spring boot 使用 Kafka
38人参与 • 2024-07-28 • Java
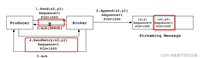
一、kafka作为消息队列的好处

-
高吞吐量:kafka能够处理大规模的数据流,并支持高吞吐量的消息传输。
-
持久性:kafka将消息持久化到磁盘上,保证了消息不会因为系统故障而丢失。
-
分布式:kafka是一个分布式系统,可以在多个节点上运行,具有良好的可扩展性和容错性。
-
支持多种协议:kafka支持多种协议,如tcp、http、udp等,可以与不同的系统进行集成。
-
灵活的消费模式:kafka支持多种消费模式,如拉取和推送,可以根据需要选择合适的消费模式。
-
可配置性强:kafka的配置参数非常丰富,可以根据需要进行灵活配置。
-
社区支持:kafka作为apache旗下的开源项目,拥有庞大的用户基础和活跃的社区支持,方便用户得到及时的技术支持。
二、springboot中使用kafka
-
添加依赖:在pom.xml文件中添加kafka的依赖,包括spring-kafka和kafka-clients。确保版本与你的项目兼容。
-
创建生产者:创建一个kafka生产者类,实现producer接口,并使用kafkatemplate发送消息。
-
配置生产者:在spring boot的配置文件中配置kafka生产者的相关参数,例如bootstrap服务器地址、kafka主题等。
-
发送消息:在需要发送消息的地方,注入kafka生产者,并使用其发送消息到指定的kafka主题。
-
创建消费者:创建一个kafka消费者类,实现consumer接口,并使用kafkatemplate订阅指定的kafka主题。
-
配置消费者:在spring boot的配置文件中配置kafka消费者的相关参数,例如group id、auto offset reset等。
-
接收消息:在需要接收消息的地方,注入kafka消费者,并使用其接收消息。
-
处理消息:对接收到的消息进行处理,例如保存到数据库或进行其他业务逻辑处理。
三、使用kafka
pom中填了依赖
<dependency>
<groupid>org.springframework.kafka</groupid>
<artifactid>spring-kafka</artifactid>
<version>2.8.1</version>
</dependency>
<dependency>
<groupid>org.apache.kafka</groupid>
<artifactid>kafka-clients</artifactid>
<version>2.8.1</version>
</dependency>-
创建生产者:创建一个kafka生产者类,实现producer接口,并使用kafkatemplate发送消息。
import org.apache.kafka.clients.producer.*;
import org.springframework.beans.factory.annotation.value;
import org.springframework.kafka.core.kafkatemplate;
import org.springframework.stereotype.component;
@component
public class kafkaproducer {
@value("${kafka.bootstrap}")
private string bootstrapservers;
@value("${kafka.topic}")
private string topic;
private kafkatemplate<string, string> kafkatemplate;
public kafkaproducer(kafkatemplate<string, string> kafkatemplate) {
this.kafkatemplate = kafkatemplate;
}
public void sendmessage(string message) {
producer<string, string> producer = new kafkaproducer<>(bootstrapservers, new stringserializer(), new stringserializer());
try {
producer.send(new producerrecord<>(topic, message));
} catch (exception e) {
e.printstacktrace();
} finally {
producer.close();
}
}
}-
配置生产者:在spring boot的配置文件中配置kafka生产者的相关参数,例如bootstrap服务器地址、kafka主题等。
import org.springframework.context.annotation.bean;
import org.springframework.context.annotation.configuration;
import org.springframework.kafka.core.defaultkafkaproducerfactory;
import org.springframework.kafka.core.kafkatemplate;
import org.springframework.kafka.core.producerfactory;
import org.springframework.kafka.core.defaultkafkaconsumerfactory;
import org.springframework.kafka.core.consumerfactory;
import org.springframework.kafka.core.consumerconfig;
import org.springframework.kafka.listener.concurrentmessagelistenercontainer;
import org.springframework.kafka.listener.messagelistener;
import org.springframework.context.annotation.propertysource;
import java.util.*;
import org.springframework.beans.factory.*;
import org.springframework.*;
import org.springframework.*;expression.*;value; @value("${kafka}") properties kafkaprops = new properties(); @bean public kafkatemplate<string, string> kafkatemplate(producerfactory<string, string> pf){ kafkatemplate<string, string> template = new kafkatemplate<>(pf); template .setmessageconverter(new stringjsonmessageconverter()); template .setsendtimeout(duration .ofseconds(30)); return template ; } @bean public producerfactory<string, string> producerfactory(){ defaultkafkaproducerfactory<string, string> factory = new defaultkafkaproducerfactory<>(kafkaprops); factory .setbootstrapservers(bootstrapservers); factory .setkeyserializer(new stringserializer()); factory .setvalueserializer(new stringserializer()); return factory ; } @bean public consumerfactory<string, string> consumerfactory(){ defaultkafkaconsumerfactory<string, string> factory = new defaultkafkaconsumerfactory<>(consumerconfigprops); factory .setbootstrapservers(bootstrapservers); factory .setkeydeserializer(new stringdeserializer()); factory .setvaluedeserializer(new stringdeserializer()); return factory ; } @bean public concurrentmessagelistenercontainer<string, string> container(consumerfactory<string, string> consumerfactory, messagelistener listener){ concurrentmessagelistenercontainer<string, string> container = new concurrentmessagelistenercontainer<>(consumerfactory); container .setmessagelistener(listener); container .setconcurrency(3); return container ; } @bean public messagelistener
消费者
import org.apache.kafka.clients.consumer.*;
import org.springframework.kafka.core.kafkatemplate;
import org.springframework.stereotype.component;
@component
public class kafkaconsumer {
@value("${kafka.bootstrap}")
private string bootstrapservers;
@value("${kafka.group}")
private string groupid;
@value("${kafka.topic}")
private string topic;
private kafkatemplate<string, string> kafkatemplate;
public kafkaconsumer(kafkatemplate<string, string> kafkatemplate) {
this.kafkatemplate = kafkatemplate;
}
public void consume() {
consumer<string, string> consumer = new kafkaconsumer<>(consumerconfigs());
consumer.subscribe(collections.singletonlist(topic));
while (true) {
consumerrecords<string, string> records = consumer.poll(duration.ofmillis(100));
for (consumerrecord<string, string> record : records) {
system.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());
}
}
}
private properties consumerconfigs() {
properties props = new properties();
props.put(consumerconfig.bootstrap_servers_config, bootstrapservers);
props.put(consumerconfig.group_id_config, groupid);
props.put(consumerconfig.key_deserializer_class_config, "org.apache.kafka.common.serialization.stringdeserializer");
props.put(consumerconfig.value_deserializer_class_config, "org.apache.kafka.common.serialization.stringdeserializer");
return props;
}
}四、kafka与rocketmq比较
kafka和rocketmq都是开源的消息队列系统,它们具有许多相似之处,但在一些关键方面也存在差异。以下是它们在数据可靠性、性能、消息传递方式等方面的比较:
- 数据可靠性:
- kafka使用异步刷盘方式,而rocketmq支持异步实时刷盘、同步刷盘、同步复制和异步复制。这使得rocketmq在单机可靠性上比kafka更高,因为它不会因为操作系统崩溃而导致数据丢失。此外,rocketmq新增的同步刷盘机制也进一步保证了数据的可靠性。
- 性能:
- kafka和rocketmq在性能方面各有千秋。由于kafka的数据以partition为单位,一个kafka实例上可能有多达上百个partition,而一个rocketmq实例上只有一个partition。这使得rocketmq可以充分利用io组的commit机制,批量传输数据,从而在replication时具有更好的性能。然而,kafka的异步replication性能理论上低于rocketmq的replication,因为同步replication与异步replication相比,性能上会有约20%-30%的损耗。
- 消息传递方式:
- kafka和rocketmq在消息传递方式上也有所不同。kafka采用producer发送消息后,broker马上把消息投递给consumer,这种方式实时性较高,但会增加broker的负载。而rocketmq基于pull模式和push模式的长轮询机制,来平衡push和pull模式各自的优缺点。rocketmq的消息及时性较好,严格的消息顺序得到了保证。
- 其他特性:
- kafka在单机支持的队列数超过64个队列,而rocketmq最高支持5万个队列。队列越多,可以支持的业务就越多。
五、kafka使用场景
- 实时数据流处理:kafka可以处理大量的实时数据流,这些数据流可以来自不同的源,如用户行为、传感器数据、日志文件等。通过kafka,可以将这些数据流进行实时的处理和分析,例如进行实时数据分析和告警。
- 消息队列:kafka可以作为一个消息队列使用,用于在分布式系统中传递消息。它能够处理高吞吐量的消息,并保证消息的有序性和可靠性。
- 事件驱动架构:kafka可以作为事件驱动架构的核心组件,将事件数据发布到不同的消费者,以便进行实时处理。这种架构可以简化应用程序的设计和开发,提高系统的可扩展性和灵活性。
- 数据管道:kafka可以用于数据管道,将数据从一个系统传输到另一个系统。例如,可以将数据从数据库或日志文件传输到大数据平台或数据仓库。
- 业务事件通知:kafka可以用于通知业务事件,例如订单状态变化、库存更新等。通过订阅kafka主题,相关的应用程序和服务可以实时地接收到这些事件通知,并进行相应的处理。
- 流数据处理框架集成:kafka可以与流处理框架集成,如apache flink、apache spark等。通过集成,可以将流数据从kafka中实时导入到流处理框架中进行处理,实现流式计算和实时分析。
赞 (0)
您想发表意见!!点此发布评论


发表评论