Java实现markdown格式内容转换为word
131人参与 • 2025-03-08 • Java
前言
最近有个需求,就是需要在项目中,初始添加的信息后,将详情页面导出为word文档,下载下来可以继续编辑。一开始考虑word的样式,字体等问题,使用开源的apache poi,在保存为word内容时候,样式基本上会丢失,导致导出后的文档样式和在页面上看的不太一样,会出现错位等情况,希望使用商业版的word处理工具,比如aspose words或者spire.doc for java(spire.doc for java 中文教程)非常专业,功能非常强大。但是付费商业方案被否了,后来推荐直接导出为pdf格式,这样后端基本上也不用处理,导出pdf后,使用adobe acrobat在转换成word即可,最后给了一个方案就是页面保存为markdown格式内容到数据库,然后下载时候,后端将markdown转换为word即可。
实现步骤
首先添加java处理的相关依赖:
<!-- excel工具 练习的项目自身的依赖-->
<dependency>
<groupid>org.apache.poi</groupid>
<artifactid>poi-ooxml</artifactid>
<version>4.1.2</version>
</dependency>
<!-- 新添加的依赖-->
<!-- markdown格式转换为html -->
<dependency>
<groupid>org.commonmark</groupid>
<artifactid>commonmark</artifactid>
<version>0.21.0</version>
</dependency>
<!-- poi-tl和poi-tl-plugin-markdown是处理markdown格式转换为word格式,处理只处理markdown转换为html,只需要commonnark依赖即可-->
<dependency>
<groupid>com.deepoove</groupid>
<artifactid>poi-tl</artifactid>
<version>1.10.1</version>
</dependency>
<dependency>
<groupid>com.deepoove</groupid>
<artifactid>poi-tl-plugin-markdown</artifactid>
<version>1.0.3</version>
</dependency>编写工具类
package com.xiaomifeng1010.common.utils;
import com.deepoove.poi.xwpftemplate;
import com.deepoove.poi.config.configure;
import com.deepoove.poi.data.style.*;
import com.deepoove.poi.plugin.markdown.markdownrenderdata;
import com.deepoove.poi.plugin.markdown.markdownrenderpolicy;
import com.deepoove.poi.plugin.markdown.markdownstyle;
import lombok.experimental.utilityclass;
import lombok.extern.slf4j.slf4j;
import org.apache.poi.xwpf.usermodel.xwpftable;
import org.apache.poi.xwpf.usermodel.xwpftablecell;
import org.commonmark.node.node;
import org.commonmark.parser.parser;
import org.commonmark.renderer.html.htmlrenderer;
import org.springframework.core.io.classpathresource;
import javax.servlet.http.httpservletresponse;
import java.io.file;
import java.io.ioexception;
import java.io.inputstream;
import java.net.urlencoder;
import java.nio.charset.standardcharsets;
import java.util.hashmap;
import java.util.map;
/**
* @author xiaomifeng1010
* @version 1.0
* @date: 2024-08-24 17:23
* @description
*/
@utilityclass
@slf4j
public class markdownutil {
/**
* markdown转html
*
* @param markdowncontent
* @return
*/
public string markdowntohtml(string markdowncontent) {
parser parser = parser.builder().build();
node document = parser.parse(markdowncontent);
htmlrenderer renderer = htmlrenderer.builder().build();
string htmlcontent = renderer.render(document);
log.info(htmlcontent);
return htmlcontent;
}
/**
* 将markdown格式内容转换为word并保存在本地
*
* @param markdowncontent
* @param outputfilename
*/
public void todoc(string markdowncontent, string outputfilename) {
log.info("markdowncontent:{}", markdowncontent);
markdownrenderdata code = new markdownrenderdata();
code.setmarkdown(markdowncontent);
markdownstyle style = markdownstyle.newstyle();
style = setmarkdownstyle(style);
code.setstyle(style);
// markdown样式处理与word模板中的标签{{md}}绑定
map<string, object> data = new hashmap<>();
data.put("md", code);
configure config = configure.builder().bind("md", new markdownrenderpolicy()).build();
try {
// 获取classpath
string path = markdownutil.class.getclassloader().getresource("").getpath();
log.info("classpath:{}", path);
//由于部署到linux上后,程序是从jar包中去读取resources下的文件的,所以需要使用流的方式读取,所以获取流,而不是直接使用文件路径
// 所以可以这样获取 inputstream resourceasstream = markdownutil.class.getclassloader().getresourceasstream("");
// 建议使用spring的工具类来获取,如下
classpathresource resource = new classpathresource("markdown" + file.separator + "markdown_template.docx");
inputstream resourceasstream = resource.getinputstream();
xwpftemplate.compile(resourceasstream, config)
.render(data)
.writetofile(path + "out_markdown_" + outputfilename + ".docx");
} catch (ioexception e) {
log.error("保存为word出错");
}
}
/**
* 将markdown转换为word文档并下载
*
* @param markdowncontent
* @param response
* @param filename
*/
public void convertanddownloadworddocument(string markdowncontent, httpservletresponse response, string filename) {
log.info("markdowncontent:{}", markdowncontent);
markdownrenderdata code = new markdownrenderdata();
code.setmarkdown(markdowncontent);
markdownstyle style = markdownstyle.newstyle();
style = setmarkdownstyle(style);
code.setstyle(style);
// markdown样式处理与word模板中的标签{{md}}绑定
map<string, object> data = new hashmap<>();
data.put("md", code);
configure configure = configure.builder().bind("md", new markdownrenderpolicy()).build();
try {
filename=urlencoder.encode(filename, standardcharsets.utf_8.name());
//由于部署到linux上后,程序是从jar包中去读取resources下的文件的,所以需要使用流的方式读取,所以获取流,而不是直接使用文件路径
// 所以可以这样获取 inputstream resourceasstream = markdownutil.class.getclassloader().getresourceasstream("");
// 建议使用spring的工具类来获取,如下
classpathresource resource = new classpathresource("markdown" + file.separator + "markdown_template.docx");
inputstream resourceasstream = resource.getinputstream();
response.setheader("content-disposition", "attachment; filename=" + urlencoder.encode(filename, "utf-8") + ".docx");
// contenttype不设置也是也可以的,可以正常解析到
response.setcontenttype("application/vnd.openxmlformats-officedocument.wordprocessingml.document;charset=utf-8");
xwpftemplate template = xwpftemplate.compile(resourceasstream, configure)
.render(data);
template.writeandclose(response.getoutputstream());
} catch (ioexception e) {
log.error("下载word文档失败:{}", e.getmessage());
}
}
/**
* 设置转换为word文档时的基本样式
* @param style
* @return
*/
public markdownstyle setmarkdownstyle(markdownstyle style) {
// 一定设置为false,不然生成的word文档中各元素前边都会加上有层级效果的一串数字,
// 比如一级标题 前边出现1 二级标题出现1.1 三级标题出现1.1.1这样的数字
style.setshowheadernumber(false);
// 修改默认的表格样式
// table header style(表格头部,通常为表格顶部第一行,用于设置列标题)
rowstyle headerstyle = new rowstyle();
cellstyle cellstyle = new cellstyle();
// 设置表格头部的背景色为灰色
cellstyle.setbackgroundcolor("cccccc");
style textstyle = new style();
// 设置表格头部的文字颜色为黑色
textstyle.setcolor("000000");
// 头部文字加粗
textstyle.setbold(true);
// 设置表格头部文字大小为12
textstyle.setfontsize(12);
// 设置表格头部文字垂直居中
cellstyle.setvertalign(xwpftablecell.xwpfvertalign.center);
cellstyle.setdefaultparagraphstyle(paragraphstyle.builder().withdefaulttextstyle(textstyle).build());
headerstyle.setdefaultcellstyle(cellstyle);
style.settableheaderstyle(headerstyle);
// table border style(表格边框样式)
borderstyle borderstyle = new borderstyle();
// 设置表格边框颜色为黑色
borderstyle.setcolor("000000");
// 设置表格边框宽度为3px
borderstyle.setsize(3);
// 设置表格边框样式为实线
borderstyle.settype(xwpftable.xwpfbordertype.single);
style.settableborderstyle(borderstyle);
// 设置普通的引用文本样式
paragraphstyle quotestyle = new paragraphstyle();
// 设置段落样式
quotestyle.setspacingbeforelines(0.5d);
quotestyle.setspacingafterlines(0.5d);
// 设置段落的文本样式
style quotetextstyle = new style();
quotetextstyle.setcolor("000000");
quotetextstyle.setfontsize(8);
quotetextstyle.setitalic(true);
quotestyle.setdefaulttextstyle(quotetextstyle);
style.setquotestyle(quotestyle);
return style;
}
public static void main(string[] args) {
string markdowncontent = "# 一级标题\n" +
"## 二级标题\n" +
"### 三级标题\n" +
"#### 四级标题\n" +
"##### 五级标题\n" +
"###### 六级标题\n" +
"## 段落\n" +
"这是一段普通的段落。\n" +
"## 列表\n" +
"### 无序列表\n" +
"- 项目1\n" +
"- 项目2\n" +
"- 项目3\n" +
"### 有序列表\n" +
"1. 项目1\n" +
"2. 项目2\n" +
"3. 项目3\n" +
"## 链接\n" +
"[百度](https://www.baidu.com)\n" +
"## 图片\n" +
"\n" +
"## 表格\n" +
"| 表头1 | 表头2 | 表头3 |\n" +
"|-------|-------|-------|\n" +
"| 单元格1 | 单元格2 | 单元格3 |\n" +
"| 单元格4 | 单元格5 | 单元格6 |";
todoc(markdowncontent, "test23");
}
}这个代码是初步版本,导出的文档直接保存在了本地,初步测试成功。如果运行main方法测试报错,比如这样:

提示找不到xx方法,是因为新添加的poi-tl依赖的版本问题,因为项目是使用的ruoyi脚手架的版本比较古老,项目本身依赖的poi版本比较旧是4.x版本,所以将poi-tl版本降低一点就行了,比如使用1.10.1版本,然后再次运行就成功了
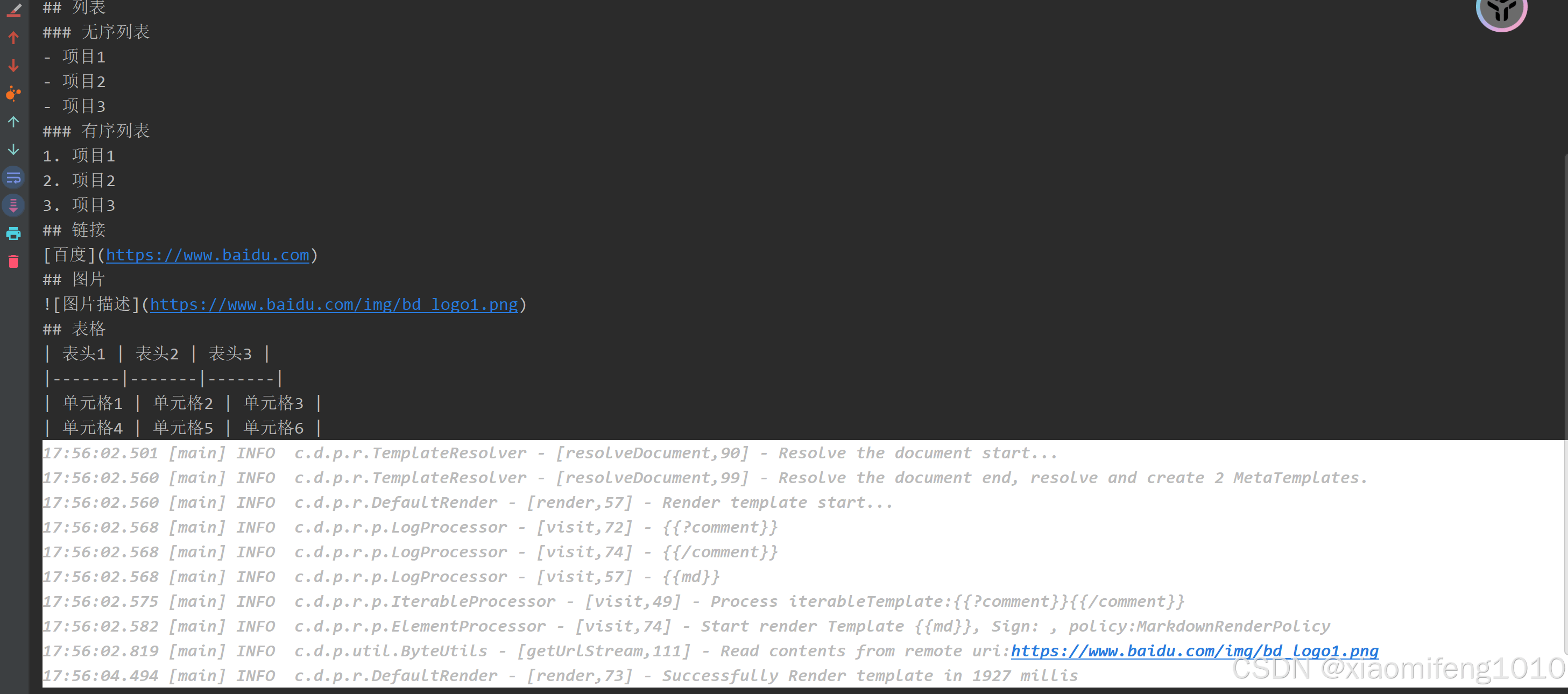
转换markdown到word过程中,首先需要一个word模板,实际上还是用markdown内容经过markdown渲染器渲染后的内容去填充word模版中的占位符{{md}}
word模版可以从poi-tl项目的官方github仓库下载:https://github.com/sayi/poi-tl/tree/master/poi-tl-plugin-markdown/src/test/resources
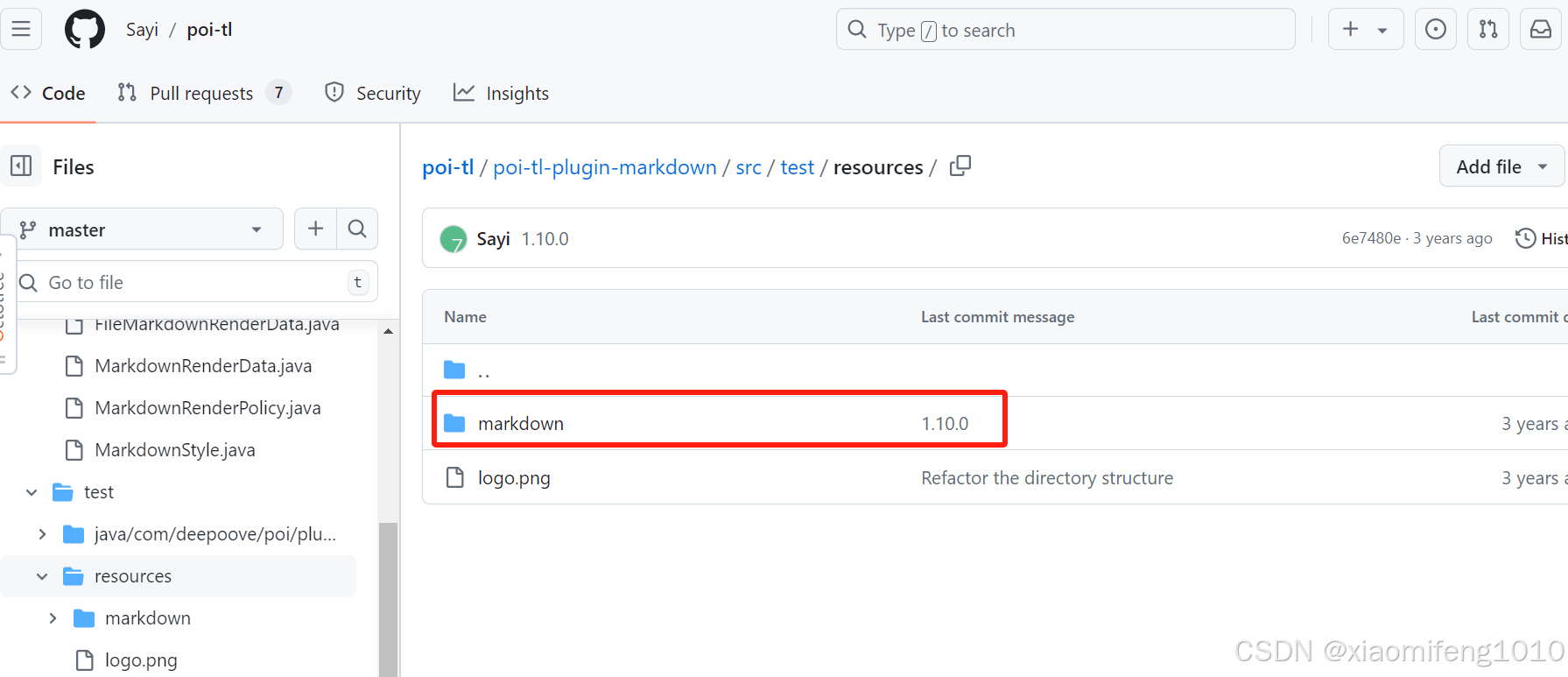
将这个markdown文件夹放在本项目的resources目录下就可以了
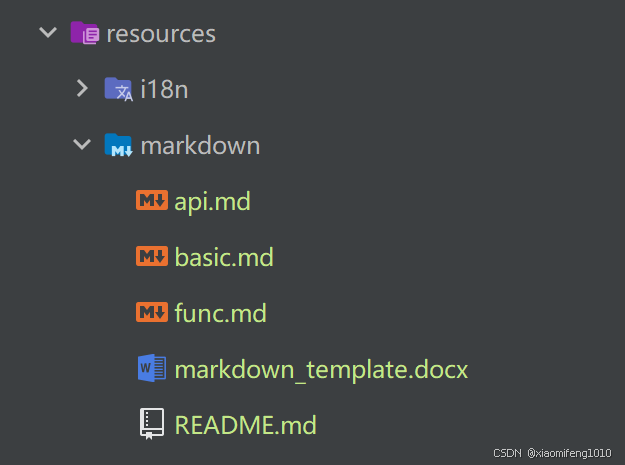
里边有5个文件,其中4个md文件主要是为了测试使用的,word文件是用于渲染的模版
内容是这样的:
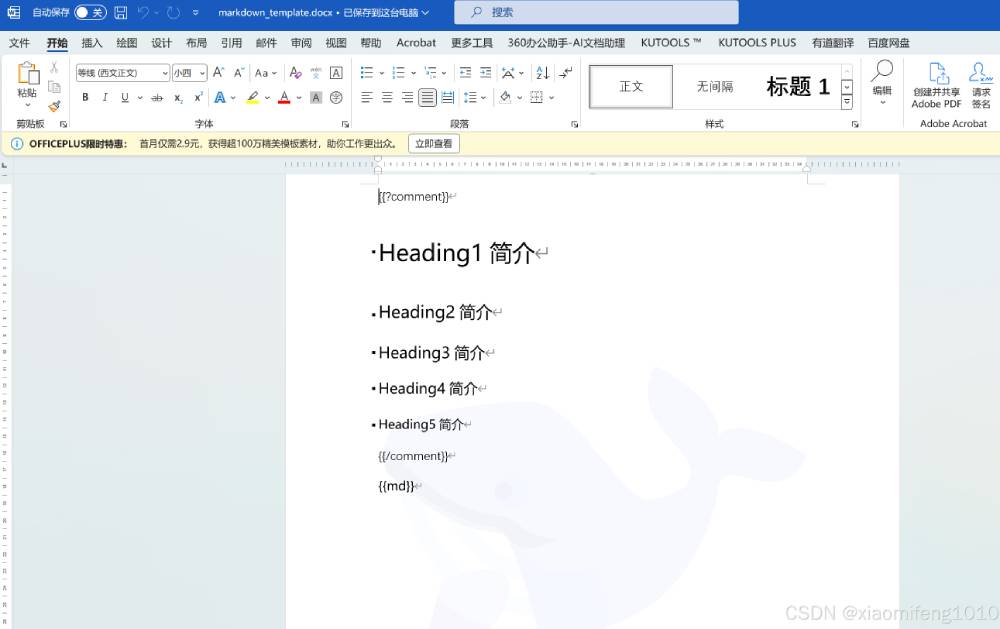
然后执行刚才工具类中main方法成功后,在项目target下就会生成一个新的渲染markdown内容填充后的word文档
内容为这样:
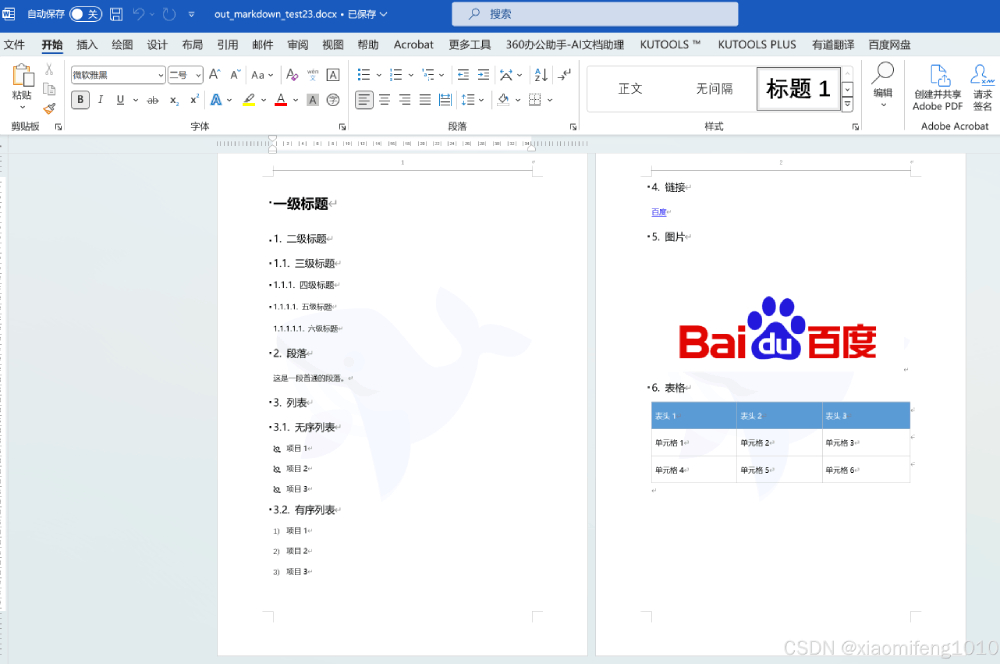
生成的效果还不错。
如果你直接用md文件测试,而不是使用一段md格式的字符串,测试方法可以参考官方的测试方法:
package com.deepoove.poi.plugin.markdown;
import java.nio.file.files;
import java.nio.file.paths;
import java.util.hashmap;
import java.util.map;
import com.deepoove.poi.xwpftemplate;
import com.deepoove.poi.config.configure;
public class markdowntest {
public static void testmarkdown(string name) throws exception {
markdownrenderdata code = new markdownrenderdata();
byte[] bytes = files.readallbytes(paths.get("src/test/resources/markdown/" + name + ".md"));
string mkdn = new string(bytes);
code.setmarkdown(mkdn);
markdownstyle style = markdownstyle.newstyle();
style.setshowheadernumber(true);
code.setstyle(style);
map<string, object> data = new hashmap<>();
data.put("md", code);
configure config = configure.builder().bind("md", new markdownrenderpolicy()).build();
xwpftemplate.compile("src/test/resources/markdown/markdown_template.docx", config)
.render(data)
.writetofile("target/out_markdown_" + name + ".docx");
}
public static void main(string[] args) throws exception {
testmarkdown("api");
testmarkdown("func");
testmarkdown("readme");
}
}实际项目中是需要web导出下载word文件的,所以在接口调用的时候,需要修改成输出流的方式就可以了。具体使用方法可以参考官方中文文档:poi-tl documentation
不过今天访问不了了,网站挂掉了,昨天还是可以正常访问的

现在直接提示这个,不知道什么原因,可能过几天就可以正常访问了 ,还有就是模版文件中有个海豚的背景,项目中使用不想要这个背景,可以在word文档中去掉
通过菜单栏【设计】->【水印】->【删除水印】即可
以上就是java实现markdown格式内容转换为word的详细内容,更多关于java markdown转word的资料请关注代码网其它相关文章!
赞 (0)
您想发表意见!!点此发布评论





发表评论