Oracle数据库使用 listagg去重删除重复数据的方法汇总
284人参与 • 2025-01-21 • Oracle
listagg聚合之后很多重复数据,下面是解决重复数据问题
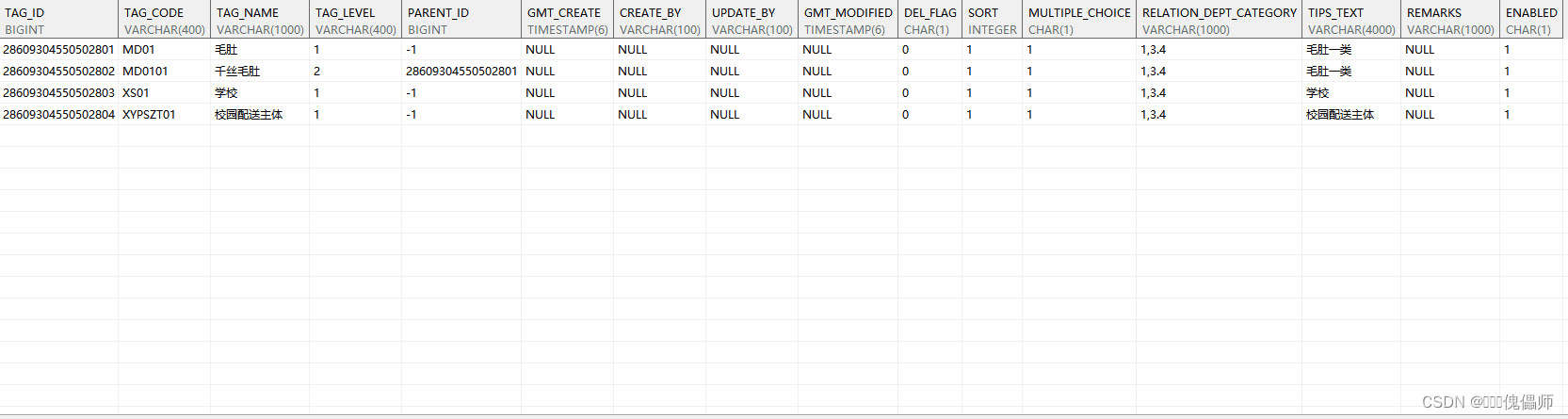
案例表
create table "dept_tag_info"
(
"tag_id" bigint not null,
"tag_code" varchar(200),
"tag_name" varchar(500),
"tag_level" varchar(200),
"parent_id" bigint,
"gmt_create" datetime(6),
"create_by" varchar(50),
"update_by" varchar(50),
"gmt_modified" datetime(6),
"del_flag" char(1),
"sort" integer,
"multiple_choice" char(1),
"relation_dept_category" varchar(500),
"tips_text" varchar(2000),
"remarks" varchar(500),
"enabled" char(1),
constraint "dept_tag_info_new_pk" not cluster primary key("tag_id")) storage(on "ctbiyi_data_v3", clusterbtr) ;
comment on table "dept_tag_info" is '企业标签基础信息表';
comment on column "dept_tag_info"."tag_id" is '主键';
comment on column "dept_tag_info"."tag_code" is '标签编码';
comment on column "dept_tag_info"."tag_name" is '标签名称';
comment on column "dept_tag_info"."tag_level" is '标签层级';
comment on column "dept_tag_info"."parent_id" is '父节点编码id';
comment on column "dept_tag_info"."gmt_create" is '创建时间';
comment on column "dept_tag_info"."create_by" is '创建人';
comment on column "dept_tag_info"."update_by" is '修改人';
comment on column "dept_tag_info"."gmt_modified" is '修改时间';
comment on column "dept_tag_info"."del_flag" is '删除标记 0-未删除 1-已删除';
comment on column "dept_tag_info"."sort" is '排序';
comment on column "dept_tag_info"."multiple_choice" is '多选(1是 0否)';
comment on column "dept_tag_info"."relation_dept_category" is '关联主体';为了方便大家看所以所有小写
select
t.tag_code,
t.tag_name,
listagg(t.tag_level, ',') within group(order by t.tag_level) as tag_levels
from
dept_tag_info t
group by
t.tag_code,
t.tag_name;第一种:使用wm_concat() + distinct去重聚合
select
t.tag_code,
t.tag_name,
wm_concat(distinct t.tag_level) as tag_levels
from
dept_tag_info t
group by
t.tag_code,
t.tag_name;第二种:使用listagg,先去重,再聚合
select
t.tag_code,
t.tag_name,
listagg(t.tag_level, ',') within group(order by t.tag_level) as tag_levels
from
(select distinct s.tag_code, s.tag_name, s.tag_level
from dept_tag_info s) t
group by
t.tag_code,
t.tag_name;第三种:xmlagg(xmlparse(content t.tag_level || ‘,’ wellformed) order by t.tag_level):
使用 xmlagg 和 xmlparse 函数将 tag_level 字段聚合为一个用逗号分隔的字符串,并按 tag_level 排序。
getclobval():将 xml 类型的结果转换为 clob(character large object)。
rtrim(…, ‘,’):去掉聚合结果末尾的逗号。
内部子查询 select distinct s.tag_code, s.tag_name, s.tag_level from dynamic_ctbiyi_v3.dept_tag_info s:
选择唯一的 tag_code、tag_name 和 tag_level
select
t.tag_code,
t.tag_name,
rtrim(
xmlagg(
xmlparse(content t.tag_level || ',' wellformed)
order by t.tag_level
).getclobval(),
','
) as tag_levels
from
(select distinct s.tag_code, s.tag_name, s.tag_level
from dept_tag_info s) t
group by
t.tag_code,
t.tag_name;listagg 的优缺点
优点:
简洁和易用:listagg 语法简单,易于理解和使用。
性能较好:在许多情况下,listagg 的执行速度会快于 xmlagg,尤其是在处理较少数据量时。
排序:支持在聚合过程中对字符串进行排序,使用 within group 子句。
缺点:
字符串长度限制:listagg 生成的字符串长度不能超过 4000 字符,如果超过这个限制,会抛出错误。
无格式化功能:listagg 仅限于字符串连接,不支持更复杂的格式化。
xmlagg 的优缺点
优点:
字符串长度更大:xmlagg 可以处理比 listagg 更大的字符串,因为生成的结果是 clob 类型,不受 4000 字符的限制。
灵活性:支持更复杂的 xml 处理和格式化功能,适合需要复杂字符串操作的场景。
缺点:
性能问题:在处理大量数据时,xmlagg 可能比 listagg 慢,因为涉及到 xml 解析和处理。
复杂性:语法相对复杂,使用起来不如 listagg 简单。
使用 listagg:当聚合后的字符串长度不超过 4000 字符时,并且只需要简单的字符串连接和排序。
使用 xmlagg:当聚合后的字符串长度可能超过 4000 字符,或者需要更复杂的格式化和处理时。
根据具体需求选择合适的函数可以在保证代码简洁性和执行效率的同时,满足业务需求。
手动处理重复数据的一种快捷安全的方式
-- 查找重复记录 select "tag_id", count(*) as cnt from dept_tag_info group by "tag_id" having count(*) > 1 order by cnt desc;
主删除语句:
delete from dept_tag_info t
where t.rowid in (
select rid
from (
select t1.rowid as rid, row_number() over (partition by t1.tag_code, t1.tag_name order by 1) as rn
from dept_tag_info t1
) t2
where t2.rn > 1
);如何在oracle sql中使用xmlagg和listagg函数进行字符串聚合。
产品工厂聚合
场景:你有一个名为product_details的表,里面有一个列product_factory,你希望将所有不同的产品工厂聚合成一个以逗号分隔的列表。
select
rtrim(xmlagg(xmlparse(content = dd.product_factory || ',' wellformed)
order by dd.product_factory).getclobval(), ',') as productfactory
from
product_details dd;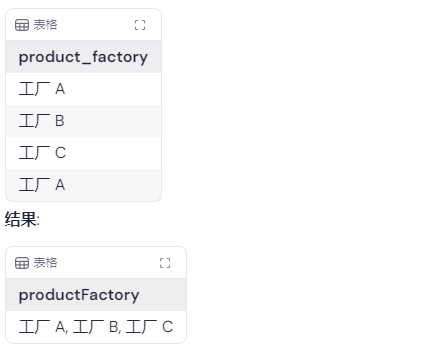
产品名称聚合
场景:你有另一个表product_changes,你想要聚合在特定日期后发生变化的产品名称。
select
listagg(dd.change_after_part_name, ',') within group (order by dd.change_after_part_name) as productname
from
product_changes dd
where
dd.change_date > '2023-01-01';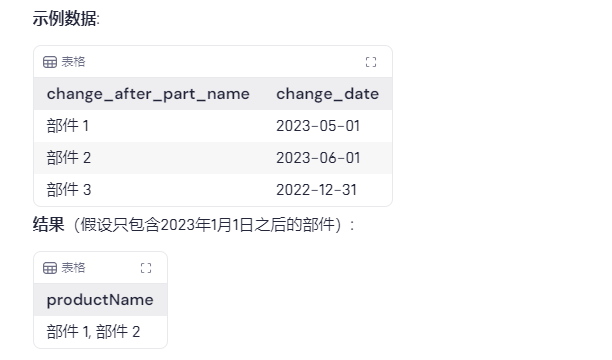
同时使用两者的聚合
场景:你希望在一个查询中获取产品工厂和其相关产品名称的列表。
select
rtrim(xmlagg(xmlparse(content = dd.product_factory || ',' wellformed)
order by dd.product_factory).getclobval(), ',') as productfactory,
listagg(cc.change_after_part_name, ',') within group (order by cc.change_after_part_name) as productname
from
product_details dd
left join
product_changes cc on dd.product_id = cc.product_id
where
cc.change_date > '2023-01-01';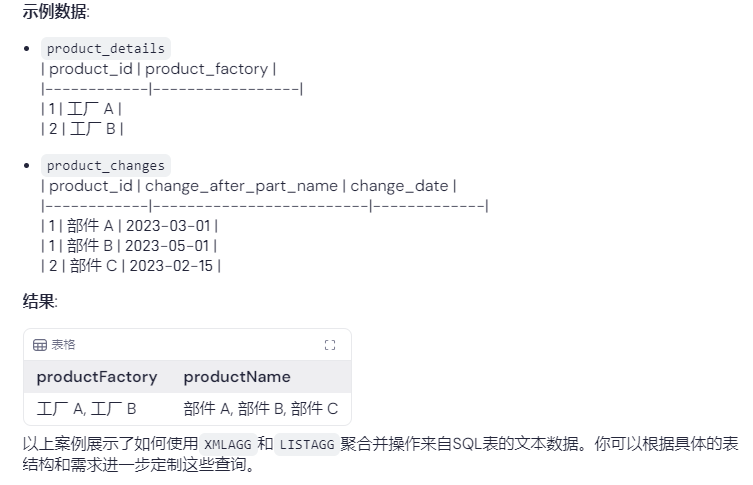
到此这篇关于oracle 系列数据库使用 listagg去重,删除重复数据的几种方法的文章就介绍到这了,更多相关oracle listagg去重内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!
赞 (0)
您想发表意见!!点此发布评论





发表评论