Rust中多线程 Web 服务器的项目实战
290人参与 • 2025-06-26 • rust
前情提要:https://www.jb51.net/program/34427748j.htm
单线程 web 服务器将依次处理每个请求,这意味着在第一个连接完成处理之前,它不会处理第二个连接。如果服务器接收到越来越多的请求,那么串行执行将越来越不理想。如果服务器接收到一个需要很长时间来处理的请求,则后续请求将不得不等待,直到长请求完成,即使新请求可以快速处理。我们需要解决这个问题,但首先我们要看看实际的问题。
模拟慢速请求
我们将了解处理缓慢的请求如何影响对单线程 web 服务器实现的其他请求。
我们使用模拟的缓慢响应实现了对 /sleep 的请求处理,该响应将导致服务器在响应之前休眠 5 s。
use std::{
fs,
io::{bufreader, prelude::*},
net::{tcplistener, tcpstream},
thread,
time::duration,
};
// --snip--
fn handle_connection(mut stream: tcpstream) {
// --snip--
let (status_line, filename) = match &request_line[..] {
"get / http/1.1" => ("http/1.1 200 ok", "hello.html"),
"get /sleep http/1.1" => {
thread::sleep(duration::from_secs(5));
("http/1.1 200 ok", "hello.html")
}
_ => ("http/1.1 404 not found", "404.html"),
};
// --snip--
}
新增了一种对 /sleep 请求的响应,当接收到该请求时,服务器将在呈现 hello.html 之前休眠 5 s。
使用 cargo run 启动服务器。然后打开两个浏览器窗口:一个用于 127.0.0.1:7878,另一个用于 127.0.0.1:7878/sleep。如果像以前一样多次输入 / uri,您将看到它快速响应。但是如果你输入 /sleep,然后加载 /,你会看到 / 等待,直到 sleep 了整整 5 s 才加载。
我们要实现一个线程池,避免慢速请求后面的请求等待。
使用线程池提高吞吐量
线程池是一组正在等待并准备处理任务的派生线程。当程序接收到一个新任务时,它将池中的一个线程分配给该任务,该线程将处理该任务。池中的剩余线程可用于处理在第一个线程正在处理时进入的任何其他任务。当第一个线程完成其任务的处理后,它将返回到空闲线程池,准备处理新任务。线程池允许您并发地处理连接,从而提高服务器的吞吐量。
我们将限制池中的线程数量,因为服务器的资源是有限的,也保护我们免受 dos 攻击。进入的请求被发送到池中进行处理,线程池将维护一个传入请求队列,池中的每个线程将从这个队列中弹出一个请求,处理该请求,然后向队列请求另一个请求。使用这种设计,我们最多可以并发处理 n 个请求,其中 n 是线程数。
这种技术只是提高 web 服务器吞吐量的众多方法之一。其他选项包括 fork/join 模型、单线程异步 i/o 模型和多线程异步 i/o 模型,等等。
初步尝试:为每个请求生成一个线程
首先,让我们探索一下,如果为每个连接创建一个新线程,我们的代码会是什么样子。正如前面提到的,这不是我们的最终计划,因为可能会产生无限数量的线程,但这是一个起点,可以首先获得一个工作的多线程服务器。然后我们将添加线程池作为改进,并且比较两种解决方案会更容易。
在单线程 web 服务器的 main 函数中进行修改:
use std::thread;
fn main() {
let listener = tcplistener::bind("127.0.0.1:7878").unwrap();
for stream in listener.incoming() {
let stream = stream.unwrap();
thread::spawn(|| {
handle_connection(stream);
});
}
}
thread::spawn 将创建一个新线程,然后在新线程中运行闭包中的代码。
如果运行这段代码并在浏览器中加载 /sleep,然后在另外两个浏览器选项卡中加载 /,对 / 的请求不必等待 /sleep 完成。然而,正如我们所提到的,这最终将使系统不堪重负,因为你将无限制地创建新线程。
现在,是时候让 async 和 await 真正发挥作用了!
实现线程池的定义和函数声明
我们的线程池的实现将独立于我们的 web 服务器正在做的工作。
创建一个src/lib.rs,先实现一个 threadpool 结构体的定义,以及 threadpool::new 函数,其参数 size 表示线程池内线程的最大数量。
pub struct threadpool;
impl threadpool {
pub fn new(size: usize) -> threadpool {
threadpool
}
}
我们将实现 execute 函数,它接受给定的闭包,并将其交给池中的空闲线程运行。该函数类似于标准库 thread::spawn 函数。
我们可以将闭包作为具有三个不同特征的参数:fn、fnmut 和 fnonce。我们需要决定在这里使用哪种闭包。我们可以看看 thread::spawn 的签名对它的参数有什么限制。文档向我们展示了以下内容:
impl threadpool {
// --snip--
pub fn execute<f>(&self, f: f)
where
f: fnonce() + send + 'static,
{
}
}
f 类型参数是我们关心的,t 类型参数与返回值有关,我们不关心这个。我们可以看到 spawn 使用 fnonce 作为 f 上的 trait 约束。因为我们最终将在 execute 中获得的参数传递给 spawn,并且运行请求的线程只会执行该请求的闭包一次,所以 fnonce 是我们想要使用的 trait。
f 类型参数也有 send trait 约束和 static 生命周期约束,这在我们的情况下很有用:我们需要 send 来将闭包从一个线程转移到另一个线程,而需要 static 是因为我们不知道线程执行需要多长时间。让我们在 threadpool 上创建一个execute方法,它将接受 f 类型的泛型参数,并具有以下约束:
impl threadpool {
// --snip--
pub fn execute<f>(&self, f: f)
where
f: fnonce() + send + 'static,
{
}
}
我们仍然在 fnonce 之后使用 (),因为这个 fnonce 表示一个闭包,它不接受参数,返回单元类型 ()。就像函数定义一样,返回类型可以从签名中省略,但即使没有参数,仍然需要括号。
threadpool 结构体的定义和两个函数的声明已经完成,使用 threadpool 结构体代替 thread::spawn 的假设接口。
修改 main.rs 中的代码:
use multi_thread_web_server::threadpool;
fn main() {
let listener = tcplistener::bind("127.0.0.1:7878").unwrap();
let pool = threadpool::new(4);
for stream in listener.incoming() {
let stream = stream.unwrap();
pool.execute(|| {
handle_connection(stream);
});
}
}
我们使用 threadpool::new 创建一个新的线程池,可配置的线程数为 4 个。然后,在 for 循环中,pool.execute 有一个类似 thread::spawn 的接口,因为它接受一个闭包,处理每一个 stream。
运行 cargo build,编译通过了。
验证 new 中的线程数
前面我们为 size 参数选择了 unsigned 类型,因为线程数为负数的池没有意义。然而,一个没有线程的池也没有意义,所以在返回 threadpool 实例之前,我们将添加代码来检查 size 是否大于 0,并通过 assert 让程序在接收到 0 时 panic。
impl threadpool {
/// create a new threadpool.
///
/// the size is the number of threads in the pool.
///
/// # panics
///
/// the `new` function will panic if the size is zero.
pub fn new(size: usize) -> threadpool {
assert!(size > 0);
threadpool
}
// --snip--
}
我们还为 threadpool 添加了一些文档和文档注释。运行 cargo doc --open,在打开的 html 文档中点击 threadpool 就能查看它的一些介绍信息。
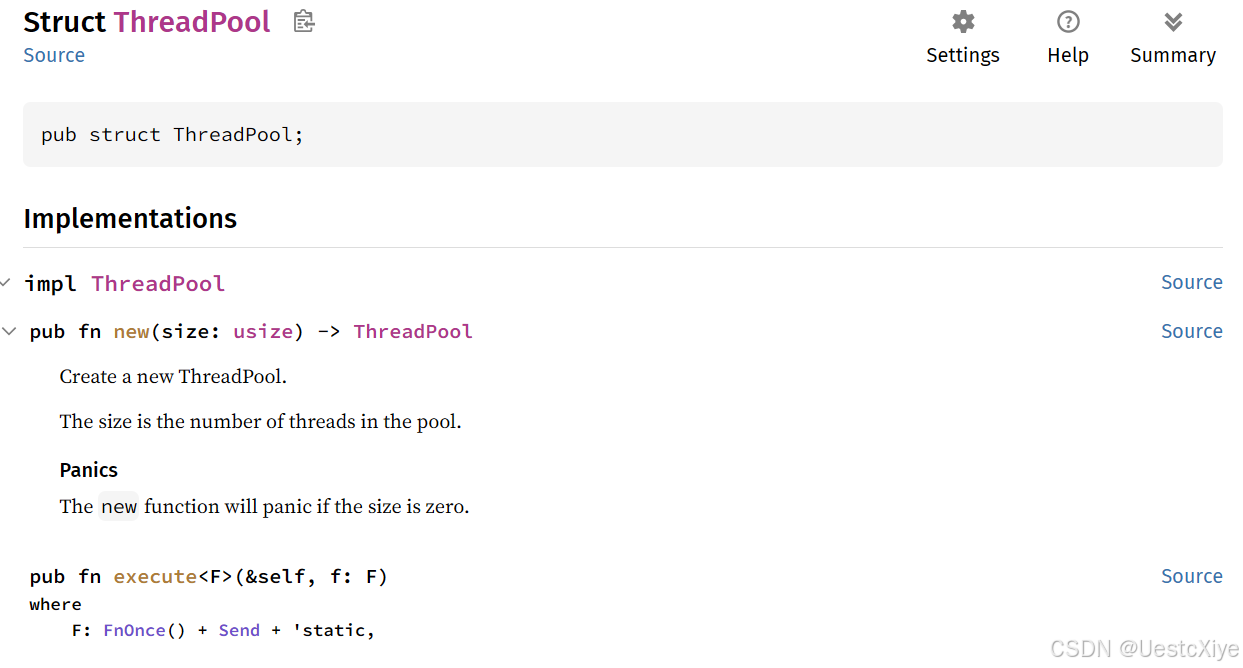
我们也可以将 new 更改为 build 并返回一个 result,就像下面的定义一样:
pub fn build(size: usize) -> result<threadpool, poolcreationerror> {
但是在这种情况下,我们尝试创建一个没有任何线程的线程池是不合理的,我们希望在错误时 panic。
创建存储线程的空间
既然我们有办法知道池中存储了有效数量的线程,我们就可以创建这些线程,并在返回结构体之前将它们存储在 threadpool 结构体中。
但是我们如何“存储”一个线程呢?让我们再看一下 thread::spawn 签名:
pub fn spawn<f, t>(f: f) -> joinhandle<t>
where
f: fnonce() -> t,
f: send + 'static,
t: send + 'static,
spawn 函数返回一个 joinhandle<t>,其中 t 是闭包返回的类型。我们也使用 joinhandle,因为我们传递给线程池的闭包将处理连接而不返回任何东西,因此 t 将是单元类型 ()。
修改 threadpool 的定义,使其包含 thread::joinhandle<()> 实例的 vector。
use std::thread;
pub struct threadpool {
threads: vec<thread::joinhandle<()>>,
}
再修改 new 函数,初始化 vector 的容量为 size,设置 for 循环,运行一些代码来创建线程,并返回一个包含它们的 threadpool 实例。
pub fn new(size: usize) -> threadpool {
assert!(size > 0);
let mut threads = vec::with_capacity(size);
for _ in 0..size {
// create some threads and store them in the vector
}
threadpool { threads }
}
再次运行 cargo build,编译成功。
负责将代码从线程池发送到线程的 worker 结构体
标准库的 thread::spawn 期望得到一些代码,这些代码应该在线程创建后立即运行。然而,在本例中,我们希望创建线程并让它们等待稍后发送的代码。
我们将通过在 threadpool 和管理这种新行为的线程之间引入一个新的数据结构来实现这种行为。我们将此数据结构称为 worker,这是池实现中的一个常用术语。worker 获取需要运行的代码,并在 worker 的线程中运行这些代码。
我们将存储 worker 结构的实例,而不是在线程池中存储 joinhandle<()> 实例的 vector。每个 worker 将存储一个 joinhandle<()> 实例。然后,我们将在 worker 上实现一个方法,该方法将接受代码的闭包来运行,并将其发送到已经运行的线程中执行。我们还将为每个 worker 提供一个 id,以便在进行日志记录或调试时区分池中 worker 的不同实例。
总结一下,我们要实现这四件事:
- 定义一个 worker 结构体,它包含一个 id 和一个 joinhandle<()>.
- 更改 threadpool 的定义,包含一个worker 实例的 vector,而不是 vec<thread::joinhandle<()>>。
- 定义一个 worker::new 函数,该函数接受一个 id 号,并返回一个包含该 id 的 worker 实例和一个由空闭包派生的线程。
- 在 threadpool::new 函数中,使用 for 循环计数器生成一个 id,用该 id 创建一个新的 worker,并将该 worker 存储在 vector 中。
use std::thread;
pub struct threadpool {
workers: vec<worker>,
}
impl threadpool {
// --snip--
pub fn new(size: usize) -> threadpool {
assert!(size > 0);
let mut workers = vec::with_capacity(size);
for id in 0..size {
workers.push(worker::new(id));
}
threadpool { workers }
}
// --snip--
}
struct worker {
id: usize,
thread: thread::joinhandle<()>,
}
impl worker {
fn new(id: usize) -> worker {
let thread = thread::spawn(|| {});
worker { id, thread }
}
}
外部代码不需要知道在 threadpool 中使用 worke r结构体的实现细节,所以我们把 worker 结构体及其函数设为 private。worker::new 函数使用我们给它的 id,并存储一个 joinhandle<()> 实例,该实例是通过使用空闭包生成一个新线程创建的。
我们将 threadpool 上的字段名称从 threads 更改为 workers,因为它现在保存 worker 实例而不是 joinhandle<()> 实例。
注意,如果操作系统因为没有足够的系统资源而无法创建线程,thread::spawn 将出现 panic,这在实际生产环境中很危险。实际情况下,我们可以使用 std::thread::builder 及其派生方法。
这段代码将编译并存储作为 threadpool::new 参数指定的 worker 实例的数量。但是我们仍然没有处理在 execute 中得到的闭包。让我们看看接下来该怎么做。
通过通道向线程发送请求
我们希望刚刚创建的 worker 结构体从 threadpool 中保存的队列中获取要运行的代码,并将该代码发送到其线程中运行。
我们将使用通道作为作业队列,execute 将把作业从 threadpool 发送到 worker 实例,后者将把作业发送到它的线程。计划如下:
- threadpool 将创建一个通道并保持发送端。
- 每个 worker 获取 receiver,作为接收端。
- 我们将创建一个新的 job 结构体来保存我们想要发送到通道中的闭包。
- execute 方法将通过发送端发送它想要执行的作业。
- 在它的线程中,worker 将遍历它的接收者,并执行它接收到的所有作业的闭包。
让我们首先在 threadpool::new 中创建一个通道,并在 threadpool 实例中保存发送端。job 结构现在还没有保存任何东西,但它将是我们发送到通道的项的类型。
use std::{sync::mpsc, thread};
pub struct threadpool {
workers: vec<worker>,
sender: mpsc::sender<job>,
}
struct job;
impl threadpool {
// --snip--
pub fn new(size: usize) -> threadpool {
assert!(size > 0);
let (sender, receiver) = mpsc::channel();
let mut workers = vec::with_capacity(size);
for id in 0..size {
workers.push(worker::new(id));
}
threadpool { workers, sender }
}
// --snip--
}
在 threadpool::new 中,我们创建了一个通道,并让 threadpool 包含 sender。这将成功编译。
让我们尝试在线程池创建通道时将通道的接收器传递给每个 worker。我们知道我们想要在 worker 实例产生的线程中使用 receiver,所以我们将在闭包中引用 receiver 参数。
impl threadpool {
// --snip--
pub fn new(size: usize) -> threadpool {
assert!(size > 0);
let (sender, receiver) = mpsc::channel();
let mut workers = vec::with_capacity(size);
for id in 0..size {
workers.push(worker::new(id, receiver));
}
threadpool { workers, sender }
}
// --snip--
}
// --snip--
impl worker {
fn new(id: usize, receiver: mpsc::receiver<job>) -> worker {
let thread = thread::spawn(|| {
receiver;
});
worker { id, thread }
}
}
代码试图将 receiver 传递给多个 worker 实例,这是行不通的,因为 rust 提供的通道实现是多个生产者,单个消费者。这意味着我们不能仅仅克隆通道的消费端(接收端)来修复此代码。我们也不想多次向多个消费者发送消息。我们想要一个包含多个 worker 实例的消息列表,这样每个消息都会被处理一次。
此外,从通道队列中取出作业涉及到改变 receiver,因此线程需要一种安全的方式来共享和修改 receiver。
为了在多个线程之间共享所有权并允许线程改变值,我们需要使用 arc<mutex<t>> 。arc 类型将允许多个 worker 实例拥有 receiver,mutex 将确保一次只有一个 worker 从接收器获得作业。
use std::{
sync::{arc, mutex, mpsc},
thread,
};
// --snip--
impl threadpool {
// --snip--
pub fn new(size: usize) -> threadpool {
assert!(size > 0);
let (sender, receiver) = mpsc::channel();
let receiver = arc::new(mutex::new(receiver));
let mut workers = vec::with_capacity(size);
for id in 0..size {
workers.push(worker::new(id, arc::clone(&receiver)));
}
threadpool { workers, sender }
}
// --snip--
}
// --snip--
impl worker {
fn new(id: usize, receiver: arc<mutex<mpsc::receiver<job>>>) -> worker {
// --snip--
}
}
在 threadpool::new 中,我们将接收者置于 arc<mutex<>> 中。对于每个新的 worker,我们克隆 arc 来增加引用计数,这样 worker 实例就可以共享 receiver 的所有权。
有了这些修改,代码就可以编译了。
实现 execute 方法
最后让我们实现 threadpool::execute 方法。我们还将 job 从结构体更改为 trait 对象的类型别名,该 trait 对象保存 execute 接收的闭包类型。
// --snip--
type job = box<dyn fnonce() + send + 'static>;
impl threadpool {
// --snip--
pub fn execute<f>(&self, f: f)
where
f: fnonce() + send + 'static,
{
let job = box::new(f);
self.sender.send(job).unwrap();
}
}
在使用获得的闭包创建新 job 实例之后,我们将该作业发送到通道中。在 send 失败的情况下我们调用 unwrap。
如果我们停止执行所有线程,这意味着接收端已经停止接收新消息,就可能发生这种情况。目前,我们不能停止线程的执行:只要池存在,线程就会继续执行。我们使用 unwrap 的原因是我们知道失败情况不会发生,但是编译器不知道。
但我们还没有完全完成!在 worker 中,传递给 thread::spawn 的闭包仍然只引用通道的接收端。相反,我们需要闭包永远循环,向通道的接收端请求作业,并在获得作业时运行作业。让我们对 worker::new 函数进行如下的更改。
// --snip--
impl worker {
fn new(id: usize, receiver: arc<mutex<mpsc::receiver<job>>>) -> worker {
let thread = thread::spawn(move || {
loop {
let job = receiver.lock().unwrap().recv().unwrap();
println!("worker {id} got a job; executing.");
job();
}
});
worker { id, thread }
}
}
在这里,我们首先在 receiver 上调用 lock 来获取互斥锁,然后调用 unwrap 来在出现错误时发出警报。
如果互斥锁处于锁定状态,获取锁可能会失败,如果其他线程在持有锁而不是释放锁时 panic,就会发生这种情况。在这种情况下,调用 unwrap 使该线程 panic 是正确的操作。你也可以将此 unwrap 更改为 expect,并显示有意义的错误消息。
如果我们获得了互斥锁,我们调用 recv 从通道接收 job。如果持有发送方的线程已经关闭,那么最后的 unwrap 也会跳过这里的任何错误,类似于如果接收方关闭,则 send 方法返回 err。
对 recv 的调用会阻塞当前线程,直到有作业可用。mutex<t> 确保一次只有一个 worker 线程试图请求作业。
至此,多线程 web 服务器已经能成功运行了。现在我们有了一个异步执行连接的线程池。创建的线程永远不会超过 4 个,所以如果服务器接收到大量请求,我们的系统也不会过载,但也不会停止。在浏览器打开多个网页,程序输出一些执行的信息:
worker 0 got a job; executing. worker 1 got a job; executing. worker 2 got a job; executing. worker 3 got a job; executing. worker 0 got a job; executing. worker 2 got a job; executing. worker 1 got a job; executing. ...
你可能想知道为什么不按照下面所示的方式编写工作线程代码。
// --snip--
impl worker {
fn new(id: usize, receiver: arc<mutex<mpsc::receiver<job>>>) -> worker {
let thread = thread::spawn(move || {
while let ok(job) = receiver.lock().unwrap().recv() {
println!("worker {id} got a job; executing.");
job();
}
});
worker { id, thread }
}
}
这段代码可以编译和运行,但不会产生期望的线程行为:缓慢的请求仍然会导致其他请求等待处理。原因有些微妙:mutex 没有公共解锁方法,因为锁的所有权是基于锁方法返回的 lockresult<mutexguard<t>> 中的 mutexguard<t> 的生命周期。在编译时,借用检查器可以强制执行由互斥锁保护的资源不能被访问的规则,除非我们持有该锁。但是,如果我们不注意 mutexguard<t>的生命周期,这种实现也会导致锁被持有的时间比预期的要长。
之前的代码使用 let job = receiver.lock().unwrap().recv().unwrap(); 之所以有效,是因为使用 let 时,在等号右侧的表达式中使用的任何临时值都会在 let 语句结束时立即删除。然而,while let(以及 if let 和 match)在相关块结束之前不会删除临时值。在使用 while let 的代码中,锁在调用 job() 期间保持持有,这意味着其他 worker 实例不能接收作业。
正常关机和清理
接下来,我们将实现 drop trait,在池中的每个线程上调用 join,这样它们就可以在关闭之前完成正在处理的请求。然后我们将实现一种方法来告诉线程它们应该停止接受新请求并关闭。要查看这段代码的实际效果,我们将修改服务器,使其在优雅地关闭线程池之前只接受两个请求。
在 threadpool 上实现d rop trait
让我们从在线程池上实现 drop 开始。当池被删除时,我们的线程都应该连接起来,以确保它们完成自己的工作。
impl drop for threadpool {
fn drop(&mut self) {
for worker in &mut self.workers {
println!("shutting down worker {}", worker.id);
worker.thread.join().unwrap();
}
}
}
我们循环遍历线程池的每个 worker。我们使用 &mut 是因为 self 是一个可变引用,而且我们还需要能够改变 worker。对于每个 worker,我们打印一条消息,表示这个特定的 worker 实例正在关闭,然后我们在该 worker 实例的线程上调用 join。如果 join 调用失败,我们使用 unwrap 使 rust 陷入 panic,并进入不正常的关闭状态。
然而,程序并不能成功编译:
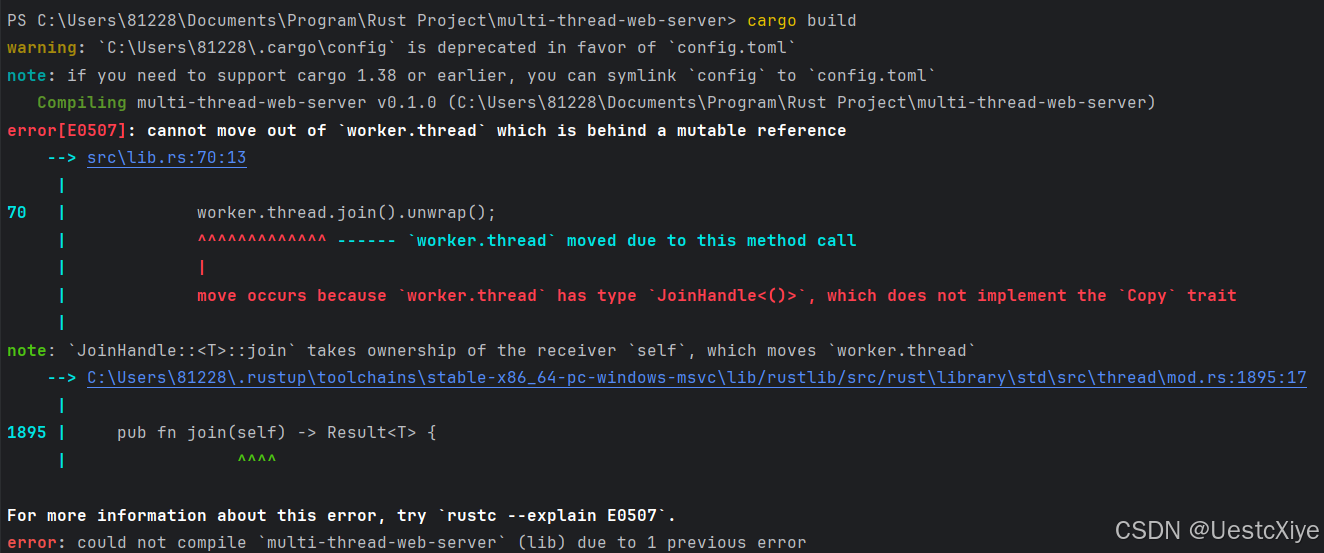
这个错误告诉我们不能调用 join,因为我们只有每个 worker 的可变借用,join 拥有其参数的所有权。为了解决这个问题,我们需要将线程移出拥有线程的 worker 实例,以便 join 可以使用线程。
一种解决方法是使用 option。如果 worker 持有 option<thread::joinhandle<()>>,我们可以调用 optio n的 take 方法将值从 some 变体中移出,并在其位置留下 none 变体。换句话说,正在运行的 worker 在线程中会有一个 some 变量,当我们想要清理 worker 时,我们将 some 替换为 none,这样 worker 就不会有线程要运行了。
然而,只有在丢弃 worker 时才会出现这种情况。使用 option 之后,我们必须在访问 worker.thread 的任何地方处理 option<thread::joinhandle<()>>,这很繁琐。
在这种情况下,存在一个更好的替代方法:vec::drain 方法。它接受一个 range 参数来指定要从vec中删除哪些项,并返回这些项的迭代器。传递 .. 将从 vec 中删除所有值。
所以我们需要像这样更新 threadpool 的 drop 实现:
impl drop for threadpool {
fn drop(&mut self) {
for worker in self.workers.drain(..) {
println!("shutting down worker {}", worker.id);
worker.thread.join().unwrap();
}
}
}
这将解决编译器错误,并且不需要对代码进行任何其他更改。
向线程发出停止监听作业的信号
程序还没有按照我们想要的方式运行。关键是由 worker 实例的线程运行的闭包中的逻辑:目前,我们调用 join,但这不会关闭线程,因为它们永远在循环寻找作业。如果我们尝试使用当前的 drop 实现来删除 threadpool,主线程将永远阻塞,等待第一个线程完成。
为了解决这个问题,我们需要改变 threadpool drop 的实现,在等待线程完成之前显式地删除 sender。然后再改变 worker 中的 loop。
pub struct threadpool {
workers: vec<worker>,
sender: option<mpsc::sender<job>>,
}
// --snip--
impl threadpool {
pub fn new(size: usize) -> threadpool {
// --snip--
threadpool {
workers,
sender: some(sender),
}
}
pub fn execute<f>(&self, f: f)
where
f: fnonce() + send + 'static,
{
let job = box::new(f);
self.sender.as_ref().unwrap().send(job).unwrap();
}
}
impl drop for threadpool {
fn drop(&mut self) {
drop(self.sender.take());
for worker in self.workers.drain(..) {
println!("shutting down worker {}", worker.id);
worker.thread.join().unwrap();
}
}
}
与线程不同,这里我们需要使用 option::take 来将 sender 移出 threadpool。
删除 sender 将关闭通道,这表明将不再发送消息。当这种情况发生时, worker 实例在 loop 中对 recv 的所有调用都会返回一个错误。在这种情况下,我们应该优雅地退出循环,这意味着线程将在 threadpool drop 实现调用 join 时结束。
impl worker {
fn new(id: usize, receiver: arc<mutex<mpsc::receiver<job>>>) -> worker {
let thread = thread::spawn(move || {
loop {
let message = receiver.lock().unwrap().recv();
match message {
ok(job) => {
println!("worker {id} got a job; executing.");
job();
}
err(_) => {
println!("worker {id} disconnected; shutting down.");
break;
}
}
}
});
worker { id, thread }
}
}
要查看这段代码的实际效果,让我们修改 main 函数,使其在优雅地关闭服务器之前只接受两个请求。
fn main() {
let listener = tcplistener::bind("127.0.0.1:7878").unwrap();
let pool = threadpool::new(4);
for stream in listener.incoming().take(2) {
let stream = stream.unwrap();
pool.execute(|| {
handle_connection(stream);
});
}
println!("shutting down.");
}
take 方法是在 iterator trait 中定义的,它将迭代最多限制在前两项。 threadpool 将在 main 函数结束时超出作用域,并运行 drop实现。
启动装载运行的服务器,并发出三个请求。第三个请求应该出错,程序输出为:
worker 0 got a job; executing. shutting down. worker 1 got a job; executing. shutting down worker 0 worker 3 disconnected; shutting down. worker 2 disconnected; shutting down. worker 0 disconnected; shutting down. shutting down worker 1 worker 1 disconnected; shutting down. shutting down worker 2 shutting down worker 3
打印的 worker id 和消息可能有不同顺序。我们可以从消息中看到这段代码是如何工作的:worker 实例 0 和 1 获得了前两个请求。服务器在第二个连接之后停止接受连接,线程池上的 drop 实现甚至在 worker 1 开始它的工作之前就开始执行。删除发送器将断开所有 worker 实例的连接,并告诉它们关闭。每个 worker 实例在断开连接时打印一条消息,然后线程池调用 join 来等待每个 worker 线程完成。
注意这个特殊执行的一个有趣的方面:threadpool 丢弃了 sender,并且在任何 worker 接收到错误之前,我们尝试加入 worker 0。工作线程 0 还没有从 recv 获得错误,所以主线程阻塞等待工作线程 0 完成。同时,worker 1 收到了一个作业,然后所有线程都收到了一个错误。当 worker 0 完成时,主线程等待其余的 worker 实例完成。在这一点上,他们都退出了循环,停止了。
我们现在已经完成了我们的项目;我们有一个基本的 web 服务器,它使用线程池进行异步响应。我们能够执行服务器的优雅关闭,这将清理池中的所有线程。
项目地址
github:uestcxiye / multi-thread-web-server-based-on-rust
到此这篇关于rust中多线程 web 服务器的项目实战的文章就介绍到这了,更多相关rust 多线程web服务器内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!
赞 (0)
您想发表意见!!点此发布评论





发表评论