如何解决缓存数据不一致性问题
297人参与 • 2025-01-11 • 缓存
1. 数据不一致的原因
1.1 双写导致数据不一致
由于分布性系统,不能保证每个节点都可用,所有可能引起 redis 在极限情况下数据没有写入成功,那么此时缓存中的数据和数据库数据不一致。
数据的更新为什么会成功:因为事务保证数据不管是成功还是失败,都不会有脏数据。
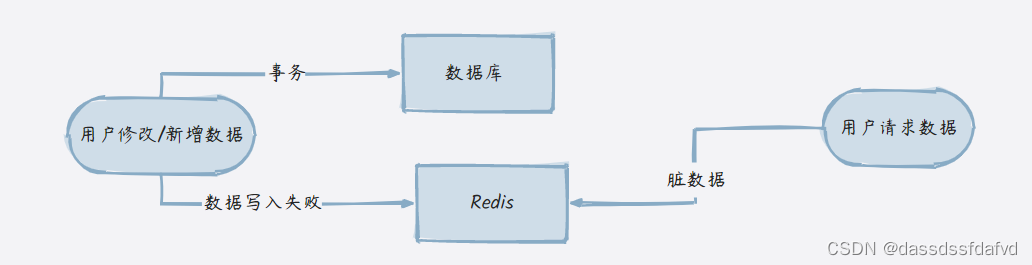
1.2 高并发导致数据不一致
数据在修改的过程中必定会存在网络延时,因为分布式系统节点相互独立部署,那么在并发读的情况之下,还没来得及修改完,那么对于读操作,读到的数据都是老的数据
如果是某些不严谨的情况,无所谓,如果是极致的严谨,那么就不能这么做了。比如我们的环境监测,大气的一些数据会每隔1-2分钟更新,甚至有的是5分钟更新,所以如果读到的是一些老的数据,是没有关系的,因为最终几秒或者几十秒以后会更新,这些数据的来去不会很大,而且我们能容忍一定的误差,所以也就无所谓了。
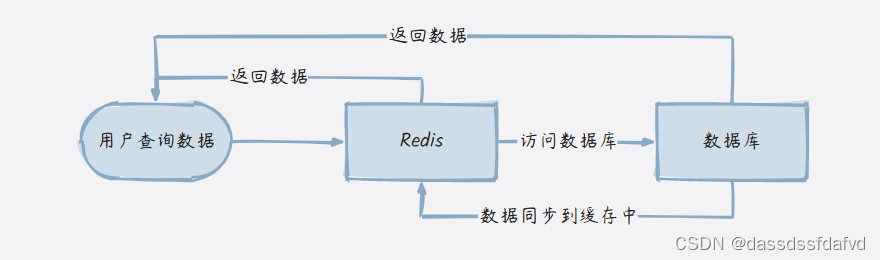
2. 查询数据的逻辑
先请求先到 redis,如果命中则返回结果。如果 redis 中没有数据,则从数据库查询,再写入到缓存中,再返回结果。
3. 更新数据的逻辑
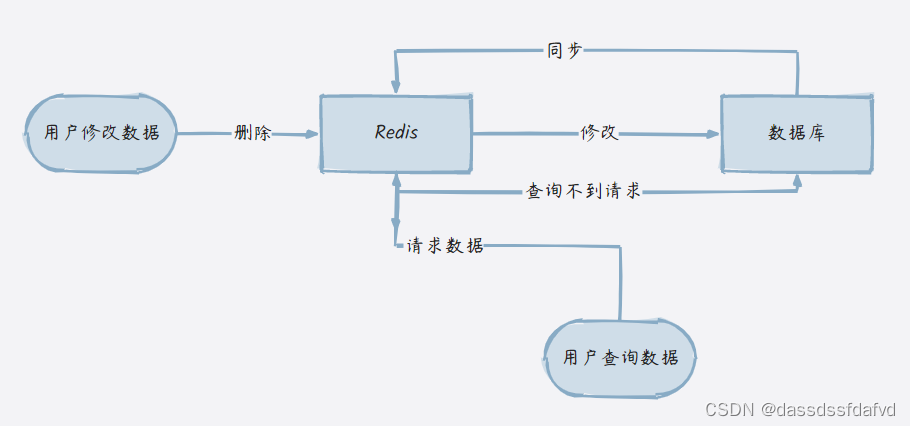
3.1 先删除缓存,再更新数据库
3.1.1 方案一
在并发不高的情况下:先删除 redis 中的旧数据。更新数据库中的数据。再将数据库中的数据同步到 redis 中。
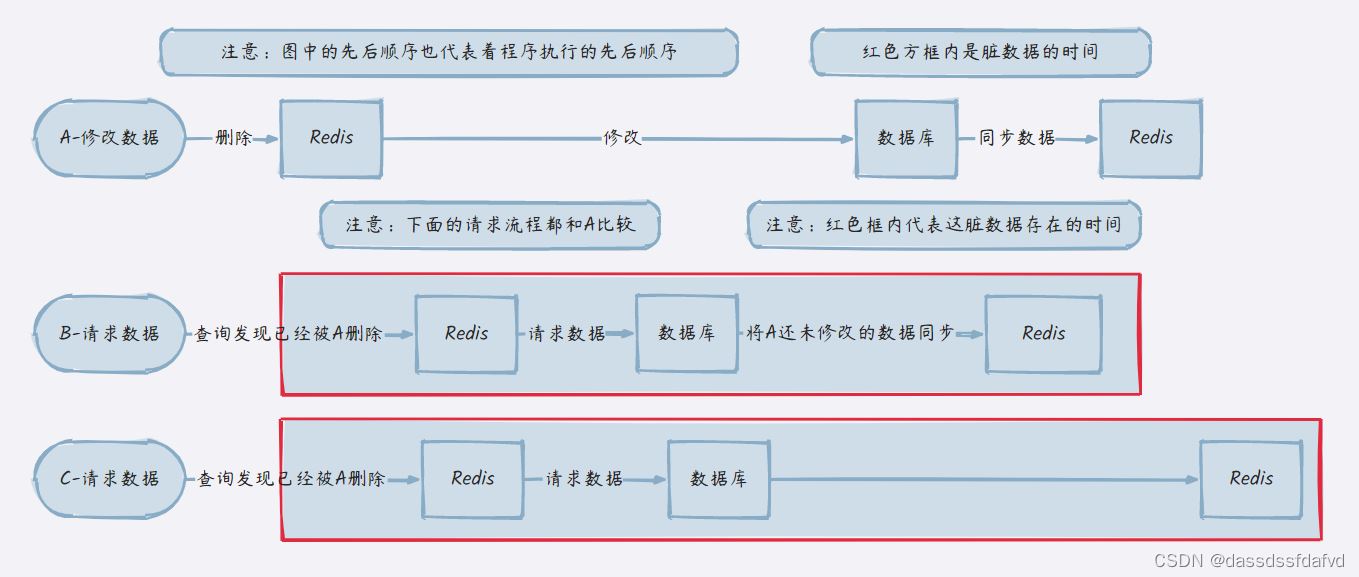
3.1.2 方案二
在高并发的情况下,假设有请求 a 进行更新操作,另一个请求 b 进行查询操作,那么有可能会出现:
- a 进行更新操作前,先删除了缓存
- b 查询发现缓存不存在
- b 查询数据库的旧值
- b 将旧值写入到缓存
- a 执行更新,将新值写入到数据库
- 后续的请求因为发现缓存中有数据,导致 a 更新的数据一直无法更新到缓存中,这样便出现了数据库与缓存不一致的情况。
3.2 先更新数据库,再删除缓存
3.2.1 方案一
该方案虽然存在并发问题,但是出现上述情况的概率是极低的,也有一些企业在使用这种方案。
在超高并发下,请求 a 执行更新操作,请求 b 进行查询操作:
- b 将新值写入到数据库
- a 查询 redis 得到旧数据
- 线程 b 删除缓存
- 这样就会导致 a 修改数据 —> a 删除 redis 之间出现脏数据。
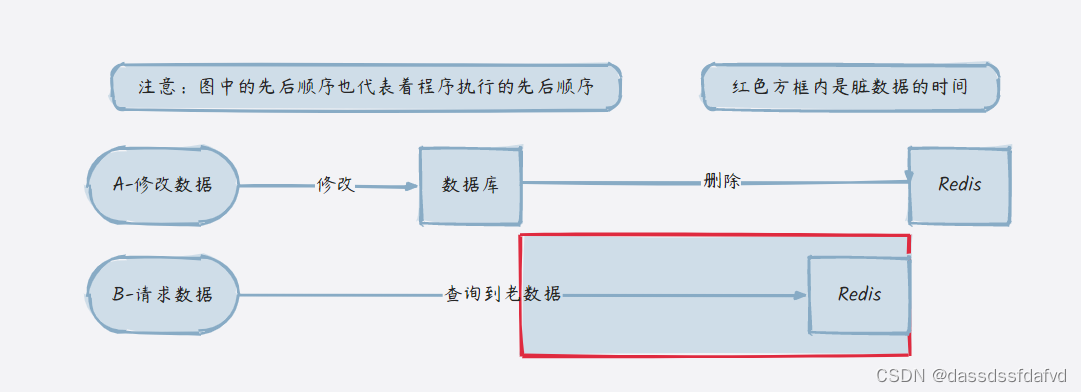
3.2.2 方案二
在超高并发下,请求 a 执行更新操作,请求 b 进行查询操作:
- 缓存刚好失效
- b 查询数据库,得到一个旧值
- a 将新值写入到数据库
- 线程 a 删除缓存
- b 将旧值写入到缓存
- 这样就会导致后续的请求之间出现脏数据。
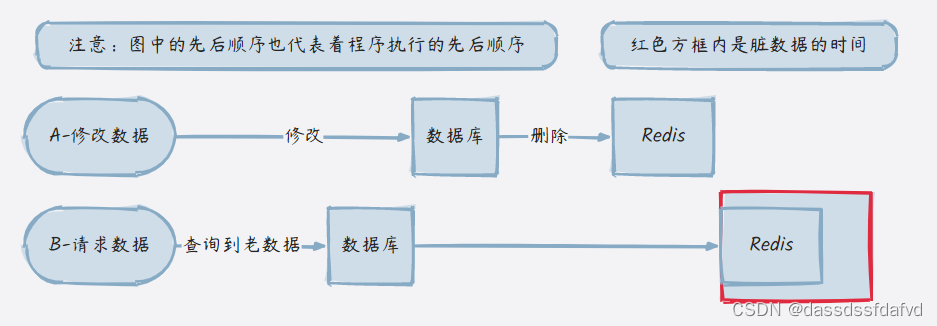
3.3 缓存双删方案
它的流程为:
- 先删除缓存
- 再写数据库
- 休眠一段时间,再删除缓存
回顾一下方案“先删除缓存,再更新数据库”可能造成数据库与缓存不一致的情况。
假设有请求 a 进行更新操作,另一个请求 b 进行查询操作,如果使用缓存双删策略:
- a 进行更新操作前,先删除了缓存
- b 查询发现缓存不存在
- b 查询数据库的旧值
- b 将旧值写入到缓存
- a 执行更新,将新值写入到数据库,执行休眠 thread.sleep(t)
- a 苏醒,再次将缓存中的值删除
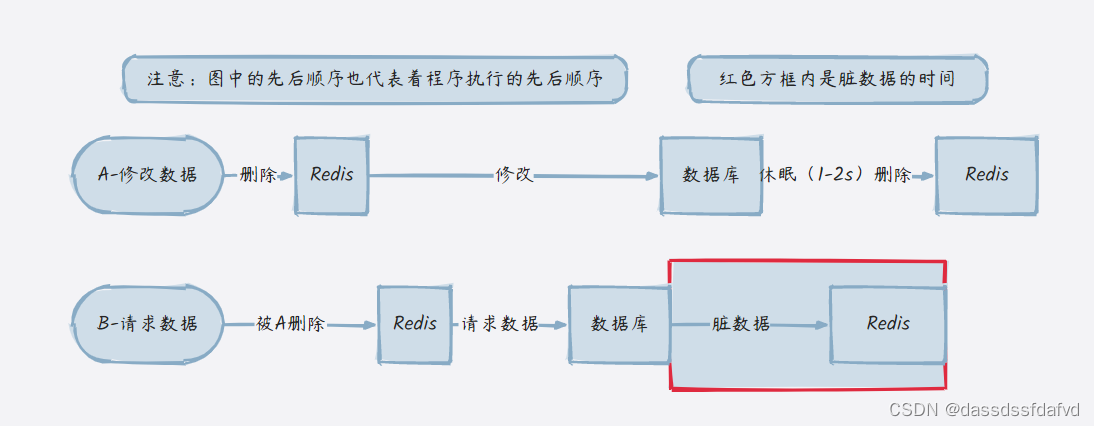
缓存双删的优点是大大降低了数据库与缓存不一致的概率的发生,注意这里只是降低,并不是说完全的避免,途中红框的地方就是缓存脏数据的时间,缺点为一定程度上降低了吞吐量,因为系统进行了休眠
这里为什么要采用休眠,对数据进行延迟缓存,原因是
- 例如:如果在 a 删除缓存之后,数据库修改之间 c 再次请求数据库,将老的信息存储进缓存,那么后续所有的请求打在缓存中,还是获取到老的数据
- 在分库分表的情况下,延迟一定的时间,也保证了,修改后的数据全部同步到所有的数据库中。
4. 扩展:其它的解决双写一直问题
通过监听数据库日志,来修改 redis 的数据,使数据的修改达到准实时的级别,例如:canal。但是这种情况下会有一些时间的延迟,也会短暂的产生脏数据。这种情况适用于写多读少的场景
完全使用缓存作为数据库,后面在定时任务修改数据库数据。这种情况下,没要求对 redis 的三高要求非常高,可以采用云厂商的 redis 服务。
读取的时候只提供 redis,也就是说,当更新操作一开始从 redis 中删除数据了,用户去读 redis,如果没有是不会从数据库中读的,因为只提供 redis 的读取,写入的时候只在数据新增以及更新后才会放入到 redis,那么如此一来,并发读的时候就不会从数据库读取老的数据并且放入 redis 中了。没有读到也没关系,做一些空数据的处理,可能会有个几百毫秒或者 1-2s 的延迟,但是可以忍受。但是要注意做好缓存穿透的校验处理。
5. 缓存数据的思考
我们能放入缓存的数据本就不应该是实时性、一致性要求超高的,所以缓存数据的时候加上过期时间,保证每天拿到当前最新数据即可。
我们不应该过度设计,增加系统的复杂性,遇到实时性、一致性要求高的数据,就应该查数据库,即使慢点。
超高并发场景的一致性,都是最终一致性,也就是弱一致性,所以要考虑每一个环节可能失败的情况,补偿 job 也是常有的。
总结
以上为个人经验,希望能给大家一个参考,也希望大家多多支持代码网。
赞 (0)
您想发表意见!!点此发布评论





发表评论