PyTorch基于MNIST的手写数字识别
140人参与 • 2026-01-19 • Pycharm
1. 深度学习与pytorch简介
深度学习作为机器学习的重要分支,已在计算机视觉、自然语言处理等领域取得了显著成果。pytorch是由facebook开源的深度学习框架,以其动态计算图和直观的api设计而广受欢迎。本文以经典的mnist手写数字数据集为例,展示如何利用pytorch框架构建并训练深度学习模型。
2. 环境配置与数据准备
2.1 环境检查
首先检查pytorch及相关库的版本,确保环境配置正确:
import torch import torchvision import torchaudio from torch import nn from torch.utils.data import dataloader from torchvision import datasets from torchvision.transforms import totensor from matplotlib import pyplot as plt print(torch.__version__) print(torchaudio.__version__) print(torchvision.__version__)
2.2 数据加载与预处理
mnist数据集包含60,000个训练样本和10,000个测试样本,每个样本为28×28像素的灰度手写数字图像。
training_data = datasets.mnist(
root="data",
train=true,
download=true,
transform=totensor(),
)
test_data = datasets.mnist(
root="data",
train=false,
download=true,
transform=totensor(),
)
参数:
root:数据存储路径train:是否为训练集download:是否自动下载transform:数据预处理转换,totensor()将pil图像转换为张量并归一化到[0,1]
2.3 数据可视化
我们可以查看数据集的样本分布:
print(len(training_data))
figure = plt.figure()
for i in range(9):
img, label = training_data[i + 59000]
figure.add_subplot(3, 3, i + 1)
plt.title(label)
plt.axis("off")
plt.imshow(img.squeeze(), cmap="gray")
plt.show()

2.4 数据批量加载
使用dataloader实现数据的批量加载和随机打乱:
# 增加批次大小
train_dataloader = dataloader(training_data, batch_size=128) # 增大batch size
test_dataloader = dataloader(test_data, batch_size=128)
for x, y in test_dataloader:
print(f"shape of x[n,c,h,w]:{x.shape}")
print(f"shape of y:{y.shape} {y.dtype}")
break

3. 神经网络模型设计
3.1 设备选择
根据可用硬件选择计算设备:
device = "cuda" if torch.cuda.is_available() else "mps" if torch.backends.mps.is_available() else "cpu"
print(f"using {device} device")

3.2 神经网络架构
设计一个包含多个全连接层的深度神经网络:
class neuralnetwork(nn.module):
def __init__(self):
super().__init__()
self.a = 10
self.flatten = nn.flatten()
原始架构
self.hidden1 = nn.linear(28 * 28, 128)
self.hidden2 = nn.linear(128, 256)
self.out = nn.linear(256, 10)
def forward(self, x):
# 原始前向传播
x = self.flatten(x)
x = self.hidden1(x)
x = torch.sigmoid(x)
x = self.hidden2(x)
x = torch.sigmoid(x)
return x
3.3 模型实例化
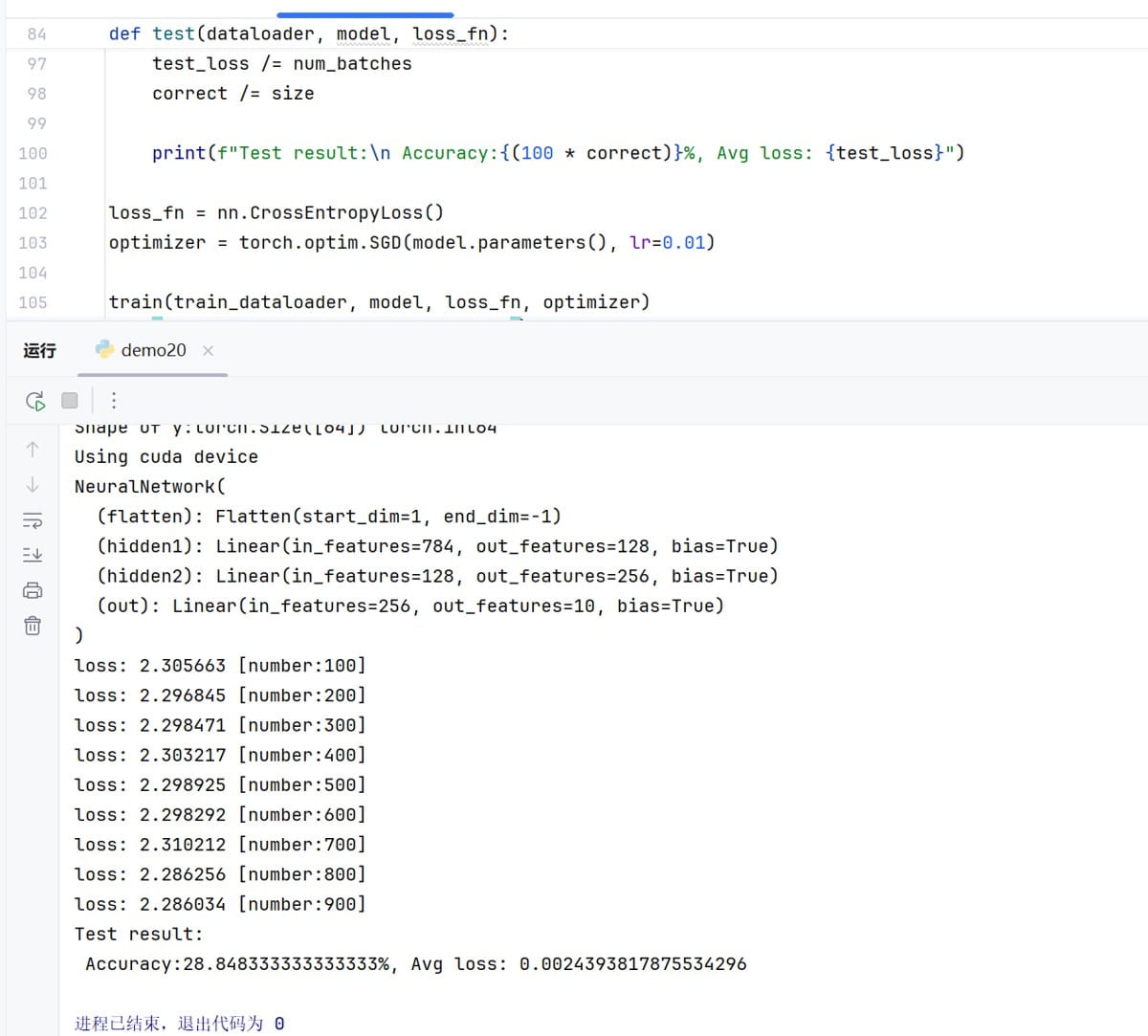
model = neuralnetwork().to(device) print(model)
4. 训练与评估流程
4.1 训练函数
def train(dataloader, model, loss_fn, optimizer):
model.train()
batch_size_num = 1
for x, y in dataloader:
x, y = x.to(device), y.to(device)
pred = model.forward(x)
loss = loss_fn(pred, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
loss_value = loss.item()
if batch_size_num % 100 == 0:
print(f"loss: {loss_value:>7f} [number:{batch_size_num}]")
batch_size_num += 1
训练步骤:
model.train():设置为训练模式(启用dropout)- 前向传播计算预测值
- 计算损失函数值
optimizer.zero_grad():清空梯度loss.backward():反向传播计算梯度optimizer.step():更新模型参数
4.2 测试函数
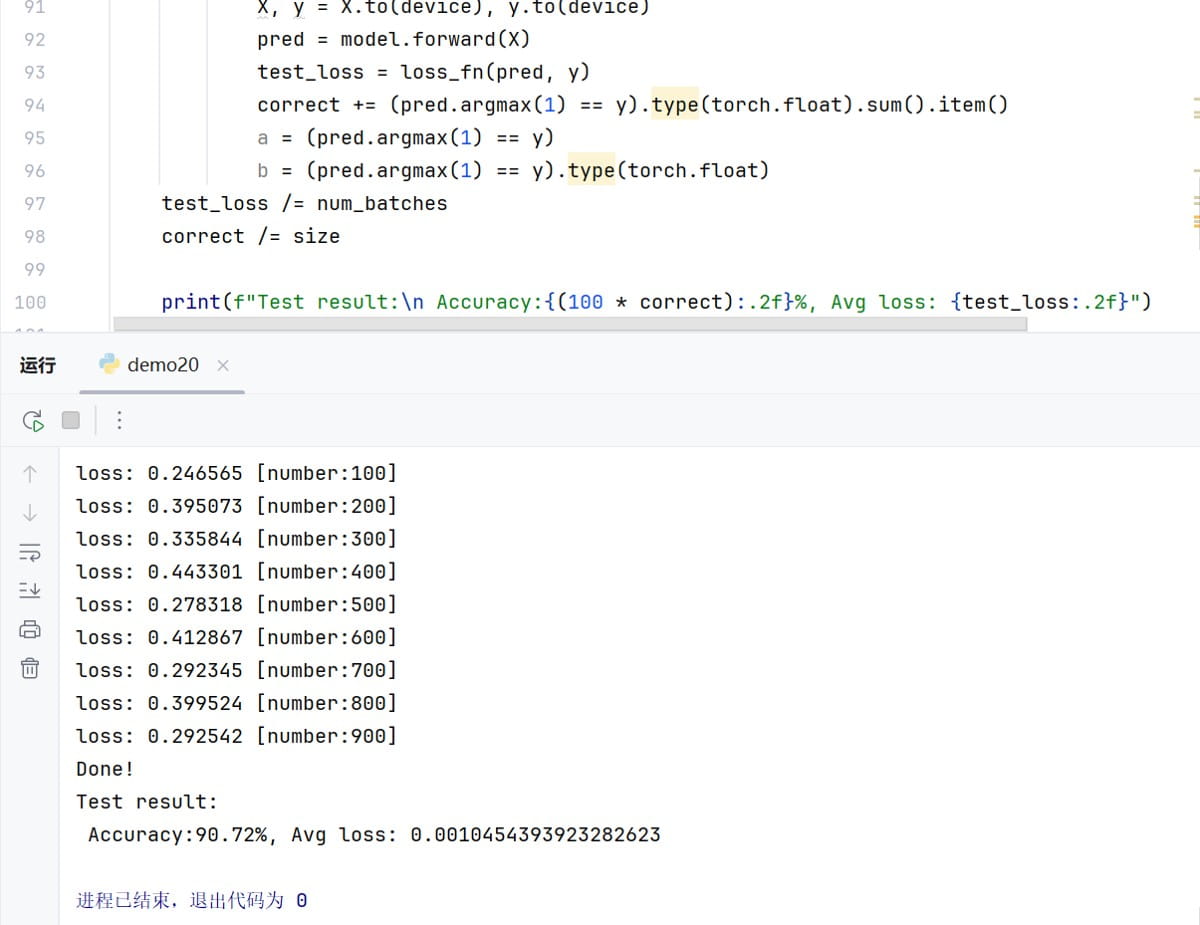
def test(dataloader, model, loss_fn):
size = len(dataloader.dataset)
num_batches = len(dataloader)
model.eval()
test_loss, correct = 0, 0
with torch.no_grad():
for x, y in dataloader:
x, y = x.to(device), y.to(device)
pred = model.forward(x)
test_loss = loss_fn(pred, y)
correct += (pred.argmax(1) == y).type(torch.float).sum().item()
a = (pred.argmax(1) == y)
b = (pred.argmax(1) == y).type(torch.float)
test_loss /= num_batches
correct /= size
print(f"test result:\n accuracy:{(100 * correct):.2f}%, avg loss: {test_loss}")
测试要点:
model.eval():设置为评估模式(禁用dropout)torch.no_grad():禁用梯度计算,节省内存pred.argmax(1):获取预测类别
5. 损失函数配置
loss_fn = nn.crossentropyloss()
损失函数说明:
- 使用
crossentropyloss,适用于多分类问题 - 结合了logsoftmax和nllloss,直接输出分类概率
6. 模型训练与评估
6.1 优化器配置
# 原始优化器 optimizer = torch.optim.sgd(model.parameters(), lr=0.01)
6.2 单次训练与测试
train(train_dataloader, model, loss_fn, optimizer) test(train_dataloader, model, loss_fn)
6.3 多轮训练(可选)
epochs = 10
for t in range(epochs):
print(f"epoch {t+1}\n----------------------")
train(train_dataloader, model, loss_fn, optimizer)
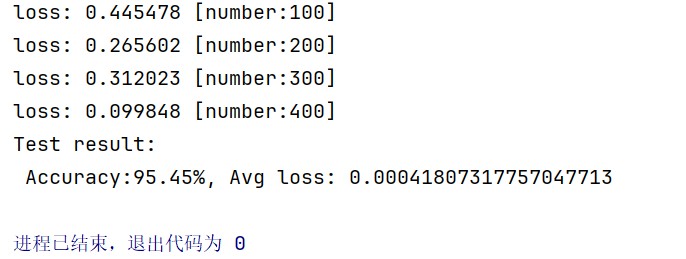
print("done!")
test(test_dataloader, model, loss_fn)
7. 提高准确率的优化方式
- 层数增加:从2层隐藏层增加到3层,增强模型表达能力
- 神经元增加:第一层从128个神经元增加到512个
- 激活函数:用relu替代sigmoid,缓解梯度消失问题
- 正则化:添加dropout层(0.2丢弃率),防止过拟合
- 改进优化器:降低学习率
# 改进架构
self.hidden1 = nn.linear(28 * 28, 512) # 增加神经元
self.dropout1 = nn.dropout(0.2) # 添加dropout
self.hidden2 = nn.linear(512, 256)
self.dropout2 = nn.dropout(0.2) # 添加dropout
self.hidden3 = nn.linear(256, 128) # 增加一层
self.out = nn.linear(128, 10)
# 改进的前向传播
x = self.flatten(x)
x = self.hidden1(x)
x = torch.relu(x) # 使用relu替代sigmoid
x = self.dropout1(x) # 训练时随机丢弃
x = self.hidden2(x)
x = torch.relu(x) # 使用relu替代sigmoid
x = self.dropout2(x) # 训练时随机丢弃
x = self.hidden3(x)
x = torch.relu(x)
x = self.out(x)
# 改进优化器 optimizer = torch.optim.adam(model.parameters(), lr=0.001) # 降低学习率
到此这篇关于pytorch基于mnist的手写数字识别的文章就介绍到这了,更多相关pytorch mnist手写数字识别内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!
赞 (0)
您想发表意见!!点此发布评论




发表评论