大型语言模型入门
80人参与 • 2024-08-03 • 腾讯游戏
大型语言模型chatgpt
快速、全面了解大型语言模型。学习李宏毅课程笔记。
chatgpt
目前由openai公司发明的非常火的人工智能ai应用chatgpt,到底是什么原理呢?
g:generative(生成)
p:pre-trained(预训练)
t:transformer(一种类神经网络模型)
当然,类似的ai技术还有其他,如:google bard、anthropic claude等等
chatgpt背后原理
chatgpt真正做的事情:就是“文字接龙”。
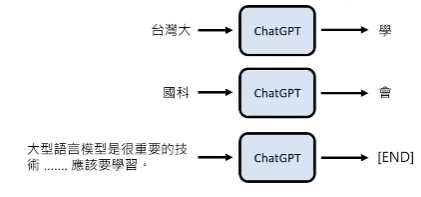
chatgpt又叫大型语言模型,那什么是语言模型呢?
能做“文字接龙”的模型,其实就是语言模型。
那语言模型,是怎么回答人类问题的呢?
当输入问题“台湾最高的山是哪座?”的时候,chatgpt会把它看作成为一个未完成的句子,它会选择一个最合理的字输出,如“玉”字;接下来,它会把上次的输出,接到这个问题后面,共同作为下次的输入,以此类推,直到chatgpt输出“end”结束。
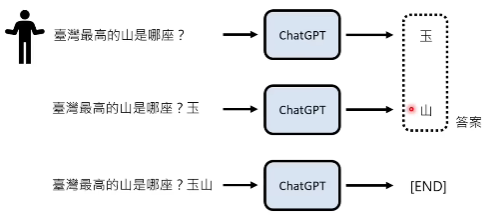
我们再详细一点看chatgpt的原理:
比如,如果输入“台湾大”,后面可以接的字有很多可能,可以接“学”、“哥”、“车”等等。chatgpt的输出其实是给每个可能输出的符号一个概率,比如在这个例子中,“学”出现的概率是50%,"车"出现的概率是25%…chatgpt就按照这些字出现的机率掷色子,掷到“学”的概率最大。所以,chatgpt每次输出的答案不一定相同。
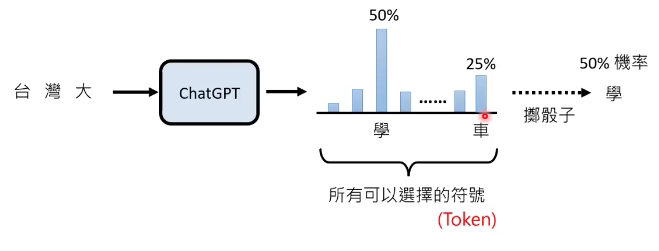
我们把输出有可能选择的这些符号,就叫做token。token是语言模型中很重要的一个概念,甚至chatgpt在计算价格的时候,都是用生成多少token,要花多少钱来收费。
token
其实,每个语言模型的token还不一样,token是开发者事先设定好的,就是做文字接龙的时候你可以选择的符号,有个平台(https://platform.openai.com/tohenizer)可以查询openai的某些语言模型的token是什么。
比如:i am unkillable,虽然是3个单词,却是6个token。

其中,unkillable就被拆成了3个token,即要做3次接龙。
那为什么不能把一个单词作为一个token呢?
因为英文单词无法穷举,因为token是一个可以被选则的符号,所以它必须是一个可以被穷举的东西,这样chatgpt才能给每个token一个概率值,英文单词那么多,而且还不断有新的新的单词产生,所以用这种相当于字首字根的东西表示更为方便。

那中文的token是什么样呢?
在openai的gpt系列中,通常不是把一个中文方块字当作一个token,一个中文方块字是好几个token,当然如果你想开发自己的人工智能,想把一个方块字就当作一个token,也是合理的。
掷色子
我们已经知道chatgpt是按照这些token出现的机率掷色子而得到最后结果。所以,chatgpt每次输出具有随机性,答案不一定相同。
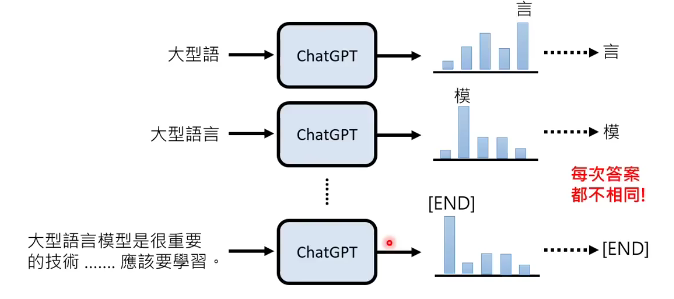
那为什么不能选则输出概率最大的那个token,而要以掷色子的形式输出呢?
因为每次输出概率最大的那个,不一定能得到最好的结果。可以看19年的这篇论文《the curious case of neural text degeneration》,每次选择概率最大的token,模型就容易跳帧,不断loop不断讲一样的话,如果是掷色子的话,就能输出很自然的回答。

为甚么chatgpt有时候也会输出一本正经的胡说八道的答案?
现在我们了解了chatgpt真正做的事是文字接龙的话,就不难想象说为什么chatgpt也会回答错误答案,因为这些答案都是凭借接龙接出来的,chatgpt根本不在意这些答案是否真实或对错。
比如下面这个例子,让chatgpt介绍台大的玫瑰花节,但是台大根本没有这个节日,它仍然会像模像样的给你一个答案,这个网址也是它自己瞎造的。

chatgpt既然是做“文字接龙”,那它是怎么知道多轮对话的呢?即怎么知道一些历史信息的呢?
举个例子:
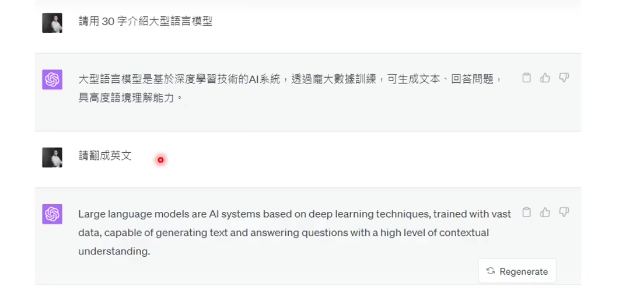
我不需要告诉它把什么翻译成英文,它自己就知道是要把上一个问题的答案翻译成英文,这是为什么呢?
就是在做文字接龙的时候,同一则对话里面,过去你问的问题+chatgpt的输出+这次你的问题,都会作为新的输入。
文字接龙
语言模型是怎么学会做文字接龙的呢?
网络上的任何一句话,都可以作为语言模型的学习数据,比如“人工智慧真神奇!”这句话,模型看到后就知道,“人”后面接“工”的概率比较大,那就提高“人”后面出现“工”的概率…,"!"后面没话了,那就提高“end”的概率。
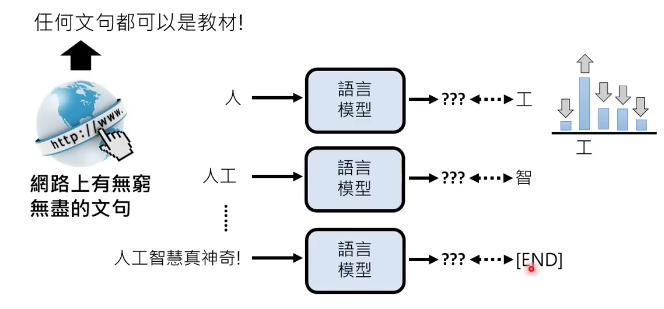
那语言模型是怎么输出这个概率分布的呢?
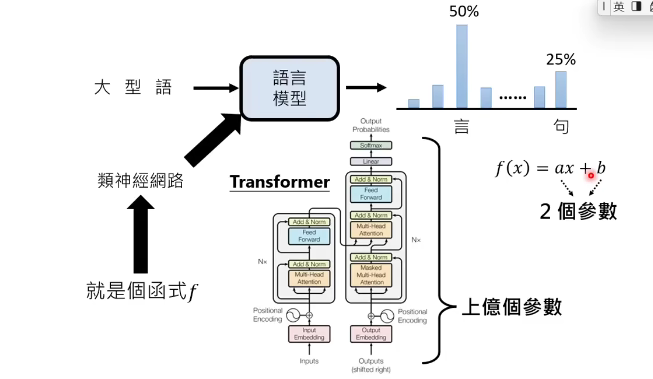
就是transformer模型。详见其他博客。
chatgpt历史
openai 在2018年开始就研究有关gpt的模型了。
-
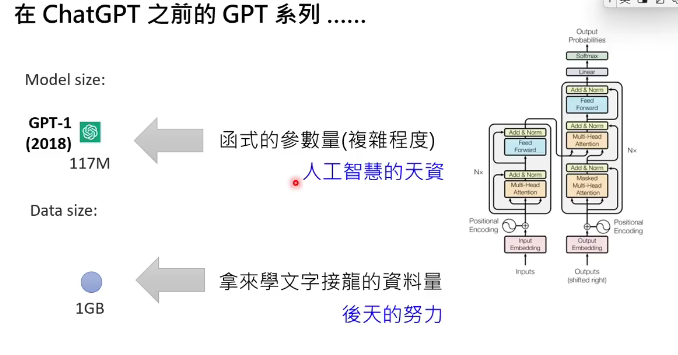
第一代gpt-1:
模型参数量只有117m,训练数据才1gb。
-
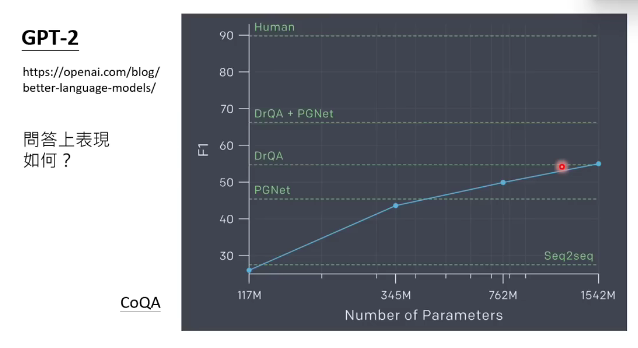
2019年诞生第二代gpt-2:
模型参数量1542m,训练数据40gb。
gpt-2也可以做问答任务,但是表现一般,正确率只有55%左右。
-
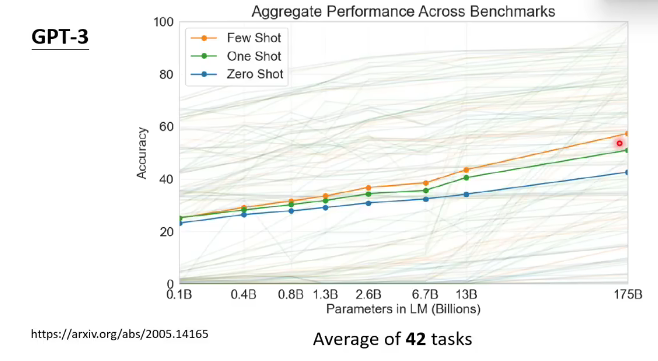
2020年诞生第三代gpt-3:
模型参数量175b,足足是gpt-2的100多倍呀!训练数据580gb,相当于阅读哈利波特全集30万遍,远超过一个正常人一辈子度过的资料量。
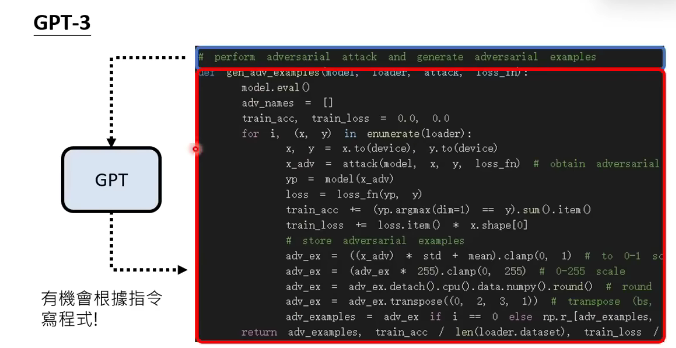
这一代的gpt-3已经会写代码了!
但在所有的任务上的表现也一般,准确率也是50%多左右。
gpt只从网络资料学习的缺点:
有人说openai走错方向了,看起来再怎么做文字接龙,也接不出一个通用的人工智能出来。但是openai并没有放弃,他们有篇论文说其实gpt-3已经很聪明了,但它表现不好的原因就是,它不知道人类社会的规则,不知道人类的需求。它就像一个山野里长大的小孩,它只见过网络上的东西,在网络上随便乱学,它并不知道要做什么事情,甚至不知道要回答问题。
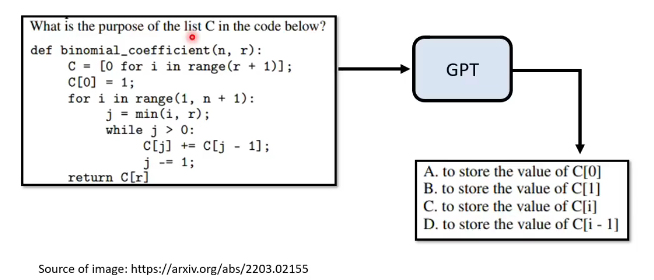
论文举了如下例子:
我们问它c在下面这段代码里面的含义是什么,它的回答是4个选项,可能因为网络上有很多考题,它在网络上学到的就是看到一个问题,对应四个选项。
- chatgpt-3.5,也就是第3.5代模型
这次引入了监督式学习,就是人类老师教给它,想要让它做的事情。
反过来说,如果gpt网络上爬了数据自己学习,叫作自监督学习,就是自己教自己,相当于课堂前的预习,就叫预训练。所以预训练就是今天很多人工智能成功的关键,预训练好的模型就叫作基石模型,然后经过一些微调,经过人类老师的教学,就可以有很大的提升。
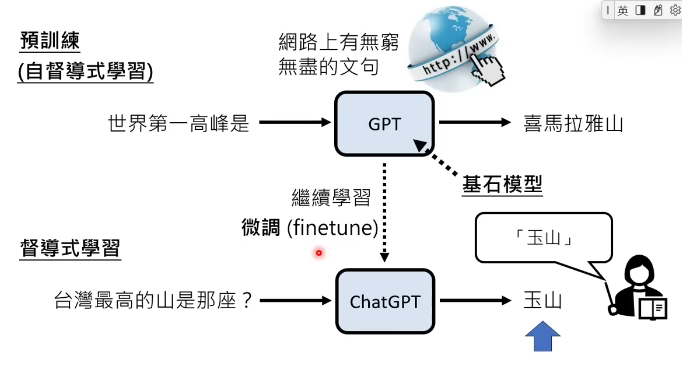
其实,chatgpt的训练有三阶段:预训练+监督学习+增强学习(后面内容介绍)
其中,监督学习+增强学习 = 对齐,即对齐人类的需求,满足人类的需求。
- chatgpt-4,第四代模型
openai 并未公开模型参数量大小和训练数据量
gpt-4新增的功能就是可以看得见了!就是你可以给它一张图片,然后问它问题,例子:

监督式学习&预训练&增强学习
监督式学习
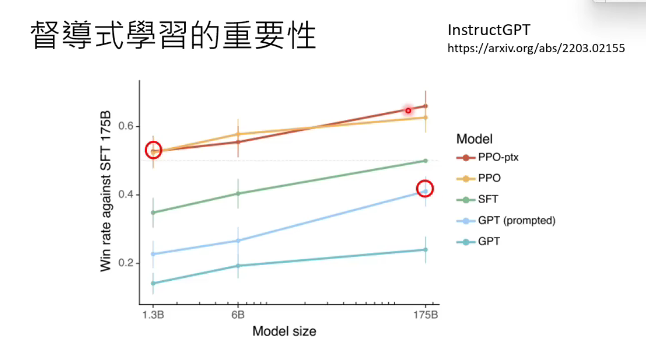
监督式学习的重要性:
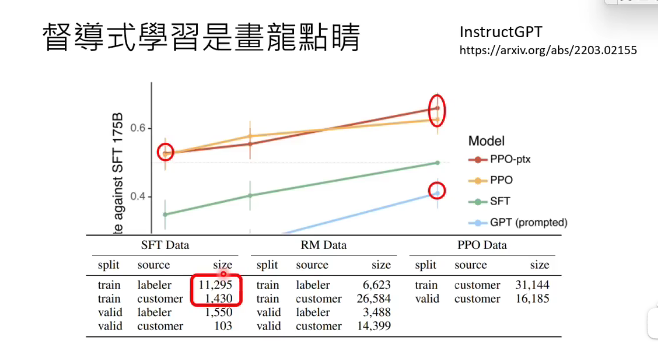
其实到今天,chatgpt背后的原理仍然是一种猜想。在instructgpt这篇文中有张图,纵轴是模型的好坏,横轴是模型参数的大小,蓝色线是模型自监督学习的结果,也就是自己学习网络数据,红色线是监督式学习,就是啊加入了人类老师指导的结果。可以看到,加入了人类指导,即使参数量很小的模型,都比参数量最大的自监督学习模型厉害。就相当于天资再好的学生,都不如那个虽然天资不好,但老师好好教他的模型,所以说明老师(监督式学习)的重要性。
预训练
预训练的重要性:有预训练后,监督式学习不用大量资料!
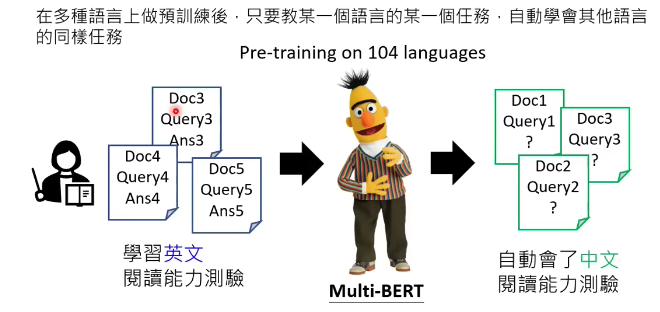
预训练有多神奇呢?在多种语言上做预训练后,只要教某一个语言的某一个任务,模型就可以自动学习学会其他语言的同样任务。
举个例子,有个语言模型bert,它自学过104种语言(预训练),现在人类教它学习英文阅能力测验(微调),但不教它中文的阅读能力测验,然后现场让它答中文的,它也答的出来!
那预训练后,需要多少数据就能微调呢?就是老师需要教多少就能让这个模型学生开窍呢。
仍然是instructgpt这篇文中也可以看到,人类老师只提供了一万多的数据,就微调好模型了。
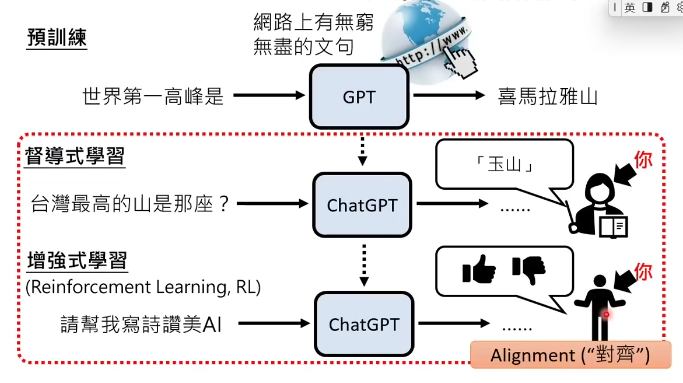
增强学习
除了监督式学习,chatgpt还有增强学习(reinforcement learning, rl)来强化它的能力。增强学习就是人类老师只提供回馈哪个答案是更好的。
那监督式学习和增强学习之间什么区别呢?
一个需要人类做解答题,一个只要做选择题。监督式学习需要人类老师提供完整的正确答案(这个很花人力气,多数人可能不愿这么做,可能只有openai的标记员有心力做这件事),但在增强学习中,老师不需要提供完整正确答案,只需要反馈哪个答案更好,因此每个人都可以做。
增强学习原理比较复杂,感兴趣的同学可以学习其他相关课程。
从人类的回馈学习,有个专门的简称:rlhf。

基本概念
当输入一个问题,模型给你两个答案,你就告诉它哪个答案更好,模型就会想办法把你觉得好的答案提高输出的概率,不好的答案降低它的概率。
一般先做预训练,再做监督式学习,最后做增强学习。为什么最后做增强学习呢?
因为模型要有一定程度的能力后,才适合进行增强学习,这样效果更好。
背后的假设就是,你的模型要偶有佳作,必须要有时候能得出不错的答案,人类反馈这个答案是好的,然后提高这个答案的概率才有意义。如果模型输出的效果整体不好,即使人类从两个差的答案里勉强选一个,模型相当于还是在提高差的答案的概率,可能这时候增强学习帮助就不大。因此,增强学习一般放在整个训练过的最后。
chatgpt中的增强学习:
刚才讲到增强学习就是增强好的那一个答案的概率,但是这样的话,机器只学习到把某一个问题做好,怎样才能做到人类给某一个问题回馈,但是其他问题也能同时做好呢?
chatgpt的增强学习过程分为两个步骤:
-
模仿人类老师的喜好
如:当人类反馈“玉山”答案更好的时候,chatgpt就会另外再训一个reward model,就是把问题+所有可能的答案输入reward model,输出一个得分,让人类觉得好的答案的分数就高,不好的分数就低,这样就相当于训练出了一个人类老师的代替品。
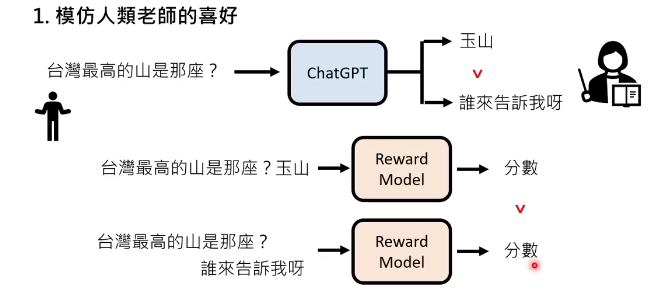 好了,现在把人类老师解放了,让reward model来代替人类老师的角色。接下来就是步骤2。
好了,现在把人类老师解放了,让reward model来代替人类老师的角色。接下来就是步骤2。 -
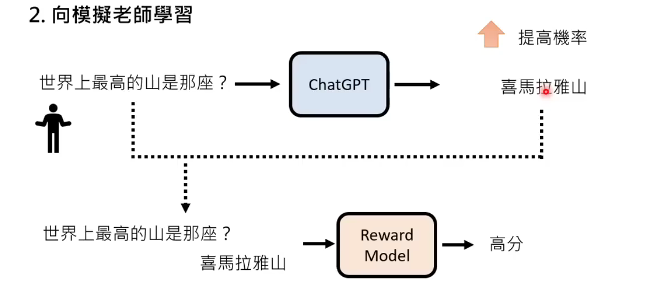
向模拟老师学习
现在就可以把问题+答案输入给reward model了,让它替人类老师打分,对好的答案打高分,差的答案打低分。
打低分,降低概率

打高分,提高概率
总结:
chatgpt的训练有三阶段:预训练+监督学习+增强学习
其中,监督学习+增强学习 = 对齐,即对齐人类的需求,满足人类的需求。
几个月前,openai发布了gpt-4,并公开了一份近百页的技术报告,最惊人的是,其中作者群长达三页!说明gpt-4背后的工程非常浩大。这份报告主要是一份炫耀文,告诉你gpt-4有多强,但技术细节只介绍了一段话:

openai 并未正式公布chatgpt-4用了多少训练数据,以及模型的参数量。
下一步:人类的努力

现在语言模型已经非常强了,接下来就是看通过人类的努力,是否能激发语言模型更大的力量。以下就是介绍一些激发语言模型力量的秘诀。
1.把需求讲清楚
比如:是希望它润色,还是改语法,还是用什么语言扩写,扩写到多少字…
2.提供信息给chatgpt
比如:让它写一篇作文,它写着自己停下来了,你就写“继续”,给它多提供点你的资料,用什么样的口吻、类型等
3.提供范例
例如:直接给他一个例子,让它模仿
4.鼓励chatgpt想一想
例如:让它回答鸡兔同笼问题,不同文法,结果不同
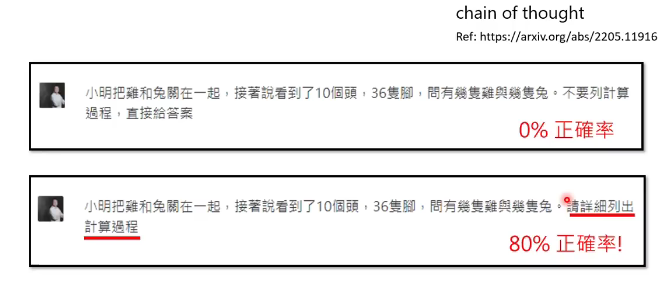
有人对比了不同的问法的准确率:

准确率最高的问法,就是神奇的咒语
5.如何找出神奇咒语
用ai来找神奇咒语
6.上传档案
7.chatgpt可以使用其他工具
8.拆解任务
9.自主进行规划
10.chatgpt其实会反省
11.跟真实环境互动
赞 (0)
打赏
 微信扫一扫
微信扫一扫
微信扫一扫
您想发表意见!!点此发布评论





发表评论