DLSS 4让帧数突破显示极限! 技嘉RTX 5080超级雕显卡评测
1018人参与 • 2025-02-17 • 显卡
blackwell 第5代tensor core
本代架构除了rt core进行了改进升级,专门负责ai及高性能计算的tensor core也迎来了重大升级。
与nvidia ada tensor cores一样,blackwell架构的tensor cores支持fp16、bf16、tf32、int8、int4和hopper的fp8 transformer engine。
blackwell还增加了对fp4和fp6 tensor core操作的新支持,以及新的第二代fp8 transformer engine。
fp4精度支持
fp4提供了一种较低的量化方法,类似于文件压缩,可以减小模型大小,提升生成速度。与fp16精度(大多数型号发布的默认方法)相比,fp4只需要不到一半的显存。fp4使用nvidia tensorrt提供的量化方法,几乎没有质量损失。

例如,目前最强的ai绘画模型flux.dev ,在fp16上需要超过23gb的显存,而这意味着它只能由每一代的期间产品rtx 4090,rtx 5090和专业gpu来支持。
而对于fp4,flux.dev测试对显存的需求将少于10gb,让更多80级和70级的显卡均能在本地运行。

在性能和效果对比上,使用带有fp16的rtx 4090,flux.dev模型可以通过30个步骤在15秒内生成图像。使用带有fp4的rtx 5090,只需5秒多一点就可以生成图像。
dlss 4
dlss 4是本代rtx 50系显卡带来的重大更新,对于玩家来说它也是最能实际感受到的。最新版本dlss 4带来了新的多帧生成(mfg),具有更快的性能和更低的显存使用等特性。包含超分辨率(sr),光线重建(rr)和深度学习抗锯齿(dlaa)模型,可进一步增强图像质量和稳定性。
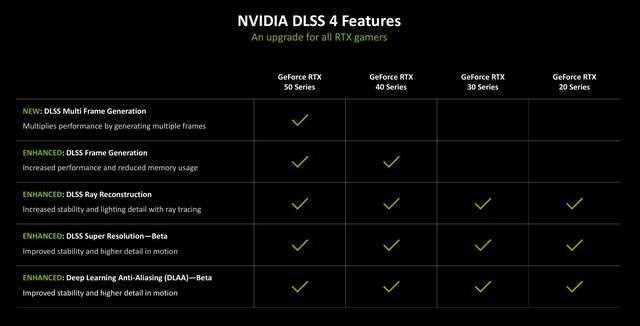
这些新技术由rtx 50系gpu和第5代tensor cores支持,并由云端的nvidia al超级计算机提供支持。不过对于手持rtx 40系或更早期显卡的玩家还无缘体会。dlss 4新增的多帧生成,目前仅支持rtx 50系显卡。
multi frame generation(多帧生成)
dlss多帧生成能够通过每个传统渲染帧,生成多达三帧的额外帧来提高fps。新的帧生成ai模型相比之前的帧生成方法快40%,使用的显存减少30%,并且每个渲染帧只需要运行一次就可以生成多个帧。高效的ai模型代替了上一代的硬件光流模型,从而加快了光流场的生成速度,并显著降低了生成额外帧的计算成本。
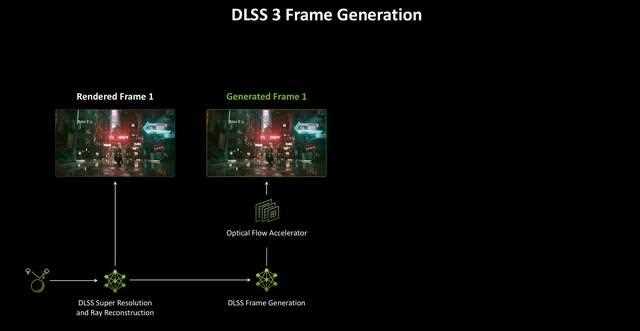
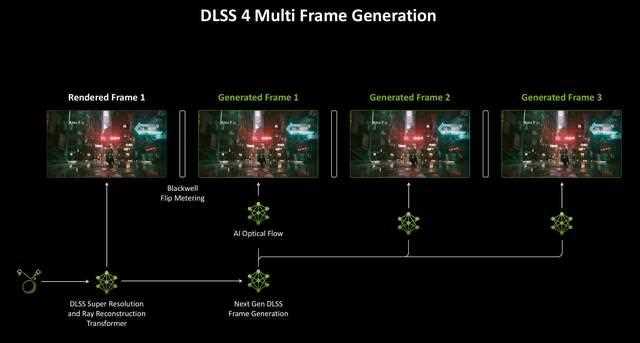
从生成帧的层面来说,上一代dlss 3帧生成基于cpu的帧节奏,而这种方式可能会让生成的帧与额外的帧混合在一起,导致每帧之间的帧节奏不太一致,影响平滑性。
为了解决生成多帧的复杂性,blackwell架构将帧节奏逻辑转移到显示引擎,使gpu能够更精确地管理显示时序,从而避免与额外帧混合的情况,进而提升帧生成的准确性及稳定性。

而第5代tensor cores拥有更高的计算能力,这使得它们能够更快地执行计算光流和生成多帧的一系列ai模型。并更好地调度dlss ai处理、图形渲染和帧速度算法。
transformer模型
此前dlss所用的模型为convolutional neural network,即我们熟悉的卷积神经网络(cnn),cnn的工作原理是将像素局部聚集在一起,并以树的形式从低到高地进行分析数据。这种结构的计算效率很高,这也是为什么它被称为卷积神经网络。

而dlss 4引入了基于transformer的ai模型,用于dlss超分辨率、dlss光线重建和深度学习抗锯齿(dlaa),从而提高图像质量和渲染平滑度。基于transformer模型体系结构的神经网络,擅长处理涉及顺序和结构化数据的任务。简单来说,就是transformer能够抓住“重点”,可以更好地理解和渲染复杂场景。
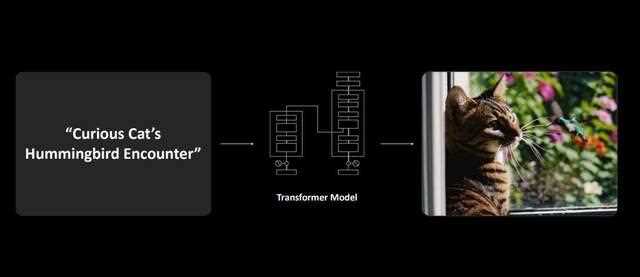
与cnn模型相比,transformer更容易在更大的像素窗口中识别更远距离的模式,具有一定的学习能力和“前瞻性”。
本代dlss 4将基于cnn的神经网络结构,转变为基于transformer的神经网络结构,在许多场景下图像质量都有着显著提升。
shader execution reordering (ser) 2.0
shader execution reordering(着色器重排序)是在rtx 40系架构中引入的一项技术,它可以使带有光追的程序有效地重组gpu上的大量并行线程,以最大限度地利用硬件。
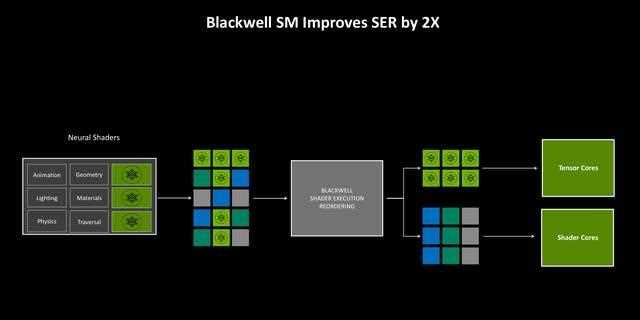
因为连贯执行神经工作负载的线程可以直接发送到tensor core,所以ser也显著加速了神经着色。在blackwell架构中,ser的核心重排序逻辑效率是原来的两倍,减少了重排序开销并提高了精度。从而进一步提高了该功能的有效性。这项功能更多地是为应用程序开发者而设计,它仅需一个小的api改动,即可执行重排序操作,进而提升总体项目的负载性能。
测试平台简介
首先介绍一下测试平台,为了保障aorus geforce rtx 5080 master 16g的性能发挥,我们的平台也再次进行了全面更新。
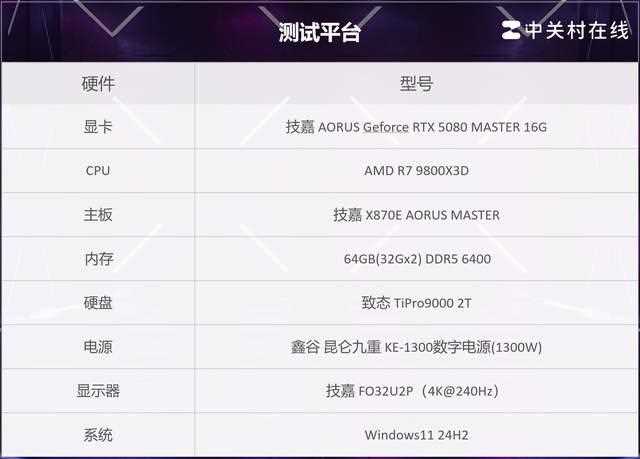
除了aorus geforce rtx 5080 master 16g这张显卡,处理器选择了amd r7 9800x3d游戏神u。
为了方便观察dlss 4在画质上的提升和4k高帧率带来的游戏变化。我们选择了技嘉fo32u2p oled显示器,这款显示器采用了4k@240hz的高分高刷规格,可完美适配dlss 4的多帧生成。而99%的dci-p3色域覆盖,更可细致入微地观察transformer模型带来的细节提升。

本次rtx 50系显卡采用了带宽速率更高的pcie5.0x16,应用于显卡的pcie5.0x16带宽速度高达128gb/s,用于固态硬盘的pcie5.0x4也高达32gb/s,致态tipro9000,实测顺序读写速度高达14526.95mb/s和13869.24mb/s,达到“满血”级别,可大幅提升操作系统/大型游戏/创作软件的响应和加载速度。
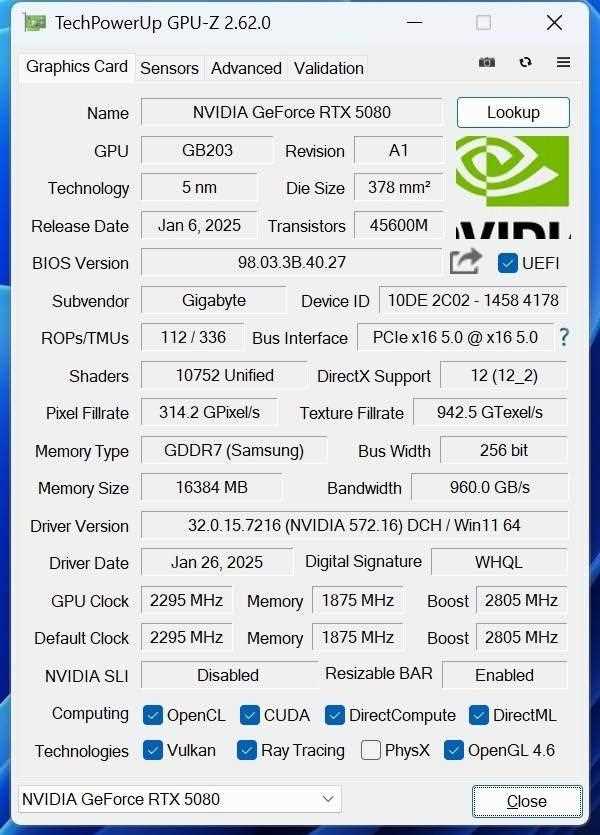
首先看一下gpu-z的参数,最新的2.62版本已经能够识别gpu信息。aorusgeforce rtx 5080 master 16g采用gb203核心,采用与上一代相同的tsmc 4nm定制工艺(tsmc 4nm 4n nvidiacustomprocess),芯片面积378mm2,相比于rtx 5090的750mm2小了一半。值得注意的是,在rtx 50系显卡中,使用了pcie×165.0带宽。
赞 (0)
您想发表意见!!点此发布评论






发表评论