StarRocks简介与搭建使用详解
325人参与 • 2025-03-07 • ar
starrocks简介
starrocks 是一款高速、实时、全场景的mpp(大规模并行处理)分析型数据库系统,专为现代数据分析场景设计,强调亚秒级查询性能和高并发能力。它兼容mysql协议,使得用户可以利用现有的mysql客户端工具和bi工具进行查询和数据分析。starrocks基于mpp架构,采用全向量化执行引擎、列式存储技术和智能优化器等先进技术,实现了数据的快速加载、实时更新以及复杂查询的高效处理。
可以满足企业级用户的多种分析需求,广泛应用于实时数仓、olap 报表、数据湖分析等场景。
mpp (massively parallel processing),即大规模并行处理。是将任务并行的分散到多个服务器和节点上,在每个节点上计算完成后,将各自部分的结果汇总在一起得到最终的结果(与hadoop相似)。
一、应用场景
olap 多维分析
利用 starrocks 的 mpp 框架和向量化执行引擎,用户可以灵活的选择雪花模型,星型模型,宽表模型 或者预聚合模型。适用于灵活配置的 多维分析报表,业务场景包括:
- 用户行为分析
- 用户画像、标签分析、圈人
- 跨主题业务分析
- 财务报表
- 系统监控分析
实时数据仓库
设计和实现了 primary-key 模型,能够 实时更新数据并极速查询,可以 秒级同步 tp (transaction processing) 数据库的变化,构建实时数仓,业务场景包括:
- 电商大促数据分析
- 物流行业的运单分析
- 金融行业绩效分析、指标计算 直播质量分析
- 广告投放分析
- 管理驾驶舱
高并发查询
starrocks 通过良好的数据分布特性,灵活的索引以及物化视图等特性,可以解决面向用户侧的分析 场景,业务场景包括:
- 广告主报表分析
- 零售行业渠道人员分析
- saas 行业面向用户分析报表
- dashboard 多页面分析
统一分析
- 通过使用一套系统解决多维分析、高并发查询、预计算、实时分析查询等场景,降低系统复杂度和 多技术栈开发与维护成本。
- 使用 starrocks 统一管理数据湖和数据仓库,将高并发和实时性要求很高的业务放在 starrocks 中 分析,也可以使用 external catalog 和外部表进行数据湖上的分析
二、starrocks与mysql比较
starrocks与mysql的相同点:
- 兼容性:starrocks支持mysql协议,用户可以直接使用mysql客户端进行查询,降低了迁移和使用门槛。
- sql语法:基本遵循mysql的sql语法,使得熟悉mysql的用户能够快速适应。
starrocks与mysql的不同点:
- 应用场景:mysql主要面向oltp(在线事务处理)场景,而starrocks专注于olap(在线分析处理)领域,尤其擅长海量数据的批量查询和实时分析。
- 架构设计:starrocks采用mpp架构,能够充分利用分布式计算资源,实现大规模数据的并行处理,相较于mysql的单机或多主从架构,更适合大数据分析。
- 存储与优化:starrocks采用列式存储和向量化执行引擎,大大提高了数据压缩率和查询速度,尤其是针对大数据量、低延迟的复杂查询场景表现优异。
- 数据导入与更新:starrocks支持实时数据摄入,允许用户快速加载大量数据,并对已有数据进行实时更新,而mysql在处理大规模数据批处理和实时分析时效率相对较弱。
starrocks的优点:
- 高性能:极致的查询性能和并发能力,适用于实时业务报表、实时数据分析等场景。
- 易用性:兼容mysql协议和丰富的生态系统,易于集成现有工具和环境。
- 扩展性:支持水平扩展,可根据业务需求动态增减计算和存储资源。
- 实时性:支持实时数据摄取和更新,满足实时数据分析需求。
starrocks的缺点(或挑战):
- 适用范围:尽管高度优化,但对于需要强事务一致性保证的oltp场景,相比传统的关系型数据库可能不占优势。
- 成熟度:相比于mysql等久经市场考验的产品,starrocks作为新兴的分析型数据库,社区和技术支持的成熟度可能还在不断提升中。
- 生态建设:尽管兼容mysql协议,但在特定插件、第三方工具支持等方面,与mysql庞大的生态系统相比可能仍有差距。
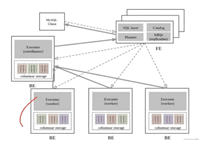
三、系统架构
- 前端(frontend, fe)节点
- 作用:fe节点负责处理客户端的所有交互,包括sql解析、查询优化、元数据管理和集群协调。
- 构成:由多个fe节点组成,其中包含follower和observer角色,通过leader选举机制确保高可用性。
- 功能
- 接收并解析sql查询请求。
- 生成高效的查询执行计划。
- 维护全局的元数据信息,如表结构、分区信息、节点状态等。
- 负责整个系统的资源调度和任务分配。
- 后端(backend, be)节点
- 作用:be节点承担实际的数据存储和计算工作,是执行查询的核心部分。
- 构成:多个be节点构成数据存储和处理集群,每个节点都有自己的计算和存储资源。
- 功能
- 存储和管理用户数据,采用列式存储和多级索引优化。
- 执行fe节点下发的查询任务,在本地节点并行处理数据。
- 支持数据的分布式存储和并行计算,实现快速数据检索和聚合。
- broker
starrocks中和外部hdfs/对象存储等外部数据对接的中转服务,辅助提供导入导出功能。
数据分布与复制
- starrocks的数据表会被划分为多个tablet(数据分片),这些tablet均匀分布在be节点上,形成分布式数据存储。
- 为了实现高可用和容错,starrocks支持数据的多副本备份,每个tablet可以在不同be节点上有多份拷贝。
查询处理流程
- 客户端提交sql查询至任意一个fe节点。
- fe节点解析sql语句,生成最优查询计划,并将执行计划分解成子任务发送给相应的be节点。
- 各个be节点并行执行子任务,并将结果返回给fe节点。
- fe节点收集各be节点的结果,并进行必要的合并与排序,最终将查询结果返回给客户端。
集群扩展与稳定性
- starrocks通过增加fe和be节点数量来线性扩展处理能力和存储容量。
- 通过心跳机制监控节点健康状况,并自动调整负载均衡和故障转移,保障系统的稳定性和可用性。
四、starrocks搭建
进入官网:download starrocks free | starrocks
下载starrocks版本3.0.9:
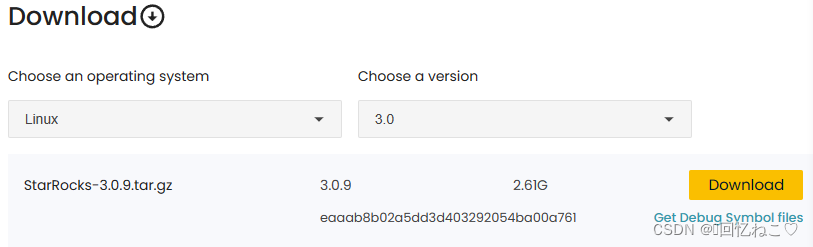
上传到虚拟机:
解压:
tar -zxvf starrocks-3.0.9.tar.gz -c /opt
进入目录修改 conf/fe.conf 中 jvm 的堆大小,根据实际的大小设置,并创建元数据目录:
cd /opt/starrocks-3.0.9/fe mkdir meta
进入到解压目录的 be 下,创建数据存储目录:
mkdir storage
fe部署:
由于我的有报错,starrocksfe进程会停掉,查找得知8030端口被java进程占用。
# 端口查看: netstat -tulpn | grep :9050
starrocks fe的8030端口被占用,进入fe文件下的conf/fe.conf文件修改改为8050:
meta_dir = /opt/starrocks-3.0.9/fe/meta java_home = /usr/java/jdk1.8.0_291-amd64 http_port = 8050
将改好的 starrocks 包分发至另外两个 服务器中:
scp -r starrocks-3.0.9 root@xy2:/opt/ scp -r starrocks-3.0.9 root@xy3:/opt/
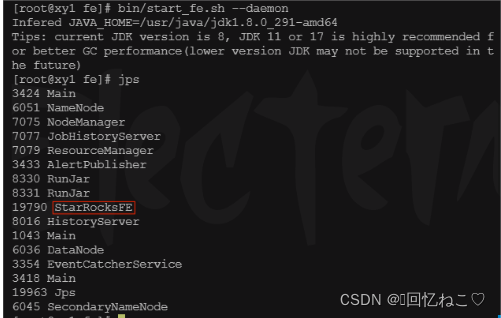
进入目录并启动fe节点,使用jps查看进程:
cd /opt/starrocks-3.0.9/fe bin/start_fe.sh --daemon
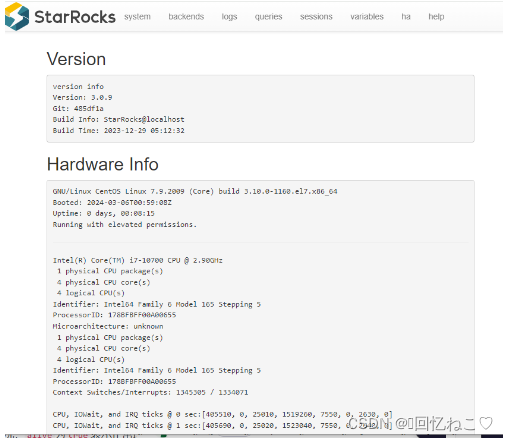
使用ip:8050可以查看web端:
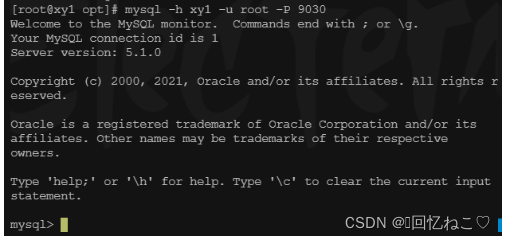
使用mysql连接fe:
mysql -h xy1 -u root -p 9030
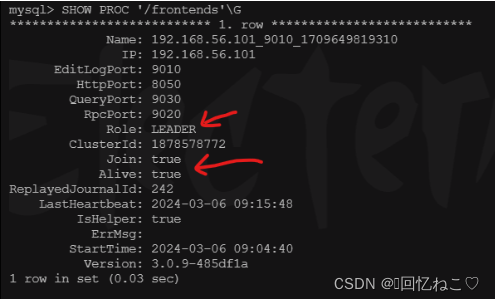
使用命令查看fe状况:
show proc '/frontends'\g
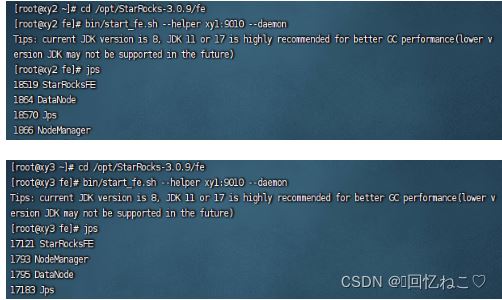
分别在另外节点启动fe:
bin/start_fe.sh --helper xy1:9010 --daemon
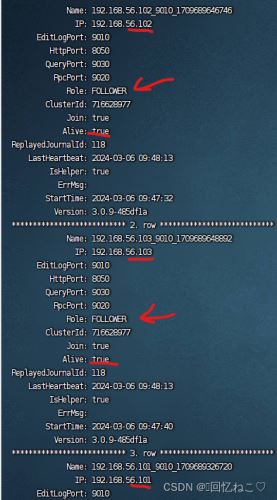
在节点xy1的mysql中添加fe节点(角色也分为follower、observer):
添加: alter system add follower "xy2:9010"; alter system add follower "xy3:9010"; 移除: alter system drop follower "xy2:9010"; alter system drop observer "xy2:9010"; 查看: show proc '/frontends'\g
be部署:
进入be,创建storage(这里上面已经创建):
cd /opt/starrocks-3.0.9/be mkdir storage
进入conf/be.conf进行修改(每个节点都要):
java_home = /usr/java/jdk1.8.0_291-amd64 storage_root_path=/opt/starrocks-3.0.9/be/storage be_http_port = 8070 priority_networks = 192.168.56.101/24
启动be:
#启动: cd /opt/starrocks-3.0.9/be ./bin/start_be.sh --daemon #停止: ./bin/stop_be.sh --daemon
通过mysql客户端添加be节点:
alter system add backend "xy1:9050"; alter system add backend "xy2:9050"; alter system add backend "xy3:9050"; #如不小心填错了,可用这个删除: alter system decommission backend "192.168.56.101:9050";
mysql查看:
show proc '/backends'\g
网页查看:
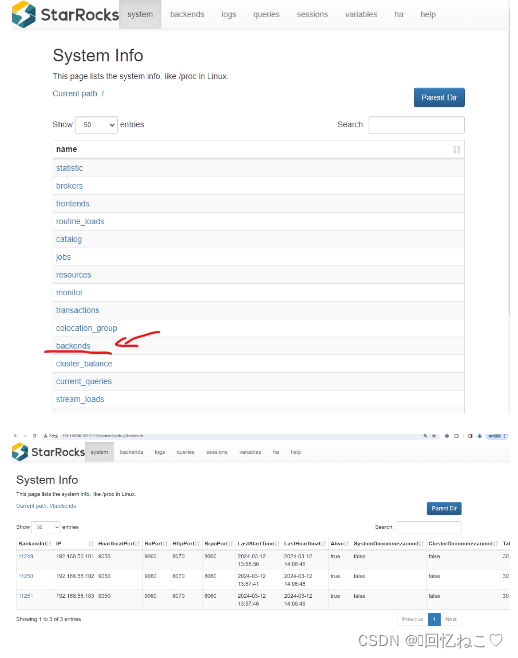
部署 broker :
#启动broker的命令:(完成配置后可用,每个节点都需要启动) cd /opt/starrocks-3.0.9 ./apache_hdfs_broker/bin/start_broker.sh --daemon
配置文件在/opt/starrocks-3.0.9/apache_hdfs_broker/conf/apache_hdfs_broker.conf(具体由安装路径而定)
复制自己的 hdfs 集群配置文件hdfs-site.xml并粘贴至 conf 路径下。
当您尝试启动starrocks的broker服务时,系统报错提示“java_home is not set”,这意味着在运行start_broker.sh脚本时,环境变量java_home尚未指向java安装目录。
解决方法:
我的java的安装路径为/usr/java/jdk1.8.0_291-amd64,可以在用户的.bashrc文件中添加以下两行来设置java_home环境变量:
进入:
vim ~/.bashrc
添加环境:
export java_home=/usr/java/jdk1.8.0_291-amd64 export path=$java_home/bin:$path
保存文件后,为了让新设置立即生效,执行以下命令:
source ~/.bashrc
现在,java_home环境变量应该已经设置好了,您可以再次尝试启动starrocks的broker服务:
./apache_hdfs_broker/bin/start_broker.sh --daemon
进入mysql添加broker节点到集群中:
mysql -h xy1 -u root -p 9030
# broker1可以设置(后续使用broker导入需要),8000是apache_hdfs_broker.conf中的端口。 alter system add broker broker1 "192.168.56.101:8000"; alter system add broker broker1 "192.168.56.102:8000"; alter system add broker broker1 "192.168.56.103:8000";
查看broker节点信息:
show proc "/brokers"\g
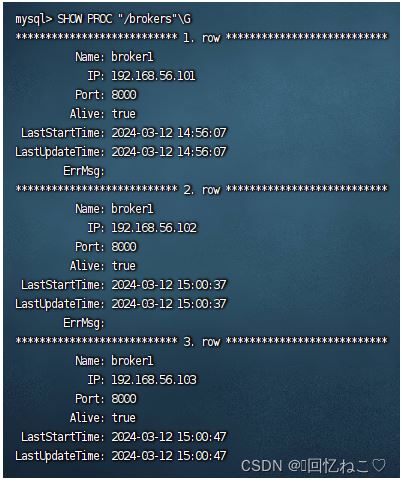
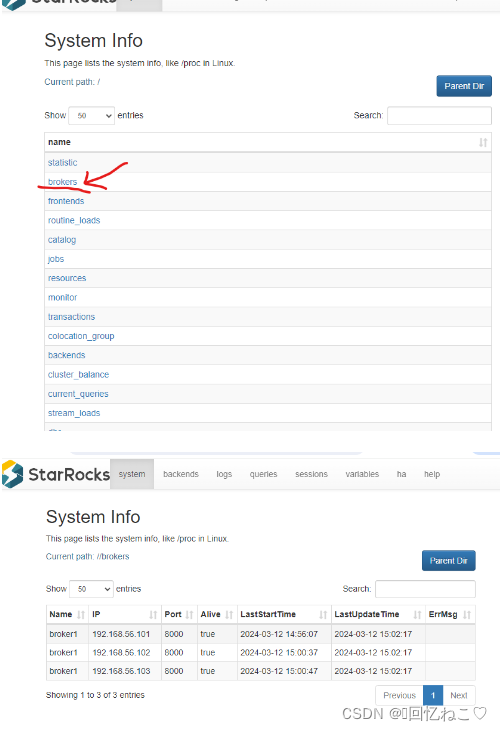
fe、be、broker启动与查看命令:
启动命令:
注意:每个节点都需要启动
#fe启动 cd /opt/starrocks-3.0.9/fe bin/start_fe.sh --daemon #be启动: cd /opt/starrocks-3.0.9/be ./bin/start_be.sh --daemon #启动broker的命令: cd /opt/starrocks-3.0.9 ./apache_hdfs_broker/bin/start_broker.sh --daemon #停止: ./bin/stop_be.sh --daemon # 进入 mysql -h xy1 -u root -p 9030
状态查看命令:
#使用查看fe状况: show proc '/frontends'\g #使用查看be状况: show proc '/backends'\g #使用查看broker状况: show proc "/brokers"\g
五、案例分享
数据从hive导入starrocks: 在starrocks中创建表:
create database if not exists db_df_lawsuits_v;
use db_df_lawsuits_v;
create table db_df_lawsuits_v.t_lawsuits_rolerelations (
eid string,
obj_id string,
ename string,
md5 string,
title string,
case_no string,
cause_action string,
type string,
role string,
court string,
trial_result string,
url string,
judgeresult string,
sub_amount double,
related_companies string,
related_relation string,
freezing_info string,
u_tags string,
`date` datetime,
pub_date datetime,
year_date string,
year_pubdate string,
row_update_time datetime,
case_type string,
case_cause string,
case_causes string,
doc_type string,
case_status string,
doc_id string,
relation_details string,
case_relation bigint,
clean_role string,
verdict_type string,
related_case_no string,
initial_court_code string,
court_area_code string,
source string,
create_time datetime,
local_update_time datetime,
local_row_update_time datetime
)
distributed by hash(eid) buckets 4;
hive-site.xml中设置hive.metastore.uris参数:
<name>hive.metastore.uris</name>
<value>thrift://xy1:9083</value>
登录starrocks:
mysql -h xy1 -u root -p 9030
hive catalog查询与导入:
在starrocks中执行以下sql语句来创建一个外部catalog,指向您的hive metastore服务。
(catalog(数据目录)功能,实现在一套系统内同时维护内、外部数据,可以不执行数据导入就轻松访问并查询存储在各类外部源的数据。)
create external catalog my_hive_catalog
properties (
"type" = "hive",
"hive.metastore.uris" = "thrift://xy1:9083"
);
查看catalog列表:首先,您可以通过执行show catalogs;命令来查看所有可用的catalog。
使用hive catalog:然后,使用set catalog 'my_hive_catalog';命令来切换到您创建的hive catalog。
查看数据库列表:通过执行show databases;命令,可以查看hive catalog中的数据库列表。
查看表列表:选择一个数据库,然后执行show tables;来查看该数据库中的表列表。
查询表结构:使用describe <table_name>;命令来查看表的结构和分区信息。
禁用严格模式:在插入数据之前,您可以通过设置会话变量来禁用严格模式,这样starrocks会将不符合条件的字段值转换为null,而不是过滤掉整行数据。执行以下命令:
set enable_insert_strict = false;
如果开启严格模式,starrocks 会把错误的数据行过滤掉,只导入正确的数据行,并返回错误数据详情。如果关闭严格模式,starrocks 会把转换失败的错误字段转换成 null 值,并把这些包含 null 值的错误数据行跟正确的数据行一起导入。
数据导入
insert into db_df_lawsuits_v.t_lawsuits_rolerelations select * from my_hive_catalog.db_df_lawsuits_v.t_lawsuits_rolerelations;
这条命令影响了25600行数据,并且耗时1.27秒完成,执行速度很快。
8.监控导入状态:导入作业提交后,先选择数据库,然后您可以通过show load命令来监控导入作业的状态。
数据使用broker导入:
基本原理:
提交导入作业以后,fe 会生成对应的查询计划,并根据目前可用 be 的个数和源数据文件的大小,将查询计划分配给多个 be 执行。每个 be 负责执行一部分导入任务。be 在执行过程中,会从 hdfs 或云存储系统拉取数据,并且会在对数据进行预处理之后将数据导入到 starrocks 中。所有 be 均完成导入后,由 fe 最终判断导入作业是否成功。
支持格式:
csv、orcfile、parquet等文件格式
在starrocks中创建表:
use db_df_lawsuits_v;
create table db_df_lawsuits_v.test_brok (
eid string,
obj_id string,
ename string,
md5 string,
title string,
case_no string,
cause_action string,
`type` string,
`role` string,
court string,
trial_result string,
url string,
judgeresult string,
sub_amount double,
related_companies string,
related_relation string,
freezing_info string,
u_tags string,
`date` datetime,
pub_date datetime,
year_date string,
year_pubdate string,
row_update_time datetime,
case_type string,
case_cause string,
case_causes string,
doc_type string,
case_status string,
doc_id string,
relation_details string,
case_relation bigint,
clean_role string,
verdict_type string,
related_case_no string,
initial_court_code string,
court_area_code string,
source string,
create_time datetime,
local_update_time datetime,
local_row_update_time datetime
)
distributed by hash(eid) buckets 4;
使用broker导入语句:
-- 加载标签 `db_df_lawsuits_v.test_brok2`,该标签表示从hdfs加载数据到starrocks数据库中的一个导入任务
load label db_df_lawsuits_v.test_brok2
(
-- 指定数据源,即hdfs上的orc格式数据文件集合
data infile("hdfs://192.168.56.101:9870/user/hive/warehouse/db_df_lawsuits_v.db/t_lawsuits_rolerelations/*")
-- 导入数据的目标表是名为 `test_brok1` 的表
into table test_brok1
-- 指定数据文件的格式为 orc 格式
format as "orc"
)
-- 使用名为 `broker1` 的hdfs broker组件进行数据搬运
with broker
(
'name' = 'broker1',
'type' = 'hdfs',
-- 配置hdfs broker连接hdfs所需的认证信息
'properties' = '{"username": "root", "password": "cqie"}'
)
-- 设置导入任务的超时时间为36000秒(即10小时)
properties
(
'timeout' = '36000'
);
-- 查看所有load label任务 show tables; -- 查看特定标签的任务 show tables from db_df_lawsuits_v; -- 查看导入作业的列表和状态 show load;
删除:
如果您想删除表中的数据,可以使用delete语句。这个语句允许您按条件删除表中的数据。例如:
delete from table_name where condition;
如果您想删除整个表(标签),则需要使用drop table语句。这将删除表及其所有数据,操作不可逆转。例如:
drop table table_name;
请注意,在执行drop table操作之前,确保您已经备份了任何重要数据,因为这个操作会永久删除表和表中的所有数据。
如果您是想清空表中的数据但保留表结构,可以使用truncate table语句。这个命令会删除表中的所有数据,但表结构仍然保留。例如:
truncate table table_name;
第三方平台方式将数据导入到starrocks
python导入数据
创表sql
create table `table1` ( `id` int(11) not null comment "用户 id", `name` varchar(65533) null comment "用户姓名", `score` int(11) not null comment "用户得分" ) engine=olap primary key(`id`) distributed by hash(`id`) buckets 10; create table `table2` ( `id` int(11) not null comment "城市 id", `city` varchar(65533) null comment "城市名称" ) engine=olap primary key(`id`) distributed by hash(`id`) buckets 10;
python代码
import requests,json
#验证密码
session=requests.session()
session.auth=('root','')
#csv导入
table='table1'
headers_csv={
'label':'123',
#分隔符
'column_separator':',',
#字段
'columns': 'id, name, score'
}
'''
1,lily,23
2,rose,23
3,alice,24
4,julia,25
'''
data=open('score.csv','r').read()
r=session.put(f'http://10.8.16.200:8040/api/testdb/{table}/_stream_load',headers=
headers_csv,data=data)
r.json()
#json导入
table='table2'
#请求头
headers_json={
'content-type': 'application/json',
"expect": "100-continue",
'strict_mode': 'true',
'format': 'json',
#jsonpaths https://www.cnblogs.com/youring2/p/10942728.html
'jsonpaths': '[\"$.name\", \"$.code\"]',
'columns': 'city,tmp_id, id = tmp_id * 100'
}
for i in [{"name": "上海", "code": 1},{"name": "重庆", "code": 3}]:
data=json.dumps(i)
r=session.put(f'http://10.8.16.200:8040/api/testdb/{table}/_stream_load',headers
=headers_json,data=data)
print(r.json())
以上就是starrocks简介与搭建使用详解的详细内容,更多关于starrocks搭建使用的资料请关注代码网其它相关文章!
赞 (0)
您想发表意见!!点此发布评论




发表评论