Python+VBA删除Excel重复行的两种实用方法详解
6人参与 • 2026-01-31 • Python
在日常处理excel数据时,重复行是高频出现的问题,不仅会增加数据量,还可能导致统计分析出错。本文将详细介绍两种高效的去重方案:free spire.xls for python(适合自动化/批量处理)和 vba 脚本(适合 excel 内直接操作),帮助你根据场景选择最优方式。
核心需求适配
你在处理 excel 重复行时,可能面临这些场景:
- 需批量处理数十个 excel 文件,希望自动化脚本一键去重;
- 仅处理单个 excel 文件,不想安装 python,直接在 excel 内操作;
- 需保留 excel 原生格式(样式、公式),同时精准控制去重规则;
- 既想掌握轻量化的 vba 快速操作,也想学会 python 的批量处理能力。
前置认知:两种方法核心对比
| 特性 | python (free spire.xls) | excel vba |
|---|---|---|
| 操作环境 | 需安装 python + spire.xls 库 | 无需额外安装,excel 原生支持 |
| 适用场景 | 批量处理多文件、跨平台 | 单个文件快速处理、轻量化操作、办公场景 |
| 格式兼容性 | 保留 excel 原生格式、公式、样式 | 完全原生操作,格式无损耗 |
| 学习成本 | 入门级 python 语法,代码可复用 | 简单 vba 语法,仅需掌握核心判重逻辑 |
| 自动化能力 | 可集成到批量脚本、定时任务 | 仅在 excel 内运行,适合单次操作 |
方法1:通过 python 删除重复行
free spire.xls for python 是一款无需安装 microsoft excel 即可操作 excel 文件的免费 python 库,适合批量处理多个 excel 文件、自动化脚本开发场景。
1. 环境准备
首先安装free spire.xls for python,执行以下命令:
pip install spire.xls.free
2. 完整实现代码
from spire.xls import *
# 创建workbook实例
workbook = workbook()
workbook.loadfromfile("duplicates.xlsx")
sheet = workbook.worksheets[0]
# 配置关键参数
key_column = 1 # a列(spire.xls中列号从1开始)
last_row = sheet.lastrow
# 定义要处理的范围
data_range = sheet.range[f"a1:a{last_row}"]
# 用于跟踪已出现的值(去重核心)
seen_values = set()
rows_to_remove = []
# 获取总行数
row_count = data_range.rows.length
# 核心逻辑:从最后一行向前遍历
for i in range(row_count, 0, -1):
# 获取单元格值并标准化
cell = data_range[i, key_column]
cell_value = str(cell.displayedtext).strip()
# 规则:空值 或 已出现过的值 → 标记为删除
if not cell_value or cell_value in seen_values:
rows_to_remove.append(i)
else:
seen_values.add(cell_value)
# 批量删除标记的行(逆序遍历收集的行号,直接删即可)
for row in rows_to_remove:
sheet.deleterow(row)
# 保存并释放资源
workbook.savetofile("removeduplicates.xlsx", excelversion.version2016)
workbook.dispose()
3. 代码关键解释
workbook():创建excel工作簿对象,负责加载/保存文件;
lastrow:获取工作表中实际有数据的最后一行,避免处理空行;
set:高效记录已出现的单元格值;
行数据去重逻辑:
- 逆序遍历:从最后一行到第一行,彻底规避 删除行后行号偏移问题,无需调整行号;
- 清晰的判断规则:拆分 空值处理和重复值处理逻辑,易读易维护;
- 批量标记 + 批量删除:先收集所有要删除的行号,再统一删除,减少 io 操作。
deleterow():删除标记为空白的行;
dispose():释放资源,避免内存泄漏。
方法2:vba 脚本删除 excel 重复行
vba(visual basic for applications)是 excel 内置的脚本语言,无需额外安装工具,适合手动操作单个 excel 文件、快速去重的场景。
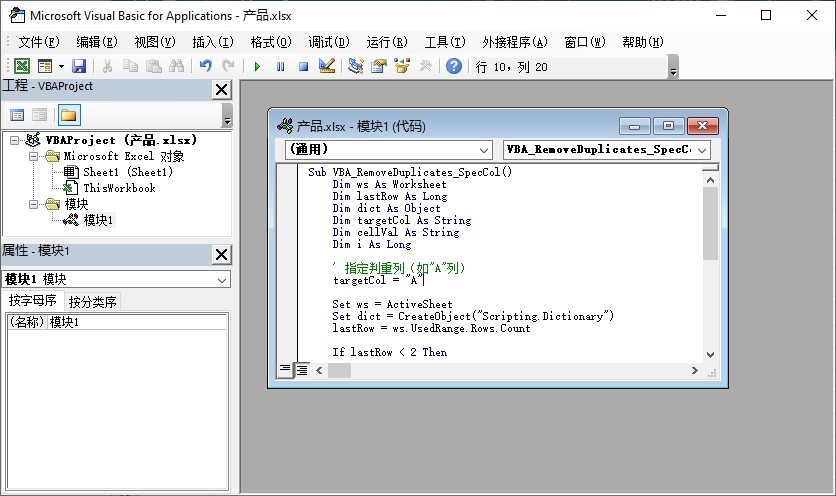
1. 准备工作:启用 vba 编辑器
- 打开 excel 文件 → 【文件】→【选项】→【自定义功能区】→ 勾选 “开发工具”;
- 按
alt + f11打开 vba 编辑器 →【插入】→【模块】,即可编写代码。
2. 完整 vba 代码
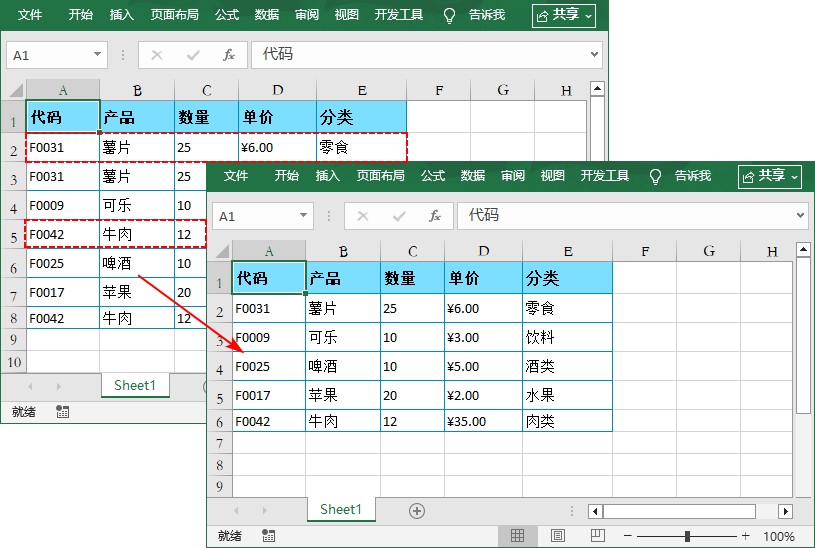
该代码会删除当前工作表中基于第一列(a列)所有的重复行,保留第一条重复行:
sub vba_removeduplicates_speccol()
dim ws as worksheet
dim lastrow as long
dim dict as object
dim targetcol as string
dim cellval as string
dim i as long
' 指定判重列(如"a"列)
targetcol = "a"
set ws = activesheet
set dict = createobject("scripting.dictionary")
lastrow = ws.usedrange.rows.count
if lastrow < 2 then
msgbox "数据不足!", vbinfo
exit sub
end if
' 倒序遍历,仅按指定列判重
for i = lastrow to 2 step -1
cellval = iif(isempty(ws.cells(i, targetcol).value), "", ws.cells(i, targetcol).value)
if dict.exists(cellval) then
ws.rows(i).delete
else
dict.add cellval, i
end if
next i
set dict = nothing
set ws = nothing
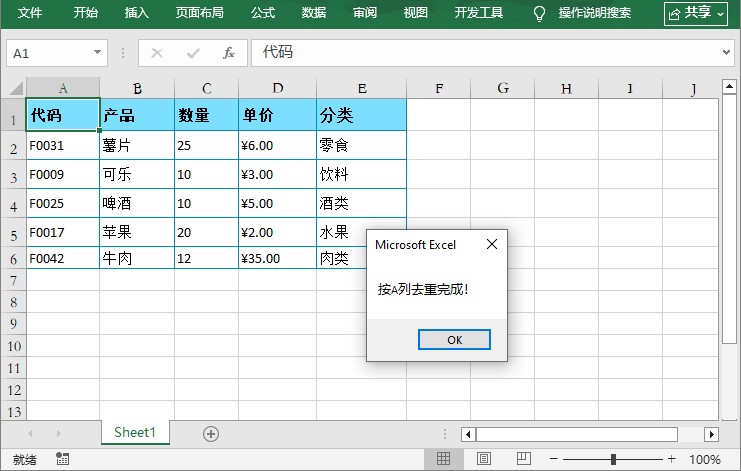
msgbox "按" & targetcol & "列去重完成!", vbinfo
end sub
3. 代码关键解释
activesheet:表示当前选中的工作表,也可手动指定thisworkbook.worksheets("sheet1");targetcol = "a": 定义判重列,改值即可切换目标列;- 判重依据:仅提取指定列单元格值,用
iif(isempty(...))统一空值为"",避免判重错误 lastrow to 2 step -1:防止删除行后索引错乱;delete:删除判断为重复的列
4. 运行 vba 代码的方法
- 在 vba 编辑器中粘贴代码;
- 按
f5运行,或点击 “运行” 按钮; - 回到 excel,弹窗提示 “按a列去重完成”。
无论是 python (free spire.xls) 的批量自动化,还是 vba 的轻量化原生操作,掌握这两种方法就能覆盖所有 excel 去重场景,从根本上解决手动删重复行的低效问题,大幅提升数据处理效率。
到此这篇关于python+vba删除excel重复行的两种实用方法详解的文章就介绍到这了,更多相关python删除excel重复行内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!
赞 (0)
您想发表意见!!点此发布评论



发表评论