PyCharm报错AttributeError: ‘NoneType‘ object has no attribute ‘find_all‘问题的原因分析及解决方案
193人参与 • 2025-07-18 • Pycharm
一、摘要
在使用 beautifulsoup 解析网页时,attributeerror: 'nonetype' object has no attribute 'find_all' 是一个十分常见却又让人头疼的错误。本篇博客将从开发场景与技术细节出发,全面剖析该异常的多种成因,并给出从入门到进阶的 15+ 种解决方案,帮助你彻底搞定 find_all 相关的 nonetype 问题。
二、开发环境
- 操作系统:macos
- python 版本:3.10.x / 3.11.x
- ide:pycharm 2025
- 解析库:beautifulsoup4 >= 4.11.1
- http 请求:requests >= 2.28.1
三、异常场景及技术细节
在执行如下代码时:
from bs4 import beautifulsoup
import requests
resp = requests.get("https://example.com")
soup = beautifulsoup(resp.text, "html.parser")
items = soup.find("div", class_="item-list").find_all("li")
如果页面结构与预期不符(例如 .item-list 不存在),soup.find(...) 返回 none,随之调用 .find_all 时就会抛出:
attributeerror: 'nonetype' object has no attribute 'find_all'
技术上,该异常表明对 none(空值)进行了成员方法调用。根本原因即上一层查找未命中或返回了错误类型。
四、核心排查思路与解决方案
4.1 检查选择器是否正确
css 语法、类名大小写:确认 html 结构与选择器一致
示例:
tag = soup.select_one("div.item-list")
if not tag:
raise valueerror("页面未包含 .item-list 节点")
items = tag.find_all("li")
4.2 网络请求与响应状态
有时请求被重定向、拦截或返回 404,导致 resp.text 中无预期内容。
if resp.status_code != 200:
print(f"请求失败:http {resp.status_code}")
resp.raise_for_status()
4.3 不同解析器差异
html.parser vs lxml vs html5lib
更换解析器重试:
beautifulsoup(resp.text, "lxml")
4.4 加强 none 检查与容错
container = soup.find("div", id="main-container")
if container is none:
# 打印日志或抛出自定义异常
print("未找到 #main-container,检查页面结构")
else:
elements = container.find_all("p")
五、进阶排查流程
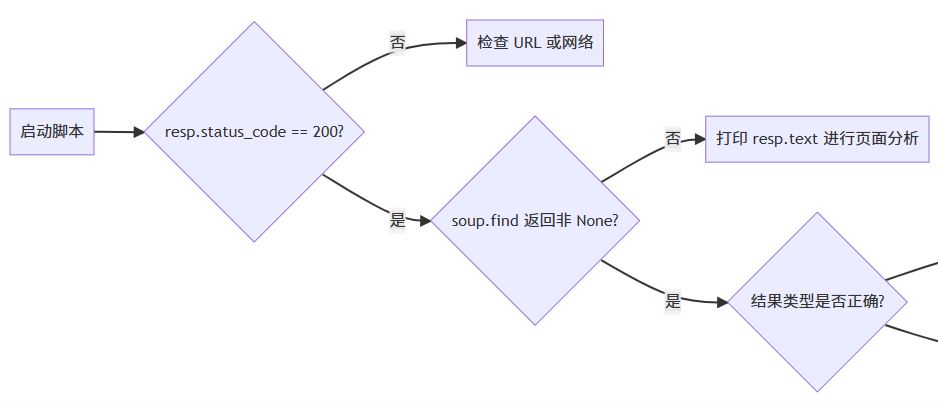
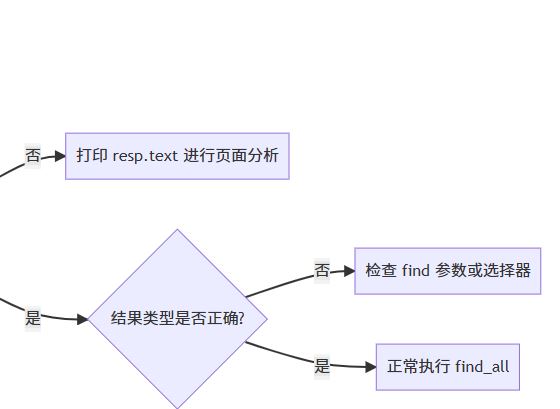
六、常见场景与对策总结
| 场景 | 原因与对策 |
|---|---|
| 找不到标签 | ① 选择器不对 ② 页面脚本动态渲染,用 selenium 或 api |
| none 直接链式调用 | 加入 if tag is none 检查 |
| 请求被拦截或返回 404/302 | 检查 resp.status_code,设置合适的 headers |
| 使用默认解析器解析失败 | 换用 lxml 或 html5lib |
| 页面内容通过 javascript 动态加载 | 使用 selenium、playwright 或抓包 api |
| 目标节点深度嵌套,忘记逐级查找 | 分步打印中间结果,定位哪一级返回 none |
七、小贴士
“最好的解析器不是代码,而是对页面结构的深入理解。”
遇到类似问题时,先不要惊慌,按以上思路逐层排查,往往能在 5 分钟内搞定。
以上就是pycharm报错attributeerror: ‘nonetype‘ object has no attribute ‘find_all‘问题的原因分析及解决方案的详细内容,更多关于pycharm attributeerror nonetype的资料请关注代码网其它相关文章!
赞 (0)
您想发表意见!!点此发布评论


发表评论