protobuf简介及使用流程
208人参与 • 2025-02-26 • rust
1. protobuf是什么
protobuf(全称protocol buffer)是数据结构序列化和反序列化框架,它具有以下特点:
- 语⾔⽆关、平台无关:即 protobuf ⽀持 java、c++、python 等多种语⾔,⽀持多个平台
- ⾼效:即⽐ xml 更小、更快、更为简单
- 扩展性、兼容性好:你可以更新数据结构,而不影响和破坏原有的旧程序
2. protobuf使⽤流程介绍
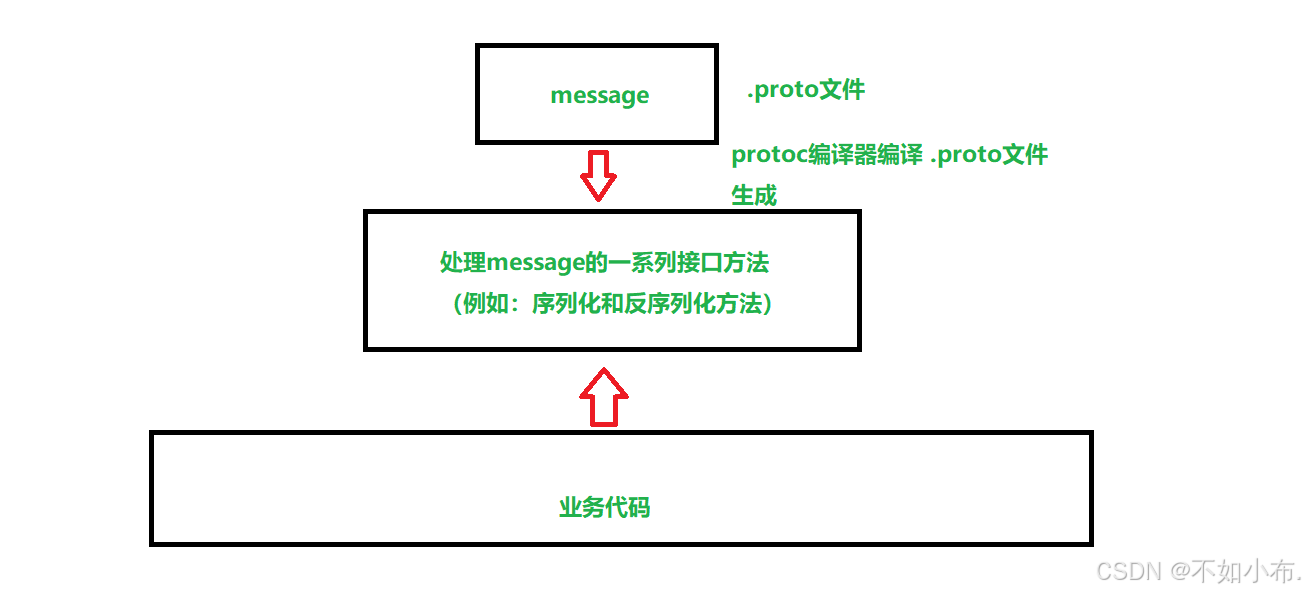
- 编写 .proto ⽂件,⽬的是为了定义结构对象(message)及属性内容。
- 使⽤ protoc 编译器编译 .proto ⽂件,⽣成⼀系列接⼝代码,存放在新⽣成头⽂件和源⽂件中。
- 依赖⽣成的接⼝,将编译⽣成的头⽂件包含进我们的代码中,实现对 .proto ⽂件中定义的字段进行设置和获取,和对 message 对象进行序列化和反序列化
3. protobuf快速上手
我们以⼀个简单通讯录的实现来驱动对protobuf的学习。在通讯录demo中,我们将实现:
- 对⼀个联系⼈的信息使⽤ protobuf 进⾏序列化,并将结果打印出来。
- 对序列化后的内容使⽤ protobuf 进⾏反序列,解析出联系⼈信息并打印出来。
- 联系⼈包含以下信息: 姓名、年龄。
通过通讯录demo,我们能快速的了解protobuf的使⽤流程。
3.1 创建 .proto ⽂件
- 创建 .proto ⽂件时,⽂件命名应该使⽤全⼩写字⺟命名,多个字⺟之间⽤ _ 连接。 例如:lower_snake_case.proto
- 书写 .proto ⽂件代码时,应使⽤ 2 个空格的缩进。
我们为通讯录 demo 新建⽂件: contacts.proto
3.2 添加注释
向⽂件添加注释,可使⽤ // 或者 /* … */
3.3 具体编写
指定 proto3 语法:
protocol buffers 语⾔版本3,简称 proto3,是 .proto ⽂件最新的语法版本。proto3 简化了 protocolbuffers 语⾔,既易于使⽤,⼜可以在更⼴泛的编程语⾔中使⽤。它允许你使⽤ java,c++,python等多种语⾔⽣成 protocol buffer 代码。在 .proto ⽂件中,要使⽤ syntax = “proto3”; 来指定⽂件语法为 proto3,并且必须写在除去注释内容的第⼀⾏。 如果没有指定,编译器会使⽤proto2语法。
在通讯录 demo 的 contacts.proto ⽂件中,可以为⽂件指定 proto3 语法,内容如下:
syntax = "proto3";
package 声明符:
package 是⼀个可选的声明符,能表⽰ .proto ⽂件的命名空间,在项⽬中要有唯⼀性。它的作⽤是为了避免我们定义的消息出现冲突。
在通讯录 demo 的 contacts.proto ⽂件中,可以声明其命名空间,内容如下:
package contacts;
定义消息(message):
消息(message): 要定义的结构化对象,我们可以给这个结构化对象中定义其对应的属性内容。在网络传输中,我们需要为传输双⽅定制协议。定制协议说⽩了就是定义结构体或者结构化数据,⽐如,tcp,udp 报⽂就是结构化的。再⽐如将数据持久化存储到数据库时,会将⼀系列元数据统⼀⽤对象组织起来,再进⾏存储。protobuf 就是以 message 的方式来⽀持我们定制协议字段,后期帮助我们形成类和⽅法来使用。
在通讯录 demo 中我们就需要为联系人定义⼀个 message:
.proto ⽂件中定义⼀个消息类型的格式为:
message 消息类型名{
}
消息类型命名规范:使⽤驼峰命名法,⾸字⺟⼤写。为 contacts.proto(通讯录 demo)新增联系⼈message
syntax = "proto3";
package contacts;
// 定义联系⼈消息
message peopleinfo {
} 定义消息字段:
在 message 中我们可以定义其属性字段,字段定义格式为:字段类型 字段名 = 字段唯⼀编号;
- 字段名称命名规范:全⼩写字⺟,多个字⺟之间⽤ _ 连接。
- 字段类型分为:标量数据类型 和 特殊类型(包括枚举、其他消息类型等)。
- 字段唯⼀编号:⽤来标识字段,⼀旦开始使⽤就不能够再改变。
样例:
// 声明语法版本
syntax = "proto3";
// 声明代码的命名空间
package contacts;
//结构化对象的描述
message peopleinfo{
// 各个字段描述: 字段类型 字段名 = 字段唯一编号
string name = 1;
int32 age = 2;
} 注:这⾥还要特别讲解⼀下字段唯⼀编号的范围:1 ~ 536,870,911 (2^29 - 1) ,其中 19000 ~ 19999 不可⽤。
19000 ~ 19999 不可⽤是因为:在 protobuf 协议的实现中,对这些数进⾏了预留。如果⾮要在.proto⽂件中使⽤这些预留标识号,例如将 name 字段的编号设置为19000,编译时就会报警。
值得⼀提的是,范围为 1 ~ 15 的字段编号需要⼀个字节进⾏编码, 16 ~ 2047 内的数字需要两个字节进⾏编码。编码后的字节不仅只包含了编号,还包含了字段类型。所以 1 ~ 15 要⽤来标记出现⾮常频繁的字段,要为将来有可能添加的、频繁出现的字段预留⼀些出来。
3.4 编译 contacts.proto 文件
编译命令⾏格式为:
protoc [--proto_path=import_path] --cpp_out=dst_dir path/to/file.proto
protoc 是 protocol buffer 提供的命令⾏编译⼯具。
--proto_path 指定被编译的.proto⽂件所在⽬录,可多次指定。可简写成 -i import_path 。如不指
定该参数,则在当前⽬录进⾏搜索。当某个.proto ⽂件 import 其他.proto ⽂件时,
或需要编译的 .proto ⽂件不在当前⽬录下,这时就要⽤-i来指定搜索⽬录。
--cpp_out= 指编译后的⽂件为 c++ ⽂件。
out_dir 编译后⽣成⽂件的⽬标路径。
path/to/file.proto 要编译的.proto⽂件编译 contacts.proto ⽂件命令如下:
protoc --cpp_out=. contacts.proto
编译 contacts.proto ⽂件后,会⽣成所选择语⾔的代码,我们选择的是c++,所以编译后⽣成了两个文件: contacts.pb.h contacts.pb.cc 。
对于编译⽣成的 c++ 代码,包含了以下内容 :
- 对于每个 message ,都会⽣成⼀个对应的消息类
- 在消息类中,编译器为每个字段提供了获取和设置⽅法,以及⼀下其他能够操作字段的方法
- 编辑器会针对于每个 .proto ⽂件⽣成 .h 和 .cc ⽂件,分别⽤来存放类的声明与类的实现
contacts.pb.h 部分代码展示:
class peopleinfo final : public ::protobuf_namespace_id::message {
public:
using ::protobuf_namespace_id::message::copyfrom;
void copyfrom(const peopleinfo& from);
using ::protobuf_namespace_id::message::mergefrom;
void mergefrom( const peopleinfo& from) {
peopleinfo::mergeimpl(*this, from);
}
static ::protobuf_namespace_id::stringpiece fullmessagename() {
return "peopleinfo";
}
// string name = 1;
void clear_name();
const std::string& name() const;
template <typename argt0 = const std::string&, typename... argt>
void set_name(argt0&& arg0, argt... args);
std::string* mutable_name();
protobuf_nodiscard std::string* release_name();
void set_allocated_name(std::string* name);
// int32 age = 2;
void clear_age();
int32_t age() const;
void set_age(int32_t value);
};上述的例⼦中:
- 每个字段都有设置和获取的方法, getter 的名称与⼩写字段完全相同,setter ⽅法以 set_ 开头。
- 每个字段都有⼀个 clear_ 方法,可以将字段重新设置回 empty 状态。
contacts.pb.cc 中的代码就是对类声明⽅法的⼀些实现,在这⾥就不展开了。
到这⾥有人可能就有疑惑了,那之前提到的序列化和反序列化⽅法在哪⾥呢?在消息类的⽗类messagelite 中,提供了读写消息实例的方法,包括序列化⽅法和反序列化⽅法。
class messagelite {
public:
//序列化:
bool serializetoostream(ostream* output) const; // 将序列化后数据写⼊⽂件
流
bool serializetoarray(void *data, int size) const;
bool serializetostring(string* output) const;
//反序列化:
bool parsefromistream(istream* input); // 从流中读取数据,再进⾏反序列化
动作
bool parsefromarray(const void* data, int size);
bool parsefromstring(const string& data);
};注意:
- 序列化的结果为⼆进制字节序列,⽽⾮⽂本格式。
- 以上三种序列化的⽅法没有本质上的区别,只是序列化后输出的格式不同,可以供不同的应⽤场景使⽤。
- 序列化的 api 函数均为const成员函数,因为序列化不会改变类对象的内容, ⽽是将序列化的结果保存到函数⼊参指定的地址中
序列化与反序列化的使用:
创建⼀个测试⽂件 test.cc,⽅法中我们实现:
- 对⼀个联系⼈的信息使⽤ pb 进⾏序列化,并将序列化结果打印出来。
- 对序列化后的内容使⽤ pb 进⾏反序列,解析出联系⼈信息并打印出来。
#include <iostream>
#include "contacts.pb.h"
using namespace std;
int main()
{
string people_str;
{
contacts::peopleinfo people;
people.set_age(20);
people.set_name("忘忧");
if(!people.serializetostring(&people_str))
{
cout << "序列化联系人失败" <<endl;
}
cout << "序列化之后的 people_str: " << people_str << endl;
// 反序列化
{
contacts::peopleinfo people;
if(!people.parsefromstring(people_str))
{
cout << "反序列化联系人失败" <<endl;
}
cout << "parse age: " << people.age() << endl;
cout << "parse name: " << people.name() << endl;
}
}
return 0;
}代码书写完成后,编译 test.cc,生成可执行程序:
g++ test.cc contacts.pb.cc -o test -std=c++11 -lprotobuf
执⾏可执⾏程序,可以看⻅ people 经过序列化和反序列化后的结果:
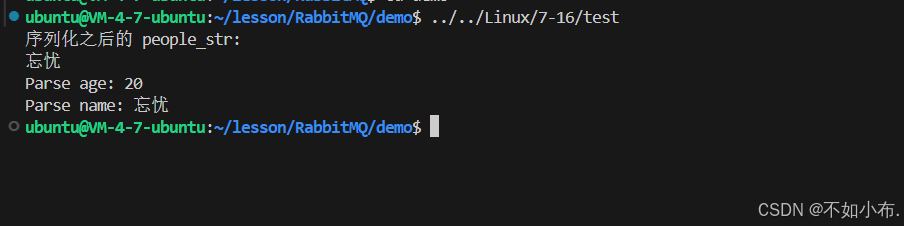
由于 protobuf 是把联系⼈对象序列化成了⼆进制序列,这⾥⽤ string 来作为接收⼆进制序列的容器。所以在终端打印的时候会有换⾏等⼀些乱码显⽰。另外相对于 xml 和 json 来说,因为pb被编码成⼆进制,破解成本增⼤,protobuf 编码是相对安全的。
到此这篇关于protobuf简介及使用流程的文章就介绍到这了,更多相关protobuf使用内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!
赞 (0)
您想发表意见!!点此发布评论





发表评论