最全docker--高级篇
461人参与 • 2024-08-06 • arm开发
文章目录
现在咱们开始docker的高级篇!
二、高级篇
1、network
首先记牢docker网络官网:https://docs.docker.com/network/
1.1、网络介绍
当前咱们搭建了docker的容器之后,容器和容器之间是需要通讯的,如果不能通讯,容器作用和价值就不大了。
比如:咱们启动了两个容器,一个项目的容器,一个redis的容器,项目是需要链接redis的,这就构成了两个容器的网络通讯。甚至容器在不同的宿主机上,无法通讯的话,docker基本上没啥用了。
关于docker容器的构成
docker是基于linux kernel的namespace,cgroups,unionfilesystem等技术封装成的一种自定义容器格式,从而提供了一套虚拟运行环境。
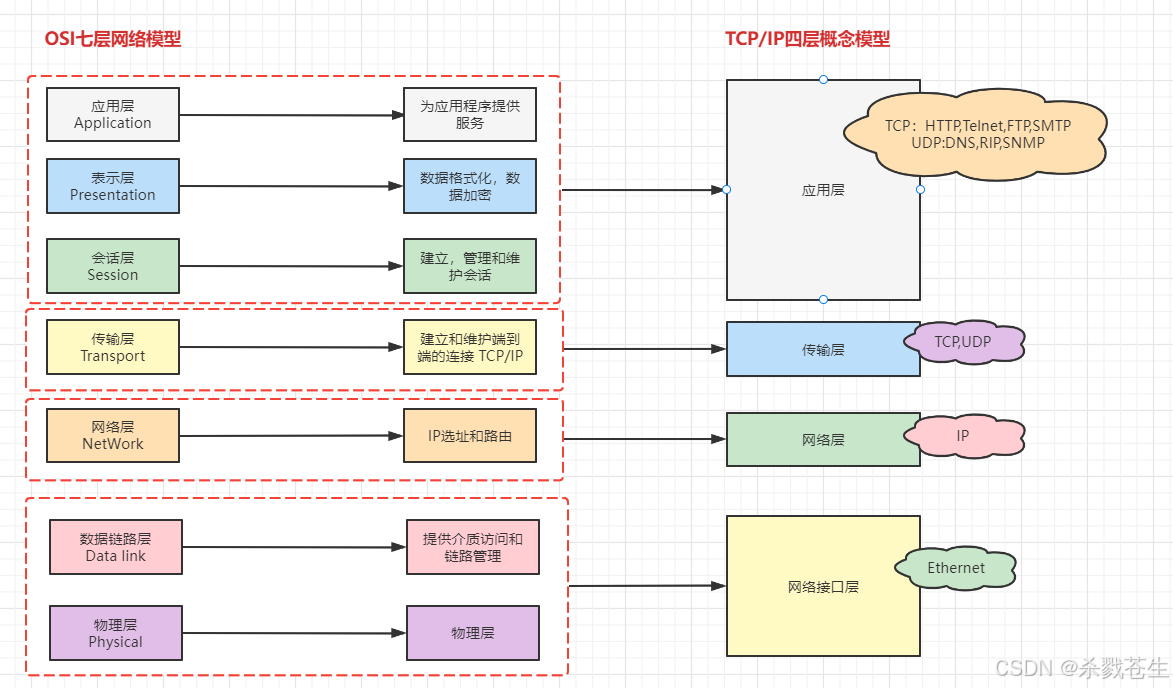
1.2、计算机网络模型
关于docker中的分层思想,其实在计算机中很多地方,都能体现到这一思想。例如:网络模型
1.2.1、网络模型和概念模型
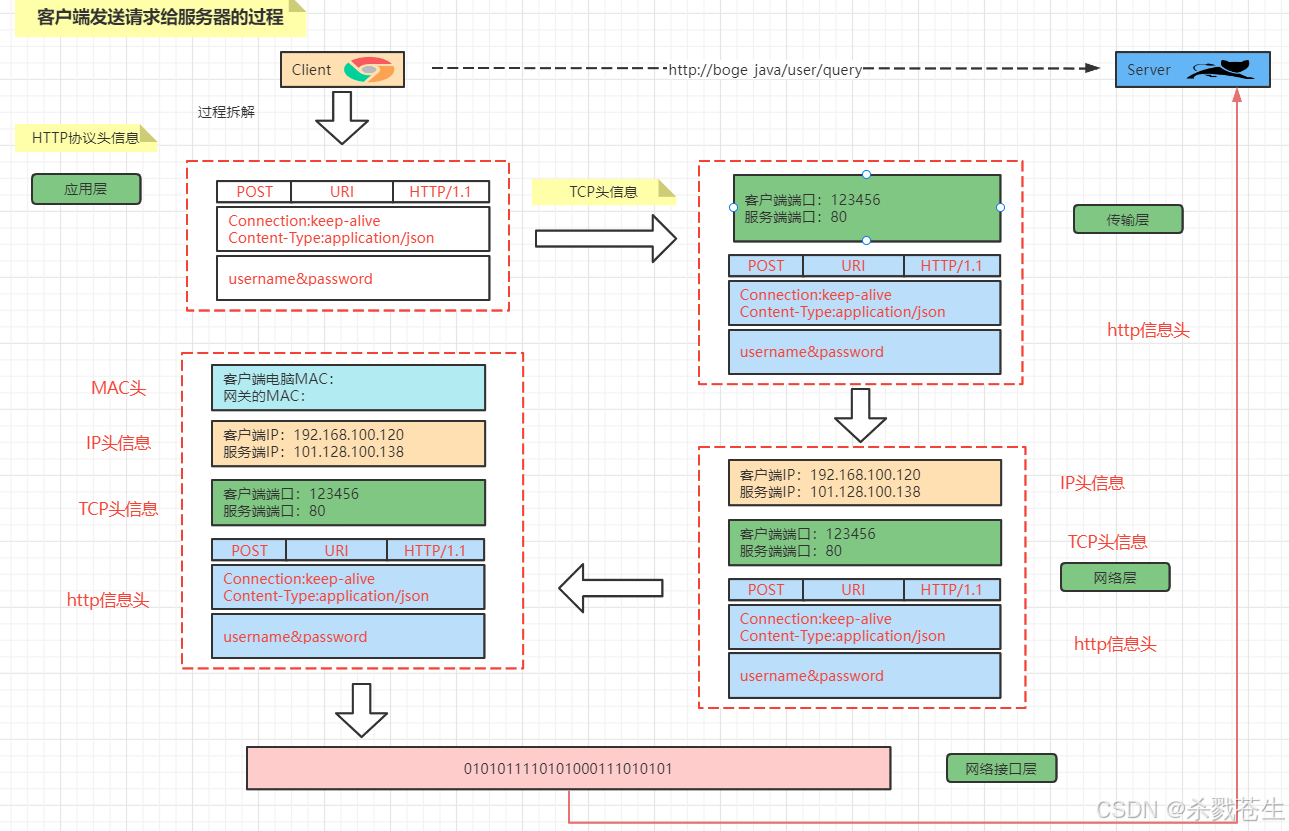
1.2.2、数据的分层封装
1.2.2.1 客户端发送请求
 解释
解释
-
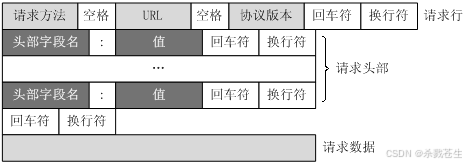
客户端发起请求首先在应用层,生成
http报文的请求行,请求头,请求体。并将http协议报文发送到传输层。
-
传输层在此报文的基础上封装上
tcp头信息,即客户端的端口,服务端的端口,并将封装过后的报文发送到网络层。 -
网络层在此基础上继续封装上
ip头信息,封装上客户端ip以及服务端ip,并将报文发送到网络接口层。 -
网络接口层,会再封装,添加上
mac头信息,即客户端的mac地址以及网关mac,然后将封装好的报文转成二进制码,发到客户端
1.2.2.2 服务端接受请求
 解释:
解释:
- 请求经过物理层的传输到达服务器后。首先需要经过网络接口层,他会将二进制的数据转成客户端封装后的报文。
- 然后,网络接口层会从报文中先解析出
mac头信息,验证mac是否正确。正确,则继续下一层,并将报文发送到网络层。 - 网络层接收到报文后,进行第二层的解析,将
ip头信息解析出来,并验证是否正确。正确,则将信息发送到传输层。 - 传输层再次解析出报文中的
tcp头信息,并验证服务端端口是正确,并且端口已经开放。都没问题,则将信息发送到应用层。 - 应用层则将最后的
http协议报文转成httpservletrequest对象发送给服务。
1.3、linux中的网卡
1.3.1、查看网卡及其作用
在知道docker是如何通信的之前,先来看一下linux的中的网卡是如何通信。毕竟原理是相通的,弄懂一个,其他的就都懂了。
[root@localhost ~]# ip a
1: lo: <loopback,up,lower_up> mtu 65536 qdisc noqueue state unknown group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: ens33: <broadcast,multicast,up,lower_up> mtu 1500 qdisc pfifo_fast state up group default qlen 1000
link/ether 00:0c:29:22:7c:7a brd ff:ff:ff:ff:ff:ff
inet 10.19.6.104/16 brd 10.19.255.255 scope global noprefixroute ens33
valid_lft forever preferred_lft forever
inet6 fe80::420c:3702:e936:a686/64 scope link noprefixroute
valid_lft forever preferred_lft forever
3: docker0: <no-carrier,broadcast,multicast,up> mtu 1500 qdisc noqueue state down group default
link/ether 02:42:9a:99:34:1b brd ff:ff:ff:ff:ff:ff
inet 172.17.0.1/16 brd 172.17.255.255 scope global docker0
valid_lft forever preferred_lft forever
[root@localhost ~]#
通过命令ip a 查看系统中的所有网卡信息。
| 网卡名称 | 干嘛用的 |
|---|---|
| lo | 回环网卡,也就是本地网卡,他主要是模拟网络接口层,解析报文发送给自己(解析网络地址)。 **举个例子:**计算机上有两个服务,服务1访问服务2,没有回环网卡,发送的数据报文就会走完传输层和网络层所有过程,再发给自己;但是有了回环网卡,就不用走这个路径,通过回环网卡解析报文,就可以发送自己。 |
| ens33 | 网络网卡,他的作用是,与外面网络进行链接 |
| docker0 | docker的网卡。docker安装后,会生成一个docker的网卡 |
查看网卡的其他命令
[root@localhost ~]# ip link show
1: lo: <loopback,up,lower_up> mtu 65536 qdisc noqueue state unknown mode default group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: ens33: <broadcast,multicast,up,lower_up> mtu 1500 qdisc pfifo_fast state up mode default group default qlen 1000
link/ether 00:0c:29:22:7c:7a brd ff:ff:ff:ff:ff:ff
3: docker0: <no-carrier,broadcast,multicast,up> mtu 1500 qdisc noqueue state down mode default group default
link/ether 02:42:9a:99:34:1b brd ff:ff:ff:ff:ff:ff
# 以文件的形式查看网卡
[root@localhost ~]# ls /sys/class/net/
docker0 ens33 lo

1.3.2、网卡的配置文件
这个文件主要是给网卡配置固定ip
[root@localhost ~]# cd /etc/sysconfig/network-scripts/
# 这个目录下面有好多文件,咱们就加条件筛选一下
[root@localhost network-scripts]# ls | grep ifcfg
ifcfg-lo
ifcfg-ens33
----------------------------
# 自己 建的文件 dhcp的
ifcfg-ens33.dhcp.bak
# 自己建的文件 配置静态ip
ifcfg-ens33.static.bak
根据你的网卡个数,就会有几个配置文件。lo对应ifcfg-lo、ens33对应ifcfg-ens33 、docker0是虚拟网卡没有配置文件。
对于固定ip的设定,这里不讲。

1.3.3、网卡操作
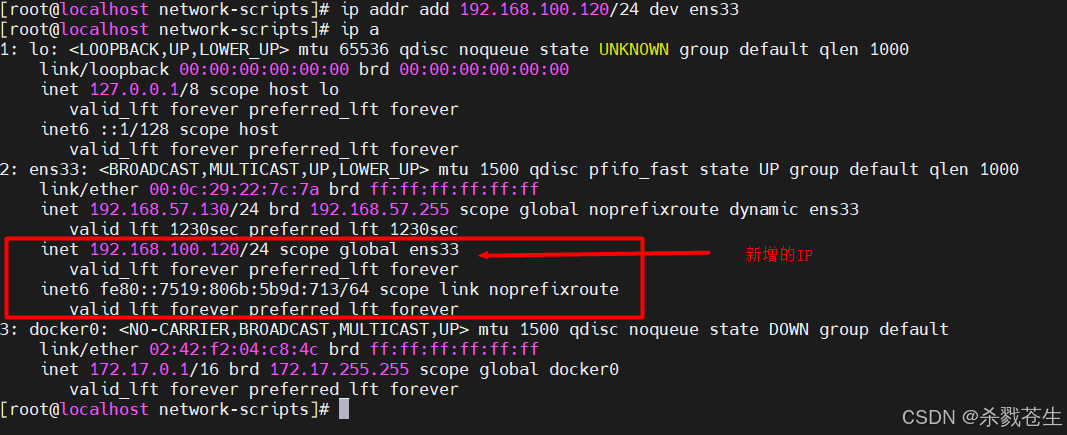
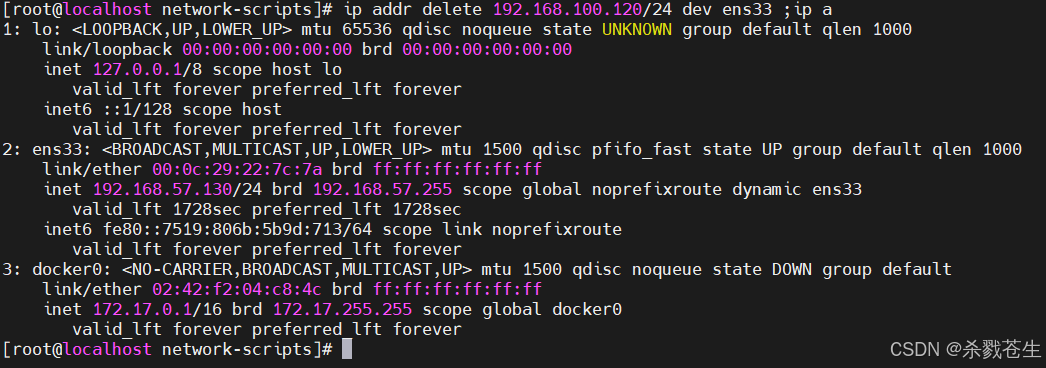
# 给网卡增加ip
ip addr add 192.168.100.120/24 dev ens33
# 删除网卡的ip
ip addr delete 192.168.100.120/24 dev ens33
1.4、namespace
接下来看,第二个知识点namespace。
network namespace 是实现网络虚拟化的重要功能,它能创建多个隔离的网络空间,它们有独自的网络栈信息。不管是虚拟机还是容器,运行的时候仿佛自己就在独立的网络中。
这也就是docker的容器在运行中是如何和其他网络隔离的。
1.4.1、namespace操作
1.4.1.1、namespace基本操作
#查看当前所有的namespace
ip netns list
#增加一个 名为【ns1】的namespace
ip netns add ns1
#删除【ns1】这个namespace
ip netns delete ns1
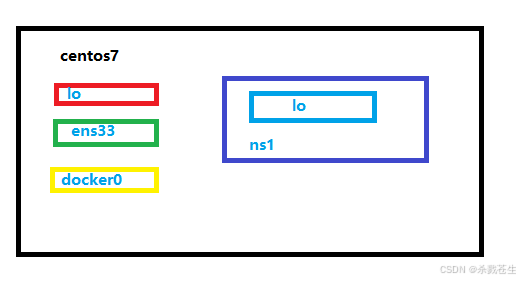
#查看namespace【ns1】的网卡情况。exec跟docker的exec命令差不多,都可以理解为进入/登录的意思。
#通过 exec登录名为【ns1】的namespace,执行【ip a】命令
ip netns exec ns1 ip a
 最后形成这样的图才对。
最后形成这样的图才对。
1.4.1.2、namespace内网卡的启动与关闭
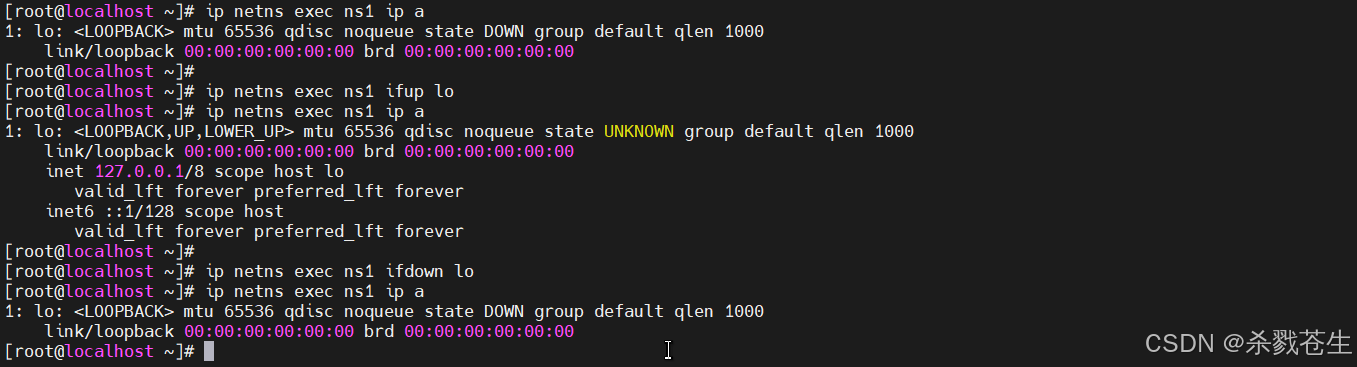
#----------ip命令--------------
# 打开(ns1的lo)网卡
ip nets exec ns1 ifup lo
# 关闭(ns1的lo)网卡
ip nets exec ns1 ifdown lo
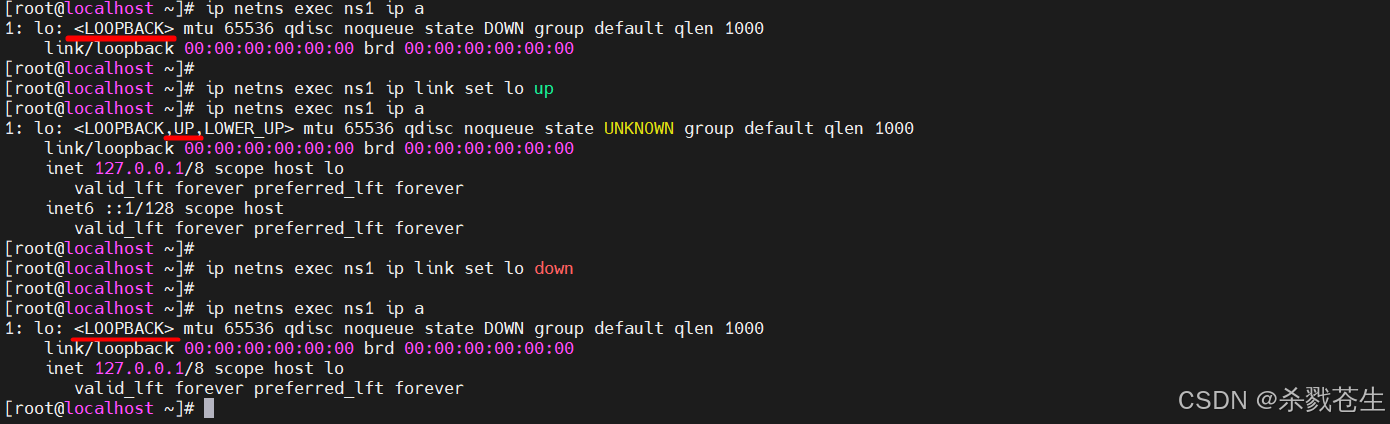
#----------link命令--------------
#通过link命令来启动网卡
ip netns exec ns1 ip link set lo up
#通过link命令来关闭网卡
ip netns exec ns1 ip link set lo down
1.4.2、不同namespace网卡的通讯
要想实现不同namespace下的网卡通讯,需要用到的技术就是:
veth pair:virtual ethernet pair,是一个成对的端口,可以实现上述功能。示意图图下:
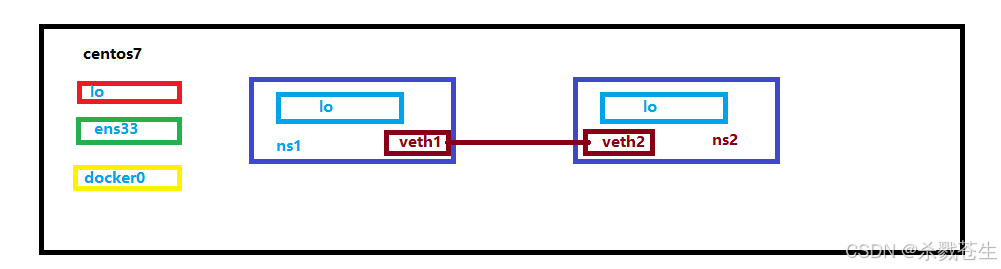
接下来命令实操
#首先创建两个namespace【ns1】【ns2】
#创建成对的 veth pair网卡 veth1 以及 veth2
ip link add veth1 type veth peer name veth2
# 将网卡 veth1 交给 ns1
ip link set veth1 netns ns1
# 将网卡 veth2 交给 ns2
ip link set veth2 netns ns2
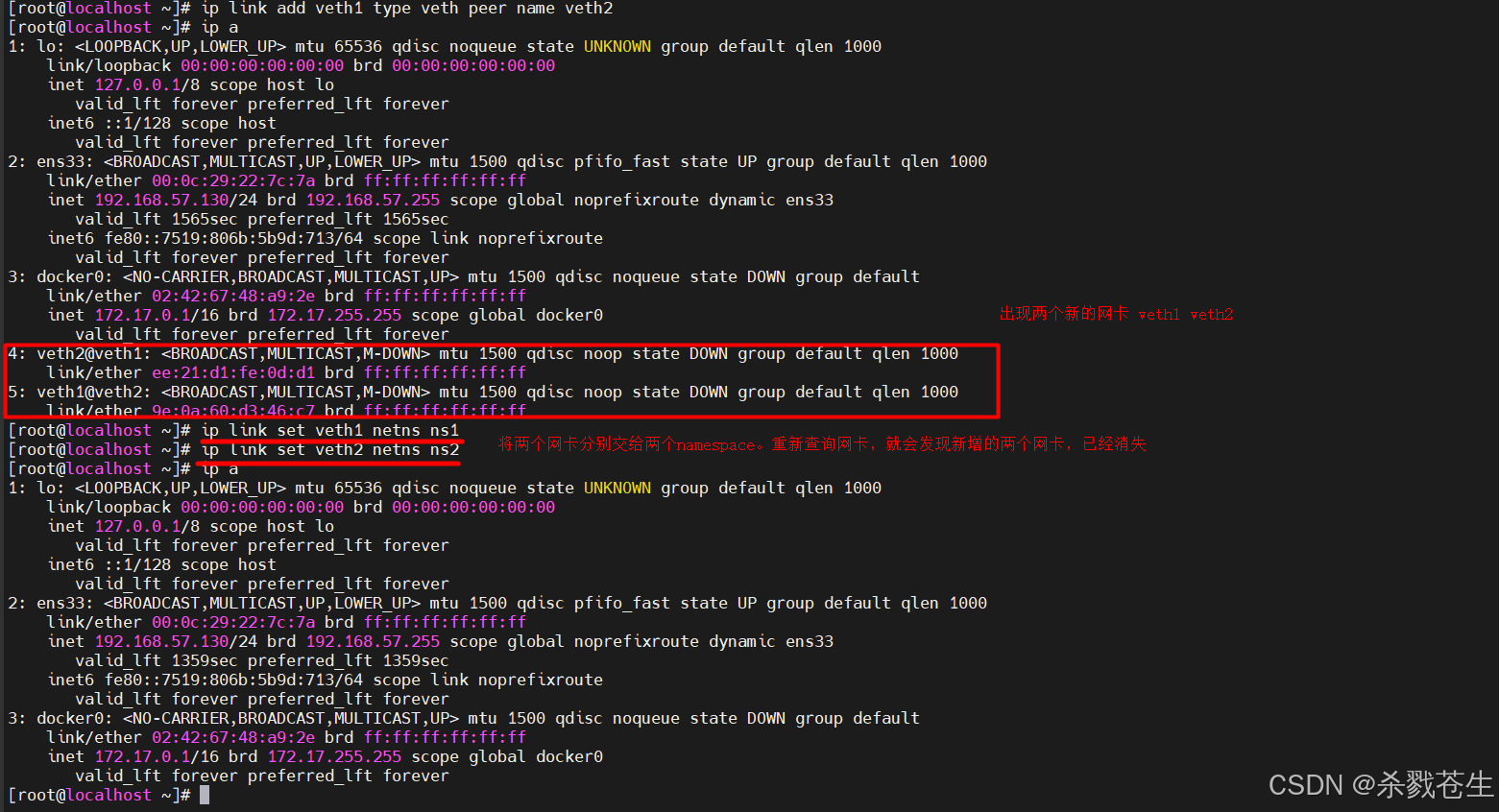
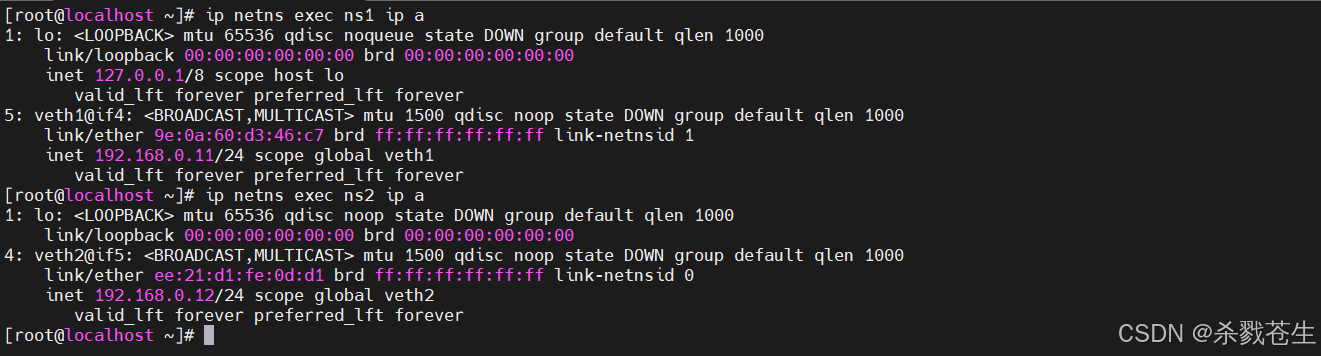
#分别查询两个namespace就会发现之前新增的两个网卡
ip netns exec ns1 ip link
ip netns exec ns2 ip link

#想要通讯,需要增加ip地址。给两个网卡增加新的ip地址。注意:网卡和namespace一定要对应好
ip netns exec ns1 ip addr add 192.168.0.11/24 dev eth1
ip netns exec ns2 ip addr add 192.168.0.11/24 dev eth2
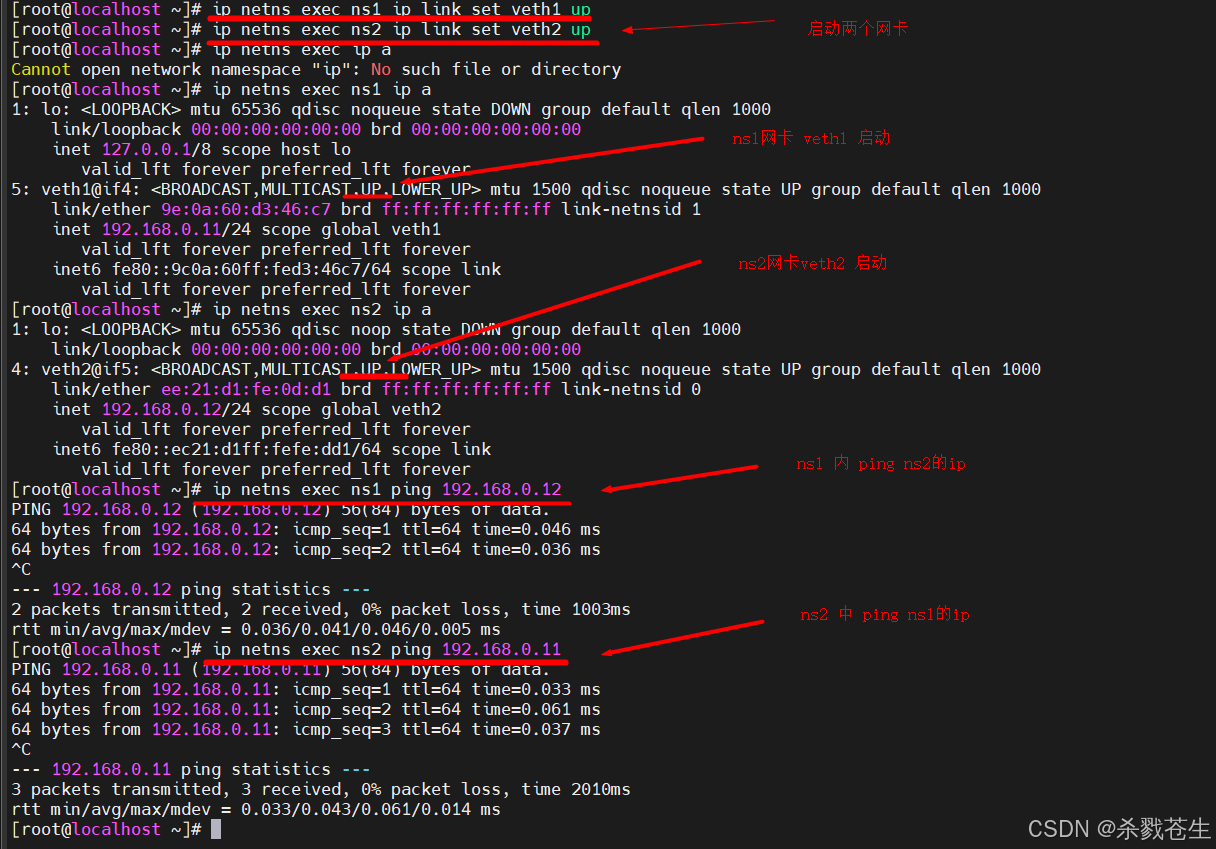
#分别启动两个网卡
ip netns exec ns1 ip link set veth1 up
ip netns exec ns2 ip link set veth2 up
# 然后需要互相ping
ip netns exec ns1 ping 192.168.0.12
ip netns exec ns2 ping 192.168.0.11
1.4.3、【docker】container的namespace
按照上面的描述,docker的每个container,都会有自己的network namespace,并且是独立的。接下验证咱们的猜想。
-
使用
docker pull centos:7命令,下载centos镜像(之所以使用centos,不直接使用tomcat镜像,是因为tomcat镜像里没有ip命令) -
创建tomcatdockerfile文件,并进行编写
from centos maintainer bugaosuni add apache-tomcat-8.5.93.tar.gz /usr/local/ env mypath /usr/local workdir $mypath #配置tomcat环境变量 env catalina_home /usr/local/apache-tomcat-8.5.93 env catalina_base /usr/local/apache-tomcat-8.5.93 env path $path:$java_home/bin:$catalina_home/lib:$catalina_home/bin #容器运行时监听的端口 expose 8080 #启动时运行tomcat cmd ["/usr/local/apache-tomcat-8.5.93/bin/catalina.sh","run"] -
构建自定义tomcat镜像
docker build -f tomcatdockerfile -t tomcat_custom:1.0.0 . -
运行tomcat镜像
docker run -d --name tomcat01 -p 8081:8080 tomcat_custom:1.0.0 docker run -d --name tomcat02 -p 8082:8080 tomcat_custom:1.0.0 -
进入容器查看ip
docker exec -it tomcat01 ip a docker exec -it tomcat02 ip a
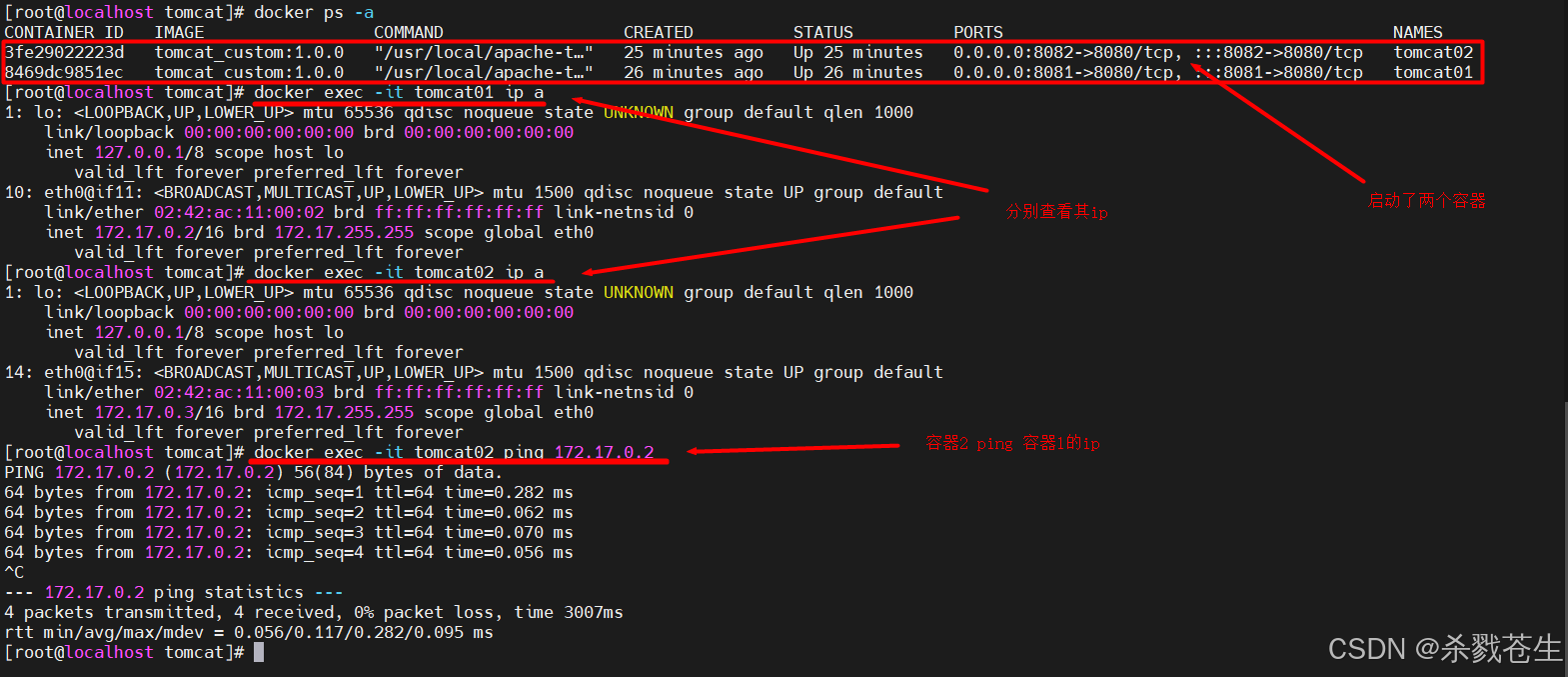
通过上面的图片,咱们就可以看到,每个容器都有自己一套网卡,容器和容器是相互隔离的。
仔细看就会发现他们的网卡eth0绑定的不是同一个mac,网卡名字也是不相同的。
他们能够相互ping的通,原理是相同的,但是他们的网卡通信却不是veth-pair技术,而是bridge技术。
1.5、docker的container网络模式
执行命令docker network ls就会发现docker中存在三种网络模式。
[root@localhost tomcat]# docker network ls
network id name driver scope
b6147ac32cc8 bridge bridge local
8673ae77bb8a host host local
5f2ed6e8566d none null local
也就是 bridge、host、none。
注意:docker的网络模式其实是4种,还有一种container模式,类似于host模式。
1.5.1、vmware虚拟机的网络模式
了解docker的网络模式之前,先来了解一下虚拟机的网络模式,毕竟一法通百法明。
打开vmware workstation pro -->虚拟机–>设置–>网络适配器。就会弹出下图。
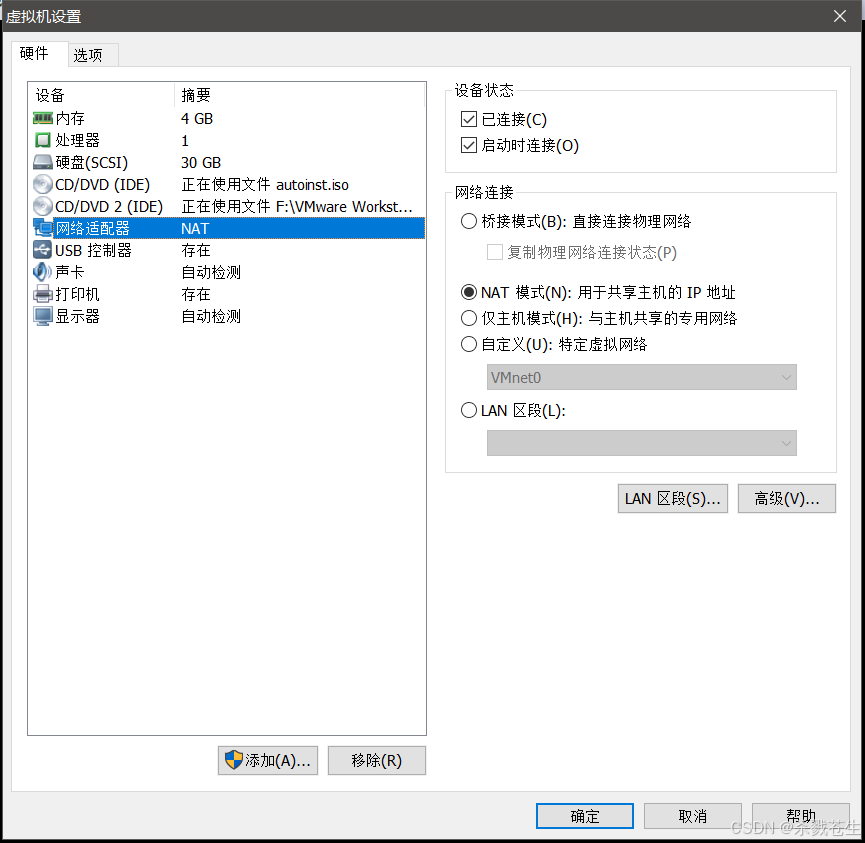
-
桥接模式:在这种模式下,vmware虚拟出来的操作系统就像是局域网中的一台独立的主机,它可以访问网内任何一台机器。
在桥接模式下,你需要手工为虚拟系统配置ip地址、子网掩码,而且还要和宿主机器处于同一网段,这样虚拟系统才能和宿主机器进行通信。
同时,由于这个虚拟系统是局域网中的一个独立的主机系统,那么就可以手工配置它的tcp/ip配置信息,以实现通过局域网的网关或路由器访问互联网。即此虚拟机可以和局域网中的其他主机互相通信。
-
使用nat模式,就是让虚拟系统借助nat(网络地址转换)功能,通过宿主机器所在的网络来访问公网。也就是说,使用nat模式可以实现在虚拟系统里访问互联网。
nat模式下的虚拟系统的tcp/ip配置信息是由
vmnet8(nat)虚拟网络的dhcp服务器提供的,无法进行手工修改,因此虚拟系统也就无法和本局域网中的其他真实主机进行通讯。采用nat模式最大的优势是虚拟系统接入互联网非常简单,你不需要进行任何其他的配置,只需要宿主机器能访问互联网即可。
-
仅主机模式:在此模式下所有的虚拟系统是可以相互通信的,但虚拟系统和真实的网络是被隔离开的。
此模式下,虚拟系统和宿主机器系统是可以相互通信的,相当于这两台机器通过双绞线互连。
此模式下,虚拟系统的tcp/ip配置信息(如
ip地址、网关地址、dns服务器等),都是由vmnet1(host-only)虚拟网络的dhcp服务器来动态分配的。
1.5.2、bridge模式
咱们容器的网卡不是veth-pair技术生成的成对的网卡,那他们是如何ping的呢?
他们用的是bridge,也就是咱们平常经常说的桥接模式!
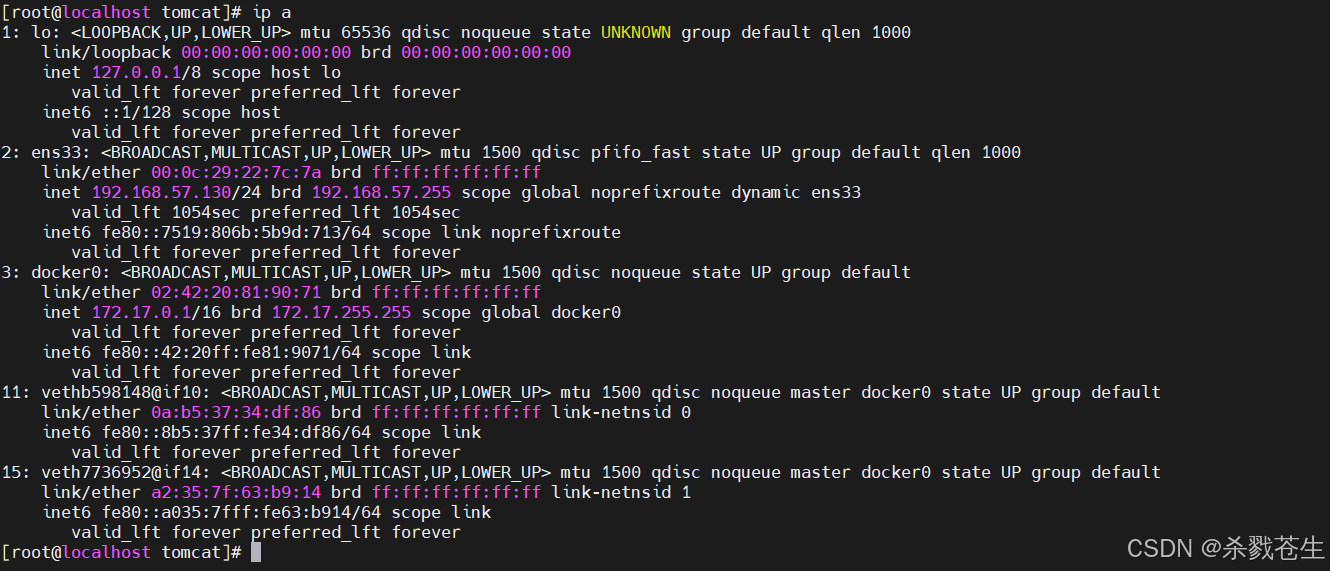 通过命令查询宿主机ip,就会发现宿主机又多了两个网卡。
通过命令查询宿主机ip,就会发现宿主机又多了两个网卡。
对比容器内的网卡就会发现网卡的规律
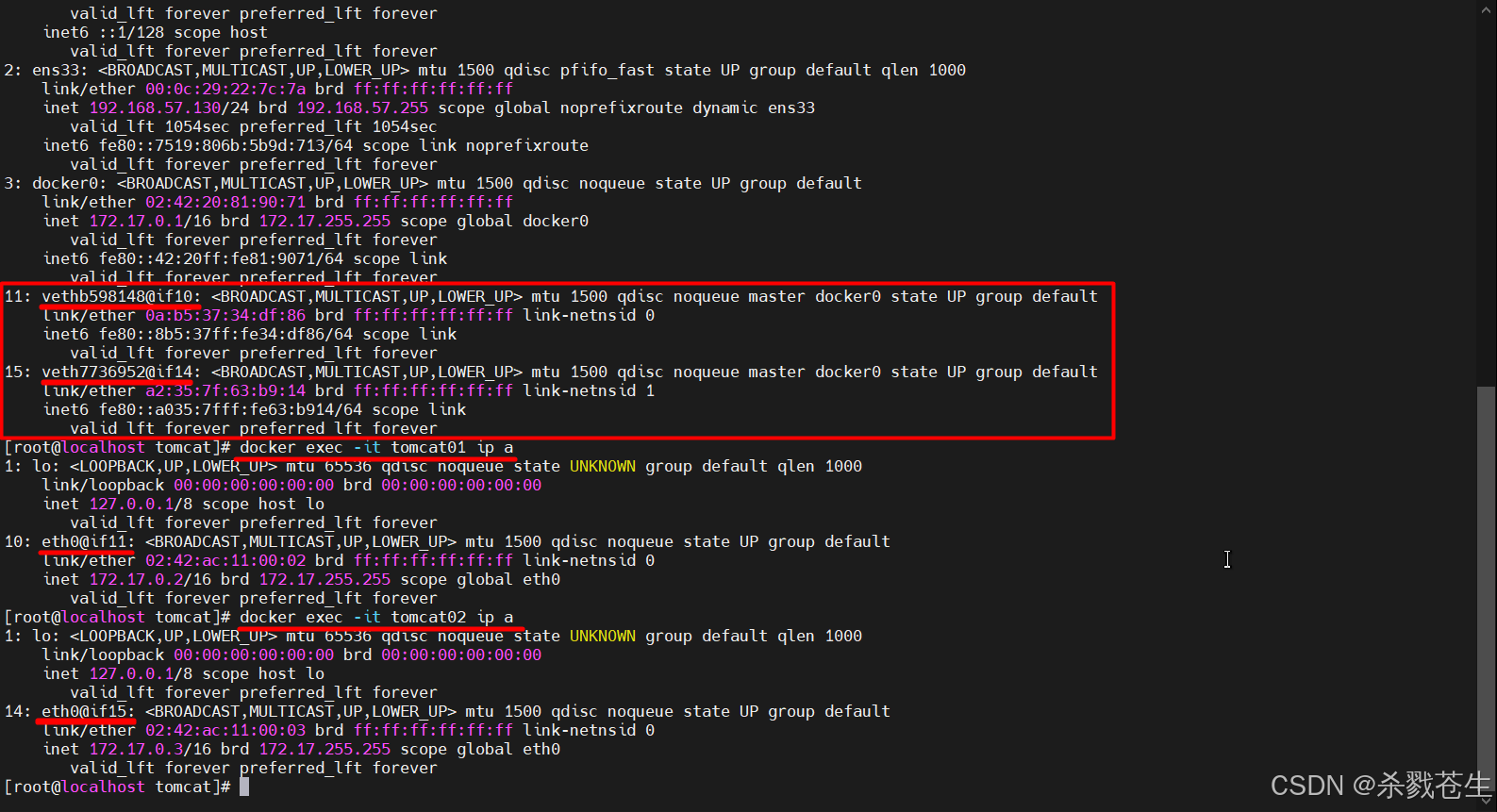 其最后的网卡示意图,是如下所示的。
其最后的网卡示意图,是如下所示的。
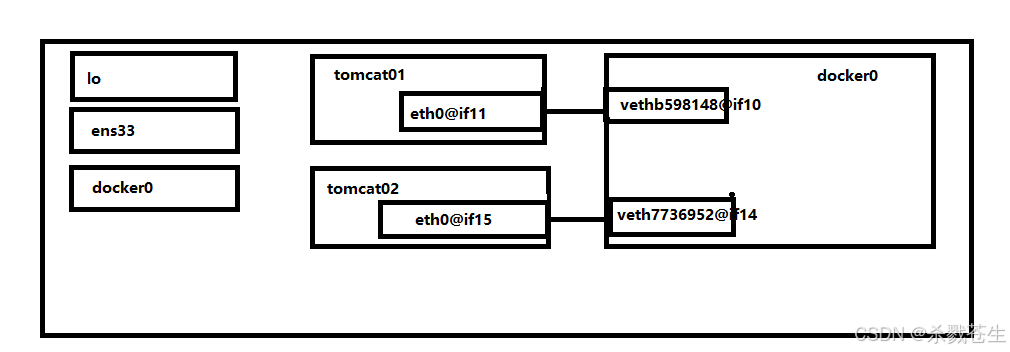 容器的网卡都在各自的容器内,和容器通讯的网卡则在宿主机上,
容器的网卡都在各自的容器内,和容器通讯的网卡则在宿主机上,eth0@if11和vethb598148@if10则构成了成对的网卡。而宿主机上的两个网卡vethb598148@if10和veth7736952@if14则都在docker0网桥中。
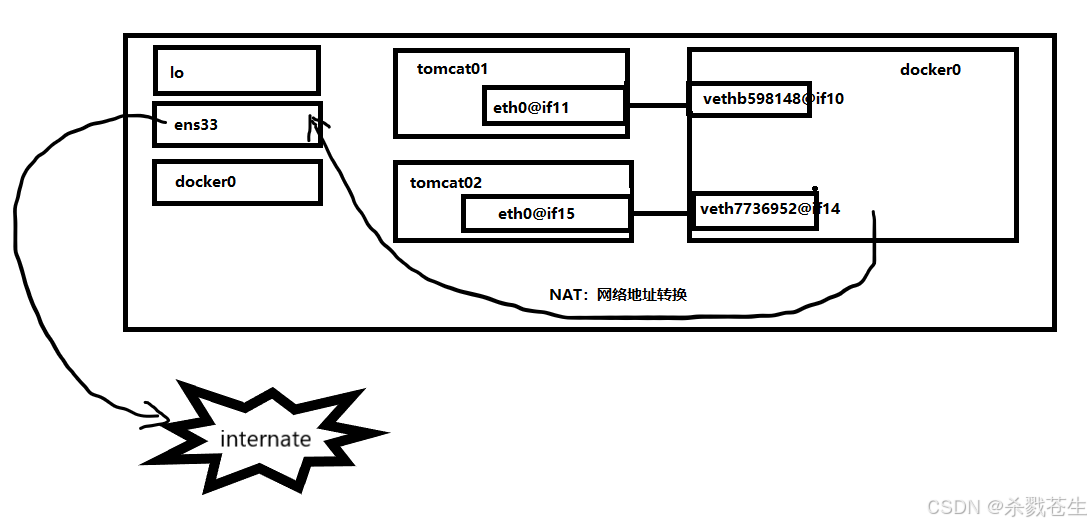
咱们使用 ip netns list 发现不了docker0网桥的,那如何验证宿主机上的两个网卡都在docker0中呢?
开始验证
#安装 网桥工具 bridge-utils
yum install bridge-utils
#执行命令
brctl show
#创建名为<网桥名>的网桥
brctl addbr <网桥名>
#卸载网桥上的端口
brctl delif <网桥名> <端口名>
#查看是否有网桥网卡名
ifconfig
#关闭此网卡
ifconfig <网桥名> down
#删除网桥
brctl delbr <网桥名>
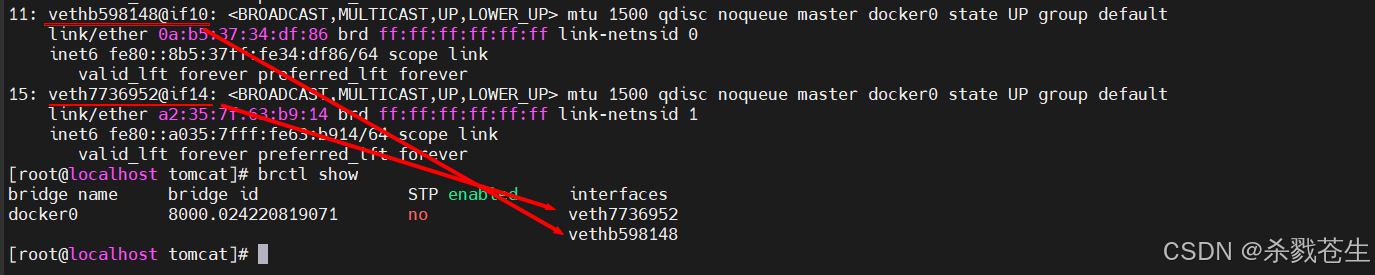 这个时候,咱么就会发现这网桥
这个时候,咱么就会发现这网桥docker0存在连个interfaces分别对应咱们宿主机上的两个网卡。那现在这张图,证明咱们上面画的那张图是正确的。
这种网络连接方式,咱们叫bridge,也就是网桥技术。
容器默认的网络是桥接模式(自己搭建的网络默认使用桥接模式,启动容器默认也是使用桥接模式)。
此模式会为每一个容器分配、设置ip等,并将容器连接到一个docker0虚拟网桥,通过docker0网桥以及iptables nat表配置与宿主机通信。
查看docker的网络模式
通过执行docker network inspect bridge 就会发现,咱们的两个容器tomcat01、tomcat02 都是桥接的。
[root@localhost tomcat]# docker network inspect bridge
[
{
"name": "bridge",
"id": "b6147ac32cc846ab99901aa99d7ec2f820d36e5733acf4bbacee874f07e1205e",
"created": "2023-10-08t09:09:09.869331457+08:00",
"scope": "local",
"driver": "bridge",
"enableipv6": false,
"ipam": {
"driver": "default",
"options": null,
"config": [
{
"subnet": "172.17.0.0/16",
"gateway": "172.17.0.1"
}
]
},
"internal": false,
"attachable": false,
"ingress": false,
"configfrom": {
"network": ""
},
"configonly": false,
"containers": {
"3fe29022223db713b5f3c68bab32355dab8affba51bfaf9b2bb78225884afc13": {
"name": "tomcat02",
"endpointid": "1f114af77950c6c93b93276cb6d27a78560da0bc4d46eac060ff8e43dd3092e1",
"macaddress": "02:42:ac:11:00:03",
"ipv4address": "172.17.0.3/16",
"ipv6address": ""
},
"8469dc9851ec7ce9922c9e3e26ffd81ef9ab08c89553307cb1da76b1198cb8e2": {
"name": "tomcat01",
"endpointid": "9c5d485714eb293a31e64f744a36be714fc78117aec4ceebc7d64e4547348fc3",
"macaddress": "02:42:ac:11:00:02",
"ipv4address": "172.17.0.2/16",
"ipv6address": ""
}
},
"options": {
"com.docker.network.bridge.default_bridge": "true",
"com.docker.network.bridge.enable_icc": "true",
"com.docker.network.bridge.enable_ip_masquerade": "true",
"com.docker.network.bridge.host_binding_ipv4": "0.0.0.0",
"com.docker.network.bridge.name": "docker0",
"com.docker.network.driver.mtu": "1500"
},
"labels": {}
}
]
1.5.3、host模式
host:在此模式下,容器将共享主机的网络堆栈,并且主机的所有接口都可供容器使用。容器的主机名将与主机系统上的主机名匹配。
这就意味着,host模式下的容器将不会虚拟出自己的网卡,配置自己的ip等,而是使用宿主机的ip和端口范围,和宿主机共用一个 network namespace。
使用host模式的容器可以直接使用宿主机的ip地址与外界通信,容器内部的服务端口也可以使用宿主机的端口,不需要进行nat,host最大的优势就是网络性能比较好,但是已经使用的端口就不能再用了,即同一个端口只能同时被一个容器服务绑定,网络的隔离性不好。
如何指定容器为host模式?
docker run -d --name tomcat-host --network host tomcat_custom:1.0.0
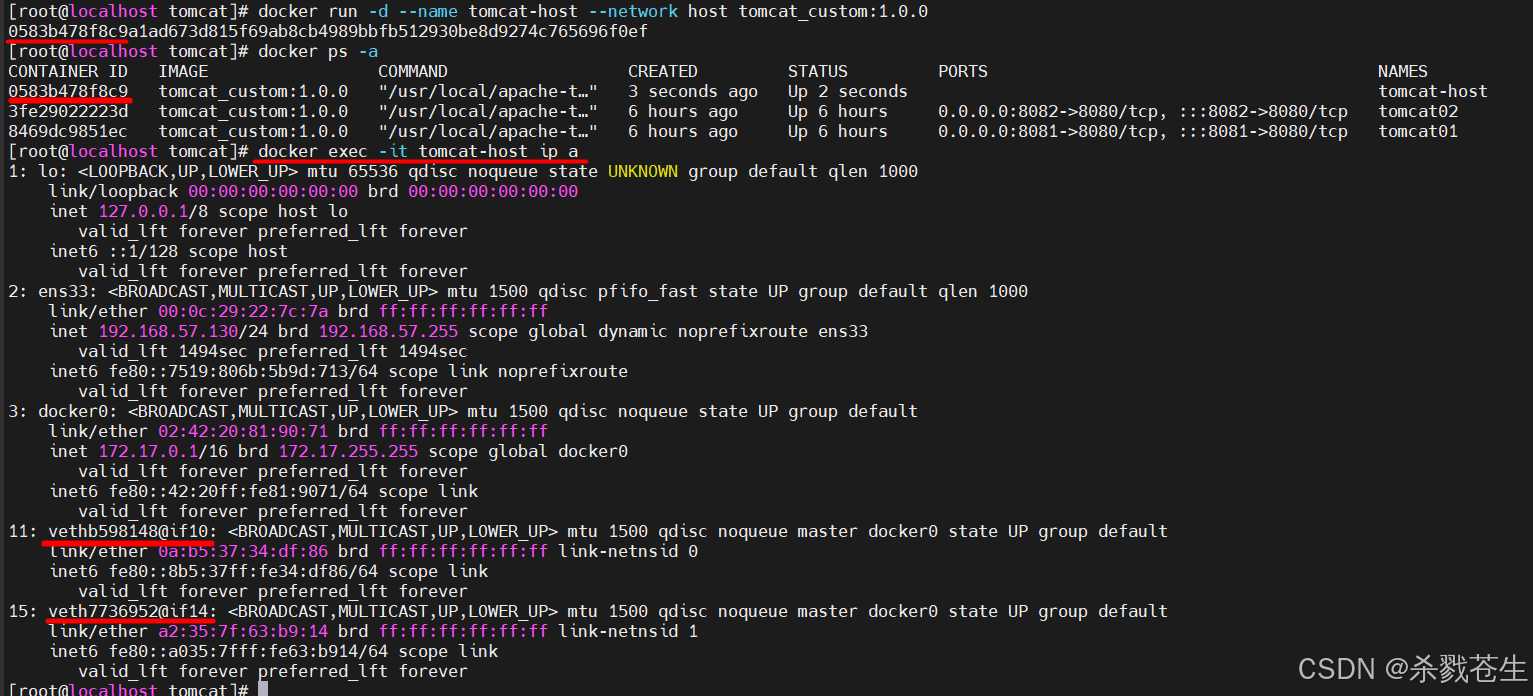 当前容器
当前容器tomcat-host的网卡跟宿主机的完全一样。
#查看docker下host模式的信息
docker network inspect host
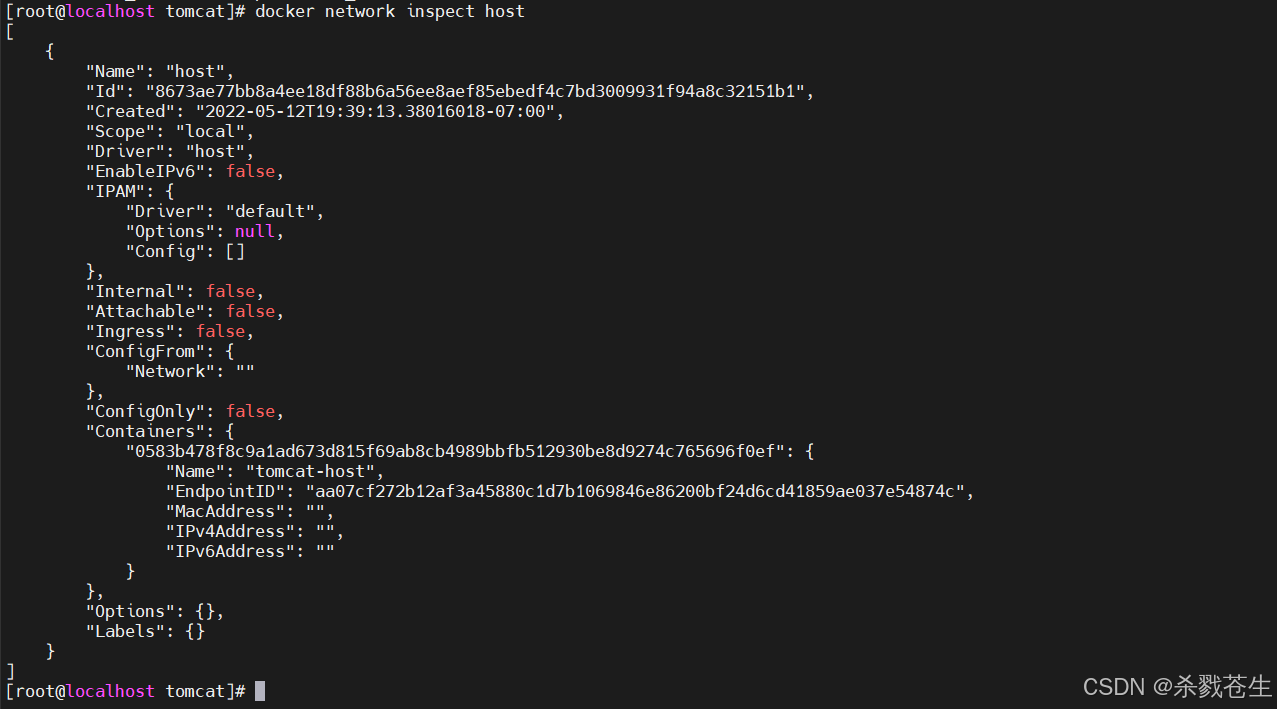 host模式下
host模式下 container内就会存在tomcat-host。而且还会看到ipv4address,macaddress都是空,docker并没有为容器虚拟这些信息。
1.5.4、container模式
这个模式和host模式很像。host模式是和宿主机共用一个network namespace,但是container模式是和已经存在的容器共用一个network namespace。
此模式下:**新创建的容器不会创建自己的网卡,不会配置自己的ip,而是和一个指定的容器共享ip、端口范围等。**同样两个容器除了网络方面相同之外,其他的如文件系统、进程列表等还是隔离的。
注意:
- 当前模式下的容器依赖于其他的容器,如果第一个以bridge方式启动的容器服务挂掉,后面依赖它的容器,都暂停服务。
- 使用此模式,容器一多,依赖关系就会变多,关系之类的就会很乱。企业开发一般不使用此模式,因为太坑。
如何指定容器为container模式?
docker run -d --name tomcat-container --net=container:容器id或容器名称 tomcat_custom:1.0.0
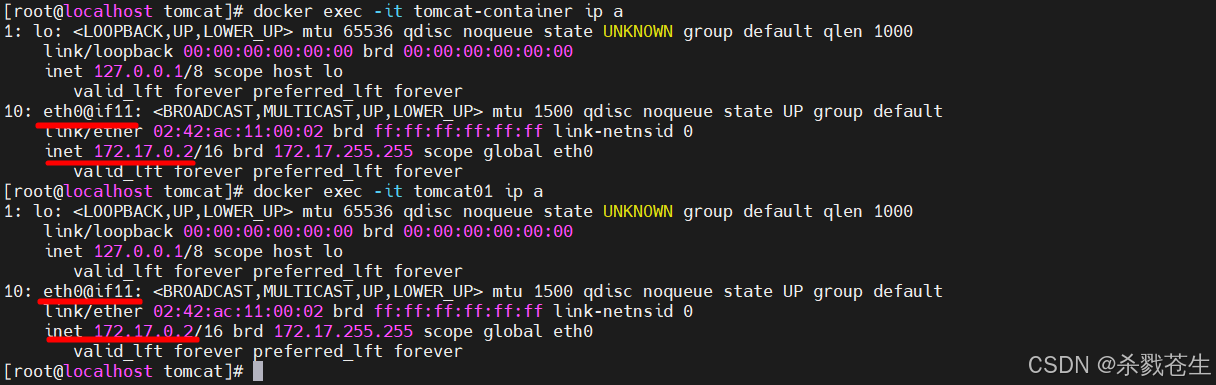 可以看到
可以看到container模式下的容器tomcat-container和bridge模式下tomcat01的网卡信息完全一样。
1.5.5、none模式
none模式不会为容器配置任何ip,也不能访问外部网络以及其他容器,它具有环回地址,可用于运行批处理作业。
如何指定容器为none模式?
docker run -d --name tomcat-none --net=none tomcat_custom:1.0.0
通过下面两图就会发现,当前模式下只有一个lo网卡。

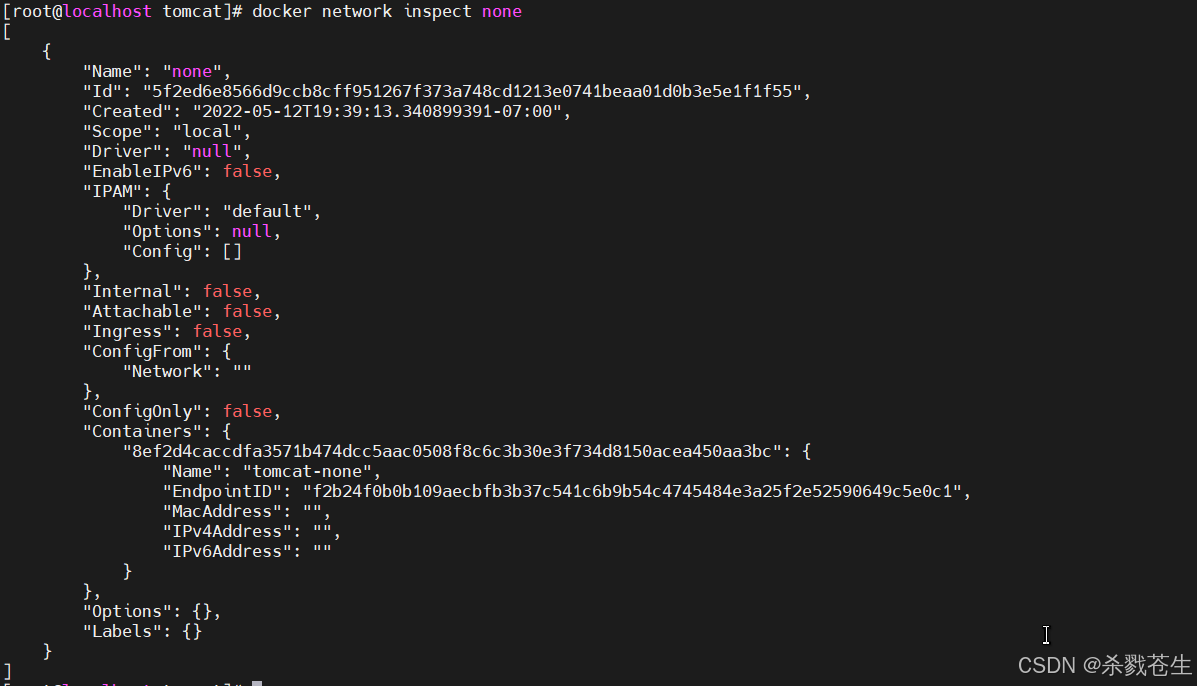
1.5.6、自定义network
#-----------网络---------------
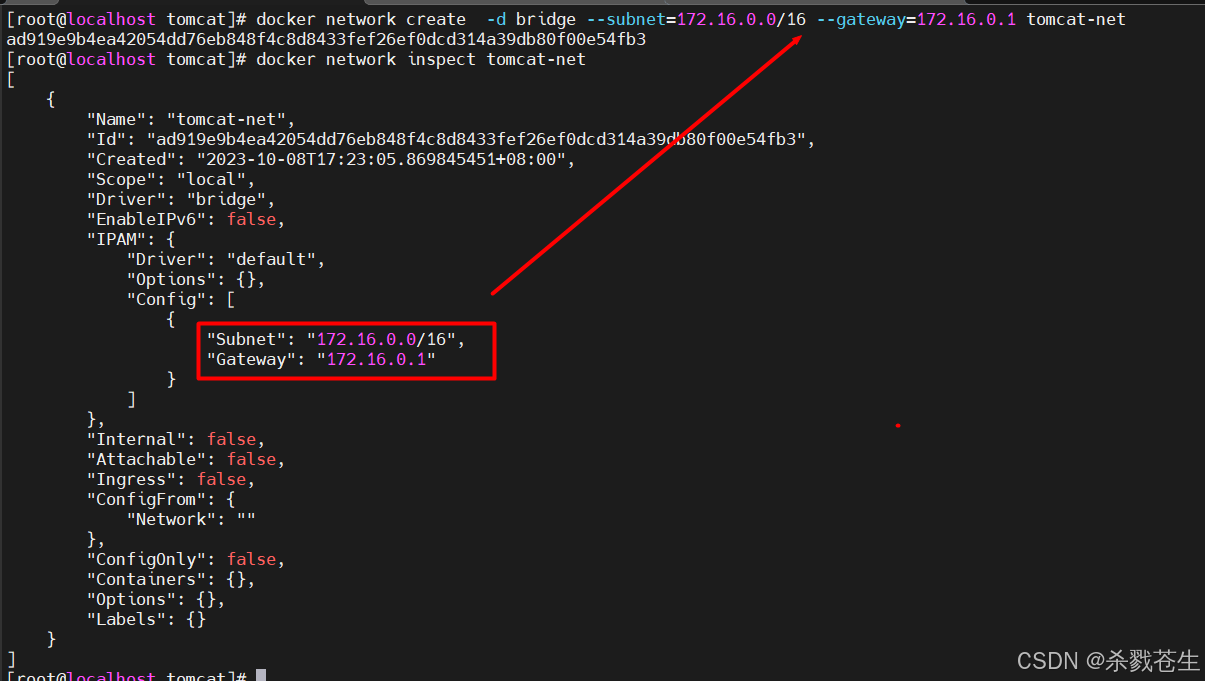
#创建网络
docker network create 网络名称 -d 模式 --subnet=网段/位数 --gateway=网关
#示例
docker network create tomcat-net -d bridge --subnet=172.16.0.0/16 --gateway=172.16.0.1
#删除网络
docker network rm tomcat-net
#查看网络信息
docker network inspect tomcat-net
#-----------容器与网络---------------
#创建容器,并指定网络
docker run -d --name custom-net-tomcat --network tomcat-net tomcat_cusotm:1.0.0
#自定义的网络,其他容器是无法访问的。tomcat01容器链接tomcat-net网络
docker network connect tomcat-net tomcat01
#容器与网络断开
docker network disconnect tomcat-net tomcat01
 创建新的容器,并指定网络。发现ip跟之前的完全不一样。然后,在新建网络的容器中ping旧容器的ip,发现ping不通。
创建新的容器,并指定网络。发现ip跟之前的完全不一样。然后,在新建网络的容器中ping旧容器的ip,发现ping不通。
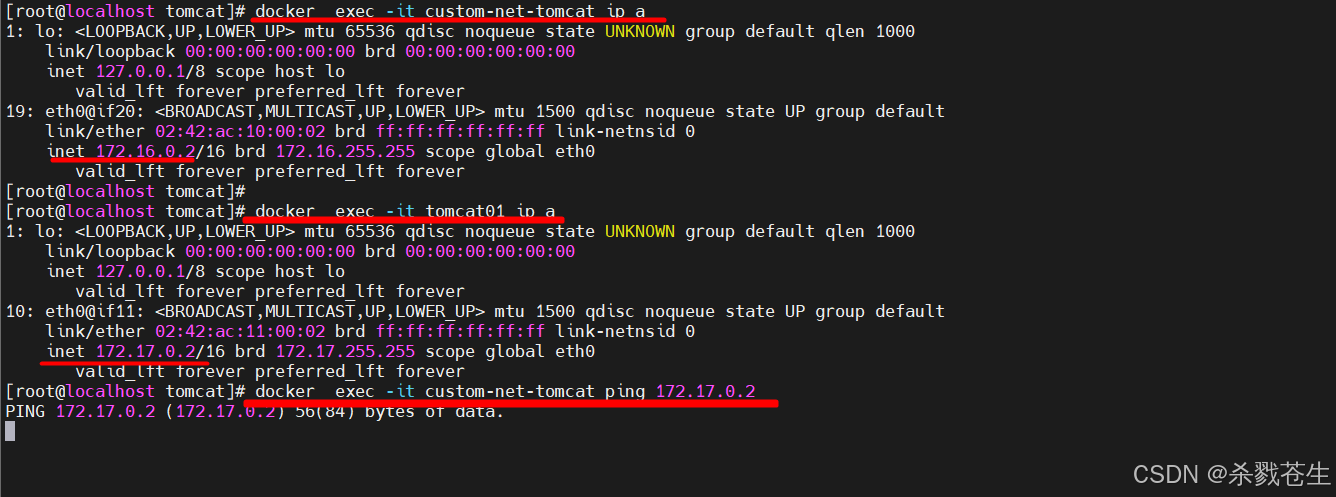
注意:
容器custom-tomcat-net链接的网络tomcat-net,在网络tomcat-net中ip为172.16.0.2容器tomcat01、容器tomcat02链接的网络bridge,ip分别为172.17.0.2、172.17.0.3
然后给 tomcat01增加新的网络tomcat-net
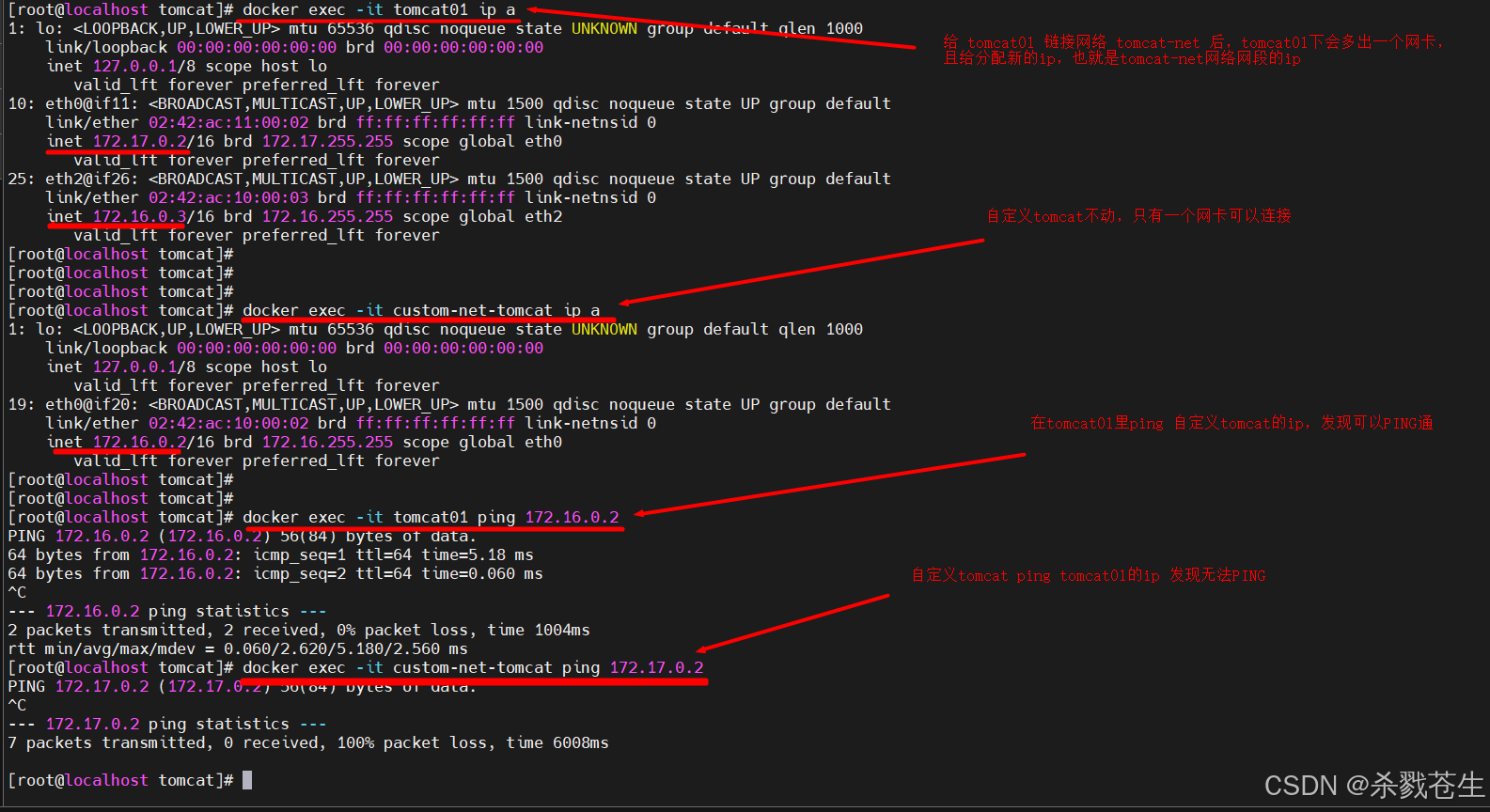 最后发现,要想ping通tomcat01,不能
最后发现,要想ping通tomcat01,不能ping 172.26.17.0.2,要ping 172.16.0.3才行。否则就要给自定义tomcat,增加新的连接网络bridge。
1.6、端口映射
1.6.1、原理
docker容器一般默认使用的是桥接,即在宿主机虚拟出一个docker容器的网桥docker0。
容器启动时,网桥会根据网段分配给容器一个ip地址,同时docker0也就成了每个容器的默认网关。多个容器都接入同一个网桥,这样容器的ip就形成同网段的ip,容器之间就能够通过容器的container-ip直接通信。
网桥docker0是宿主机虚拟出来的,并不是真实存在网络设备,外部网络是无法寻址到的,这也意味着外部网络无法直接通过container-ip访问到容器。
如果容器希望外部访问能访问到,可以通过映射容器端口到宿主主机(端口映射),即 docker run创建容器时通过-p或-p参数来启用,访问容器的时候就通过[宿主机ip]:[容器端口]访问容器 。
1.6.2、容器端口映射
容器的端口映射有四种方式:随机端口映射、指定端口映射、指定网卡随机端口映射、指定网卡端口映射
-
随机端口映射
随机端口映射,就是容器的端口随机映射为宿主机的一个端口。
启动命令里,使用参数-pdocker run -itd -p --name tomcatport1 tomcat_custom:1.0.0

-
指定端口映射
指定端口映射,就是把容器的端口映射为宿主机的指定端口。
启动命令里,使用参数-p 宿主机端口:容器端口docker run -itd -p 8080:8080 --name tomcatport2 tomcat_custom:1.0.0
-
指定网卡随机端口映射
指定网卡随机端口映射:就是把容器的端口映射为宿主机的指定网卡的随机端口。
启动命令里,使用参数-p 宿主机ip::容器端口docker run -itd -p 192.168.57.130::8080 --name tomcatport3 tomcat_custom:1.0.0

-
**指定网卡端口映射 **
指定网卡端口映射:就是把容器的端口映射为宿主机的指定网卡的指定端口。
启动命令里,使用参数-p 宿主机ip:宿主机端口:容器端口docker run -itd -p 192.168.57.130:32770:8080 --name tomcatport4 tomcat_custom:1.0.0
1.7、多机通信
上面说的都是所有通信都是在一个宿主机内,但如果是多机通信呢?
举个例子:咱们应用服务器上有一个服务的容器,但是服务链接的数据库在另一个服务器的容器上,他们是如何通信的呢?
这通信的技术就是:vxlan(virtual extensible lan,虚拟可扩展局域网)。
其原理就是:在现有ip网络上创建一个逻辑的二层网络,实现不同物理网络之间的互通。
vxlan是一种虚拟化技术,旨在解决传统局域网(lan)无法覆盖大规模、分布式环境的问题。
在这个章节【网络模型和概念模型】咱们可以看到在请求中,报文封装了四层。
在vxlan中原始二层报文的基础上在进行了封装。中间的报文则决定了之后报文发送的方向。

2、dockercompose
2.1、简介
compose 是用于定义和运行多容器 docker 应用程序的工具。
通过 compose,您可以使用 yml 文件来配置应用程序需要的所有服务。然后,使用一个命令,就可以从 yml 文件配置中创建并启动所有服务。即一键启动所有的服务。
dockercompose的使用步骤
- 创建对应的dockerfile文件
- 创建yml文件,在yml文件中编排我们的服务
- 通过
docker-compose up命令 一键运行我们的容器
2.2、compose的安装
dockercompose官网地址:https://docs.docker.com/compose
#使用github下载compose
sudo curl -l "https://github.com/docker/compose/releases/download/1.29.2/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose
#速度比较慢的话使用下面的地址:
curl -l https://get.daocloud.io/docker/compose/releases/download/1.25.0/docker-compose-`uname -s`-`uname -m` > /usr/local/bin/docker-compose
#这个地方踩了一个不大不小的坑。。。
#大家下载的时候看一下啊。 `uname -s` 结果是`linux`才能下载,我这下载了两次都没下载下来。最后找了半天的错误,才发现的。。。人家的名字叫`docker-compose-linux-x86_64`,我下载的是`docker-compose-linux-x86_64`,路径不对哈,下载不下来的。
#个人推荐直接进github下的docker-compose-releases页面(https://github.com/docker/compose/releases)找一下最新版本哈。
#当然,如果自己有yum的话,可以执行yum安装命令。
yum install docker-compose-plugin.x86_64
#额。。。公司的网,github打不开,下不下来,我这直接yum下载的。。
#使用`yum` 安装完了,使用find命令找一下安装文件。
[root@localhost cli-plugins]# find / -name docker-compose
/usr/libexec/docker/cli-plugins/docker-compose
修改文件夹权限
#下载的
chmod +x /usr/local/bin/docker-compose
#yum安装的
chmod +x /usr/libexec/docker/cli-plugins/docker-compose
建立软连接
#想要使docker-compose命令生效,需要将这个命令,放到/usr/local/bin/下。可以建立链接,也可以直接拷贝文件。
#不过我不建议拷贝文件,因为文件内部可能存在相对路径导致命令执行的失败。建议建立链接。链接大家可以理解为windows里的快捷方式。
#下载的
ln -s /usr/local/bin/docker-compose /usr/bin/docker-compose
#yum安装的。链接文件应该是放到/usr/bin/才对,但是不知道为啥,我这直接执行docker-compose命令的时候,linux往/usr/local/bin/下找docker-compose这个文件。emmm。。。所以我只能将链接建到/usr/local/bin/下了。
ln -s /usr/libexec/docker/cli-plugins/docker-compose /usr/local/bin/docker-compose
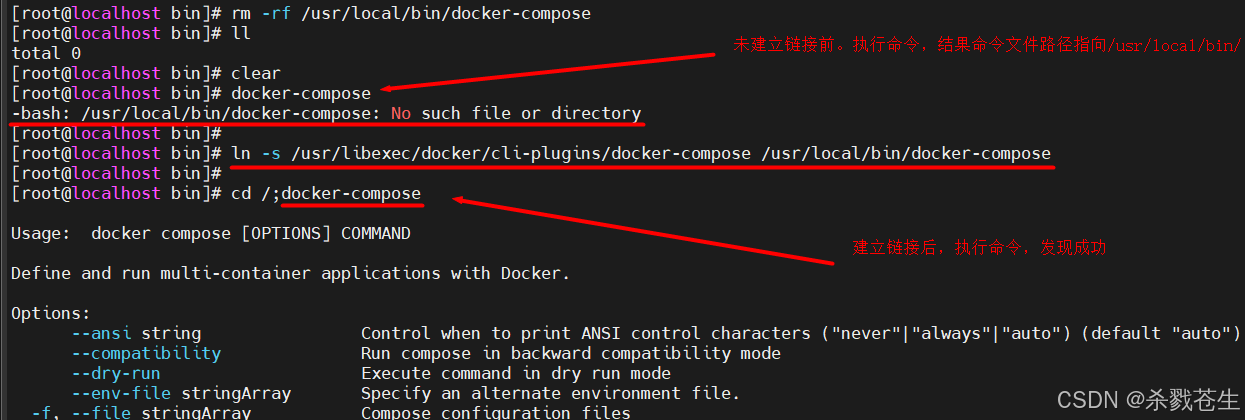 校验是否安装成功
校验是否安装成功
docker-compose --version

2.3、compose初体验
注意:使用前compose前,请先确定一下当前docker的版本,是否支持你的compose文件的版本
官网:
关于如何使用docker-compose官网给与了使用案例
英文的不好读,咱们按照案例执行一下:
#第一步: 在opt下创建composetest目录,并进入当前目录
cd /opt;mkdir composetest;cd composetest;
#第二步:创建 app.py 文件,并写入以下内容。咱们直接使用tee命令来做这件事
sudo tee app.py <<-'eof'
import time
import redis
from flask import flask
app = flask(__name__)
cache = redis.redis(host='redis', port=6379)
def get_hit_count():
retries = 5
while true:
try:
return cache.incr('hits')
except redis.exceptions.connectionerror as exc:
if retries == 0:
raise exc
retries -= 1
time.sleep(0.5)
@app.route('/')
def hello():
count = get_hit_count()
return 'hello world! i have been seen {} times.\n'.format(count)
eof
#第三步:创建 requirements.txt 文件,并写入以下内容。咱们直接使用tee命令来做这件事
sudo tee requirements.txt <<-eof
flask
redis
eof
#第四步:创建 dockerfile 文件,并写入以下内容。咱们直接使用tee命令来做这件事
tee dockerfile <<-eof
# syntax=docker/dockerfile:1
from python:3.7-alpine
workdir /code
env flask_app=app.py
env flask_run_host=0.0.0.0
run apk add --no-cache gcc musl-dev linux-headers
copy requirements.txt requirements.txt
run pip install -r requirements.txt
expose 5000
copy . .
cmd ["flask", "run"]
eof
#第五步:创建compose.yaml文件,并写入以下内容。咱们直接使用tee命令来做这件事
tee compose.yaml <<-eof
services:
web:
build: .
ports:
- "8000:5000"
redis:
image: "redis:alpine"
eof
#第六步:启动 compose
docker compose up
注意:启动compose这个比较慢哈。。。我这整整起了3小时+。。。早上11点开始的,中午睡了一觉,1点半起来发现还没加载完。
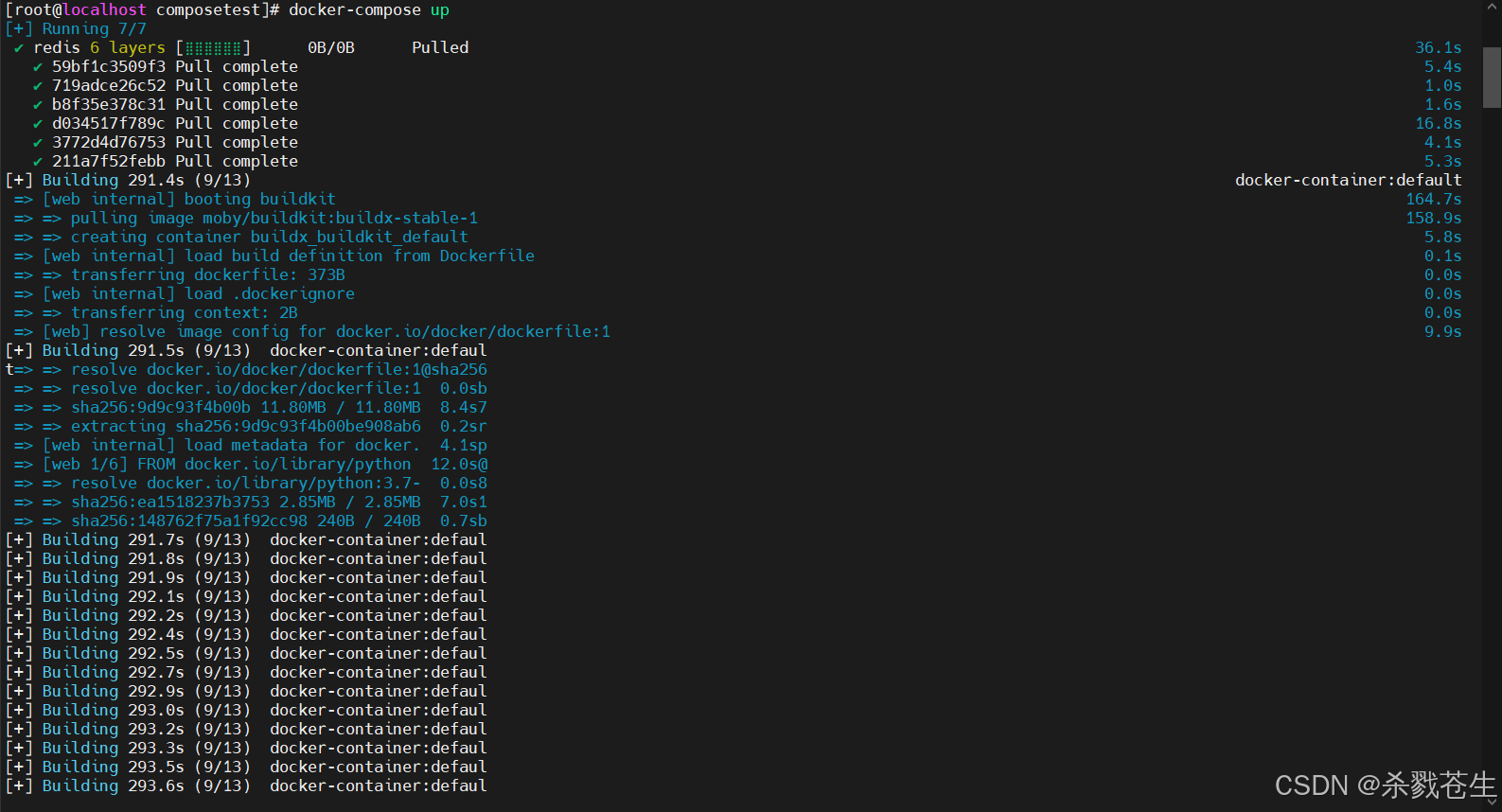 省略中间不知道多少日志。。。
省略中间不知道多少日志。。。
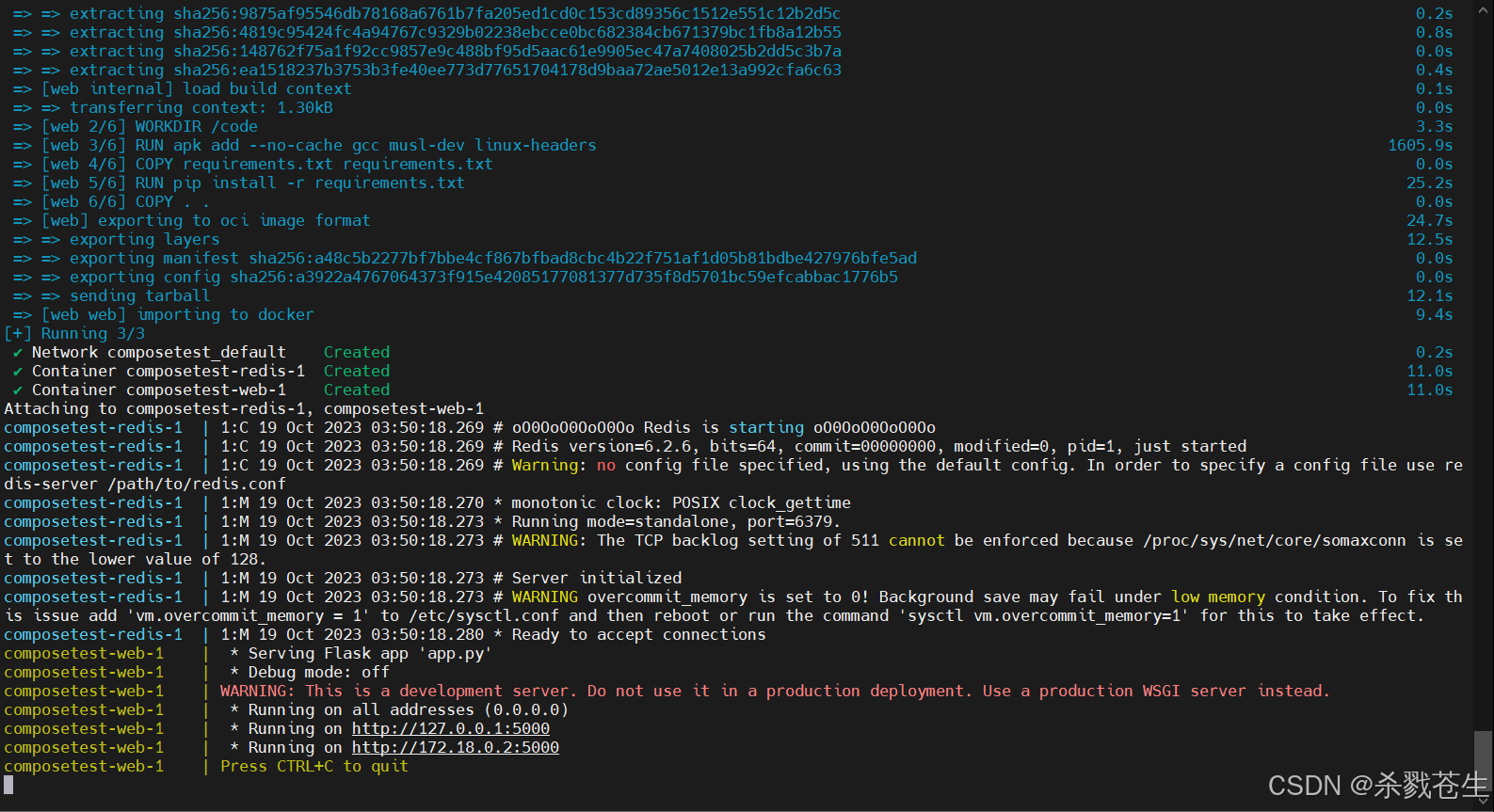 测试:composetest-web
测试:composetest-web
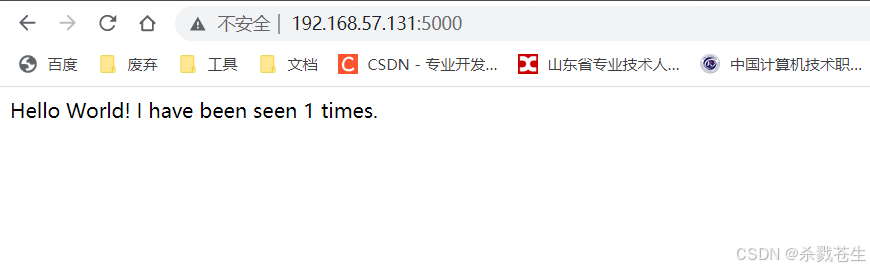
终止compose
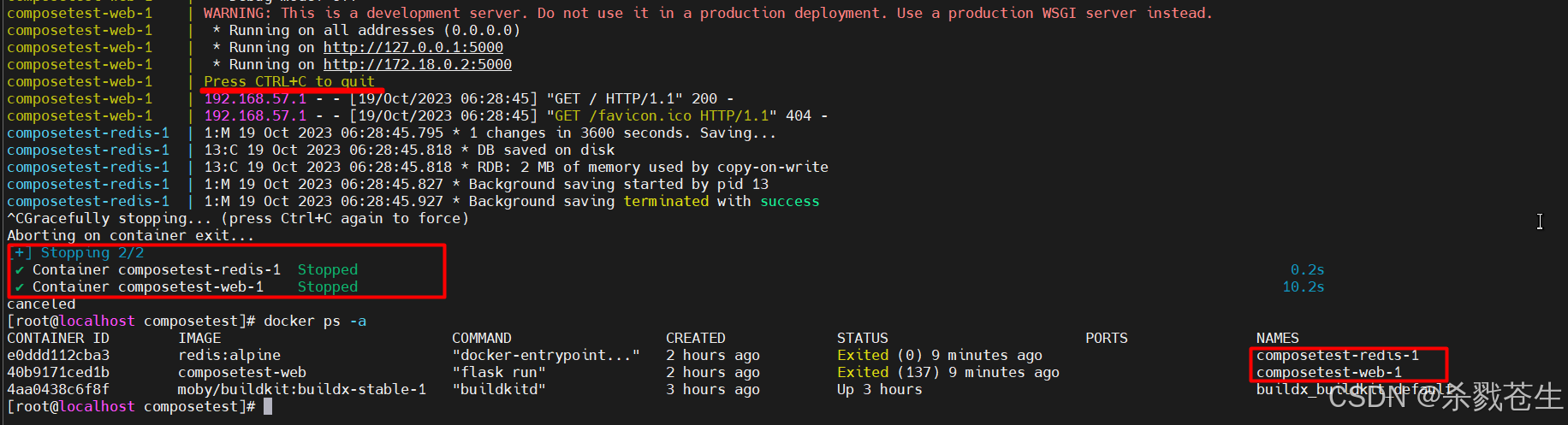 发现关闭了两个容器,和
发现关闭了两个容器,和 compose.yaml里配置的完全对的上。至于buildx_buildkit_default那个是pthoy的一个类库。
2.4、compose.yml规则
配置文件的规则:
- 官网地址:service configuration
- 另外推荐一篇博客:
2.5、compose部署实战
2.5.1、一键部署wp博客
以wp博客为例
#1、创建该目录,并进入该目录
mkdir my_wordpress; cd my_wordpress
#2、使用tee命令,创建docker-compose.yml文件,并写入内容
tee docker-compose.yml <<-eof
version: "3.9"
services:
db:
image: mysql:5.7
volumes:
- db_data:/var/lib/mysql
restart: always
environment:
mysql_root_password: somewordpress
mysql_database: wordpress
mysql_user: wordpress
mysql_password: wordpress
wordpress:
depends_on:
- db
image: wordpress:latest
volumes:
- wordpress_data:/var/www/html
ports:
- "8000:80"
restart: always
environment:
wordpress_db_host: db:3306
wordpress_db_user: wordpress
wordpress_db_password: wordpress
wordpress_db_name: wordpress
volumes:
db_data: {}
wordpress_data: {}
eof
#3、启动docker-compose
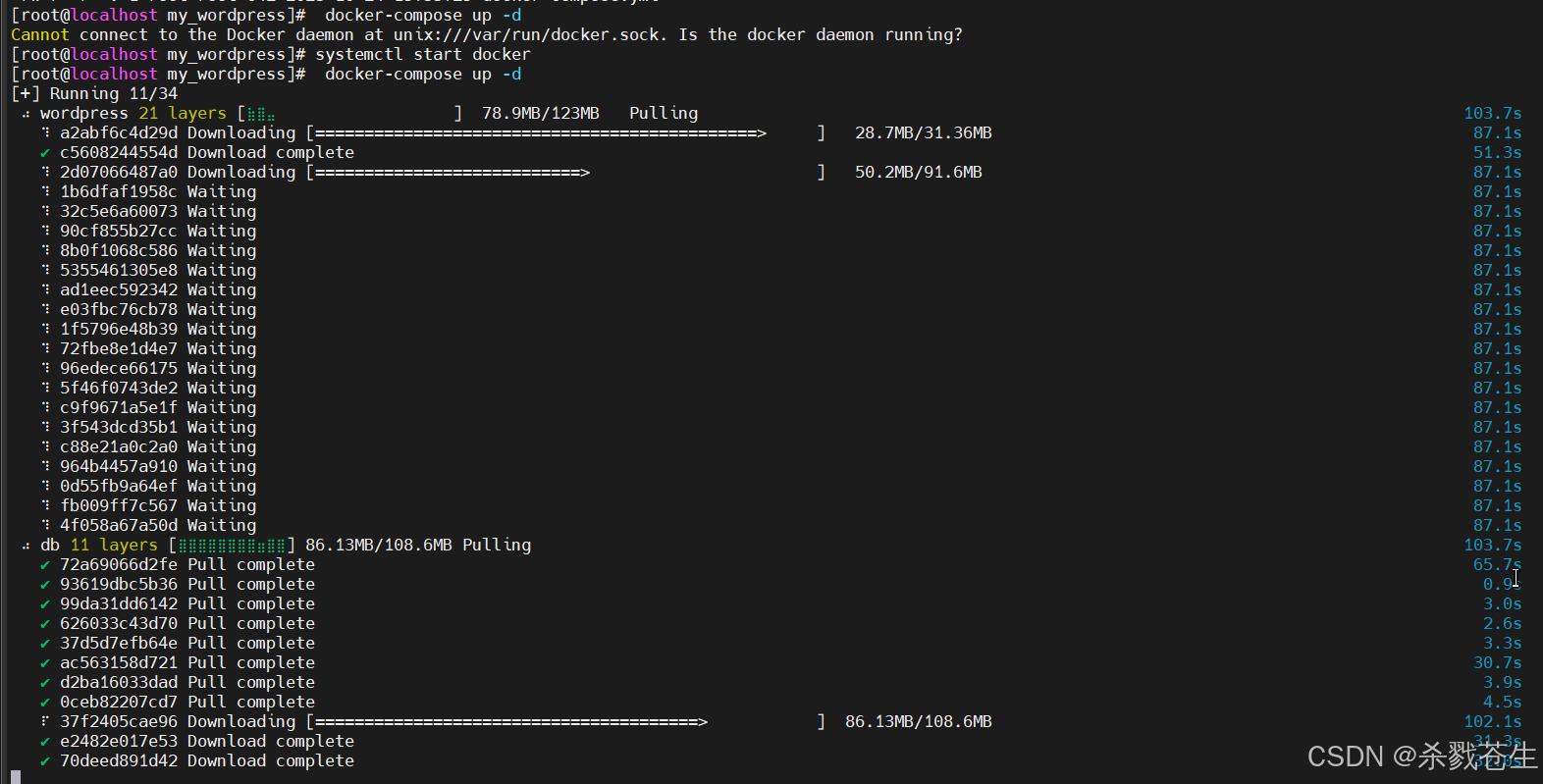
docker-compose up -d
报错:
错误信息1:
cannot connect to the docker daemon at unix:///var/run/docker.sock. is the docker daemon running?
出现该错误,是因为docker没启动哈。
使用命令启动docker
systemctl start docker
错误信息2:
no configuration file provided: not found
出现该错误,是因为当前所在目录不对,要切换到docker-compose.yml文件所在目录,再执行启动命令
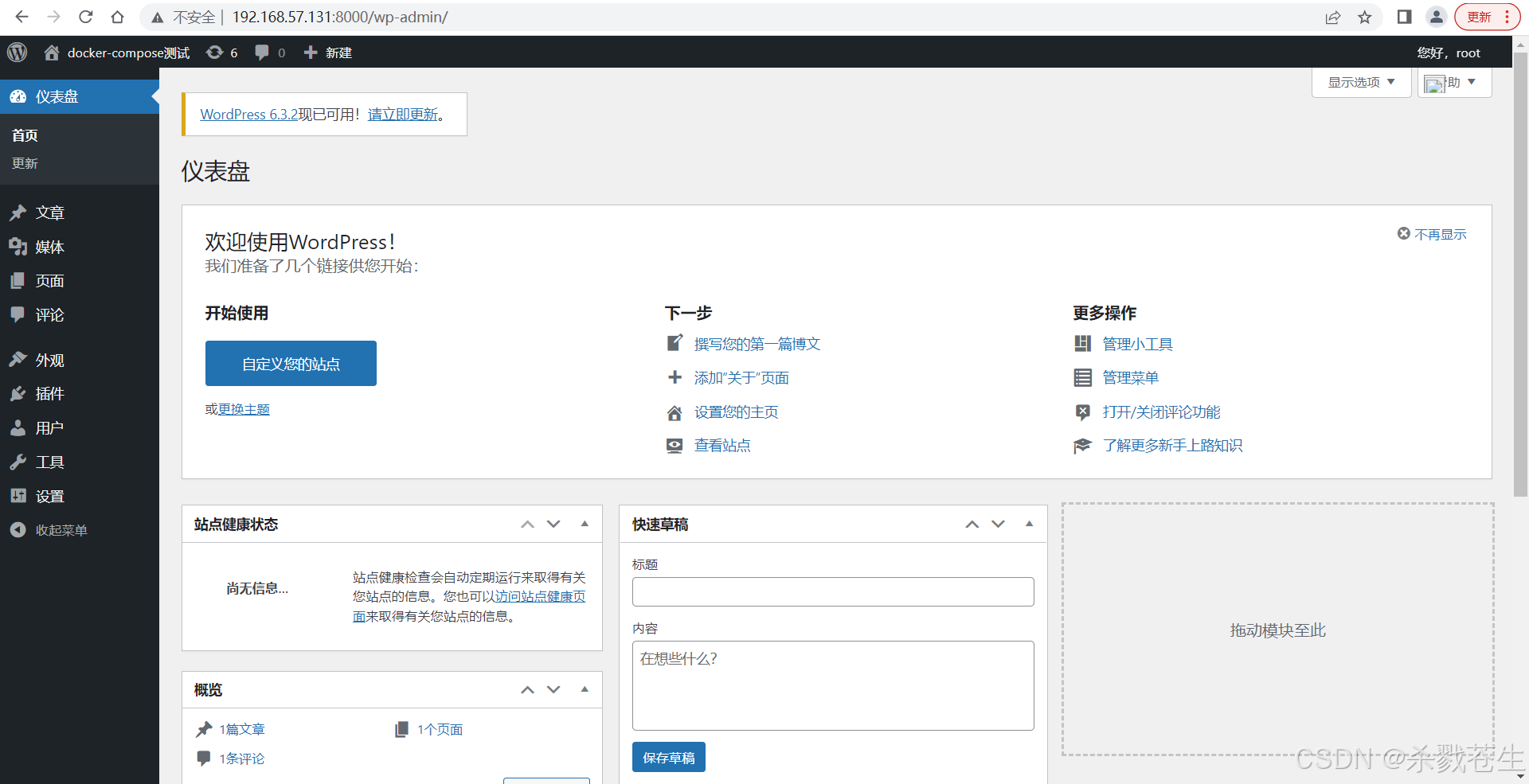
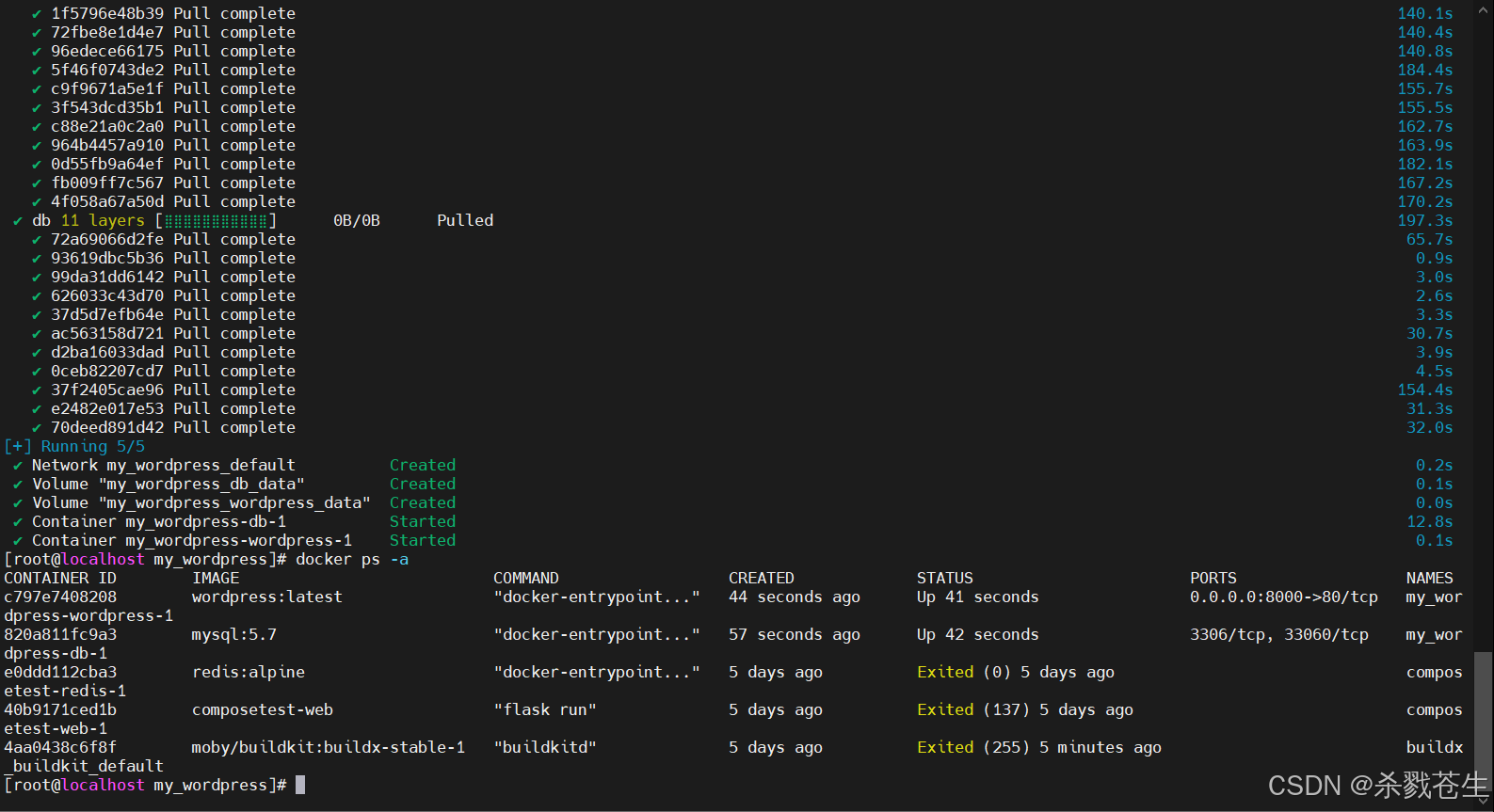 测试,项目是否可以:
测试,项目是否可以:
2.5.2、部署一个springcloud项目
临时写一个项目太麻烦了,自己现在做的项目有很多不能往外写。所以咱们以开源项目ruoyi-cloud-v3.5.0为例。
下载代码:
我这项目是github上下载的。码云上tag没有3.5.0的版本,大家注意哈!
写自己的compose.yml。。。好吧!突然发现人家给提供了。。
version: '3.8'
services:
ruoyi-nacos:
container_name: ruoyi-nacos
image: nacos/nacos-server
build:
context: ./nacos
environment:
- mode=standalone
volumes:
- ./nacos/logs/:/home/nacos/logs
- ./nacos/conf/application.properties:/home/nacos/conf/application.properties
ports:
- "8848:8848"
- "9848:9848"
- "9849:9849"
depends_on:
- ruoyi-mysql
ruoyi-mysql:
container_name: ruoyi-mysql
image: mysql:5.7
build:
context: ./mysql
ports:
- "3306:3306"
volumes:
- ./mysql/conf:/etc/mysql/conf.d
- ./mysql/logs:/logs
- ./mysql/data:/var/lib/mysql
command: [
'mysqld',
'--innodb-buffer-pool-size=80m',
'--character-set-server=utf8mb4',
'--collation-server=utf8mb4_unicode_ci',
'--default-time-zone=+8:00',
'--lower-case-table-names=1'
]
environment:
mysql_database: 'ry-cloud'
mysql_root_password: password
ruoyi-redis:
container_name: ruoyi-redis
image: redis
build:
context: ./redis
ports:
- "6379:6379"
volumes:
- ./redis/conf/redis.conf:/home/ruoyi/redis/redis.conf
- ./redis/data:/data
command: redis-server /home/ruoyi/redis/redis.conf
ruoyi-nginx:
container_name: ruoyi-nginx
image: nginx
build:
context: ./nginx
ports:
- "80:80"
volumes:
- ./nginx/html/dist:/home/ruoyi/projects/ruoyi-ui
- ./nginx/conf/nginx.conf:/etc/nginx/nginx.conf
- ./nginx/logs:/var/log/nginx
- ./nginx/conf.d:/etc/nginx/conf.d
depends_on:
- ruoyi-gateway
links:
- ruoyi-gateway
ruoyi-gateway:
container_name: ruoyi-gateway
build:
context: ./ruoyi/gateway
dockerfile: dockerfile
ports:
- "8080:8080"
depends_on:
- ruoyi-redis
links:
- ruoyi-redis
ruoyi-auth:
container_name: ruoyi-auth
build:
context: ./ruoyi/auth
dockerfile: dockerfile
ports:
- "9200:9200"
depends_on:
- ruoyi-redis
links:
- ruoyi-redis
ruoyi-modules-system:
container_name: ruoyi-modules-system
build:
context: ./ruoyi/modules/system
dockerfile: dockerfile
ports:
- "9201:9201"
depends_on:
- ruoyi-redis
- ruoyi-mysql
links:
- ruoyi-redis
- ruoyi-mysql
ruoyi-modules-gen:
container_name: ruoyi-modules-gen
build:
context: ./ruoyi/modules/gen
dockerfile: dockerfile
ports:
- "9202:9202"
depends_on:
- ruoyi-mysql
links:
- ruoyi-mysql
ruoyi-modules-job:
container_name: ruoyi-modules-job
build:
context: ./ruoyi/modules/job
dockerfile: dockerfile
ports:
- "9203:9203"
depends_on:
- ruoyi-mysql
links:
- ruoyi-mysql
ruoyi-modules-file:
container_name: ruoyi-modules-file
build:
context: ./ruoyi/modules/file
dockerfile: dockerfile
ports:
- "9300:9300"
volumes:
- ./ruoyi/uploadpath:/home/ruoyi/uploadpath
ruoyi-visual-monitor:
container_name: ruoyi-visual-monitor
build:
context: ./ruoyi/visual/monitor
dockerfile: dockerfile
ports:
- "9100:9100"
然后在服务器compose.yml文件的位置,执行docker-compse up -d即可。
2.5.3、部署一个springboot项目
上面那个项目,人家都弄好了,不算实操。
咱们新建一个springboot项目,引入redis,一个democontroller,一个无参的post请求,返回一个简单的字符串,其他的什么都不加。
#dockerfile
from java:8
copy my-0.0.1-snapshot.jar demo.jar
expose 8080
cmd ["java","-jar","demo.jar"]
#docker-compose.yml。将两个放到同一文件夹下,进行执行。
version: '3.8'
services:
myapp:
build: .
image: demo
depends_on:
- redis
ports:
- "8080:8080"
redis:
image: "library/redis:alpine"
2.6、docker-compse的命令
2.6.1、查看版本号
#查看版本号:
docker-compose version
2.6.2、执行compose文件
#执行compose文件
docker-compose up
#指定yml文件启动
docker-compose up -f filename.xml
#后台启动
docker-compose up -d
2.6.3、查看所有服务/容器
# 列出工程中所有服务的容器
docker-compose ps
# 列出工程中指定服务的容器
docker-compose ps tomcat
2.6.4、拉取服务依赖的镜像
#镜像拉取,拉取服务的依赖镜像。跟docker pull,不一样,docker pull是直接拉取镜像
#拉取工程中所有服务依赖的镜像
docker-compose pull
#拉取工程中 nginx 服务依赖的镜像
docker-compose pull tomcat
#拉取镜像过程中不打印拉取进度信息
docker-compose pull -q
2.6.5、查看docker-compose的images
#查看所有服务的容器所对应的镜像
docker-compose images
#查看指定服务的容器所对应的镜像
docker-compose images tomcat
2.6.6、启动/暂停/停止/重启/杀死服务
语法:docker-compose [start|pause|stop|restart|kill] [service...]
# 启动/暂停/停止/重启工程中所有服务的容器
docker-compose start|pause|stop|restart|kill
# 启动/暂停/停止/重启工程中指定服务的容器
docker-compose start|pause|stop|restart|kill tomcat
2.6.7、删除服务
# 删除所有(停止状态)服务的容器
docker-compose rm
# 先停止所有服务的容器,再删除所有服务的容器
docker-compose rm -s
# 不询问是否删除,直接删除
docker-compose rm -f
# 删除服务容器挂载的数据卷
docker-compose rm -v
# 删除工程中指定服务的容器
docker-compose rm -sv nginx
2.6.8、删除服务及其所有相关内容
#停止并删除工程中所有服务的容器、网络、镜像、数据卷
docker-compose down
# 停止并删除工程中所有服务的容器、网络、镜像
docker-compose down --rmi all
# 停止并删除工程中所有服务的容器、网络、数据卷
docker-compose down -v
2.8.9、指定端口映射
#指定服务容器的某个端口所映射的宿主机端口。 注意:端口映射还有其他语法
docker-compose port tomcat 80
2.8.10、显示正在运行的进程
# 显示工程中所有服务的容器正在运行的进程
docker-compose top
# 显示工程中指定服务的容器正在运行的进程
docker-compose top tomcat
2.8.11、进入服务
# 进入工程中指定服务的容器
docker-compose exec nginx bash
# 当一个服务拥有多个容器时,可通过 --index 参数进入到该服务下的任何容器
docker-compose exec --index=1 tomcat bash
2.8.12、日志
# 输出日志,不同的服务输出使用不同的颜色来区分
docker-compose logs
# 跟踪日志输出
docker-compose logs -f
# 关闭颜色
docker-compose logs --no-color
2.8.13、在服务上运行命令
# 在工程中指定服务的容器上执行 echo "helloworld"
docker-compose run tomcat echo "helloworld"
2.7 集群扩容scale
一般当咱们使用docker-compose的时候,很多时候,是会出现集群方面的管理。
一旦出现集群,就会涉及到服务的扩容,缩容等方面的问题。例如:redis,每次扩容缩容是需要修改配置文件,然后再重启服务,特麻烦。
于是,docker-compose就提供了这方面的功能。
#将redis服务进行扩容到5个,且后台运行。
docker-compose up --scale redis=5 -d
3、常用的镜像私服仓库
3.1、docker hub

在服务器上直接输入docker login,输入用户名密码,即可登录。
 推送之前【2.5.3】我们构建的
推送之前【2.5.3】我们构建的demo.jar的镜像到docker hub上
#docker push 你的登录用户名/镜像名称。注意镜像名称的命名,否则push不成功
docker push username/demo
下载
docker pull username/demo
如果,你想查看你推送的。可以登录官网地址:hub.docker.com,输入username/demo,就能查看到了。
3.2、阿里云docker registry
3.2.1、创建阿里云私服
访问地址:https://cr.console.aliyun.com/cn-hangzhou/instances
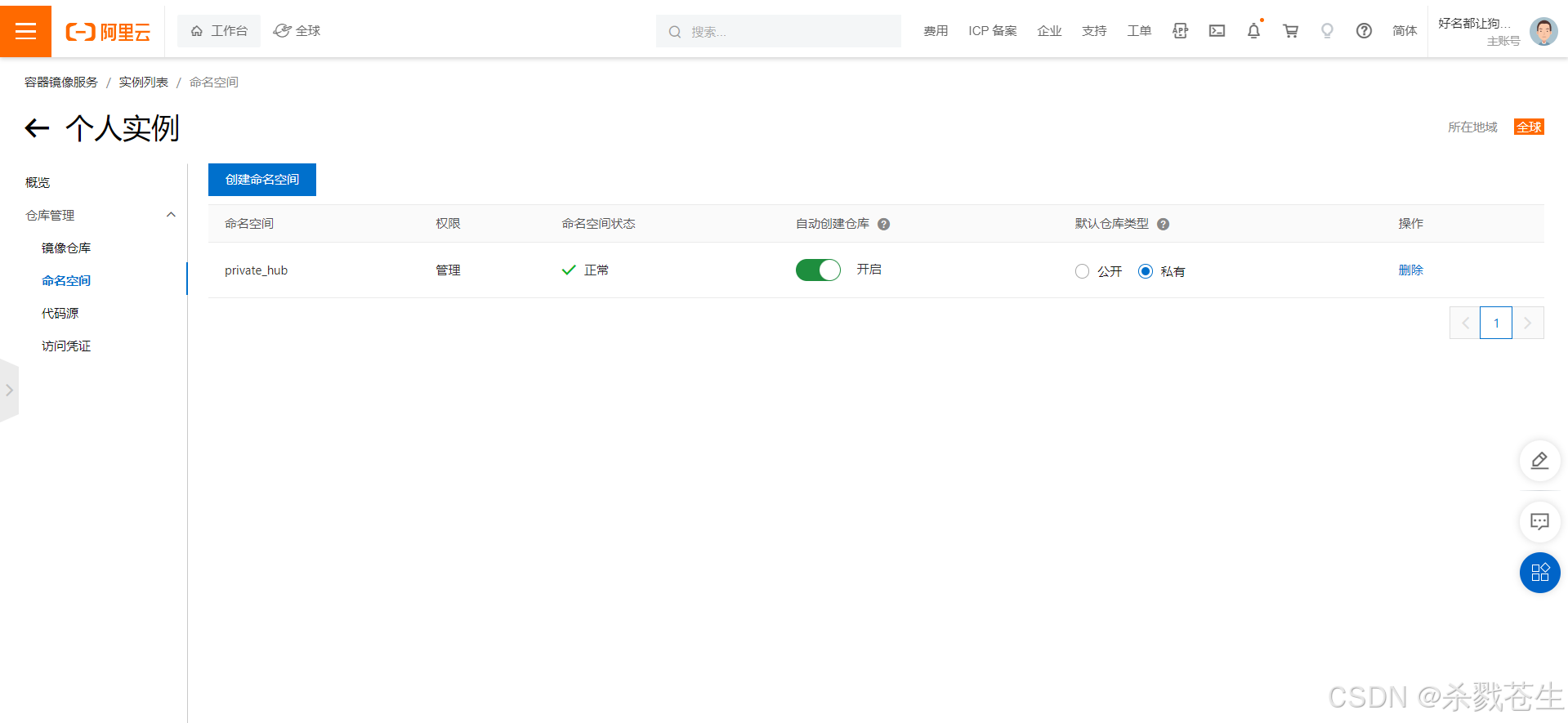
创建私人仓库:点击创建个人实例—>同意授权–>填写仓库信息–>立即购买(好像不支付也可以,忘了咋操作的了)
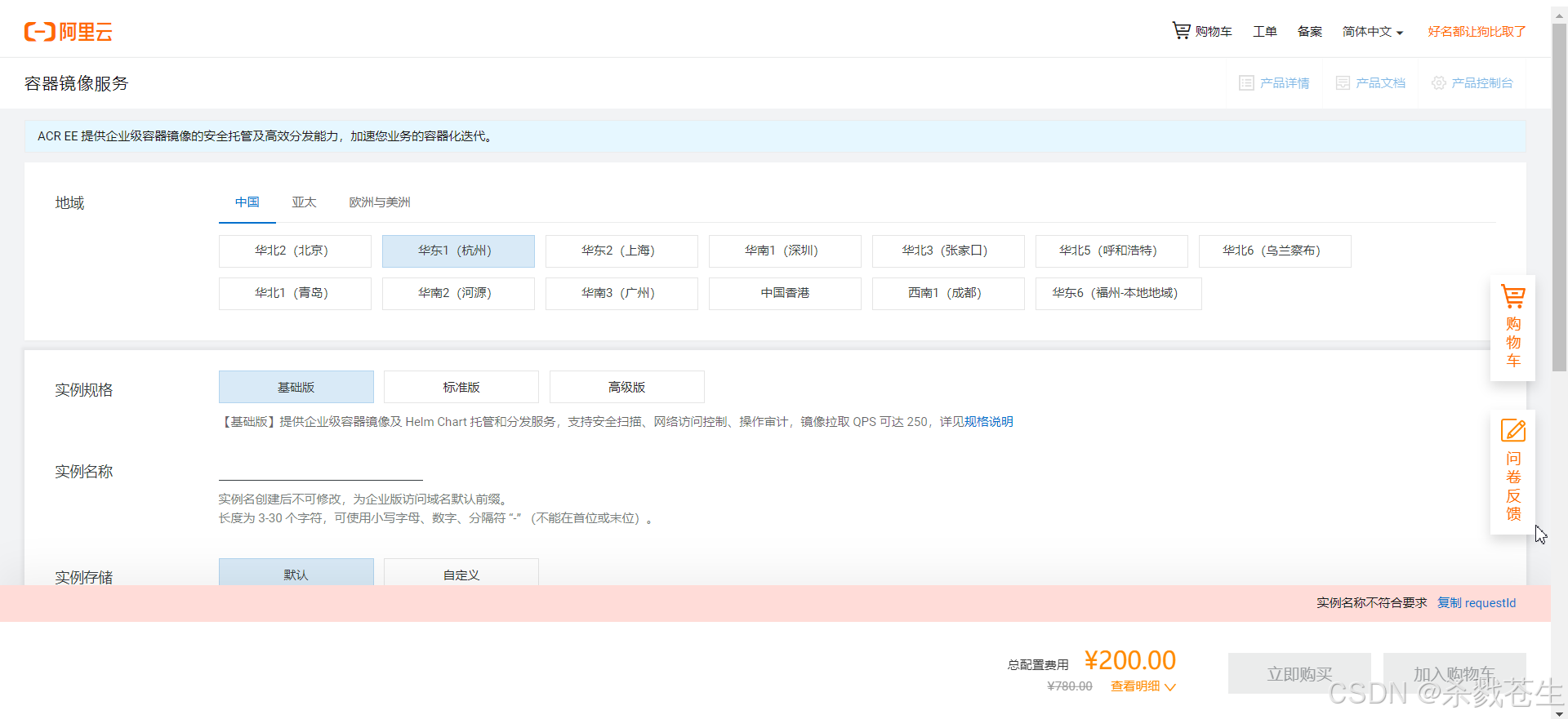
命名空间–>创建命名空间
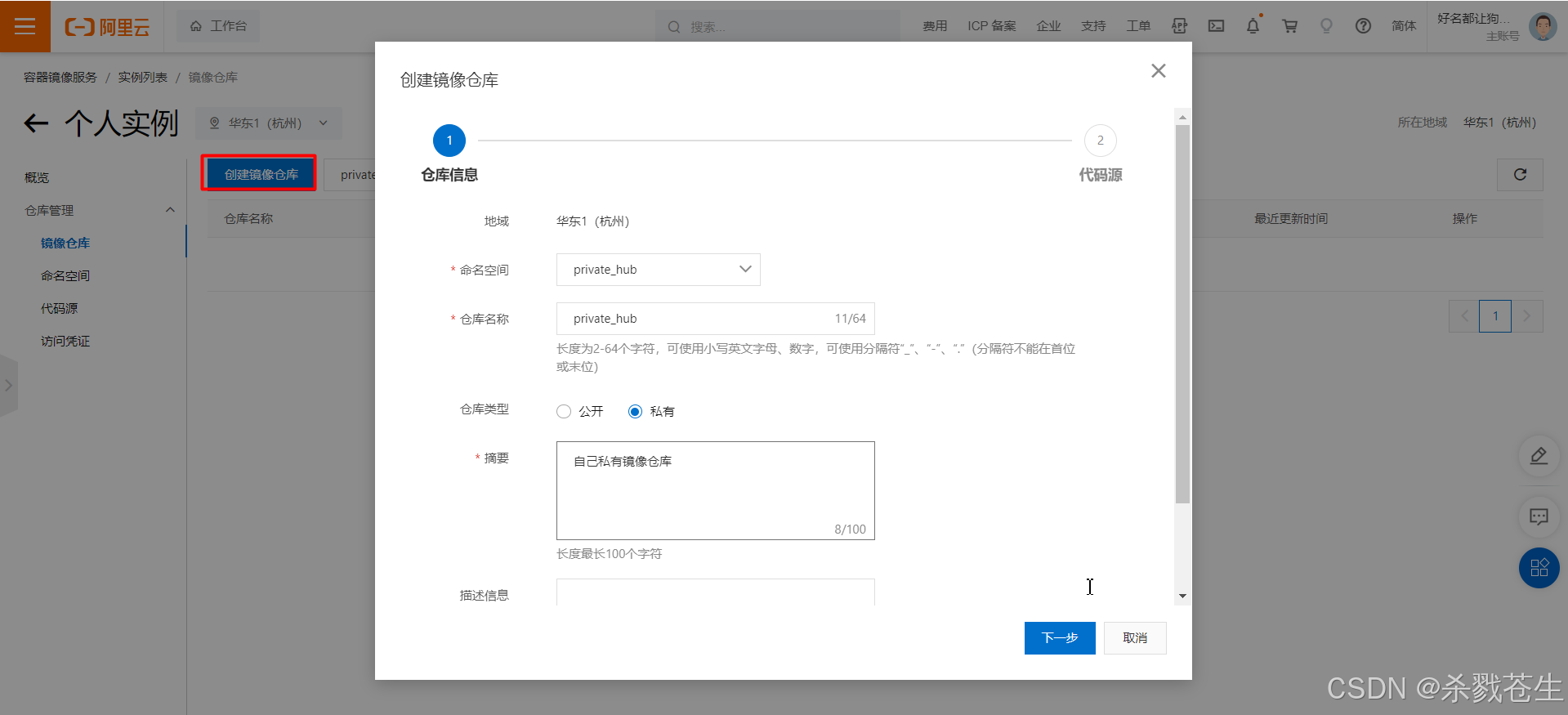
镜像仓库–>创建镜像仓库–>下一步
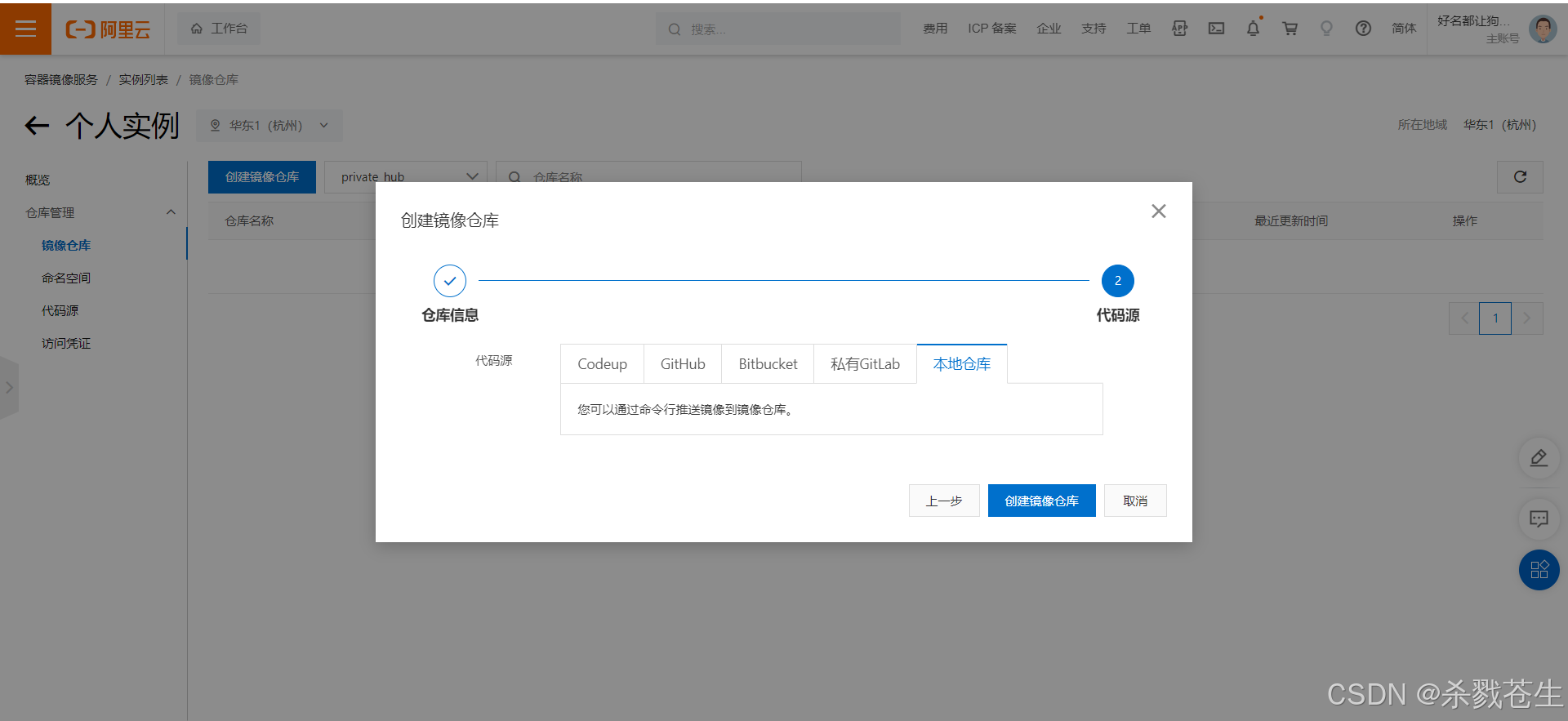
填写代码源–>选择本地仓库–>创建镜像仓库
创建成功,尝试登录。
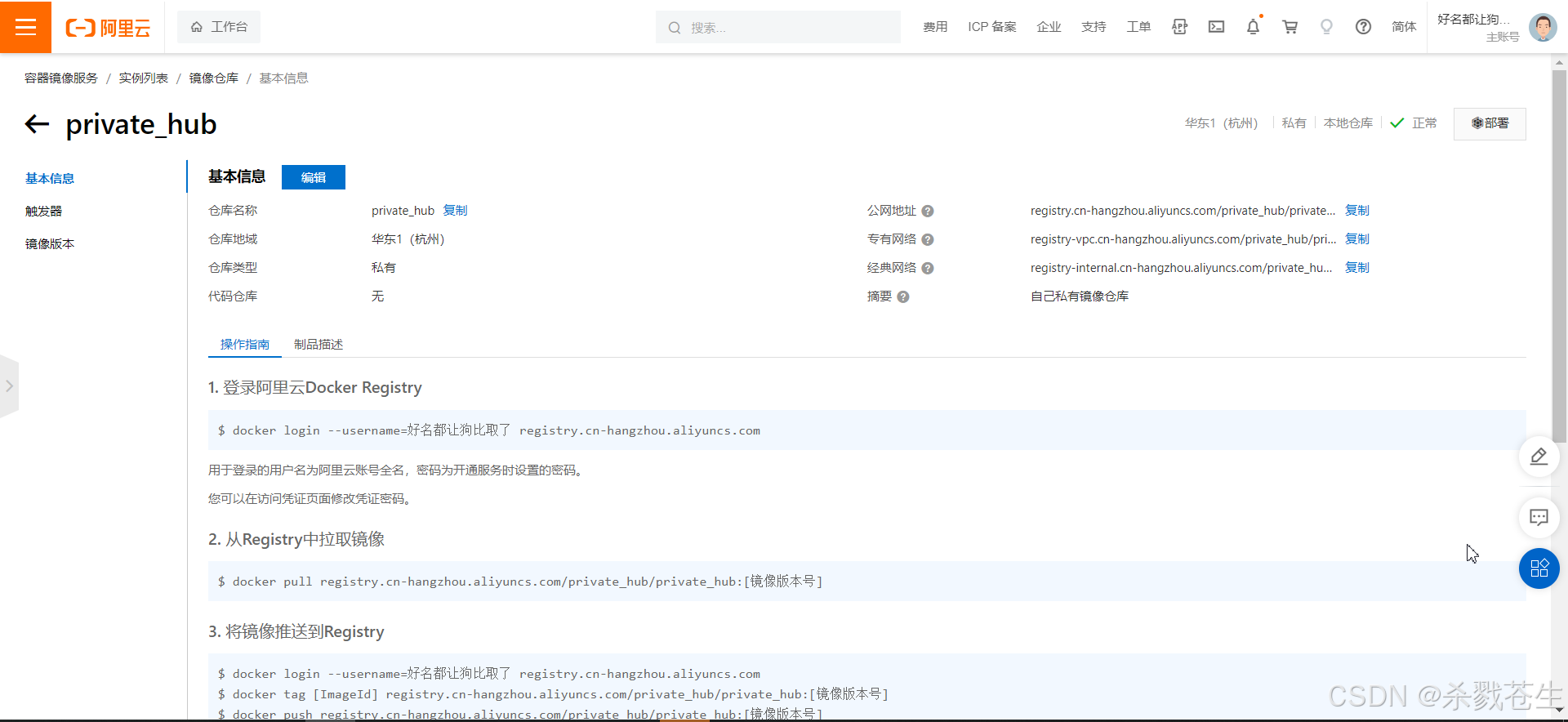
3.2.2、login、push、pull
开始推送demo到阿里云服务器
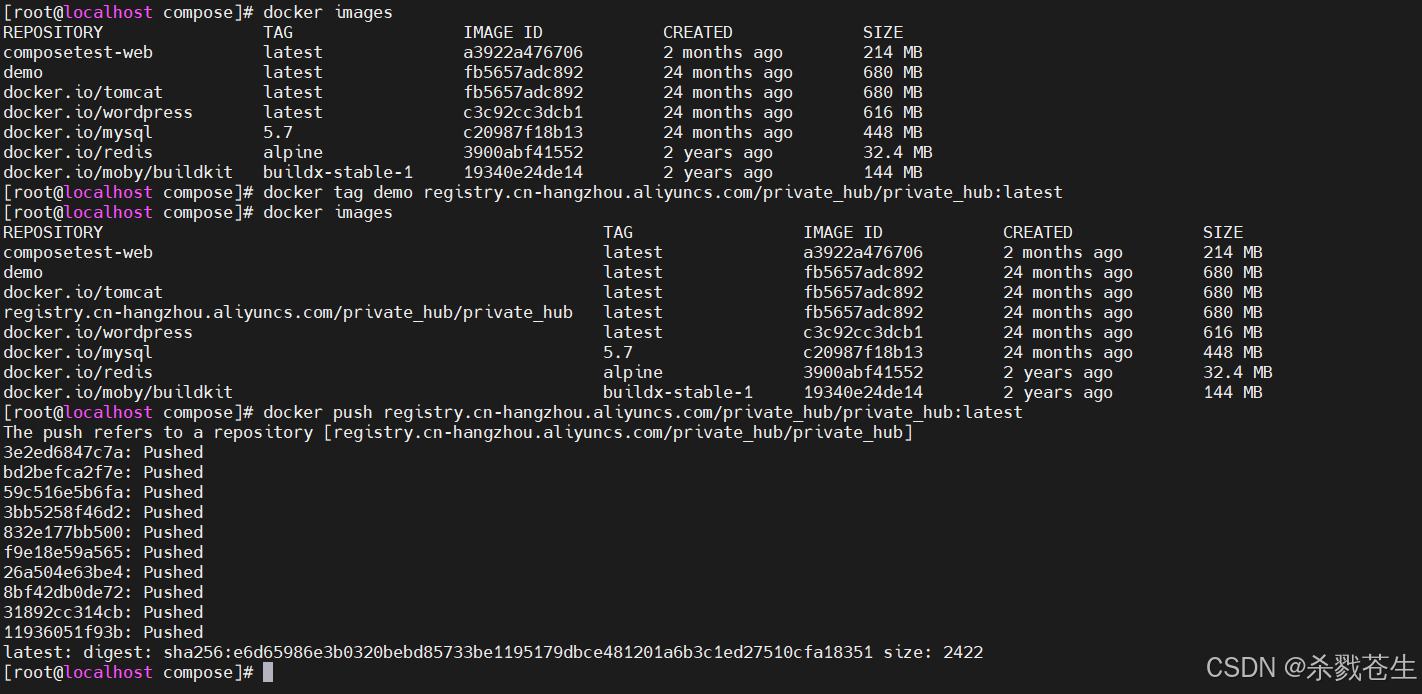
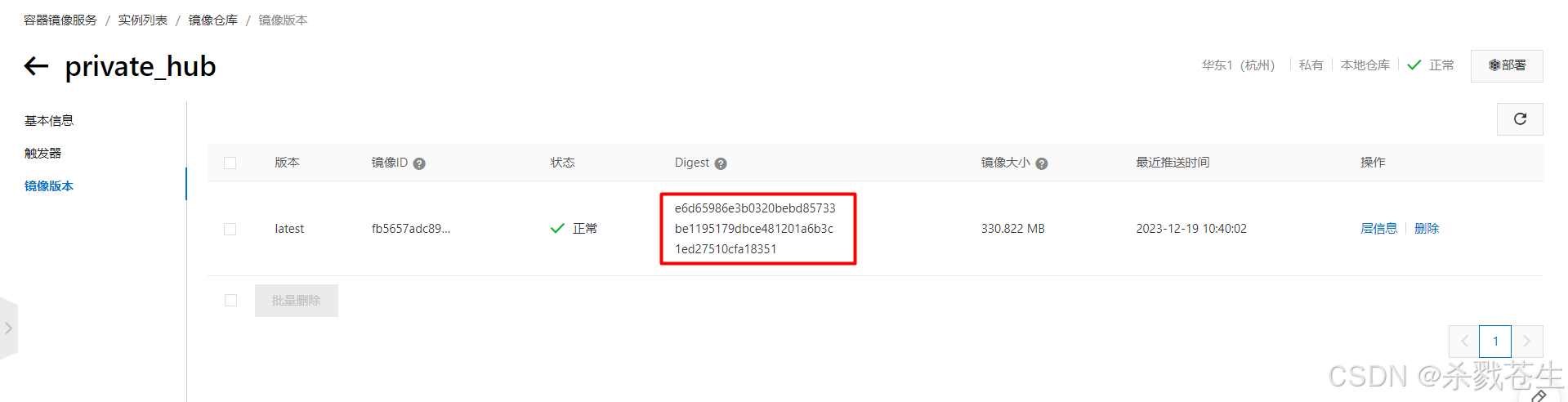
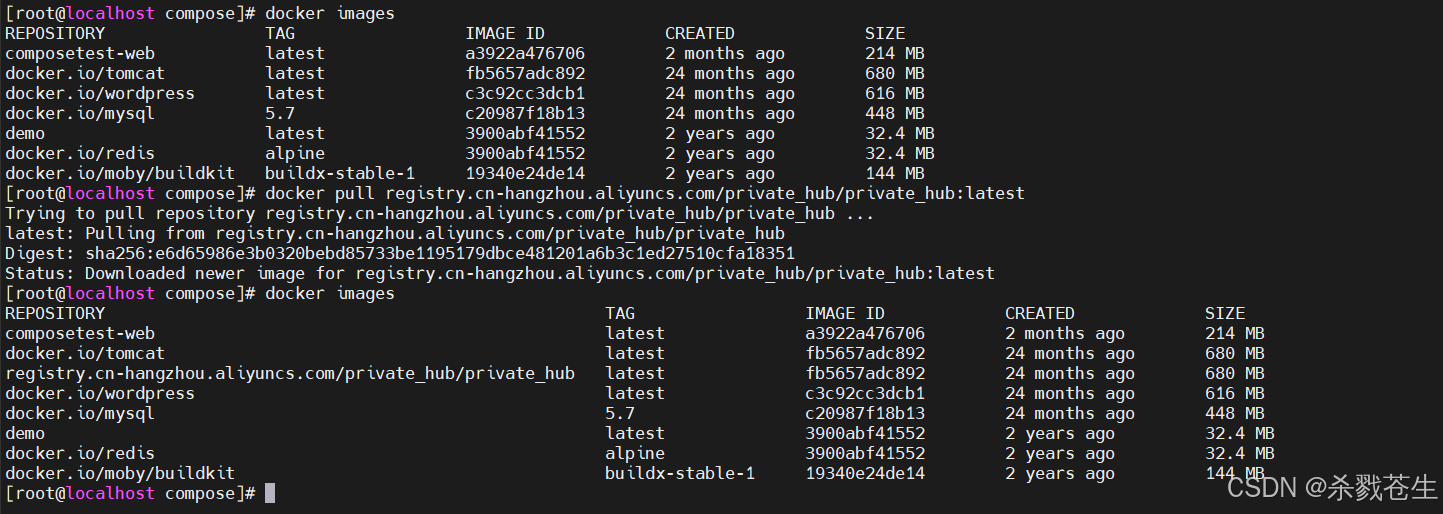
下载私有镜像
3.3、私服harbor
3.3.1、简介
harbor是由vmware公司开源的企业级的docker registry管理项目,harbor主要提供dcoker registry管理ui,提供的功能包括:基于角色访问的控制权限管理(rbac)、ad/ldap集成、日志审核、管理界面、自我注册、镜像复制和中文支持等。harbor的目标是帮助用户迅速搭建一个企业级的docker registry服务。它以docker公司开源的registry为基础,额外提供了如下功能:
- 基于角色的访问控制(role based access control)
- 基于策略的镜像复制(policy based image replication)
- 镜像的漏洞扫描(vulnerability scanning)
- ad/ldap集成(ldap/ad support)
- 镜像的删除和空间清理(image deletion & garbage collection)
- 友好的管理ui(graphical user portal)
- 审计日志(audit logging)
- restful api
- 部署简单(easy deployment)
harbor的所有组件都在dcoker中部署,所以harbor可使用docker compose快速部署。需要特别注意:由于harbor是基于docker registry v2版本,所以docker必须大于等于1.10.0版本,docker-compose必须要大于1.6.0版本!

| 组件 | 功能 |
|---|---|
| harbor-adminserver | 配置管理中心 |
| harbor-db | mysql数据库 |
| harbor-jobservice | 负责镜像复制 |
| harbor-log | 记录操作日志 |
| harbor-ui | web管理页面和api |
| nginx | 前端代理,负责前端页面和镜像上传/下载转发 |
| redis | 会话 |
| registry | 镜像存储 |
3.3.2、harbor安装
3.3.2.1、下载
这玩意600mb+。。。。下载的老鸡儿慢了。。。
我这下载了好几天,重试了无数次,终于从一个百度云上下载下来了

3.3.2.2、安装
- 解压
#第一步,解压
[root@manager harbor]# tar -zxcf harbor-offline-installer-v2.4.3.tgz
[root@manager harbor]# ll
total 642184
drwxr-xr-x. 2 root root 122 2023-12-26 10:37:58 harbor
-rw-r--r--. 1 root root 657593723 2023-12-26 10:32:18 harbor-offline-installer-v2.4.3.tgz
- 尝试安装harbor
#第二步, 进入安装目录,开始安装harbor
[root@manager harbor]# sh install.sh
[step 0]: checking if docker is installed ...
# 注意 docker版本太低。。。。。
note: docker version: 1.13.1
✖ need to upgrade docker package to 17.06.0+.
- 卸载旧版本docker,安装新版本docker
#第三步,卸载旧版本的docker
[root@manager harbor]# rpm -qa | grep docker
docker-buildx-plugin-0.10.4-1.el7.x86_64
docker-compose-plugin-2.21.0-1.el7.x86_64
docker-common-1.13.1-209.git7d71120.el7.centos.x86_64
docker-1.13.1-209.git7d71120.el7.centos.x86_64
docker-scan-plugin-0.23.0-3.el7.x86_64
docker-client-1.13.1-209.git7d71120.el7.centos.x86_64
[root@manager harbor]# yum remove -y docker-buildx-plugin-0.10.4-1.el7.x86_64 docker-compose-plugin-2.21.0-1.el7.x86_64 docker-common-1.13.1-209.git7d71120.el7.centos.x86_64 docker-1.13.1-209.git7d71120.el7.centos.x86_64 docker-scan-plugin-0.23.0-3.el7.x86_64 docker-client-1.13.1-209.git7d71120.el7.centos.x86_64
#第四步,安装新版本docker
[root@manager harbor]# curl -fssl https://get.docker.com/ | sh
#省略日志.....具体看图片
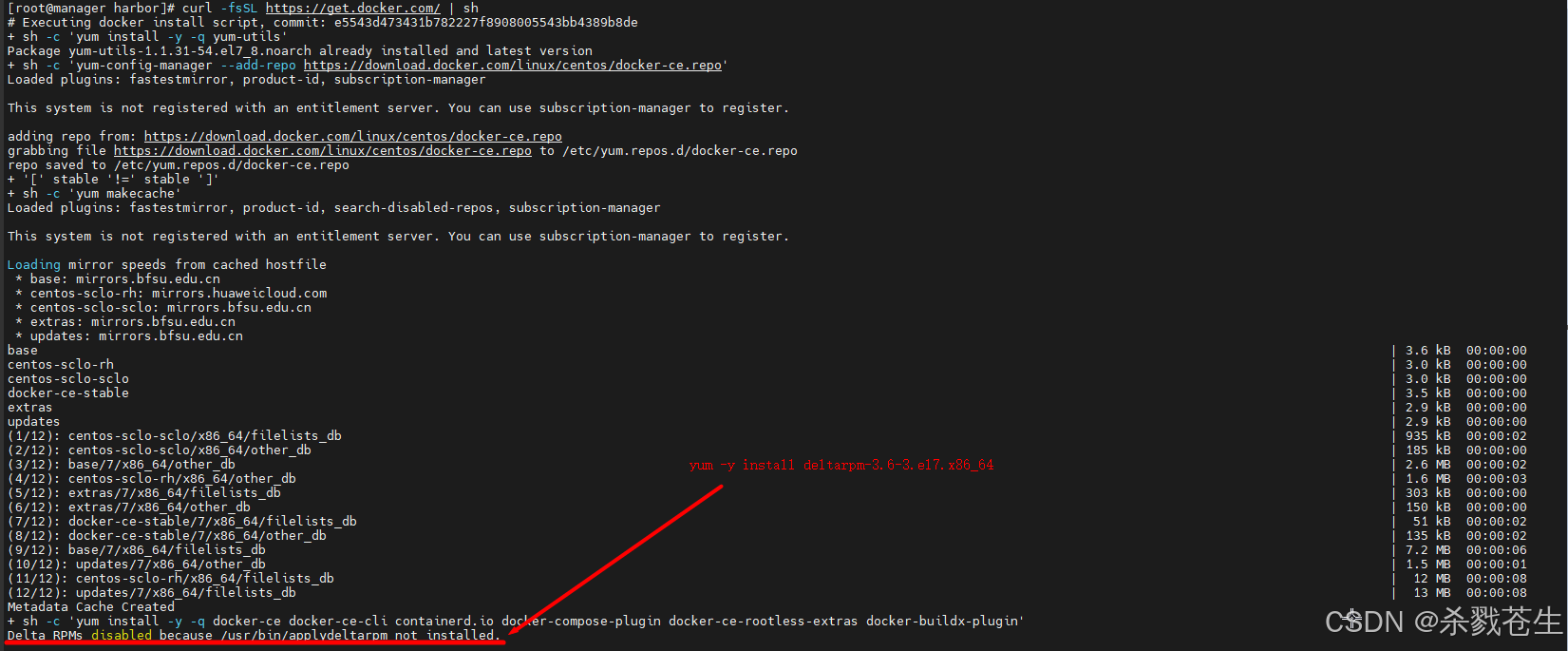
#出现以上错误
#delta rpms disabled because /usr/bin/applydeltarpm not installed
#安装一下 deltrapm,重新安装docker就可以了
yum -y install deltarpm-3.6-3.el7.x86_64
安装完成如下所示:

- 第二次重新安装harbor
这玩意。。。安装老慢了。。。等吧
出现这个错误:是因为没有提前准备配置文件。。。。。
- 准备配置文件
harbor提供了配置文件,在你当前解压目录下,有一个 harbor.yml.tmpl,将其重命名为harbor.yml,修改一下几项内容即可使用。
# 修改位置1:域名或则是 ip
hostname: 192.168.57.131
http:
port: 80
#修改位置2:注释掉https相关内容
#harbor默认没有https访问,如需要https,需要先生成证书。证书生成步骤 【3.3.2.3、 证书】
#https:
# port: 443
# certificate: /opt/harbor/servercert/192.168.56.131.crt
# private_key: /opt/harbor/servercert/192.168.56.131.key
external_url: https://192.168.57.15
harbor_admin_password: harbor12345
database:
password: root123
max_idle_conns: 50
max_open_conns: 100
#修改位置3:数据卷位置
data_volume: /opt/harbor/data
clair:
updaters_interval: 12
jobservice:
max_job_workers: 10
notification:
webhook_job_max_retry: 10
chart:
absolute_url: disabled
#修改位置4:log文件位置
log:
level: info
local:
rotate_count: 50
rotate_size: 200m
location: /opt/harbor/logs
_version: 1.10.0
proxy:
http_proxy:
https_proxy:
no_proxy:
components:
- core
- jobservice
- clair
#修改文件,文件修改地方如上所示。
[root@manager harbor]# vim harbor.yml
#执行文件,准备环境
[root@manager harbor]# ./prepare
prepare base dir is set to /opt/harbor/harbor
clearing the configuration file: /config/portal/nginx.conf
clearing the configuration file: /config/log/logrotate.conf
clearing the configuration file: /config/log/rsyslog_docker.conf
clearing the configuration file: /config/nginx/nginx.conf
clearing the configuration file: /config/core/env
clearing the configuration file: /config/core/app.conf
clearing the configuration file: /config/registry/passwd
clearing the configuration file: /config/registry/config.yml
clearing the configuration file: /config/registry/root.crt
clearing the configuration file: /config/registryctl/env
clearing the configuration file: /config/registryctl/config.yml
clearing the configuration file: /config/db/env
clearing the configuration file: /config/jobservice/env
clearing the configuration file: /config/jobservice/config.yml
generated configuration file: /config/portal/nginx.conf
generated configuration file: /config/log/logrotate.conf
generated configuration file: /config/log/rsyslog_docker.conf
generated configuration file: /config/nginx/nginx.conf
generated configuration file: /config/core/env
generated configuration file: /config/core/app.conf
generated configuration file: /config/registry/config.yml
generated configuration file: /config/registryctl/env
generated configuration file: /config/registryctl/config.yml
generated configuration file: /config/db/env
generated configuration file: /config/jobservice/env
generated configuration file: /config/jobservice/config.yml
loaded secret from file: /data/secret/keys/secretkey
generated configuration file: /compose_location/docker-compose.yml
clean up the input dir
[root@manager harbor]#
- 第三次安装harbor(成功)
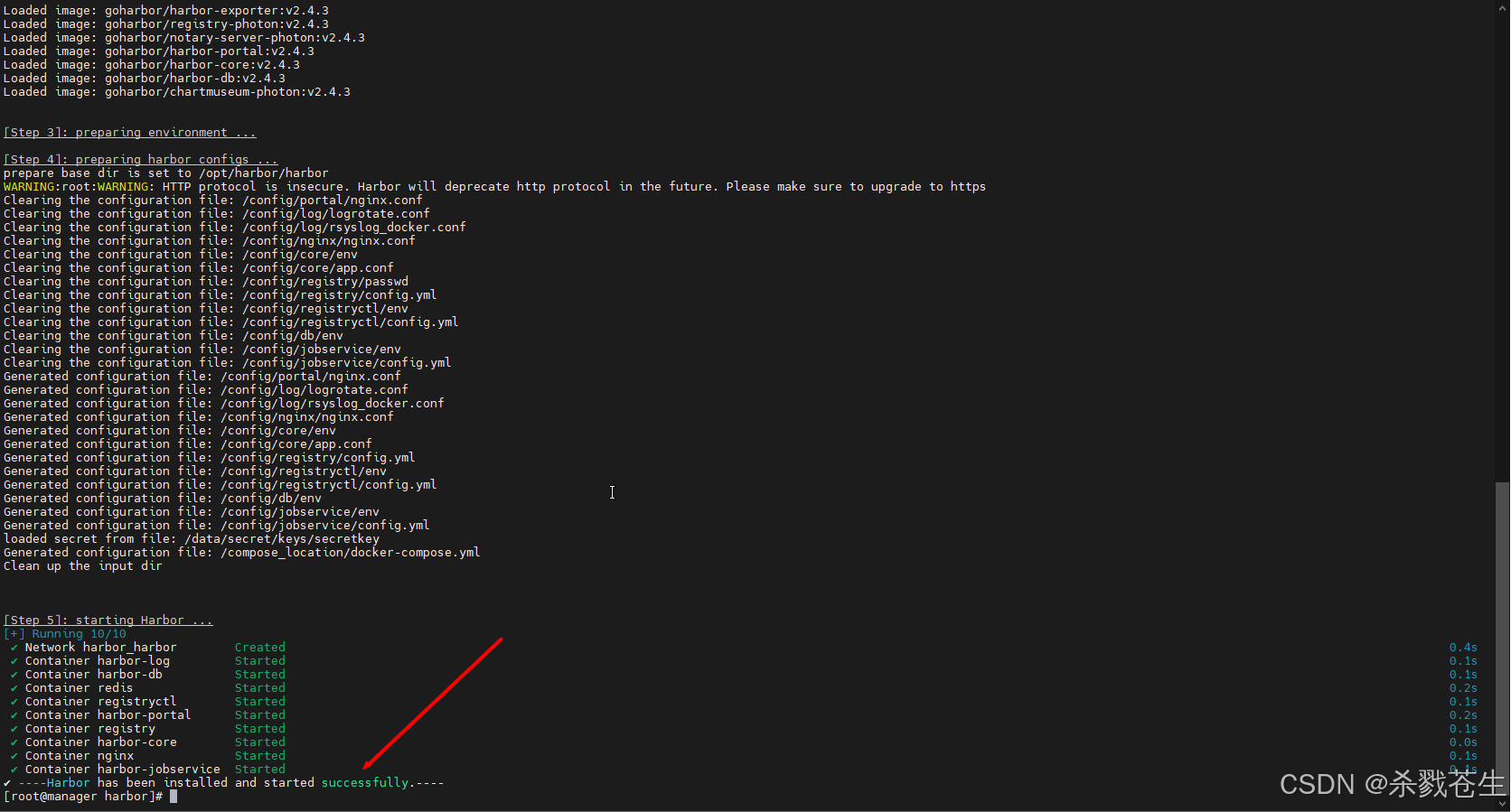 harbor依赖docker,所以咱们能够在docker里看到harbor的所有容器
harbor依赖docker,所以咱们能够在docker里看到harbor的所有容器

3.3.2.3、证书
本章节关于https证书的申请。
默认情况下,harbor不附带证书。可以在没有安全性的情况下部署harbor,以便您可以通过http连接到它。但是,只有在没有外部网络连接的空白测试或开发环境中,才可以使用http。在没有空隙的环境中使用http会使您遭受中间人攻击。在生产环境中,请始终使用https。如果启用content trust with notary来正确签名所有图像,则必须使用https。
要配置https,必须创建ssl证书。您可以使用由受信任的第三方ca签名的证书,也可以使用自签名证书。
证书签证:证书的签发与生成
证书合并:证书合并成证书包
- ca证书的签发与生成
咱们将证书生成到上层目录,即和data、logs同级的路径下,即 /opt/harbor/cert下
- 生成ca证书私钥。
openssl genrsa -out ca.key 4096
- 生成ca证书
调整-subj选项中的值以反映您的组织。如果使用fqdn连接harbor主机,则必须将其指定为通用名称(cn)属性。
# -days 表示证书有效天数,3650代表10年
openssl req -x509 -new -nodes -sha512 -days 3650 \
-subj "/c=cn/st=beijing/l=beijing/o=example/ou=personal/cn=yourdomain.com" \
-key ca.key \
-out ca.crt
如果是 ip访问,记得 将 yourdomain.com替换为你的ip。
- 服务器证书的签发与生成
证书一般包含两个文件,一个yourdomain.com.crt 一个yourdomain.com.key 两个文件
咱们将服务器生成的证书,放到 /opt/harbor/servercert 下。
这个地方我踩了一个坑,建议大家直接放到ca证书文件夹下,不要重新建一个文件夹,因为生成服务器证书文件,需要上面的ca证书的两个文件(cat.key、ca.crt)
- 生成私钥文件
#注意将 yourdomain.com更换为你自己的域名,或者是 ip
openssl genrsa -out yourdomain.com.key 4096

- 生成证书签名请求(csr)
#调整-subj选项中的值以映射你的域名。如果使用fqdn连接harbor主机,则必须将其指定为通用名称(cn)属性,并在密钥和csr文件名中使用它。
#注意修改yourdomain.com成你的域名,如果是ip访问,请改成你自己的ip
openssl req -sha512 -new \
-subj "/c=cn/st=beijing/l=beijing/o=example/ou=personal/cn=yourdomain.com" \
-key yourdomain.com.key \
-out yourdomain.com.csr

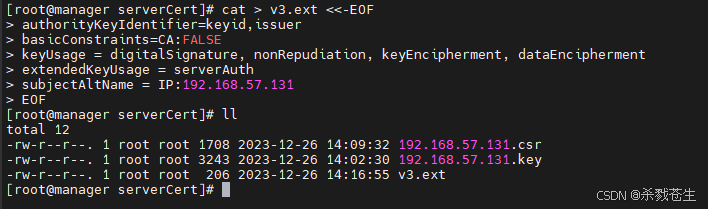
- 生成x509 v3扩展文件
无论您使用fqdn还是ip地址连接到harbor主机,都必须创建此文件,以便可以为您的harbor主机生成符合主题备用名称(san)和x509 v3的证书扩展要求。替换dns条目以反映您的域
#使用改名的时候。需要将 dns 的3项改成你自己的域名,如果是ip访问,需修改subjectaltname项
cat > v3.ext <<-eof
authoritykeyidentifier=keyid,issuer
basicconstraints=ca:false
keyusage = digitalsignature, nonrepudiation, keyencipherment, dataencipherment
extendedkeyusage = serverauth
subjectaltname = @alt_names
[alt_names]
dns.1=yourdomain.com
dns.2=yourdomain
dns.3=hostname
eof
- 使用x509 v3扩展文件生成harbor主机的证书。
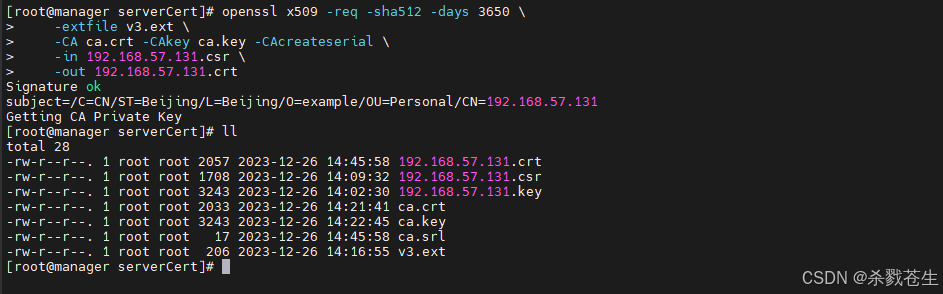
#将crs和crt文件名中的“yourdomain.com”替换为“harbor”主机名。
openssl x509 -req -sha512 -days 3650 \
-extfile v3.ext \
-ca ca.crt -cakey ca.key -cacreateserial \
-in yourdomain.com.csr \
-out yourdomain.com.crt
如果出现下面这个错误:
[root@manager servercert]# openssl x509 -req -sha512 -days 3650 \
> -extfile v3.ext \
> -ca ca.crt -cakey ca.key -cacreateserial \
> -in 192.168.57.131.csr \
> -out 192.168.57.131.crt
signature ok
subject=/c=cn/st=beijing/l=beijing/o=example/ou=personal/cn=192.168.57.131
error opening ca certificate ca.crt
140014055364496:error:02001002:system library:fopen:no such file or directory:bss_file.c:402:fopen('ca.crt','r')
140014055364496:error:20074002:bio routines:file_ctrl:system lib:bss_file.c:404:
unable to load certificate
#或者是这个错误
[root@manager servercert]# openssl x509 -req -sha512 -days 3650 \
> -extfile v3.ext \
> -ca ca.crt -cakey ca.key -cacreateserial \
> -in 192.168.57.131.csr \
> -out 192.168.57.131.crt
signature ok
subject=/c=cn/st=beijing/l=beijing/o=example/ou=personal/cn=192.168.57.131
getting ca private key
ca certificate and ca private key do not match
139797921482640:error:06067099:digital envelope routines:evp_pkey_copy_parameters:different parameters:p_lib.c:137:
139797921482640:error:02001002:system library:fopen:no such file or directory:bss_file.c:402:fopen('ca.srl','r')
139797921482640:error:20074002:bio routines:file_ctrl:system lib:bss_file.c:404:
139797921482640:error:0b080074:x509 certificate routines:x509_check_private_key:key values mismatch:x509_cmp.c:343:

以上两种错误,都是说文件(ca.crt、ca.srl)找不到,出现这个错误,是因为当前文件夹下没有ca证书文件。
大家指定一下ca的文件路径,或者是,将现在所有的文件都拷贝到ca证书所在的文件夹下就可以了。
- 提供证书给harbor和docker
生成后ca.crt,192.168.57.131.crt和192.168.57.131.key文件,必须将它们提供给harbor和docker,重新配置它们。
- 将文件文件拷贝到harbor证书文件夹下
#将证书文件拷贝到 harbor主机的 证书文件夹下。 默认是: /data/cert
mkdir -p /data/cert/
cp 192.168.57.131.crt /data/cert/
cp 192.168.57.131.key /data/cert/
#这个目录 是 在上一步中 harbor.yml中 http.certificate 和 https.private_key 中配置的。
#如果不改 harbor.yml, 那就需要移动文件到配置的目录下
- 生成docker的证书
openssl x509 -inform pem -in 192.168.57.131.crt -out 192.168.57.131.cert
#将这个几个文件 拷贝到 docker下,注意文件夹路径,必须是这个目录下
mkdir -p /etc/docker/certs.d/192.168.57.131/
cp 192.168.57.131.cert 192.168.57.131.key ca.crt /etc/docker/certs.d/192.168.57.131/
如果将默认nginx端口443 映射到其他端口,请创建文件夹/etc/docker/certs.d/yourdomain.com:port或/etc/docker/certs.d/harbor_ip:port
最后生成的目录如下:
/etc/docker/certs.d/
└── 192.168.57.131
├── ca.crt
├── 192.168.57.131.cert
└── 192.168.57.131.key
重启docker
systemctl restart docker
注意:重启docker后,harbor的容器,好多是不会自动启动的,需要咱们自己手动启动harbor的容器
#停止并删除服务
docker-compose down -v
#推荐使用docker-compose。在安装目录下有docker-compose.yml,可是使用docker-compose
docker-compose up -d

3.3.2.4、验证服务
根据配置harbor.yml配置项:arbor_admin_password=harbor12345,可得用户名密码: admin/harbor12345
- http访问
- https 访问 *
3.3.3、部署应用
3.3.3.1、shell登录
个人私服搭建完成。现在进行私服的登录,并进行images的上传下载。
#进行登录即可
docker login 192.168.57.131

如果出现这个错误,可是看一下配置文件harbor.yml中external_url是否配置了。
根据博客中描述,是因为external_url的问题,后来经过排查确实是这个问题。
#另外因为咱们本地可能已经登陆了其他的 docker私服,或者是配置了 docker私服,导致上面的命令登录的时候,会出现错误!
#推荐使用这个命令。
docker login -u admin -p harbor12345 192.168.57.131

3.3.3.2、创建仓库
3.3.3.3、上传私服
#将自己images改名 改为
docker tag source_image[:tag] 192.168.57.131/private/repository[:tag]
#示例
docker tag demo:latest 192.168.57.131/private/demo:latest
#上传
docker push 192.168.57.131/private/demo:latest

#下载
docker pull 192.168.57.131/private/demo:latest
#或者是使用人家harbor提供的命令。不过这个命令需要在页面系统上进行复制。。。普通用户是无法登陆私服的,一般上面那个就可以使用。
docker pull 192.168.57.131/private/demo@sha256:32f8cf4bf6412626b21273fed376182b6786b75182e4a19f90f3f57d01362fbb

4、swarm
官网地址:https://docs.docker.com/engine/swarm/
开源代码:https://github.com/docker/swarm
4.1、简介
swarm是docker官方提供的一款集群管理工具,能够跨节点的容器编排,其主要作用是把若干台docker主机抽象为一个整体,并且通过一个入口统一管理这些docker主机上的各种docker资源。swarm和kubernetes比较类似,但是更加轻,具有的功能也较kubernetes更少一些。
不同的是,docker compose 是一个在单个服务器或主机上创建多个容器的工具,而 docker swarm 则可以在多个服务器或主机上创建容器集群服务,对于微服务的部署,显然 docker swarm 会更加适合。
4.2、大体架构
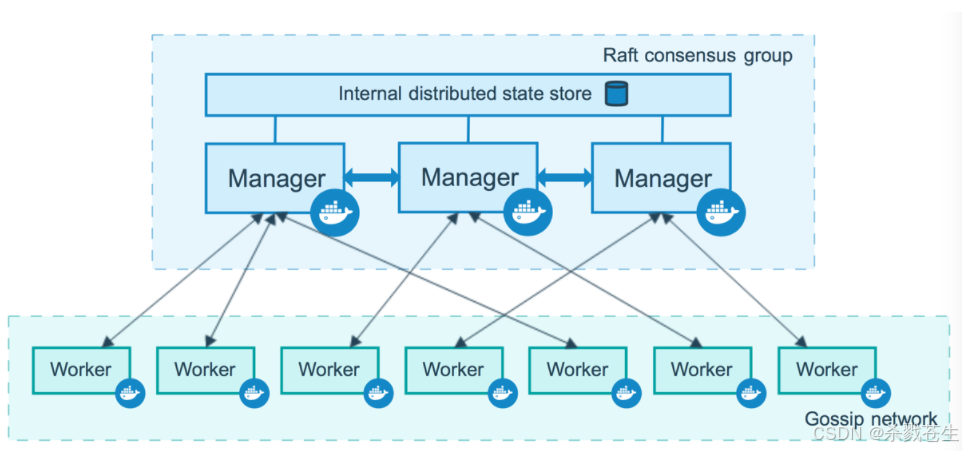
上面的部分,是swarm manager,下面的是worker node。
swarm manager,即节点(集群)管理处
管理节点处理集群管理任务:
- 维护集群状态
- 调度服务
- 服务群模式http api 端点
其内部使用raft实现,管理器维护整个 swarm 及其上运行的所有服务的一致内部状态。出于测试目的,可以使用单个管理器运行 swarm。如果单管理器群中的管理器出现故障,您的服务会继续运行,但您需要创建一个新集群来恢复。
为了利用 swarm 模式的容错特性,docker 建议您根据组织的高可用性要求实现奇数个节点。当您有多个管理器时,您可以在不停机的情况下从管理器节点的故障中恢复。
- 三个管理器的群体最多可以容忍一个管理器的损失。
- 一个五管理器群可以容忍最大同时丢失两个管理器节点。
- 一个
n管理器集群最多可以容忍管理器的丢失(n-1)/2。 - docker 建议一个群最多有七个管理器节点。
worker node,即工作节点
工作节点也是 docker 引擎的实例,其唯一目的是执行容器。worker 节点不参与 raft 分布式状态,不做出调度决策,也不为 swarm 模式 http api 提供服务。
您可以创建一个由一个管理器节点组成的群,但是如果没有至少一个管理器节点,您就不能拥有一个工作节点。默认情况下,所有经理也是工人。在单个管理器节点集群中,您可以运行类似命令docker service create,调度程序将所有任务放在本地引擎上。
为防止调度程序将任务放置在多节点群中的管理器节点上,请将管理器节点的可用性设置为drain。调度器在drainmode 中优雅地停止节点上的任务并调度active节点上的任务 。调度程序不会将新任务分配给具有drain 可用性的节点。
4.3、工作原理
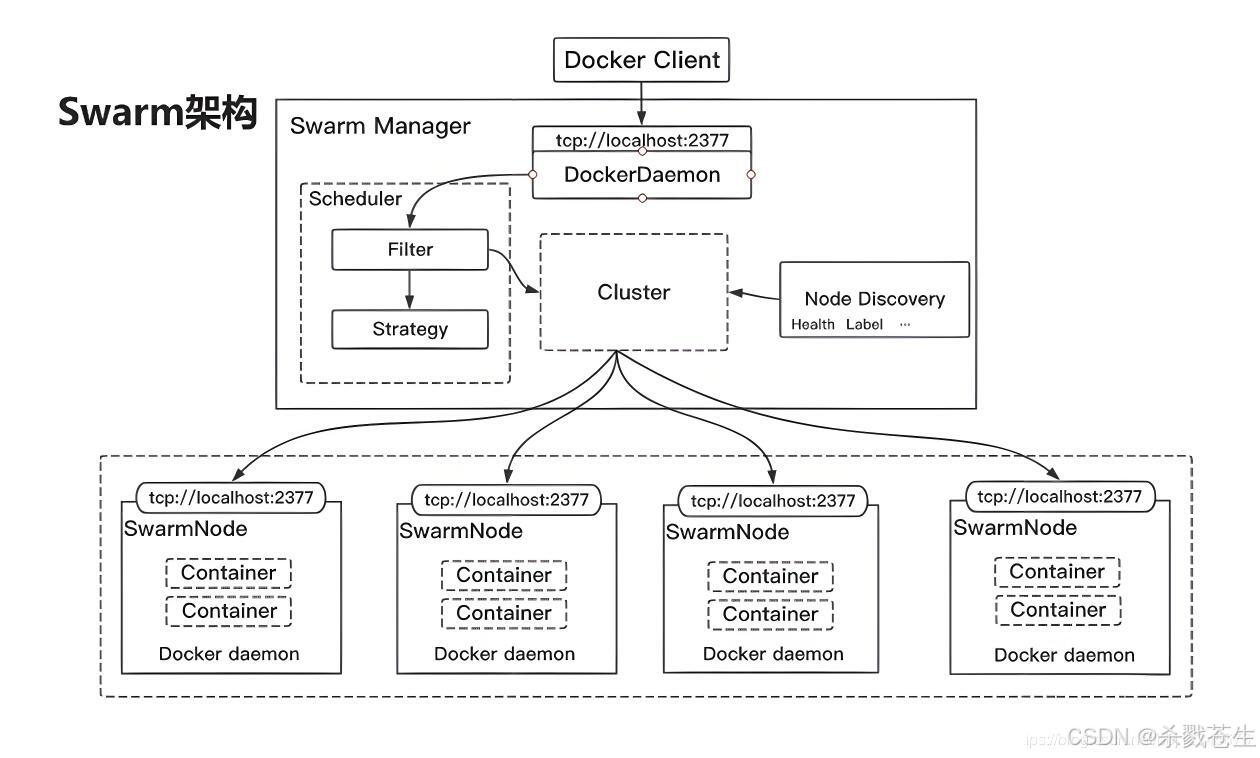
swarm是典型的master-slave结构,通过发现服务来选举manager。manager是中心管理节点,各个node上运行agent接受manager的统一管理,集群会自动通过raft协议分布式选举出manager节点,无需额外的发现服务支持,避免了单点的瓶颈问题,同时也内置了dns的负载均衡和对外部负载均衡机制的集成支持。
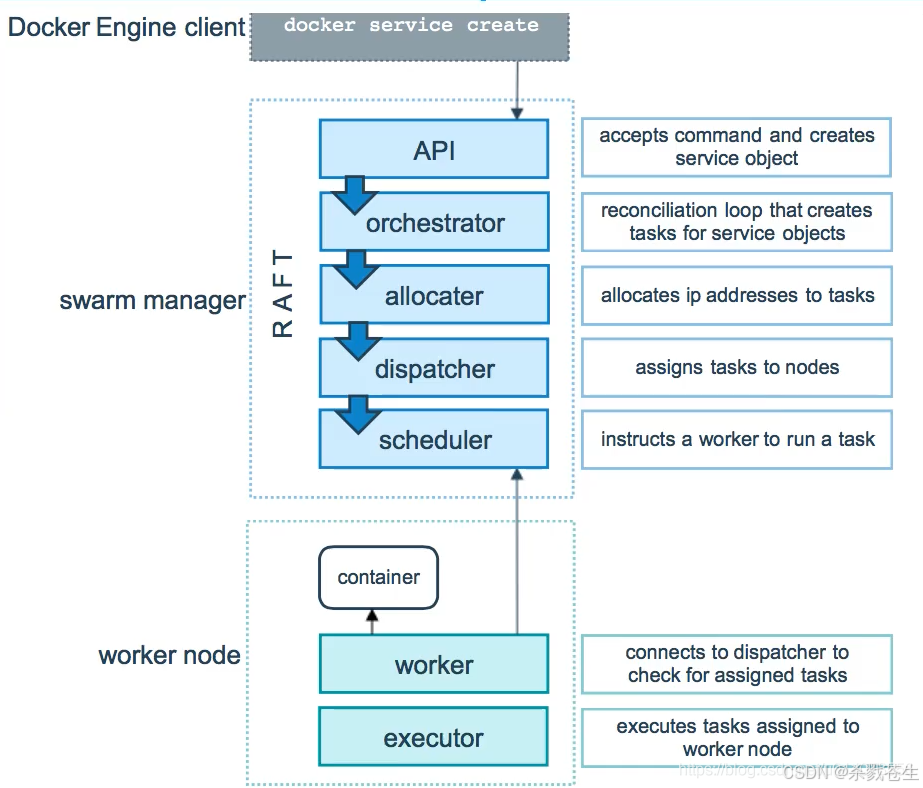
docker engine clientdocker service create:我们通过docker service create这个命令去创建一个服务。
swarm managerapi:这个请求直接由swarm manager的api进行接收,接收命令并创建服务对象。orchestrator:为服务创建一个任务。allocater:为这个任务分配ip地址。dispatcher:将任务分配到指定的节点。scheduler:再该节点中下发指定命令。
worker node:接收manager任务后去运行这个任务container:创建相应的容器。worker:连接到调度程序以检查分配的任务executor:执行分配给工作节点的任务
4.4、swarm集群搭建
在线swarm演示:http://labs.play-with-docker.com 。通过dock hub 的账号密码登录即可,注意哈,有效会话4个小时。
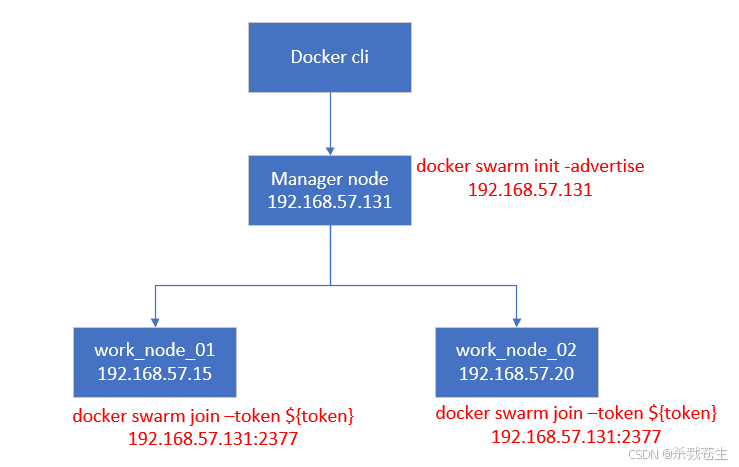
如图所示,咱们需要准备三个节点,一个是manager node,另外两个是work node。
注意:修改另外两个节点的hostname,使其三个节点的hostname,不重复
- 创建manager节点
docker swarm init --advertise-addr 192.168.57.131
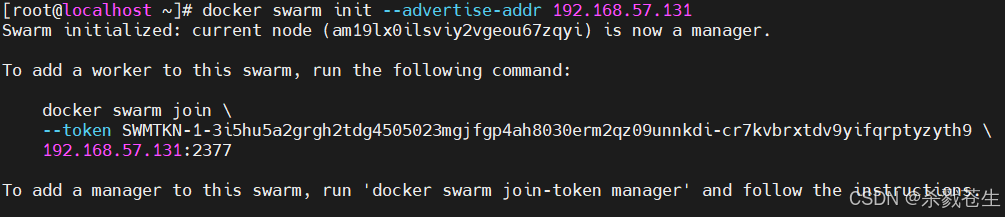
#注意:上面的执行日志,需要拿到token,以便下一步的node节点的加入
docker swarm join \
--token swmtkn-1-3i5hu5a2grgh2tdg4505023mgjfgp4ah8030erm2qz09unnkdi-cr7kvbrxtdv9yifqrptyzyth9 \
192.168.57.131:2377
- work点加入集群
#分别进入两个两个work节点,修改两个节点的hostname,否则通过manager查看节点的时候会无法区分。
[root@localhost ~]# sudo hostnamectl set-hostname work.node.01
[root@localhost ~]# hostnamectl
static hostname: work.node.01
icon name: computer-vm
chassis: vm
machine id: f7c149e722294dd1bd78ece186af5379
boot id: 62417a21b65f4b2cbc457d5e79a71d2d
virtualization: vmware
operating system: centos linux 7 (core)
cpe os name: cpe:/o:centos:centos:7
kernel: linux 3.10.0-1160.88.1.el7.x86_64
architecture: x86-64
#执行上一步拿到的 token 以及 命令
#=========================报错了=====================================
[root@localhost ~]# docker swarm join \
> --token swmtkn-1-3i5hu5a2grgh2tdg4505023mgjfgp4ah8030erm2qz09unnkdi-cr7kvbrxtdv9yifqrptyzyth9 \
> 192.168.57.131:2377
error response from daemon: rpc error: code = 14 desc = grpc: the connection is unavailable
#==========================报错解决后====================================
[root@localhost ~]# docker swarm join --token swmtkn-1-3i5hu5a2grgh2tdg4505023mgjfgp4ah8030erm2qz09unnkdi-cr7kvbrxtdv9yifqrptyzyth9 192.168.57.131:2377
this node joined a swarm as a worker.
 出现在这个错误,是因为防火墙的问题,
出现在这个错误,是因为防火墙的问题,manager的防火墙未关闭导致的。
#可以停掉防火墙
systemctl stop firewalld.service
#或者是开放防火墙2377端口。
firewall-cmd --add-port=2377/tcp --permanent
#查看端口开发情况
firewall-cmd --zone=public --list-ports
#如果是增加开发端口后,一定重启防火墙
firewall-cmd --reload
注意:防火墙的关闭/端口开放,work节点也要加的,否则会报错。
关闭防火墙,再次使用join命令,重新加入manager

3. 验证节点数量
#在manager上查看节点数量
docker node ls
#从集群中移除。注意本命令在work.node上执行
docker swarm leave -f
docker swarm leave --force
#错误的节点,可以(使用node的id)直接在manager删除掉
docker node rm $nodeid
 移除之后,就会发现节点
移除之后,就会发现节点status变为down。不过不知道为啥hostname没有发生变化。
移除之后,重新添加集群,就会发现该节点出现了。
 最后两个节点都启动起来。
最后两个节点都启动起来。

- node类型转换
# 可以将worker提升成manager,从而保证manager的高可用
docker node promote worker01-node
docker node promote worker02-node
#降级可以用demote
docker node demote worker01-node
4.5、raft一致性协议
swarm内部使用的是raft一致性协议,这个协议只要节点半数存活,集群可用。而不是挂掉一个节点,整个集群都奔溃了!
下面验证这个结论:
- 一主两从
停掉一个work节点
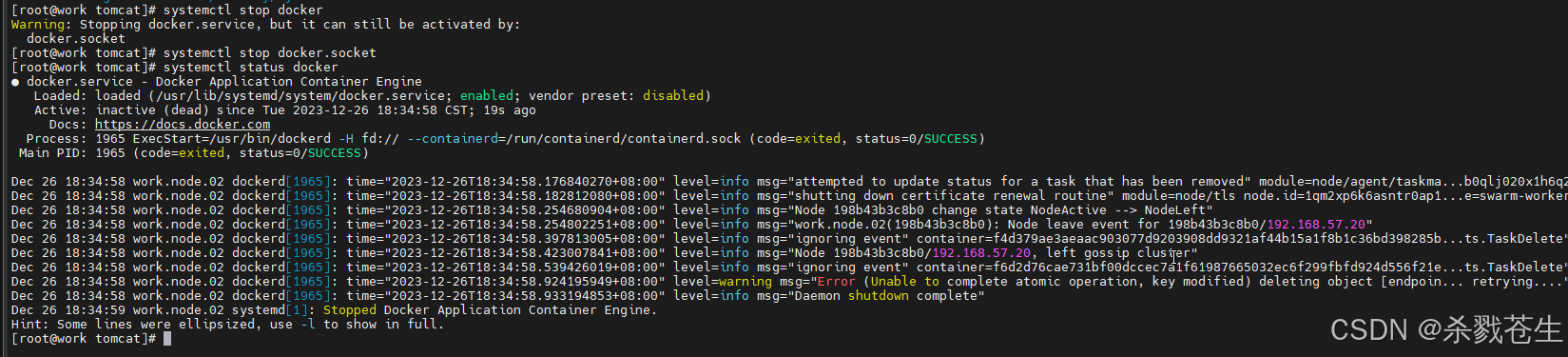 再manager就会发现,已经启动的集群,服务还能工作。只不过切换到其他节点上了。
再manager就会发现,已经启动的集群,服务还能工作。只不过切换到其他节点上了。
 停掉第二个work节点
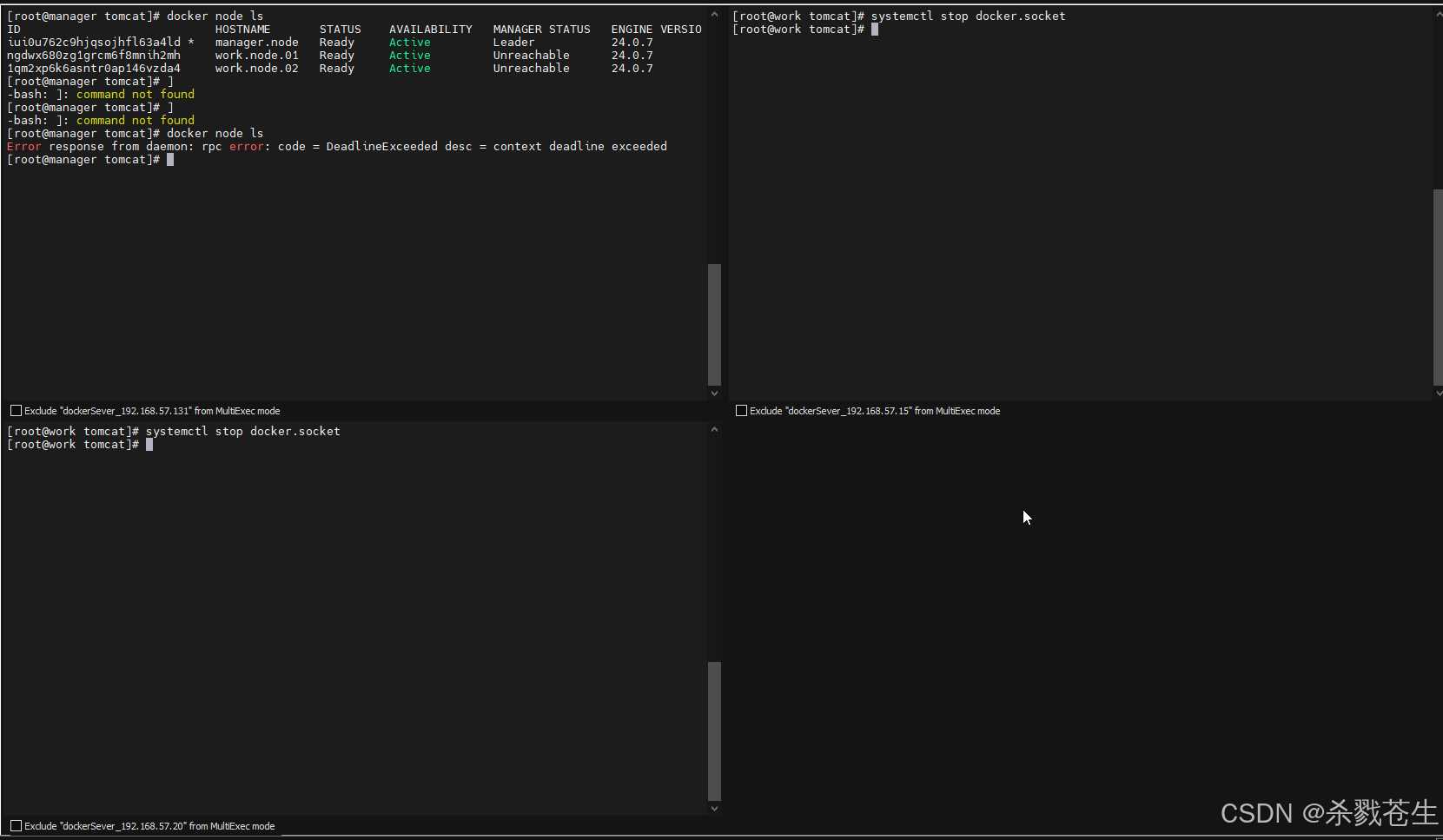
停掉第二个work节点
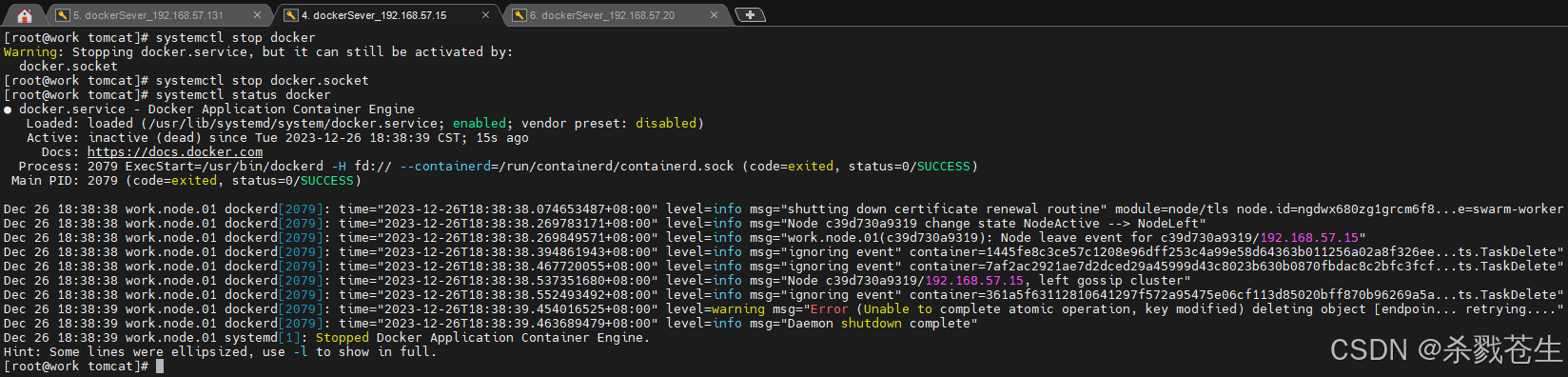 再manager就会发现,已经启动的集群,服务还能工作。只不过都跑到manager上了
再manager就会发现,已经启动的集群,服务还能工作。只不过都跑到manager上了
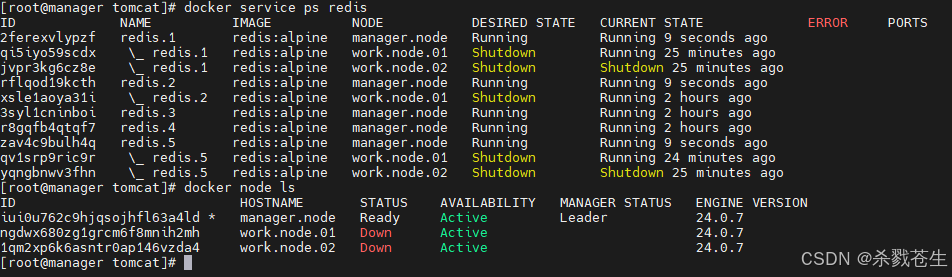
- 两主一从
简单验证一下。关于work节点关闭后,集群还能正常运行,就不截图了,上面已经验证过了。总共两个manager,咱们关闭一个,看一下效果:
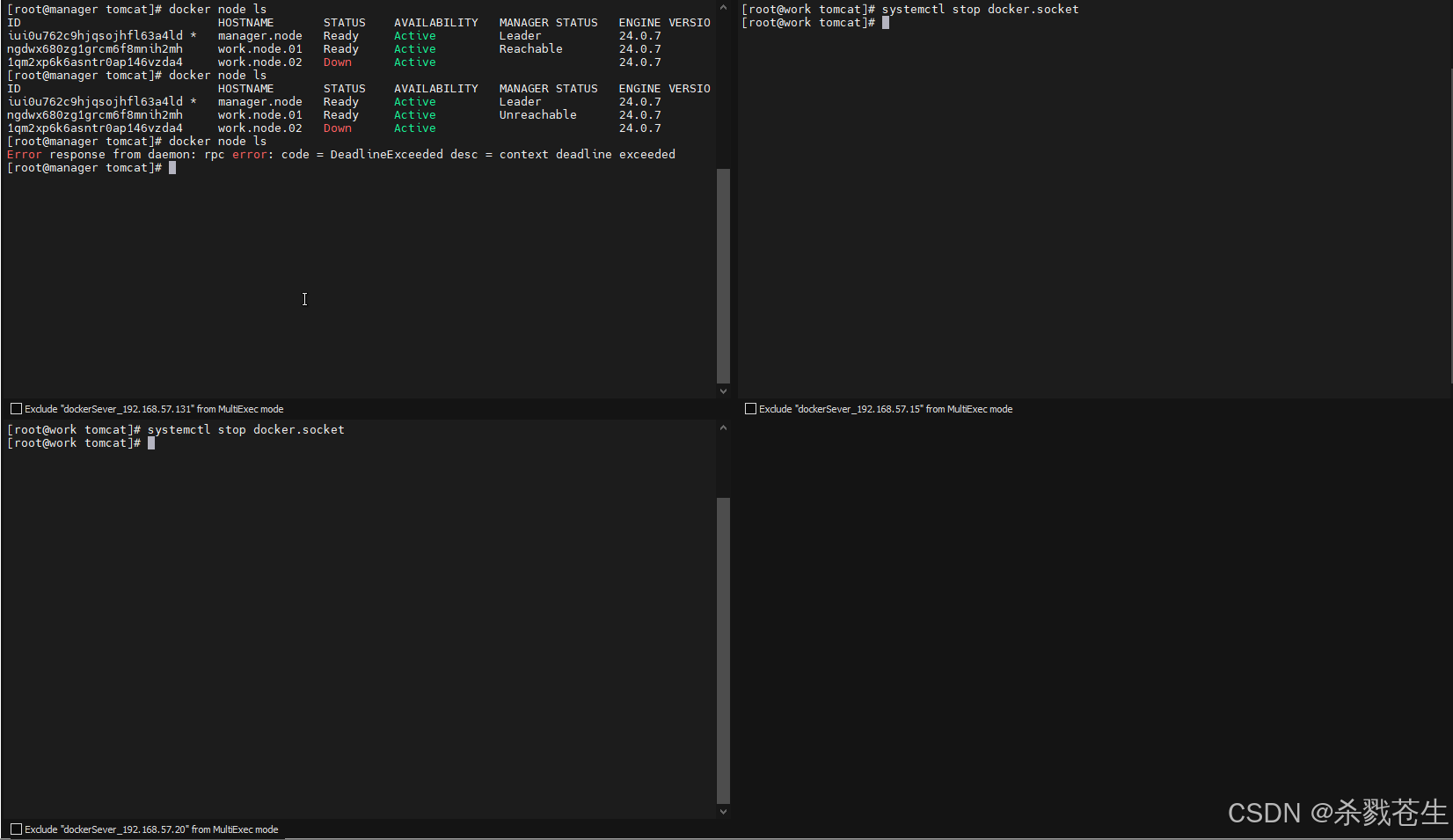
那如果咱们没有关闭work,只关闭一个manager是不是集群还能存活?验证如下:两个主节点关闭一个,剩余一个主节点,一个work节点,集群也办法运行。
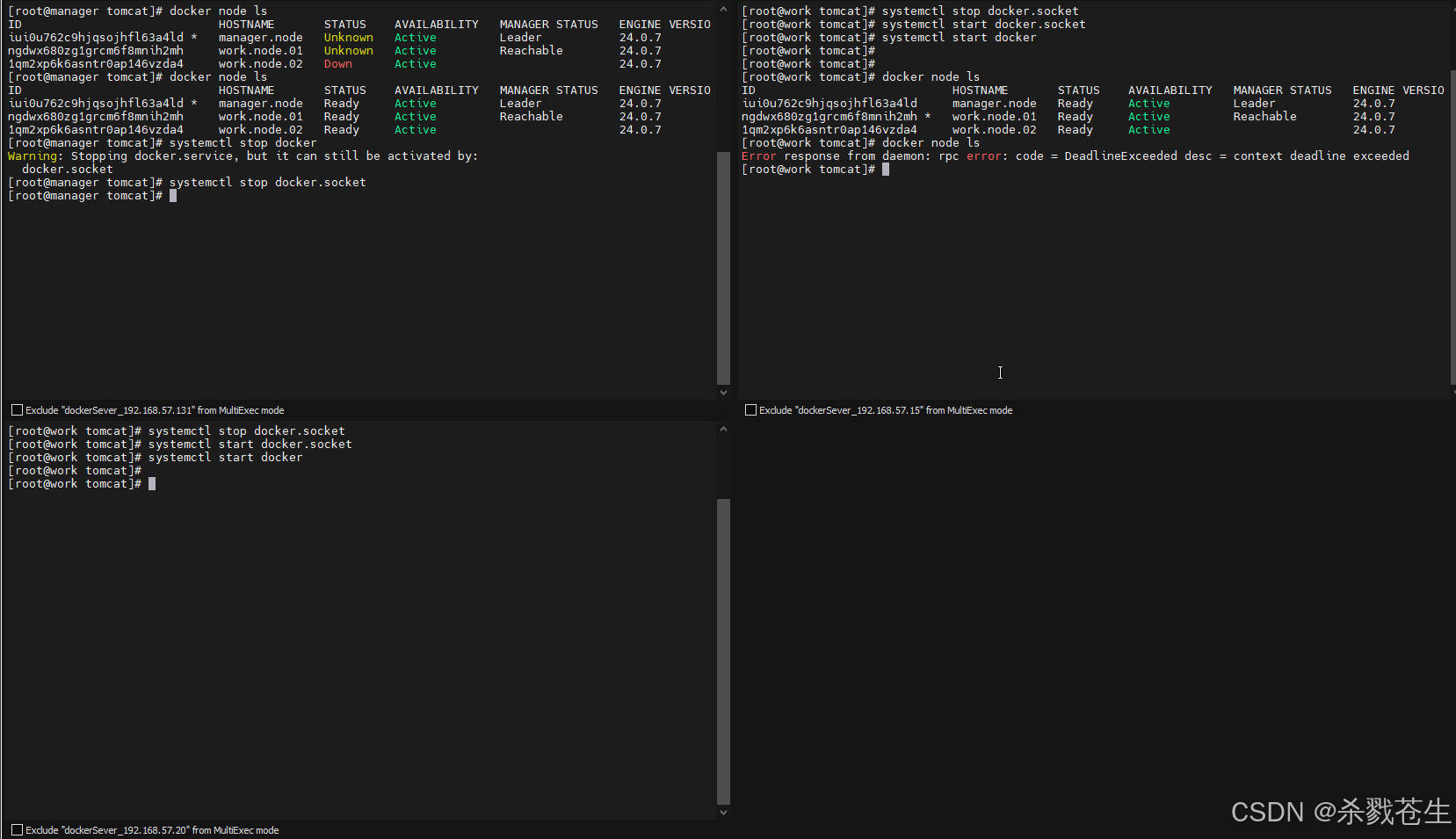 > manage宕机超过半数(包括半数),进群就会挂掉!
> manage宕机超过半数(包括半数),进群就会挂掉!
- 三主零从
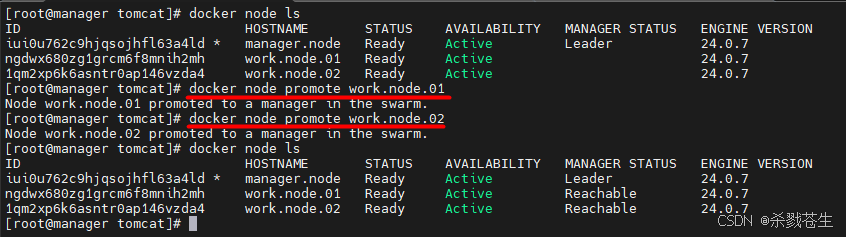
停掉另外两个节点,就会发现在 第一个manager上执行docker node ls命令会报错,因为集群蹦了。。。。
4.6、镜像部署集群
在【4.4】章节,咱们搭建起来了集群,那现在咱们开始在集群上运行咱们的项目。
要想运行项目,就需要使用一个命令docker service
4.6.1、docker service命令
4.6.1.1、创建service
# 跟单机启动差不多,参数啥的都是一样的。不同的是,启动时使用的命令不一样
#一个是 docker run 一个是docker service
docker service create --name my_tomcat tomcat
4.6.1.2、查看当前swarm下的服务
docker service ls
4.6.1.3、查看service的运行日志
docker service logs my_tomcat
4.6.1.4、查看service的运行在哪个节点
docker service ps my_tomcat
4.6.1.5、删除服务
docker service rm my_tomcat
4.6.1.6、扩容/缩容
#将my_tomcat服务扩容/缩容到5个
docker service scale my_tomcat=5
4.6.1.7、查看服务详情
docker service inspect my_tomcat
4.6.1.8、更新以及回滚
# 更新 操作参数 太多。。。只讲几个常用的。具体的自己使用 docker service update --help 查看帮助文档
dcoker service update
--image tomcat:9.0.6 my_tomcat #更新tomcat版本
--host-add www.baid.com:180.101.50.188 #增加host映射
--args querylog=/opt/log #增加参数,一般用于增加一些启动参数/环境变量/运行属性
--workdir xxx #指定运行目录
--dns-add #增加一个dns
#如果更新出错,可是使用rollback命令
docker service rollback my_tomcat
4.6.2、部署服务
假设咱们以tomcat为基础镜像,已经构建了一个自己项目的镜像tomcat:0.0.1,且集群已经构建完毕。
 现在咱们开始部署:
现在咱们开始部署:
- 在manager上创建service
#首先在 manager 节点
[root@manager tomcat]# docker service create --name my-tomcat tomcat:0.0.1
error response from daemon: rpc error: code = 4 desc = context deadline exceeded
#该错误表示找不到其他的节点,说明work节点上的端口没有开放。我加了防火墙后,问题解决。
[root@manager tomcat]# docker service create --name my-tomcat tomcat:0.0.1
unable to pin image tomcat:0.0.1 to digest: manifest unknown: manifest unknown
h3l43kn3sgmnqtfvd4sgqckay
虽然上面的执行报错了,但是其实咱们执行成功了,明显的看见创建了一条新的service。
 此时节点上,都没有在运行的容器
此时节点上,都没有在运行的容器


- 扩容
#将该服务扩容为5个
docker service scale [servicename]=5
#将 my_tomcat 扩容为5
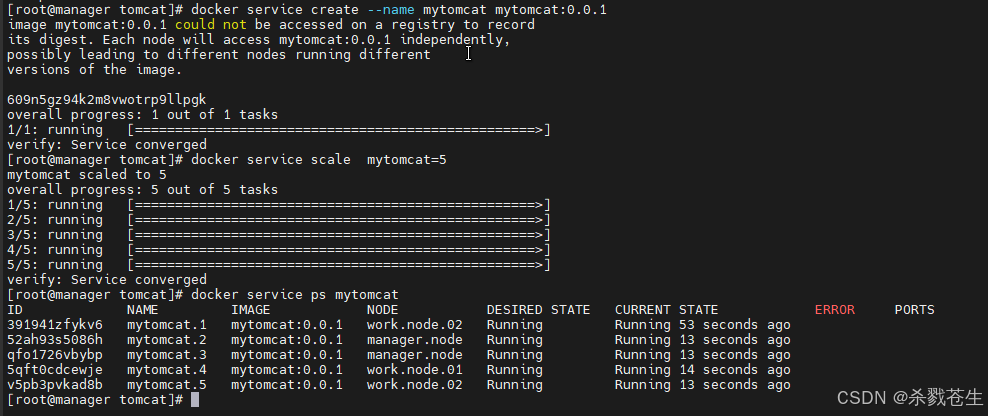
docker service scale my-tomcat=5
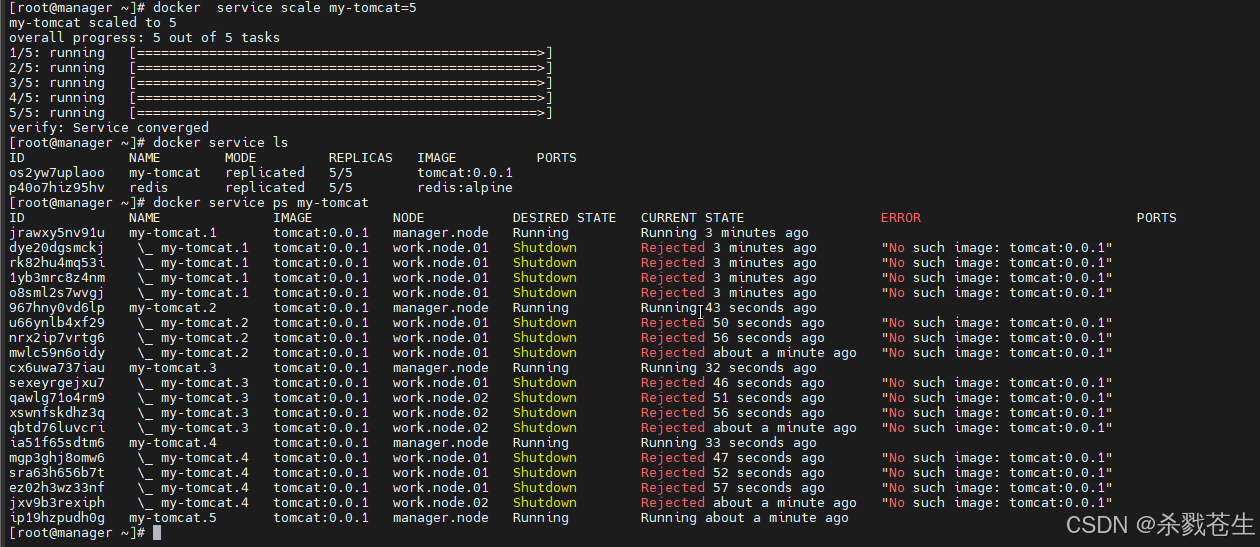 为啥会出现这种问题。是因为 其他的work节点,没有这个
为啥会出现这种问题。是因为 其他的work节点,没有这个tomcat:0.0.1镜像,所以其他启动的时候,会被拒绝。。启动到manager上了…
#咱们换一个,用redis的images启动,就会发现没问题了。。。因为其他节点redis的images都有
docker service create --name redis redis:alpine
docker service scale redis=5
 再次验证一下,服务都启动在manager,是不是work节点上包的问题哈
再次验证一下,服务都启动在manager,是不是work节点上包的问题哈
#再次验证一下是不是包的问题哈。
#在每个节点上都构建一个程序包的景象 mytomcat:0.0.1
docker build -f dockerfile -t mytomcat:0.0.1 .
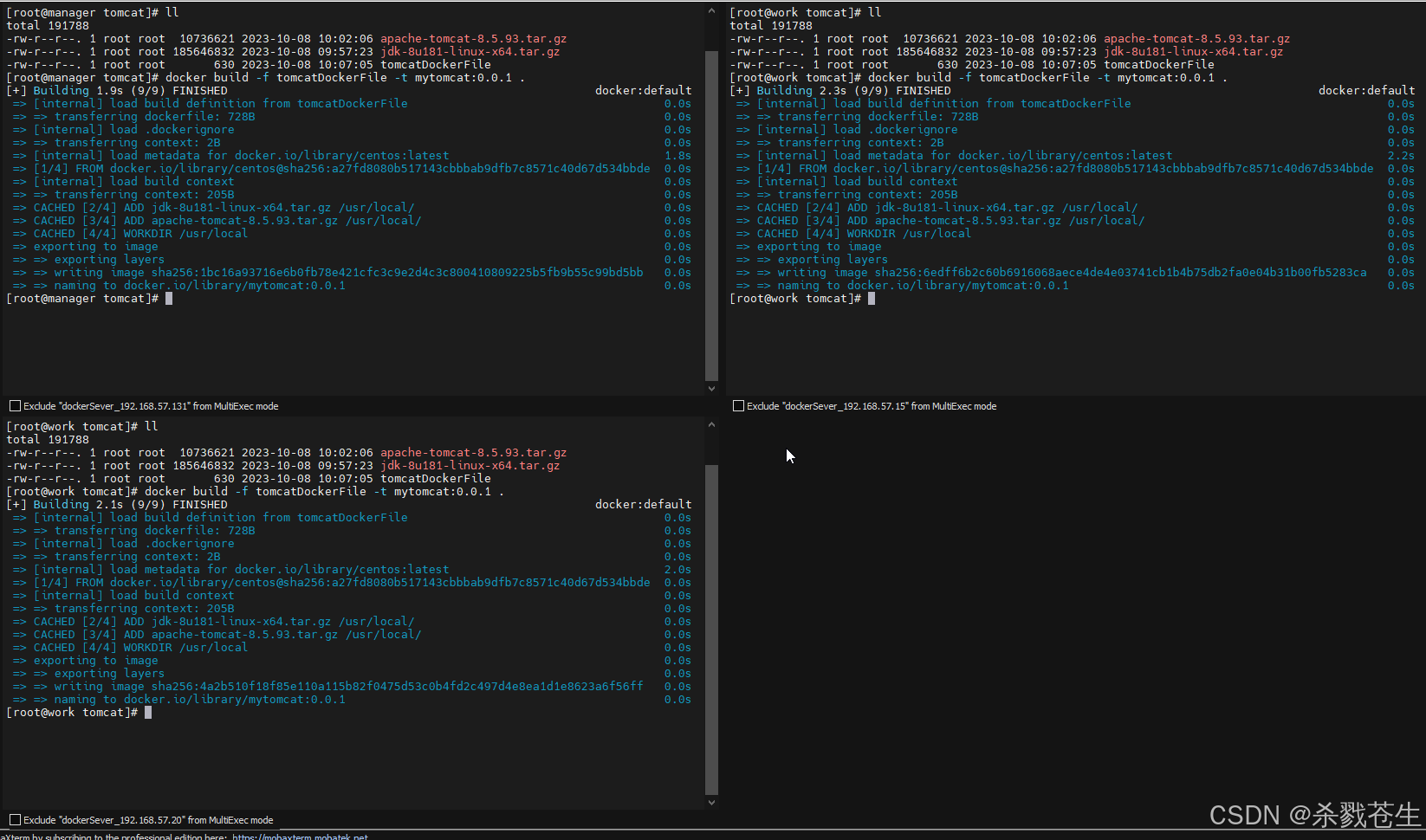
赞 (0)
您想发表意见!!点此发布评论



发表评论