阿里云日志服务SLS:从海量乱序日志中“揪”出恶意攻击来源
366人参与 • 2025-07-06 • 阿里
系列引言
阿里云日志服务(sls)为客户提供云上海量日志数据的存储、查询和分析服务,用户在 sls 上的使用场景千变万化,但最终殊途同归,都是为自身业务所服务。基于 sls sql 的数据分析能力,用户可以从任意结构(无论是数值,还是 json,亦或无结构的文本)的海量日志数据中提取出有效信息,以支撑业务运维、运营、洞察、决策。
一直以来,我们强调 sql 的基础通用能力、高性能、低成本,却较少分享用户使用 sls 服务在最终业务上面的落地。事实上,用户在我们的基础能力之上,开展了各式各样的业务,产生了非常多的奇思妙想和经典解决方案,这些是真正业务价值的体现,我们希望通过本系列,以“用户故事”的方式分享用户遇到的问题、解决思路、实践落地等,我们相信这些真实的用户故事和经验,同样会是许多用户正在经历和思索的,期待给读者带来启发、引起共鸣、互学互鉴。
本系列将以轻松愉悦的方式带给读者不一样的阅读体验,每篇故事简短轻量,风格活泼,阅读时间将不超过 5 分钟,请各位看官放心阅读。
系列第一篇,我们讲述一个大型平台客户被恶意攻击的溯源分析案例。
“糟糕,我们被恶意攻击了...”
某天,中午时分,客户线上遭受大规模流量攻击,大量来自全球各地的 ip 持续大规模访问服务,导致服务负载陡升,影响到了正常用户的服务请求。
业务部门紧急电话联系运维负责人,希望能够找出攻击来源,并进行紧急封禁处理。
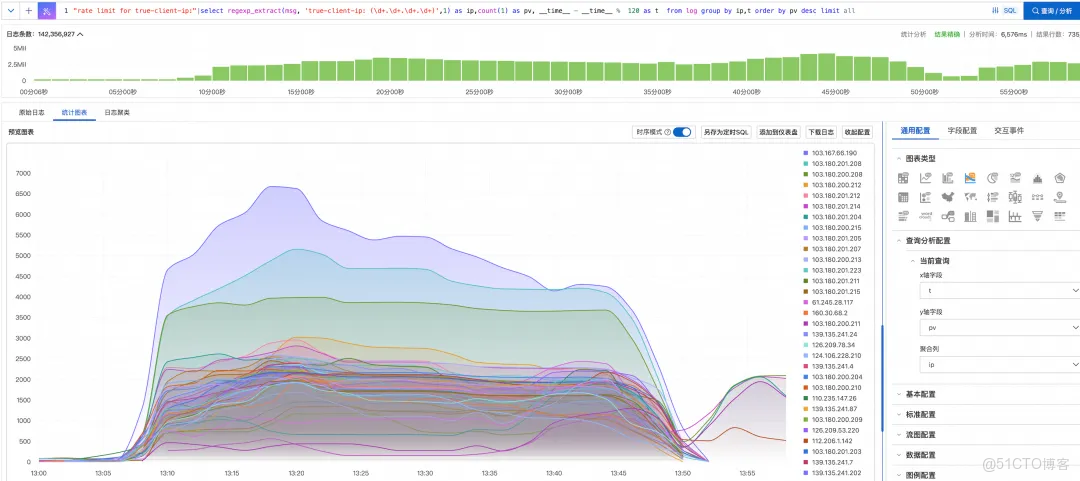
检索并找出高频访问 ip
幸运的是,访问日志中记录了“高频”行为:短时间内超过 n 次访问会记录如下特征日志:...rate limit for true-client-ip: 139.135.241.87 trace_id: ... 。
利用 sls 查询检索能力,根据关键词可以快速从海量访问日志中检索出高频特征数据。
"rate limit for true-client-ip"

ok,接下来对这些特征数据使用 sql 按 ip 分组聚合,统计最高频 ip 就搞定了!
但是,等等~
这个日志是一个无结构化的纯文本数据(只有一个大段的 msg 字段),我们并没有建立 ip 列,又怎么统计分析最高频的 ip 呢?
没问题!sls sql 提供了灵活的无结构化数据提取能力,利用正则提取函数 regexp_extract,可以轻松从 msg 字段的海量数据中根据日志 pattern 提取出 ip 列,同时对提取出的 ip 列按每 2 分钟为粒度分组聚合,统计分析出时间区间内最高频的访问 ip。
"rate limit for true-client-ip:" | select regexp_extract(msg, 'true-client-ip: (\d+.\d+.\d+.\d+)', 1) as ip, count(1) as pv, __time__-time % 120 as t from log group by ip, t order by pv desc limit all
关联分析恶意账号
果然,在此时间段,存在大量的高频访问 ip,但高频访问 ip 的量实在太多了,黑客可能从全球各地使用“肉鸡”进行 ddos 攻击,业务方很难根据这么大量的 ip 进行封禁控制,何况攻击 ip 还在实时变化中~
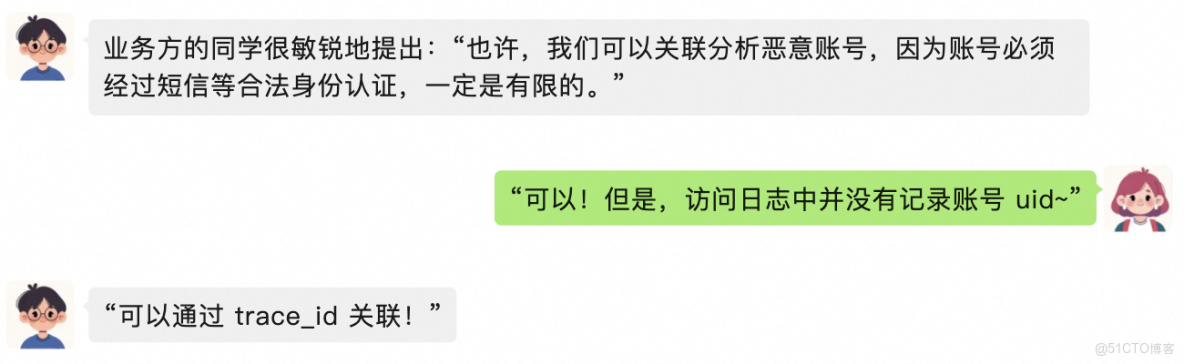
[10/may/2025:12:55:31 +0800] player.getsmscode received "uid":nbngq01wrwiosvci2y/huw== "trace_id":7b3d9f2a-418a-4b4e-9c52-a60c1f3e8b45 [10/may/2025:13:55:36 +0800] "get /index.html http/1.1" 200 432 "-" "mozilla/5.0 (windows nt 10.0; win64; x64) applewebkit/537.36 (khtml, like gecko) chrome/123.0.0.0 safari/537.36" "rate limit for true-client-ip": 139.135.241.87 "trace_id": 7b3d9f2a-418a-4b4e-9c52-a60c1f3e8b45
用户的访问日志库存放了大量的异构日志,有短信接收日志(记录了账号 uid、trace_id 等信息),也有上述高频访问日志,还有其他常规访问日志数据等等。
基于这些事实数据(哪怕它们很乱),利用 sls 强大的查询和分析能力,我们就可以实现数据关联分析了。
* | select
date_trunc('minute', __time__) t,
uuid,
count(1) cnt,
array_agg(distinct ip) ip
from (
select __time__, regexp_extract(msg, '"true-client-ip": (\d+.\d+.\d+.\d+)', 1) as ip, trace_id from log where msg has '"rate limit for true-client-ip": '
) t1
left join (
select trace_id, regexp_extract(msg, '"uid":"([^"]*)"', 1) uuid from log where msg has 'player.getsmscode'and msg has 'received'
) t2
on t1.trace_id = t2.trace_id
group by t, t2.uuid
having cnt > 100
order by cnt desc虽然,这可能稍微有点高阶,稍微解释一下:
- 我们使用了两个子查询,分别提取出高频访问的 ip 和 trace_id,以及账号登录接收短信的 uid 和 trace_id。
- 在子查询中我们高效检索出特征数据(使用
where msg has 'xxx'可以高效利用索引过滤出有效数据)。 - 利用 sql join 将左右子表以 trace_id 进行关联。
- 同时,我们对 uid 分组聚合,并过滤出单分钟内访问频次超过 100 次的高频账号(疑似恶意攻击账号)。
- 最后,我们利用聚合函数
array_agg(distinct ip)汇聚列出每分钟每个疑似账户的攻击 ip 列表。
但是,非常高效,我们仅通过一次分析,便将所有可疑账户和 ip 来源分析出来了。
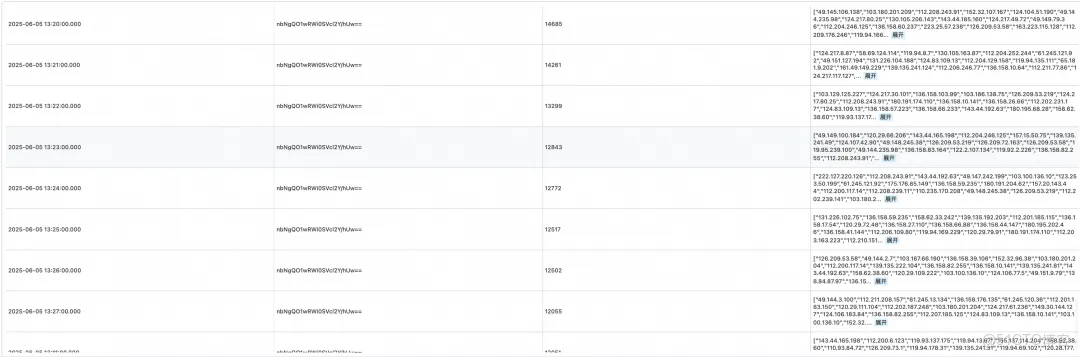
截图展示数据仅为示意数据
地理信息溯源
更进一步,我们还可以利用 sls 的 ip 地理位置函数分析确定 ip 来源。
sql 中只需要将 array_agg(distinct ip) 改为 array_agg(distinct ip_to_country(ip)) 即可。
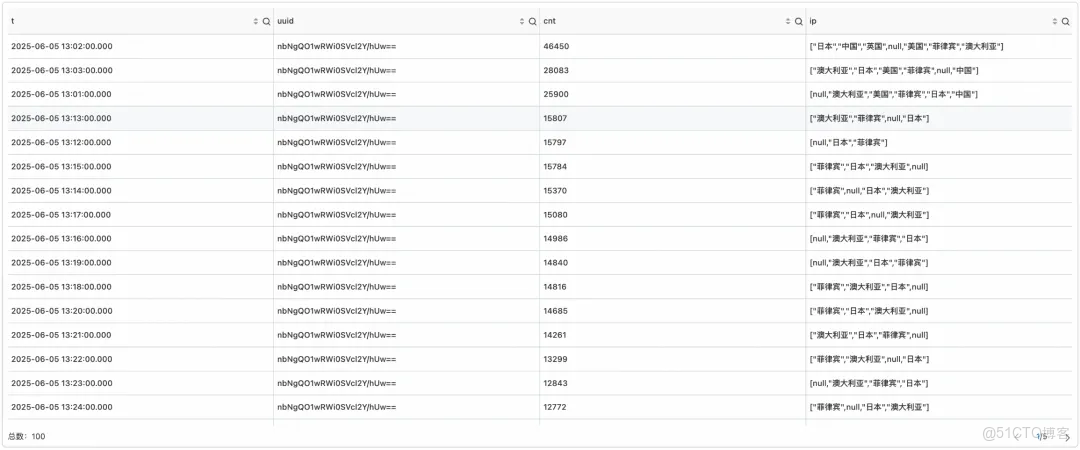
截图展示数据仅为示意数据
最终,经过业务部门核对,以上分析准确溯源了恶意账号和 ip 来源,并且恶意账号只有一个,交由风控部门进行紧急封禁控制,有效阻止了持续的恶意攻击。
多云联动
拿到以上异常 ip 后,就可以配置防火墙封堵策略,结果又遇到了以下问题:
- ip 误封:异常 ip 很多,来不及审查,办公室 ip/关联方 ip 也在里面。狠起来,我们自己人都不放过。
- 频繁攻击:黑客一个定时脚本半夜攻击。业务运维人员半夜起床搬砖,头发掉得一把一把的。
在这个友方和头发保卫战中,提出了一个自动化封堵方案。
客户的服务是多云部署(同时在 aws、阿里云部署)的,有了这次的成功经验,运维负责人进一步发挥,通过自动化方案,定期从 sls 进行查询分析,同步更新到阿里云和 aws 的 waf 服务中,攻击账号和 ip 来源存储 3 天,过期释放,从而实现了真实业务恶意攻击的自主分析和防控能力。
整体方案核心逻辑如下
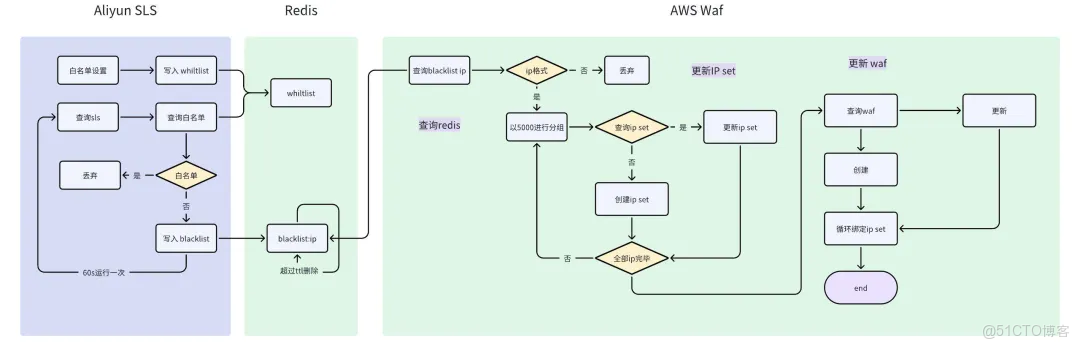
分为两部分:sls 异常 ip 自动检测和 aws waf 动态更新 ip 策略。利用 redis 实现 ip 数据的生命周期管理,借助 redis ttl 功能,可以更轻松实现 ip 数据的定时释放(判刑也有时限,黑名单用户同样如此)。
sls 异常 ip 自动检测
这里基于阿里云 sls 提供的 python sdk 来实现定时查询和结果处理,sdk 已经提供了完善的 sls 操作方法,文档也丰富,可以快速完成对应功能的实现。其核心处理代码如下:
def get_logs_from_sls():
# 查询阿里云sls记录中有可能是攻击的ip sql 拼接
query = "\"rate limit for true-client-ip:\"|select " + \
" ..... + \ #此处省略n个重要的sql拼接部分
" limit all "
...
# 通过sql查询日志。
request = getlogsrequest(project_name, logstore_name, from_time, to_time, query=query)
response = client.get_logs(request)
#日志处理为json格式
logs_data={}
for log in response.get_logs():
ip = none
...
if ip and cnt:
#判断是否为 办公室 / 合作方 ip
if not is_in_whitelist(ip):
logs_data[ip]=int(cnt)
else:
continue
return logs_data整体程序主要步骤如下:
- 利用 sls 查询分析出高频访问 ip
- 基于白名单去重,生成最终的异常 ip 清单,供后续使用。
aws waf 动态更新 ip 策略
aws waf(web application firewall)是 amazon web services 提供的一种托管型 web 应用防火墙服务,用于保护 web 应用程序免受常见的网络攻击。该设置步骤需要两部分内容:
- ip sets:用于定义封堵/允许的 ip 地址池,单个设置上限为 1 万条。
- web acls:waf 主要配置策略,引用 ip sets 中的地址池并设置对应的访问策略(运行/拒绝)
此处,采用 aws 提供的 python sdk boto3 来进行 waf 相关的更新与创建。核心操作代码如下:
# 创建 web acl
def create_web_acl(waf_acl_name, waf_rules):
try:
response = waf_client.create_web_acl(
name=waf_acl_name, # web acl 的名称
scope=region_scope, # 适用于 regional 或 cloudfront
defaultaction={
'allow': {} # 默认操作:拒绝流量
},
rules=waf_rules,
visibilityconfig={
'sampledrequestsenabled': true,
'cloudwatchmetricsenabled': true,
'metricname': waf_acl_name+'aclmetric'
}
)
return response['summary']['id']
except clienterror as e:
mylog("error",f"error creating web acl: {e}")
return none其中变量“waf_rules”定义的就是阻挡策略,以下是一个具体配置示例,其中 arn 就是关联 ip sets 与 web acl 的关键:
{
"name": "blacklist_ip_sets_1",
"priority": 101,
"action": {
"block": {}
},
"visibilityconfig": {
"sampledrequestsenabled": true,
"cloudwatchmetricsenabled": true,
"metricname": "blacklist_ip_sets_1_metric"
},
"statement": {
"ipsetreferencestatement": {
"arn": "arn:aws:****0f"
}
}
}整体更新流程需要操作的内容如下:
- 从 redis 读取 ip 数据集,处理成 ip 格式:“192.168.1.100/32”,并以 5000(上限为 1 万)进行分组。
- 对于分组后的数据,创建 / 更新 对应的 ip sets 信息。
- 记录创建/更新的 ip sets 的 name,arn 信息,提供后续使用。
- 读取现有 web acls 配置,记录历史 rule 信息,只更新自动创建的策略。
创建后的效果展示:
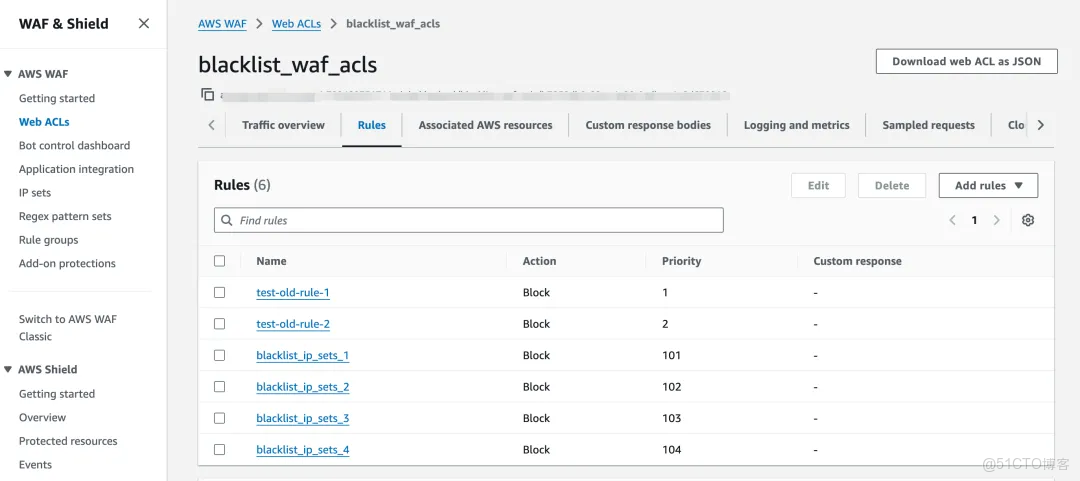
通过以上操作,再配置上对应的运行环境,定时任务就可以实现异常 ip 自动获取与 waf 更新,非常完美。
01 客户反馈
sls 是真的好用,关键时刻确实顶,接下来需要好好学习 sql,把价值发挥起来!
02 技术关键词
异构数据特征提取、regexp_extract、ip_to_country、单表自 join。
结语
本文讲述了一个大型平台客户被恶意攻击的溯源分析案例,结合多种异构的访问日志数据源,利用关键词检索、正则提取、join 关联分析、地理位置函数等溯源到恶意攻击来源,并有效进行了安全防控。不管是什么样的数据,在阿里云日志服务 sls 中,利用高性能的查询检索和灵活易用的分析能力,都可以实现任意且灵活的业务分析、安全审计、风险预估,帮助客户在关键时刻快速定位问题、锁定目标、消除风险。
到此这篇关于阿里云日志服务sls:从海量乱序日志中“揪”出恶意攻击来源的文章就介绍到这了,更多相关阿里云日志服务sls:日志中找出攻击源内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!
赞 (0)
您想发表意见!!点此发布评论





发表评论