Apache Kafka单节点极速部署指南及搭建开发单节点环境的操作步骤
288人参与 • 2025-03-05 • 缓存
apache kafka单节点极速部署指南:10分钟搭建开发单节点环境
kafka简介:apache kafka是由linkedin开发并捐赠给apache基金会的分布式流处理平台,现已成为实时数据管道和流应用领域的行业标准。它基于高吞吐、低延迟的设计理念,能够轻松处理每秒百万级消息传输,具备水平扩展、数据持久化、高容错等核心特性。kafka广泛应用于日志聚合、实时监控、事件溯源、消息队列等场景,是大数据生态中连接传统数据库与流处理引擎(如flink、spark)的关键组件,被腾讯云、netflix、uber等顶级互联网企业深度应用于核心业务系统。
一、环境准备与安装
1. 安装 java(详细步骤)
# centos sudo yum install -y java-1.8.0-openjdk-devel # ubuntu sudo apt update && sudo apt install -y openjdk-8-jdk # 验证安装 java -version # 应输出类似 "openjdk version 1.8.0_382"


2. 下载并解压 kafka
wget https://downloads.apache.org/kafka/3.6.1/kafka_2.13-3.6.1.tgz tar -xzf kafka_2.13-3.6.1.tgz mv kafka_2.13-3.6.1 /opt/kafka # 建议移动到标准化目录 cd /opt/kafka
如果服务器网络不佳可在kafka官网手动下载并上传至服务器:
下载地址:apache kafka


二、配置文件详解
1. zookeeper 配置
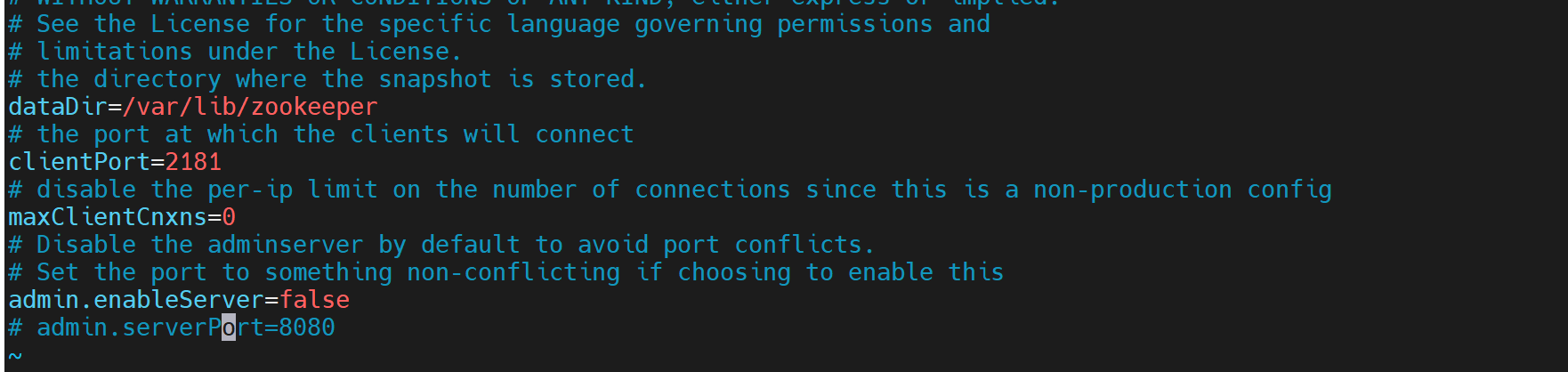
config/zookeeper.properties
# 数据存储目录(重要:生产环境需改为持久化路径,如 /var/lib/zookeeper) datadir=/tmp/zookeeper # 客户端连接端口 clientport=2181 # 最大客户端连接数(0 表示无限制) maxclientcnxns=0 # 集群配置(单节点无需配置) # server.1=zk-node1:2888:3888 # server.2=zk-node2:2888:3888
2. kafka broker 配置
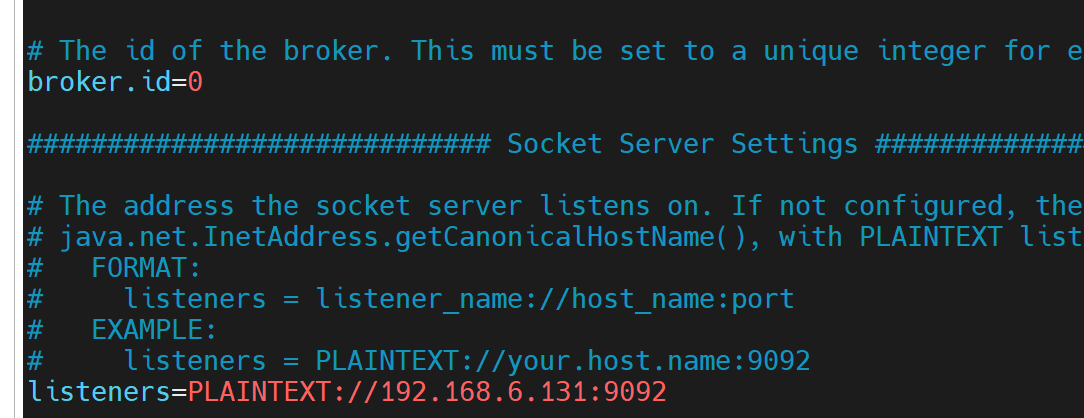
config/server.properties
# broker 的唯一标识(集群中每个节点必须不同) broker.id=0 # 监听地址和协议(生产环境建议用具体ip,如 plaintext://192.168.1.100:9092) listeners=plaintext://:9092 # kafka 日志存储目录(生产环境需改为持久化路径,如 /var/lib/kafka-logs) log.dirs=/tmp/kafka-logs # 每个 topic 的默认分区数(影响并行度) num.partitions=1 # zookeeper 连接地址(集群用逗号分隔,如 zk1:2181,zk2:2181) zookeeper.connect=localhost:2181 # 其他重要参数(可选) # 日志保留时间(小时) log.retention.hours=168 # 单个日志文件最大大小(字节) log.segment.bytes=1073741824 # 网络线程数 num.network.threads=3 # io 线程数 num.io.threads=8
三、配置为系统服务(systemd)
1. 创建 zookeeper 服务文件
sudo vim /etc/systemd/system/zookeeper.service
内容如下:
[unit] description=apache zookeeper service after=network.target [service] type=simple user=kafka # 建议创建专用用户(见下方说明) group=kafka execstart=/opt/kafka/bin/zookeeper-server-start.sh /opt/kafka/config/zookeeper.properties execstop=/opt/kafka/bin/zookeeper-server-stop.sh restart=on-failure restartsec=10s [install] wantedby=multi-user.target
2. 创建 kafka 服务文件
sudo vim /etc/systemd/system/kafka.service
内容如下:
[unit] description=apache kafka service after=zookeeper.service [service] type=simple user=kafka group=kafka execstart=/opt/kafka/bin/kafka-server-start.sh /opt/kafka/config/server.properties execstop=/opt/kafka/bin/kafka-server-stop.sh restart=on-failure restartsec=10s [install] wantedby=multi-user.target
3. 创建专用用户和目录(增强安全性)
sudo useradd -r -s /bin/false kafka
sudo mkdir -p /var/lib/{zookeeper,kafka-logs}
sudo chown -r kafka:kafka /var/lib/{zookeeper,kafka-logs} /opt/kafka4. 修改配置文件中的持久化路径
修改 zookeeper.properties:
datadir=/var/lib/zookeeper
修改 server.properties:
log.dirs=/var/lib/kafka-logs
5. 启用服务
sudo systemctl daemon-reload sudo systemctl enable --now zookeeper sudo systemctl enable --now kafka # 检查状态 sudo systemctl status zookeeper kafka
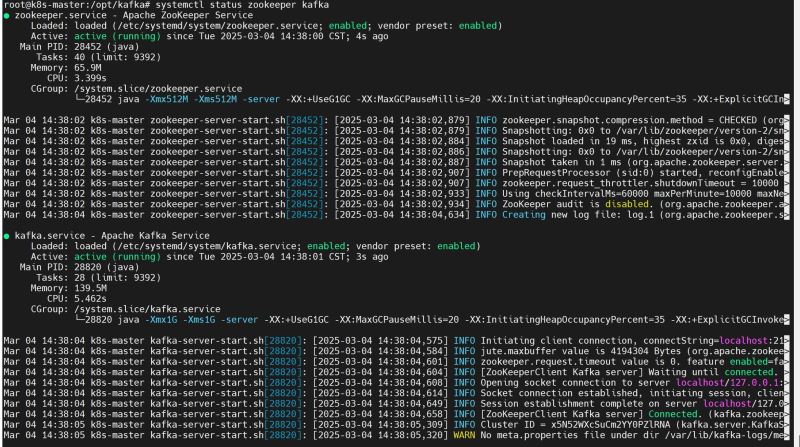
*四、验证服务
1. 功能测试(详细命令)
# 创建 topic(明确指定分区和副本) /opt/kafka/bin/kafka-topics.sh --create \ --topic test-topic \ --bootstrap-server localhost:9092 \ --partitions 3 \ --replication-factor 1 # 生产消息(输入多行消息后按 ctrl+c 退出) /opt/kafka/bin/kafka-console-producer.sh \ --topic test-topic \ --bootstrap-server localhost:9092 # 消费消息(新终端执行) /opt/kafka/bin/kafka-console-consumer.sh \ --topic test-topic \ --bootstrap-server localhost:9092 \ --from-beginning
测试效果如图:



五、关键配置项深度解析
| 配置项 | 作用说明 | 生产环境建议值 |
|---|---|---|
broker.id | broker 的唯一标识,集群中必须唯一 | 数字递增(0,1,2…) |
listeners | broker 监听的网络地址和协议 | 使用服务器内网ip,如 plaintext://192.168.1.100:9092 |
log.dirs | kafka 数据存储目录,多个目录用逗号分隔可提升性能 | 挂载独立磁盘,如 /data/kafka-logs |
zookeeper.connect | zookeeper 集群地址,格式为 host1:port1,host2:port2 | 至少3节点集群 |
num.partitions | 新建 topic 的默认分区数(影响并行处理能力) | 根据业务需求设置(通常3-10) |
log.retention.hours | 消息保留时间 | 按业务需求(如 168=7天) |
default.replication.factor | 新建 topic 的默认副本数(高可用关键) | 至少2,集群节点数≥副本数 |
六、故障排查指南
1. 查看服务日志
# zookeeper 日志 journalctl -u zookeeper -f # kafka 日志 journalctl -u kafka -f
2. 端口占用检查
sudo netstat -tlnp | grep -e '2181|9092'
3. 文件权限修复
sudo chown -r kafka:kafka /var/lib/{zookeeper,kafka-logs}到此这篇关于apache kafka单节点极速部署指南及搭建开发单节点环境的操作步骤的文章就介绍到这了,更多相关apache kafka单节点部署内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!
赞 (0)
您想发表意见!!点此发布评论




发表评论