498人参与 • 2024-08-06 • 数据结构
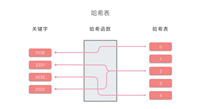
哈希表(hash table),也称为散列表,是一种使用哈希函数组织数据,以支持快速插入和搜索的数据结构。哈希表的基本思想是通过哈希函数把键(key)映射到表中一个位置来访问记录,以加快查找的速度。这个映射的函数称作哈希函数,存放记录的数组称作哈希表或散列表。
1.哈希函数设计:设计一个好的哈希函数是哈希表效率的关键。理想的哈希函数应该满足两个基本条件:一是尽量减少冲突,二是计算简单快速。哈希函数通常将输入(比如字符串、数字等)转换成一个整数,这个整数的范围通常是0到哈希表大小减一。
2.处理哈希冲突:由于不同的输入可能会被映射到同一个输出,因此必须有方法来处理这种"哈希冲突"(hash collision)。解决哈希冲突的方法主要有两种:开放寻址法(open addressing)和链表法(chaining)。
(1)开放寻址法:当发生冲突时,探索表中的下一个空槽,并将元素插入其中。
(2)链表法:每个表格元素维护一个链表,所有映射到该位置的元素都存放在这个链表中。
3.动态扩容:为了保持哈希表的高效性,当哈希表中的元素过多,导致负载因子(即元素个数与表容量的比值)超过某个阈值时,通常需要进行扩容,即创建一个更大的哈希表,并将所有现有的元素重新映射到新表中。
1.快速访问:理想情况下,哈希表的查找、插入和删除操作的时间复杂度都是o(1)。
2.灵活键值对应:可以直接通过键值对快速访问数据,非常适合需要频繁查找的场景。
1.空间占用:为了减少哈希冲突,哈希表可能会预留大量空间,导致空间使用效率不高。
2.顺序遍历困难:由于数据是根据哈希值分布的,哈希表不支持高效的顺序访问。
3.哈希冲突:虽然有方法解决,但是在极端情况下,哈希冲突可能会导致性能大幅下降。
示例代码:
unordered_map 是c++标准模板库(stl)中的一个关联容器,提供了键值对的存储能力,其中每个键都是唯一的,并且可以通过键快速检索到值。
#include <iostream>
#include <unordered_map>
#include <string>
using namespace std;
int main() {
// 创建一个unordered_map,键为string类型,值为int类型
std::unordered_map<std::string, int> agemap;
// 插入键值对
agemap["alice"] = 30;
agemap["bob"] = 25;
agemap["charlie"] = 35;
// 通过键访问值
std::cout << "alice's age: " << agemap["alice"] << std::endl;
// 检查键是否存在
if (agemap.find("diana") == agemap.end()) {
std::cout << "diana is not in the age map." << std::endl;
}
else {
std::cout << "diana's age: " << agemap["diana"] << std::endl;
}
// 遍历unordered_map
std::cout << "all entries in the age map:" << std::endl;
for (const auto& pair : agemap) {
std::cout << pair.first << ": " << pair.second << std::endl;
}
// 删除键值对
agemap.erase("bob");
std::cout << "after erasing bob, we have:" << std::endl;
for (const auto& pair : agemap) {
std::cout << pair.first << ": " << pair.second << std::endl;
}
return 0;
}
在 c++ 中,当使用 std::unordered_map 或任何基于哈希的容器时,容器自身会自动处理哈希冲突。但了解它是如何处理这些冲突的可以更好地理解哈希表的工作原理。一般来说,哈希冲突的处理方法包括链地址法(也称为分离链接法)和开放寻址法,其中链地址法是最常用的方法之一,且是许多标准库实现的选择。
在链地址法中,哈希表的每个桶(或称为槽)不直接存储键值对,而是存储指向键值对链表的指针。当多个键哈希到同一个桶时,这些键值对会被存储在同一个链表中,从而解决了冲突。查找、插入和删除操作会首先定位到桶,然后在链表中进行。
下面的示例代码不是使用 std::unordered_map 的标准处理方式,,展示了一个简化的哈希表实现,使用链地址法来处理哈希冲突:
#include <iostream>
#include <list>
#include <vector>
#include <utility>
class simplehashtable {
private:
static const int hash_size = 10; // 哈希表大小,简单起见设为一个小值
std::vector<std::list<std::pair<int, std::string>>> table; // 哈希表
public:
simplehashtable() : table(hash_size) {}
void insert(int key, const std::string& value) {
int index = hashfunction(key);
// 遍历链表以查找是否已存在相同的键
for (auto& pair : table[index]) {
if (pair.first == key) {
pair.second = value; // 如果键已存在,更新值
return;
}
}
// 如果键不存在,添加到链表的末尾
table[index].push_back(std::make_pair(key, value));
}
bool search(int key, std::string& value) {
int index = hashfunction(key);
for (const auto& pair : table[index]) {
if (pair.first == key) {
value = pair.second;
return true; // 找到键,返回true
}
}
return false; // 未找到键,返回false
}
bool remove(int key) {
int index = hashfunction(key);
for (auto it = table[index].begin(); it != table[index].end(); ++it) {
if (it->first == key) {
table[index].erase(it); // 找到键,删除
return true;
}
}
return false; // 未找到键,返回false
}
private:
int hashfunction(int key) {
return key % hash_size; // 简单的模运算哈希函数
}
};
int main() {
simplehashtable hashtable;
hashtable.insert(1, "alice");
hashtable.insert(11, "bob"); // 会产生哈希冲突并处理
std::string value;
if (hashtable.search(1, value)) {
std::cout << "found key 1 with value: " << value << std::endl;
}
if (hashtable.search(11, value)) {
std::cout << "found key 11 with value: " << value << std::endl;
}
return 0;
}
补充:
有序表(ordered list)是数据结构中的一种,它按照元素的某种特定顺序(如升序或降序)组织数据。这种数据结构支持高效的查找、插入和删除操作,因为元素的有序性使得可以使用比如二分查找等高效算法。有序表可以通过多种方式实现,包括数组、链表、平衡树(如avl树、红黑树)、跳表等。下面是有序表的一些关键特点和常用实现方式:
(1)有序性:有序表中的元素根据键(key)的值进行排序。这意味着元素在表中的位置是由其键的值决定的。
(2)动态操作:支持动态地插入和删除元素,同时保持元素的有序性。
(3)高效查找:由于元素是有序的,因此可以使用二分查找等高效算法,以对数时间复杂度进行查找操作。
(4)范围查询:有序表使得基于范围的查询变得简单和高效,如查找所有键在某个区间内的元素。
(1)静态数组:将元素存储在固定大小的数组中。插入和删除操作可能需要移动多个元素,因此效率较低。
(2)动态数组:可以调整大小的数组,以容纳更多元素。插入和删除操作的平均时间复杂度较好,但最坏情况下可能需要移动大量元素。
单链表或双链表:元素通过指针相连,每个元素包含数据和指向下一个(和/或前一个)元素的指针。插入和删除操作可以在o(1)时间内完成,如果已经到达相应位置的话。但查找操作通常需要o(n)的时间复杂度。
(1)二叉查找树(bst)的变体,如avl树、红黑树:这些树结构通过旋转操作来保持平衡,确保最坏情况下的操作时间复杂度为o(log n)。
(2)b树和b+树:特别适用于存储系统中的数据索引,能够高效管理大量数据。
跳表是一个通过多层结构来实现快速查找的链表。它通过添加额外的"快速通道"链表,使得查找效率可以接近二分查找的效率,即o(log n)。
有序表在很多领域都有广泛的应用,包括数据库索引、内存管理、文件系统以及各种需要快速查找和维护有序数据的场景。每种实现方式有其特定的适用场景和优缺点,选择哪一种取决于具体的应用需求,如操作的频率、数据量的大小以及是否需要支持快速的插入或删除操作。
示例代码:
在 c++ 中,有序表可以通过使用 std::map 来实现,这是一个基于红黑树的自平衡二叉搜索树,能够保持元素按照特定的顺序(通常是键的升序)进行排序。
#include <iostream>
#include <map>
#include <string>
int main() {
// 创建一个std::map实例,键和值的类型都是string
std::map<std::string, std::string> phonebook;
// 向map中添加键值对
phonebook["alice"] = "555-1234";
phonebook["bob"] = "555-5678";
phonebook["charlie"] = "555-9999";
// 通过键访问值
std::cout << "alice's phone number: " << phonebook["alice"] << std::endl;
// 检查键是否存在并访问
auto search = phonebook.find("diana");
if (search != phonebook.end()) {
std::cout << "diana's phone number: " << search->second << std::endl;
}
else {
std::cout << "diana is not in the phone book." << std::endl;
}
// 遍历map
std::cout << "all entries in the phone book:" << std::endl;
for (const auto& entry : phonebook) {
std::cout << entry.first << ": " << entry.second << std::endl;
}
// 删除键值对
phonebook.erase("bob");
std::cout << "after erasing bob, the phone book contains:" << std::endl;
for (const auto& entry : phonebook) {
std::cout << entry.first << ": " << entry.second << std::endl;
}
return 0;
}
补充:
链表是一种常用的数据结构,它由一系列节点组成,每个节点包含数据部分和指向下一个节点的指针(在双向链表中还包含指向上一个节点的指针)。链表是一种动态的数据结构,可以在运行时动态添加或删除节点,这使得它在需要频繁插入和删除操作的场景下非常有用。链表的元素不像数组那样在内存中连续存储,因此它们的插入和删除操作不需要移动其他元素。
每个节点只包含一个指向下一个节点的指针。这种结构使得遍历只能是单向的,从头节点开始到尾节点结束。
每个节点包含两个指针,一个指向下一个节点,另一个指向上一个节点。这使得链表可以正向或反向遍历。
题目1:反转单向和双向链表
分别实现反转单向链表和反转双向链表的函数【要求】如果链表长度为n,时间复杂度要求为o(n),额外空间复杂度要求为o(1)
(1)反转单向链表
#include <iostream>
// 定义单向链表的节点结构
struct listnode {
int val;
listnode *next;
listnode(int x) : val(x), next(nullptr) {}
};
// 反转单向链表的函数
listnode* reverselist(listnode* head) {
listnode *prev = nullptr;
listnode *curr = head;
while (curr != nullptr) {
listnode *nexttemp = curr->next;
curr->next = prev;
prev = curr;
curr = nexttemp;
}
return prev; // 新的头节点
}
// 用于打印链表,验证结果
void printlist(listnode* node) {
while (node != nullptr) {
std::cout << node->val << " ";
node = node->next;
}
std::cout << std::endl;
}
// 示例主函数
int main() {
// 创建示例链表:1 -> 2 -> 3 -> 4
listnode *list = new listnode(1);
list->next = new listnode(2);
list->next->next = new listnode(3);
list->next->next->next = new listnode(4);
std::cout << "original list: ";
printlist(list);
listnode *reversedlist = reverselist(list);
std::cout << "reversed list: ";
printlist(reversedlist);
// 释放链表内存(在实际应用中应该逐节点释放,此处为简化示例未包含)
return 0;
}
(2)反转双向链表
#include <iostream>
// 定义双向链表的节点结构
struct dlistnode {
int val;
dlistnode *prev, *next;
dlistnode(int x) : val(x), prev(nullptr), next(nullptr) {}
};
// 反转双向链表的函数
dlistnode* reversedlist(dlistnode* head) {
dlistnode *temp = nullptr;
dlistnode *current = head;
while (current != nullptr) {
temp = current->prev;
current->prev = current->next;
current->next = temp;
current = current->prev;
}
if (temp != nullptr) {
head = temp->prev;
}
return head; // 新的头节点
}
// 用于打印双向链表,验证结果
void printdlist(dlistnode* node) {
while (node != nullptr) {
std::cout << node->val << " ";
node = node->next;
}
std::cout << std::endl;
}
// 示例主函数
int main() {
// 创建示例双向链表:1 <-> 2 <-> 3 <-> 4
dlistnode *dlist = new dlistnode(1);
dlist->next = new dlistnode(2);
dlist->next->prev = dlist;
dlist->next->next = new dlistnode(3);
dlist->next->next->prev = dlist->next;
dlist->next->next->next = new dlistnode(4);
dlist->next->next->next->prev = dlist->next->next;
std::cout << "original list: ";
printdlist(dlist);
dlistnode *reverseddlist = reversedlist(dlist);
std::cout << "reversed list: ";
printdlist(reverseddlist);
// 释放链表内存(在实际应用中应该逐节点释放,此处为简化示例未包含)
return 0;
}
注意:对于双向链表的反转,交换了每个节点的 prev 和 next 指针,并更新了头节点。在真实应用中,还需要适当管理内存,例如通过逐个删除链表中的节点来避免内存泄露。
题目2:打印两个有序链表的公共部分
给定两个有序链表的头指针head1和head2,打印两个链表的公共部分要求】如果两个链表的长度之和为n,时间复杂度要求为o(n),额外空间复杂度要求为o(1)。
思路:
为了打印两个有序链表的公共部分,并满足时间复杂度为 o(n) 且额外空间复杂度为 o(1) 的要求,可以采用双指针遍历的方式。因为两个链表都是有序的,可以同时遍历这两个链表,比较当前遍历到的节点值:
#include <iostream>
// 定义单向链表的节点结构
struct listnode {
int val;
listnode *next;
listnode(int x) : val(x), next(nullptr) {}
};
// 打印两个有序链表的公共部分
void printcommonpart(listnode* head1, listnode* head2) {
while (head1 != nullptr && head2 != nullptr) {
if (head1->val == head2->val) {
// 找到公共元素,打印
std::cout << head1->val << " ";
// 同时移动两个链表的指针
head1 = head1->next;
head2 = head2->next;
} else if (head1->val < head2->val) {
// 移动第一个链表的指针
head1 = head1->next;
} else {
// 移动第二个链表的指针
head2 = head2->next;
}
}
}
int main() {
// 创建两个示例有序链表
listnode *list1 = new listnode(1);
list1->next = new listnode(2);
list1->next->next = new listnode(3);
list1->next->next->next = new listnode(4);
list1->next->next->next->next = new listnode(6);
listnode *list2 = new listnode(2);
list2->next = new listnode(4);
list2->next->next = new listnode(6);
list2->next->next->next = new listnode(8);
std::cout << "common parts: ";
printcommonpart(list1, list2);
std::cout << std::endl;
// 释放链表内存(在实际应用中应该逐节点释放,此处为简化示例未包含)
return 0;
}
1)对于笔试,不用太在乎空间复杂度,一切为了时间复杂度
2)对于面试,时间复杂度依然放在第一位,但是一定要找到空间最省的方法
重要技巧:
1)额外数据结构记录(哈希表等)
2)快慢指针
题目1:判断一个链表是否为回文结构
给定一个单链表的头节点head,请判断该链表是否为回文结构。【例子】1->2->1,返回true;1->2->2->1,返回true;15->6->15,返回true;1->2->3,返回false。
要求:如果链表长度为n,时间复杂度达到o(n),额外空间复杂度达到o(1)。
思路:
#include <iostream>
// 定义链表的节点结构
struct listnode {
int val;
listnode *next;
listnode(int x) : val(x), next(nullptr) {}
};
// 反转链表函数
listnode* reverselist(listnode* head) {
listnode *prev = nullptr, *curr = head;
while (curr != nullptr) {
listnode *nexttemp = curr->next;
curr->next = prev;
prev = curr;
curr = nexttemp;
}
return prev;
}
// 寻找链表中点函数
listnode* findmiddle(listnode* head) {
listnode *slow = head, *fast = head;
while (fast->next != nullptr && fast->next->next != nullptr) {
slow = slow->next;
fast = fast->next->next;
}
return slow;
}
// 判断链表是否为回文结构
bool ispalindrome(listnode* head) {
if (head == nullptr || head->next == nullptr) {
return true;
}
listnode* middle = findmiddle(head);
listnode* secondhalfstart = reverselist(middle->next);
listnode* p1 = head;
listnode* p2 = secondhalfstart;
bool ispalindrome = true;
while (p2 != nullptr) { // 只需要比较后半部分
if (p1->val != p2->val) {
ispalindrome = false;
break;
}
p1 = p1->next;
p2 = p2->next;
}
// 恢复链表(如果需要)
middle->next = reverselist(secondhalfstart);
return ispalindrome;
}
int main() {
// 创建示例链表:1 -> 2 -> 2 -> 1
listnode* head = new listnode(1);
head->next = new listnode(2);
head->next->next = new listnode(2);
head->next->next->next = new listnode(1);
std::cout << "is palindrome: " << ispalindrome(head) << std::endl;
// 释放链表内存(在实际应用中应该逐节点释放,此处为简化示例未包含)
return 0;
}
题目2:将单向链表按某值划分成左边小、中间相等、右边大的形式
【题目】给定一个单链表的头节点head,节点的值类型是整型,再给定一个整数pivot。实现一个调整链表的函数,将链表调整为左部分都是值小于pivot的节点,中间部分都是值等于pivot的节点,右部分都是值大于pivot的节点。
#include <iostream>
// 定义链表的节点结构
struct listnode {
int val;
listnode *next;
listnode(int x) : val(x), next(nullptr) {}
};
// 调整链表
void partition(listnode* &head, int pivot) {
listnode *lesshead = new listnode(0), *equalhead = new listnode(0), *greaterhead = new listnode(0);
listnode *lesstail = lesshead, *equaltail = equalhead, *greatertail = greaterhead;
listnode *current = head;
// 遍历链表,分配节点
while (current != nullptr) {
if (current->val < pivot) {
lesstail->next = current;
lesstail = lesstail->next;
} else if (current->val == pivot) {
equaltail->next = current;
equaltail = equaltail->next;
} else {
greatertail->next = current;
greatertail = greatertail->next;
}
current = current->next;
}
// 连接三个部分
greatertail->next = nullptr; // 最后一个部分的结尾要指向 nullptr
equaltail->next = greaterhead->next; // 等于部分连接大于部分
lesstail->next = equalhead->next; // 小于部分连接等于部分
head = lesshead->next; // 更新头节点
// 释放临时头节点
delete lesshead;
delete equalhead;
delete greaterhead;
}
// 打印链表
void printlist(listnode* node) {
while (node != nullptr) {
std::cout << node->val << " ";
node = node->next;
}
std::cout << std::endl;
}
int main() {
listnode* head = new listnode(9);
head->next = new listnode(0);
head->next->next = new listnode(4);
head->next->next->next = new listnode(5);
head->next->next->next->next = new listnode(1);
std::cout << "original list: ";
printlist(head);
partition(head, 3);
std::cout << "partitioned list: ";
printlist(head);
// 释放链表内存(在实际应用中应该逐节点释放,此处为简化示例未包含)
return 0;
}
#include <iostream>
struct listnode {
int val;
listnode *next;
listnode(int x) : val(x), next(nullptr) {}
};
void partition(listnode*& head, int pivot) {
listnode *lesshead = nullptr, *lesstail = nullptr;
listnode *equalhead = nullptr, *equaltail = nullptr;
listnode *greaterhead = nullptr, *greatertail = nullptr;
listnode *current = head;
while (current != nullptr) {
if (current->val < pivot) {
if (lesstail == nullptr) {
lesshead = lesstail = current;
} else {
lesstail->next = current;
lesstail = current;
}
} else if (current->val == pivot) {
if (equaltail == nullptr) {
equalhead = equaltail = current;
} else {
equaltail->next = current;
equaltail = current;
}
} else {
if (greatertail == nullptr) {
greaterhead = greatertail = current;
} else {
greatertail->next = current;
greatertail = current;
}
}
current = current->next;
}
// 连接三个部分
listnode* newhead = nullptr;
if (lesshead) {
newhead = lesshead;
lesstail->next = equalhead ? equalhead : greaterhead;
}
if (equalhead) {
newhead = newhead ? newhead : equalhead;
equaltail->next = greaterhead;
}
if (greaterhead) {
newhead = newhead ? newhead : greaterhead;
greatertail->next = nullptr;
}
head = newhead; // 更新头指针
}
void printlist(listnode* node) {
while (node) {
std::cout << node->val << " ";
node = node->next;
}
std::cout << std::endl;
}
int main() {
listnode* head = new listnode(9);
head->next = new listnode(0);
head->next->next = new listnode(4);
head->next->next->next = new listnode(5);
head->next->next->next->next = new listnode(1);
std::cout << "original list: ";
printlist(head);
partition(head, 4);
std::cout << "partitioned list: ";
printlist(head);
// 在实际应用中应该逐节点释放链表内存,此处为简化示例未包含释放代码
return 0;
}
您想发表意见!!点此发布评论
版权声明:本文内容由互联网用户贡献,该文观点仅代表作者本人。本站仅提供信息存储服务,不拥有所有权,不承担相关法律责任。 如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 2386932994@qq.com 举报,一经查实将立刻删除。





发表评论