Oracle 11g数据库常用对象创建与管理方法详解
75人参与 • 2025-11-05 • Oracle
引言
在oracle数据库的浩瀚世界里,数据本身固然重要,但如何高效地组织、访问和管理这些数据,才是发挥其强大威力的关键。这一切都离不开数据库对象。无论是初入行的dba还是后端开发人员,熟练掌握oracle常用对象的创建与管理都是一项核心技能。
本文将带您系统地了解oracle 11g中几种最常用的数据库对象,包括表、视图、序列、索引和同义词。我们将通过清晰的语法示例和实用的管理技巧,助您夯实基础,提升数据库操作能力。
一、表(table):数据的基石
表是数据库中存储数据的基本单位,由行和列组成。设计良好的表结构是高效数据库系统的前提。
1. 创建表
使用 create table 语句,你需要定义列名、数据类型和约束。
create table employees (
employee_id number(6) primary key,
first_name varchar2(20),
last_name varchar2(25) not null,
email varchar2(25) not null unique,
hire_date date default sysdate not null,
salary number(8,2),
department_id number(4),
-- 定义外键约束,关联到部门表
constraint fk_dept_id
foreign key (department_id)
references departments(department_id)
);关键点:
数据类型:
number,varchar2,date,clob,blob等。约束:
primary key,foreign key,not null,unique,check。约束保证了数据的完整性和一致性。
2. 管理表
修改表(alter table): 用于添加、修改或删除列,以及添加或删除约束。
-- 添加新列 alter table employees add (phone_number varchar2(15)); -- 修改列数据类型 alter table employees modify (salary number(9,2)); -- 删除列 alter table employees drop column phone_number; -- 添加约束 alter table employees add constraint chk_salary check (salary > 0);
- 删除表(drop table):
drop table employees; -- 谨慎使用!会删除表结构和所有数据。 drop table employees cascade constraints; -- 同时删除与之相关的引用完整性约束
- 重命名表(rename):
rename employees to emp_backup;
- 截断表(truncate table): 快速删除表中所有数据,不可回滚,并释放表空间。
truncate table emp_backup;
二、视图(view):虚拟的逻辑窗口
视图是基于一个或多个表的查询结果集。它本身不存储数据,像一个预定义的查询窗口,简化了复杂查询,增强了数据安全性。
1. 创建视图
create or replace view vw_emp_dept as
select e.employee_id,
e.first_name || ' ' || e.last_name as full_name,
e.salary,
d.department_name
from employees e
join departments d on e.department_id = d.department_id
where e.salary > 10000;
2. 管理视图
查询视图: 像查询普通表一样。
select * from vw_emp_dept;
- 删除视图:
drop view vw_emp_dept;
优点:
简化操作: 将复杂的多表查询封装成一个简单的视图。
安全性: 可以只暴露视图中的特定列给用户,隐藏敏感数据。
逻辑独立性: 即使底层表结构发生变化,只需修改视图定义,而不影响应用程序。
三、序列(sequence):自动编号发生器
序列是一个数据库对象,用于生成唯一的、连续的整数编号,通常为主键字段提供值。
1. 创建序列
create sequence seq_emp_id increment by 1 -- 每次增加1 start with 1000 -- 从1000开始 nomaxvalue -- 无最大值(或 maxvalue 9999) nocycle -- 不循环 cache 20; -- 缓存20个序列值以提高性能
2. 使用序列
nextval: 获取序列的下一个值。currval: 获取序列的当前值(必须先使用nextval)。
insert into employees (employee_id, first_name, last_name, email) values (seq_emp_id.nextval, '张', '三', 'zhangsan@example.com'); select seq_emp_id.currval from dual;
3. 管理序列
-- 修改序列(不能修改start with,通常用于修改增量、缓存值等) alter sequence seq_emp_id increment by 2; -- 删除序列 drop sequence seq_emp_id;
四、索引(index):加速查询的引擎
索引是一种提高数据检索速度的数据库结构,类似于书的目录。
1. 创建索引
单列索引:
create index idx_emp_last_name on employees(last_name);
- 复合索引:
create index idx_emp_dept_salary on employees(department_id, salary desc);
- 唯一索引:(通常由unique或primary key约束自动创建,也可手动)
create unique index idx_emp_email on employees(email);
2. 管理索引
-- 重建索引(优化索引性能) alter index idx_emp_last_name rebuild; -- 删除索引 drop index idx_emp_last_name;
索引使用场景:
经常出现在
where、join、order by子句中的列。表的数据量很大。
注意事项:
索引会占用存储空间。
会降低
insert,update,delete数据的速度,因为索引也需要维护。
五,作业
1.views表:
| column name | type |
| article_id | int |
| author_id | int |
| viewer_id | int |
| view_date | data |
此表可能会存在重复行。(换句话说,在 sql 中这个表没有主键)
此表的每一行都表示某人在某天浏览了某位作者的某篇文章。
请注意,同一人的 author_id 和 viewer_id 是相同的。
请查询出所有浏览过自己文章的作者。
结果按照作者的 id 升序排列。
查询结果的格式如下所示:
输入:
-- 创建 views 表
create table views (
article_id int,
author_id int,
viewer_id int,
view_date date
);
-- 插入示例数据
insert into views (article_id, author_id, viewer_id, view_date) values (1, 3, 5, date '2019-08-01');
insert into views (article_id, author_id, viewer_id, view_date) values (1, 3, 6, date '2019-08-02');
insert into views (article_id, author_id, viewer_id, view_date) values (2, 7, 7, date '2019-08-01');
insert into views (article_id, author_id, viewer_id, view_date) values (2, 7, 6, date '2019-08-02');
insert into views (article_id, author_id, viewer_id, view_date) values (4, 7, 1, date '2019-07-22');
insert into views (article_id, author_id, viewer_id, view_date) values (3, 4, 4, date '2019-07-21');
insert into views (article_id, author_id, viewer_id, view_date) values (3, 4, 4, date '2019-07-21');
-- 查询验证
select * from views;输入结果:
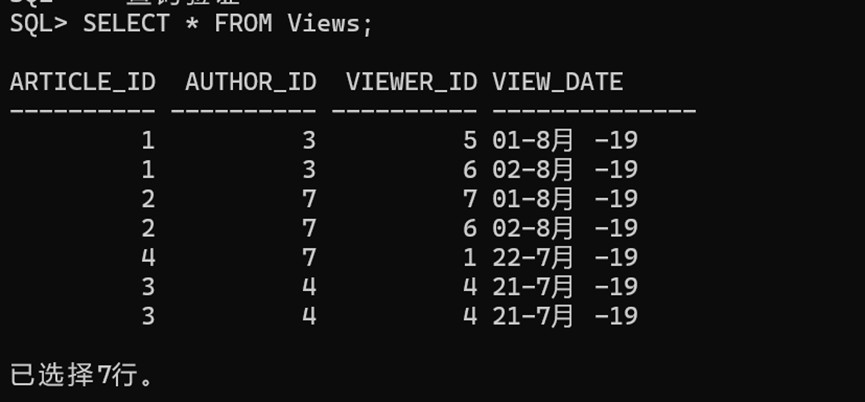
输出:
select distinct author_id as id from views where author_id = viewer_id order by author_id;
输出结果:
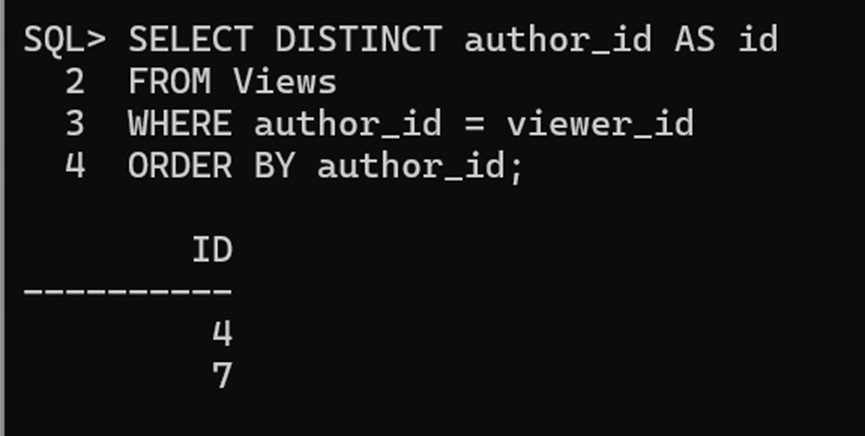
2、表:tweets
| column name | type |
| tweet_id | int |
| content | varchar |
在 sql 中,tweet_id 是这个表的主键。
content 只包含字母数字字符,'!',' ',不包含其它特殊字符。
这个表包含某社交媒体 app 中所有的推文。
查询所有无效推文的编号(id)。当推文内容中的字符数严格大于 15 时,该推文是无效的。
以任意顺序返回结果表。
查询结果格式如下所示:
输入:
-- 创建 tweets 表
create table tweets (
tweet_id int primary key,
content varchar2(4000)
);
-- 插入示例数据
insert into tweets (tweet_id, content) values (1, 'vote for biden');
insert into tweets (tweet_id, content) values (2, 'let us make america great again!');
-- 查询验证
select * from tweets;输入结果:
输出:
select tweet_id from tweets where length(content) > 15;
输出结果:
3、表:visits
| column name | type |
| visit_id | int |
| customer_id | int |
visit_id 是该表中具有唯一值的列。
该表包含有关光临过购物中心的顾客的信息
| column name | type |
| transaction_id | int |
| visit_id | int |
| amount | int |
transaction_id 是该表中具有唯一值的列。
此表包含 visit_id 期间进行的交易的信息。
有一些顾客可能光顾了购物中心但没有进行交易。请你编写一个解决方案,来查找这些顾客的 id ,以及他们只光顾不交易的次数。
返回以 任何顺序 排序的结果表。
返回结果格式如下例所示。
输入:
-- 创建 visits 表
create table visits (
visit_id int primary key,
customer_id int
);
-- 创建 transactions 表
create table transactions (
transaction_id int primary key,
visit_id int,
amount int
);
-- 插入 visits 示例数据
insert into visits (visit_id, customer_id) values (1, 23);
insert into visits (visit_id, customer_id) values (2, 9);
insert into visits (visit_id, customer_id) values (4, 30);
insert into visits (visit_id, customer_id) values (5, 54);
insert into visits (visit_id, customer_id) values (6, 96);
insert into visits (visit_id, customer_id) values (7, 54);
insert into visits (visit_id, customer_id) values (8, 54);
-- 插入 transactions 示例数据
insert into transactions (transaction_id, visit_id, amount) values (2, 5, 310);
insert into transactions (transaction_id, visit_id, amount) values (3, 5, 300);
insert into transactions (transaction_id, visit_id, amount) values (9, 5, 200);
insert into transactions (transaction_id, visit_id, amount) values (12, 1, 910);
insert into transactions (transaction_id, visit_id, amount) values (13, 2, 970);
-- 查询验证
select * from visits;
select * from transactions;输入结果:
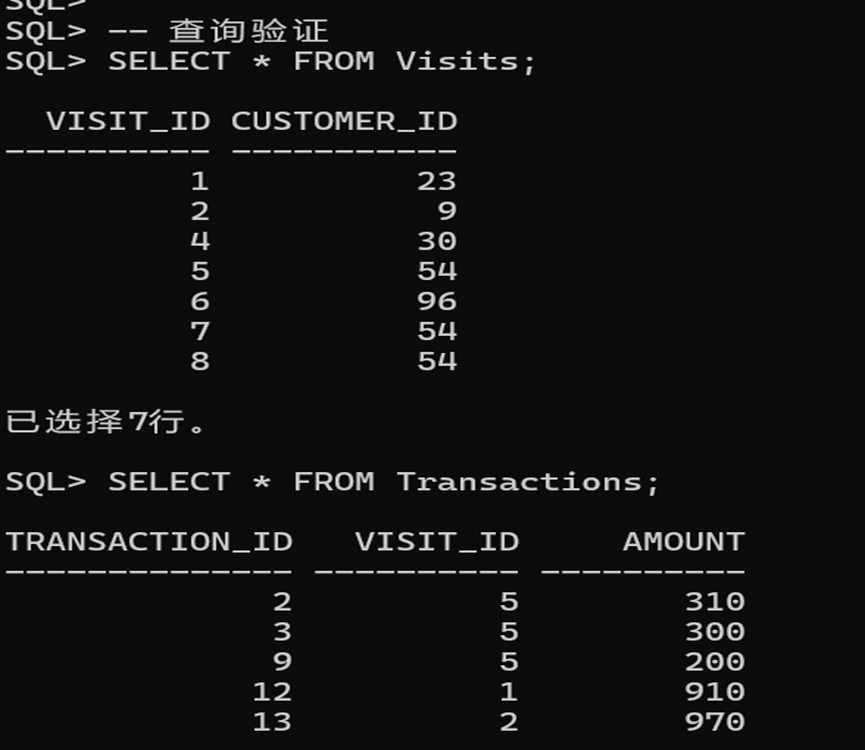
输出:
select v.customer_id, count(*) as count_no_trans from visits v left join transactions t on v.visit_id = t.visit_id where t.transaction_id is null group by v.customer_id order by count_no_trans desc, v.customer_id;
输出结果:
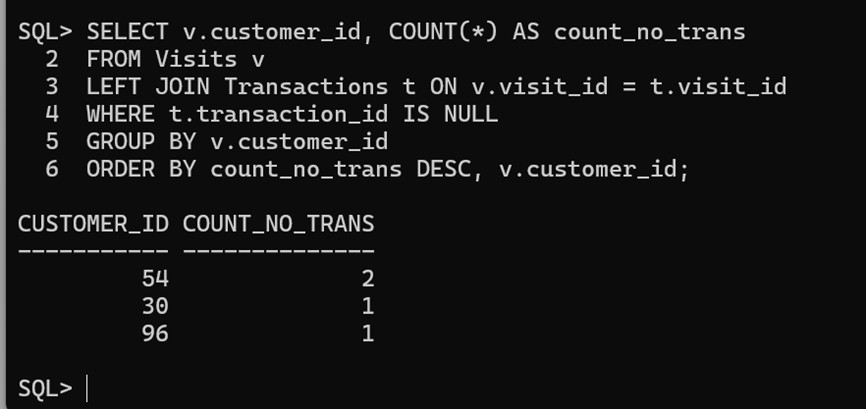
总结
到此这篇关于oracle 11g数据库常用对象创建与管理方法详解的文章就介绍到这了,更多相关oracle 11g对象创建与管理内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!
赞 (0)
您想发表意见!!点此发布评论






发表评论