Rust获取命令行参数及IO操作方法
177人参与 • 2025-06-13 • rust
rust获取命令行参数以及io操作
rust作为一门系统编程语言,提供了强大且安全的i/o操作支持。与c/c++不同,rust通过所有权系统和丰富的类型系统,在编译期就能避免许多常见的i/o错误。rust的标准库std::io模块包含了大多数i/o功能,而std::fs模块则专门处理文件系统操作。
1、接收命令行参数
1.1 读取参数值
rust 标准库提供的std::env::args 能够获取传递给它的命令行参数的值
这个函数返回一个传递给程序的命令行参数的 迭代器(iterator)。
use std::env;
fn main() {
let args: vec<string> = env::args().collect();
println!("{:?}", args);
}首先使用 use 语句来将 std::env 模块引入作用域以便可以使用它的 args 函数。
注意 std::env::args 函数被嵌套进了两层模块中。
当所需函数嵌套了多于一层模块时,通常将父模块引入作用域,而不是其自身。
这便于我们利用 std::env 中的其他函数。这比增加了 use std::env::args; 后仅仅使用 args 调用函数要更明确一些,因为 args 容易被错认成一个定义于当前模块的函数。
得到的第一个参数是生成的程序本身,后面都是命令行参数
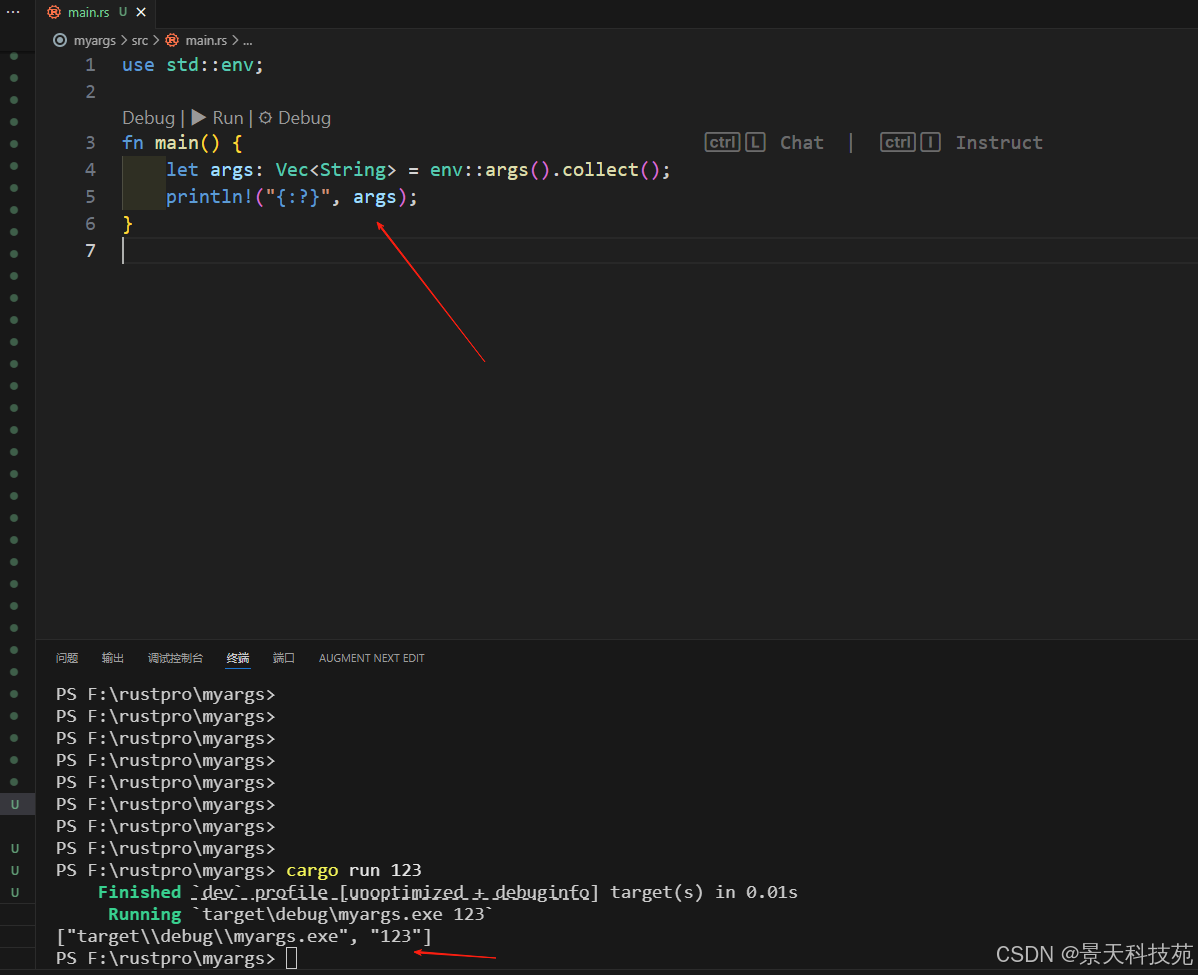
在 main 函数的第一行,我们调用了 env::args,并立即使用 collect 来创建了一个包含迭代器所有值的 vector。
collect 可以被用来创建很多类型的集合,所以这里显式注明 args 的类型来指定我们需要一个字符串 vector。
虽然在 rust 中我们很少会需要注明类型,然而 collect 是一个经常需要注明类型的函数,因为 rust 不能推断出你想要什么类型的集合。
最后,我们使用调试格式 :? 打印出 vector。
注意 vector 的第一个值是 “target\debug\myargs.exe”,它是我们二进制文件的名称。这与 c 中的参数列表的行为相匹配,让程序使用在执行时调用它们的名称。
如果要在消息中打印它或者根据用于调用程序的命令行别名更改程序的行为,通常可以方便地访问程序名称,不过考虑到本章的目的,我们将忽略它并只保存所需的两个参数。
注意args 函数和无效的 unicode
注意 std::env::args 在其任何参数包含无效 unicode 字符时会 panic。
如果你需要接受包含无效 unicode 字符的参数,使用 std::env::args_os 代替。这在某些操作系统中可能发生
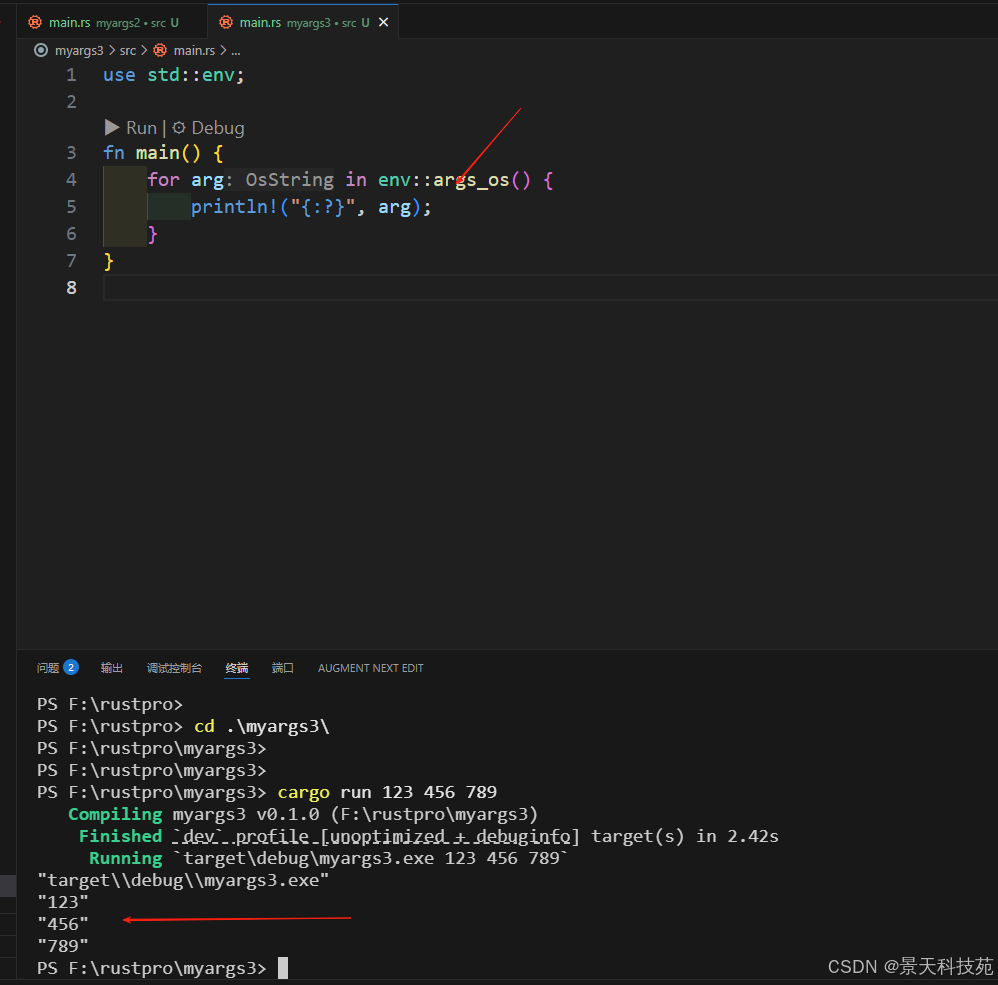
这个函数返回 osstring 值而不是 string 值。
osstring 值每个平台都不一样而且比 string 值处理起来更为复杂。
use std::env;
fn main() {
for arg in env::args_os() {
println!("{:?}", arg);
}
}
1.2 将参数值保存进变量
打印出参数 vector 中的值展示了程序可以访问指定为命令行参数的值。现在需要将这两个参数的值保存进变量这样就可以在程序的余下部分使用这些值了。
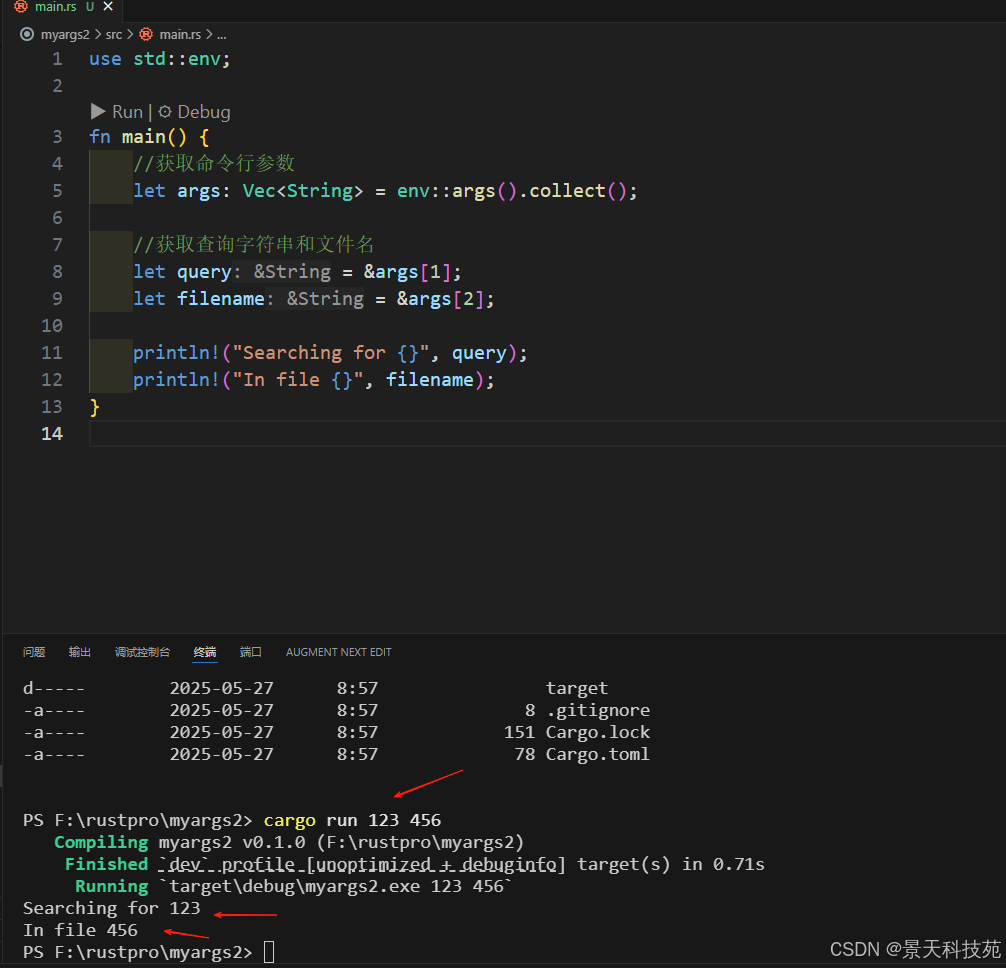
use std::env;
fn main() {
//获取命令行参数
let args: vec<string> = env::args().collect();
//获取查询字符串和文件名
let query = &args[1];
let filename = &args[2];
println!("searching for {}", query);
println!("in file {}", filename);
}正如之前打印出 vector 时所看到的,程序的名称占据了 vector 的第一个值 args[0],所以我们从索引 1 开始。
myargs2 获取的第一个参数是需要搜索的字符串,所以将其将第一个参数的引用存放在变量 query 中。第二个参数将是文件名,所以将第二个参数的引用放入变量 filename 中。
2、rust读取文件
在 rust 中读取文件是常见的 i/o 操作,标准库提供了多种方法来处理文件读取。下面我将详细介绍各种文件读取方法及其适用场景
2.1. 基本文件读取
2.1.1 一次性读取整个文件到字符串
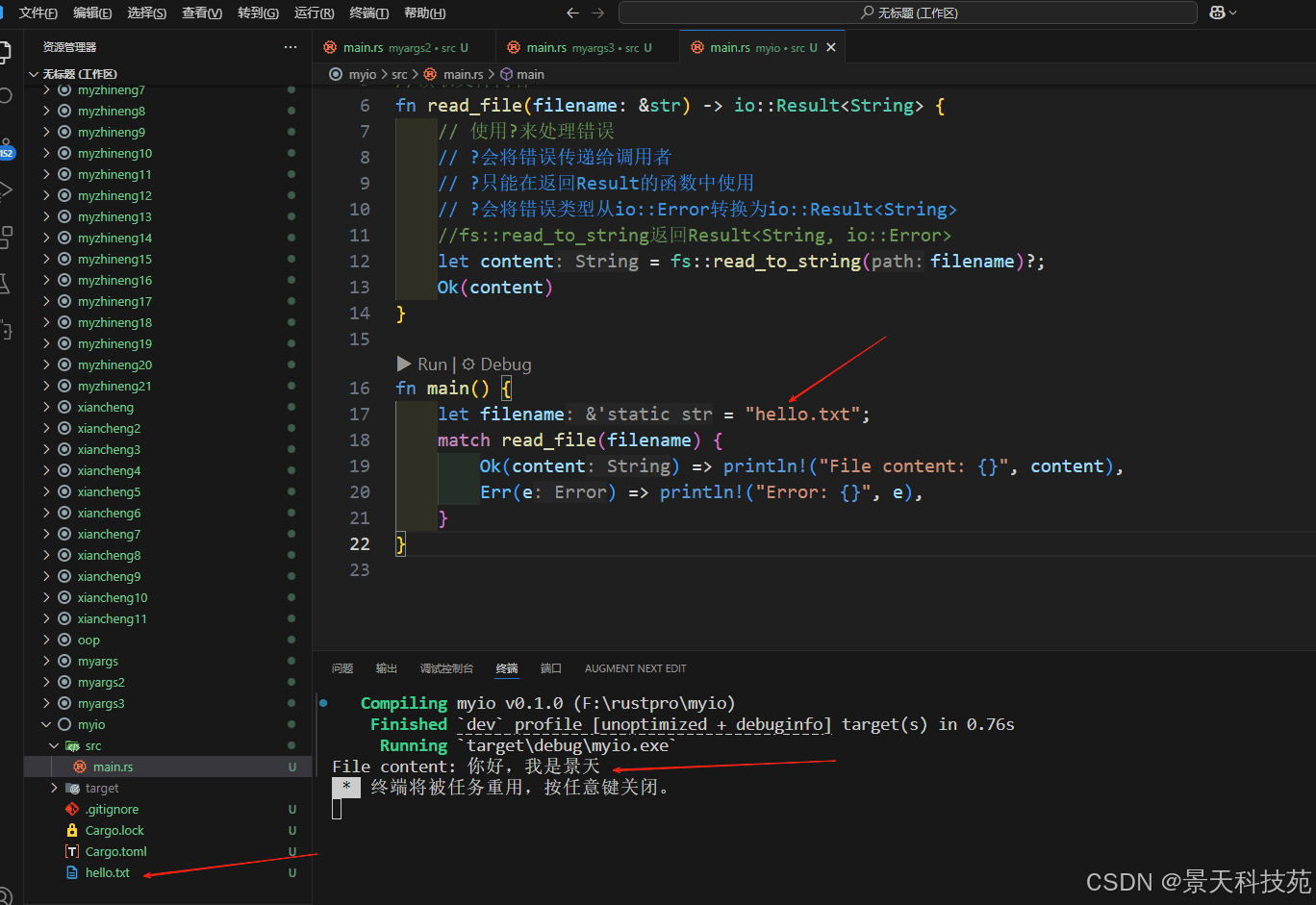
use std::fs;
use std::io;
//读取文件内容
fn read_file(filename: &str) -> io::result<string> {
// 使用?来处理错误
// ?会将错误传递给调用者
// ?只能在返回result的函数中使用
// ?会将错误类型从io::error转换为io::result<string>
//fs::read_to_string返回result<string, io::error>
let content = fs::read_to_string(filename)?;
ok(content)
}
fn main() {
let filename = "hello.txt";
match read_file(filename) {
ok(content) => println!("file content: {}", content),
err(e) => println!("error: {}", e),
}
}
2.1.2 一次性读取整个文件到字节向量
用于读取二进制文件
//读取文件到字节向量
use std::fs;
use std::io;
//读取二进制文件内容
fn read_file(filename: &str) -> io::result<vec<u8>> {
// 使用?来处理错误
// ?会将错误传递给调用者
// ?只能在返回result的函数中使用
// ?会将错误类型从io::error转换为io::result<vec<u8>>
//fs::read返回result<vec<u8>, io::error>
let content = fs::read(filename)?;
ok(content)
}
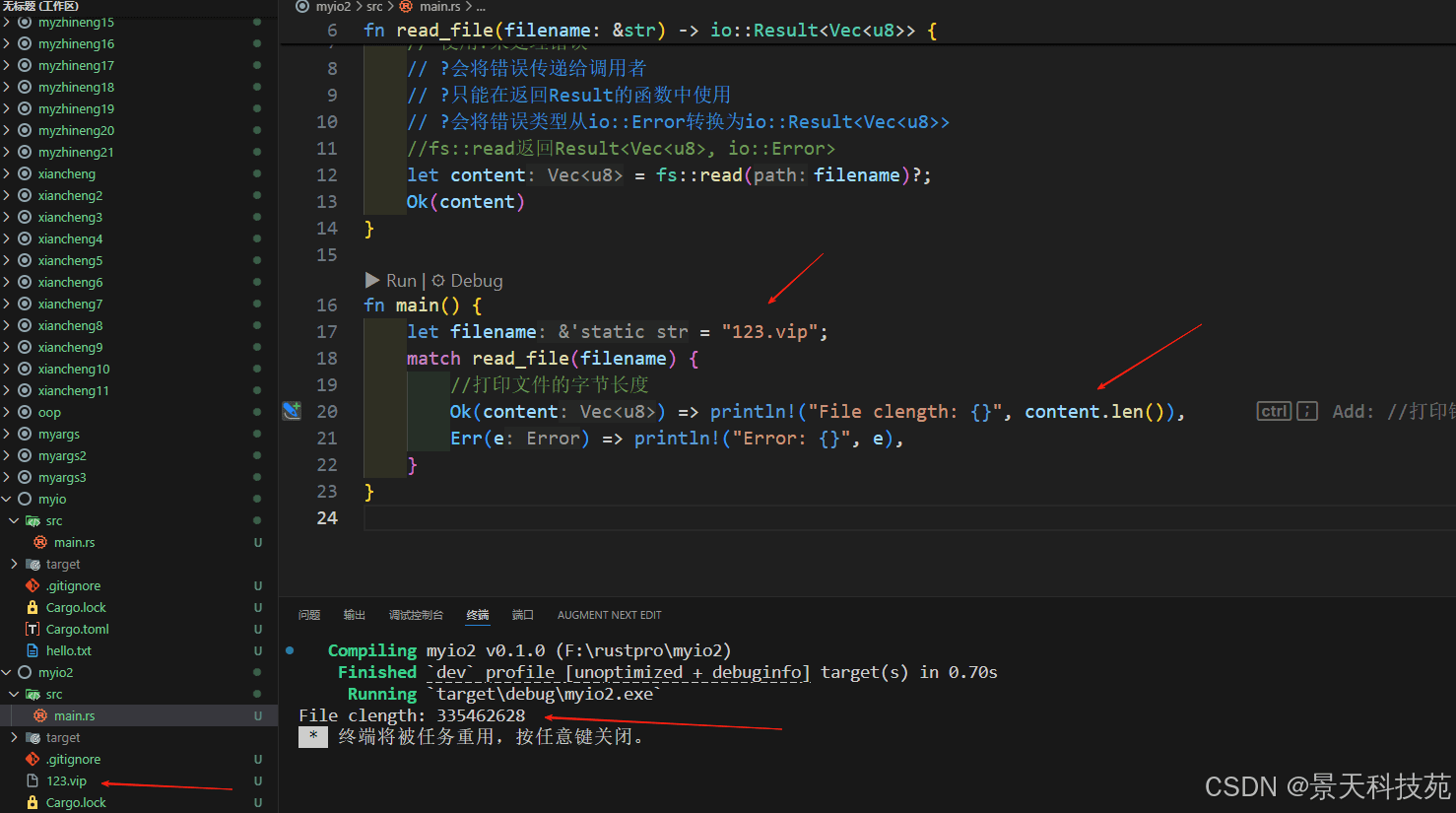
fn main() {
let filename = "123.vip";
match read_file(filename) {
//打印文件的字节长度
ok(content) => println!("file clength: {}", content.len()),
err(e) => println!("error: {}", e),
}
}
2.2. 逐行读取文件
对于大文件,逐行读取更高效且内存友好。
2.2.1 使用 bufreader 逐行读取
//读取大文件
use std::fs::file;
use std::io::{ bufread, bufreader };
//读取大文件内容
fn read_file(filename: &str) -> std::io::result<()> {
let file = file::open(filename)?;
let reader = bufreader::new(file);
for line in reader.lines() {
println!("{}", line?);
}
ok(())
}
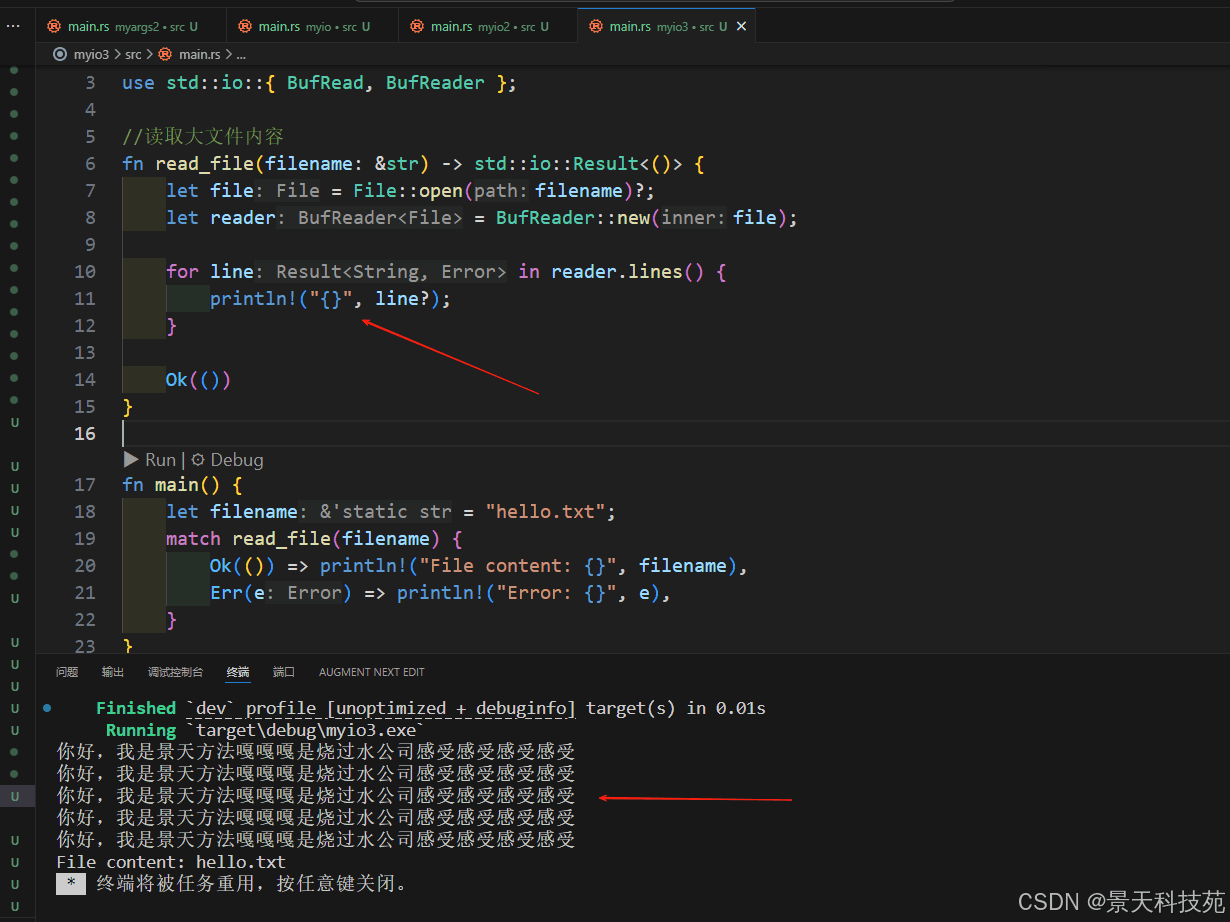
fn main() {
let filename = "hello.txt";
match read_file(filename) {
ok(()) => println!("file content: {}", filename),
err(e) => println!("error: {}", e),
}
}
特点:
内存效率高
自动处理换行符
lines() 返回 result<string>,需要处理可能的错误
2.2.2 使用 bufreader 读取字节块
//使用 bufreader 读取字节块
use std::io::{ self, read };
use std::fs::file;
//读取字节块
fn read_file(filename: &str) -> io::result<()> {
let file = file::open(filename)?;
let mut reader = io::bufreader::new(file);
//定义一个字节缓冲区
//缓冲区的大小为1024字节
let mut buffer = [0; 10];
//循环读取字节块
//read方法会将字节块读取到缓冲区中
//read方法返回读取的字节数
//如果读取到文件末尾,就退出循环
loop {
let n = reader.read(&mut buffer)?;
if n == 0 {
break; //读取到文件末尾,退出循环
}
println!("read {} bytes: {:?}", n, &buffer[..n]);
// 处理 buffer[..n]
}
ok(())
}
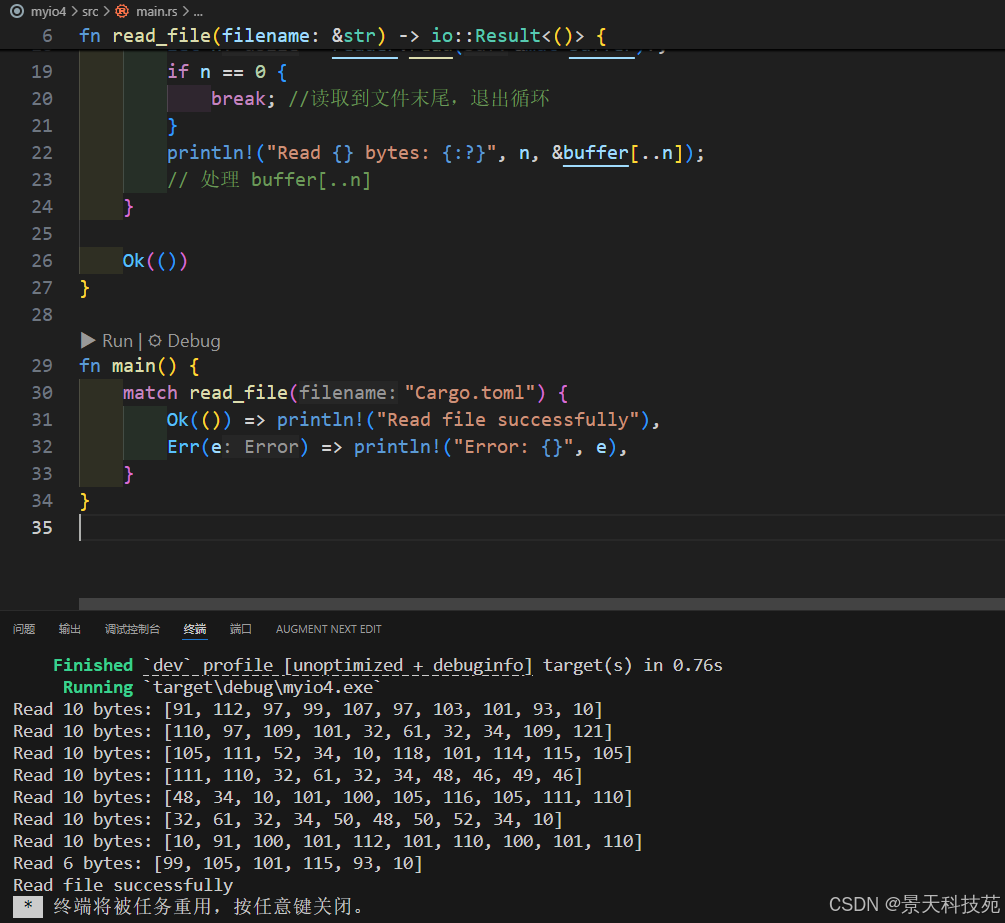
fn main() {
match read_file("cargo.toml") {
ok(()) => println!("read file successfully"),
err(e) => println!("error: {}", e),
}
}
特点:
适用于二进制文件
可以控制缓冲区大小
适合网络传输或处理大文件
2.3 使用内存映射文件 (memmap2)
对于超大文件,内存映射可以提高性能:
use std::fs::file;
use memmap2::mmap;
fn main() -> std::io::result<()> {
let file = file::open("cargo.toml")?;
//使用memmap2映射文件到内存,需要使用unsafe,需要注意
let mmap = unsafe { mmap::map(&file)? };
// 假设我们搜索某个字节模式
let pattern = b"\xde\xad\xbe\xef";
if let some(pos) = mmap.windows(pattern.len()).position(|w| w == pattern) {
println!("pattern found at offset: {}", pos);
} else {
println!("pattern not found");
}
ok(())
}注意:内存映射涉及 unsafe 代码,需要谨慎使用。
3、rust向文件中写内容
//写入文件
use std::fs;
use std::io;
fn write_file(filename: &str, content: &str) -> io::result<()> {
fs::write(filename, content)
}
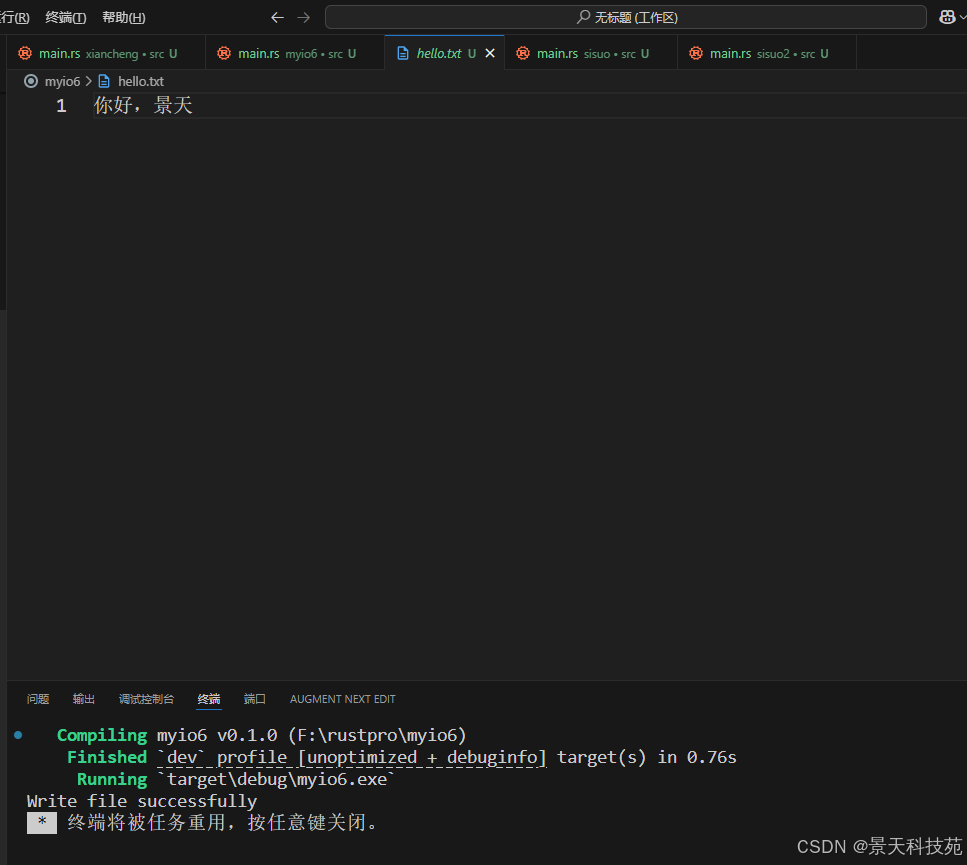
fn main() {
let filename = "hello.txt";
let content = "你好,景天";
match write_file(filename, content) {
ok(()) => println!("write file successfully"),
err(e) => println!("error: {}", e),
}
}
4、rust序列化与反序列化
使用 serde 库可以方便地进行 i/o 操作:
需要安装第三方库
cargo add serde
cargo add serde_json
并且在cargo.toml中配置
//序列化和反序列化
use serde::{ serialize, deserialize };
use std::fs;
use serde_json;
#[derive(serialize, deserialize, debug)]
#[allow(dead_code)]
struct person {
name: string,
age: u8,
phones: vec<string>,
}
fn main() {
let person = person {
name: "john".to_string(),
age: 30,
phones: vec!["1234567890".to_string(), "0987654321".to_string()],
};
//序列化
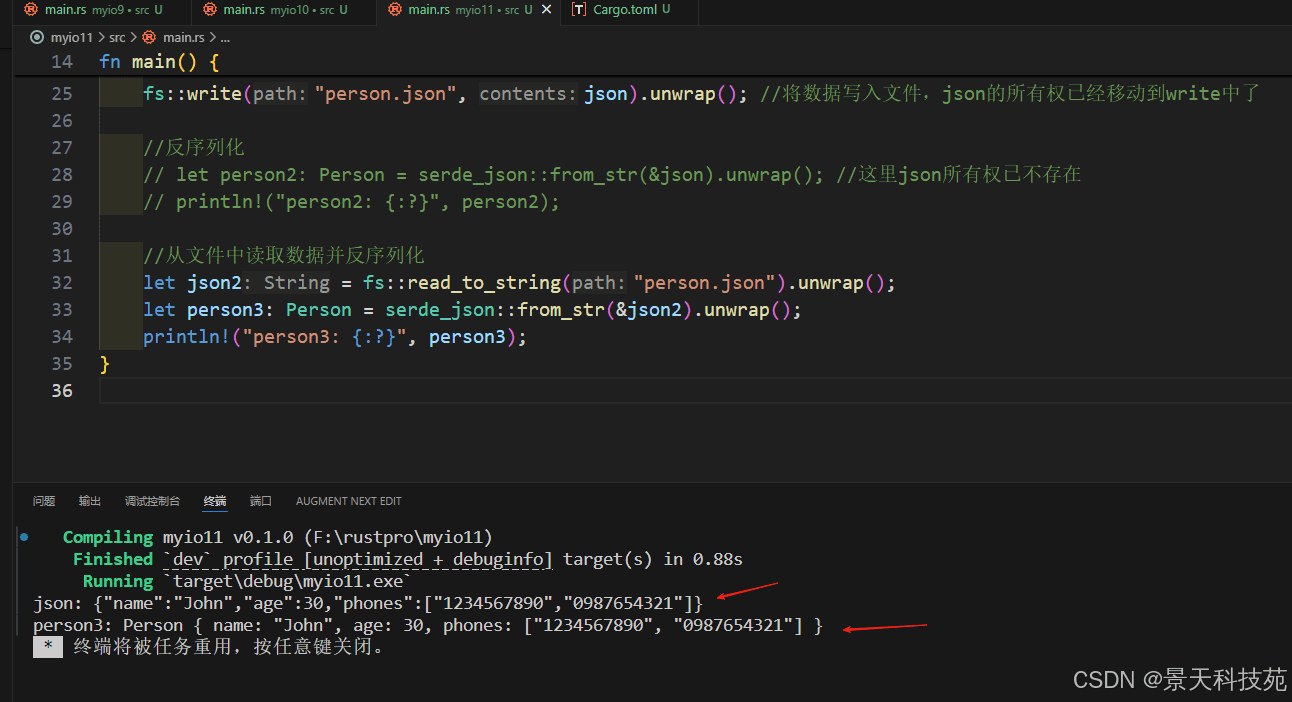
let json = serde_json::to_string(&person).unwrap(); //将结构体序列化为json字符串
println!("json: {}", json);
//将序列化后的数据写入文件
fs::write("person.json", json).unwrap(); //将数据写入文件,json的所有权已经移动到write中了
//反序列化
// let person2: person = serde_json::from_str(&json).unwrap(); //这里json所有权已不存在
// println!("person2: {:?}", person2);
//从文件中读取数据并反序列化
let json2 = fs::read_to_string("person.json").unwrap();
let person3: person = serde_json::from_str(&json2).unwrap();
println!("person3: {:?}", person3);
}
到此这篇关于rust获取命令行参数以及io操作的文章就介绍到这了,更多相关rust获取命令行参数内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!
赞 (0)
您想发表意见!!点此发布评论





发表评论