消费级处理器中的生产力王者 锐龙9 9950X/9900X处理器评测
578人参与 • 2024-10-24 • Cpu
回望2017年,amd的cpu业务来到了关键节点,所有的希望都押注在了全新的zen架构上。赌赢了,迎来了希望的曙光。赌输了,英特尔一家独大。幸好,一切都如amd所预料的一般,全新的zen架构锐龙处理器与当时的酷睿处理器站在了同一水平线上。

从第一代zen架构问世,到如今的zen5架构发布,amd用了7年的时间。其中有大刀阔斧的ccd改良,也有细致入微的微架构优化,每一步都走的很稳也很谨慎。如果你细看zen架构每一代的升级,就会发现zen 2的ipc提升了15%、zen 3提升了19%、zen 4提升了13%、zen 5提升了16%。每一代的ipc提升都是稳步增长,除了zen3因为ccd的大改良,实现19%的ipc提升,其他几代都保持在15%上下。zen5架构实现的16% ipc提升幅度,在历代ipc提升中也属佼佼者,充分体现了zen 5架构的优秀。
zen5架构概览

zen 5架构的改良有几个要素构成,其中包括:1.全新的前端设计,更宽的执行窗口和重新设计的指令提取、译码、分发单元2.全新的前端设计让zen5架构可以在每个时钟周期执行更多指令3.因为每个时钟周期可以执行更多指令,所以微操缓存和寄存器带宽也对应增大4.zen 5架构有了完整的512-bit fpu执行模块,以提高运行avx512/vnni指令大语言模型的ai效率。

zen 5架构的设计目标是奔着单线程和双线程性能优化而去的,我们将在zen 5核心上看到显著的单核性能提高。除此以外,zen 5核心整体的加大加宽思路还为以后的计算架构打下了基础,avx 512的完整支持则是为了提高数据吞吐量以及ai性能。


前端部分,zen 5架构主要优化了分支预测和预取单元,并将译码管道升级为两组4 inst/cycle并行操作,分发单元(dispatch)和微操缓存(op cache)也对应升级为8-wide和6-wide x 2,主要是为了增加每个时钟周期,前端流水线可以同时处理的指令数。

zen 5的流水线有一个很关键的数字是“8”,比如译码(decode)和分发单元(dispatch)都是8-wide/cycle,而现在rename(重命名)和retire(回退)寄存器同样也是8-wide/cycle,这保持了流水线增宽的统一效率。增宽的流水线让zen5架构可以设计更多执行单元,zen4时候是4个alu和3个agu,zen5则增加至6个alu和3个agu,理论上能提高50%的运算吞吐量。

zen5架构在浮点单元部分采用了完整的512-bit fpu以及与其位宽匹配的流水线管道,之前的zen 4架构其实也支持avx512指令集,但主要是通过2个256-bit fpu单元在两个时钟周期合并执行,算力和效率和完整的512-bit都要差不少。amd在zen 5上花费大量核心面积来提升avx 512的性能,主要是ai大语言模型能够使用avx512/vnni指令,为ai路线强化产品竞争力。

存取单元应该算每代必增大的一环,zen5从zen4的8路32kb l1 d-cache提高到12路48kb d-cache,指令操作数也从每周期3 load/2 store提高到4 load/2 store,更大的存取队列和更大的d-tlb页目数一定程度上降低了缓存miss的概率。
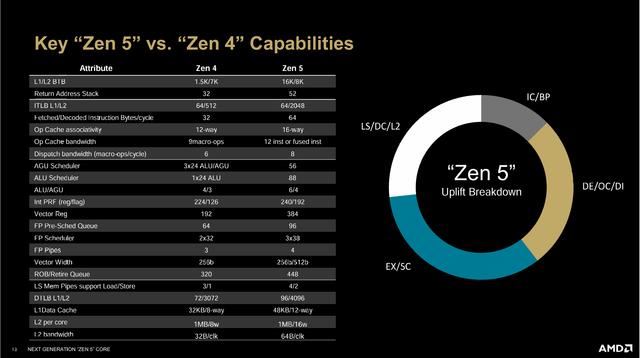
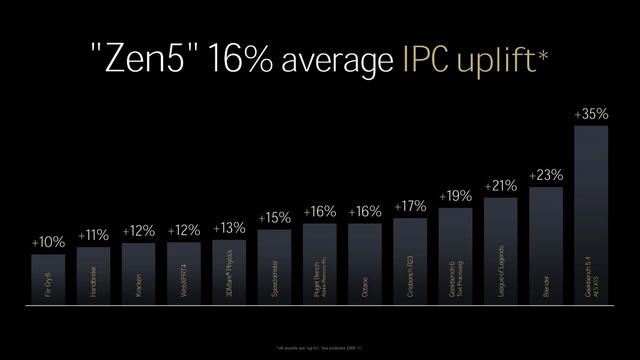
zen 5架构的ipc性能相较zen 4有了16%的平均增长,前端设计、执行单元和缓存结构组成了zen 5架构ipc性能增长的主要部分。
锐龙9000处理器规格
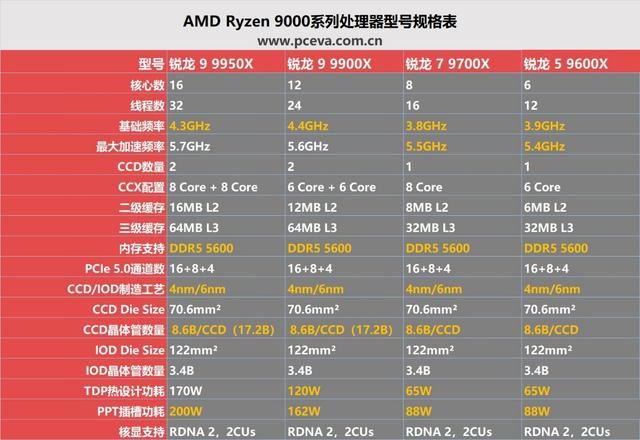
锐龙9000系列处理器首发型号还是四款,分别是锐龙9 9950x、锐龙9 9900x、锐龙7 9700x、锐龙5 9600x,核心规格与上代基本相同,不同的地方我们都用黄字标了出来。
赞 (0)
您想发表意见!!点此发布评论






发表评论