Nodejs解析网站网址内容并获取标题图标
147人参与 • 2025-02-13 • Node.js
介绍
在很多应用场景中,我们需要从一个网页中提取信息,比如标题(title)、网站图标(favicon)以及简介(description)。这些信息常用于以下场景:
分享功能:当用户在社交平台分享链接时,展示链接的标题、缩略图和描述内容。
数据抓取:用于分析网页信息,生成报告或构建爬虫应用。
预览功能:为用户提供链接的简要信息,提升交互体验。
在node.js中,可以借助cheerio库高效地解析和提取html内容。cheerio类似于jquery的api,让我们可以方便地操作html文档,而无需启动浏览器环境(如puppeteer)。
代码实现
异步获取指定url的内容
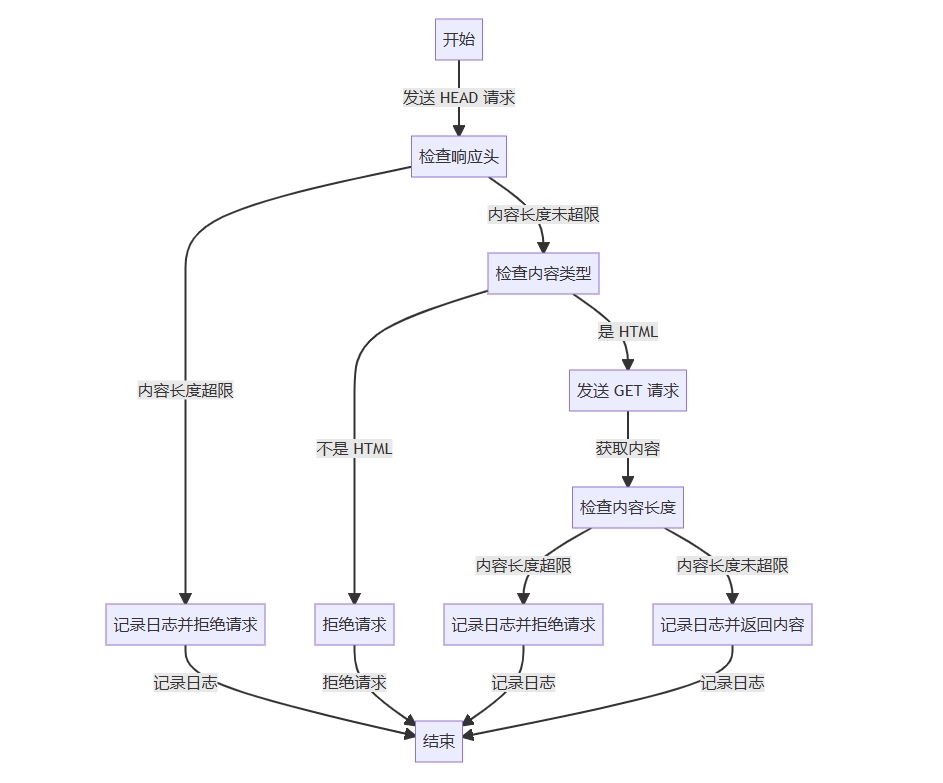
代码定义了一个异步函数 fetchurlcontent,用于获取指定 url 的内容。主要功能如下:
- 发送 head 请求:首先发送一个 head 请求来获取响应头信息,检查内容长度是否超过限制。
- 检查内容长度:如果内容长度超过限制,记录日志并返回错误。
- 检查内容类型:如果内容类型是 html,则发送 get 请求获取实际内容。
- 再次检查内容长度:在获取到实际内容后,再次检查内容长度是否超过限制。
- 记录日志并返回结果:如果一切正常,记录日志并返回内容;否则记录错误并抛出异常。
/**
* 异步获取指定url的内容
* 该函数首先发送一个http head请求,以检查url的内容类型和大小
* 如果内容类型为html且大小在允许范围内,则进一步发送get请求获取实际内容
*
* @param url 目标url地址
* @returns promise对象,解析后返回url的内容,如果发生错误则拒绝promise
*/
export async function fetchurlcontent(url: string) {
return axios
.head(url, {
validatestatus: () => true,
maxcontentlength: configs.fetch_url_info.max_response_size,
headers: {
'content-type': 'charset:utf-8',
accept: 'application/json, text/plain, */*',
'accept-encoding': 'gzip, deflate, br'
},
timeout: configs.fetch_url_info.timeout
})
.then((res) => {
// 检查内容大小是否超出限制
if (res?.headers?.['content-length'] && parseint(res?.headers['content-length']) > configs.fetch_url_info.max_response_size) {
logger.log('[url] 限制:', url, res?.headers['content-length'], res?.headers['content-type']);
return promise.reject(new customerror('url_content_error', '不支持该url内容解析'));
}
// 检查内容类型是否为html
if (res?.headers['content-type']?.includes('text/html')) {
return axios
.get(url, { headers: { accept: 'text/html', 'content-type': 'text/html;charset:utf-8', 'user-agent': configs.fetch_url_info.user_agent }, timeout: configs.fetch_url_info.timeout })
.then((res) => {
if (res) {
logger.log('[url] 爬取成功 axios', url);
// 再次检查内容大小是否超出限制
if (res.data?.length > configs.fetch_url_info.max_response_size) {
logger.log('[url] buffer大小: ', url, res.data?.length);
return promise.reject(new customerror('url_content_error', '内容过大解析失败'));
}
return res.data;
}
return promise.reject(res);
})
.catch((e) => {
logger.error('[url] fetch get', url, e.message);
throw new customerror('url_get_fetch_error', '不支持该url内容解析');
});
}
return promise.reject(new customerror('url_unvalid_error', '不支持该url内容解析'));
})
.catch((e) => {
logger.error('[url] fetch head', url, e.message);
throw new customerror('url_head_fetch_error', '不支持该url内容解析');
});
}
解析网址内容
具体实现
/**
* 解析url内容
* @param url 页面url
* @param html 页面html内容
* @returns 返回包含url、图标、简介和标题的对象
*/
export async function parseurlcontent(url: string, html: string): promise<{ url: string; icon: string; intro: string; title: string }> {
const $ = load(html);
let title = '';
let intro = '';
let icon = '';
// 获取标题节点
const titleel = $('title');
if (titleel?.text()) {
title = titleel?.text();
}
// 获取icon
const linkel = $('link');
const links: string[] = [];
if (linkel) {
linkel.each((_i, el) => {
const rel = $(el).attr('rel');
const href = $(el).attr('href');
if (rel?.includes('icon') && href) {
links.push(href);
}
});
}
logger.log('[url] 获取icon', links);
if (links.length) {
icon = resolveurl(url, links[0]);
}
/**
* 获取meta属性
* @param metaelement
* @param name
* @returns
*/
const getpropertycontent = (element, name: string) => {
const propertyname = $(element)?.attr('property') || $(element)?.attr('name');
return propertyname === name ? $(element)?.attr('content') || '' : '';
};
// 获取详情
const metas = $('meta');
for (const meta of metas) {
if (title && intro) {
break;
}
// 如果没有标题
if (!title) {
const titleoattr = ['og:title', 'twitter:title'];
for (const attr of titleoattr) {
const text = getpropertycontent(meta, attr);
if (text) {
title = text;
break;
}
}
}
// 简介
if (!intro) {
const introattr = ['description', 'og:description', 'twitter:description'];
for (const attr of introattr) {
const description = getpropertycontent(meta, attr);
if (description) {
intro = description;
break;
}
}
}
// icon
if (!icon) {
const imageattr = ['og:image', 'twitter:image'];
for (const attr of imageattr) {
const image = getpropertycontent(meta, attr);
if (image) {
intro = resolveurl(url, image);
break;
}
}
}
}
// 没有简介提取全部
if (!intro) {
const body = $('body').html();
intro = body ? htmlstringreplace(body, configs.fetch_url_info.max_intro_length) : '';
}
logger.log('[url] 爬取结果', { url, title, intro, icon });
return {
url,
title: title?.trim() || '',
intro: intro?.trim() || '',
icon
};
}
代码解释
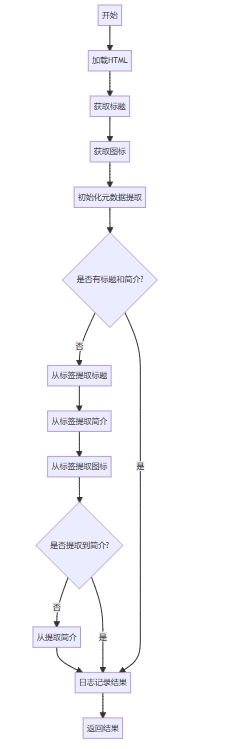
这段 typescript 代码定义了一个异步函数 parseurlcontent,用于解析 html 内容并提取 url 的标题、图标、简介和原始 url。具体步骤如下:
- 加载 html:使用 load 函数加载传入的 html 字符串。
- 获取标题:从 <title> 标签中提取页面标题。
- 获取图标:从 <link> 标签中提取 favicon 图标。
- 获取元数据:定义一个辅助函数 getpropertycontent 用于从 <meta> 标签中提取特定属性的内容。
- 提取详情:从 <meta> 标签中提取标题、简介和图标。
- 处理简介:如果没有提取到简介,则从 <body> 中提取部分内容作为简介。
开发api的用法
// js演示
var axios = require('axios');
var data = json.stringify({
url: 'https://xygeng.cn/post/200'
});
// 注意只支持post请求
var config = {
method: 'post',
url: 'https://api.xygeng.cn/openapi/url/info',
headers: {
'user-agent': 'mozilla/5.0 (macintosh; intel mac os x 10_15_7) applewebkit/537.36 (khtml, like gecko) chrome/112.0.0.0 safari/537.36',
'content-type': 'application/json',
accept: '*/*',
connection: 'keep-alive'
},
data: data
};
axios(config)
.then(function (response) {
console.log(json.stringify(response.data));
})
.catch(function (error) {
console.log(error);
});
到此这篇关于nodejs解析网站网址内容并获取标题图标的文章就介绍到这了,更多相关nodejs解析网站网址内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!
赞 (0)
您想发表意见!!点此发布评论





发表评论