xv6(RISC-V)操作系统源码分析第七节——进程的调度与交互
508人参与 • 2024-08-06 • 交互
一、调度的必要性
任何操作系统运行的进程数量都可能超过计算机的cpu数量,因此必须制定一个方案,使各进程能够分时共享cpu。这就涉及到进程的切换,这种切换就是调度。调度的目的是实现多路复用。
二、实现多路复用的注意点
多路复用是一个具有挑战性的机制。xv6采用下面技术来实现多路复用:
- 上下文切换可以实现多路复用,但xv6中的上下文切换是最不透明的代码之一
- xv6使用定时器中断来驱动上下文切换
- 许多cpu会在进程间并发切换,锁可以用来避免竞争
- 当进程退出时,必须释放进程的内存和其他资源,但进程本身不能完全释放掉所有资源,比如它不能在使用内核栈的同时释放内核栈
- 多处理器计算机的每个cpu必须记住它正在执行的进程
三、何时调度
xv6仅在下面两种情况下会发生调度:
- 当一个进程等待设备或管道i/o,或在sleep系统调用中等待
- 定时器中断引起的调度
四、与进程切换有关的数据结构
xv6运行在多核处理器上,并且一个核可并发运行多个进程,为了实现进程调度等功能,我们需要数据结构来标识不同的核与不同的进程。
(一)cpu
struct cpu {
struct proc *proc; // the process running on this cpu, or null.
struct context context; // swtch() here to enter scheduler().
int noff; // depth of push_off() nesting.
int intena; // were interrupts enabled before push_off()?
};xv6为每个cpu都维护了一个cpu结构体,它详细记录了该cpu的对xv6有用的信息。每个cpu都有一个编号——hartid,该编号保存在每个cpu的mhartid寄存器中。xv6可以通过该编号来索引分辨不同的cpu。
这里值得注意的是,如果想获得当前cpu的信息,但是这时发生了定时器中断,可能当前的执行的cpu会变成其他的cpu,那么获得的cpu信息就有误,为了保证正确性,会在读cpu信息前关闭定时器中断,读完后才会打开。
(二)process
struct proc {
struct spinlock lock;
// p->lock must be held when using these:
enum procstate state; // process state
void *chan; // if non-zero, sleeping on chan
int killed; // if non-zero, have been killed
int xstate; // exit status to be returned to parent's wait
int pid; // process id
// wait_lock must be held when using this:
struct proc *parent; // parent process
// these are private to the process, so p->lock need not be held.
uint64 kstack; // virtual address of kernel stack
uint64 sz; // size of process memory (bytes)
pagetable_t pagetable; // user page table
struct trapframe *trapframe; // data page for trampoline.s
struct context context; // swtch() here to run process
struct file *ofile[nofile]; // open files
struct inode *cwd; // current directory
char name[16]; // process name (debugging)
};它的设计理念与注意事项同cpu。
五、上下文切换
上下文切换可以简单地理解为在调度前保护现场或恢复现场(保护或恢复cpu中的寄存器组),而xv6中的上下文特指以下寄存器:
- ra
- sp
- s0
- s1
- s2
- s3
- s4
- s5
- s6
- s7
- s8
- s9
- s10
- s11
函数swtch(使用汇编语言编写)负责内核线程切换的保护和恢复。它有两个参数第一个参数是old context,第二个参数是new context,它会将当前寄存器保存至old context中,而从new中加载寄存器并返回。
void swtch(struct context*, struct context*);swtch不直接知道线程,只是保护和恢复寄存器组,该寄存器组称为上下文。
.globl swtch
swtch:
sd ra, 0(a0)
sd sp, 8(a0)
sd s0, 16(a0)
sd s1, 24(a0)
sd s2, 32(a0)
sd s3, 40(a0)
sd s4, 48(a0)
sd s5, 56(a0)
sd s6, 64(a0)
sd s7, 72(a0)
sd s8, 80(a0)
sd s9, 88(a0)
sd s10, 96(a0)
sd s11, 104(a0)
ld ra, 0(a1)
ld sp, 8(a1)
ld s0, 16(a1)
ld s1, 24(a1)
ld s2, 32(a1)
ld s3, 40(a1)
ld s4, 48(a1)
ld s5, 56(a1)
ld s6, 64(a1)
ld s7, 72(a1)
ld s8, 80(a1)
ld s9, 88(a1)
ld s10, 96(a1)
ld s11, 104(a1)
ret当一个进程放弃cpu时,进程的内核线程会调用swtch保护自己的上下文并返回到调度器的上下文。
每个上下文都包含在一个结构体context中,而context又被包含于进程的结构体proc或cpu的结构体cpu中。
// saved registers for kernel context switches.
struct context {
uint64 ra;
uint64 sp;
// callee-saved
uint64 s0;
uint64 s1;
uint64 s2;
uint64 s3;
uint64 s4;
uint64 s5;
uint64 s6;
uint64 s7;
uint64 s8;
uint64 s9;
uint64 s10;
uint64 s11;
};
当发生定时器中断时,usertrap调用yield,yield会调用sched,sched会调用swtch,如下:
swtch(&p->context, &mycpu()->context);这条语句会将当前上下文保存至p->context(旧线程)中,然后切换到mycpu->context(调度器的上下文)。
六、进程的切换
从一个用户进程切换到另一个用户进程涉及下面步骤(顺序):
- 通过系统调用或中断进入旧用户进程的内核线程
- 上下文切换到当前cpu调度器线程
- 上下文切换到新进程的内核线程
- 通过trap返回新用户进程
上面的过程可用下图表示。
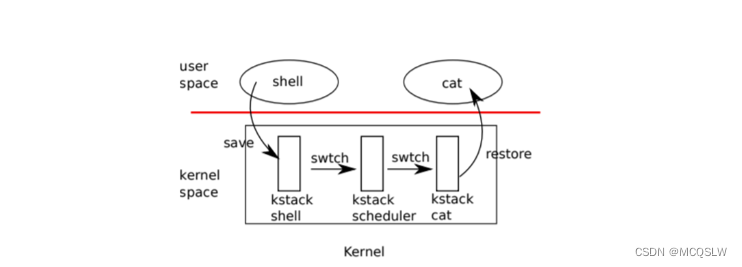
xv6的调度器线程在每个cpu上都有一个专有的内核栈,因为从上面可以知道,调度器线程作为进程切换的中介。
总而言之,xv6的用户进程的切换不会是两个用户进程间的直接切换,而是采取用户进程①——cpu调度器线程——用户进程②这种方式实现的间接切换。
进程的切换涉及到yield、sched、swtch与scheduler这四个函数。下面我将按照进程切换的步骤依次讲解yield、sched与scheduler这三个函数。
(一)yield
当定时器中断被响应后,yield函数就会执行。
yield名为放弃,即调用此函数的进程会放弃cpu,所以有了这句话:
p->state = runnable;调用yield的进程的状态会被置为runnable(就绪状态),该状态意味着该进程没有在运行,但已经准备好去运行。
这时问题就来了,就目前而言,该进程正运行在当前进程的内核线程中。为了保证该进程不会被另一个cpu运行,我们在这里加了锁。这样一来,就不会出现该进程在两个cpu上运行的情况。
由于xv6是单线程,如果不加锁,另一个cpu也运行该进程,那么就会出现两个cpu在同一个栈上运行的情况。
然后就轮到sched函数了。
(二)sched
sched的主要作用就是检测当前要放弃cpu的进程是否存在问题,若没问题,就进行上下文切换
(三)scheduler
现在运行的程序是cpu调度器线程,具体的函数就是scheduler。
scheduler会找到一个就绪状态的线程,并更新该线程的状态为running,然后进行上下文切换。
上下文切换的目的仍然是两个——得到新线程的上下文与进入到新线程中执行。
现在,请读者想想,进行上下文切换后的ra中存储的地址指向哪里?
显然应该是指向sched函数中的语句,因为切换到的新线程必然是之前同样由于定时器中断处于就绪状态的线程。
现在程序会正常执行完毕sched与yield,只不过此时执行这些函数的不是以前的线程,而是新线程,或者说是之前由于定时器中断而被暂停的线程。
这是非常值得玩味的一点!!!
正因为如此,sched与scheduler这两个程序可以视作彼此的协程。
这样一来,就完成了一次进程切换。
七、进程的交互
进程调度让一个进程对于另一个进程而言是透明的,但在有些情况下,我们需要进程间进行交互。即在一个进程中操纵本进程或其他进程的执行,典型的操纵机制就是睡眠(sleep)与唤醒(wakeup)机制。这个机制又被称为序列协调或条件同步机制。我们通过下面的一个例子引出睡眠与唤醒机制。
(一)为什么使用睡眠与唤醒机制
考虑一个信号量,它协调生产者与消费者。信号量维护一个计数并提供两个操作。v操作增加计数值(只有生产者拥有此操作),p操作减少计数值(只有消费者拥有此操作),考虑只有一个生产者和一个消费者。我们可以有下面代码:
struct semaphore
{
struct spinlock lock;
int count;
};
void v(struct semaphore *s)
{
acquire(&s->lock);
s->count += 1;
release(&s->lock);
}
void p(struct semaphore *s)
{
while (s->count == 0)
;
acquire(&s->lock);
s->count -= 1;
release(&s->lock);
}上面代码的问题就是,如果生产者很少生产,那么消费者会将大量时间浪费在等待的while循环上。因此我们考虑一种机制,这种机制使得当s为0时,消费者放弃cpu,并只有当s非0时,消费者才得到cpu。这便是睡眠与唤醒机制的思想。
我们修改代码如下:
void v(struct semaphore *s)
{
acquire(&s->lock);
s->count += 1;
wakeup(s); // 修改
release(&s->lock);
}
void p(struct semaphore *s)
{
while (s->count == 0)
sleep(s); // 修改
acquire(&s->lock);
s->count -= 1;
release(&s->lock);
}当s为0时,消费者就调用sleep放弃cpu,形象地说消费者睡在chan(管道)上,chan称为等待通道。而wakeup唤醒所有在chan上sleep的进程(前提是chan上有睡眠的进程)并让它们的sleep调用返回。如果没有进程在chan上,wakeup就不做任何事。
改进后的代码会提高效率,但仍然存在问题。考虑如下情况,当s为0且p恰好执行完毕while的条件判断语句:
s->count == 0此时v又将s改为非0并调用wakeup,wakeup没有在chan上发现睡眠的进程,于是什么也不做。而p继续执行下面的语句:
sleep(s);这时消费者睡眠,但s却非0。除法生产者再次调用v,否则消费者将永远毫无意义地等待。这便是丢失唤醒问题。
从不变量理论的角度看,这个问题的根源是在错误时刻运行的v违反了p只在特定条件下睡眠的这个不变量,保护该不变量的方法是将更多的操作原子化,如下面的代码:
void
v(struct semaphore *s)
{
acquire(&s->lock);
s->count += 1;
wakeup(s);
release(&s->lock);
}
void
p(struct semaphore *s)
{
acquire(&s->lock); // 修改
while(s->count == 0)
sleep(s);
s->count -= 1;
release(&s->lock);
}这虽然解决了丢失唤醒问题,但却引出新的问题。消费者睡眠后拥有着锁,这让生产者无法增加s,于是导致死锁。
所以,我们可以将锁引入到睡眠与唤醒机制中。如下修改代码:
void
p(struct semaphore *s)
{
acquire(&s->lock);
while(s->count == 0)
sleep(s, &s->lock); // 修改
s->count -= 1;
release(&s->lock);
}修改sleep的接口,在调用sleep后,便会释放锁,而在wakeup唤醒睡眠进程后,sleep便会让被唤醒进程获得锁并返回,这就解决了死锁问题。
(二)具体实现
结合上面的分析,我们不难理解实现的原理。
1.sleep
void sleep(void *chan, struct spinlock *lk)
{
struct proc *p = myproc();
// must acquire p->lock in order to
// change p->state and then call sched.
// once we hold p->lock, we can be
// guaranteed that we won't miss any wakeup
// (wakeup locks p->lock),
// so it's okay to release lk.
acquire(&p->lock); //doc: sleeplock1
release(lk);
// go to sleep.
p->chan = chan;
p->state = sleeping;
sched();
// tidy up.
p->chan = 0;
// reacquire original lock.
release(&p->lock);
acquire(lk);
}
2.wakeup
void wakeup(void *chan)
{
struct proc *p;
for(p = proc; p < &proc[nproc]; p++) {
if(p != myproc()){
acquire(&p->lock);
if(p->state == sleeping && p->chan == chan) {
p->state = runnable;
}
release(&p->lock);
}
}
}
(三)使用睡眠唤醒机制的典型例子——管道
经过上面的分析,我们可以知道任何涉及生产者和消费者问题的功能都可以考虑睡眠唤醒机制,典型的例子就是管道。
管道本质上是一个双端队列,一头读,一头写,xv6使用一块内存缓冲块实现管道。

管道的数据结构:
#define pipesize 512
struct pipe {
struct spinlock lock;
char data[pipesize];
uint nread; // number of bytes read
uint nwrite; // number of bytes written
int readopen; // read fd is still open
int writeopen; // write fd is still open
};实现管道的缓存块是一个循环队列。 所以管道空的条件是:
pi->nread == pi->nwrite管道满的条件是:
pi->nwrite == pi->nread + pipesize
参考资料:
[1] xv6-riscv-book-chinese/chapter-7.md at main · frankzn/xv6-riscv-book-chinese (github.com)
赞 (0)
您想发表意见!!点此发布评论





发表评论