JVM内存飙升线上问题排查方式
210人参与 • 2025-03-07 • 内存
前言
最近线上环境的cms服务出现内存增长非常快的情况,上午内存2.4g下午就到了4g以上并且内存的增长随着时间推移一直增长,直到达到内存空间限制然后pod重启。由于之前没有接触过所以这次排查完记录一下,主要是分享一下排查的思路和工具以及一些指令等。
这次问题的排查思路是先查看gc日志,通过gc日志分析内存升高的过程主要是发生在哪个区,如果是堆外内存那可能不大好排查,可以查看代码中哪些涉及到大文件、大的字符串处理等,如果是新生代gc频繁那就是临时对象较多,gc日志只是做个大概的定位;其次主要还是需要对堆栈信息作分析,使用dump命令做快照,分别在服务刚启动时和内存飙升后做快照,对比升高后哪些对象的数量和大小增加。
gc日志
gc日志开启
在启动 java 应用程序时,通过 jvm 参数启用 gc 日志记录
jdk 8 及以下版本
-xx:+printgcdetails -xx:+printgcdatestamps -xloggc:/path/to/gc.log
-xx:+printgcdetails:打印 gc 的详细信息。-xx:+printgcdatestamps:在日志中记录 gc 的时间戳。-xloggc:<file>:指定日志文件的位置。
jdk 9 及以上版本
-xlog:gc*:file=/path/to/gc.log:time,uptime,level,tags
gc*:记录所有 gc 相关的日志。file=/path/to/gc.log:将日志输出到指定文件。time,uptime,level,tags:控制日志格式。
查看gc日志
下面是线上的部分gc日志,从gc的间隔时间60、90、115可以看出频率较高,表明应用程序内存分配压力较大,同时新生代 gc 耗时从 0.127秒 增加到 0.715秒
2024-12-18t06:44:01.909+0000: 84819.612: [gc (allocation failure) 2024-12-18t06:44:01.910+0000: 84819.614: [defnew: 1151910k->52843k(1230656k), 0.1256773 secs] 3431287k->2333097k(3965440k), 0.1275887 secs] [times: user=0.13 sys=0.00, real=0.13 secs]
2024-12-18t06:45:01.366+0000: 84879.070: [gc (allocation failure) 2024-12-18t06:45:01.368+0000: 84879.071: [defnew: 1143848k->77773k(1230656k), 0.1896575 secs] 3424102k->2362281k(3965440k), 0.1915247 secs] [times: user=0.18 sys=0.01, real=0.20 secs]
2024-12-18t06:46:31.906+0000: 84969.609: [gc (allocation failure) 2024-12-18t06:46:31.907+0000: 84969.610: [defnew: 1171725k->67117k(1230656k), 0.1596144 secs] 3456233k->2362116k(3965440k), 0.1615306 secs] [times: user=0.15 sys=0.01, real=0.16 secs]
2024-12-18t06:48:27.092+0000: 85084.795: [gc (allocation failure) 2024-12-18t06:48:27.093+0000: 85084.797: [defnew: 1161069k->136703k(1230656k), 0.2665425 secs] 3456068k->2466626k(3965440k), 0.2688204 secs] [times: user=0.24 sys=0.03, real=0.27 secs]
2024-12-18t06:48:28.749+0000: 85086.452: [gc (allocation failure) 2024-12-18t06:48:28.751+0000: 85086.454: [defnew: 1230655k->136704k(1230656k), 0.7121741 secs] 3560578k->2689414k(3965440k), 0.7152341 secs] [times: user=0.38 sys=0.33, real=0.72 secs]
时间戳:
2024-12-18t06:44:01.909+0000:gc 触发的时间。84819.612:jvm 启动后的相对时间(秒)。
gc 触发原因:
(allocation failure):因为无法为新对象分配空间触发 gc。
gc 类型:
[defnew]:使用 serial gc,这是年轻代的 gc 类型(defnew 表示新生代 gc)。
内存变化:
1151910k->52843k(1230656k)
- 新生代从 1151910kb 降到 52843kb,容量上限为 1230656kb。
- 新生代的回收效果较明显。
3431287k->2333097k(3965440k)
- 堆内存从 3431287kb 降到 2333097kb,总堆内存上限为 3965440kb。
耗时:
0.1275887 secs:gc 总耗时 127ms。
user=0.13 ser=0.13 sys=0.00, real=0.13 secs
user:用户线程执行 gc 的 cpu 时间。sys:内核线程执行 gc 的 cpu 时间。real:实际经过的时间。
堆栈快照
直接查看高内存时的内存快照可能无法定位导致高内存占用的对象,可以在项目刚启动时和内存占用很高时分别记录快照,再使用内存分析工具对比,可以比较直观的看到导致内存升高的对象,从而在项目里面快速定位。
生成快照
如果命令成功运行,会在 /tmp 目录下生成名为 heapdump.hprof 的文件,大小跟实际占用的内存差不多,在做导出前可以使用压缩指令压缩提高传输效率
# 查看pid ps -ef | grep java # 生成内存快照到指定目录下 jmap -dump:format=b,file=/tmp/heapdump.hprof <pid> # 压缩 tar -czvf /tmp/heapdump.tar.gz /tmp/heapdump.hprof # 解压 tar -xzvf /tmp/heapdump.tar.gz
jmap:java 内存映射工具,用于生成堆转储或打印内存统计信息。
-dump:指定生成堆转储。format=b:转储文件的格式为二进制(默认格式)。file=/tmp/heapdump.hprof:堆转储文件保存的路径。<pid>:目标 jvm 进程的进程 id,可以通过jps或操作系统工具如ps查找。
得到的文件转出到本地后解压
idea中打开
2024.intellij idea 2024.1.3 jprofiler
run > open profiler snapshot > open再选择文件即可打开快照文件
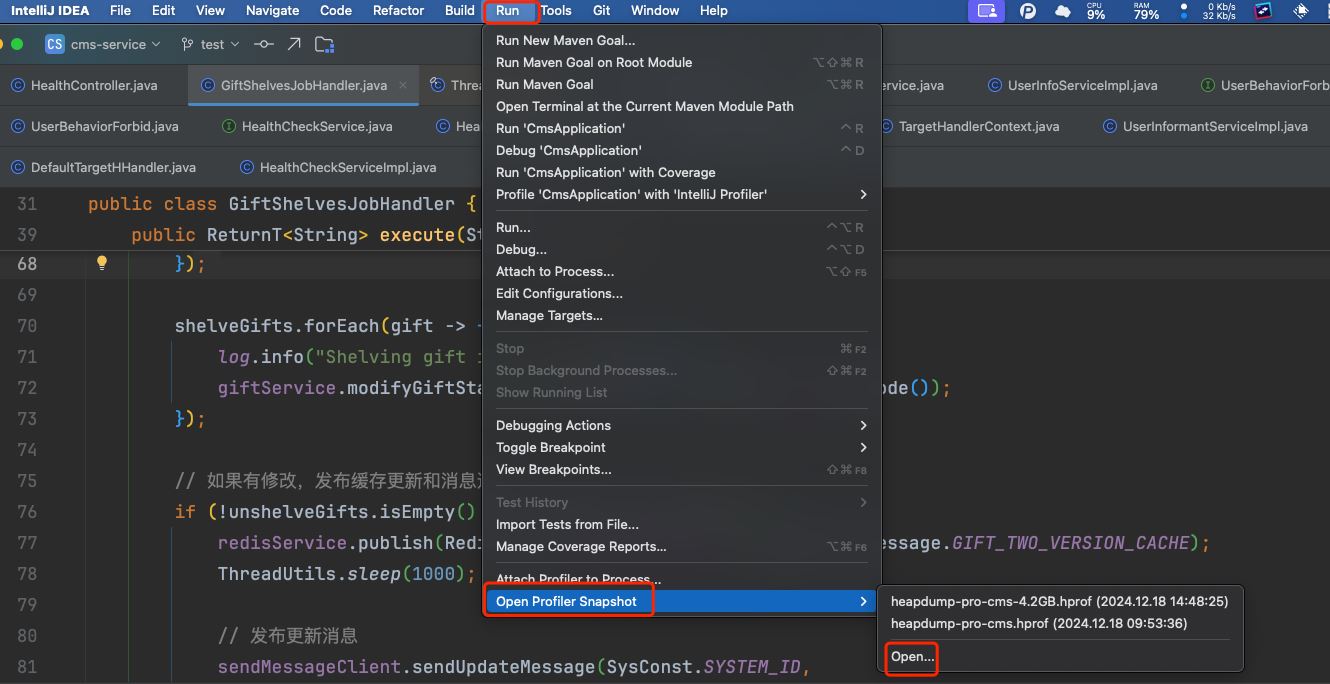
jprofiler的使用
下面是打开的效果图,图片下面是解释分析内存界面中的栏目字段含义。
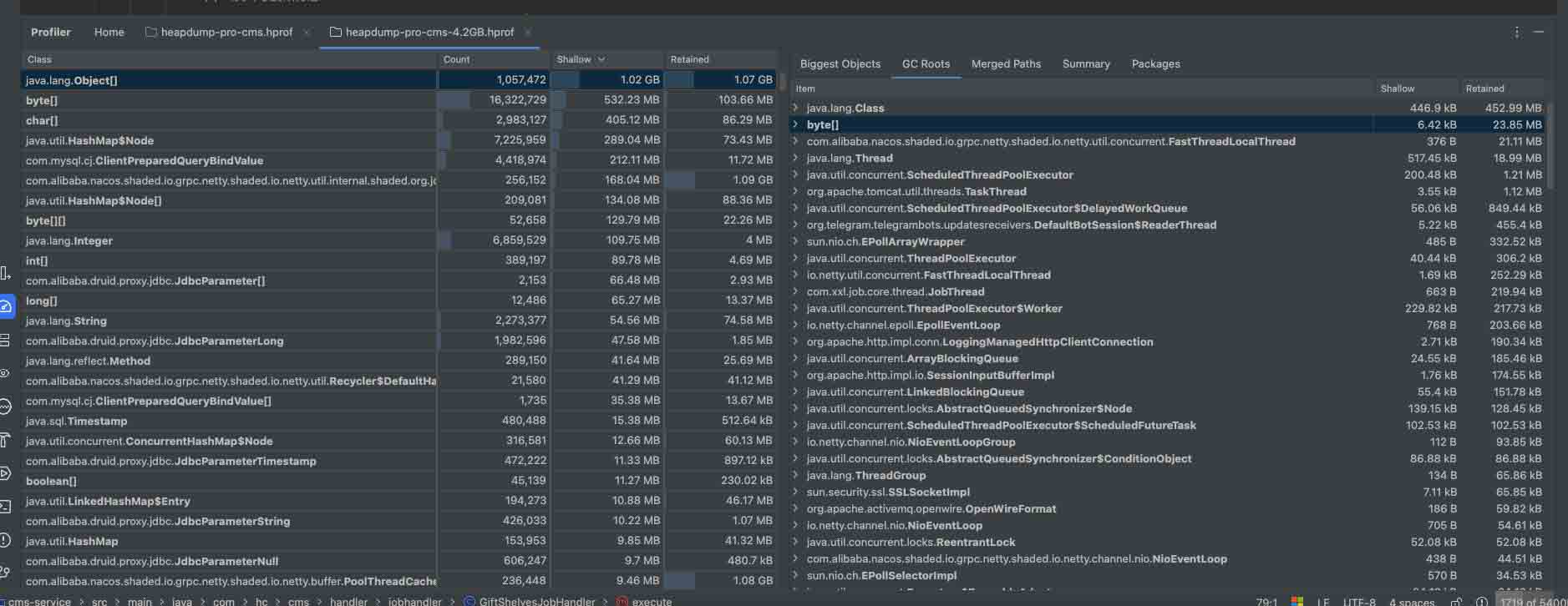
1. count
- 含义:表示特定类型的对象的实例数量。例如,某个类
com.example.myclass的对象在堆中有多少个实例。
2. shallow
- 含义:shallow size(浅表大小),指某个对象本身占用的内存大小,不包括它引用的其他对象。
- 单位:字节(bytes)。
- 注意:例如,一个对象引用了其他对象,但 shallow size 只包括这个对象自身的内存(如类头和它的基本字段所占的内存)。
3. retained
- 含义:retained size(保留大小),表示某个对象被回收后可以释放的总内存,包括该对象本身和它所有可达的对象。
- 单位:字节(bytes)。
- 重要性:retained size 是排查内存泄漏的重要指标。如果某个对象的 retained size 很大,说明它可能是根源问题。
4. biggest objects
- 含义:列出占用内存最大的对象,通常根据 retained size 排序。
- 作用:帮助快速找到哪些对象占用了最多的内存,可能是内存泄漏或不合理使用的根源。
5. gc roots
- 含义:gc roots(垃圾回收根)是指那些始终可达的对象,它们是垃圾回收的起点。
- 典型 gc roots
- java 栈中的局部变量。
- 静态变量(类加载器持有)。
- jni 引用的对象。
- 线程对象。
- 用途:通过分析对象如何从 gc roots 保持引用,可以找出内存泄漏的路径。
6. merged paths
- 含义:在内存分析中,工具会尝试合并多条路径,以简化视图并显示引用链的关键部分。
- 作用:方便查看某个对象如何被其他对象引用和保留。
7. summary
- 含义:一个总览页面,汇总堆中的信息,例如总对象数、内存使用量、各类对象的分布等。
- 作用:快速获取堆的整体状况。
8. packages
- 含义:显示对象所属的包(package),并按包进行分组统计。
- 用途:便于按模块分析内存使用情况,找出可能存在问题的模块或包。
内容太多总结一下分析时比较重要的:
- 可以重点关注shollow栏并且根据他排序,它代表快照时在内存中这个对象占用的大小,而它后面一栏retained代表的是这个对象被回收的大小也具有很高的参考意义当然需要结合shollow如果只是被回收的多但是占用的不多那应该也是问题不大,shallow和retained栏两个都高的需要重点关注。
- 其次merged paths栏在问题分析中也非常重要,可以在选中左侧的类之后分析这个类的来源以及引用链;summary是线程的状态信息,我这边大部分是netty中的一些阻塞线程没什么很明显的问题;packages是用来分析不同包下内存占用情况的,我这里lang包占了1.28g实际上是不正常的但我分析的时候没有经验也没有引起重视。
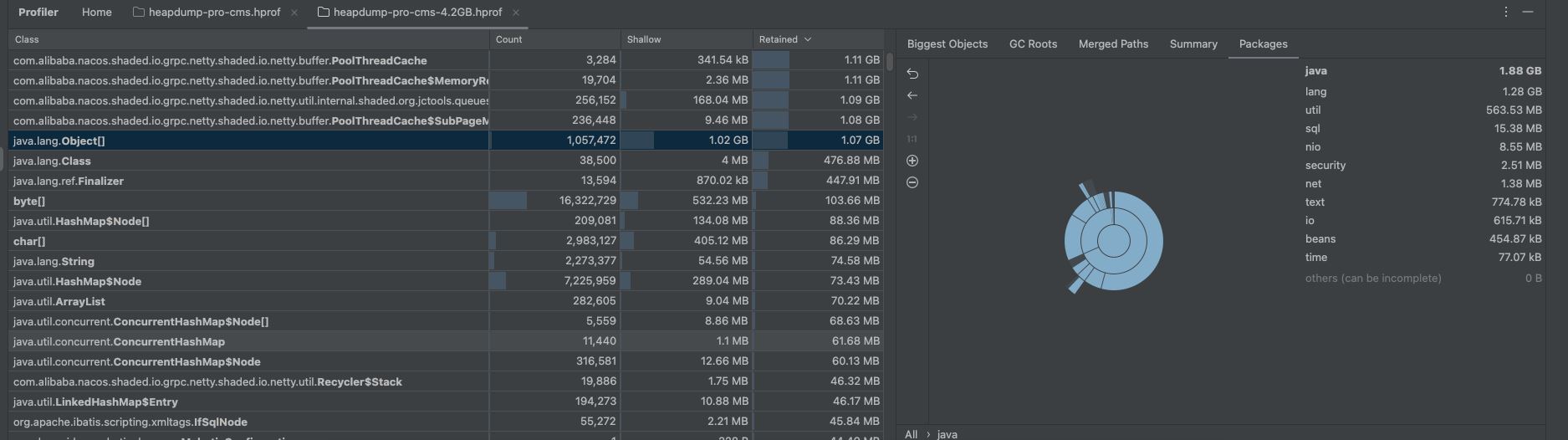
分析shollow栏下切到 merged paths
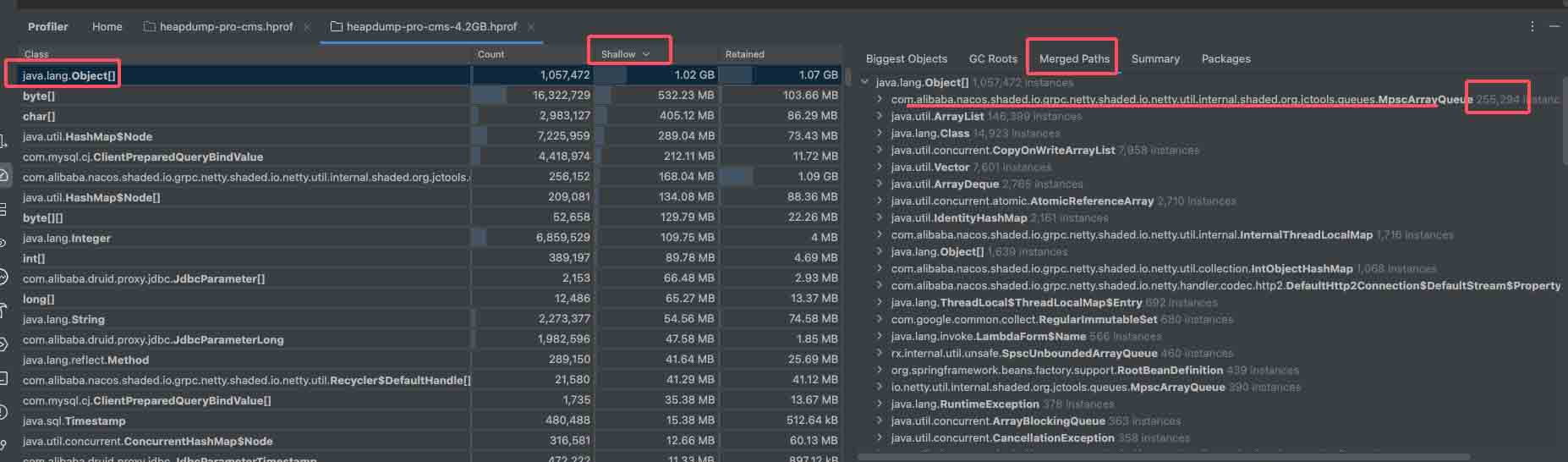
先选中最大的对象,找到数量最多的类打开,查看object[]的来源,最终指向的都是nacos下poolthreadcache对象,并且有一个很反常的现象就是对象的回收java.lang.ref.finalizer层级非常深根本点不完一直点一直有,并且对比启动时的该对象内存情况升高十分明显,并且右侧这个类的数量也是十分的高;
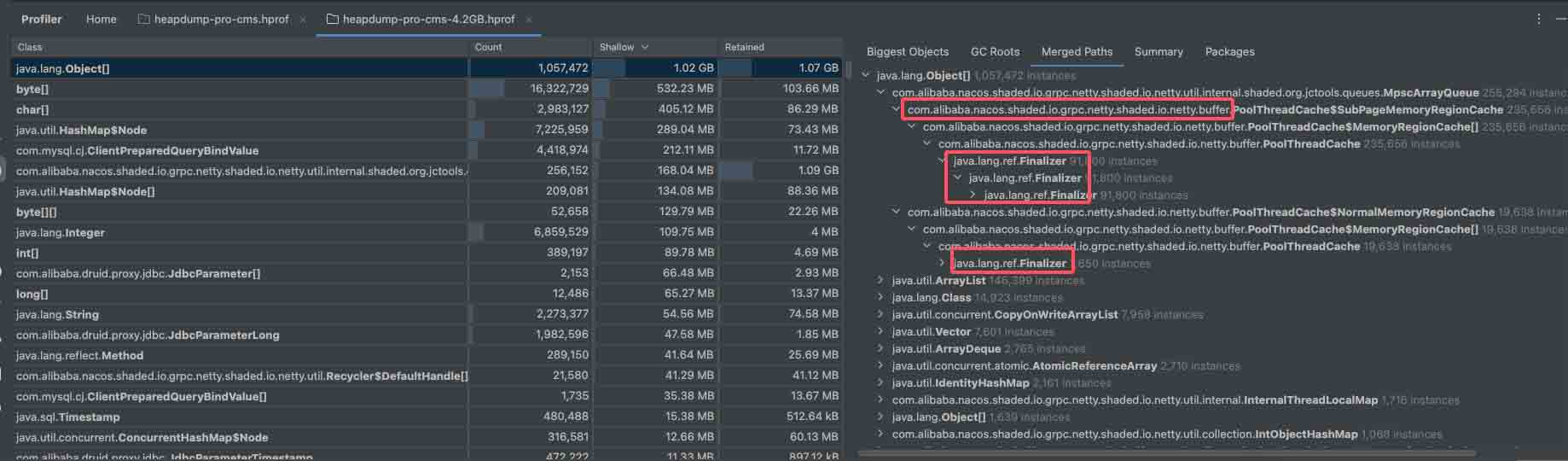
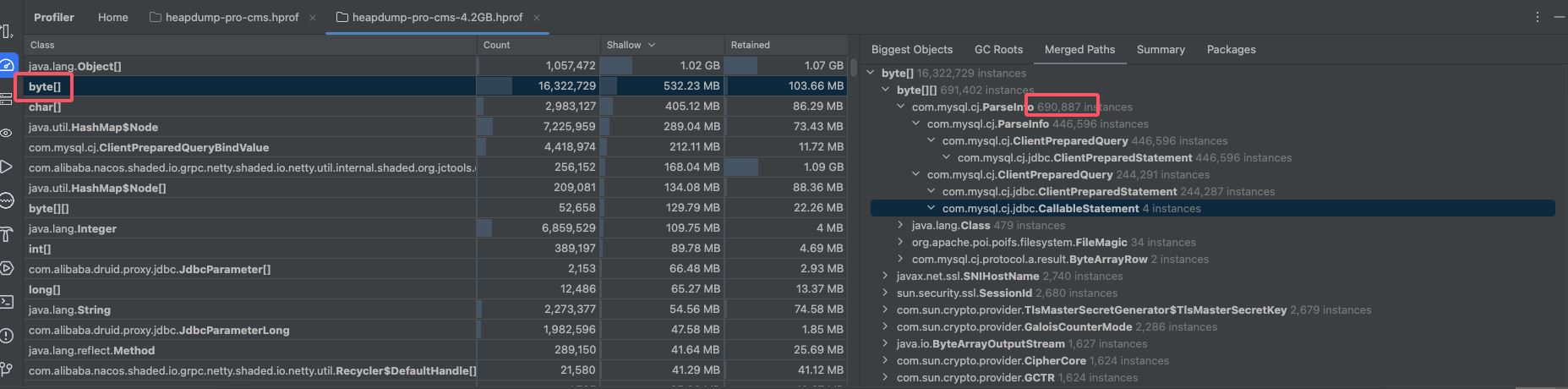
除此之外在对比时发现com.mysql.cj.jdbc.callablestatement对象增长也十分明显,它是在sql查询时创建的查询对象,理论上来说它也应该在查询完之后进行销毁,但实际上却没有被回收,不过这个对象被回收的数量也比较多又100多m,jdbc涉及到的配置也有限制,但限制外的预编译对象没有被回收,这个可能也有问题不过这次优化中没有处理内存持续升高是其他问题造成,它的影响不是很大
# 是否开启预编译语句(preparedstatement)的池化 db.master.poolpreparedstatements=true # 每个数据库连接可以缓存的 preparedstatement 对象的最大数量 db.master.maxpoolpreparedstatementperconnectionsize=10
retained栏下切到 merged paths
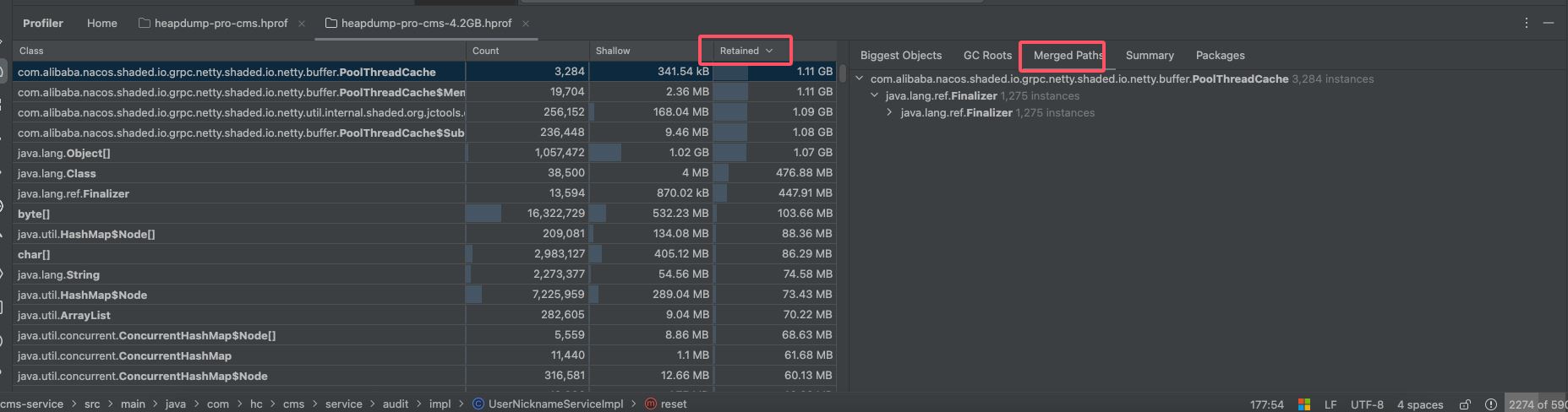
切换过去之后问题就很明显,回收对象大小排在前面的都是nacos相关的类,并且内部都是java.lang.ref.finalizer对象,层级非常深。
java.lang.ref.finalizer实际是一个对象在创建时都会被一个特殊的 finalizer 对象所追踪,当一个对象即将被垃圾回收器(gc)回收时,finalizer 会将该对象标记为可终结的对象,并调用其 finalize() 方法,主要作用就是清理资源和对象回收前的通知机制,finalize() 方法可以用于清理非 java 堆中的资源,例如关闭文件流、socket、释放内存等,不过但现代开发中,不建议依赖 finalize() 来做资源清理,因为它的执行时间和顺序不可控,它只是通知或者是建议gc来干活需要进行垃圾回收,但实际上是否进行垃圾回收由jvm 和垃圾回收器控制,同时它也可以让对象在完全销毁之前执行一些逻辑,例如记录日志或释放资源。
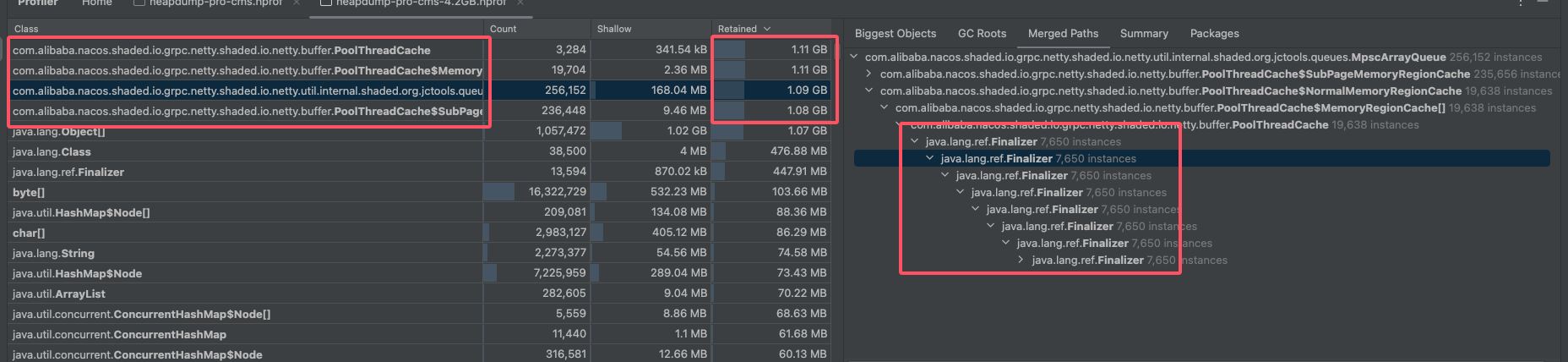
到这里初步定位于nacos的使用相关,网上查了一下对于java.lang.ref.finalizer嵌套较深的原因是:finalizer线程会和主线程进行竞争,不过由于它的优先级较低,获取到的cpu时间较少,因此它永远也赶不上主线程的步伐。可以参考这篇文章java的finalizer引发的内存溢出,仔细一想其实是句废话说白了就是回收垃圾的速度赶不上制造垃圾的速度,实际结果肯定是这样不然也不会有内存持续升高最终溢出的结果,除此之外github上也有帖子nacos客户端2.0.1 poolthreadcache 内存溢出,说是nacos某些版本的bug并且该问题没有给出解决方案就被关闭了。
由于是nacos相关的问题,所以直接在项目中搜索"nacos.",看哪些类有使用nacos相关的类,结果只有健康检查类里面有相关使用,下面是用到的部分代码,主要逻辑就是获取nacos中所有可用的服务,请求服务的某个接口如果返回数据就代表服务健康状态。
public void checkservicehealth() throws nacosexception {
syslogger.info(this.getclass(),"健康检查进入:");
namingservice namingservice = namingfactory.createnamingservice(serverlist);
// 获取所有服务的列表
list<string> servicenames = namingservice.getservicesofserver(1, integer.max_value).getdata();
// 遍历所有服务
for (string servicename : servicenames) {
// 获取指定服务的所有实例
list<instance> instances = namingservice.getallinstances(servicename);
// 遍历服务的实例
for (instance instance : instances) {
//......
// 模拟http请求向服务发送健康检查接口
responseentity<string> response = resttemplate.getforentity(serverip, string.class)
}
}
}问题就出在代码
namingservice namingservice = namingfactory.createnamingservice(serverlist)
下面是这个方法的内部代码,通过反射去创建namingservice对象,说明对象并不是单例的每次都会创建一个新对象,而这个方法由于是健康检查使用几分钟就执行一次,时间一长对象就会非常多。尽管这个对象会创建很多但是理论上还是会被垃圾回收器回收掉对内存的影响可能也不会很大,但是问题的关键就在于模拟http请求时的
responseentity<string> response = resttemplate.getforentity(serverip, string.class);
resttemplate 默认使用的是 http keep-alive 机制,这是一种复用底层 tcp 连接的机制,可以提升 http 请求的性能并减少资源消耗,但如果跟非单例对象一起可能导致namingservice形成强引用无法被回收。
public static namingservice createnamingservice(string serverlist) throws nacosexception {
try {
class<?> driverimplclass = class.forname("com.alibaba.nacos.client.naming.nacosnamingservice");
constructor constructor = driverimplclass.getconstructor(string.class);
namingservice vendorimpl = (namingservice)constructor.newinstance(serverlist);
return vendorimpl;
} catch (throwable var4) {
throwable e = var4;
throw new nacosexception(-400, e);
}
}解决
知道了原因修改的话就很简单了,把namingservice的获取方式变成单例就可以了
@autowired
private namingservice namingservice;
// 获取所有服务的列表
list<string> servicenames = namingservice.getservicesofserver(1, integer.max_value).getdata();总结
修改之后上线观察cms的内存占用情况改善非常明显,由原来的4个多g变成现在的2g左右,并且稳定在2g左右基本不会升高。本次解决的问题只有namingservice对象较多无法回收的问题,但实际上在分析的过程中也发现了在运行的过程中com.mysql.cj.jdbc.callablestatement对象增上也十分迅速,由2g内存时的20w增长到4.2g内存时的90w,这个问题并没有在这次优化中处理,后面这个对象肯定会随着时间的推移数量变的越来越多,并且这个对象也不会被垃圾回收器回收,所以可能后面还需要处理这个问题。
本次线上问题的定位与解决都是我同事,在此仅仅是做个记录,我在做分析时我看到了那个引用链非常长的问题,但是并没有引起我的注意,因为我一看这个是nacos的类所以不会有问题如果我们的项目有问题那类似用了nacos的是不是都会有问题,所以直接忽略了在其他地方浪费了很多时间,我想说的是在分析问题时还需要耐心的分析不忽略任何可能的点,定位问题时不能先入为主,想当然的认为某个地方肯定没有问题,因为这样很有可能会漏掉最重要的点,同时告诫自己做事多一些耐心、细心。
以上为个人经验,希望能给大家一个参考,也希望大家多多支持代码网。
赞 (0)
您想发表意见!!点此发布评论





发表评论