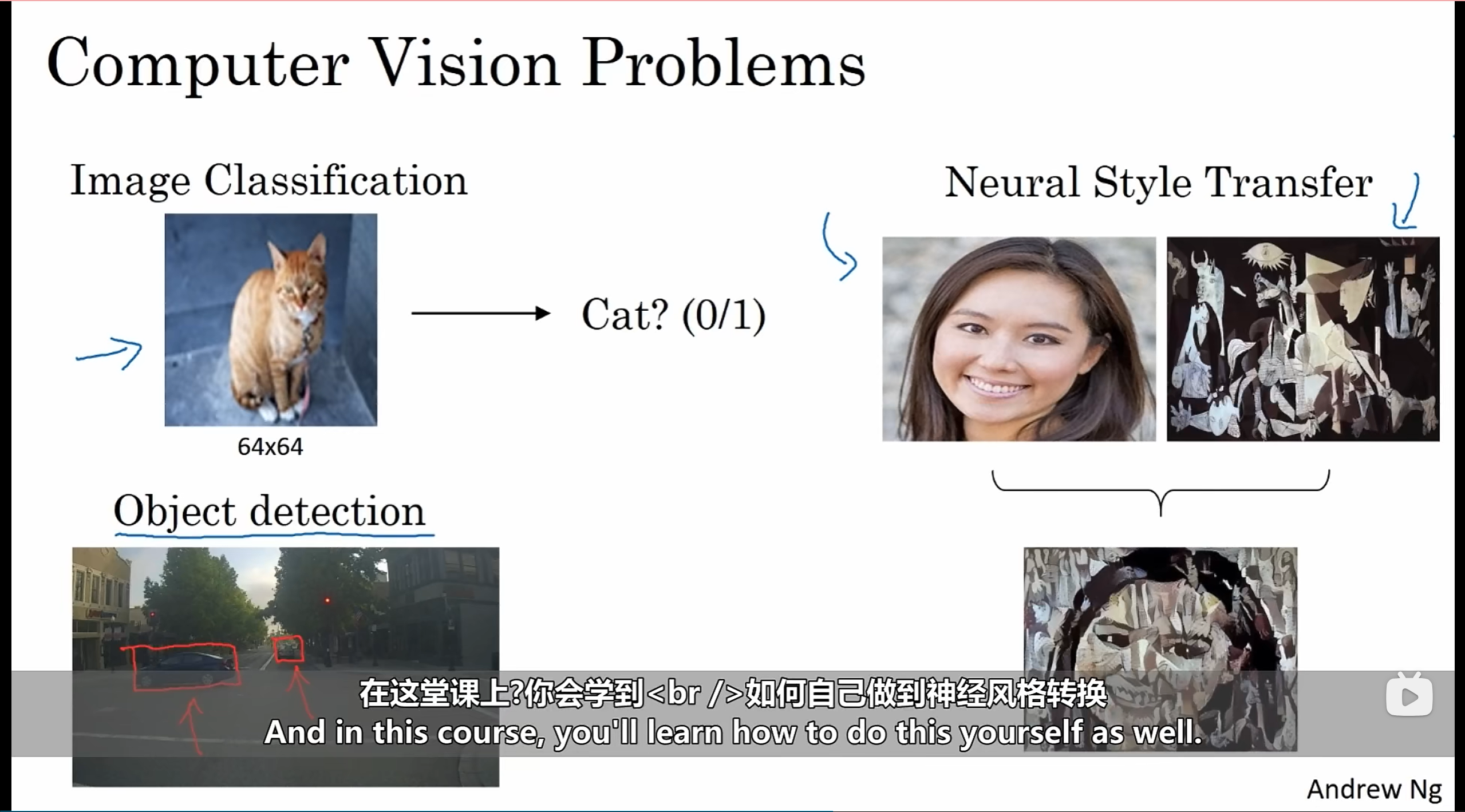
如果输入层和隐藏层和之前一样都是采用全连接网络,参数过多会导致过拟合问题,其次这么多的参数存储下来对计算机的内存要求也是很高的

解决这一问题,就需要用到——卷积神经网络
二、卷积神经网络
2.1:卷积运算
卷积运算是卷积神经网络的基本组成单元之一
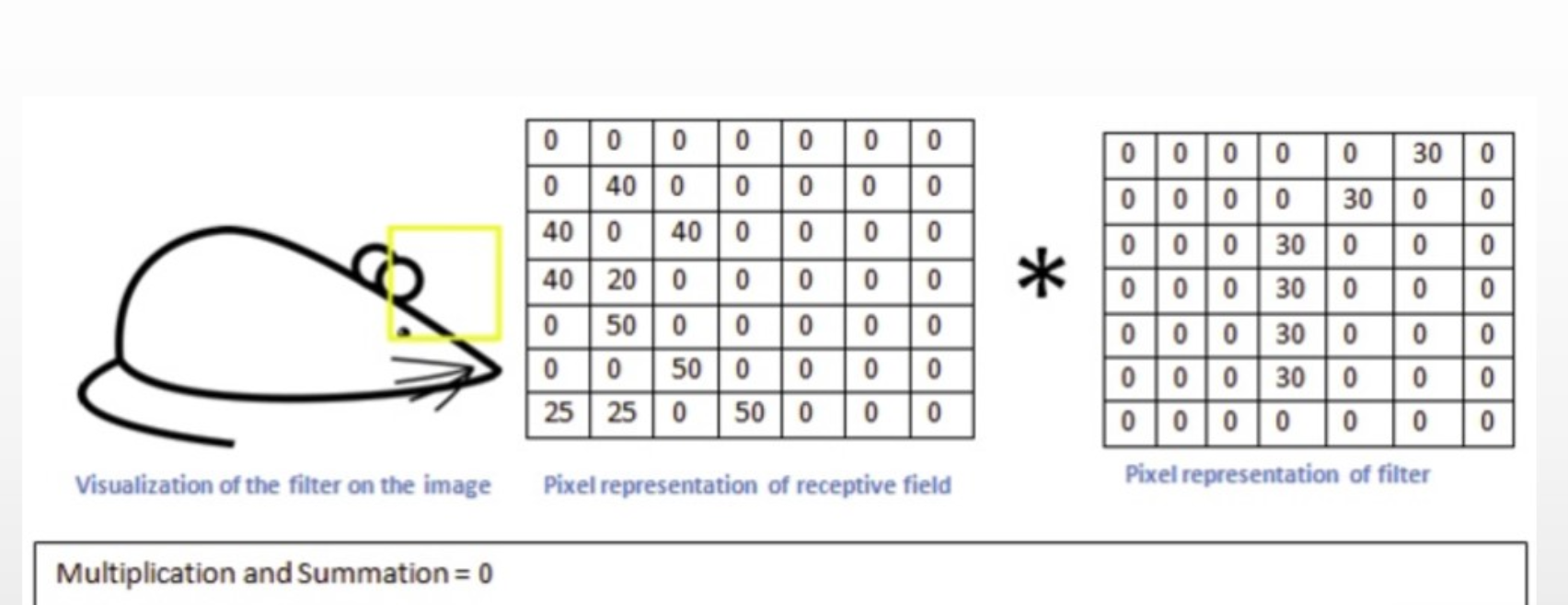
这里将从边缘检测(edge detection)入手,举例来介绍卷积神经网络
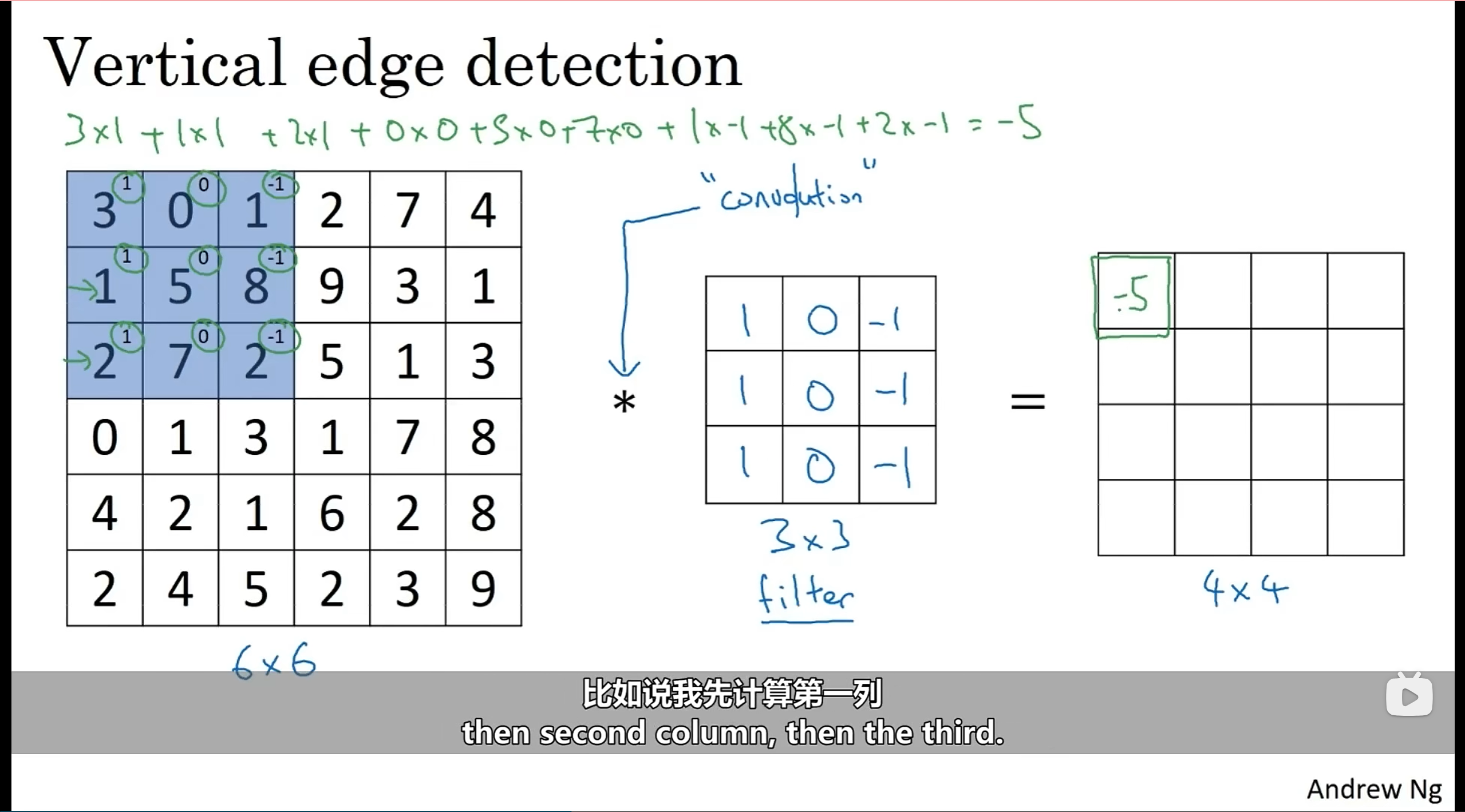
通过这种卷积运算,我们可以检测到图像的边缘:(我们把中间的3x3的矩阵称为:过滤器、边缘检测器、卷积核
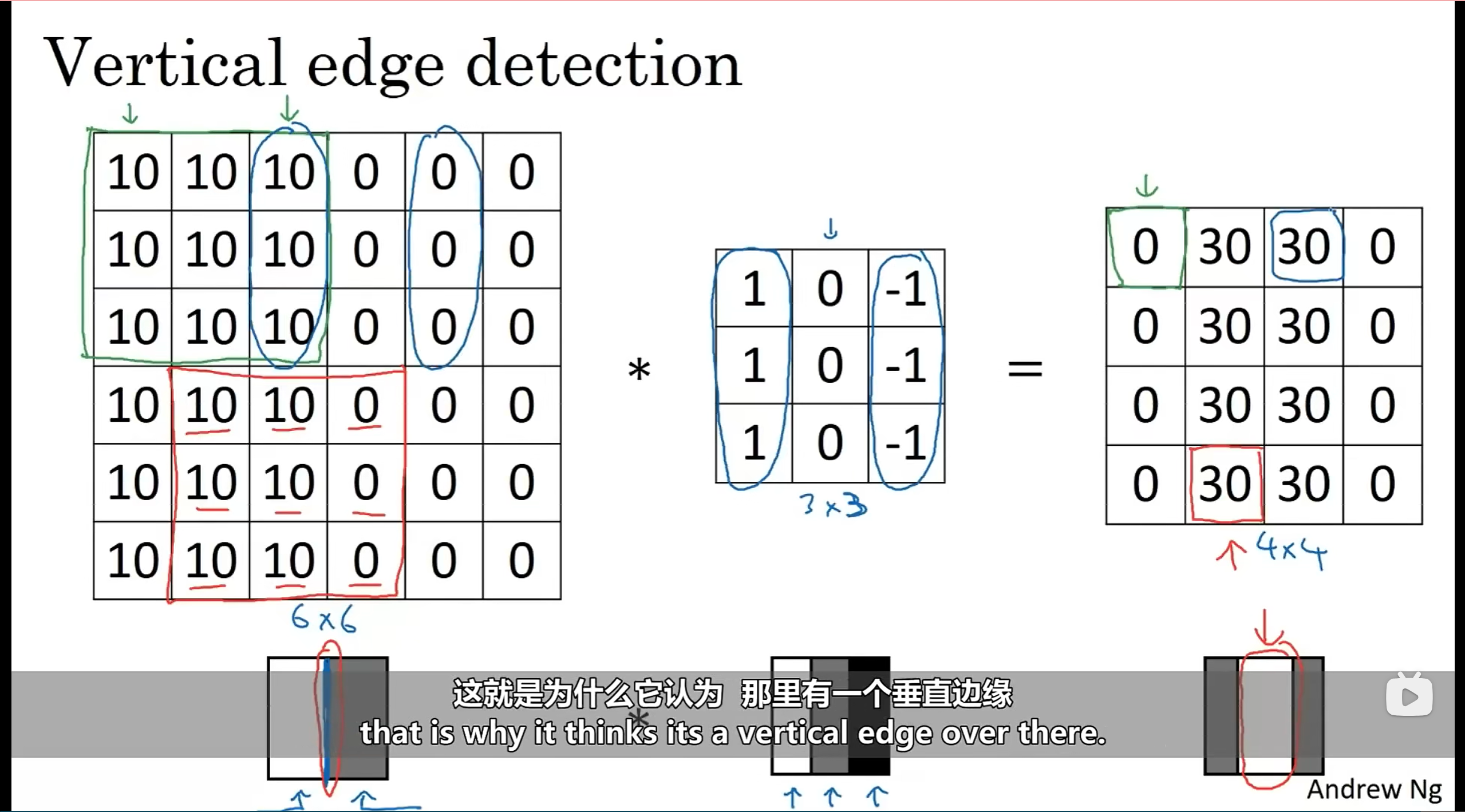
下面来讲,如何将这种卷积运算作为基本单元,运用到卷积神经网络中。
-
正边缘(positive edges)和负边缘(negative edges):由亮变暗和由暗变亮
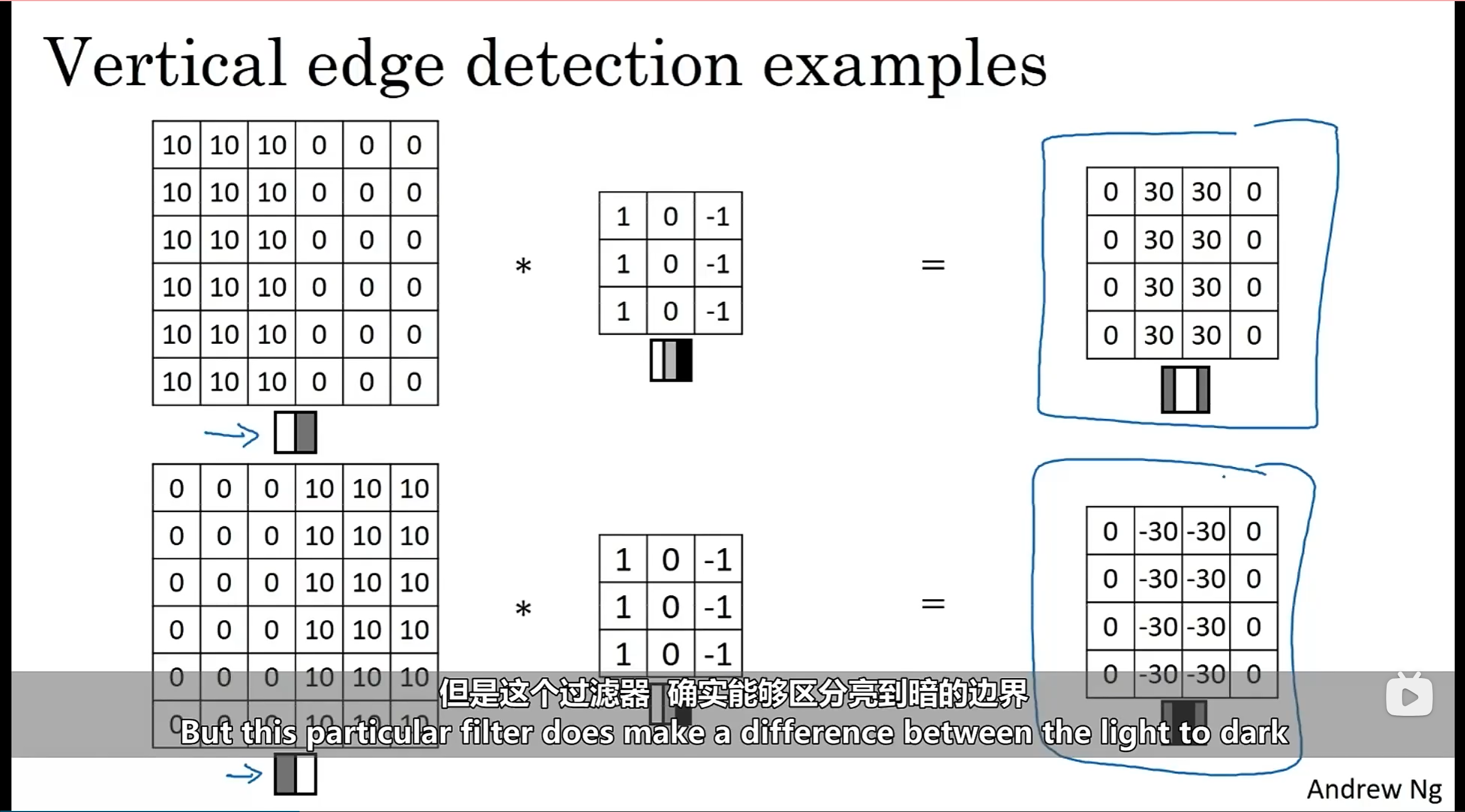
-
其他的边缘检测器(卷积核)

-
如何让算法自己学习得到边缘检测器,而不是像上面那样手动设计(传统的计算机视觉)——卷积神经网络
🦄原理就是把卷积核中的数看作参数,利用反向传播(back propagation)去学习
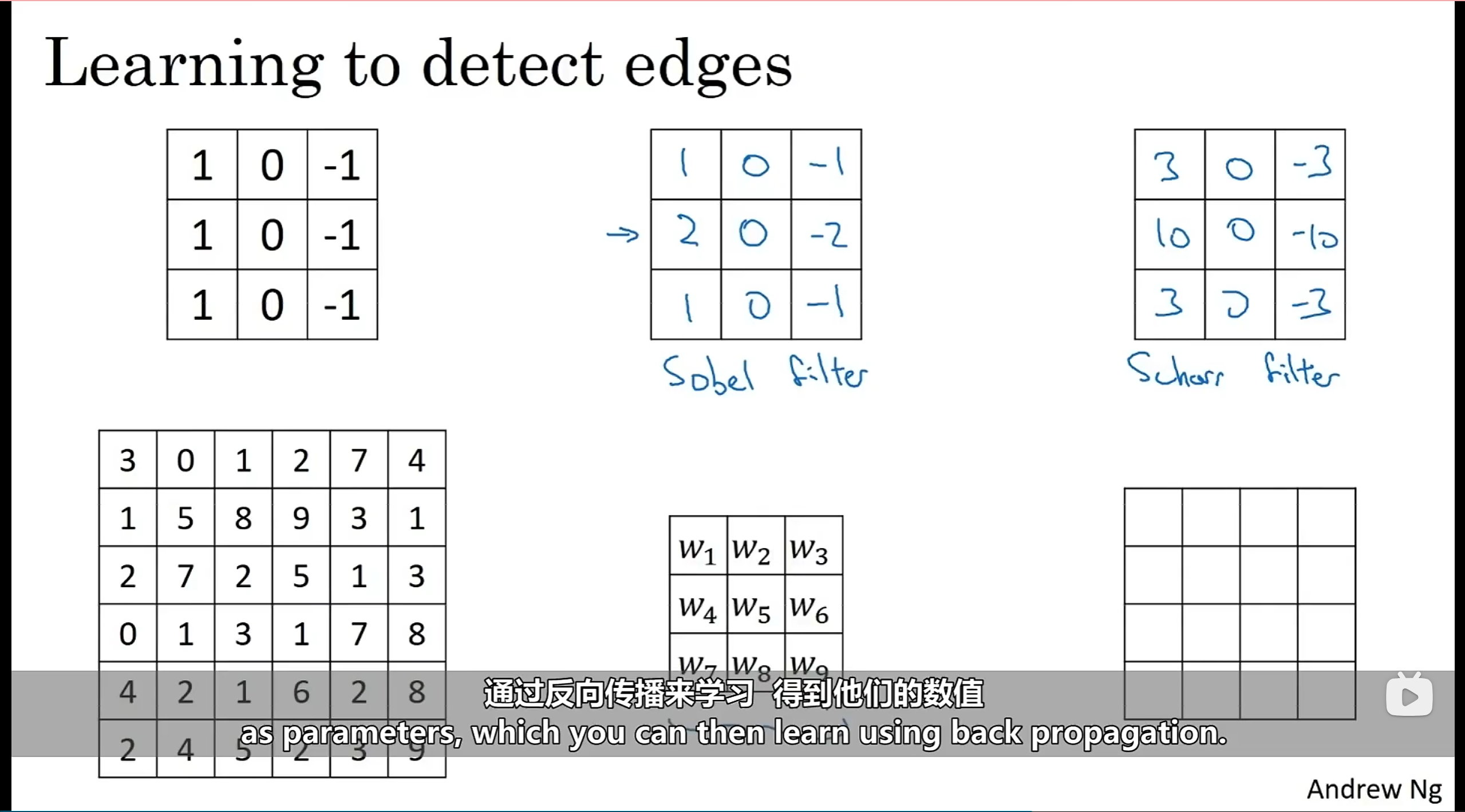
这种学习得到的卷积核,会比计算机视觉研究人员所精心选择的更加稳定
在具体讲如何利用反向传播来学习得到卷积核的这9个参数之前,让我们学习一下卷积神经网络——卷积计算的底层架构的非常重要的组成部分
2.1.1:填充(padding)
首先看不对图像做填充的情况:
即:nxn的图像和fxf的卷积核进行卷积,得到结果大小为:(n-f+1)x(n-f+1)
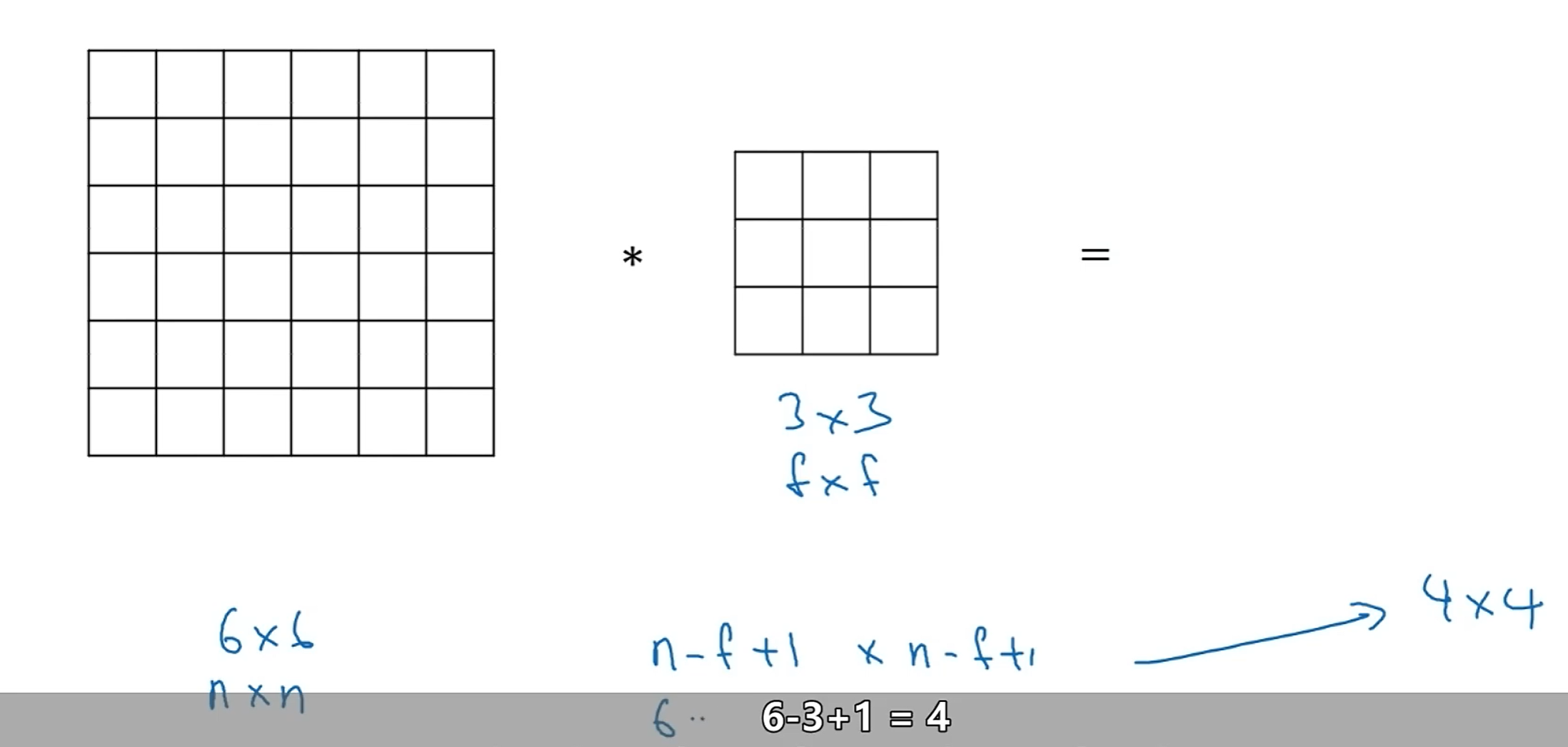
💐这样卷积的缺点有:
- shrinky output:这样得到的卷积结果会比原图像小,而没通过一层这样的卷积,图像就会缩小,在深层卷积神经网络中,最后得到的图像就会非常的小
- throw away info from the edge:丢失边缘像素的信息。即对比于图像中其他像素提供的信息,边缘像素在卷积过程中只被利用一次或少次,这样我们会丢失掉一些边缘信息。
所以为了解决这两个问题,使用填充,对原图像进行像素填充
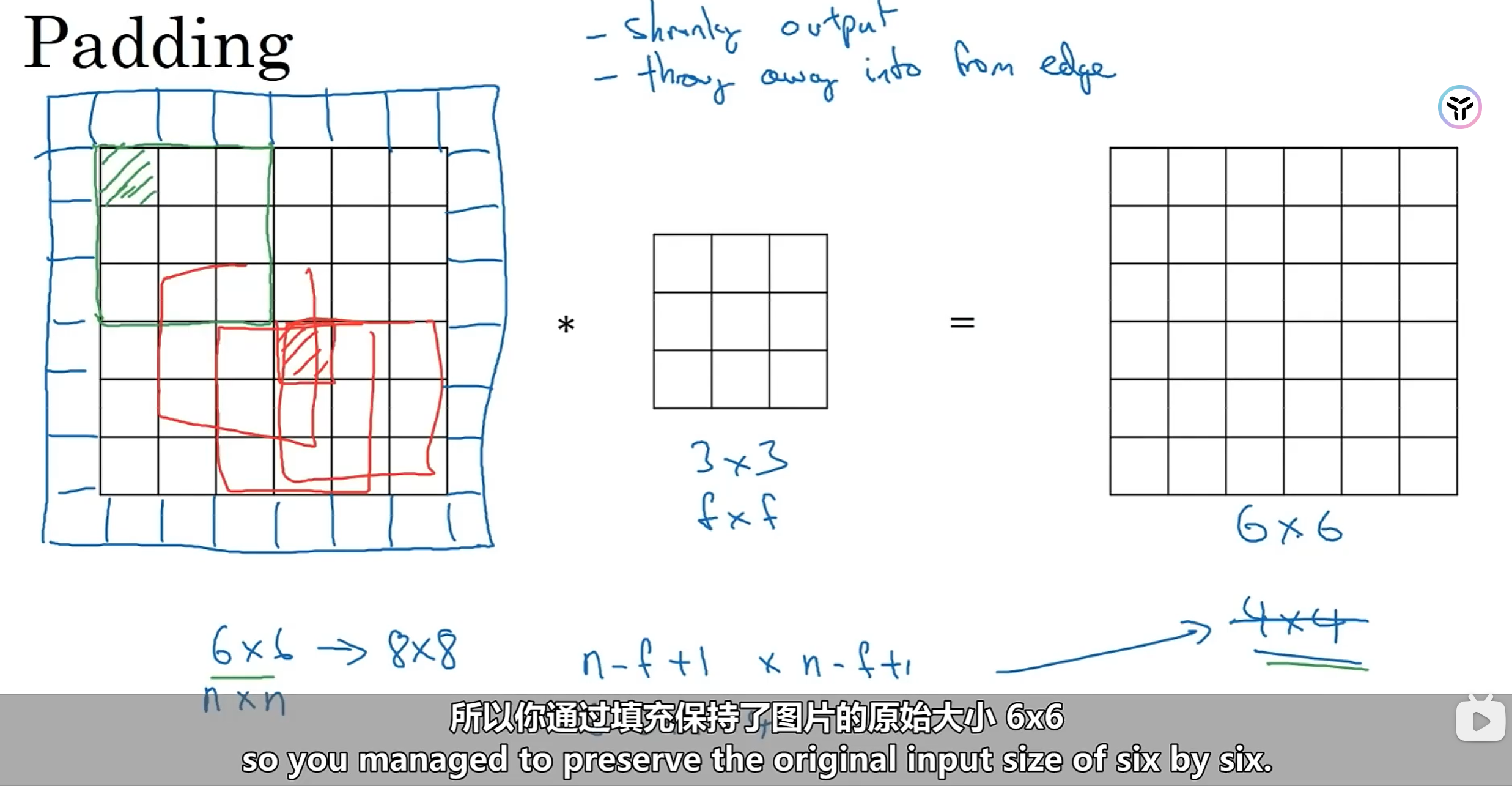
总结一下,上面其实涉及到两种常用卷积:
- valid convolutions:即不对原图像进行任何填充
- same convolutions:对原图像进行填充并且保证卷积结果图像和原图像大小相同

由上图可知,对于same convolutions,我们通常需要保证卷积核fxf的f为奇数时,才可保证p = (f-1)/2,使得卷积结果大小与原图像大小相同。这也解释了为什么通常我们所使用的卷积核大小都是3x3和5x5。另外一个原因是,当卷积核是奇数时,会有一个中心像素点,事实上对图像进行卷积时,这个特殊的中心像素点是不可或缺的(你可以试想一下如果卷积核是偶数,你该如何卷积),中心像素可以很好的描述卷积核的位置,使用奇数的卷积核这也是计算机视觉所约定俗成的一种传统。
2.1.2:步长(stride)
上文所讲到的,也是默认卷积运算中步长为1,事实上,步长也是可以设定的。和padding一样,步长不同,也会影响卷积结果。下图是设置步长为2时的卷积示例
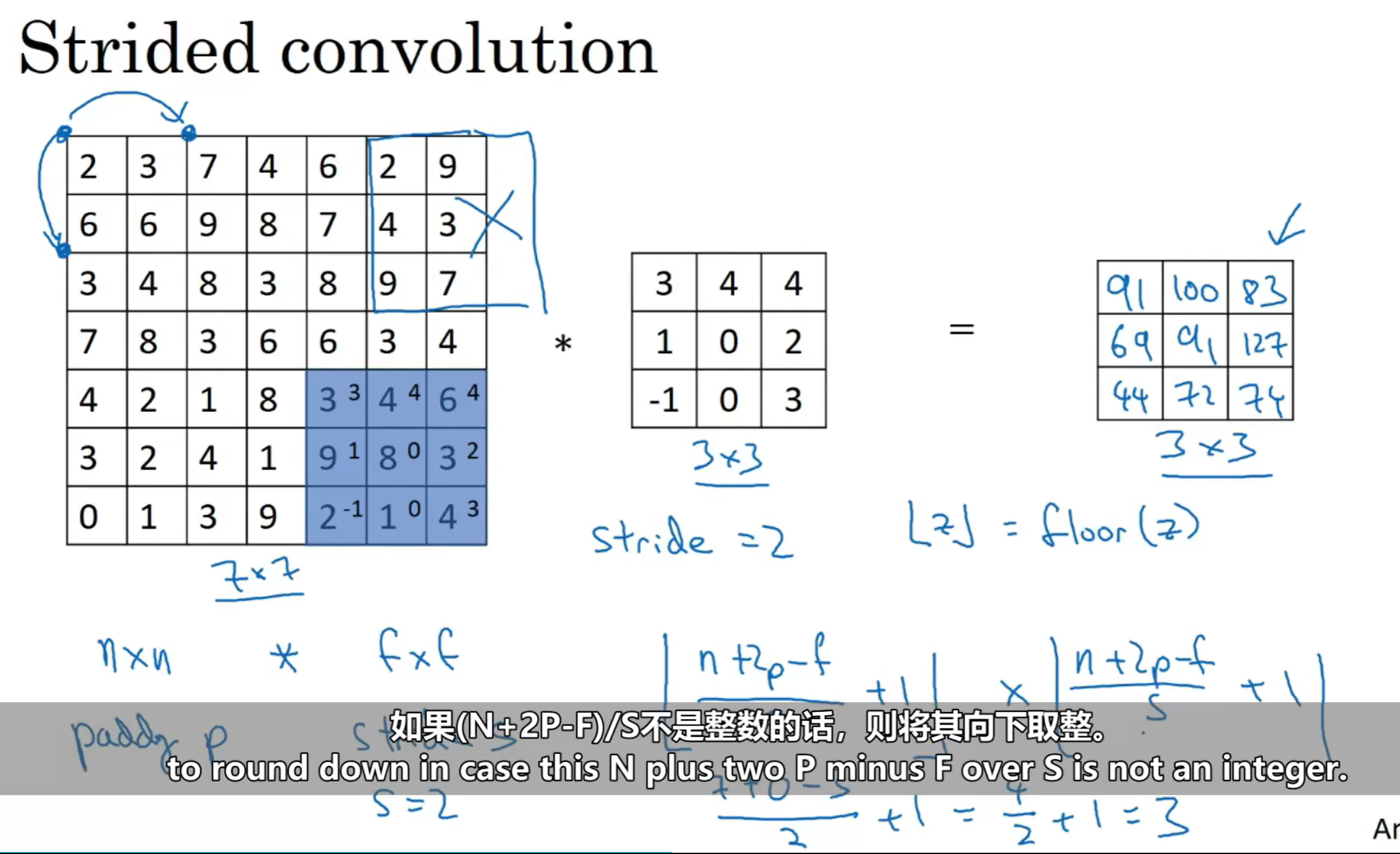
总结一下:(注意,这里的向下取整的实际含义是,保证卷积核始终在原图像填充后的那个图像中,而不能超出)

2.1.3:交叉相关(cross-correlation)
这一小节其实是一个概念补充。事实上学过数字信号处理的话,对于图像卷积(图像其实就是一个2维的数字信号),会将卷积核进行翻转后,再进行元素相乘、相加。事实上在计算机视觉领域,省略了翻转这一步骤,而是直接进行相乘、相加,所以在数学领域会将其称为交叉相关(corss-correlation),但是在深度学习和计算机视觉及其相关文献中,通常还是会将其称为卷积(convolutions).

2.1.4:3维卷积
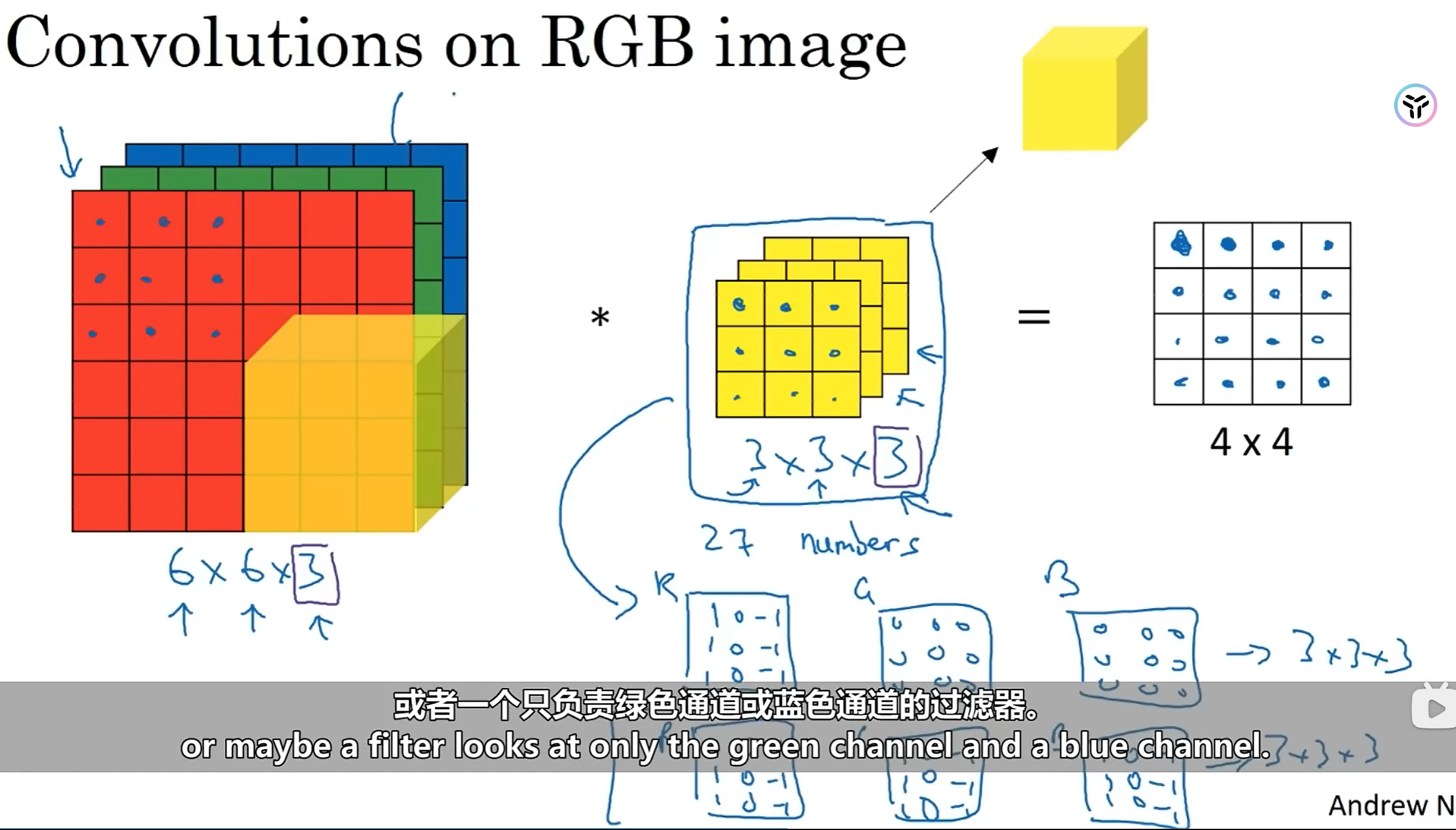
事实上,上面所讲到的卷积都是对于2维图像而言(也就是灰度图),也成为二维卷积。而对于包含rgb这种三维图像,则属于三维卷积

但是你可能和我一样有相同的疑问:这有什么用呢?得到的结果还是二维
像下图展示这样,通过设置3d卷积核不同通道的参数值,你可以选择只检测红色通道的边缘,同时把其他通道的卷积核的参数值设置为0.或者只是把三个通道的卷积核参数设置为一样,这样的意义在于即使输入进来的是rgb图像也可以不用将其转为灰度图像而直接进行卷积计算(效果也是一样的)。
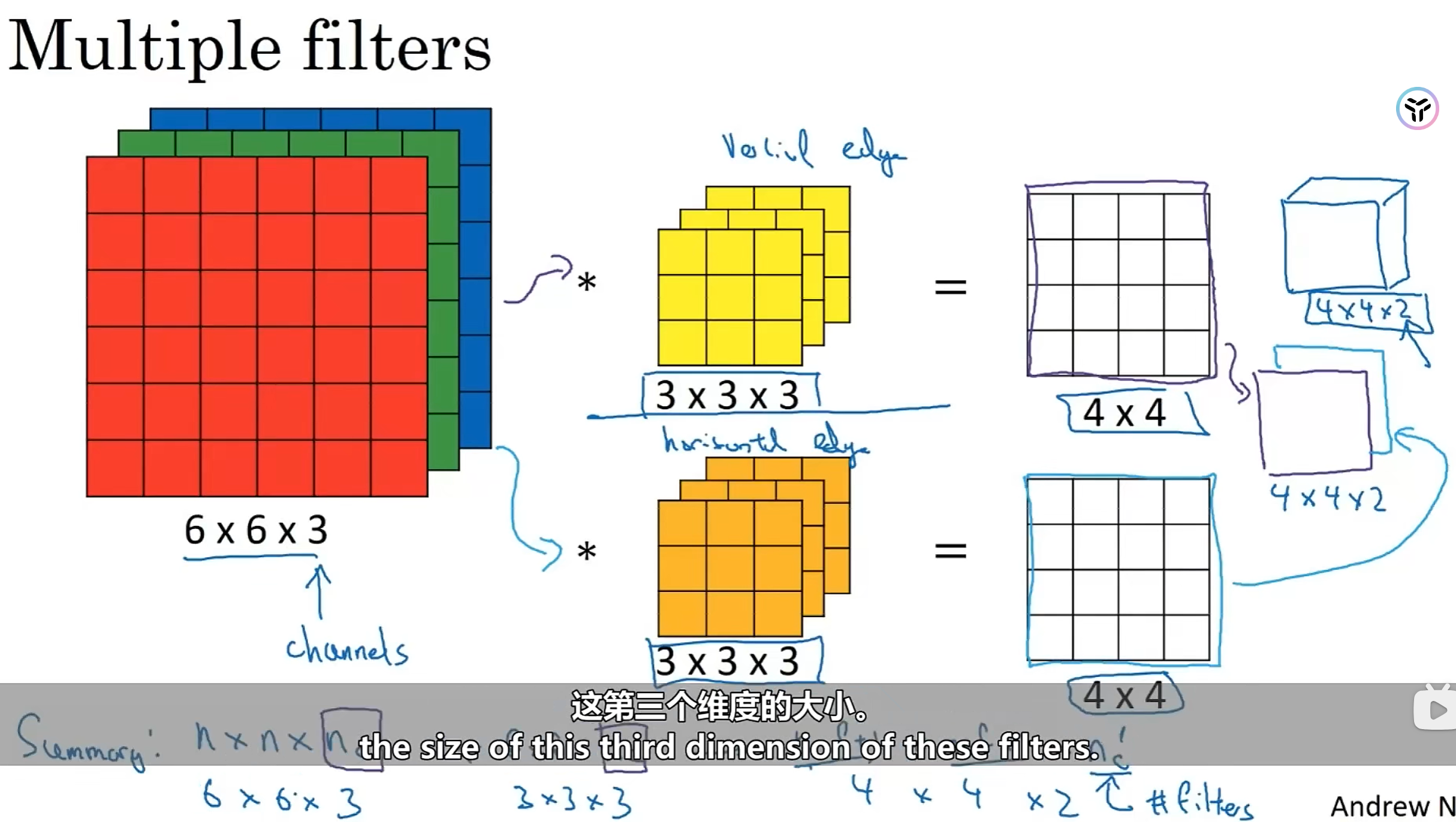
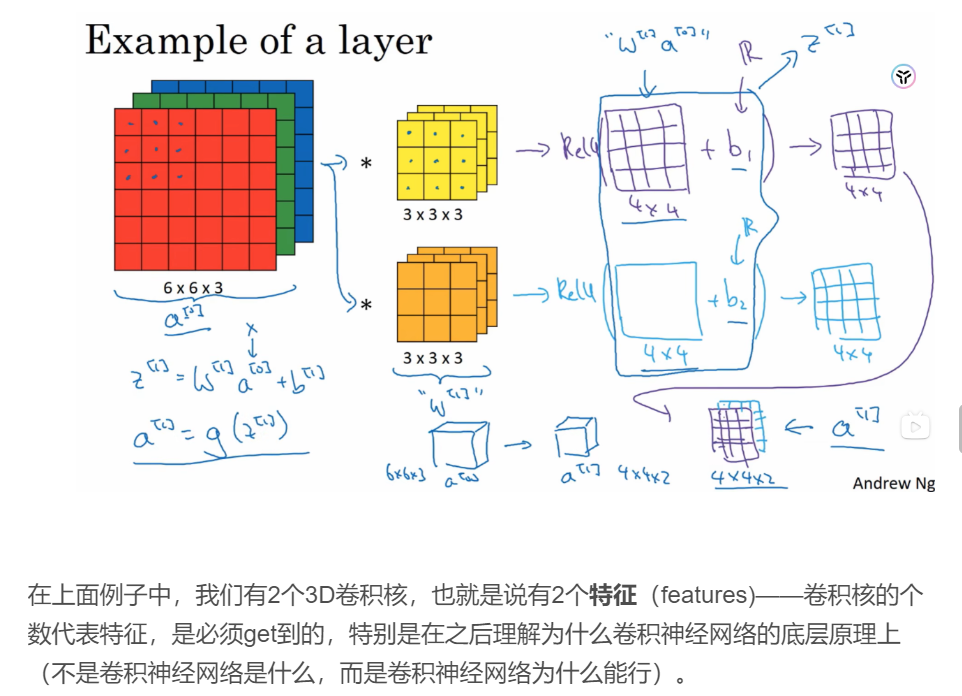
还有一个问题,就是:上文中,我们只是单单检测一种边缘——垂直。如果想同时检测多种边缘呢?比如同时检测水平和竖直边缘。那么我们需要多个检测器,或者说多个3d卷积核、过滤器,就像下图这样。但是注意到,得到的卷积结果的第三维度的大小就是使用的3d卷积核的个数。
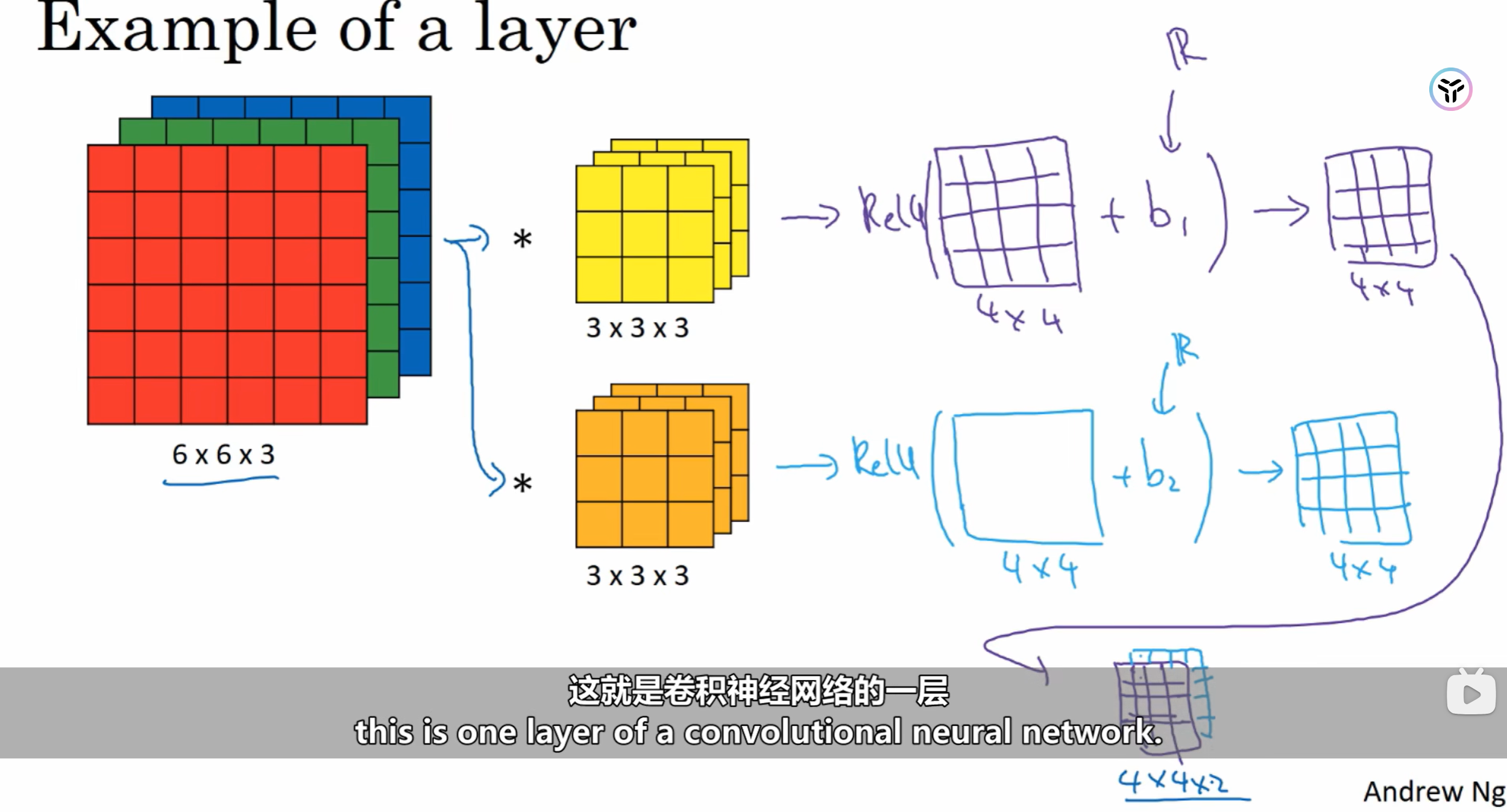
2.2:卷积网络的一层
对卷积结果进行每个元素相加偏差b,并对其进行非线性变化,再对各个3d卷积核得到的结果进行整合于是得到4x4x2的一层卷积网络的输出结果。
2.2.1:和传统神经网络的对比
其实过程还是一致的
- 首先进行线性运算,将输入a[0]和参数w(对应的就是卷积核)进行相乘再相加
- 再加上偏差
b - 最后通过激活函数(即进行非线性变换)

在上面例子中,我们有2个3d卷积核,也就是说有2个特征(features)——卷积核的个数代表特征,是必须get到的,特别是在之后理解为什么卷积神经网络的底层原理上(不是卷积神经网络是什么,而是卷积神经网络为什么能行)。
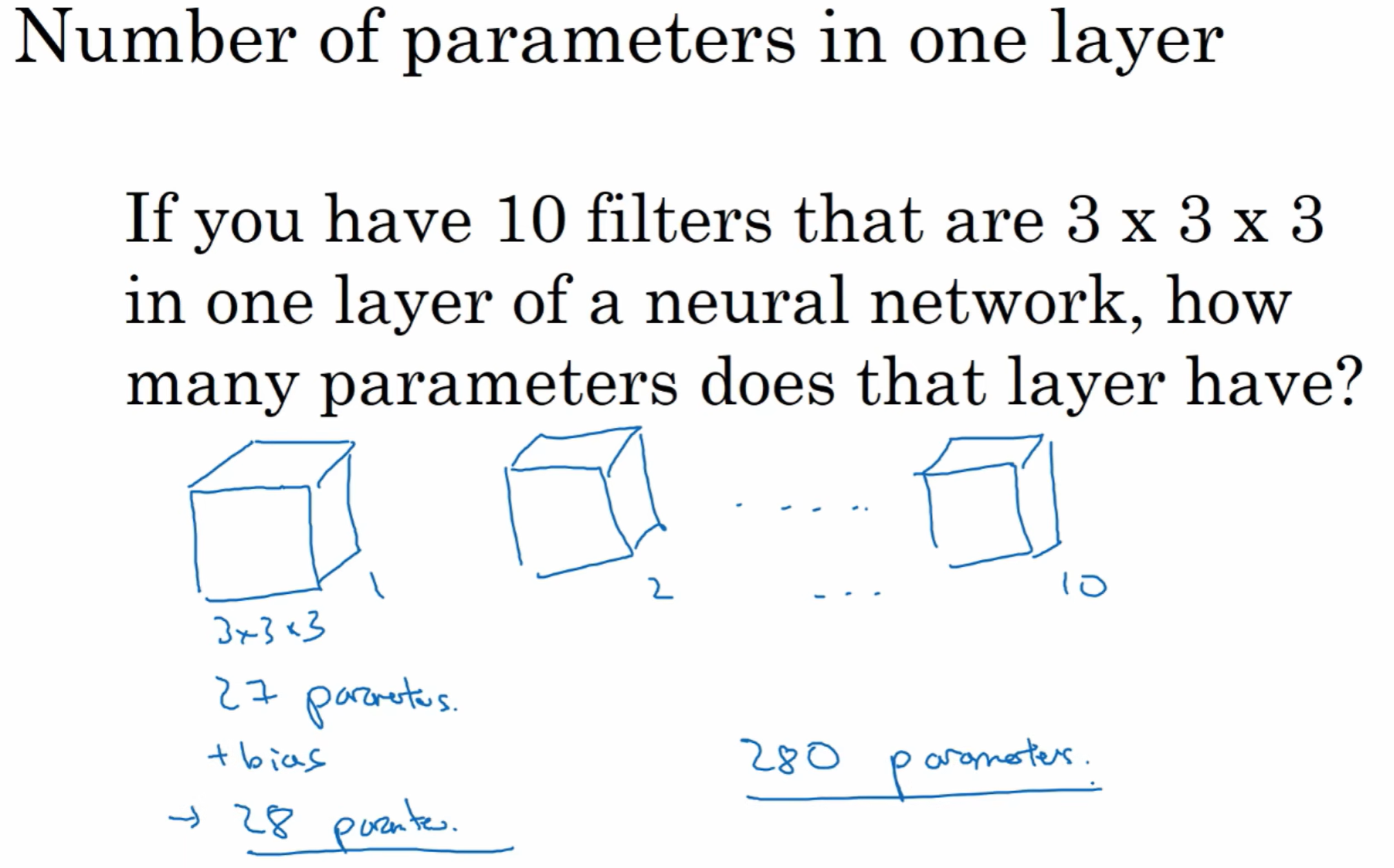
我们再来解释一下本文最开始提到的,传统的全连接神经网络容易过拟合的问题(图像增大,则参数增多),而为什么卷积网络不会。
如下图,不管输入图像多大,卷积网络这一层需要通过训练从而学习得到的参数个数总是固定的:(27+1)x10.由此可知,卷积神经网络不易产生过拟合(overfitting)的问题。
2.2.2:summary of notations

2.3:卷积神经网络的简单实例
如下图,经过几层卷积后,最后被一步会把得到的卷积结果进行flatten展平,输入进全连接神经网络,通过逻辑回归或softmax进行分类。

这里我们可以观察到的是,输入图像(通常比较大),但随着卷积神经网络的深入,与开始图像会保持大小几乎不变,但随着输入图像会逐渐变小,而通道数逐渐增加。
2.3.1:超参数(hyperparameter)
如上图,我们把箭头下方的那些参数(filter的个数、步长、padding…)称为超参数,选择这些超参数是卷积神经网络设计过程中的主要工作。
2.3.2:组成
在一个典型的卷积神经网络中,完整应该由以下3部分组成
- 卷积层
- 池化层
- 全连接层

2.3.3:卷积层的多层叠加
我们前面提到过随着卷积层的深入,通道数增大而图像减小。这样得到的好处是,每层使用较小的卷积核如3x3也能获得更大的感受野,只要叠加更多的卷积层,就能让感受野覆盖到整个图片。这也是为什么我们需要使用多个卷积层进行叠加。
打个比方,假设我们正在训练一个卷积神经网络来进行面部识别。在网络的第一层,卷积可能只识别出一些基本的特性,如边缘和颜色。到了第二层,卷积可能会学习如何将这些边缘和颜色组合成更简单的形状(比如眼睛、鼻子)。到了第三层,模型可能再将简单的形状组合成面部特征。因此,更深的层亦即卷积层叠加起来,能够把低级特征逐渐组合成高级和更有意义的特征。
那什么又是感受野呢?
2.3.4:感受野(receptive field)
感受野是一个非常重要的概念,receptive field往往是描述两个feature maps a/b上神经元的关系,假设从a经过若干个操作得到b,这时候b上的一个区域areab只会跟a上的一个区域areaa相关,这时候areaa成为areab的感受野。用图片来表示:
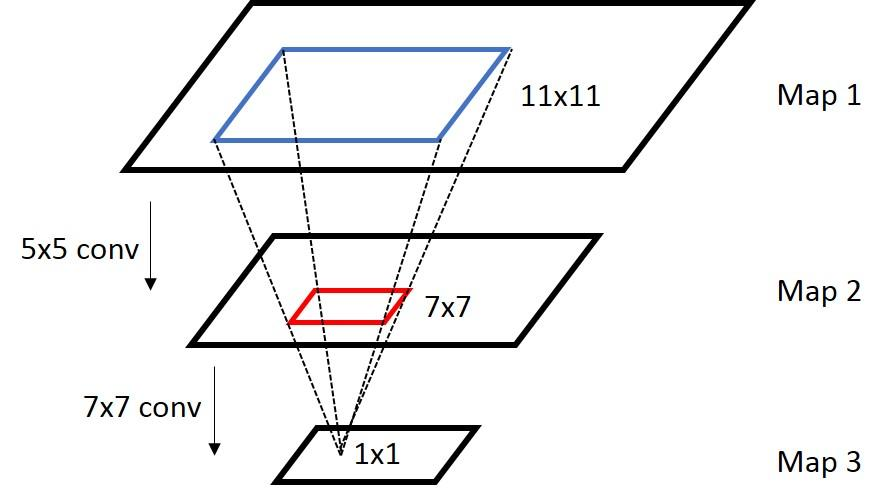
在上图里面,map3里1x1的区域对应map2的receptive field是那个红色的7x7的区域,而map2里7x7的区域对应于map1的receptive field是蓝色的11x11的区域,所以map3里1x1的区域对应map 1的receptive field是蓝色的11x11的区域。
2.4:池化层
我们先来看两种池化类型的示例:
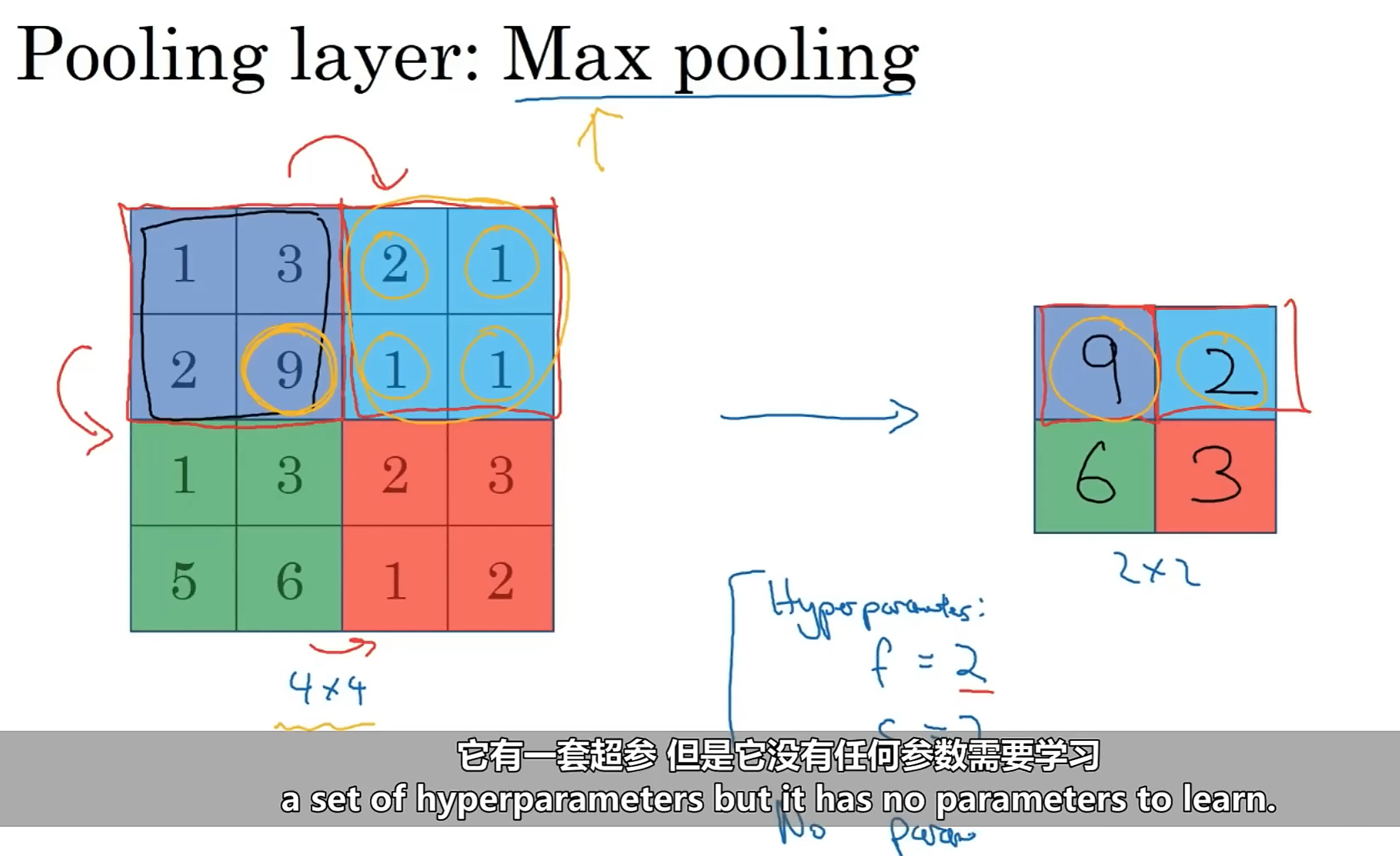
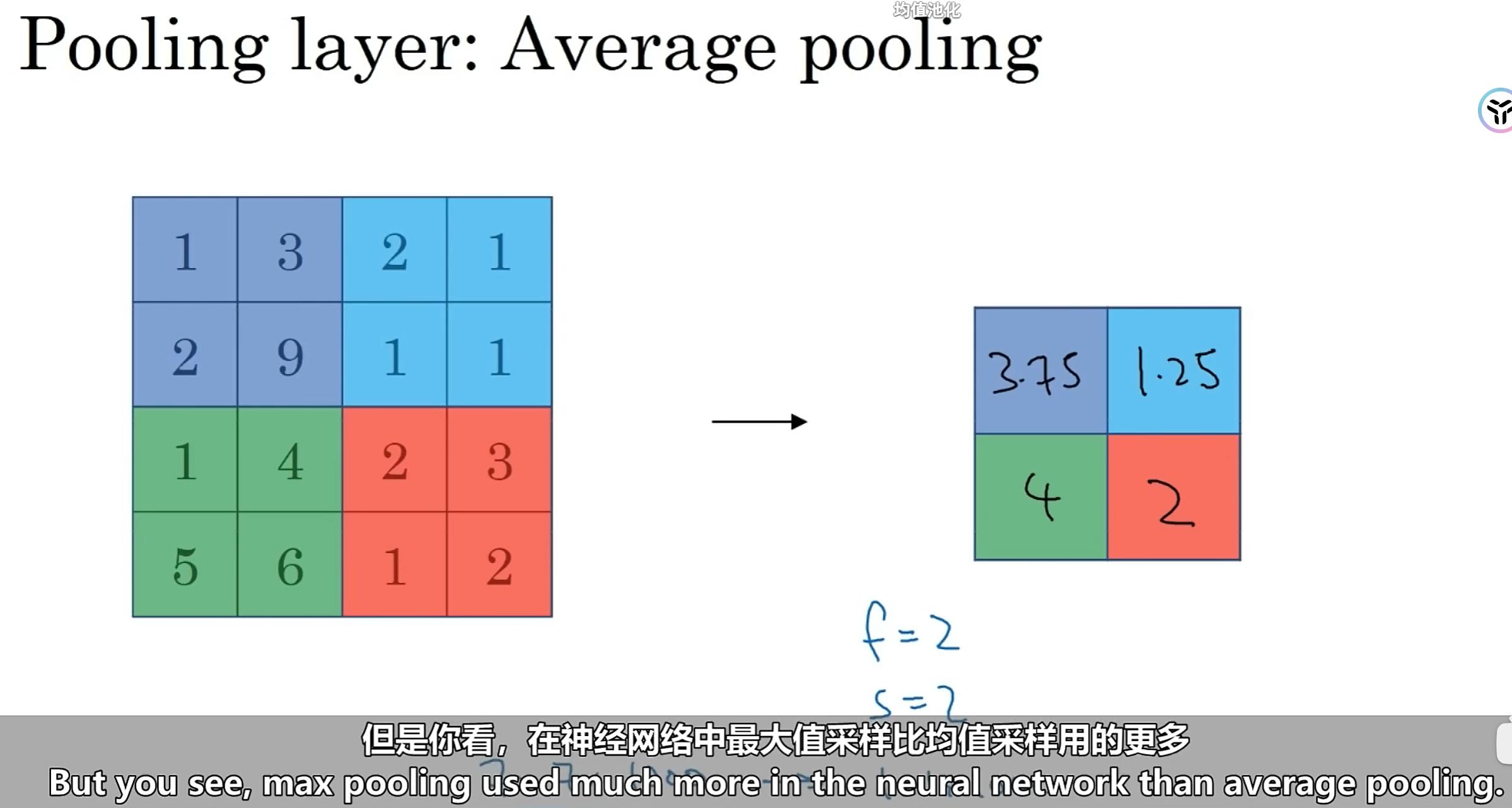
2.4.1:原理
池化操作的作用有两个
- 减轻计算负担
- 增加感受野
- 防止过拟合
吴恩达老师在视频中也说到过,池化操作背后深刻的原理其实也不见得有人能说得透彻清除,本质上就是因为实验效果好,可以加。
其实非要去理解的话,也是可以的,因为图像本身就是存在冗余信息的,用4个像素所表示特征信息可以用1个像素代替。从原图像中进行最大值或均值采样后(也就是所谓的池化),可以更好的把图像中的特征得到、识别,既然这样,能加为什么不加呢?
这个操作的直观理解就像是,你看了某个特殊景色,过段时间你可能记不清那里的每个细节,但是你肯定记得那里是美的。这个“美”的概念,就相当于经过池化操作之后保留下来的特征。
还需要补充一点是,在alphago的算法背后,利用的也是卷积神经网络,不同的是只有卷积层而没有池化层,因为在棋盘上每一个像素点都至关重要,不能因为减轻计算负担而随意舍去。这也是理解池化的一个例子。
2.4.2:总结
需要注意两点
- 池化层的超参数是人工设定的,不需要通过训练从而学习得到
- 池化层的最大值和平均值采样是单独作用于输入的每一个通道的。池化结果的通道数和输入的通道数相同。

2.5:完整的卷积神经网络示例

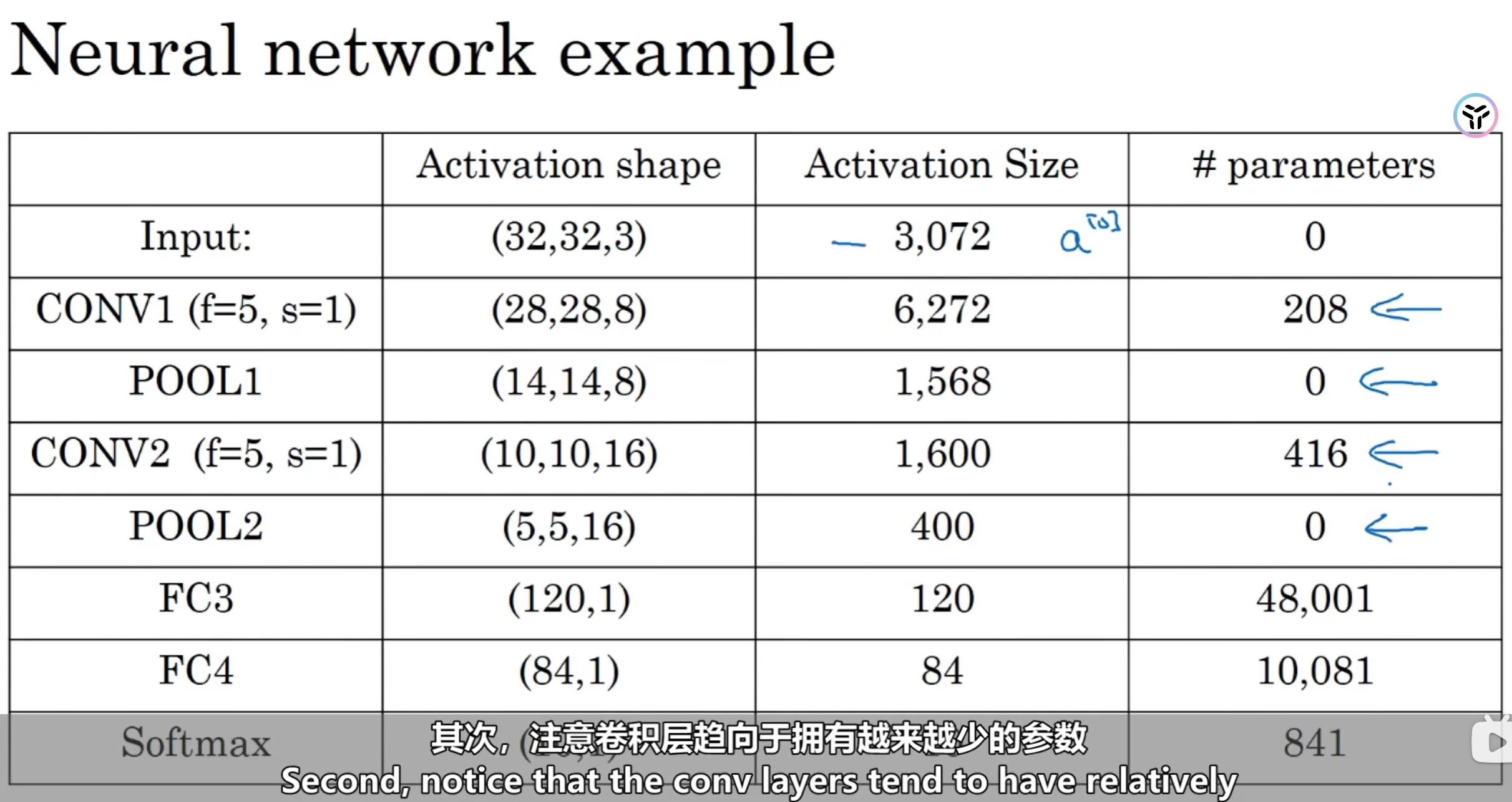
你需要清除以下几点
- 池化层没有任何需要学习的参数
- 卷积层趋向于拥有越来越少的参数
- 多数参数存在于全连接神经网络上
2.6:卷积神经网络的原理
其实上文一直在谈的是——卷积神经网络是什么,由什么组成等等。但是我觉得最重要的还是理解:为什么,为什么卷积神经网络可以。(虽然在本文最开始也把传统的全连接神经网络和带卷积的神经网络进行的简单的对比,说明为什么需要采用卷积而不是全连接,但我觉得那只是一方面)
首先我们需要理解,卷积神经网络,其实是计算机视觉+深度学习。在之前的机器学习中我们知道,通过输入数据,可以很好的进行分类、回归。将计算机视觉和深度学习结合起来,其实本质还是一样的,不同的在于:输入的数据,这也是为什么需要加入卷积层,而不能直接运用全连接层处理数据的原因。
比如之前讲的预测房价,输入就是房子大小、年龄这些基本的单特征。而对于计算机而言,你给它一张图片,只是一个三维或者二维矩阵,没有任何特征信息,换句话来说,直接把图片输入到全连接神经网络,即将像素点作为特征,这样的特征难以利用和复用以及进行比较。而卷积层的作用呢?提取特征,而且是有用的可复用的局部特征。通过卷积层提取到特征,并输入到全连接层进行相应的和之前机器学习中学到的传统的全连接神经网络进行特征信息处理并进行预测一模一样。一言蔽之:卷积神经网络识别图像的第一步:利用卷积层提取图像的局部特征。
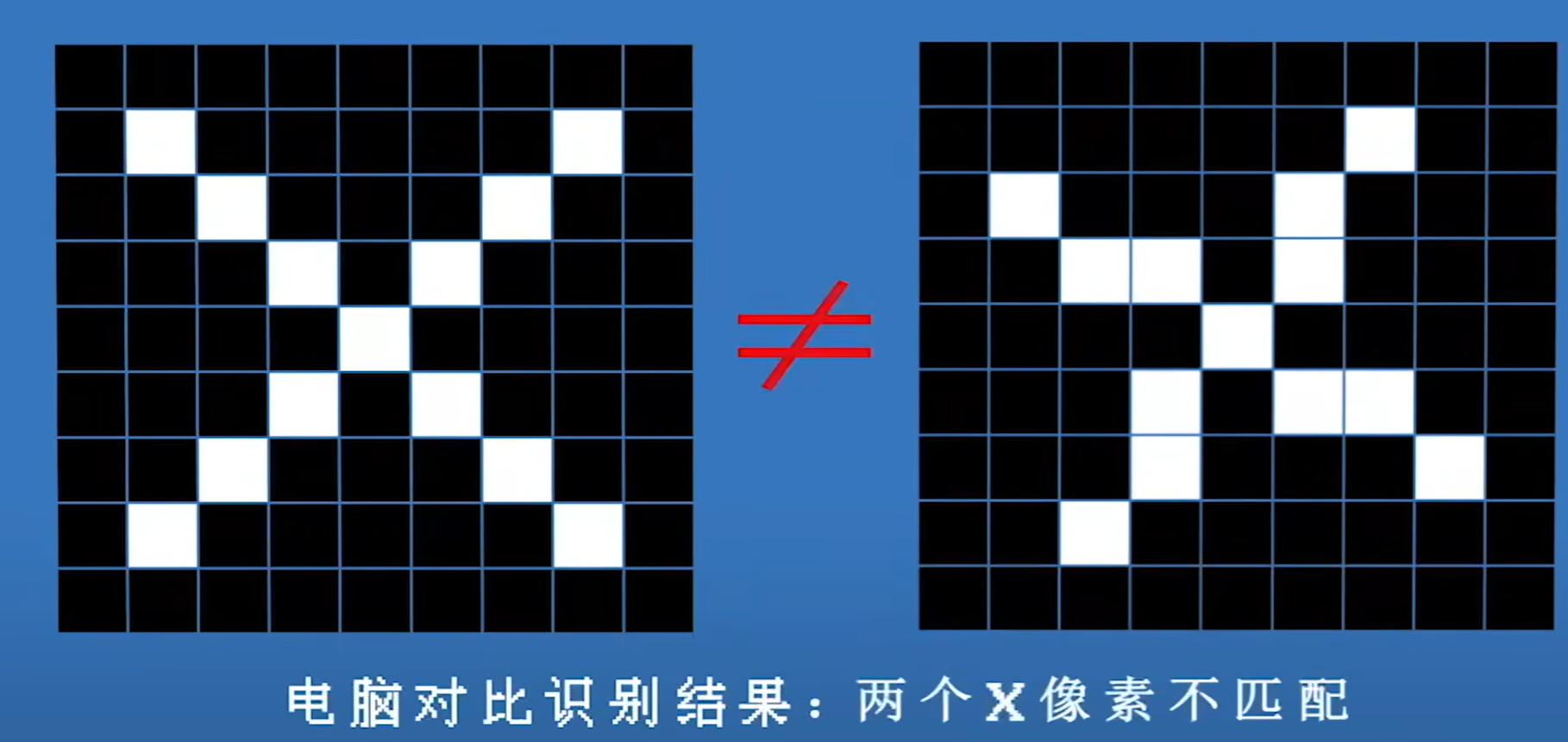
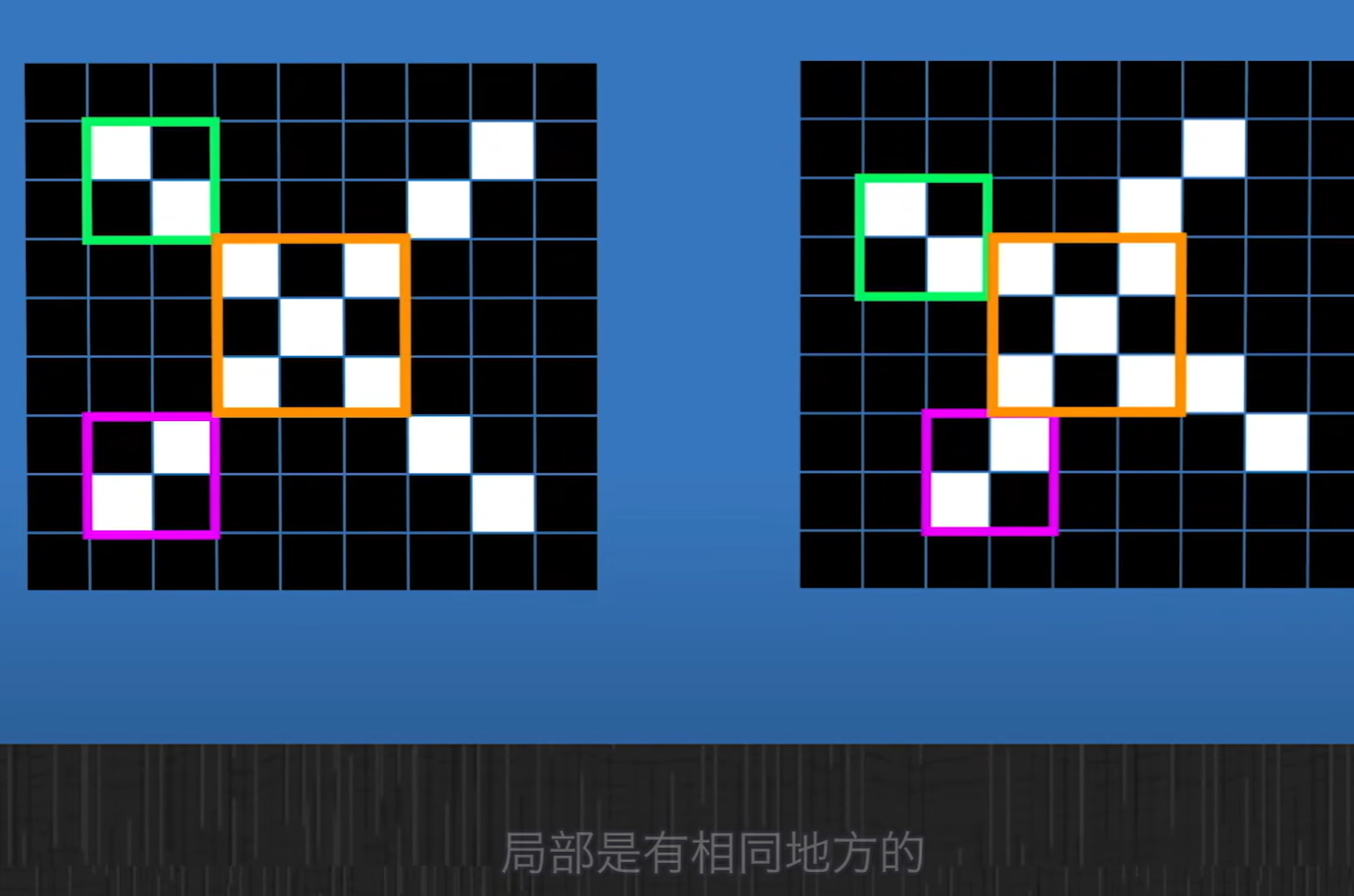
🌸总结:
而所谓的"卷积操作",可以简单理解为一个滤镜的过程,在图片上不断滑动,把图片局部的像素值经过一定的运算(这里的运算参数就是网络需要学习的部分),得到一个新的值,这个新的值就代表了这部分区域的某种特征。
ok,现在我们理解了卷积的作用——提取图像中的特征信息。我们现在的问题就缩小到了——卷积为什么能提取特征?提取的特征又是如何形式的?为什么这种方式提取的特征有效?
2.6.1:特征提取
从上文所讲的卷积操作,以及下面卷积操作结果的直观感受:卷积操作确实能提取特征。例如下图就利用垂直卷积核和水平卷积核,将图像中的垂直边缘信息和水平边缘信息提取出来。
到这里我们知道两点
- 卷积操作确实可以提取局部特征
- 不同的特征需要设计不同的卷积核(而在神经网络中,卷积核中的参数无需手动设计,网络会自己学习

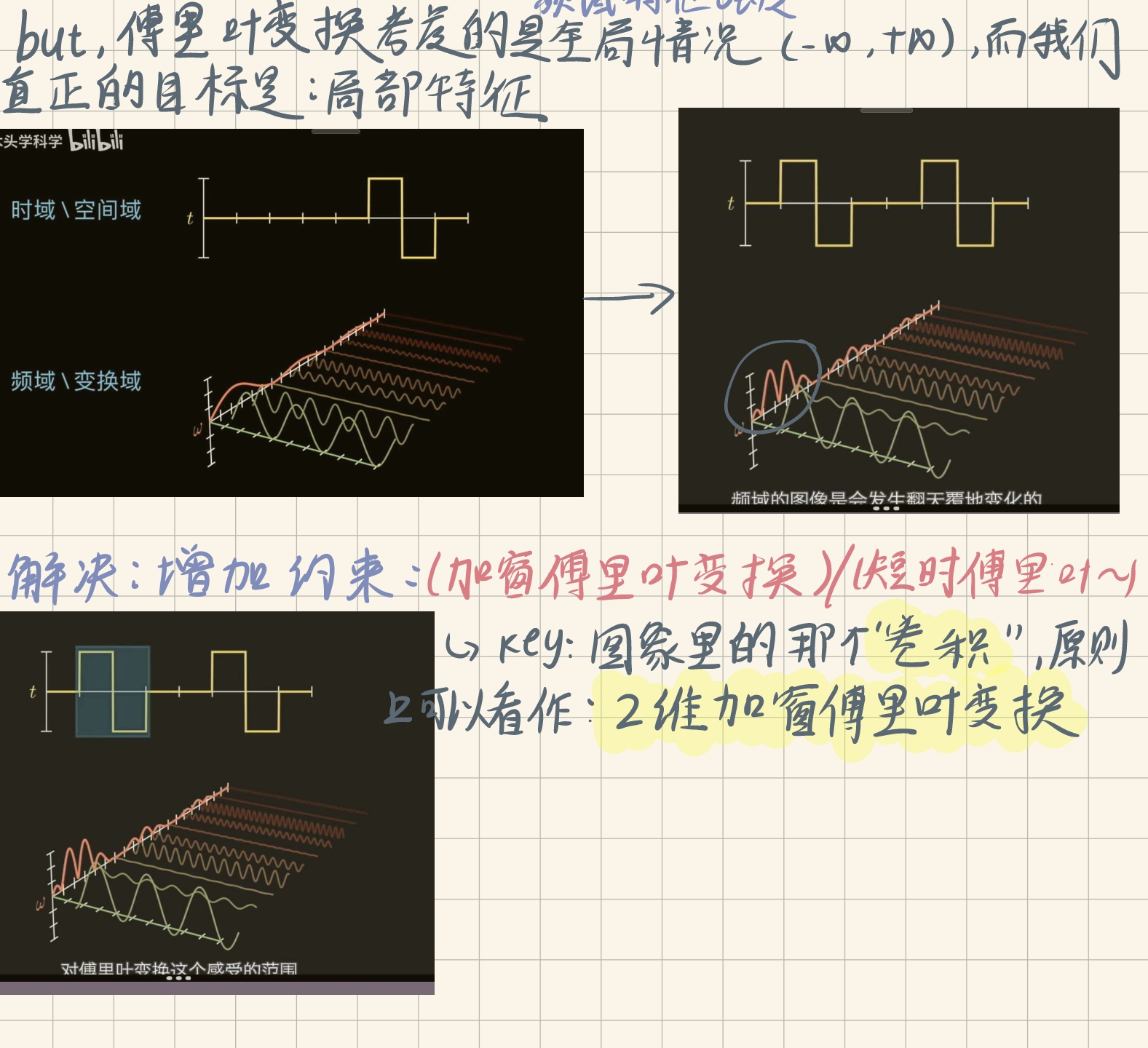
关于卷积操作为什么能提取特征背后的本质,和卷积核到底充当一个什么角色,深入理解的话,那就需要了解下面所讲的:傅里叶变换和加窗傅里叶变换
2.6.2:加窗傅里叶变换
卷积的本质是:二维的加窗傅里叶变换。学过信号与系统的话,大致对傅里叶变换有一个理解,我之前也专门写了一篇理解傅里叶变换的博客:傅里叶变换和其图像处理中的应用。这里的卷积核其实就是类比于傅里叶基,通过利用卷积核对二维图像数据进行卷积操作(加窗傅里叶变换),其实是将图像中和卷积核相似的特征信息提取出来(说白了,如果卷积核套在这块像素和卷积核想表达的特征相似,那么这次卷积得到的中心像素值就大,也就是这块存在这种卷积特征)。
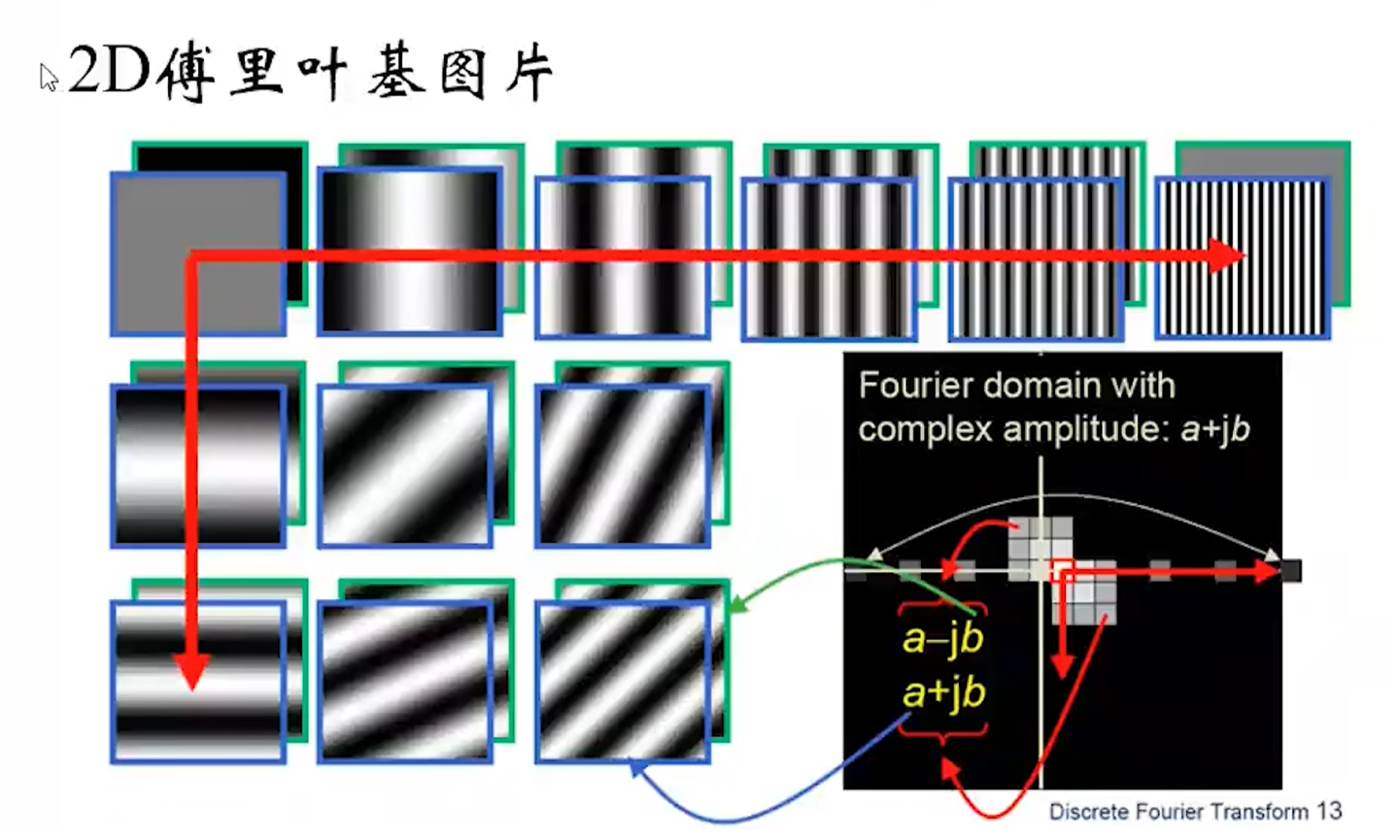
比如下面这个就是很好的一个例子:


这也是为什么上文讲卷积操作时,吴恩达老师会说,有几个卷积核,也就是有几个特征的含义。
不过需要注意的是,不像上图中那些规则的卷积核,神经网络中卷积核的样子(也就是卷积核的参数)是由反向传播学习得到的,具体卷积核的样子也是等到训练结束后才得知。

比如下面举例识别字母x的例子。我们假设一开始卷积核模板已经学习得到或者设计好,即以下三个特征(模式/卷积核/过滤器)。

当利用相应的模板(卷积核)对其进行卷积操作时,与模板特征匹配越高,在中心像素点位置的值也就越高(响应越高)——本质上就是,在这个位置捕捉到了这个卷积核对应的特征!

然后向之前一样,用过滤器将原图像分别卷积一遍,得到3个feature map

思考:我们可以看到,这样得到的特征信息,包含两个方面:
- 这个位置存在什么特征
- 这个特征存在的位置
🪧结合位置+特征这两个信息,将其展平(并不会丢失信息),输入全连接神经网络,神经网络开始干活,对特征信息进行像传统神经网络该做的事情,进行预测。
当然,上面这个例子过于简单,只有一层,多层神经网络和池化我们也讲到,其实还是为了获得更大的感受野和减轻计算负担,本质上还是一样的!
所以为什么经常会看到说对比于传统的计算机视觉,卷积神经网络可以自己学习特征,说到底就是通过反向传播学习这些卷积核里的参数。
2.6.3:卷积神经网络特征图可视化
接下来我们对特征图feature map进行可视化,来深入了解:
定义了一个4层的卷积,每个卷积层分别包含9个卷积、relu激活函数和尺度不等的池化操作,系数全部是随机初始化
输入原图:

第一层卷积后可视化的特征图:

第二层卷积后可视化的特征图:

第三层卷积后可视化的特征图:
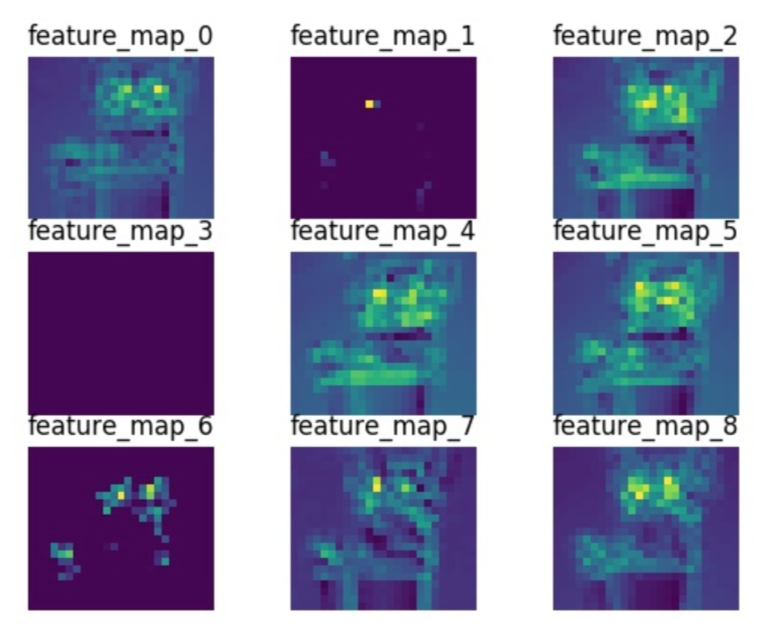
第四层卷积后可视化的特征图:

从不同层可视化出来的特征图大概可以总结出一点规律:
- 浅层网络提取的是纹理、细节特征
- 深层网络提取的是轮廓、形状、最强特征(如猫的眼睛区域)——或者说是前面特征(卷积核)叠加效果的通用、最强特征(个人直觉上),但看一层的特征当然看起来似乎不可解释,但是实际上最后得到的特征图是建立在前面那么多卷积核作用之后的。
- 浅层网络包含更多的特征,也具备提取关键特征(如第一组特征图里的第4张特征图,提取出的是猫眼睛特征)的能力
- 相对而言,层数越深,提取的特征越具有代表性
- 图像的分辨率是越来越小的

以上是个人结合一些视频和文章资料学习、整合和加入自己理解所写,能力有限,若有欠妥地方,欢迎评论区讨论和指正!💐
赞 (0)
您想发表意见!!点此发布评论





发表评论