DLSS 4让帧数突破显示极限! 技嘉RTX 5080超级雕显卡评测
1013人参与 • 2025-02-17 • 显卡
完整的gb202核心包含192个sm单元,每个sm包含128个cuda核心;1个第4代rt core;4个第5代tensor core;4个纹理单元。1个256kb的寄存器文件和128kb的l1共享缓存,它可以根据图形和计算工作负载的需要配置不同的大小。
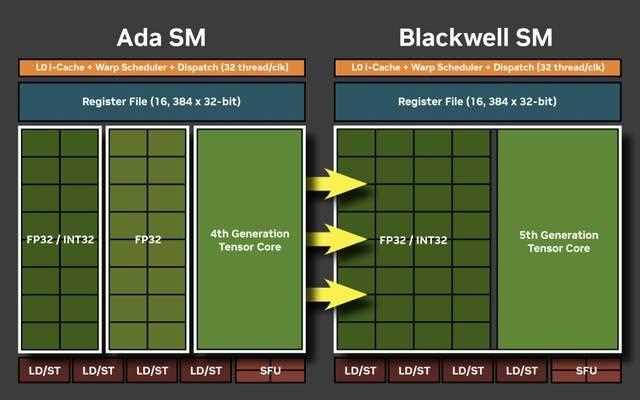
在blackwell架构的sm单元中,int32整数运算的数量增加了一倍。与ada架构的sm单元相比,实现了int32与fp32内核的完全统一。不过在时钟周期内,统一内核只能作为fp32或int32内核运行。
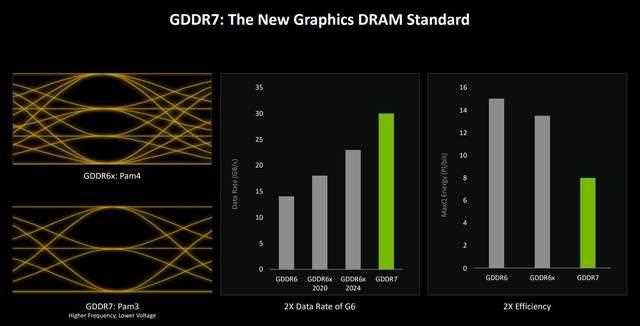
与blackwell架构一同推出的还有gddr7显存,采用pam3信号技术,它有着更高频率与更低电压的特点。
本代rtx 5090配备28 gbps gddr7显存,峰值显存带宽可达1792gb/s/秒,而rtx 5080配备更高的30 gbps时钟频率的gddr7显存,峰值内存带宽可达960 gb/秒。结合新的引脚编码方案,gddr7实现了显著增强的信噪比(snr)。
通过增加信道密度、改进的pam3信噪比、先进的均衡方案、重新设计的时钟架构和增强的i/o训练,gddr7提供了更高的带宽。这些进步还显著提高了能源效率,提供了更好的性能和延长电池寿命,特别是在移动端,或功率受限的系统中。
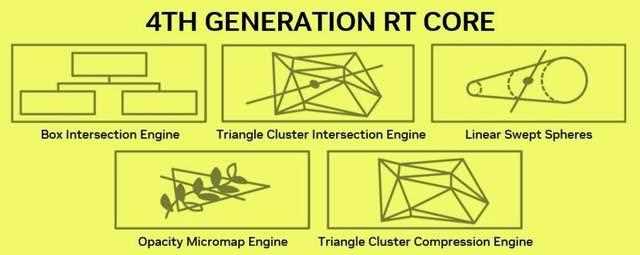
blackwell 第4代rt core
在第4代rt core中,简单来说它相比ada架构,在渲染光线追踪场景时,提供了两倍光线三角形相交测试吞吐量,并引入了mega geometry的结构算法。
opacity micromap engine
不透明微引擎在ada架构中已经引入,这里不再过多讲述,它主要的作用是优化光线追踪渲染,可大幅减轻着色器的工作负担。
比如树叶之类的复杂物体,不同的光线都会影响它的表现状态,以及树叶之间的光线反弹,所以对于光线追踪的计算量是巨大的。
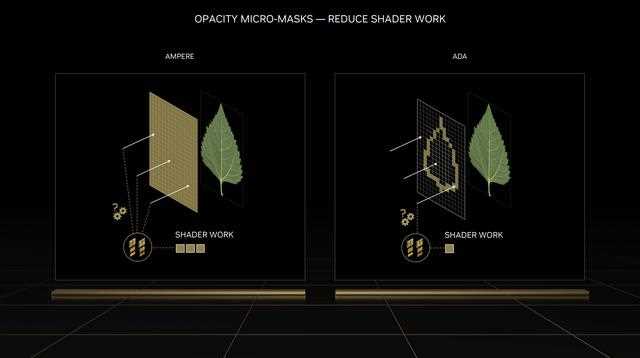
不过opacity micromap engine可以将光线追踪特性烘焙到不透明蒙版中,所以那些不规则形状和半透明的对象,也就能够更快更精准的渲染出来,从而极大减轻着色器的工作负担。
rtx mega geometry
除了上面提到的opacity micromap engine,在blackwell架构中,还引入了mega geometry(大型几何)的运算概念。其中包含了triangle clusterintersection engine、linear swept spheres等新硬件。
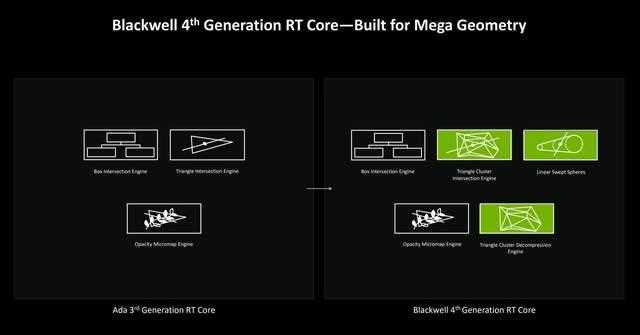
新的blackwell rt核心包含一个triangle clusterintersection engine三角形群集交集引擎,它能够进一步加速大型几何的光线追踪,同时它的工作还包含标准的光线三角形交集测试。linear swept spheres则主要用于光线追踪中精细的几何形状,比如发丝。
rtx mega geometry的理念与虚幻5引擎的nanite虚拟微多边形几何体系统相同,在现代游戏中,模型更加细致,需要渲染的工作量大幅增加,如果全部按照最精细的级别处理,将会耗费极大的计算资源,所以将lod分级便应运而生。
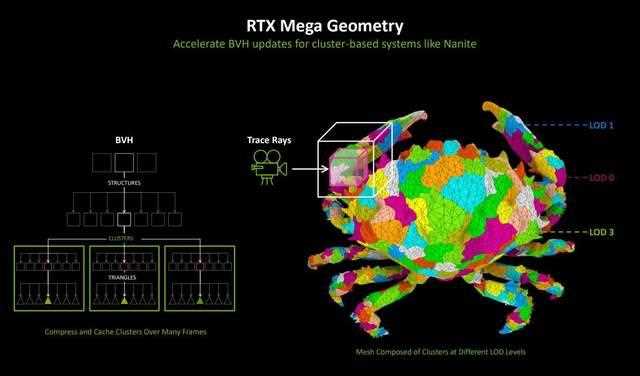
简单来说,就是根据一个物体距离摄像机的远近,来调节物体的细节水平。此前《黑神话:悟空》便应用了这样的技术,它消除了lod的繁琐任务,可以扫描并导入极高精细程度的模型。并且,这不会影响性能。仍然可以获得实时帧速率。
在rtx mega geometry中提供了新的bvh构建功能,它采用三角形集群作为一级基元。新的集群加速结构cluster-level acceleration structures(clas)可以从256个三角形空间紧凑批次中生成,然后使用clas集合作为输入来构建最终的bvh。
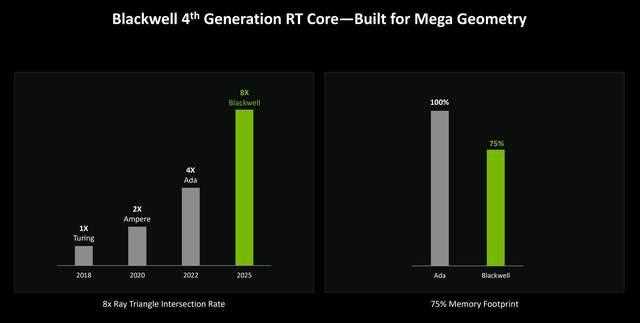
不过虚幻5引擎并非专为blackwell而设计,rtx mega geometry的工作只是更高效的让游戏引擎调用api。由于其输入参数完全由gpu内存驱动,游戏引擎可以在gpu上更高效的运行lod选择、动画、剔除等逻辑。同时最大限度减少对cpu的往返,进而减少与bvh管理相关的cpu开销。
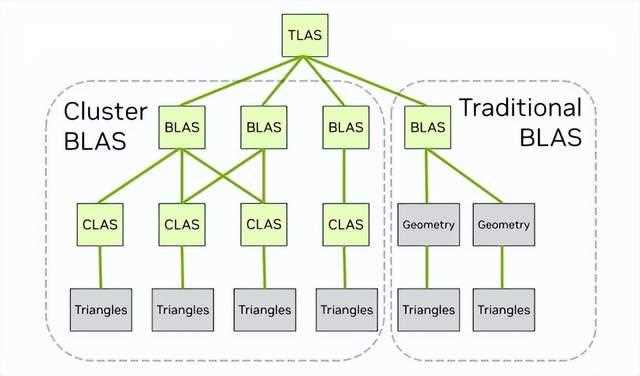
然而在更加精细化的游戏引擎中,按照传统的流程,应用程序必须从场景中的每一帧的所有对象中构建一个顶层加速结构。而随着更大的世界规模以及繁杂的场景物体,仅靠lod分级仍然难以实现质的变化。
为了解决这个问题,rtx mega geometry引入了一种新型的顶层加速结构(tlas),称为分区顶层加速结构(ptlas)。
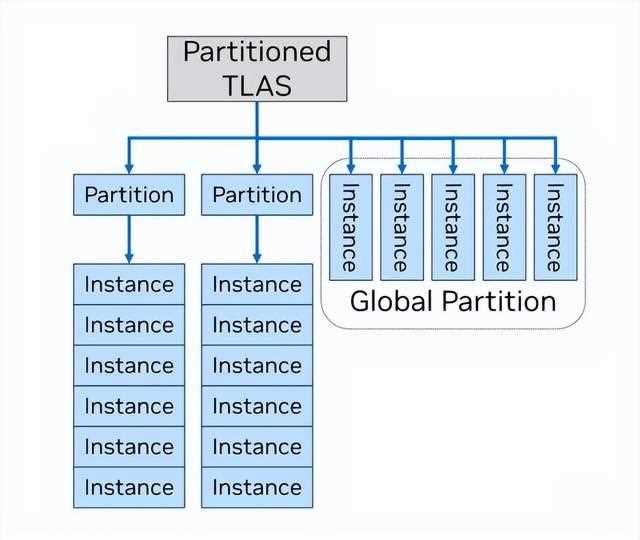
它无需在每一帧都从头开始构建一个新的tlas,ptlas能够辨别从一帧到另一帧,哪些对象是静态的。
应用程序通过将对象聚合到分区中,并仅更新那些已更改的对象来节省开销。

例如,游戏可以将静态游戏世界的各个部分放入所属的分区中,同时将动态对象分离到每帧重建的“全局分区”中。与传统的tlas相比,请求的分区更新越少,节省的运行时开销就越大。
另外好消息是,rtx mega geometry可通过底层api进行扩展支持,适用于所有支持光线追踪的nvidia gpu,也就是从图灵架构(turing)开始。
不过blackwell的第4代rt core是专门为rtxmega geometry而设计的,硬件中的特殊集群引擎实现了几何和bvh数据的新压缩方案,同时是第3代rt core光线三角形相交率的2倍。因此,blackwell架构可以实现用更小的显存,更高效的处理这些内容。
linear swept spheres (lss)
lss(线性扫描球体)是blackwell架构中新增的图形语言,它极大地简化了复杂头发和毛发的渲染开销,并能提升质量。
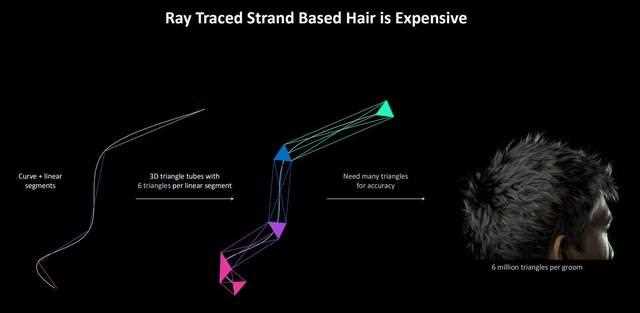
此前渲染头发仍然需要最基础的三角形来表达物体,如图所示,发丝中的一个线段需要6个三角形,而一根头发便需要无数个三角形来确保其精度。比如我们的头发则需要600万个三角形来表达。
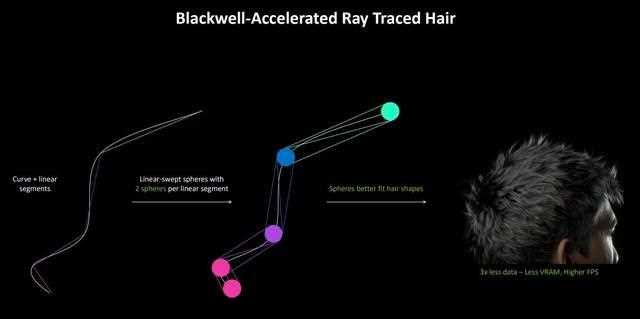
blackwell架构的rt core引入了lss新语言的支持,它类似于镶嵌曲线,允许灵活地近似各种链型。并且球体也更适合发行构建。
lss的引入可以让发型构建,减少3倍的数据量,速度大约快了2倍,并可以使用更少的显存,获得更高的帧数。
赞 (0)
您想发表意见!!点此发布评论






发表评论