(ROOT)KAFKA详解
40人参与 • 2024-07-28 • Java
生产篇
使用
/*
* licensed to the apache software foundation (asf) under one or more
* contributor license agreements. see the notice file distributed with
* this work for additional information regarding copyright ownership.
* the asf licenses this file to you under the apache license, version 2.0
* (the "license"); you may not use this file except in compliance with
* the license. you may obtain a copy of the license at
*
* http://www.apache.org/licenses/license-2.0
*
* unless required by applicable law or agreed to in writing, software
* distributed under the license is distributed on an "as is" basis,
* without warranties or conditions of any kind, either express or implied.
* see the license for the specific language governing permissions and
* limitations under the license.
*/
package kafka.examples;
import org.apache.kafka.clients.producer.callback;
import org.apache.kafka.clients.producer.kafkaproducer;
import org.apache.kafka.clients.producer.producerrecord;
import org.apache.kafka.clients.producer.recordmetadata;
import org.apache.kafka.clients.producer.producerconfig;
import org.apache.kafka.common.serialization.integerserializer;
import org.apache.kafka.common.serialization.stringserializer;
import java.util.properties;
import java.util.concurrent.countdownlatch;
import java.util.concurrent.executionexception;
public class producer extends thread {
private final kafkaproducer<integer, string> producer;
private final string topic;
private final boolean isasync;
private int numrecords;
private final countdownlatch latch;
public producer(final string topic,
final boolean isasync,
final string transactionalid,
final boolean enableidempotency,
final int numrecords,
final int transactiontimeoutms,
final countdownlatch latch) {
properties props = new properties();
//指定kafka集群节点列表(全部 or 部分均可),用于kafkaproducer初始获取server端元数据(如完整节点列表、partition分布等等)
props.put(producerconfig.bootstrap_servers_config, kafkaproperties.kafka_server_url + ":" + kafkaproperties.kafka_server_port);
props.put(producerconfig.client_id_config, "demoproducer");
props.put(producerconfig.key_serializer_class_config, integerserializer.class.getname());
props.put(producerconfig.value_serializer_class_config, stringserializer.class.getname());
if (transactiontimeoutms > 0) {
props.put(producerconfig.transaction_timeout_config, transactiontimeoutms);
}
if (transactionalid != null) {
props.put(producerconfig.transactional_id_config, transactionalid);
}
props.put(producerconfig.enable_idempotence_config, enableidempotency);
//指定服务端有多少个副本完成同步,才算该producer发出的消息写入成功
props.put(producerconfig.acks_config, "-1");
//失败重试次数;
props.put(producerconfig.retries_config, "3");
producer = new kafkaproducer<>(props);
this.topic = topic;
this.isasync = isasync;
this.numrecords = numrecords;
this.latch = latch;
}
kafkaproducer<integer, string> get() {
return producer;
}
@override
public void run() {
// key用来决定目标partition
int messagekey = 0;
int recordssent = 0;
while (recordssent < numrecords) {
//传递业务数据
string messagestr = "message_" + messagekey;
long starttime = system.currenttimemillis();
if (isasync) { // send asynchronously
producer.send(new producerrecord<>(topic,
messagekey,
messagestr), new democallback(starttime, messagekey, messagestr));
} else { // send synchronously
try {
// kafkaproducer中各类send方法均返回future,并不会直接返回发送结果,其原因便是线程模型设计。
producer.send(new producerrecord<>(topic,
messagekey,
messagestr)).get();
system.out.println("sent message: (" + messagekey + ", " + messagestr + ")");
} catch (interruptedexception | executionexception e) {
e.printstacktrace();
}
}
messagekey += 2;
recordssent += 1;
}
system.out.println("producer sent " + numrecords + " records successfully");
latch.countdown();
}
}
class democallback implements callback {
private final long starttime;
private final int key;
private final string message;
public democallback(long starttime, int key, string message) {
this.starttime = starttime;
this.key = key;
this.message = message;
}
/**
* a callback method the user can implement to provide asynchronous handling of request completion. this method will
* be called when the record sent to the server has been acknowledged. when exception is not null in the callback,
* metadata will contain the special -1 value for all fields except for topicpartition, which will be valid.
*
* @param metadata the metadata for the record that was sent (i.e. the partition and offset). an empty metadata
* with -1 value for all fields except for topicpartition will be returned if an error occurred.
* @param exception the exception thrown during processing of this record. null if no error occurred.
*/
public void oncompletion(recordmetadata metadata, exception exception) {
long elapsedtime = system.currenttimemillis() - starttime;
if (metadata != null) {
system.out.println(
"message(" + key + ", " + message + ") sent to partition(" + metadata.partition() +
"), " +
"offset(" + metadata.offset() + ") in " + elapsedtime + " ms");
} else {
exception.printstacktrace();
}
}
}
图解
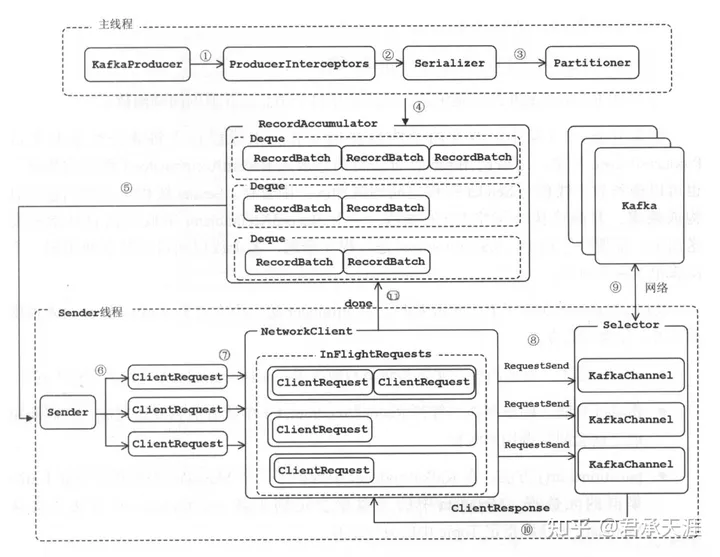
1)producerinterceptors:消息过滤器,对消息进行发送拦截;
2)serializer:对消息key和value进行序列化;
3)partitioner:为消息选择合适的分区;
4)recordaccumulator:消息收集器,可以认为是主线程和sender线程之间的消息缓冲区,对消息进行分批量发送;
5)sender:负责从消息收集器获取批量消息发送;
6)创建clientrequest;
7)将clientrequest交给networkclient,准备发送;
8)networkclient将requestsend发送给kafkachannel缓存区域;
9)向kafka服务执行网络io请求;
10)收到响应,将cientresponse交给clientrequest的回调函数;
11)调用recordbatch的回调函数,最终会指定每条消息的回调函数;
recordbatch
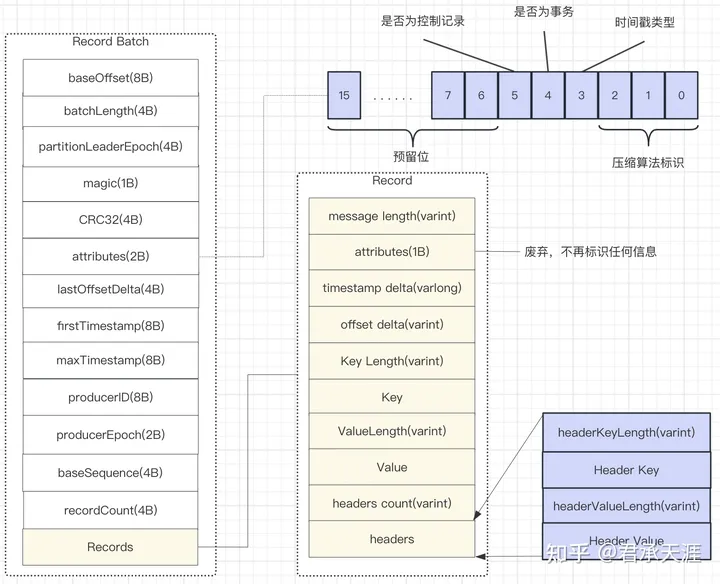
batch部分
1)baseoffset:当前recordbatch的起始位移,record中的offset delta与该baseoffset相加才能得到真正的offset值。当recordbatch还在producer端的时候,offset是producer分配的一个值(不partition的offset);
2)batchlength:recordbatch的总长度,从`partition leader epoch`到末尾的长度;
3)partitionleaderepoch:用于标记目标 partition中leader replica的纪元信息,可以看做是分区leader的版本号或者更新次数;
4)magic:魔数值,v0就是0,v1就是1,v2就是2;
5)crc32校验码:参与校验的部分是从attributes到recordbatch末尾的全部数据;partitionleaderepoch 不在 crc 里面是因为每次 broker 收到 recordbatch 的时候,都会赋值 partitionleaderepoch,如果包含在 crc 里面会导致需要重新计算crc;
6)attributes:从 v1 版本中的 8 位扩展到 16 位,0~2 位表示压缩类型,第 3 位表示时间戳类型,第 4 位表示是否是事务型记录。所谓“事务”是kafka的新功能,开启事务之后,只有在事务提交之后,事务型 consumer 才可以看到记录。5表示是否是 control record,这类记录总是单条出现,被包含在一个 control record batch 里面,它可以用于标记“事务是否已经提交”、“事务是否已经中止” 等,它只会在 broker 内处理,不会被传输给 consumer 和 producer,即对客户端是透明的;
7)lastoffsetdelta:recordbatch最后一个record的相对位移,用于broker确认recordbatch中records的组装正确性。
8)firsttimestamp:recordbatch第一条record的时间戳。
9)maxtimestamp:recordbatch中最大的时间戳,一般是最后一条消息的时间戳,用于broker确认recordbatch中 records 的组装正确性。
10)producerid:生产者编号,用于支持事务和幂等性;
11)producerepoch:生产者纪元,用于支持事务和幂等性;
12)basesequence:基础序号,用于支持事务和幂等性,校验是否是重复record;
13)recordcount:record 的数量;
14)records:消息record集合,每个record结构如下;
record部分:
1)所有标识长度的字段都是变长字段(varint或者varlong)
2)timestamp和offset是偏移量,也叫做delta值;
3)attributes字段不再标识任务信息;
4)headers:增加的header相关扩展,每个header结构如下;
header部分:
1)headerkeylength:消息头key的长度;
2、headerkey:消息头key的值;
3、headervaluelength:消息头值的长度;
4、headervalue:消息头的值;
recordaccumulator
业务线程(或者叫做主线程)使用kafkaproducer.send()方法发送message的时候,会先将其写入recordaccumulator,然后主线程就从send方法中返回了,此时message还未真正发送到kafka,而是暂存在消息收集器中了,然后主线程继续使用send方法发送message不断向recordaccumulator追加消息,当recordaccumulator中缓存的message达到一定阈值(batch大小/linger.ms时间)的时候,会唤醒sender线程发送recordaccumulator,发送到kafka,以达到减少网络请求开销,提高吞吐目的;
recordaccumulator至少有主线程和sender线程访问,所以要保证线程安全性。
重要成员变量
1)batchs
在recordaccumulator内部,维护了一个map集合batchs,用于缓存发送到kafka服务端的批次消息,因为需要保证线程安全,所以类型是concurrentmap<topicpartition, deque<producerbatch>>,并且初始化的时候设置的对象是kafka自定义的一个对象copyonwritemap,deque的实例是arraydeque,这个是非线程安全的,所以在操作的时候是要加锁的
2)free
free是缓冲池对象(bufferpool),用于存储消息字节,使用的是bytebuffer数据结构,简单的说bufferpool就是管理bytebuffer的分配和释放。
3)incomplete
存放未发送或者发送未ack的producerbatch,类型是incompletebatches,在该类的内部维护了一个set集合,存放这些producerbatch;
memoryrecordsbuilder
1.在memoryrecordsbuilder内,将bytebuffer封装到bytebufferoutputstream,bytebufferoutputstream实现了outputstream,所以可以按照流的方式写入数据。
2.向当前recordbatch追加消息record方法appendwithoffset
- 首先是是进行一些消息格式的验证:
- 当前不处理controlbatch,controlbatch有自己的逻辑处理;
- 当前record要追加的记录肯定是要在最近一次lastoffset之后才是合理的;
- 消息record的timestamp需是大于0的合法数字;
- 然后调用数据写入方法写入数据流dataoutputstream,更新当前recordbatch的相关元数据;
3.该类里面还有一个重要的方法就是hasroomfor方法,该方法用于判断当前的memoryrecords是否有足够的空间追加新的消息;
4.判断当前recordbatch的空间是否满的方法:isfull
5.预估已写入的字节大小方法:estimatedbyteswritten
6.获取memoryrecords的build()
memoryrecordsbuilder负责创建memoryrecords,方法build()的作用就是返回创建和写入的memoryrecords,要返回memoryrecords了,那么之后写入相关的操作就要禁止了
public void close() {
if (aborted)
throw new illegalstateexception("cannot close memoryrecordsbuilder as it has already been aborted");
if (builtrecords != null)
return;
// 简单的参数校验
validateproducerstate();
// 流资源的释放和关闭
closeforrecordappends();
// 初始化records位置
if (numrecords == 0l) {
buffer().position(initialposition);
builtrecords = memoryrecords.empty;
} else {
if (magic > recordbatch.magic_value_v1)
this.actualcompressionratio = (float) writedefaultbatchheader() / this.uncompressedrecordssizeinbytes;
else if (compressiontype != compressiontype.none)
this.actualcompressionratio = (float) writelegacycompressedwrapperheader() / this.uncompressedrecordssizeinbytes;
//复制一份bytebuffer出来,然后切换到读模式(flip),通过slice()方法得到新一个独立的bytebuffer,设置给builtrecords,builtrecords对象里面持有对象bytebuffer
bytebuffer buffer = buffer().duplicate();
buffer.flip();
buffer.position(initialposition);
builtrecords = memoryrecords.readablerecords(buffer.slice());
}
}producerbatch
producerbatch是sender线程发送的对象,对应就是上面提到的recordbatch,producerbatch包含多条record,生产者每个批次发送的消息大小通过batch.size决定,默认16kb;
在recordaccumulator中的batchs队列中的每个元素就是producerbatch,第一次发送消息的时候会消息所在分区的producerbatch队列,并创建producerbatch将该条消息追加在producerbatch,然后有新的消息发送时,就会追加消息到对应topicpartition的producerbatch队列里面最后一个producerbatch中,如果producerbatch空间满了,会再创建一个新的producerbatch来存放消息;
1.追加消息到producerbatch
2.拆分producerbatch(split方法)
当producerbatch过大时,可以通过slice方法将一个大的batch拆分为更小的batch。这个方式是在sender线程中发送失败返回”message_too_large"时,需要将batch拆分并重新加入消息收集器的batch队列
public deque<producerbatch> split(int splitbatchsize) {
// 分割结果
deque<producerbatch> batches = new arraydeque<>();
// 获取当前batch的memoryrecords对象,也就是获取当前batch的bytebuffer中存储的消息;
memoryrecords memoryrecords = recordsbuilder.build();
iterator<mutablerecordbatch> recordbatchiter = memoryrecords.batches().iterator();
if (!recordbatchiter.hasnext())
throw new illegalstateexception("cannot split an empty producer batch.");
recordbatch recordbatch = recordbatchiter.next();
if (recordbatch.magic() < magic_value_v2 && !recordbatch.iscompressed())
throw new illegalargumentexception("batch splitting cannot be used with non-compressed messages " +
"with version v0 and v1");
if (recordbatchiter.hasnext())
throw new illegalargumentexception("a producer batch should only have one record batch.");
iterator<thunk> thunkiter = thunks.iterator();
// we always allocate batch size because we are already splitting a big batch.
// and we also retain the create time of the original batch.
producerbatch batch = null;
// 遍历batch的record
for (record record : recordbatch) {
assert thunkiter.hasnext();
thunk thunk = thunkiter.next();
if (batch == null)
//首次循环会调用createbatchoffaccumulatorforrecord()方法来分配一个bytebuffer内存空间,空间大小根据record和splitbatchsize(batch.size)最大值来决定,然后创建memoryrecordsbuilder和producerbatch对象,这里同正常创建memoryrecordsbuilder和producerbatch一样,不同的是这里的record记录的大小可能超过batch.size;
batch = createbatchoffaccumulatorforrecord(record, splitbatchsize);
//调用方法tryappendforsplit来追加当前记录到新创建的更大的producerbatch,tryappendforsplit追加record的方式同上面的tryappend基本差不多,不同的是这里的thunk对象使用已经存在的即可,这里thunk里面使用的是元数据futurerecordmetadata 链,也就是加在原来batch的future后面;在batch拆分的情况下,此时的producerbatch应该只有一条record的,如果在下次循环或者某个循环内,tryappendforsplit失败的情况下,也是空间不足了,就再创建新的producerbatch,以此类推,直到把所有的records记录循环完毕;
// a newly created batch can always host the first message.
if (!batch.tryappendforsplit(record.timestamp(), record.key(), record.value(), record.headers(), thunk)) {
batches.add(batch);
batch.closeforrecordappends();
batch = createbatchoffaccumulatorforrecord(record, splitbatchsize);
batch.tryappendforsplit(record.timestamp(), record.key(), record.value(), record.headers(), thunk);
}
}
// 拆分后的batch存放在队列batches里面,并结束拆分前的batch的发送结果producefuture,调用了producerequestresult.done()方法之后,就会唤醒等待在producerequestresult处理结果上的await的线程;
// close the last batch and add it to the batch list after split.
if (batch != null) {
batches.add(batch);
batch.closeforrecordappends();
}
producefuture.set(produceresponse.invalid_offset, no_timestamp, index -> new recordbatchtoolargeexception());
//会唤醒等待在producerequestresult处理结果上的await的线程;
producefuture.done();
// 当设置basesequence基础序号的时候,需要设置producerstate用于支持事务和幂等性,校验是否是重复record;
if (hassequence()) {
int sequence = basesequence();
produceridandepoch produceridandepoch = new produceridandepoch(producerid(), producerepoch());
for (producerbatch newbatch : batches) {
newbatch.setproducerstate(produceridandepoch, sequence, istransactional());
sequence += newbatch.recordcount;
}
}
return batches;
}
/**
* this method is only used by {@link #split(int)} when splitting a large batch to smaller ones.
* @return true if the record has been successfully appended, false otherwise.
*/
private boolean tryappendforsplit(long timestamp, bytebuffer key, bytebuffer value, header[] headers, thunk thunk) {
if (!recordsbuilder.hasroomfor(timestamp, key, value, headers)) {
return false;
} else {
// no need to get the crc.
this.recordsbuilder.append(timestamp, key, value, headers);
this.maxrecordsize = math.max(this.maxrecordsize, abstractrecords.estimatesizeinbytesupperbound(magic(),
recordsbuilder.compressiontype(), key, value, headers));
futurerecordmetadata future = new futurerecordmetadata(this.producefuture, this.recordcount,
timestamp,
key == null ? -1 : key.remaining(),
value == null ? -1 : value.remaining(),
time.system);
// chain the future to the original thunk.
thunk.future.chain(future);
this.thunks.add(thunk);
this.recordcount++;
return true;
}
}
3.done() 方法
在sender线程将消息发送到kafka后,producerbatch需要进行一些善后工作,比如释放资源(例如bytebuffer)、回调用户自定义的callback等等,这些就是done方法做的事情了。
1)设置发送结果状态producerbatch.finalstate,一共有3种结果:aborted, failed, succeeded,如果服务端返回了异常,那么设置为failed,否则就是succeeded;
在这里要注意的是:如果finalstate之前已经设置过且是succeeded,说明是一个已经处理的结果,会抛出非法状态异常
2)将服务端返回的offset、logappendtime(这个在log类型是createtime时值为-1)设置给future元数据,以便执行future元数据的done方法;
3)回调用户自定义的callback
4)future的done上面也说过就是producerequestresult.done()方法,会唤醒等待在producerequestresult处理结果上的await的线程;
调用关系
kafkaproducer().send(producerrecord<k, v> record, callback callback)
@override
public future<recordmetadata> send(producerrecord<k, v> record, callback callback) {
// intercept the record, which can be potentially modified; this method does not throw exceptions
producerrecord<k, v> interceptedrecord = this.interceptors.onsend(record);
return dosend(interceptedrecord, callback);
}kafkaproducer().send包含:kafkaproducer().dosend(producerrecord<k, v> record, callback callback)
/**
* implementation of asynchronously send a record to a topic.
*/
private future<recordmetadata> dosend(producerrecord<k, v> record, callback callback) {
topicpartition tp = null;
try {
throwifproducerclosed();
// first make sure the metadata for the topic is available
long nowms = time.milliseconds();
clusterandwaittime clusterandwaittime;
try {
clusterandwaittime = waitonmetadata(record.topic(), record.partition(), nowms, maxblocktimems);
} catch (kafkaexception e) {
if (metadata.isclosed())
throw new kafkaexception("producer closed while send in progress", e);
throw e;
}
nowms += clusterandwaittime.waitedonmetadatams;
long remainingwaitms = math.max(0, maxblocktimems - clusterandwaittime.waitedonmetadatams);
cluster cluster = clusterandwaittime.cluster;
byte[] serializedkey;
try {
serializedkey = keyserializer.serialize(record.topic(), record.headers(), record.key());
} catch (classcastexception cce) {
throw new serializationexception("can't convert key of class " + record.key().getclass().getname() +
" to class " + producerconfig.getclass(producerconfig.key_serializer_class_config).getname() +
" specified in key.serializer", cce);
}
byte[] serializedvalue;
try {
serializedvalue = valueserializer.serialize(record.topic(), record.headers(), record.value());
} catch (classcastexception cce) {
throw new serializationexception("can't convert value of class " + record.value().getclass().getname() +
" to class " + producerconfig.getclass(producerconfig.value_serializer_class_config).getname() +
" specified in value.serializer", cce);
}
int partition = partition(record, serializedkey, serializedvalue, cluster);
tp = new topicpartition(record.topic(), partition);
setreadonly(record.headers());
header[] headers = record.headers().toarray();
int serializedsize = abstractrecords.estimatesizeinbytesupperbound(apiversions.maxusableproducemagic(),
compressiontype, serializedkey, serializedvalue, headers);
ensurevalidrecordsize(serializedsize);
long timestamp = record.timestamp() == null ? nowms : record.timestamp();
if (log.istraceenabled()) {
log.trace("attempting to append record {} with callback {} to topic {} partition {}", record, callback, record.topic(), partition);
}
// producer callback will make sure to call both 'callback' and interceptor callback
callback interceptcallback = new interceptorcallback<>(callback, this.interceptors, tp);
if (transactionmanager != null && transactionmanager.istransactional()) {
transactionmanager.failifnotreadyforsend();
}
recordaccumulator.recordappendresult result = accumulator.append(tp, timestamp, serializedkey,
serializedvalue, headers, interceptcallback, remainingwaitms, true, nowms);
if (result.abortfornewbatch) {
int prevpartition = partition;
partitioner.onnewbatch(record.topic(), cluster, prevpartition);
partition = partition(record, serializedkey, serializedvalue, cluster);
tp = new topicpartition(record.topic(), partition);
if (log.istraceenabled()) {
log.trace("retrying append due to new batch creation for topic {} partition {}. the old partition was {}", record.topic(), partition, prevpartition);
}
// producer callback will make sure to call both 'callback' and interceptor callback
interceptcallback = new interceptorcallback<>(callback, this.interceptors, tp);
result = accumulator.append(tp, timestamp, serializedkey,
serializedvalue, headers, interceptcallback, remainingwaitms, false, nowms);
}
if (transactionmanager != null && transactionmanager.istransactional())
transactionmanager.maybeaddpartitiontotransaction(tp);
if (result.batchisfull || result.newbatchcreated) {
log.trace("waking up the sender since topic {} partition {} is either full or getting a new batch", record.topic(), partition);
this.sender.wakeup();
}
return result.future;
// handling exceptions and record the errors;
// for api exceptions return them in the future,
// for other exceptions throw directly
} catch (apiexception e) {
log.debug("exception occurred during message send:", e);
if (callback != null)
callback.oncompletion(null, e);
this.errors.record();
this.interceptors.onsenderror(record, tp, e);
return new futurefailure(e);
} catch (interruptedexception e) {
this.errors.record();
this.interceptors.onsenderror(record, tp, e);
throw new interruptexception(e);
} catch (kafkaexception e) {
this.errors.record();
this.interceptors.onsenderror(record, tp, e);
throw e;
} catch (exception e) {
// we notify interceptor about all exceptions, since onsend is called before anything else in this method
this.interceptors.onsenderror(record, tp, e);
throw e;
}
}kafkaproducer().dosend包含:recordaccumulater().append(topicpartition tp, long timestamp, byte[] key, byte[] value, header[] headers, callback callback, long maxtimetoblock, boolean abortonnewbatch, long nowms)
消息append是accumulator的核心,将一条消息record存放到指定topicpartition的batchs队列,并返回append结果recordappendresult。该方法的源码如下:
/**
* add a record to the accumulator, return the append result
* <p>
* the append result will contain the future metadata, and flag for whether the appended batch is full or a new batch is created
* <p>
*
* @param tp the topic/partition to which this record is being sent
* @param timestamp the timestamp of the record
* @param key the key for the record
* @param value the value for the record
* @param headers the headers for the record
* @param callback the user-supplied callback to execute when the request is complete
* @param maxtimetoblock the maximum time in milliseconds to block for buffer memory to be available
* @param abortonnewbatch a boolean that indicates returning before a new batch is created and
* running the partitioner's onnewbatch method before trying to append again
* @param nowms the current time, in milliseconds
*/
public recordappendresult append(topicpartition tp,
long timestamp,
byte[] key,
byte[] value,
header[] headers,
callback callback,
long maxtimetoblock,
boolean abortonnewbatch,
long nowms) throws interruptedexception {
// we keep track of the number of appending thread to make sure we do not miss batches in
// abortincompletebatches().
// 统计当前accumulator中正在追加消息的执行次数,在方法的执行最后的finally块再进行减1操作;该值越大,说明并发越高、或者block在缓冲区的线程越多,比如可能由于内存没有空间分配,缓冲区的消息没能及时发送到kafka等多种原因;
appendsinprogress.incrementandget();
bytebuffer buffer = null;
if (headers == null) headers = record.empty_headers;
try {
// check if we have an in-progress batch
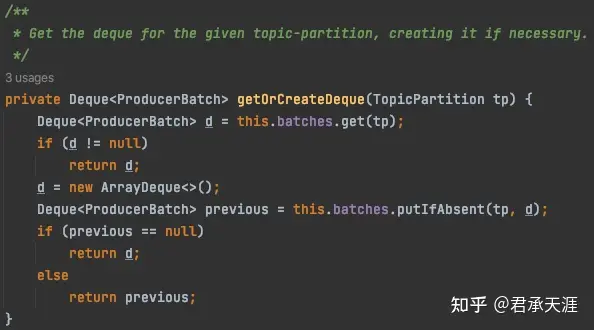
// 调用方法getorcreatedeque获取或者创建topicpartition对应的producerbatch队列;
deque<producerbatch> dq = getorcreatedeque(tp);
// 锁住dq,保证只有一个线程执行tryappend方法来追加当前消息到数据缓冲区,如果tryappend成功返回,就直接返回append的结果的封装对象recordappendresult;
synchronized (dq) {
if (closed)
throw new kafkaexception("producer closed while send in progress");
// 如果tryappend失败,比如在当前producerbatch空间不足或者队列中还没有可用的producerbatch时,如果标示abortonnewbatch=true,标示放弃创建新的producerbatch,直接返回一个“空”的recordappendresult;
recordappendresult appendresult = tryappend(timestamp, key, value, headers, callback, dq, nowms);
if (appendresult != null)
return appendresult;
}
// we don't have an in-progress record batch try to allocate a new batch
if (abortonnewbatch) {
// return a result that will cause another call to append.
return new recordappendresult(null, false, false, true);
}
byte maxusablemagic = apiversions.maxusableproducemagic();
// 调用estimatesizeinbytesupperbound方法是对追加的record大小进行一个预估,根据上面record格式的不同,采取的预估值不同,最终取的还是batch.size和预估值的最大值进行内存分配;
int size = math.max(this.batchsize, abstractrecords.estimatesizeinbytesupperbound(maxusablemagic, compression, key, value, headers));
log.trace("allocating a new {} byte message buffer for topic {} partition {} with remaining timeout {}ms", size, tp.topic(), tp.partition(), maxtimetoblock);
buffer = free.allocate(size, maxtimetoblock);
// update the current time in case the buffer allocation blocked above.
nowms = time.milliseconds();
synchronized (dq) {
// need to check if producer is closed again after grabbing the dequeue lock.
if (closed)
throw new kafkaexception("producer closed while send in progress");
recordappendresult appendresult = tryappend(timestamp, key, value, headers, callback, dq, nowms);
if (appendresult != null) {
// somebody else found us a batch, return the one we waited for! hopefully this doesn't happen often...
return appendresult;
}
// 如果tryappend成功返回,就直接返回append的结果的封装对象recordappendresult,如果tryappend失败,那么就新创建producerbatch,这里就用到了上面的memoryrecordsbuilder机制来实现recordbatch缓冲区数据的追加及消息相关元数据的管理;
将新的producerbatch添加的batches队列,这样后续的消息就可以使用该producerbatch来追加消息了;
memoryrecordsbuilder recordsbuilder = recordsbuilder(buffer, maxusablemagic);
producerbatch batch = new producerbatch(tp, recordsbuilder, nowms);
futurerecordmetadata future = objects.requirenonnull(batch.tryappend(timestamp, key, value, headers,
callback, nowms));
dq.addlast(batch);
incomplete.add(batch);
// don't deallocate this buffer in the finally block as it's being used in the record batch
// 没在finally执行了buffer = null,是因为在finally块如果在buffer不为空的时候会进行释放bytebuffer内存,正常情况下因为消息成功的加入了缓冲区,不能进行释放,但是如果在执行的过程中发生了异常,没能成功加入缓冲区的情况下,要进行已分配bytebuffer内存的释放;
buffer = null;
return new recordappendresult(future, dq.size() > 1 || batch.isfull(), true, false);
}
} finally {
if (buffer != null)
free.deallocate(buffer);
appendsinprogress.decrementandget();
}
}recordaccumulater().append包含:recordaccumulater().tryappend(long timestamp, byte[] key, byte[] value, header[] headers, callback callback, deque<producerbatch> deque, long nowms)
1)从指定topicpartition对应的deque取最后一个producerbatch,因为每次append消息都是向队列最后一个缓冲区添加;如果队列中没有producerbatch,就直接返回null;然后在上面的append方法中会新创建producerbatch添加到队列;
2)调用producerbatch.tryappend方法试着将当前消息追加到最后一个缓冲数据流(bytebuffer)中;如果返回了null,说明当前缓冲区可能空间不足,那么就关闭当前producerbatch的数据写入,等待sender线程的发送;如果追加成功,就返回追加结果封装对象recordappendresult;
/**
* try to append to a producerbatch.
*
* if it is full, we return null and a new batch is created. we also close the batch for record appends to free up
* resources like compression buffers. the batch will be fully closed (ie. the record batch headers will be written
* and memory records built) in one of the following cases (whichever comes first): right before send,
* if it is expired, or when the producer is closed.
*/
private recordappendresult tryappend(long timestamp, byte[] key, byte[] value, header[] headers,
callback callback, deque<producerbatch> deque, long nowms) {
producerbatch last = deque.peeklast();
if (last != null) {
futurerecordmetadata future = last.tryappend(timestamp, key, value, headers, callback, nowms);
if (future == null)
last.closeforrecordappends();
else
return new recordappendresult(future, deque.size() > 1 || last.isfull(), false, false);
}
return null;
}recordaccumulater().tryappend包含:producerbatch().tryappend(long timestamp, byte[] key, byte[] value, header[] headers, callback callback, long now)
1)判断当前recordbatch是否有足够的空间,没有泽直接返回null;
2)在空间足够的情况下,调用memoryrecordsbuilder的append方法,最终调用就是appendwithoffset方法来追加当前记录到recoredbatch中;
3)futurerecordmetadata是作为保存消息发送的future元数据,在sender线程发送producerbatch时记录请求结果相关元数据的;
4)每个thunk保存着一个record消息发送的callback和futurerecordmetadata,所以每次追加消息记录的时候就会创建一个新的thunk封装用户自定义的callback和futurerecordmetadata,在sender线程处理结果中进行回调用户的callback和请求的结果处理
/**
* append the record to the current record set and return the relative offset within that record set
*
* @return the recordsend corresponding to this record or null if there isn't sufficient room.
*/
public futurerecordmetadata tryappend(long timestamp, byte[] key, byte[] value, header[] headers, callback callback, long now) {
if (!recordsbuilder.hasroomfor(timestamp, key, value, headers)) {
return null;
} else {
this.recordsbuilder.append(timestamp, key, value, headers);
this.maxrecordsize = math.max(this.maxrecordsize, abstractrecords.estimatesizeinbytesupperbound(magic(),
recordsbuilder.compressiontype(), key, value, headers));
this.lastappendtime = now;
futurerecordmetadata future = new futurerecordmetadata(this.producefuture, this.recordcount,
timestamp,
key == null ? -1 : key.length,
value == null ? -1 : value.length,
time.system);
// we have to keep every future returned to the users in case the batch needs to be
// split to several new batches and resent.
thunks.add(new thunk(callback, future));
this.recordcount++;
return future;
}producerbatch().tryappend调用:memoryrecordsbuilder().hasroomfor(long timestamp, byte[] key, byte[] value, header[] headers)
1)isfull()方法判断当前recordbatch是否满了;如果满了则不会再追加记录;
2)numrecords是已有的records数量;
3)然后就是针对v2和非v2格式的消息大小的计算处理;
4)在已有预估大小加上当前记录大小之后小于等于可用剩余空间才会返回true,表示空间足够;
/**
* check if we have room for a new record containing the given key/value pair. if no records have been
* appended, then this returns true.
*
* note that the return value is based on the estimate of the bytes written to the compressor, which may not be
* accurate if compression is used. when this happens, the following append may cause dynamic buffer
* re-allocation in the underlying byte buffer stream.
*/
public boolean hasroomfor(long timestamp, bytebuffer key, bytebuffer value, header[] headers) {
if (isfull())
return false;
// we always allow at least one record to be appended (the bytebufferoutputstream will grow as needed)
if (numrecords == 0)
return true;
final int recordsize;
if (magic < recordbatch.magic_value_v2) {
recordsize = records.log_overhead + legacyrecord.recordsize(magic, key, value);
} else {
int nextoffsetdelta = lastoffset == null ? 0 : (int) (lastoffset - baseoffset + 1);
long timestampdelta = basetimestamp == null ? 0 : timestamp - basetimestamp;
recordsize = defaultrecord.sizeinbytes(nextoffsetdelta, timestampdelta, key, value, headers);
}
// be conservative and not take compression of the new record into consideration.
return this.writelimit >= estimatedbyteswritten() + recordsize;
}memoryrecordsbuilder().hasroomfor调用:memoryrecordsbuilder().isfull()
1)appendstream上面讲过是bytebuffer的写入流dataoutputstream;
2)numrecords:当前已写入的record记录数;
3)writelimit:recordbatch的可用剩余空间带下,初始值就是batch.size;
4)estimatedbyteswritten()是预估当前已写入的recordbatch的总大小:日志头大小与records大小之和;
public boolean isfull() {
// note that the write limit is respected only after the first record is added which ensures we can always
// create non-empty batches (this is used to disable batching when the producer's batch size is set to 0).
return appendstream == closed_stream || (this.numrecords > 0 && this.writelimit <= estimatedbyteswritten());
}memoryrecordsbuilder().isfull()调用:memoryrecordsbuilder().estimatedbyteswritten()
1)batchheadersizeinbytes在v2消息格式下就是recordbatch结构下非record(日志头部分)的字节大小,总长度是61(b);
2)uncompressedrecordssizeinbytes:在每次追加record之后都会累加的值,表示已写入record的累加大小;
3)estimatedcompressionratio:预估的压缩率,目前4种压缩算法的值默认都是1.0;
4)compression_rate_estimation_factor:预估空间大小时用的一个值,默认1.05,应该是用于将预估值放大已确保追加记录时判断空间是否足够的准确性;
/**
* get an estimate of the number of bytes written (based on the estimation factor hard-coded in {@link compressiontype}.
* @return the estimated number of bytes written
*/
private int estimatedbyteswritten() {
if (compressiontype == compressiontype.none) {
return batchheadersizeinbytes + uncompressedrecordssizeinbytes;
} else {
// estimate the written bytes to the underlying byte buffer based on uncompressed written bytes
return batchheadersizeinbytes + (int) (uncompressedrecordssizeinbytes * estimatedcompressionratio * compression_rate_estimation_factor);
}
}producerbatch().tryappend包含:memoryrecordsbuilder().append(long timestamp, byte[] key, byte[] value, header[] headers)
memoryrecordsbuilder().append包含:...
memoryrecordsbuilder().append包含:memoryrecordsbuilder().appendwithoffset(long offset, boolean iscontrolrecord, long timestamp, bytebuffer key, bytebuffer value, header[] headers)
/**
* append a new record at the given offset.
*/
private void appendwithoffset(long offset, boolean iscontrolrecord, long timestamp, bytebuffer key,
bytebuffer value, header[] headers) {
try {
if (iscontrolrecord != iscontrolbatch)
throw new illegalargumentexception("control records can only be appended to control batches");
if (lastoffset != null && offset <= lastoffset)
throw new illegalargumentexception(string.format("illegal offset %s following previous offset %s " +
"(offsets must increase monotonically).", offset, lastoffset));
if (timestamp < 0 && timestamp != recordbatch.no_timestamp)
throw new illegalargumentexception("invalid negative timestamp " + timestamp);
if (magic < recordbatch.magic_value_v2 && headers != null && headers.length > 0)
throw new illegalargumentexception("magic v" + magic + " does not support record headers");
if (basetimestamp == null)
basetimestamp = timestamp;
if (magic > recordbatch.magic_value_v1) {
appenddefaultrecord(offset, timestamp, key, value, headers);
} else {
appendlegacyrecord(offset, timestamp, key, value, magic);
}
} catch (ioexception e) {
throw new kafkaexception("i/o exception when writing to the append stream, closing", e);
}
}memoryrecordsbuilder().appendwithoffset包含(v2版本):memoryrecordsbuilder().appenddefaultrecord(long offset, long timestamp, bytebuffer key, bytebuffer value, header[] headers)
private void appenddefaultrecord(long offset, long timestamp, bytebuffer key, bytebuffer value,
header[] headers) throws ioexception {
ensureopenforrecordappend();
int offsetdelta = (int) (offset - baseoffset);
long timestampdelta = timestamp - basetimestamp;
int sizeinbytes = defaultrecord.writeto(appendstream, offsetdelta, timestampdelta, key, value, headers);
recordwritten(offset, timestamp, sizeinbytes);
}高并发和线程安全保证
1 读写分离的设计copyonwritemap
recordaccumulator类中batches的实例类型是kafka自定义的类copyonwritemap,实现了接口concurrentmap,用读写分离来实现线程安全。
- 线程要修改map内容,就复制一份map,在修改之后,把新的指针赋给map,且put方法是加了 synchronized修饰的,因此同一时间只能有一个线程修改内容。
- 在修改的时候别的线程依然可以读取老的map。
源码如下:
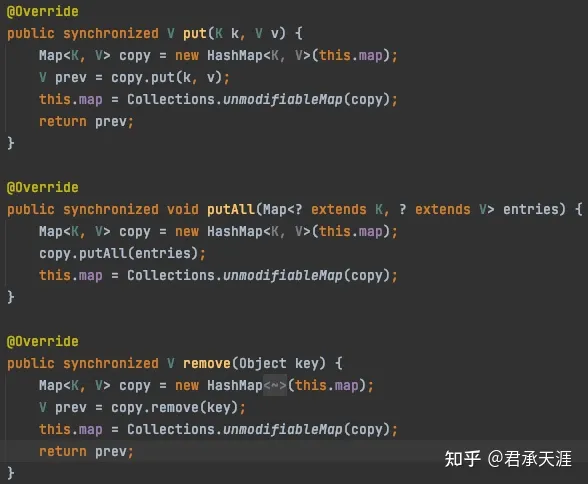
这个非常适合读多写少的场景。这里扩展两个细节:
2 消息追加方法recordaccumulator.append的线程安全和高并发效率的保证
在append方中,使用了synchronized同步锁来锁住deque,且使用了两次,这样设计的有何巧妙之处吗?
1)第一个地方:调用getorcreatedeque(tp)获取或者创建deque后,对dq进行加锁。
2)第二个地方:在分配了bytebuffer内存空间之后,再次对dp加锁
分析:这么做既保证了只有一个线程调用tryappend方法追加消息到缓冲队列,同时由防止了锁住整个batches的性能影响,且又能保证写batches的安全性,这里只锁住了dp,同时在上面的copyonwritemap中提到了该方法不会锁住读,所以也不会影响到其他线程读batches,所以也保证了高并发的效率;还有一点需要提到,这里锁住dp,然后追加消息记录到deque的最后一个批次缓冲中,除非批次没有足够的空间会再创建producerbatch,这样就能高效的利用每一个批次的缓冲区,防止了内存的支离破碎现象;
如何触发sender线程发送
具备发送条件的分区节点
缓冲区的消息在发送给kafka之前,sender线程会先调用recordaccumulator.ready方法来获取缓冲区中消息对应的分区中已经准备好的分区leader节点,以便将消息发送的分区对应的leader节点上。
那些情况属于准备好了呢?
- recordbatch 满了
- 消息在recordbatch中停留的时间超过了linger.ms;
- 消息缓冲区内存不足存在线程等待分配空间;
- recordbatch写入流关闭了
- 手动执行了kafkaproducer的flush方法:这会触发所有分区的ready来发送消息;
- 当满了上面说的5个条件之一时,设置sendable=true
- 在sendable=true且当前batch不属于重试时,就认为该分区leader节点已经准备就绪了:
- 否则可能就是sendable条件不满足或者是发送重试的batch,计算下次准备检查的时间nextreadycheckdelayms
- 封装ready计算结果对象readycheckresult
producerbatch过期处理
如果sender线程在发送缓冲区的消息时,发现缓冲区的消息停留的时间太长,这些消息的发送也许是没有意义的,也可能是因为kafka集群问题导致发送超时等等问题引起。消息缓冲区producerbatch过期后,对应的appendstream就会关闭不再允许写入数据了,且该producerbatch的状态就是abort了。
这里逻辑比较简单,主要就是过期的条件:linger.ms+request.timeout.ms之和,或者用户自定义的更小的投递超时时间;
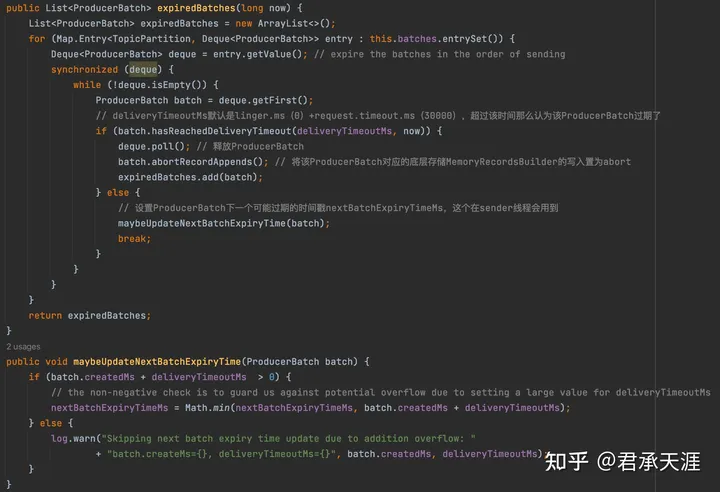
producerbatch重入队列
producerbatch重入队列有两种情况:
1 在sender线程发送producerbatch到kafka后,发生了异常,在可以重试的时候,就将producerbatch重新加入队列,等待下次重试的时候再从队列drain;
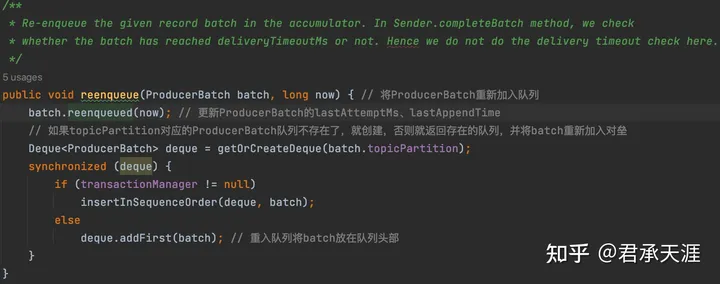
batch.reenqueued方法更新重入队列的相关时间:

2 kafka返回“message_too_large”时,进行batch的拆分和冲入队列。
1)在将bigbatch拆分只是将batches中的record拆分成多个producerbatch,但不会拆具体的record;
2)bigbatch拆分后,bigbatch自身也就不再支持写数据了;
3)需要注意一点:拆分的batches的内存不由缓冲池来管理,所以这部分内存的释放是在缓冲池外释放的;
总结:kafka 源码解析 - 消息收集器机制 - 知乎 (zhihu.com)
server篇
kafka源码分析(三) - server端 - 消息存储 - 知乎 (zhihu.com)
消费篇
kafka——消费者原理解析 - 简书 (jianshu.com)
spring kafka源码分析——消息是如何消费的_kafka messaging.handler.annotation.support.message-csdn博客
赞 (0)
您想发表意见!!点此发布评论



发表评论