Open-TeleVision——通过VR人机合一控制人形机器人训练:兼备远程控制和深度感知能力
464人参与 • 2024-08-06 • vr
前言
7.3日,我司七月在线(集ai大模型职教、应用开发、机器人解决方案为一体的科技公司)的「大模型机器人(具身智能)线下营」群里的一学员发了《open-television: teleoperation with immersive active visual feedback》这篇论文的链接[其submitted on 1 jul 2024 (v1), last revised 8 jul 2024 (this version, v2)]
我当时快速看了一遍,还是挺有价值的一个工作(与moblie aloha、humanplus最大的区别是,moblie aloha是通过主动臂遥控,humanplus则是用过影子系统遥控,而television则是远程遥控,之后机器人再自主操作),一直想做下解读来着
无奈过去一周一直在弄mamba2的解读,所以没来得及弄,但后来考虑到
- 7.11,在和一长沙的朋友聊到我司给工厂的机器人解决方案时,他无意中也发了「open-television」这个工作的链接给我,说他也在关注这个团队,并表示:“vr+具身智能,应用场景太大了”
- 之前本计划解读完mamba2之后,便解读open-television、我司7方面review微调gemma2,再之后是ttt、nature审稿微调、序列并行
但没想7.12这天,flashattention3又来了..,实属应接不暇
故打算加快发布一篇篇新文章的节奏,即暂停对mamba2的修订(过几天后继续),而先开始解读这个open-television了
故,本文来了
第一部分 open-television的原理、创新点与技术架构
1.1 open-television的原理与创新点
1.1.1 之前的各种远程操作方法
基于模仿学习的机器人在本博客的前几篇机器人文章中已经介绍过很多了,其中有个关键点便是数据的收集
而数据收集的其中一种重要的方式便是远程操作,它不仅提供了准确和精确的操
作演示,还提供了自然和流畅的轨迹,使学习到的策略能够推广到新的环境配置和任务中
而各种远程操作方法包括且不限于

- 使用vr设备 [learning visuotactile skills with two multifingered hands, open teach: a versatile teleoperation system for robotic manipulation]
- rgb相机[anyteleop:a general vision-based dexterous robot arm-hand teleoperation system, robotic telekinesis: learning a robotic hand imitator by watching humans on youtube , a mobile robot hand-arm teleoperation system by vision and imu]
- 可穿戴手套 [a systematic review of commercial smart gloves: current status and applications, high-fidelity grasping in virtual reality using a glove-based system, a glove-based system for studying hand-object manipulation via joint pose and force sensing]
- 定制硬件 [aloha之learning fine-grained bimanual manipulation with low-cost hardware , airexo: low-cost exoskeletons for learning whole-arm manipulation in the wild]
其中,aloha框架[10]提供了对细粒度操作任务的精确控制,具有精确的关节映射。在作者团队发现基于vr的远程操作系统通过手部重定向也可以实现对细粒度操作任务的精确控制,而不是采用关节复制,详见:act的原理解析:斯坦福炒虾机器人moblie aloha的动作分块算法act
大多数远程操作系统中有两个主要组件:执行和感知
- 对于执行,使用关节复制来操纵机器人提供了高控制带宽和精度 [aloha, yell at your robot: improving on-the-fly from language corrections, gello: a general, low-cost, and intuitive
teleoperation framework for robot manipulators]
然而,这要求操作员和机器人必须在同一地点,无法进行远程控制,即每个机器人硬件需要与一个特定的远程操作硬件配对
重要的是,这些系统尚不能操作多指灵巧手(moblie aloha和umi确实都没有灵巧手,dexcap才有)
好在,vr头显制造商通常集成内置的手部跟踪算法,这些算法融合了来自多种传感器的数据,包括多个摄像头、深度传感器和imu。通过vr设备收集的手部跟踪数据通常被认为比自开发的视觉跟踪系统更稳定和准确,而后者仅使用了所提到传感器的一部分(rgb+rgbd[4],depth + imu[6]等) - 对于感知,最直接的方法是用操作员自己的眼睛以第三人称视角 [robotic telekinesis,anyteleop, learning visuotactile skills with two multifingered hands] 或第一人称视角 [mobile aloha, dexcap] 观察机器人任务空间
然,这不可避免地会在远程操作过程中遮挡操作员的视线(例如,被机器人手臂或躯干遮挡),操作员无法确保收集的演示已捕捉到策略学习所需的视觉观察
重要的是,对于细粒度的操作任务,远程操作员很难在操作过程中近距离直观地观察物体
此外,第三人称静态摄像头视图或在vr头戴设备中使用透视功能 [learning visuotactile skills with two multifingered hands, open teach, using apple vision pro to train and control robots] 也会遇到类似的挑战
提前说一嘴,总之,在television之前,没有系统同时提供远程控制和深度感知:操作员被迫在直接观看(需要物理存在)和rgb流(放弃深度信息)之间做出选择。 通过利用立体流媒体,television将首次在单一设置中提供了这两种功能
1.1.2 television的创新点与改进之处
为了解决上述一系列问题,来自加州大学圣地亚哥分校、麻省理工学院的研究者们(xuxin cheng, jialong li, shiqi yang, ge yang, xiaolong wang,又是个华人团队)于24年7月初提出了本television
如下图所示,便是television的远程操作数据收集和学习设置

- 上图左侧:是远程操作系统
首先,vr设备(虽然系统对vr设备型号不敏感,但还是选择的apple visionpro作为vr设备平台)将人体的手部、头部和手腕的姿态流式传输到服务器
其次,服务器再将人类姿态重新定向到机器人(用了两个机器人做实验,一个来自宇树科技的具有多手指的unitree h1,一个则是傅里叶智能的具有抓手的fourier gr1)
最后,将关节位置目标发送到机器人
换言之,通过捕捉人类操作员的手部姿势,然后进行重新定位以控制多指机器人手或平行爪抓手,最后依靠逆运动学将操作员的手根位置转换为机器人手臂末端执行器的位置 - 上图右侧:使用基于transformer的动作分块算法即act,为每个任务训练模仿策略,比如transformer编码器捕捉图像和本体感觉token的关系,transformer解码器输出特定块大小的动作序列
而television对允许细粒度操作的主要贡献来自感知,它结合了具有主动视觉反馈的vr系统
即在机器人头部使用单个主动立体rgb相机,配备2或3个自由度的驱动,模仿人类头部运动以观察大工作空间。 在远程操作过程中,摄像头会随着操作员的头部移动而移动,进行流
媒体传输,即如下图所示

这是因为实时、自我中心的3d观察传输到vr设备,使得人类操作员看到的是机器人看到的。 这种第一人称主动感知为远程操作和策略学习带来了好处
- 对于远程操作,它为用户提供了一种更直观的机制,通过移动机器人的头部来探索更广阔的视野,并关注重要区域以进行详细交互
- 对于模仿学习,television的策略将模仿如何在操作的同时主动移动机器人的头部
与其采用进一步的静态捕获视图作为输入,主动摄像头提供了一种自然的注意机制,专注于下一步操作相关区域并减少需要处理的像素,从而实现平滑、实时和精确的闭环控制
1.2 television system:实现实时远程遥控
1.2.1 vr将人体姿态传到服务器,服务器处理重定向,传达目标姿态给机器人
humanplus通过影子系统实现了人类操作员对机器人的实时控制,那television又是如何做到实时远程遥控的呢
事实上,television基于vuer [19]开发了一个网络服务器
- vr设备将操作员的手、头和手腕姿态以 se(3)格式流式传输到服务器
- 服务器处理人到机器人的运动重定向
下图便显示了机器人如何跟随人类操作员的头部、手臂和手的动作

反过来,机器人以每只眼480x640的分辨率流式传输立体视频(整个循环以60 hz的频率进行)

且过程中只考虑它们的主动感知颈部、两个7自由度的手臂和末端执行器,而其他自由度未被使用。其中,h1的每只手有6个自由度 [20],而gr-1有一个1自由度的下颚夹持器
此外,为了主动感知,设计了一个具有两个旋转自由度(偏航和俯仰)的云台,安装在h1躯干顶部,该云台由3d打印部件组装而成,并由dynamixel xl330-m288-t电机驱动 [21]
对于gr-1,使用了厂家提供的3自由度颈部(偏航、滚动和俯仰),且两个机器人都使用zed mini [22] 立体相机提供立体rgb流
1.2.2 对机器人手臂、手部的控制
对于手臂控制而言,人类手腕姿态首先转换为机器人的坐标系。 具体来说,机器人末端执行器与机器人头部之间的相对位置应与人类手腕和头部之间的相对位置相匹配,且机器人的手腕方向与人类手腕的绝对方向对齐,这些方向是在初始化apple visionpro手部追踪后端时估计的
这种对末端执行器位置和方向的差异化处理确保了当机器人的头部随人类头部移动时,机器人末端执行器的稳定性
过程中,television采用基于pinocchio[23, 24, 25]的闭环逆运动学(clik)算法来计算机器人手臂的关节角度
输入的末端执行器姿态使用se(3)群滤波器进行平滑处理,该滤波器由pinocchio的 se(3)插值实现,从而增强了ik算法的稳定性
为了进一步降低ik失败的风险,当手臂的可操作性接近其极限时,加入了关节角度偏移。 这种校正过程对末端执行器的跟踪性能影响最小,因为偏移量被投影到机器人手臂雅可比矩阵的零空间,从而在解决约束的同时保持跟踪精度
对于手部控制而言,通过dex-retargeting,一个高度通用且计算速度快的运动重定向库,人手关键点被转换为机器人关节角度命令 [anyteleop]
television的方法在灵巧手和夹持器形态上都使用了向量优化器。 向量优化器将重定向问题表述为一个优化问题 [anyteleop, dexpilot],而优化是基于用户选择的向量定义的:
在上述公式中
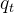 表示时间
表示时间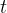 时的机器人关节角度
时的机器人关节角度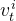 是人手上的第
是人手上的第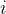 个关键点向量
个关键点向量- 函数
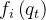 使用来自关节角度的正向运动学计算机器人手上的第个关键点向量
使用来自关节角度的正向运动学计算机器人手上的第个关键点向量 - 参数 α是一个缩放因子,用于考虑人手和机器人手之间的尺寸差异(将其设置为1.1用于inspire手)
- 参数 β权衡了确保连续步骤之间时间一致性的惩罚项。 优化是使用顺序最小二乘二次规划(slsqp)算法[27]在nlopt库[28]中实时进行的,正向运动学及其导数的计算在pinocchio[24]中进行
此外
- 对于灵巧手,使用7个向量来同步人手和机器人手,其中
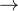 5个向量表示手腕和每个指尖关键点之间的相对位置 另外2个向量,从拇指指尖延伸到主要指尖(食指和中指),以增强细致任务中的运动精度
5个向量表示手腕和每个指尖关键点之间的相对位置 另外2个向量,从拇指指尖延伸到主要指尖(食指和中指),以增强细致任务中的运动精度 - 对于夹持器,优化是使用一个单一向量实现的,该向量定义在人类拇指和食指指尖之间。 这个向量与夹爪上下端之间的相对位置,使得通过简单地捏住操作员的食指和拇指,可以直观地控制夹爪的开合动作
1.3 television的技术架构:选择act做模仿学习
1.3.1 act作为模仿学习算法,但做了两项修改
television和moblie aloha一样,选择 act[10]作为的模仿学习算法

但进行了两项关键修改
- 首先,用更强大的视觉骨干 dinov2替换了resnet,这是一个通过自监督学习预训练的视觉transformer(vit)[详见dinov2: learning robust visual features without supervision, vision transformers need registers]
- 其次,使用两幅立体图像而不是四幅单独排列的 rgb 摄像机图像作为transformer编码器的输入
dinov2 骨干为每张图像生成 16 × 22个token。 状态token是从机器人的当前关节位置投影出来的,且使用绝对关节位置作为动作空间 对于 h1,动作维度是 28(每个手臂 7 个,每只手 6 个,主动颈部 2 个); 对于gr-1,动作维度是19(每只手臂7个,每个夹爪1个,主动颈部3个)
至于本体感觉token是从相应的关节位置读数投影出来的
1.3.2 act相关的超参数设置
用于训练act [10] 模型的超参数详见下图(虽然这些超参数在所有基线和所有任务中大多数是一致的,但也有一些例外,包括块大小和时间加权)

提前说一嘴,在所有任务中television使用60的块大小,除了罐插入任务中,television使用100的块大小。 在television的设置中使用60的块大小有效地为机器人提供了大约一秒的记忆,与推理和动作频率60hz相对应
尽管如此,我们注意到在罐插入任务中,使用更大的块大小(对应于包含更多的历史动作)对模型执行正确的动作序列是有利的
第二部分 television的4个任务及其效果表现
2.1 4个任务的具体操作:分类、插入、折叠、卸载
2.1.1 罐子分类:5个雪碧与5个可乐的分类
如下图a所示,此任务涉及将随机放置在桌子上的可乐罐(红色)和雪碧罐(绿色)分类

罐子一个接一个地放在桌子上,但位置和类型(可乐或雪碧)是随机的
- 目标是拾起桌子上的每个罐子并将其扔进指定的箱子:左边是红色的可乐,右边是绿色的雪碧
- 解决此任务需要机器人根据每个罐子的位置信息和方向进行自适应泛化,以实现准确抓取。 这也要求策略能够根据当前持有的罐子的颜色调整其计划的动作
每一集包括连续分类10个罐子(5个雪碧和5个可乐随机)
2.1.2 罐子插入:将苏打罐放入槽中
如下图c所示,此任务涉及从桌子上拾取软饮料罐,并将它们按预定顺序小心地插入容器内的槽中

虽然和上一个任务罐子分类都涉及饮料罐的操作,但此任务要求更精确和细致的动作,因为成功的插入需要高精度
此外,此任务采用了不同的抓取策略。 在之前的罐子分类任务中,机器人只需要将罐子扔到指定区域,因此形成了一种涉及手掌和所有五个手指的抓取策略,这是一种宽容但不精确的抓取策略
在这个任务中,为了将罐子插入仅比罐子稍大的槽中(苏打罐的直径大约为5.6厘米,槽的直径大约为7.6厘米),television采用了一种更类似于捏的策略,仅使用拇指和食指,从而在罐子的放置上进行更细微的调整
这两种不同的抓取策略表明,系统能够完成具有复杂手势要求的任务(该任务的每一集都包括将所有六个罐子放入正确的槽中)
2.1.3 折叠
如下图d所示,此任务涉及将毛巾折叠两次

任务的区别在于它展示了系统操作柔软和顺从材料(如毛巾)的能力。 该任务的动作序列如下展开:
- 捏住毛巾的两个角
- 提起并折叠
- 轻轻将毛巾移到桌子的边缘以准备进行第二次折叠
- 再次捏住、提起并折叠
该任务的每一集都包括一次完整的毛巾折叠
2.1.4 卸载
如下图e所示,此任务是一个复合操作,涉及管子的提取和手内传递

在此任务中,一个芯片管被随机放置在分类盒内的四个槽中的一个中。目标是识别包含管子的槽,用右手提取管子,传递给左手并将管子放置在预定位置
为了成功执行这个任务,机器人需要视觉推理来辨别管子的位置信息,并且需要准确的动作协调来提取和传递管子。 这个任务的每一集包括从4个随机槽中拾取4个管子,传递到另一只手,最后放在桌子上
2.2 4个任务的具体效果——模仿学习
作者团队对television系统的关键设计选择进行了一系列消融实验,并通过真实世界的实验展示了它们的有效性
- 两个基线分别是w. resnet18「它使用了原始的act视觉骨干resnet18 [31]」,以及w/o stereo input
后者只从左图像中获取视觉token,而不是同时从左图像、右图像中一块获取「the two baselines are w. resnet18, which uses the original act visual backbone resnet18 [31], and w/o stereo input, which only takes the visual tokens from the left image instead of both,相当于w/o stereo input只是单个rgb图像」 - 所有模型都使用adam w优化器 [32, 33] 进行训练,学习率为 5e − 5,批处理大小为 45,并在单个 rtx 4090 gpu 上进行 25k次迭代
且除罐子分类(包括 h1 罐子分类和gr-1 罐子分类)外,所有任务都使用20轮人类演示进行训练
相比之下,罐子分类仅使用10轮演示,且每轮演示又包括10个(gr-1罐分类为6个)单独的罐分类操作。 因此,10轮演示下来总计包含100个单独的分类操作,提供了充足的训练数据
2.2.1 在罐头分类和罐头插入任务上的结果表现
2.2.1.1 当不用dinov2时,h1执行罐子分类的结果:先pick后place
作者团队在 h1 和 gr-1 机器人上进行分类罐头任务。 所有其他任务仅由h1机器人执行。从下表中显示的实验结果来看,可以看到到原始的resnet骨干网络未能充分执行所有4项任务
对于can sorting而言,主要就两个步骤:先抓后放。首先,先看h1执行罐子分类(即can sorting)的效果(为方便大家接下来的理解,我july多说一句,下面,你会看到一系列分析、改进,之所以有这些分析、改进,其实都在于那个数字没到90%,^_^)
- 相比于dinov2,w. resnet18在拾取和分类方面明显较差(成功率分别仅为74%、58%),可能是由于其骨干网络的限制,为何这么说呢?
因为,在原始act实现中,使用了4个摄像头(两个固定,两个腕部安装)以缓解使用rgb图像时缺乏显式空间信息的问题
然而,作者在做实验时,虽然针对resnet用了立体rgb摄像头,但在数量上毕竟只是两个,这可能使得resnet骨干网络的空间信息检索更加困难(毕竟原始act使用resnet时建议4个摄像头,这里只配了2个摄像头) - w/o stereo input表现的更差:无深度信息,从而pick不好导致place也不好
毕竟其没有来自立体输入的隐式深度信息(如上文说过的,which only takes the visual tokens from the left image instead of both), 使得w/o stereo input无法正确拾取pick罐头(46%成功率),正因为它不能很好的把罐头抓起来,所以便导致了紧随其后的较低的分类准确率(52%成功率),导致作者团队必须人工频繁帮助其抓取罐子,这一动作干扰了第二步的视觉推断(相当于如果w/o stereo input第一步的pick不好,则第二步的place效果 即便有人工辅助也不会好到哪去)
2.2.1.2 当用上dinov2之后,h1和gr-1在罐子分类第二步place上的表现
那当作者团队用上dinov2算法后,h1和gr-1在pick之后的place这第二步上的表现如何呢(为何重点看place呢,因为dinov2有深度信息,不至于像w/o stereo input pick不好,所以就重点看place的效果)
不出预料,h1的表现还好(h1的place成功率是88%),这能理解,毕竟h1在面对place这个任务时,用的算法越先进 最终place的效果越好(算法上,从w/o stereo input、resnet18到dinov2,效果上,从52%、58%到88%)
| h1 can sorting之第二步place | |
| dinov2 | 88% |
| resnet18 | 58% |
| w/o stereo input | 52% |
但为何gr-1的表现却如此之差呢(gr-1的place成功率才区区60%)?这就奇怪了,在算法变更强的前提下,dinov2的效果竟没有随之而提高(dinov2的成功率反倒还不如w/o stereo input的63%了)
| gr-1 can sorting之第二步place | |
| dinov2 | 60% |
| resnet18 | 50% |
| w/o stereo input | 63% |
h1远高于gr-1的主要原因在于,毕竟h1是灵巧手,而gr-1是夹爪,使得
- 当h1的机器人手抓住罐子时,摄像头能够看到罐子的颜色并根据所见做出动作
- 相比之下,当gr-1的夹持器抓住罐子时,由于显著的遮挡,摄像头几乎无法辨认颜色,复杂了视觉推断

正因为gr-1在抓住罐子准备分类到对应的收纳盒中时,罐子被夹持器遮挡严重,阻碍了gr-1的视线,从而使得无论用什么算法,都不好使,哪怕是最强的dinov2
而gr-1这“在place步骤上的仅仅60%的准确率”岂能忍?故接下来,得想办法彻底改进之
怎么改呢?算法上是没啥改进空间了,那非算法上呢..
2.2.1.3 gr-1执行罐子分类第二步place步骤时给罐子贴上带颜色的胶布
功夫不负有心人,后来,如television论文附录b中所示,他们还另外做了一个实验,即为避免由于gr1的夹持器导致的视觉遮挡,故他们在gr1执行第二步place步骤时给罐子贴上了带着颜色的胶布

最终使得gr1无论用什么算法,都在放置place这个步骤上的的成功率得到显著提高(w/o stereo input从0.63提升到0.93,w. resnet18从0.50提升到0.97,dinov2的成功率直接从60%到100%),具体如下图右侧所示(从右到左看:←)

且他们又顺带看了下gr-1 罐子分类在抓取pick这个步骤上的表现(试问为何会有这个实验或分析呀,原因在于本2.2.1节开头说过的,现在place已经解决了到90%甚至超过90%的成功率了,但pick目前在各个算法之下的73% 83% 87%都还没到90%的成功率呢),发现
- w. resnet18和dinov2在抓取任务中的成功率也都有所提高(当然 提高不会太明显,毕竟只是加个颜色胶布而已,没法很大的促进抓取pick操作的效果)
- 但 w/ostereo input并没有表现出类似的改进,这种差异进一步验证了上面提到过的观点,即想成功的抓取pick罐头需要立体图像的空间信息
2.2.2 折叠与卸载任务的结果表现
对于折叠衣服这个任务而言,我们来看机器人在不掉落毛巾的情况下连续执行两次折叠的能力,结果如下图左侧所示
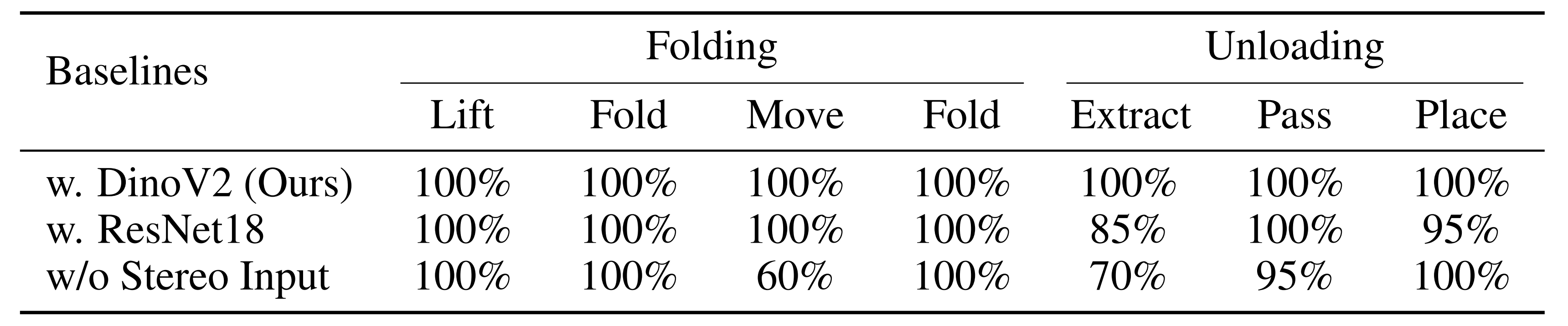
dinov2和w. resnet18模型在执行折叠任务时均达到了100%的成功率,这种高成功率是折叠衣服这个任务具有高度的动作重复度
另一方面,w/o stereo input由于没有立体输入,所以偶尔在folding的第三阶段-move时失败(2/5次失败,即60%成功率),在这一阶段,机器人应该轻轻地将毛巾移到桌子的边缘,以便进行第二次折叠
可由于没有立体输入倾向于将手按得太重在桌子上,阻碍了毛巾的成功移动。 这种动作可能是由于使用单个rgb图像缺乏深度信息,因为这一步需要机器人根据与桌子的距离调整手部施加的力量
对于卸载这个任务而言,分别评估三个连续阶段的成功率:提取管子extract、手中传递pass和放置place
如上图右侧所示
- dinov2模型在所有的extract-pass-place三个阶段都达到了100%的成功率
- 而使用resnet18和没有立体输入的w/o stereo input在某些槽中提取管子extract时失败,分别为3/20次失败(85%成功率)和6/20次失败(70%成功率)
resnet18在提取管子时有3/20次失败还好,但为何w/o stereo input在提取管子时会达到6/20次失败呢,其实w/o stereo input之所以会出现6/20次失败(70%成功率),还是在于其没有立体输入,部分原因是它无法正确估计管子和手之间的相对方向 - 至于手中传递pass和放置place相对简单,因为这两个阶段在数据收集过程中不涉及太多随机化。然而,使用resnet18和没有立体输入的w/o stereo input仍然偶尔会失败(两者均为1/20失败),而dinov2模型在这两个阶段没有出错
第三部分 硬件相关的配置
3.1 television的相机
下图比较了广角相机和我们的主动相机设置的视图

单个静态广角相机仍然难以捕捉所有的兴趣点(poi)。 必须安装多个相机 [10, 12] 或为每个任务调整相机位置
静态广角相机还捕捉到无关的信息,这如下图所示,为训练和部署带来了额外的计算成本(对训练和部署步骤各抽取100个批次,并平均其计算时间。 基线名称中的数字表示批次大小。裁剪主动从 640x480下采样到308x224,导致每个摄像头有352个图像标记。广角镜头以相同的比例下采样至588x336,导致每个摄像头有1008个图像标记。 由于rtx 4090 gpu的内存限制,对广角镜头使用了10的批量大小)

television在相同批量大小下训练速度快 2倍,并且可以在4090 gpu上容纳 4倍的数据。在推理过程中,television也快 2倍,留出足够的时间进行ik和重定向计算,以达到 60hz的部署控制频率
当使用广角图像作为输入时,推理速度较低,大约为 42帧每秒
此外,对于静态摄像头,操作员需要注视图像边缘的兴趣点,这会带来额外的不适和非直观性,因为人类使用中央(中央凹)视觉来聚焦 [34, 35]
3.2 远程操作
接下来,再展示下television能够完成的更多远程操作任务
- 木板钻孔任务表明,由于系统兼容灵巧的手部操作,可以使用为人类设计的重型(1千克)工具,并且可以施加足够的力量将木板钻透。 这样的任务对于夹持器来说几乎是不可能的

- 耳塞包装任务表明我们的系统足够灵巧和响应迅速,能够执行敏捷的双手协调操作

- 移液管任务表明television也能够执行精确的动作。这也是一个极其困难或不可能由机械手夹持器完成的任务,因为移液管的使用是专为类人手设计的

尽管h1类人机器人上的电机是带有行星减速器的准直接驱动电机,这些电机已知具有齿轮间隙且精度和刚度远低于直接驱动电机,但在有人工操作员参与的情况下,television仍能实现高精度操作
此外,系统还实现了下图所示的远程遥操作,即位于美国波士顿的操作员可以操作位
于美国圣地亚哥(大约3000英里外)的机器人

3.3 灵巧手
对于h1机器人的设置,与斯坦福的humanplus一致,也是使用的inspire robots的拟人手 [20]
其每只手有五根手指和12个自由度,其中6个是驱动自由度:拇指有两个驱动自由度,其余每根手指各有一个驱动自由度

- 每个非拇指手指在掌指关节(mcp)处有一个单独的驱动旋转关节,作为整个手指的驱动自由度。这四根手指的近端指间关节(pip)通过连杆机构由mcp关节驱动,增加了四个欠驱动自由度
- 拇指在腕掌关节(cmc)处配备了两个驱动自由度
- 拇指的mcp和指间(ip)关节也由连杆机构驱动,增加了两个欠驱动的自由度
3.4 远程操作界面
下图是television的基于网络的跨平台界面,不仅可以从vr设备访问,还可以从笔记本电脑、平板电脑和手机访问

左:apple vision pro。中:meta quest。右:macbook、ipad和iphone
在vr设备上,用户可以进入沉浸式会话,开始通过手部和手腕姿态流进行远程操作。 在其他设备上,手和手腕的流媒体传输不可用,但用户仍然可以看到传输的图像,并通过在设备屏幕上拖动来控制机器人的主动颈部
后记
继斯坦福这4个开源机器人:moblie aloha、umi、dexcap、humanplus之后「这4个开源机器人都在本博客内仔细解读过,详见该系列:」,迎来了加州大学这个television
- 一方面,television的每个附录 都解读了,且一些重要的表述会引用原英文论文中的描述
- 二方面,我在解读过程中特别注意尽可能让每个读者阅读下来,在思维逻辑上比读原论文还更清晰,也会经常出现说唱人口中所谓的那个punchline(点睛之笔)
比如2.2.1节开头所写的
“为方便大家接下来的理解,我july多说一句,下面,你会看到一系列分析、改进,之所以有这些分析、改进,其实都在于那个数字没到90%”
这也算是为何我写的如此受欢迎的原因之一吧
解读完之后,感慨:1 总算有个斯坦福之外的了,2 实际落地还是得做不少改进、改造工作
赞 (0)
您想发表意见!!点此发布评论




发表评论